



中文古籍数字化实践及研究进展(1)
李明杰 虞 有 周 亚 宋登汉
(武汉大学信息管理学院)
【摘 要】本文概述了现阶段中文古籍数字化发展现状,通过文献调研和数字统计对国内外图书馆、学术机构及数字出版企业古籍数字化成果的构成比例、地区分布、数据类型、载体与媒介类型、分类方法与系统功能、字库与字体特点等进行了详细分析,综述了中文古籍数字化理论研究成果,并就古籍数字化技术研究的发展阶段及热点问题展开了讨论。最后认为:建立国家范围内古籍数字化统一管理及协调机制,实现跨行业、跨地区乃至跨国界的联合协作是未来古籍数字化发展的方向;古籍数字化产品研制与古籍文献资源开发相结合的趋势将更加明显;古籍版本的非物质文化遗产保护将成为古籍数字化的重要职能之一。
【关键词】古籍数字化 古籍资源开发 古籍保护
Digitization Progress of Chinese Ancient Books in Practice and Research
Li Mingjie Yu You Zhou Ya Song Denghan
(School of Information Management of Wuhan University)
【Abstract】The paper reviews the development of the digitization of Chinese ancient books.By detailed literature investigation and statistics,it describes the proportions,regional distribution,data and medium types,classificationmethod and system functionsof these digital ancient books produced by domestic and foreign libraries,academic institutions and the digital publishing enterprises.And then,it summarizes the theorical and technical achievements on the digitization of Chinese ancient books.Finally,it suggests establishing a national management and coordination mechanism for the digitization of Chinese ancient books and argues that international collaboration across sectors and regionswill be the future of the develpomment of digitization of Chinese ancient books.The combination between the production of digital ancient books and the exploiture of literature resourceswill become closer and the preservation for intangible cultural heritage will be one of the functions of digitization of Chinese ancient books.
【Keywords】digitization exploiture preservation Chinese ancient books
1 中文古籍数字化发展概述
中文古籍数字化的实践最初是从计算机编制单书索引开始的。1975年,德国汉堡大学的吴用彤编制了英文版《诗经》索引,开启了计算机编制古籍索引的实践;1978年美国人P.J.Ivanhoe运用计算机编制了《朱熹大学章句索引》等经书索引(2);1983年,彭昆仑运用电子计算机分析统计了《红楼梦》中的时间进程和人物年龄问题;1984年,深圳大学建成了《红楼梦》多功能检索系统,这是国内较早的古籍数字化成果(3)。随后,国内外很多其他科研单位也纷纷利用计算机建立索引或全文检索系统。但这些系统大多是出于科研目的的试验性成果,而且,一般只在机构内部试用,没有进行大规模地推广与市场化运作。1984年,台湾“中央研究院”着手研制“瀚典全文检索系统”(4),这是古籍全文数字化大规模实践的开始。在古籍书目数据库建设方面,台湾地区也走在了前列。1981年起,台湾“中央图书馆”即着手编制古籍机读目录,1984年编目工作过渡到全面自动化阶段(5)。
