



8.2.2 我国情报学研究概况
1.以作者同被引(ACA)为方法的分析
(1)关于ACA分析
ACA是作者同被引分析(Author Co-citation Analysis)的简称。1981年,White和Griffith两位学者运用ACA方法描述了情报科学结构,开启了ACA分析的先河,并在学术界引起广泛关注。在此后的20多年中,一些学科的学者相继沿用这种方法对学科领域以及学科发展进行了探讨。例如,我国学者王崇德、佘珊选取JASIS、JIS(Journal of Information Science)、Scientometrics三种样本期刊,统计了1989~1990年发表的论文,进行了作者同被引聚类,与White1981年的结果进行了比较,发现情报学的作者人数有了增减,学科研究热点发生了转移(38)。2005年,刘林青以战略管理研究领域为例,应用作者同被引方法对该领域的学派进行了分析,所得出的结果与专家的观点相互印证(39)。
ACA分析是共被引分析当中的一种方法,在此之前,学者们已经开始运用文献同被引法(documents cocitation)来探讨科学文献的特征及分布规律等问题。这两种方法虽然选取的分析对象不同,但二者的前提是一致的:当两篇文献(或两位著者)同时被第三篇文献(或第三个著者)引用时,这两篇文献(或这两位著者)之间就存在同被引关系;如果文献(或著者)的同被引次数越高,则证明二者之间的相关度越高,在图中所显示的距离就越近;关系较为密切的文献(或著者)会较为集中,不同的研究方向和研究领域的文献(或著者)从而形成各自的聚类结果。
1990年,McCain将ACA的程序归整为选择作者、检索同被引频次、构成同被引矩阵、转化为皮尔逊相关系数矩阵、多元分析和解释结果等几个步骤(40),人们称其为传统ACA。在后来的发展中,学者们对传统ACA进行了一些修正,其应用范围也开始扩展到主题检索领域(41)。
目前,国内学者在对情报学研究状况的探讨当中,较多采用的是词频统计方法,对情报学文献的题目或关键词进行统计分析,以揭示当前学科的研究现状和热点。而本节所作的分析,基本上沿用的是传统ACA的方法和步骤,力求通过这样的尝试,从著者角度对国内情报学的学科结构以及发展脉络进行揭示。
(2)核心著者选择
核心著者的选择是ACA分析中的难点所在,目前尚无统一的方法。White和Griffith在1981年的研究中,以Griffith编著的《情报科学中的核心文献》(Key Papers in Information Science)一书作为主要参考,从中选取了22位该领域的核心著者,并增添了17位他们认为在情报学领域作出了突出贡献的学者,最终确定了39位核心著者作为同被引分析的对象。1998年,White和McCain在其研究中,首先选择《情报科学技术年评》(Annual Review of Information Science and Technology)、《信息处理与管理》(Information Pro-cessing&Management)、《美国情报科学学会会刊》(Journal of the American Society for Information Science)、《文献杂志》(Journal of Documentation)、《情报科学》(Journal of Information Science)、《图书馆与情报科学研究》(以及《图书馆研究》)(Library&Information Science Research(and Library Research))、《美国情报科学学会会议录》(以及学会年会辑录)(Proceedings of the American Society for Information Science(and Proceedings of the ASIS Annual Meeting))、《科学计量学》(Scientometrics)、《电子图书馆》(Electronic Library)、《信息技术与图书馆》(以及《图书馆自动化》)(Information Technology and Library(and Journal of Library Automation))、《图书馆资源与技术服务》(Library Resources&Technical Service)、《自动化图书馆与信息系统》(Program-Automated Library and Information Systems)这12种情报科学以及图书馆自动化领域的核心期刊,通过这些期刊中1972~1995年的著者被引统计,确定了120位高频被引著者。
我国学者在国内情报学核心著者评价方面也进行了一系列的研究。刘东维选择了我国情报学界较有影响的7种学术期刊(《科技情报工作》、《图书情报工作》、《情报科学》、《情报学刊》、《情报学报》、《情报杂志》、《情报业务研究》),根据各期刊自创刊以来至1985年底的发文篇数、被征引篇次数、平均被引率和基础文献发文数的综合评价指标,用定量化的方法确定了我国情报学研究领域的33位核心著者(42)。黄萍建、方太强和曾国秀通过《图书情报工作》1998~2002年发文篇数、被引篇次数和重要文献数的综合指标,统计得出我国图书情报学领域的78名学术带头人(43)。郦金花和苏新宁通过中国社会科学引文索引(CSSCI)1998~2002年间的图书馆学情报学论文的统计分析,分别得出该领域发文最多以及被引最多的前32位作者(44)。
国内的这些研究由于时间段和评价指标的差异,核心著者的结果也不同。本节则在这些结果的基础上,通过综合分析,确定出我国情报学领域的37位核心著者,以此作为ACA分析的对象。(如表8-4所示,按姓氏拼音排序)
表8-4 我国情报学领域的核心著者