20世纪80年代以后,包括台湾地区,中国内地和香港、欧洲、美国、日本、韩国等国家和地区均已开始中文古籍的数字化进程。参与古籍数字化的主体既有各类图书馆,如中国国家图书馆、南京图书馆、美国国会图书馆、台湾“中央图书馆”、大英图书馆、日本国立国会图书馆等图书馆;也有高等院校与科研院所,如中国社会科学院、东北师范大学、河南大学、四川大学、北京大学、台湾“中央研究院”、台湾元智大学、香港中文大学、日本东京大学东洋文化研究所等;还有为数不少的数字出版企业,如北京书同文数字化技术有限公司、爱如生数字化技术研究中心、北京国学时代文化传播股份有限公司等。这些数字出版企业虽然起步较晚,但取得了重要成果。
台湾元智大学罗凤珠教授在总结台湾地区古籍数字化发展进程时,将其归纳为5个阶段(6):①处理中文文字资料时期;②单机版古籍全文资料库的研发;③网络版古籍全文资料库的研发;④多功能、多媒体、多元化的文献数据库;⑤以3D动画技术呈现立体文献资料。实际上,这几个阶段的划分也基本符合中国内地和香港与国外中文古籍数字化实践的发展路线。第一个阶段是古籍数字化必须突破的技术瓶颈期(实际上,直到现在,字库问题仍是困扰古籍数字化的重要问题)。目前的古籍数字化成果中,多数处于第二、三阶段。其他几个阶段也有相应的成果,但总的来说仍处于试验或小范围内试用阶段。
2 中文古籍数字化成果的调查分析
笔者通过文献调查(7)与网络检索等途径,对目前国内外中文古籍数字化成果作了较为详尽的调查统计。调查对象包括图书馆(公共图书馆、高校图书馆、科研院所图书馆等)、高等院校与科研院所等学术机构(包括民间学术团体与个人)、数字出版企业(包括部分.COM域名网站);调查内容包括数据类型(书目、全文、影像、多媒体)、载体与媒介(单机版、网络版等)、分类方法、系统功能、是否收费(或IP限制)、字符集(GB2312、BIG5、Unicode等)、字体(简体中文、繁体中文)等;并对数字化成果进行了归类整理。
2.1 图书馆古籍数字化成果
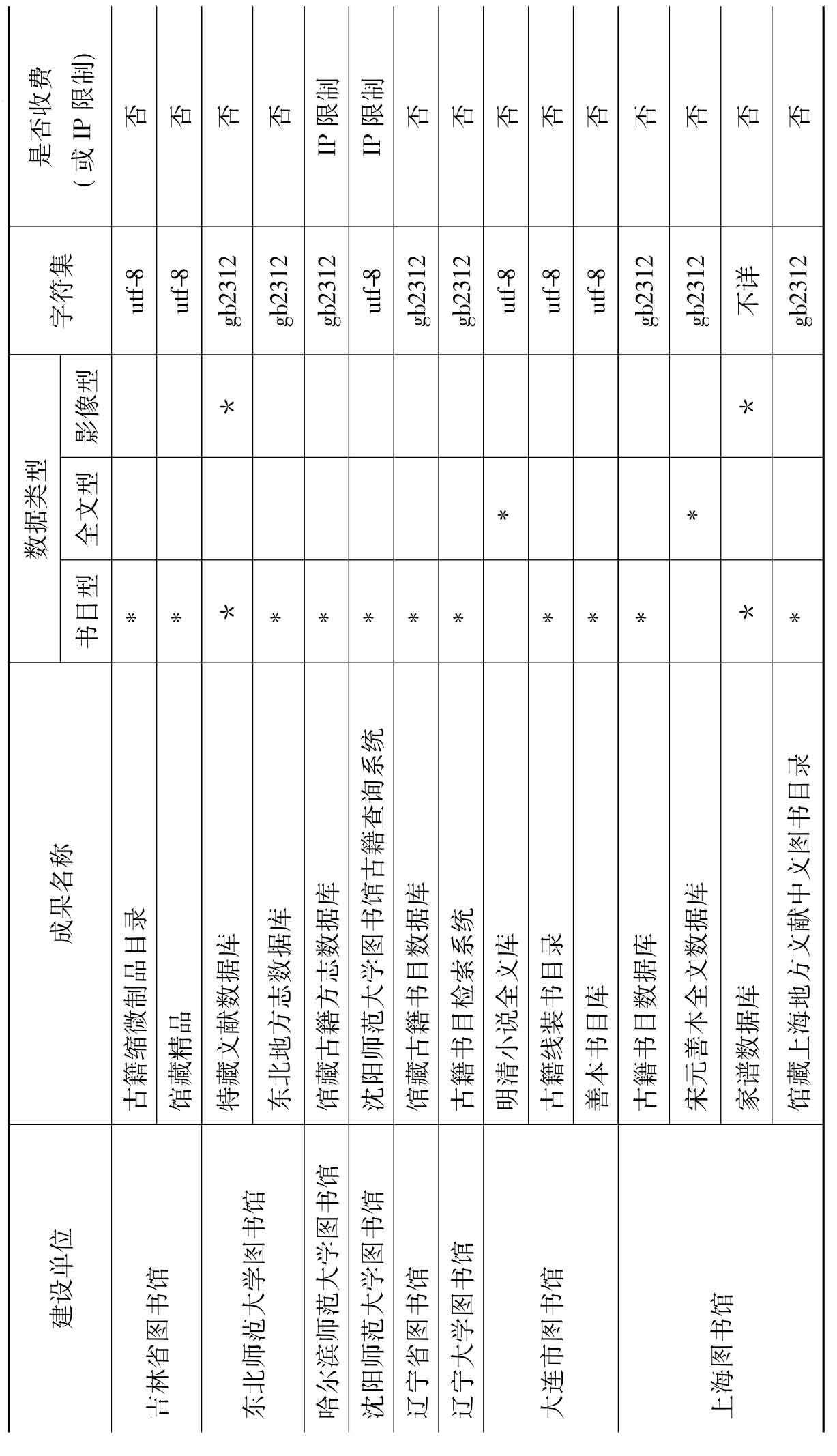
根据调查结果,笔者将国内外各类型图书馆所建中文古籍数据库的情况,按建设单位、成果名称、数据类型、字符集、是否收费(或IP限制)制成表1。
从表1可以看出,图书馆的古籍数字化成果很好地体现了公益性的性质:在建设的245种古籍类数据库中,231种(占94.3%)是免费向社会提供使用,只有14种(约占5.7%)数据库限制在图书馆局域网范围内使用(采用IP验证)。从数据类型来看,图书馆开发的古籍数据库以书目型最多,部分提供全文和影像数据。这表明,图书馆系统的古籍数字化水平还比较低,仍停留在揭示馆藏的层面。但不可否认,图书馆在古籍数字化领域的潜力非常巨大。从选题来看,公共图书馆非常注重根据自己馆藏的地方特色来开发本土文化资源,特别是地方文献(方志及家谱等)的数字化得到了高度重视。
2.2 学术机构古籍数字化成果
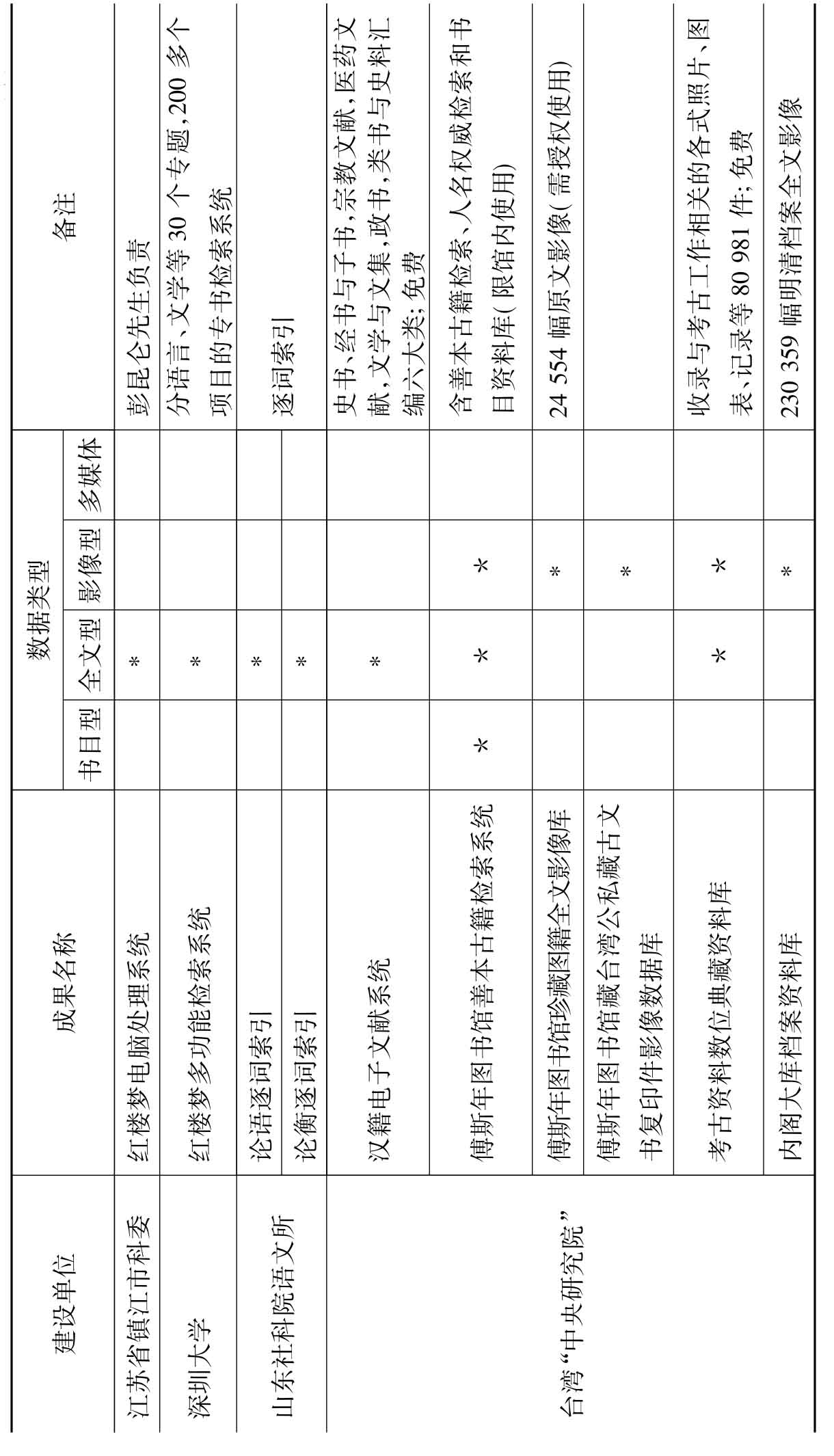
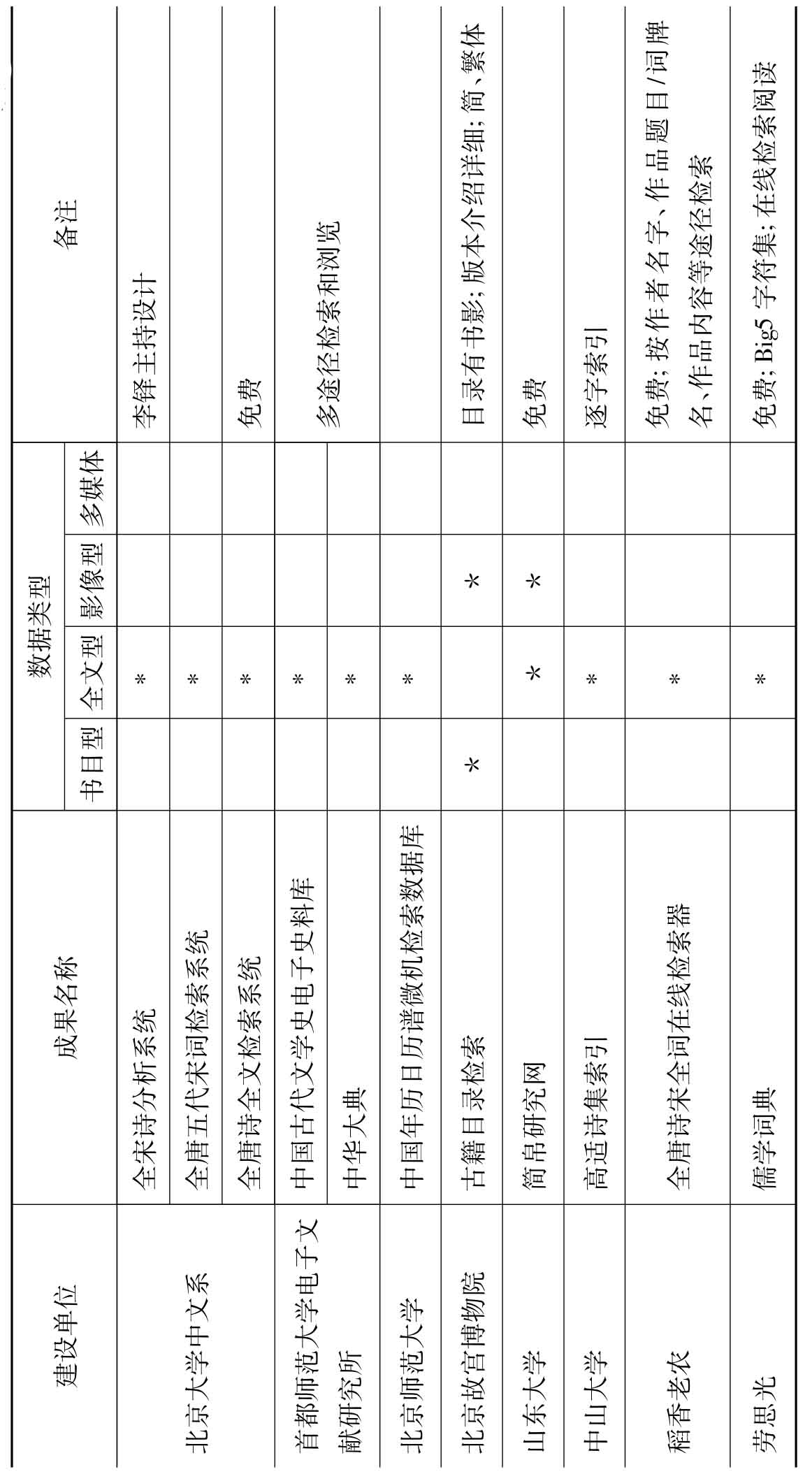
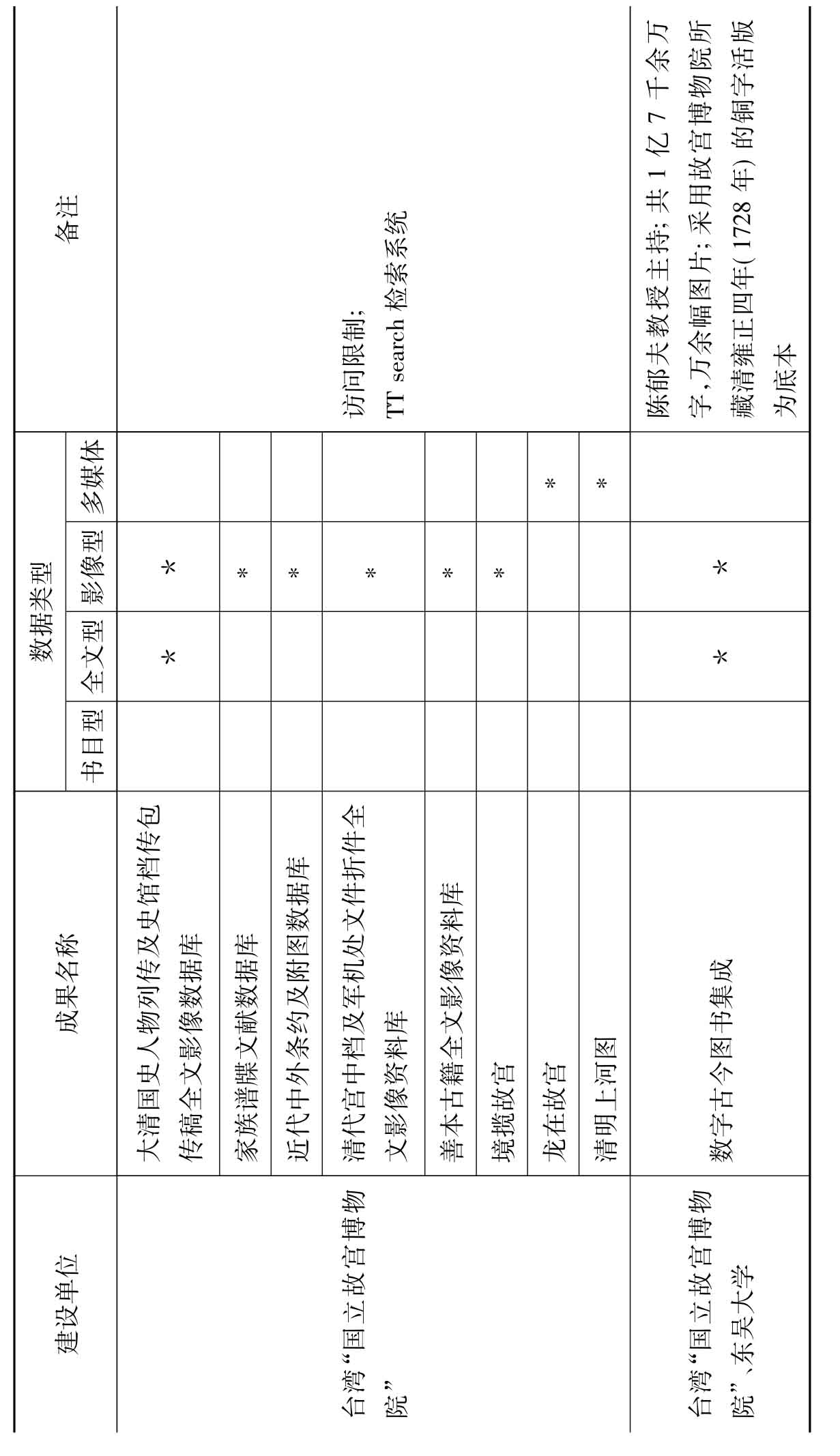
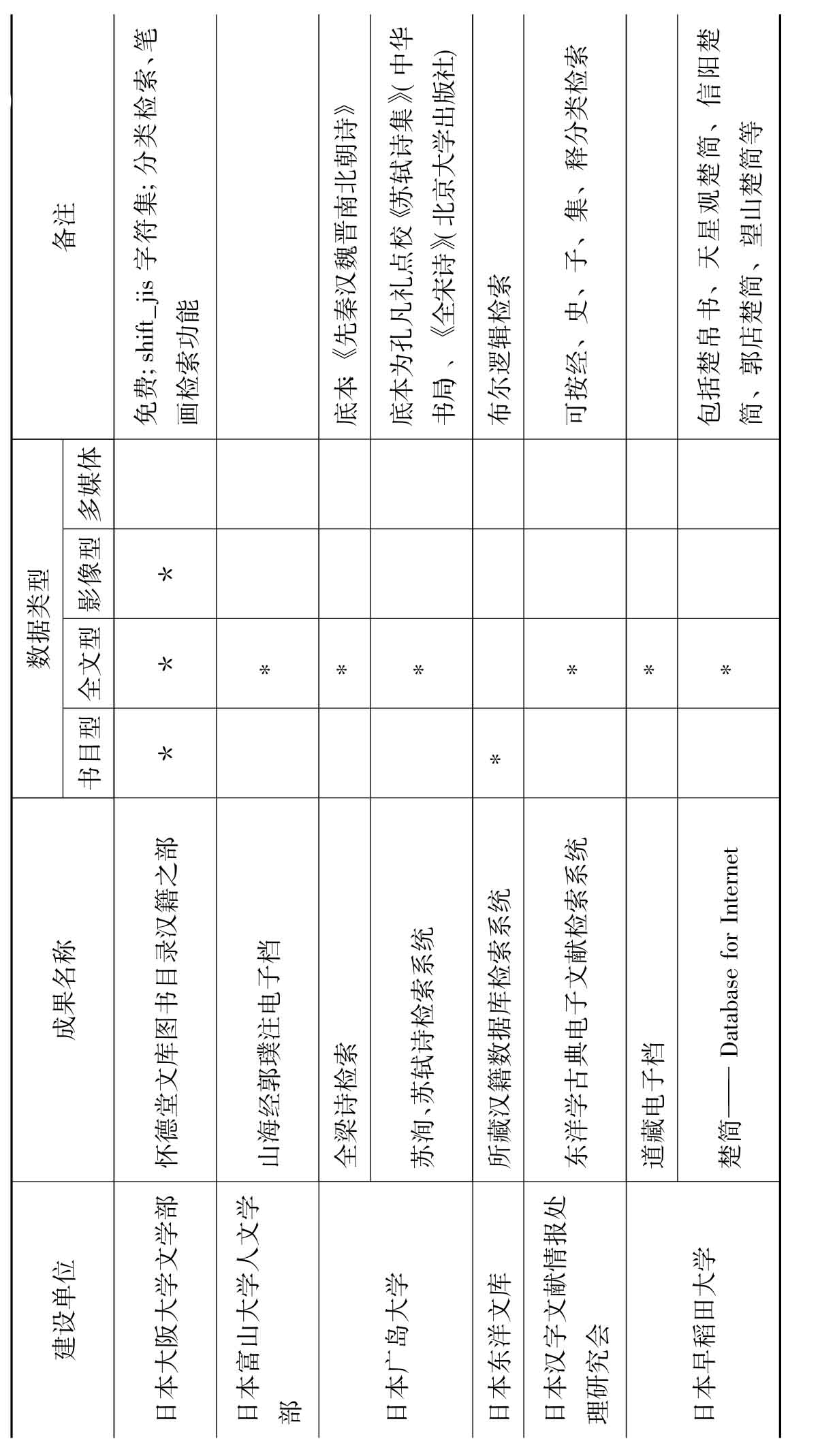
根据调查结果并结合学术机构(含民间学术团体与隶属于学术机构的个人)中文古籍数字化成果的特点,笔者将按建设单位、成果名称、数据类型、备注(资源内容及数量、是否为免费资源、字符集、系统功能等)等项,制成表2。
从表2可以看出,学术机构在古籍数字化方面有以下特点:一是参与的机构和个人数量比较多,多以专书、总集或丛书为数字化对象;二是注重满足教学和科研的实际需要,选题多集中在古典文学和历史研究领域,非常具有针对性和实用性;三是系统功能参差不齐,早期开发的系统一般只有简单的字词索引功能,而后期的古籍数字化系统功能比较强大,不断向多功能、多媒体、多元化数据库以及多元数据整合、知识增值利用的方向迈进。它们或依托强大检索功能而具有较强辅助研究功能,或利用3D等技术以多媒体呈现。例如:台湾大学研制的以3D技术模拟呈现的“士昏礼”系统,台湾“中央研究院”的“不朽的殿堂——汉代的墓葬与文化”,复旦大学中国历史地理研究中心研制的以时间、地点、人物为三轴的立体资料库“中国历史地理信息系统”、台湾元智大学罗凤珠教授开发建设的多媒体古典文学学习与研究平台“网络展书读”等。
2.3 数字出版企业(网站)古籍数字化成果
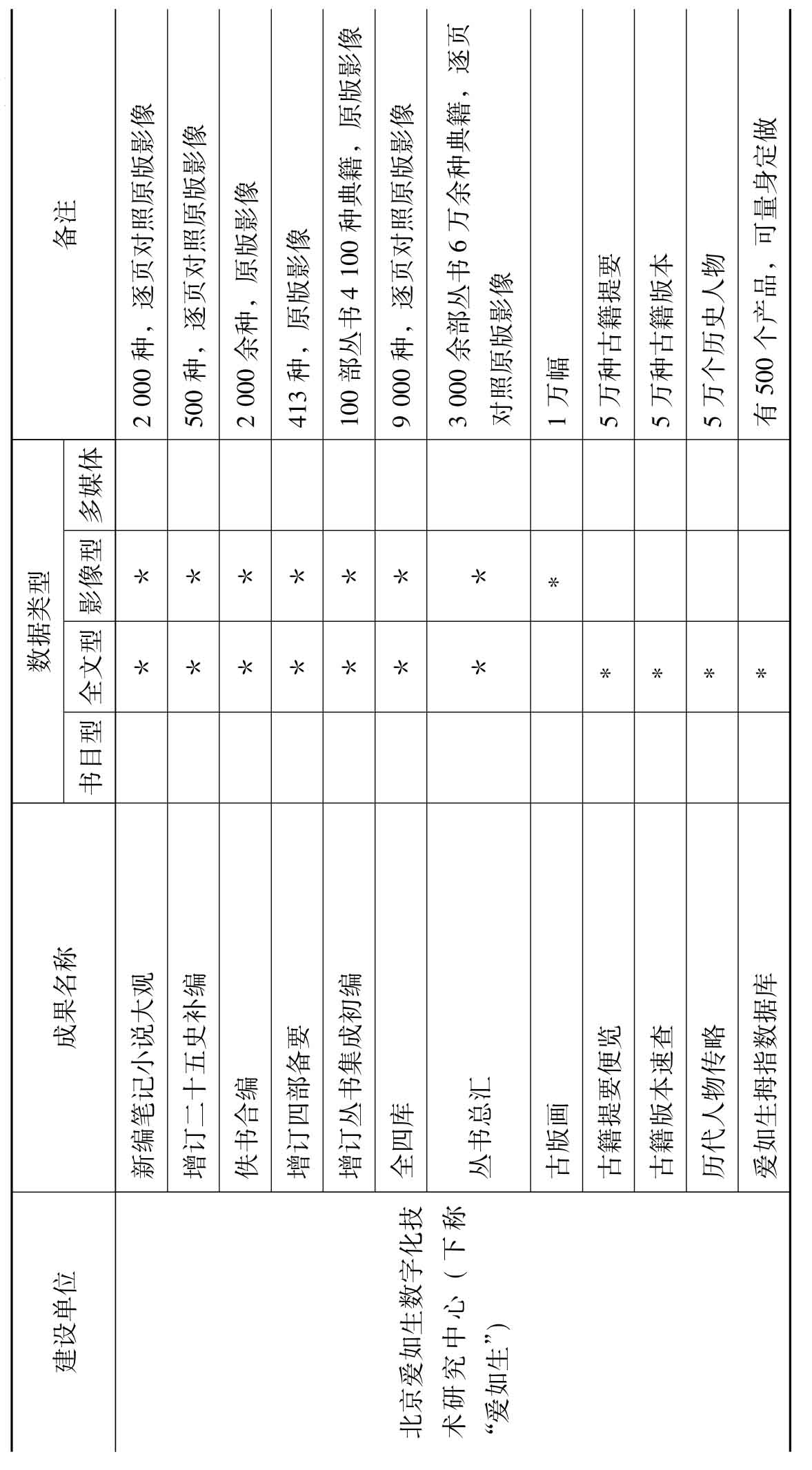
除了图书馆、学术机构外,数字出版企业(包括部分.COM域名的网站)也是从事古籍数字化的中坚力量之一。笔者对国内外从事中文古籍数字化的企业作了较详细的调查,并按企业名称、成果名称、数据类型、备注(是否免费资源、内容及数量、分类方法、字符集、载体等)等项目,制成表3。
表3调查的结果显示,数字出版企业开发的古籍数字化产品以大型的综合数据库(如中国基本古籍库、国学宝典)和丛书数据库(如《四库全书》、《四部丛刊》、《二十五史》等)为特色,比较成系统,功能强大,基本没有书目型数据库。除了能进行多途径的全文检索外,一般都配备有各种知识辅助工具,极大地改善了古籍研究条件,同时也为专业研究人员带来了研究思路和方法的革新。
表1 图书馆及其古籍数字化成果

续表

续表

续表

续表
续表

续表

续表

续表

续表

续表

续表

续表

续表

续表

续表

续表

续表

续表

续表

表2 学术机构含(民间学术团体与个人古)籍数字化成果

续表
续表

续表

续表

续表

续表

续表
续表

续表

续表

续表

续表
续表

续表

续表
续表

续表

续表
续表

表3 数字出版企业网(站)及其古籍数字化成果

续表

续表

续表

续表

续表

续表
续表

续表

续表

续表

续表

作为古籍数字化的一支新兴力量,参与古籍数字化的数字出版企业数量虽然不多,但取得的成绩却令人刮目相看。这与数字出版企业灵活的市场运作模式有很大关系。它们或依托图书馆的古籍善本资源,或吸纳文史专业研究人员参与研发,或与高校学术机构联合成立电子文献研究所,通过大规模、成系统地将常用基本古籍数字化,很大程度上满足了专业研究人员的需要。但需要指出的是,它们开发的数字化产品,选题重复情况比较严重,一味追求资源的规模和总量,有地方特色和专业特色的数据库不是很多,彼此之间缺少协作。
3 基于调查统计的分析
3.1 古籍数字化主体构成及成果数量比例
本次调查发现,国内外共有271家单位(含隶属于某机构的个人)参与古籍数字化建设(因条件所限,可能与实际情况存在一定偏差)。其中,以图书馆数量最多,有124家;学术机构其次,有111家;数字出版企业数量最少,有36家。表4列出了各类型建设单位的数量(单位:家;按地区复分)、主体比例(该类型建设单位数量/各类型古籍数字化单位总数)、成果数量(包括各种书目数据库、全文数据库等;单位:种;按地区复分)、成果比例(该类型建设单位成果数量/现有古籍数字化成果总数量)、平均成果数量(该类型建设主体的成果数量/该类型建设单位的数量)。
表4 中文古籍数字化主体构成及成果数量比例