续表

姓名下标含义为:
1-为265页脚注①文献中确定的核心著者。
2-为265页脚注②文献中确定的学术带头人。
3-1-为266页脚注①文献中所确定的发文量最多的作者。
3-2-为266页脚注①文献中所确定的被引最多的作者。
从学科背景来看,由于图书馆学和情报学研究的相通性与交叉性,这些核心著者除了有情报学者外,还包括一些图书馆学者。从年代分布来看,有的属于情报学领域的早期带头人,有的是后起之秀,有的则是至今仍活跃在该领域的资深学者。
(3)著者同被引次数矩阵
著者同被引次数的统计是ACA分析中的关键步骤。在1981年的调查中,White和Griffith以SCI和SSCI为检索源,通过构建检索式在线获取核心著者的同被引次数。1998年,由于数据较多,White和McCain应用了宏语言和程序指令,对著者同被引次数进行检索统计和整理。
本书选择中国学术期刊全文数据库(CNKI)作为统计源(45),利用该数据库系统引文检索中的著者同被引检索功能,在线检索出37位核心著者的同被引次数,共有(37×36)/2=666组不同的数据。具体方法是:在检索路径中选择“引文”字段,在检索词中分别输入任意两位著者的姓名,二者为逻辑“与”关系,而后得出两位著者的同被引次数以及同被引的文献列表。检索年限选择系统的默认值,为1994~2005年。检索学科范围为全部,而不仅仅局限于情报学(46)。由于笔者检索时间为2005年11月份,且数据库具有一定的滞后性,因而2005年的数据为不完全统计。
在同被引次数的统计的基础上,可形成著者同被引次数矩阵。该矩阵为对称矩阵,非主对角线中单元格的值为著者同被引次数,主对角线的数据定义为缺失值。矩阵中去掉了同被引次数为0的著者,剩下36位著者(见表8-5),各自的平均同被引次数如表8-6所示。
(4)分析方法与步骤
在ACA分析中,SPSS软件可作为统计分析的工具。首先,利用SPSS中的相关分析,将著者同被引次数矩阵转化为皮尔逊相关矩阵(Pearson r correlations),由此能够消除由著者被引次数差异所带来的影响。经过转换的相关矩阵将作为后面聚类分析(Cluster Analysis)以及多维尺度分析(MDSCAL,Multi-dimension Analysis)的对象。
运用多维分析能够在二维空间中直观反映我国情报学学术团体的位置、学者组成以及学者之间的相似程度。但学术团体的数目和边界的确定需要借助因子分析和聚类分析的结果(47)。本文中,因子分析采用主成分方法(Principal components)和方差极大正交旋转(Varimax rotation)。聚类分析采用系统聚类(Hierarchical Cluster),选择离差平方和法(Ward's method)与欧氏距离平方法(Squared Euclidean distance)。二维体系图由多维尺度分析(ALSCAL)生成。
表8-6 我国情报学核心著者平均同被引次数
(5)数据结果
①聚类分析。聚类分析的结果如图8-6所示,结合因子分析和本身聚类的效果,可分为六类。接下来所进行的多维尺度分析将以此作为参考。
②多维尺度分析。图8-7为多维尺度分析的结果,其中Stress值等于0.15760,RSQ等于0.88719,说明模型的拟合效果较好。参照聚类分析结果,可将国内情报学研究划分为五个领域(48):早期研究者,情报学理论,情报检索,图书馆学研究,文献资源建设。
第一类,早期研究者。这些著者基本上出自文献(49)中所确定的国内情报学核心著者,20世纪80年代较为活跃。这个分支类似于1981年White和Griffith研究中的先驱者集团。
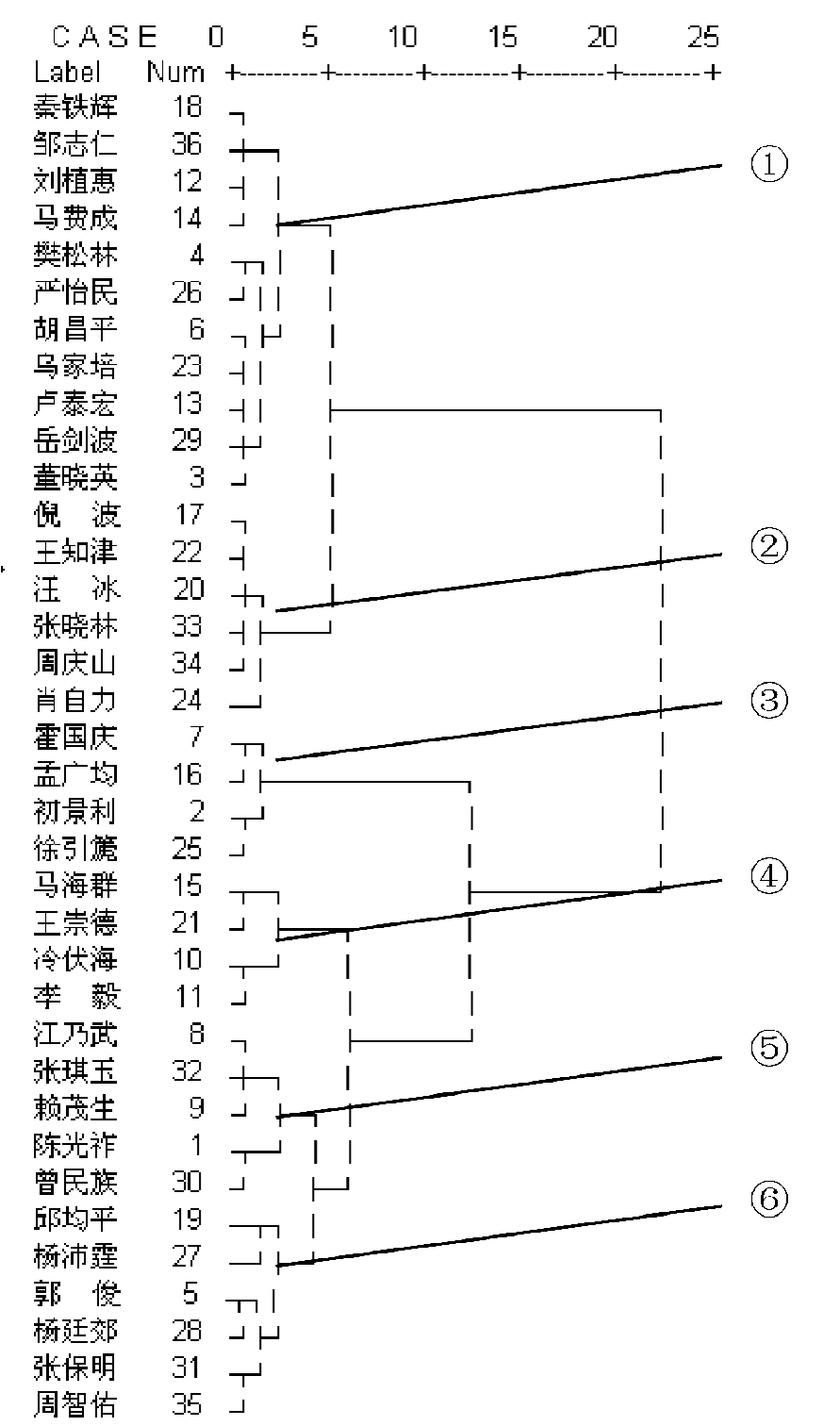
图8-6 ACA聚类分析结果
第二类,情报学理论。这个领域研究者数量最多,研究者之间的关系也较为密切。具体研究内容包括情报学学科基本理论、学科发展、信息用户与服务、信息经济学、竞争情报、信息资源管理等。