表4中的数据显示,中文古籍数字化成果比例最高的依次是图书馆、学术机构和数字出版企业,但效率最高的却是数字出版企业。数字出版企业在古籍数字化方面虽然起步较晚,数量不多(36家),但却在古籍数字化领域,尤其是大型古籍全文数据库的开发方面具有举足轻重的地位。表现在:①只占13%的数字出版企业却开发了25%的成果,平均成果数量最高;②其产品很多都是大型综合数据库。许多数据库的字数都在1亿字以上,如国学公司的“中国历代基本典籍库·隋唐五代卷”(1亿字)、爱如生的“中国基本古籍库”(8亿字)和“中国经典库”(20亿字)等;③很多产品在社会上具有广泛影响。例如,香港迪志文化出版有限公司与书同文、上海人民出版社合作开发的《文渊阁四库全书》被认为在古籍数字化的道路上具有里程碑意义(8);爱如生与北大中文系合作开发的“中国基本古籍库”在各大高校图书馆也得到了广泛的认可和应用。另外,数字出版企业的产品基本是以赢利为目的,但也有一些成果(10种左右,约占6.8%)免费向社会公众提供使用,如百度公司的“百度国学”、国学公司的“彩图版二十六史”、“古籍电子定本工程”等。这些企业的免费古籍电子产品,为在全社会普及传统文化知识、形成良好的阅读氛围起到了一定的积极意义;同时,也彰显了企业的社会责任感与传播文化的使命感。
3.2 国家与地区分布
目前从事古籍数字化建设的271家单位中,中国内地有179家,占66%;中国港台地区有28家,占10%;日本、美国、英国等国共有64家,占24%。表5列出了中文古籍数字化单位在各个国家和地区的详细分布情况。
表5 中文古籍数字化单位地区/国家分布表

从表5可以看出,中国内地古籍数字化单位多分布很不平衡,多集中在经济和科教较为发达的地区。北京、江苏、浙江、上海等地区经济发达,企业、高校与科研院所较多,图书馆事业相对发达,具有进行古籍数字化的经济、技术与资源优势。结合表4中的数据,内地古籍数字化的单位数量与成果数量,以图书馆为最多。港台地区较早开始了古籍数字化工作,从事该工作的机构也较多,主要为高等院校、科研院所等学术机构。国外的古籍数字化单位也以学术机构为主,日、英、美等国的图书馆(主要为国家图书馆、高校的东亚图书馆)收藏中国古籍较多,也积极从事古籍数字化工作。其中,日本从事中文古籍数字化的机构最多,这与该国的汉学与中国学研究传统是密切相关的。值得指出的是,印度虽有16家古籍数字化单位,主要是因为其在“大学数字图书馆国际合作计划”(CADAL)中与中美两国有着良好的合作,并不足以说明其在古籍数字化领域有超越英美等国的表现。
3.3 数据类型
根据数据类型(书目、全文、影像、多媒体)的不同,现有古籍数字化成果可分为以下类别:A.纯书目型数据库;B.纯文本全文数据库;C.纯影像数据库;D.书目与文本结合型数据库;E.书目与影像结合型数据库;F.文本与影像结合型数据库;G.书目、文本、影像综合型数据库;H.多媒体数据库。现将目前主要古籍数字化成果按以上类型分类,制成表6。
从表6可以看出,图书馆的古籍数字化成果中,纯书目型数据库最多(占63%),几乎没有进行书目、全文、影像综合型数据库与多媒体数据库的建设;学术机构主要从事纯文本全文数据库的建设(占61%),也全面涉足其他类型数据库的建设;数字出版企业的数据库产品最多的是文本与影像结合型数据库(占49%)(即图文结合数据库),纯文本全文数据库也较多(占43%),较少涉及书目类数据库的建设。从总体上讲,现有古籍数字化成果中,纯文本全文数据库的种类最多(占36%)(主要是学术机构开发的),
表6 古籍数字化成果数据类型统计

紧随其后的是纯书目型数据库(占31%)(主要是图书馆建设的),文本与影像结合型数据库(即图文结合数据库,主要是企业开发的)占17%,书目与文本结合型数据库最少,也出现了一些多媒体数据库(13种)(主要是学术机构研发的)。可以看出,当前古籍数字化成果主要为传统意义上的数据库类型,而综合应用文字、图像、音频、动画等数据类型的多媒体数据库具有很大的发展潜力。
3.4 载体与媒介类型
古籍数字化成果的存储与传播媒介是和技术同步发展的。早期的古籍数据库一般是以单机版形式存在的,以光盘或计算机硬盘为存储媒介;随着互联网技术的发展,开始通过网络在局域网或更大范围内传播,很多图书馆建立了自己的古籍目录查询系统;而随着移动硬盘和移动通信等技术的发展,很多数字出版企业的产品也出现了一些新的载体类型,例如国学公司研制了一些U盘版、笔记本版、手机版的产品,载体类型更趋多样化。总的来说,图书馆的古籍数字化成果以网络传输为主,而学术机构与数字出版企业的古籍数字化成果则以光盘版等单机形式居多。
3.5 分类方法与系统功能
在分类方面,不同系统采用的分类方法不同。现将目前古籍数据库所采用的主要分类方法归纳如下:①四部分类法(经、史、子、集;甲、乙、丙、丁;或在经史子集类目基础上增加丛书类等):如吉林大学图书馆的“古籍在线阅读”、武汉市图书馆的“馆藏古籍善本数据库”、百度公司的“百度国学”、国学公司的“国学宝典”等;②八分法:例如,清华大学图书馆的“馆藏古籍目录”检索系统将古籍分为甲(总类)、乙(哲学)、丙(自然科学)、丁(应用科学)、戊(社会科学)、己(历史地理)、庚(文学)、辛(艺术)八类;③按时间(朝代)分类:例如,国学公司的“古代小说典”、“中国历代笔记”等;④按体裁分类:如国学公司的“中国古代戏剧专辑”光盘数据库;⑤中国图书馆图书分类法:例如,超星集团的“古籍电子图书”、江西省图书馆的“地方志查询”等;⑥中国科学院图书馆图书分类法:例如,北京语言大学图书馆的“古籍书目数据”、山西省图书馆的“馆藏地方志书目提要”等;⑦其他分类法:LCC,如美国国会图书馆的“Online Catalog”;NDLC,如日本国立国会图书馆馆藏古籍OPAC检索系统等。
从系统功能来看,目前古籍数字化系统已趋成熟的功能有:①书目、全文及影像浏览:按类别、书名、作者等分类浏览;②书目检索:按书名、作者、主题等单一字段基本检索或多字段组合的复合检索;布尔逻辑检索(专家检索);二次检索(进阶检索);③全文检索:任意关键词或关键词组配的全文检索。目前应用较多的功能有:①对数据库内容的操作处理:放缩、高清查看、翻转、点缀、设置、标注、书签、打印、下载、版式设定、字体转换、分类收藏、版本速查、编辑等(在商业数据库中较多);②增设常用工具:配备联机古汉语字典、人名词典、书名词典、帝王纪年等常用数据库工具和生僻字输入工具、古今纪年换算、干支公元换算、简繁字异体字对照表等辅助检索与学习工具。③智能检索:全文逐字注解,动态关联人名、书名、帝王年号等,实现关联查询、语义模糊检索;④统计功能:字词统计等。目前已实现但不太普遍的功能包括:①时空检索:利用GIS技术,在时间和空间的层次上进行文献资源数据的检索,北京大学图书馆“古文献资料库”的拓片检索有此功能;②智能化分析:例如,国学公司的“三国演义电子史料库”具有文本比对、图文对照、同词脱文分析、文本差异分析、相似程度分析、小说历史对照等智能化功能;国家图书馆的“中国古籍善本书目导航系统”可对人物(刻书家、藏书家等)、人物相关性、动作(刻、跋等)、时间(朝代)等进行数据分析,并将分析结果以可视化的形式展现;③多媒体元素综合:增加背景音乐、动画、彩色插图等多媒体形式,融声、乐、图、画等现代元素于一体。
3.6 字库与字体
字库是应用于计算机、网络及相关电子产品上的中外文字体及其相关字符的电子文字字体集合。目前出现的字库有GB、GBK等。不同字库所收录的文字数量不同,对古籍数字化具有重要影响。以图书馆古籍数字化成果为例:在245种古籍数据库中,采用GB2312的最多(148种,占60%);采用Unicode的有52种,占21%;采用Big5和GBK的有21种,占9%;其他的采用EUC、iso-8859-1等字符集。图书馆的古籍数据库较多地采用GB2312字库,这与数据库多为简体中文有关,但由于GB2312仅收录6 763个常见汉字,很多古籍中的繁体字及冷僻字不能显示,这在一定程度上造成了古籍信息内容的失真与错误。Big5和GBK则多为港台地区所采用。较少采用Unicode字符集不仅限制了古籍数据库的建设(受限于冷僻汉字的显示问题),同时,也在一定程度上限制了古籍数字化资源跨平台与跨地区的资源共建共享。
在是否采用繁体字方面,不同单位、不同系统的做法也不一样。总的来说,内地的古籍书目类数据库较多地采用简体字,也有一些单位采用繁体字,例如,复旦大学图书馆“明人文集书目”、“清人文集书目”、武汉大学图书馆的“馆藏古籍善本数据库”等;中国港台地区与国外的古籍数字化成果则较多地采用繁体中文。
4 中文古籍数字化理论探索
4.1 古籍数字化概念
1995年,上海博物馆的祝敬国在《古籍语料库字体与结构研究》一文中首先使用了“古籍电子化”这一术语(9)。1997年,刘炜《上海图书馆古籍数字化的初步尝试》一文提出了“古籍数字化”这一概念(10)。此后,其他学者也纷纷撰文提出了类似的概念。总的来说,“古籍数字化”、“古籍电子化”这两个概念起初基本上是交替使用的,这主要是由于20世纪90年代对“数字化”、“电子化”这两个概念混用造成的。
21世纪初,学术界才有了明确的古籍数字化(电子化)定义。2000年李运富在《谈古籍电子版的保真原则和整理原则》一文中首次界定了“古籍电子化”的概念:“所谓古籍电子化,是指利用现代信息技术,将历来以抄写本、刻铸本、雕版、活字版、套版及铅字印刷等方式所呈现的古代文献,转化为电子媒体的形式。”(11)此概念仅着眼于古籍文本的技术转化角度,缺少对古籍数字化功能和目标的界定。彭江岸补充认为:“古籍数字化就是利用数字技术将古籍的有关信息转换成数字信息,存储在计算机上,从而达到使用和保护古籍目的。”(12)类似的定义还有,如孙安认为:“古籍数字化就是利用现代信息技术将古籍转化为电子媒体的形式,通过光盘、网络等介质予以保存和传播。”(13)童顺荣将古籍数字化概括为“古籍数字化是利用现代信息技术将古籍转化为数字化形式进入存储和利用。”(14)以上可看作古籍数字化概念发展的第一个阶段,可概括为“古籍存储介质转换”说。
将对古籍数字化的认识仅仅限于存储介质的转换,而忽略计算机对古籍内容强大的加工处理功能,显然是不可取的。因此有学者进一步认为,在实现媒介转换的同时,还应深入揭示古籍的内容资源。例如,张雪梅认为:“古籍数字化就是采用计算机技术,对古籍文献进行加工、处理,制成古籍文献书目数据库和古籍全文数据库,用以揭示古籍文献中所蕴涵的极其丰富的信息资源,从而达到使用和保护古籍的目的。”(15)刘琳、吴洪泽在《古籍整理学》一书中对古籍数字化作了动态描述:“所谓古籍数字化,就是将古代典籍中以文字符号记录的信息输入计算机,从而实现了整理、存储、传输、检索等手段的计算机化。”(16)毛建军在分析综合上述观点的基础上指出:“古籍数字化就是从利用和保护古籍的目的出发,采用计算机技术,将常见的语言文字或图形符号转化为能被计算机识别的数字符号,从而制成古籍电子索引、古籍书目数据库和古籍全文数据库,用以揭示古籍文献信息资源的一项系统工作。”(17)潘德利认为,古籍数字化是“采用计算机技术对古籍文献进行加工、处理,制成古籍文献书目数据库和古籍全文数据库,用以揭示古籍文献中所蕴涵的极其丰富的信息资源,为古籍的开发利用奠定良好的基础。”(18)王刚把古籍数字化概括为“古籍文献制作成数字成品的过程,是利用现代计算机信息技术,将常见的语言文字或图形符号转化为能被计算机识别的数字符号,从而制成古籍文献书目数据库和古籍全文数据库,用以揭示古籍文献中所蕴涵的极其丰富的信息资源,通过光盘、网络等介质保存和传播,为古籍的开发利用奠定良好的基础,从而达到保护和利用古籍的目的。”(19)以上可以看作古籍数字化概念发展的第二个阶段,或可概括为“古籍内容资源开发”说。
随着古籍数字化实践的深入,人们又进一步认识了古籍数字化的本质。1999年,史睿在《论中国古籍的数字化与人文学术研究》一文中指出:“古籍数字化的理论问题比技术问题更为重要,因为一旦理论发生了偏差,技术越高明,则解决方案越是难以成功。”(20)2002年,他明确指出,古籍数字化属于古籍整理和学术研究(或称校雠学)的范畴。并强调,就本质而言,学术研究的应用要求在于“知识发现”(21)。2005年,李明杰在《中文古籍数字化基本理论问题刍议》一文中延续了史睿的观点,并作了进一步阐述:“从本质上讲,古籍数字化不是一个单纯的技术问题,而是一个文化问题和学术问题。古籍数字化是以保存与普及传统文化为基本目的的,以知识发现的功能服务学术研究为最高目标的,在对传统纸质古籍进行校勘整理的基础上,利用计算机技术将其转换成可读、可检索及实现了语义关联和知识重组的数字化信息的过程。”(22)这一观点,实际上是把古籍数字化看作是传统古籍整理在新技术条件下的合理延伸。此可视作古籍数字化概念发展的第三阶段,或可称之为“古籍整理与学术研究”说。
4.2 古籍数字化基本理论构建
相对于方兴未艾的古籍数字化实践热潮,古籍数字化理论研究显得稍稍有些滞后。古籍数字化基本理论研究大致是从以下几方面展开的:
第一,关于古籍数字化的性质。正确认识古籍数字化的性质,有助于深刻理解古籍数字化的内涵。史睿是最早关注古籍数字化基本理论问题的学者之一。早在2002年,他在《数字化条件下古籍整理的基本问题(论纲)》一文中首次阐明古籍数字化的性质:“古籍数字化属于古籍整理和学术研究(或称校雠学)的范畴。”(23)2005年,李明杰在此基础上对古籍数字化性质的认识又有所升华:“古籍数字化不是一个单纯的技术问题,但也不同于一般的学术研究,而是属于古籍整理的范畴,是传统校雠学在现代技术条件下的合理延伸。”(24)2006年,毛建军也基本沿袭了上述观点:“古籍数字化是对古籍或古籍内容的再现和加工,属于古籍整理的范畴,是古籍整理的一部分。古籍数字化是21世纪古籍整理的主流,代表着未来古籍整理的发展方向。古籍数字化属于古籍整理和学术研究(或称校雠学)的范畴。”(25)应该说,在古籍数字化性质的认识方面,学界基本达成了共识。
第二,关于古籍数字化基本特征。2002年,李国新在《中国古籍资源数字化的进展与任务》一文中也强调,数字化古籍必须对古籍原典作出具有计算机浏览、检索、利用特点的深度开发。他认为,“古籍数字化”应具备四个基本特征:即实现文本字符的数字化、具有基于超链接设计的浏览阅读环境、具有强大的检索功能、具有研究支持功能(26)。2006年,牛惠萍在《对我国古籍数字化相关问题的研究》(27)一文中重申了李国新的观点。2007年,徐清在《古籍数字化资源的深度开发》(28)将古籍数字化资源的深度开发目标定位于提供基于超文本的立体阅读环境、建立强大的智能化检索系统、提供科学准确的统计数据和信息,实际上仍未能逾越李国新提出的四个特征。
第三,关于古籍数字化的原则。2002年,史睿最早提出了古籍数字化必须遵循的四个原则:①古籍数字化属于古籍整理和学术研究的范畴;②必须遵循古籍整理的基本原则,懂得学术研究的基本思维过程;③遵循以应用为指针的原则;④必须建立在深入标引和严格规范控制的基础上(29)。这四个原则的提出,对于古籍数字化具有方向性的指导意义。2006年,郑章飞认为,作为保护和弘扬中华文化遗产的一项工作,古籍文献数字化应遵循以下五个原则(30):①保真原则。即数字化古籍产品应该具有“文物存储性”,具有重现作为历史文物的古籍原貌的功能,具体表现是数字化古籍产品应该形成数字图形版。②整理原则。即数字化古籍产品应该具有“资料应用性”,具有超文本浏览阅读、全文检索、研究支持等功能,具体表现是数字化古籍产品应该形成数字文本版。③标准化原则。标准化是古籍数字化的基础,直接影响古籍数字资源的制作质量和咨询服务的效果。标准化的主要内容有数据格式标准化和标引语言标准化。④网络化原则。网络化是古籍数字化的发展趋势,这主要是基于信息资源共享的考虑。一方面,可以发挥网络传输迅捷、异地使用的特点,供全民共享,使其资源社会效益最大化;另一方面,也可为古籍数字化选题提供快捷的参考信息,避免选题过于集中和重复。⑤整体规划、合作共享原则。古籍数字化应向总体规划、合作共享的方向发展,以保证古籍文献资源的广泛传播。以上两个原则体系,可以互为补充。