图8-7 ACA多维尺度分析结果
第三类,情报检索。这是情报学中最具特色的领域之一,在国外情报学学科结构中占据了主导地位。但国内这一领域的研究者数量较少,尚未形成较为成熟的学术集团。从研究内容上看,学者江乃武所从事的主要是期刊研究,但聚类、多维尺度以及因子分析的结果都显示其属于情报检索领域。具体的原因还需进一步分析。
第四类,图书馆学研究。情报学与图书馆学有着深厚的渊源,两个学科的研究互有交叉,学者也多有交流。在二维体系图中,这一团体规模不大,四位学者都来自中科院文献情报中心,但与其他领域集团分割明显,自成一体。
第五类,文献资源建设。这个区域是情报学与图书馆学的交叉领域,将情报学的理论、技术等运用到图书馆的文献信息资源建设、管理和利用当中,探讨信息服务、知识服务的机制和模式。
图8-7中的横向维度可视为学科维度。坐标线以左,表示图书馆学的理论和方法,坐标线以右,表示情报学的理论和方法。但坐标线本身并不作为严格的分界线,我们可以理解为:从左向右的走向反映了学科属性由图书馆学向情报学的逐渐过渡。
③因子分析。通过因子分析,著者同被引矩阵的因子数削减为10个,能够解释全部信息的85.114%。其中,仅第一、第二个因子解释的信息量就达50.794%,说明这两个学术团体是国内情报学研究的主导力量(见表8-7)。表8-7显示了因子负载大于0.4的著者分类情况。无论是在规模还是研究实力上,各学术团体中的研究者呈明显的梯形递减分布。
与聚类和二维体系相比,因子分析所提供的分类更为细致。一些学者在不同学术集团中的迁移,可以通过因子负载值加以进一步分析(参见表8-7和表8-8)。
表8-7 ACA因子分析结果(著者因子负载>0.4)