第四,关于古籍数字化的理论体系。毛建军在分析当前古籍数字化实践及研究的现状后指出,随着古籍数字化资源的丰富和开发经验的积累以及古籍数字化理论的成熟,古籍数字化必将为传统的古典文献学开拓新的研究领域带来新的发展契机。他依据于鸣镝先生提出的“大文献学”理论,构建了古籍数字化的理论体系(31):①数字化古籍生产学:研究古籍数字化编辑及其规律的科学;②数字化古籍流通学:研究数字化古籍出版、发行、典藏及其规律的科学;③数字化古籍整序学:研究数字化古籍索引、导航和链接原理及方法的科学;④数字化古籍利用学:研究如何有效利用数字化古籍的科学。2009年他主编的《古籍数字化的理论与实践》一书由航空工业出版社出版,标志着古籍数字化的理论建构已具雏形。
5 中文古籍数字化技术研究
5.1 发展阶段的划分
中文古籍数字化技术的发展,是与古籍数字化过程及古籍书目库的建设、发展阶段相对应的。它大体可以分为以下三个阶段:
第一阶段:探索阶段(20世纪70年代到90年代中期)。这一阶段的技术特征是利用计算机技术探索建立书目数据库和专题索引库,因此研究重点主要集中于计算机索引技术、汉字字符集的设计,特别是如何利用计算机辅助索引的编制来对专书进行检索、统计等,如20世纪80年代武汉大学陈光祚进行的地方志检索系统的研究(32)。1987年6月,哈尔滨师范大学李波等建成《史记全文检索系统》,北京师范大学建成了中国年历日历谱微机检索数据库等。同时,不少研究者针对古籍录入过程中遇到的庞大的汉字字符集问题,认为汉字字符集是古籍数字化的一个基础性的工作,是关系到数字化能否成功实现的关键,因此提出建立符合中国古籍特点的中文平台(33)。
第二阶段:产品输出阶段(20世纪90年代中期到2000年左右)。这一阶段,汉字字符集的进一步统一、文字录入、图像识别以及版面还原等技术成为研究与探索的主要内容。古籍数字化虽然都需要借助于计算机信息技术将纸质文献转换为数字化的多媒体信息,但在古籍具体数字化过程中,依据需求和目标等的不同,具体的录入方式也存在差异,包括手工录入的方式、以图像形式保存古籍文献的方式、图文结合建立数据库的方式等。吴民《论古籍数字化建设》分别介绍了这三种录入方式的优点和不足,并指出,图文结合建库的方式不仅能有效综合其他两种方式优势,同时也最大限度地克服了其他两种方式之不足(34)。随着古籍数字化工资的深入开展,图文结合建库的方式因其优势得到了越来越多的应用和发展。北京书同文公司在研制《文渊阁四库全书》电子版时,与清华大学合作完善了OCR技术,并开发出与之配套的校对软件。这一尝试意味着利用OCR技术扫描录入将成为一种重要的古籍录入方式。但OCR技术扫描录入的局限为速度不够快,处理大幅面的古籍比较麻烦,因此有学者指出,数码相机拍摄可以克服这些局限(35)。随着数码拍摄技术的成熟及与之配套的校对软件的完善,可以预见,图文结合建库这种方式有望成为古籍数字化的主导方式,也将是古籍全文数据库建设的方向。
第三阶段:功能提升阶段(2002年至今)。以基于互联网的古籍数字化产品和大型全文数据库的出现为标志,全文检索、可视检索、知识库等技术得到了快速发展;同时针对古籍的统一字符集的问题,研究者也作了进一步探索。在全文检索与基于Web检索方面,2005年研制成功的《中国基本古籍库》总计500张光盘、20亿字数、2 000万页图像,收录了先秦到民国时期的典籍1万余种,提供一个通行版本的全文信息和1~2个重要版本的图像信息,利用ASE检索系统,可以进行分类检索、条目检索、全文检索和高级检索,速度都可以在两秒内完成,方便快速,具有良好的阅读编辑功能(36)。关于字库技术,2002年出版的《西夏文字数字化方法及其应用》系统介绍了非汉字古籍数字化的方法,讨论了西夏字库的建立和编码及版面识别等问题(37)。2006年刘博在《大规模古籍数字化之汉字编码选择》一文中,分析了ISO/IEC10646和Unicode对古籍数字化的重要意义,探讨了以Unicode为汉字编码的古籍数字化的跨平台展现(38)。徐健、肖卓针对古籍数字化工作中大量繁难汉字录入和显示困难的问题,从计算机汉字输入与显示的基本原理入手,从五个方面提出了具体解决方案,较好地解决了古籍繁难文字处理的难题(39)。而黄飞龙提出针对W indows最新的操作系统,利用其Unicode平台进行蒙古文古籍版本库的构建,该数据库系统除了基本功能(填加、修改、检索、统计、关联推荐)之外,还将提供容错检索、拉丁文转写自动生成、传统蒙古文排版、多种蒙古文的录入解决方案、版本统计等。这是中国第一个基于Unicode编码的少数民族语言文字建立的数据库(40)。
5.2 研究热点分析
5.2.1 古籍书目数据库
古籍书目数据库建设是我国最早开启古籍开发研究的领域。早在1988年,东北师大古籍研究所就开始了这方面的尝试。1991年,刘乾先对利用计算机整理及检索古籍的经验进行了总结,对该项工作的起因、准备和具体运作流程作了介绍,描述了计算机处理和检索古籍数据的功能和优越性(41),这在当时的中国内地是具有开创意义的。1992年,李致忠在《略谈建立中国古籍书目数据库》一文中,首次提出了建设中国古籍书目数据库的整体构想,对古籍书目数据库建设的基础性问题进行了分析,提出要制定统一的录入工作单(42)。该文的发表,对中国古籍书目库的建设指明了科学和规范化的方向。由于当时在中国内地建立古籍书目数据库尚属空白,很多技术和经验尚未积累,急需借鉴其他国家和地区的先进经验,因此张治江(43)、姜振儒(44)等对国外古籍目数据库建设的情况作了介绍。1995年,李致忠先生结合几年来的思考又撰写了《再论建立中国古籍书目数据库》,对统一建库的认识更进一步,提出了“统一建库认识、统一建库规范、统一古籍机读格式、统一建库软件、统一字库”等意见(45)。1993年,北京大学图书馆设立了古籍合作编目工作站并实现了跨域通信。1995年,工作站正式运行,其时共有北大图书馆、中科院图书馆、辽宁省图书馆、湖北省图书馆、复旦大学图书馆等单位加入,以工作单形式向RLG-CHRB提交中国内地的古籍善本书目数据。杨光辉在总结这一跨国合作项目的经验时指出,中国完全有能力建设自己的古籍书目数据库,并提出以这五大图书馆为核心,依托通信网进行全国小范围的合作编目(46)。该项目的启动和运作,第一次在中国内地范围内引入了古籍机读格式,并在古籍数目数据库的全面建设、规范制定、协调统一等方面积累了不可多得的经验。与此同时,依托国家图书馆建设古籍书目数据库也引起了许多有识之士的关注。刘刚指出,应该把古籍数据库的建设跟当时国家图书馆的新书书目数据库以及普通图书的回溯数据库的建设连接起来,不能断层,并针对古籍书目描述中的分类和主题标引问题、机读格式问题,以及字库问题进行了探索,并首次提出以ISO10646字符集来解决古籍字库的问题(47)。
针对古籍书目库的规范化建设,秦淑贞认为:“规范化的古籍书目数据库,是指在各种编目软件支持下做出的在格式、内容、标引依据以及字体等方面都按国家标准做出的一致的古籍书目数据库。要达到古籍书目数据库规范化必须做到六个统一。即:统一的机读目录格式;统一的著录规则;统一的分类法;统一的主题标引依据;统一的字库;古籍和普通图书统一建库。”(48)在《古籍书目数据库的标准与评价研究》(49)一文中,毛建军肯定秦淑贞“六个统一”观点,同时对其作了进一步的阐释。他认为:统一标准的机读目录格式是建设和使用古籍书目数据库的必要前提,出台适合古籍特征的《古籍机读目录格式》是十分必要的,并援引姚秀敏的观点,认为《古籍机读目录格式》的制定应以CNMARC为蓝本,结合《古籍著录规则》,研究出一种标准的古籍机读目录格式;在统一著录规则方面,1996年由中国文献编目小组编撰了《中国文献编目规则》融合了各类型文献著录规则,确定了不同名称的参照关系,并通过标目法对文献题名和责任者名称予以规范控制,从而形成了适合我国汉语言文字特点,又与世界书目控制原则相吻合的一套完整、系统的编目规则;在古籍分类标准问题上,他引用刘劼的观点——一个行之有效的分类法对古籍书目数据库的建设至关重要(50),认为图书馆界多数学者倾向于《中图法》和《四部法》相结合,采用《中图法》第3版和《中国古籍总目分类表》作为古籍分类规范化的标准;关于主题标引标准,他认为我国各级图书馆的编目主要是建立在《中图法》和《汉语主题词表》的基础上的,因此在机读数据库中使用《中国分类主题词表》不会打乱原有的图书编目体系;在统一字库的问题上,他肯定了目前国内学术界在字符集的采用上的主流看法,即:坚定不移地采用国际标准ISO/IEC10646/Unicode字符集。
随着古籍书目数据库建设活动的不断深入,特别是国家图书馆、北京大学图书馆全面开展古籍数字化和古籍书目库的建设,古籍联合目录的建设也被提上了日程。李致忠针对古籍联合目录编制所面临的古籍界定范围、目录编法、目录性质、品种定义、版本目录的款目、机读格式、成员馆、分类主题标引工具、著录规范、中心数据库的建立和维护、数据的使用等一系列问题提出了自己的看法(51),为中国步入古籍联合目录的新阶段起到了引领作用。从2000年开始,CALIS就开始启动了古籍书目联合数据库的筹建工作,在充分调研和前期准备的基础上,2003年12月联合目录正式启动。CALIS以北京大学、清华大学、武汉大学、南京大学、复旦大学等10所高校图书馆为试点单位,编制了专门的客户端软件和书影扫描软件,制订了专门的古籍联合目录记录编制规范和提交规范,使得多年的期望成为现实。到目前为止,其成员馆扩大到44家,收录的古籍书目数据超过3.1万条,并提供书影对象链接。
5.2.2 古籍元数据
国内古籍元数据研究始于1997年上海图书馆启动的第一个数字化项目——善本古籍的数字化。在上海图书馆的数字图书馆项目实施中,元数据方案的选择是其中的一个关键所在。上海图书馆采用的元数据方案是以DC为核心、多种对应于不同资源类型元数据并存的元数据集,通过RDF体系将它们进行封装(52)。北京大学数字图书馆自1999年研发以来,在元数据研究方面成果显著,有《中文元数据标准框架及其应用》、《古籍描述元数据著录规范》等研究成果。《中文元数据标准框架及其应用》针对具有中国特色和在我国广泛应用的数字对象分别建立了相应的数字规范,包括格式定义、语义定义、开放标记规范、内容编码体系、扩展规则以及各种专门元数据与基本元数据的标准转换关系和转换模板,编制了各个专门元数据的应用指南、元数据定义信息、应用协议和转换工具的等级机制。《古籍描述元数据著录规范》解决了古籍著录的对象范围、古籍的著录级别、古籍的基本著录单位,以及著录对象之间不同关系等有关元数据标准确立的基本性问题(53)。同时,针对北京大学图书馆收藏的近3万种、6万多份金石拓片,特别是其中缪荃孙艺风堂、张仁蘸柳风堂的全部藏拓的开发利用,北京大学图书馆对拓片的元数据进行了设计和开发(54)。2003年,姚伯岳等人对北京大学图书馆的古籍元数据研究进行了总结,明确了古籍著录的对象范围、古籍的著录级别、古籍的基本著录单位,以及著录对象之间不同关系等有关元数据标准确立的基本性问题,并介绍了北京大学数字图书馆古籍元数据标准的结构、内容、实施方案(55)。此外还有施艳蕊对藏文古文献的元数据研究(56),丁侃对中医古籍的元数据研究(57)。山川尝试用XML和XML Schema语言来描述古籍元数据,并提出了一种基于本体论著录古籍元数据的方案(58)。
5.2.3 FRBR研究
FRBR是IFLA提出的一种革命性的编目理念模型,它的全称是Functional Requirements for Bibliographic Records。1997年,在哥本哈根召开的IFLA编目委员会上,FRBR研究小组正式提出这些基本理念,包括四个方面:①书目记录所涵盖的文献范围,包括资料、媒体、格式及信息记录模式;②书目记录所面向的各种使用者,包括读者、图书馆员、出版商等;③书目记录适应图书馆馆内与馆外各种环境的使用需要;④FRBR所采用的实体关系(E—R)模型(59)。FRBR提出了三组编目实体:①知识;②对知识作品或艺术创作、出版、制作、收藏等负责的个人或团体;③作品的主题特征。其中第一组实体“知识”又划分为四个层次:作品(W ork)、作品表达方式(Expression)、作品表现方式(Manifestation)、作品单件(Item),从而涵括了从抽象到具体的认知过程或文献知识的实现过程。四个层次的编目实体在各自的层面之间又呈现出既错综复杂又可以梳理使之有序化的各种关系。而著录四层结构,建立“核心记录”,充分揭示四层结构中各自所存在的实体之间各种关联以及与记录实体相关的个人或团体、学科主题等,就把庞大的文献集合勾画成一个包容各种载体、充分揭示各种关系、面向所有用户的一个结构化的体系,从而为使用者提供查找(Find)、识别(Identify)、选择(Select)、获取(Obtain)的有效途径。这就是FRBR的根本性任务。
严格地说,FRBR的出现是古籍书目描述的一次革命,但其思想关系到古籍数字化建设的整个方面,对于全文库、书目库、知识库等均有相应的影响,故一些有识之士已经开始这方面的研究。其中,鲍国强在古籍书目元素设计、古地图书目元素设计以及可视化检索上面利用FRBR的原理进行的探索值得肯定。在《文献编目新理念对古籍数字化的影响》(60)一文中,作者在分析归纳文献编目中FRBR、复本编目、文献关联、全面规范和工具保障等新理念的基础上,具体说明了古籍数字化系统工程中书目、载体、图文、知识、关联和工具六个方面的主要内容,并从书目揭示、信息规范、知识链接和工具保障四个层面重点阐述了这些新的编目原则和理论对古籍数字化各方面工作的重大影响。而在《FRBR基本模式在古旧地图编目及数字化信息检索中的应用》(61)中,作者针对FRBR提出的书目实体的三组四维实体的概念,分析了中国古地图的文献特点,并做了对应性的比较,提出了著作、品种、版本、复本的概念,对于古旧地图的类型、古旧地图在书目层次的元素组成、古旧地图在规范数据制作要求等都作了相应的说明,并描述了古旧地图实体之间所存在的基本关系,以及这些关系与MARC之间的映射关系。鲍国强提出,FRBR关系模式的作用就是建立一种古旧地图和其他古旧地图的连接,古旧地图诸对象、属性之间的连接,进一步帮助用户更好的在所描述的书目数据库和数字化信息库中“航行”。为了达到这种导航,他认为可起用GIS检索模式,拓展书目检索点,健全信息规范关联。这种探索利用FRBR所建立的古籍关系关联机制,对于把古籍书目库、版本库、知识库、全文库进行关联,通过本体的Web发布和检索,并利用GIS检索模式,使可视化检索和关联检索联合起来,将使FRBR在古籍的数字化过程起到很重要的作用。
5.2.4 古籍全文检索与本体论
随着古籍数字化的逐步深入,一些基于知识发现的技术应用到古籍全文库中。利用本体论的思想来建构知识库、进行语义识别和检索成为当前古籍数字化研究的热点之一。例如,杨继红在调研了中医古籍信息资源组织方式的基础上,系统分析了知识的组织体系及表示方法,阐述了叙词表、本体的基础理论和研究进展,在柳长华教授提出的基于“知识元”的中医古籍计算机知识表示方法建设的中医古籍知识库的工作基础上,充分利用中医传统知识保护课题组有关中医传统知识分类的研究成果,借鉴本体论的思想,采用自上而下的方法编制了适合知识库建设的中医古籍分类表和古籍概念关系体系,作为分类主题一体化中医古籍叙词表的基础(62)。谷建军也就中医古籍的本体设计方面作了有益的探索。他根据中医古籍数据库的实际情况,参考国内外领域本体的建设方法,在知识推理层面提出了基于叙词表的适合中医古籍数据库应用的中医古籍文献领域本体建设方法(63)。李晓菲以彝文典籍为例,在已有的彝文古籍分类的基础上,探讨了如何利用领域本体的理论和方法构建少数民族古籍本体,从而实现民族古籍的知识管理和知识创新的目的(64)。曹玲以农业古籍本体构建为例,从数据选择、构建方法、总体设计几个方面探讨领域本体构建流程,并采用Jena实现了对该本体的可视化浏览以及基于自然语言的语义检索(65)。肖怀志选取较有代表性的史书《三国志》为例,通过历史年代本体建立的语义关联来聚集相关历史年代知识元,达到聚集同一或相关史实的目的,为古籍数字化知识发现功能的实现提供了一条全新的思路(66)。这些研究以某个专题为突破口,以本体的建设为机制来探索语义检索,对于寻找新的技术手段实现古籍的知识发掘,无疑具有开启新思维的作用。
5.2.5 古籍数据库整合研究
随着古籍数字化技术的发展以及人们对古籍利用层次的要求的提高,有研究者开始就古籍数据库的整合设计进行探索。如程佳羽认为,首先要以DC元数据为基础,书目著录检索系统要充分保证多层次的数据集成体系,并结合主题标引进行全文解析,在充分利用书目数据库的基础上,利用可扩展的灵活存储机制和多种发布形式把全文库和书目数据库整合起来进行全方位的统一设计。数据库的整合包括内容的整合与功能的整合。对于不同类型的古籍,即便处于同一个系统内,也需要不同的处理办法,譬如舆图、金石拓片和刻本,就需要根据其不同的性质,设计与之相适应的元数据描述、管理和发布方式,但若把这些不同类型的古籍分别设计在彼此不相关的单个数据库内,则人为地割裂了其可能存在的联系。因此,需要在一个同一的标准之下,对不同类型的古籍单独定义,使其保持相对的独立,但又保证了其应有的关联性,也就是要做到内容的整合(67)。这对于整合现有古籍数字资源无疑具有重要意义。
6 中文古籍数字化展望
古籍数字化的发展过程也是在实践中不断总结的过程。从2000年至今,不断有学者发表论文对当前古籍数字化的现状进行分析,对未来古籍数字化发展方向进行展望,提出了许多有建设性和预见性的观点。例如,2000年王桂平在《我国古籍数字化的现状及展望》一文中就曾对当时我国古籍数字化建设提出了六点设想:超文本技术将得到广泛应用;实现古籍数字化的标准化和规范化;网络化是古籍数字化,特别是古籍善本数字化的发展趋势;善本古籍数字化将最终实现;制作善本古籍数字化的辅助软件和电子工具书;数字式照相将成为古籍数字化的主要方式(68)。2003年,陈立新指出我国古籍数字化建设亟待解决的五大问题:建立统一的古籍机读目录;建立支持古籍数字化的汉字平台;建立古籍文献规范文档;建立古籍影像处理的标准化;研究适合古籍的Metadata(即元数据)(69)。2006年,郑永晓《古籍数字化对学术的影响及其发展方向》一文论述了古籍数字化的五个发展方向:逐步建立并规范古籍数字化的元数据标准;制订适合古籍整理和古籍数字化的文档格式和图片格式;尽快完善汉字字符代码集;建立符合学科特点的古籍数据库全文检索系统;优化选题,整合资源,建设具有较高学术水准的专题数据库(70)。2007年,郝淑东等在《古籍数字化的发展概述》一文中对当时的古籍数字化建设作出了展望,提出了六点看法:建立古籍数字化共享平台;建立古籍整理的自动完成集成系统;检索系统和支持系统研究将成为古籍数字化工作的重点;国家对古籍资源数字化进行整体规划;人才培养势在必行;古籍数字化项目国际性合作将是未来发展的目标(71)。2008年,孟忻在《古籍数字化的现状与发展方向》一文中指出了古籍数字化的三个发展方向:注重特色资源的开发;优化选题,整合资源,建设具有较高学术水准的数字化古籍数据库;联合开发,资源共享(72)。相关的古籍数字化设想和展望不一而足。我们发现,随着古籍数字化建设的深入开展,学者们的众多设想和预言有的已经成为现实,如“超文本技术将得到广泛应用”、“数字式照相将成为古籍数字化的主要方式”、“完善汉字字符代码集”等;有的正在逐步成为现实,如“实现古籍数字化的标准化和规范化”、“逐步建立并规范古籍数字化的元数据标准”、“人才培养势在必行”等;有的还需要继续努力才能实现,如“联合开发,资源共享”、“建立古籍数字化共享平台”等。基于当前古籍数字化的实际,笔者认为古籍数字化将呈现以下趋势。
第一,建立国家范围内古籍数字化统一管理及协调机制。如前文调查显示,我国古籍数字化呈现出三大主体(即以图书馆为主体的文献保藏部门、学术机构和数字出版企业)三足鼎立的局面。作为不同性质的社会机构,它们存在于这个社会的意义和价值是不同的,即区别于它们的公益性、学术性和商业性,表现在古籍数字化实践过程中有不同的利益诉求,古籍数字化因而既具古籍保护的公益性质、古籍学术利用的研究性质,又具古籍资源开发的商业性质。这就是我国古籍数字化目前的基本格局。为避免资源浪费和重复开发,在公益性保护、学术性研究和商业性开发之间保持应有的平衡,必须在国家层面进行统一管理和协调。因为古籍数字化是一项保护和弘扬中华文化遗产的工作,具有强烈的公益性色彩,不能完全走市场化的道路,有必要制定古籍数字化中长期规划。这样做既可以避免选题重复开发,也有利于古籍保护。同时,要制定和推广古籍数字化行业标准和规范,避免“各自为政”的局面。另外,还要建立配套的古籍数字化项目招标机制、古籍数字化产品信息发布机制、古籍底本使用补偿机制、民间古籍善本征集机制等(73)。
第二,跨行业、跨地区乃至国际协作是未来古籍数字化发展的方向。古籍数字化主要由版本资源、内容专家、技术专家三大要素构成,而这三大要素分别来自不同的行业或机构,如版本资源主要来自以图书馆为主体的文献保藏部门,内容专家主要来自古籍研究所等科研机构;技术专家主要来自数字技术公司。为使各种要素合理配置,必须发挥上述跨行业协调机制的作用,使他们能联手协作开发古籍数字化产品。同时必须明确的是,古籍数字化仍属古籍整理和学术研究范畴,因此在整个数字化过程中,内容专家应处于主导地位,应由他们提出选题并进行科学论证,对古籍数字化对象进行版本鉴别和文本校勘,对系统目标和功能进行整体规划,而技术专家只是服务于内容专家,使这些目标和功能顺利实现。这好比建筑师与建筑工人的关系,由建筑师设计好图纸,建筑工人只负责施工。另外众所周知的是,在古籍数字化过程中,内地具有丰富的资源优势,港台地区则有数字化技术优势和经验,若两者能够加强合作,就能优势互补,有效促进古籍数字化建设的发展,充分发挥古籍数字化成果及其价值。由此可以进一步预见,古籍数字化的跨地区,乃至跨国界合作将成为其发展方向。这对于实现中文古籍文献资源在全球范围内的共建共享至关重要。
第三,古籍数字化产品的研制与古籍文献资源的开发相结合的趋势更加明显。从选题来讲,早期的古籍数字化产品主要集中在《四库全书》、《二十五史》等几部大型丛书上,是一种“大而全”的思路。这对于满足一般的阅读和研究需求当然是有必要的。但随着古籍数字化参与主体的增多和古籍数字化产品的丰富,选题重复的问题不可避免地产生了。这就要求改变原有的思路,走一条“专而精”的道路。如北京国学时代文化传播有限公司开发的“经典文库”,包括《国学备览》、《书法备览》、《绘画备览》、《兵学备览》、《蒙学备览》、《唐诗备览》、《宋词备览》、《元曲备览》、《篆刻备览》、《小说备览》等。以《篆刻备览》为例,又分源流篇、文献篇、荟萃篇三大部分。源流篇简述篆刻艺术的发展历史;文献篇收录历代关于篆刻的论著59种,并精选15位名家印款400余种及论印绝句100余首;荟萃篇则荟萃古今印章篆刻无数。它实际上就是一部专题资料汇编,是传统文献编纂理论与方法在古籍数字化资源开发中具体应用的例证。这说明,传统的文献整理方法在古籍数字化中仍有用武之地,也证明了内容专家在古籍数字化中的主导地位。从功能设计上看,古籍数字化产品更加注重研究支持功能的开发。古籍书目库、版本影像库、全文库、知识库及各种研究工具(如联机古汉语词典、年号与公元纪年对照表、字词频率统计信息、版本异同的比对显示、异体字的汇聚显示、读音的自动标注、在线标点断句等)的集成和互操作,是未来古籍数字化产品研发的方向。
第四,古籍版本的非物质文化遗产保护将成为古籍数字化的重要职能之一。由于纸质文献的物理寿命毕竟是有限的,中华古籍善本终究有一天要变换它的存储介质,而它所承载的丰富的历史文化信息也将由另一种更为现代的形式留存下去,这将是古籍善本数字化保存的必由之路。笔者比照2005年国务院办公厅印发的《关于加强我国非物质文化遗产保护工作的意见·附件1》中对“非物质文化遗产”的表述,论述了古籍版本文化的非物质性、活态性、民族性、传承性和发展性,认为:“中国古籍版本完全符合非物质文化遗产的定义,具备了非物质文化遗产的所有特性。”(74)通过古籍善本的数字化,一方面能够有效地减少对古籍原本的使用,保护已经非常脆弱的古籍版本资源;另一方面,随着图文对照的古籍全文数据库建设的成熟,我们完全可以期待通过此类数据库来替代对古籍原本所进行的古籍版本相关方面的研究。笔者曾在《构建中华古籍层级保护体系的设想》(75)一文中建议,以全国古籍普查为基础,由国家古籍保护中心出面组织创建“国家古籍版本数据中心”,有计划、分步骤地建设“宋代版本数据库”、“元代版本数据库”、“明代版本数据库”、“清代版本数据库”。该系列数据库以保存历代古籍版本的封面、牌记、卷端、版式、藏印、题跋等的影像资料为己任,而不独以提供全文检索为目标。宋、元版本数量有限,可以考虑悉数收入;明清二代版本数量众多,可以考虑按写本、刻本、活字本、拓本等版本类型,选取有代表性的样本建库。这实际上是数字化的古籍版本档案馆和博物馆。可以预见,随着专门的古籍版本数据库的建成,古籍版本的非物质文化遗产保护也将成为古籍数字化的重要职能之一。
【作者简介】

李明杰,男,汉族,1971年7月生,江西丰城人。博士,武汉大学信息管理学院副教授,硕士生导师,《图书情报知识》编辑。主讲“中国历史文献学”、“中国古籍编撰史”、“档案文献编纂学”等课程。主要研究领域:文献学、中国出版史和出版文化、文献保护。主持国家社科基金青年项目1项,湖北省人文社科一般项目1项,武汉大学人文社科青年项目1项。出版著作2部(《宋代版本学研究》获“第十届(2006年度)华东地区优秀古籍图书二等奖),在包括Journal of Documentation、《中国图书馆学报》等在内的国内外知名刊物上发表论文40余篇。
虞有,男,1986年生,2009级硕士研究生。研究方向:文献与出版。
周亚,男,1988年生,2010级硕士研究生。研究方向:文献与出版。
宋登汉,男,1970年生,博士研究生,武汉大学图书馆副研究馆员,发表论文近20篇。研究方向:信息资源数字化保存。
【注释】
(1)本文系国家社科基金青年项目“版本文化遗产保护与开发利用机制研究”(项目编号:08CTQ005)的研究成果之一。
(2)毛建军.古籍索引的电子化实践[J].中国索引,2006(4):37-40.
(3)耿元骊.三十年来中国古籍数字化研究综述(1979-2009)[EB/OL].[2010-03-18].http://www.guoxue.com/wk/000652.htm.
(4)杨虎.港台地区古籍数字化资源述略[J].电子出版,2003(8): 8-11.
(5)毛建军.中文古籍书目数据库的调查与分析[J].图书馆论坛,2007(5):75-78.
(6)罗凤珠.台湾地区中国古籍文献资料数位化的过程与未来的发展方向[EB/OL].[2010-03-19].http://www.360doc.com/content/09/0423/09/ 66222_3234683.shtml,2009-4-23/2010-3-26.
(7)本次调查主要参考了李明杰《中文古籍数字化的主体构成及协作机制初探》、毛建军《古籍索引的电子化实践》、王立清等《港台地区古籍数字化现状分析及启示》、毛建军《中文古籍书目数据库的调查与分析》、毛建军《中国古籍网络出版概述》、毛建军《台湾地区古籍书目数据库的建设及其特点》、毛建军《国内科研院所古籍数字化资源的建设》、毛建军《欧美地区古籍数字化成果概述》、耿元骊《三十年来中国古籍数字化研究综述(1979—2009)》、毛建军《日本中文古籍数字资源的建设》等文献。
(8)刘伟红.中文古籍数字化的现状与意义[J].图书与情报,2009(4):134-137.
(9)祝敬国.古籍语料库字体与结构研究[J].文物保护与考古科学,1995(1):39-43.
(10)刘炜.上海图书馆古籍数字化的初步尝试[J].图书馆杂志,1997(4):33-34.
(11)李运富.谈古籍电子版的保真原则和整理原则[J].古籍整理研究学刊,2000(1):1-7.
(12)彭江岸.论古籍的数字化[J].河南图书馆学刊,2000(2):63-65.
(13)孙安.中文古籍数字化资源概览[J].科技资讯,2009(16):228-229.
(14)童顺荣.古籍数字化相关问题的开放思考[J].兰台世界,2009(9):17-18.
(15)张雪梅.古籍数字化与文献信息资源共享[J].天津工业大学学报,2002(3):85-86.
(16)刘琳,吴洪泽.古籍整理学[M].成都:四川大学出版社,2003:368.
(17)毛建军.古籍数字化理论与实践[M].北京:航空工业出版社,2009:162.
(18)潘德利.中国古籍数字化进程和展望[J].图书情报工作,2002(7):117-120.
(19)王刚.古籍数字化研究文献的统计分析[J].中国索引,2009(3):38-43.
(20)史睿.论中国古籍的数字化与人文学术研究[J].北京图书馆馆刊,1999(2):28-35.
(21)史睿.数字化条件下古籍整理的基本问题(论纲)[EB/OL].[2010-03-26].http://www.nlc.gov.cn/service/wjls/pdf/08/08_07_a5b17.pdf.
(22)李明杰.中文古籍数字化基本理论问题刍议[J].图书馆论坛,2005(5):97-100.
(23)史睿.数字化条件下古籍整理的基本问题(论纲)[EB/OL].[2010-03-26].http://www.nlc.gov.cn/service/wjls/pdf/08/08_07_a5b17.pdf.
(24)李明杰.中文古籍数字化基本理论问题刍议[J].图书馆论坛,2005(5):97-100.
(25)毛建军.古籍数字化概念的形成过程探析[J].科技情报开发与经济,2006(22):160-162.
(26)李国新.中国古籍资源数字化的进展与任务[J].大学图书馆学报,2002(1):21-26,41.
(27)牛惠萍.对我国古籍数字化相关问题的研究[J].当代图书馆,2006(1):39-42.
(28)徐清.古籍数字化资源的深度开发[J].图书情报工作,2007(3): 95-97.
(29)史睿.数字化条件下古籍整理的基本问题(论纲)[EB/OL].[2010-03-26].http://www.nlc.gov.cn/service/wjls/pdf/08/08_07_a5b17.pdf.
(30)郑章飞.从书院文化数据库建设看古籍文献数字化[J].图书馆,2006(6):75-77.
(31)毛建军.关于古籍数字化理论建构的思考.高校理论动态,2006(4):40-43.
(32)刘宁.汉字全文检索系统的分析、设计——从湖北省地方志全文检索系统的研制谈系统功能及设计方法[J].现代图书情报技术,1988(2):10-15.
(33)师文.海峡两岸中国古籍整理研究现代化技术研讨会在京举行[J].语文建设,1993(12):9.
(34)吴民.论古籍数字化建设[J].高校图书馆工作,2009(4):34-35,38.
(35)王桂平.我国古籍数字化的现状及展望[J].图书情报知识,2000(4):50-51,54.
(36)陈尚君.《中国基本古籍库》初感受[EB/OL].[2010-03-20].http://www.confucianism.com.cn/html/wenxue/9220163.html.
(37)马希荣,王行愚.西夏文字数字化方法及其应用[M].兰州:甘肃文化出版社,2002:240.
(38)刘博.大规模古籍数字化之汉字编码选择[J].科技情报开发与经济,2006(5):53-54.
(39)徐健,肖卓.古籍数字化中的汉字录入与显示[J].图书与情报,2006(6):79-82.
(40)黄飞龙,札·义兰.基于Unicode的中国蒙古文古籍版本数据库的构建[J].内蒙古民族大学学报,2009(3):160-161.
(41)刘乾先,王彩云.文献书目微机处理研究报告:利用计算机整理及检索现存古籍书[J].古籍整理研究学刊,1991(2):15-17.
(42)李致忠.略谈建立中国古籍书目数据库[J].国家图书馆学刊,1992(1):56-60.
(43)张治江.日本古籍综合目录数据库及其特点[J].图书馆学研究,1992(6):64-69.
(44)雪岛宏一著.英国古籍书目数据库——ISTC[J].姜振儒,编译.河北科技图苑,1993(3):56-57.
(45)李致忠.再论建立中国古籍书目数据库[J].国家图书馆学刊,1995(3/4):19-25.
(46)杨光辉.关于中国参与RLG-CHRB工作的调查报告——兼谈中国古籍书目数据库的建设[J].上海高校图书情报学刊,1996(2):20-23.
(47)刘刚.浅谈古籍书目数据库建设的若干问题[J].国家图书馆学刊,1996(1):80-84.
(48)秦淑贞.论古籍书目数据库规范化[J].中国图书馆学报,1997(1):79-82.
(49)毛建军.古籍书目数据库的标准与评价研究[J].图书馆理论与实践,2009(6):30-33.
(50)刘劼.古籍书目数据库建设刍议[J].图书馆理论与实践,1998(4):27-28.
(51)李致忠.关于古籍联合目录数据库的构建[J].中国图书馆学报,2000(5):38-41.
(52)刘炜,赵亮.上海图书馆数字图书馆元数据方案[EB/OL].[2010-03-23].http://www.chinalibs.net.
(53)肖珑,陈凌等.中文元数据标准框架及其应用[J].大学图书馆学报,2001(5):29-35.
(54)胡海帆,汤燕等.北京大学古籍数字图书馆拓片元数据标准的设计及其结构[J].图书馆杂志,2001(8):14-18.
(55)姚伯岳、张丽娟等.古籍元数据标准的设计及其系统实现[J].大学图书馆学报,2003(1):17-21.
(56)施艳蕊,单广荣.藏文古籍书籍类数字图书馆元数据标准的设计研究[J].甘肃科技,2009(11):10-12.
(57)丁侃.基于知识元信息技术的中医古籍元数据研究[D].北京:中国中医科学院,2006.
(58)山川,罗晨光.XML著录古籍元数据初探[J].图书馆工作与研究,2007(6):53-56.
(59)刘孝文.国内FRBR研究综述[J].图书馆理论与实践,2009(2): 42-45,48.
(60)鲍国强.文献编目新理念对古籍数字化的影响[EB/OL].[2010-03-27].http://www.nlc.gov.cn/hxjy/2008/0701/article_48.htm.
(61)鲍国强.FRBR基本模式在古旧地图编目及数字化信息检索中的应用[EB/OL].[2010-03-27].http://www.nlc.gov.cn/service/wjls/pdf/16/16_01_a5b18.pdf.
(62)杨继红.基于本体的中医古籍叙词表构建方法研究[D].北京:中国中医科学院,2005.
(63)谷建军.基于叙词表的中医古籍文献领域本体建模方法研究[D].北京:中国中医科学院,2003.
(64)李晓菲,郁奇.基于分类的民族古籍本体构建与知识创新——以彝族典籍为例[J].大连民族学院学报,2008(5):465-469.
(65)曹玲,何琳.农业古籍本体构建及应用[J].广西师范大学学报:自然科学版,2007(2):1-4.
(66)肖怀志,李明杰.基于本体的历史年代知识元在古籍数字化中的应用——以《三国志》历史年代知识元的抽取、存储和表示为例[J].图书情报知识,2005(5):28-33.
(67)程佳羽.古籍全文数据库的理想实现模式[J].图书馆建设,2006(3):54-56.
(68)王桂平.我国古籍数字化的现状及展望[J].图书情报知识,2000(4):50-51,54.
(69)陈立新.数字图书馆与古籍数字化[J].现代图书情报技术,2002(年刊):56-58.
(70)郑永晓.古籍数字化对学术的影响及其发展方向[J].社会科学管理与评论,2006(4):81-88.
(71)郝淑东,张亮等.古籍数字化的发展概述[J].情报探索,2007(7):114-116.
(72)孟忻.古籍数字化的现状与发展方向[J].中国索引,2008(1): 39-41.
(73)李明杰,俞优优.中文古籍数字化的主体构成及协作机制初探[J].图书与情报,2010(1):34-44.
(74)李明杰.非物质文化遗产视角下的中国古籍版本文化保护[J].图书馆,2009(3):4-9.
(75)李明杰.构建中华古籍层级保护体系的设想——从古籍价值属性创新古籍保护思路[J].图书馆杂志,2009(3):14-19.
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