续表

注:按照严格要求,负载临界值应为0.5。由于负载临界值越高,所确定的分类结构越简单。根据本节的实际数据,这里将负载临界值定为0.4,以达到较好反映出学术团体组成结构的目的。
a.三位著者同时在第一、第二个因子出现,且因子负载在0.4至0.6之间,体现出这两个因子之间的相关度。在二维体系图中,这两类合并为一类。由聚类分析也可以看出这种趋势。
b.第一、第四以及第六个因子之间的著者有交叉,经过迁移和整合之后,在二维体系图中仍表现为三个类别。这也可以进一步说明文献资源管理领域的跨学科性,它在图书馆学和情报学之间起到了连接的作用。
表8-8 因子分析确定的著者分类

注:著者下标的含义为该著者因子负载的排序。
c.聚类分析的第④类集团中的四位著者,在因子分析中作为第三个因子被抽取列出,其各自的因子负载值均大于0.6。除此之外,马海群在第一个因子上的负载值为0.326,冷伏海在第八个因子上的负载值为0.360,王崇德在第二个因子上的负载值为0.428,李毅在第九个因子上的负载值为0.373,说明他们与这几个领域也有所关联。在二维体系图里的反映即是这四位著者分别合并到了这几个类别当中。
d.从因子分析来看,情报检索集团中曾民族和陈光祚这两位著者的因子负载最大值并不出现在该领域。曾民族的因子负载最大值为0.516,出现在第一个因子中;陈光祚的因子负载最大值为0.531,出现在第七个因子,次高值为0.307,位于第二个因子。通过多维尺度分析,可以看出他们的位置也较为靠近情报学理论集团。与实践型研究相比较,两位学者更侧重于情报检索理论和方法的探讨。
(6)讨论与说明
借助ACA分析手段,我们可以对国内情报学的研究作进一步的探讨。
第一,学科研究力量不均衡。多维尺度和因子分析都显示,我国情报学的研究,情报学理论占据了绝对的主导,但与相邻学术集团的边界不够清晰。White和Griffith1981年的研究(50)显示,国外情报学的7个分支研究实力都较为均衡。而我国的学术集团实力则呈梯形递减分布。
第二,具有特色的学术流派尚未形成。在国外,情报学学科划分为文献与交流、情报检索两大领域。与此相比,我国的情报检索分支虽然有所显现,但集团规模较小,成熟度也不高。而作为主导的情报学理论则显得包容性太强,研究内容繁多,不够具体和细化,从而导致学术流派不明显。可以预测,随着国内情报学学科的发展,一些流派和分支将会从目前的情报学理论中分化出来,并逐渐形成自身的明朗化特色。这也是学科成熟的表现之一。
第三,学者的研究领域较为宽泛。在二维体系图中,很容易找出处于中心位置以及周围区域的学者。通过因子分析,我们发现,各领域带头学者的因子负载基本上在0.7以上,这些著者的研究领域较为专一,集团归属较为明确。除此之外,相当一部分的著者则是横跨两个或者更多的领域,其因子负载值较为平均。如果将负载临界值取为0.3,则可以看出更为明显的分散现象。
本书所选取的是1994~2005年的数据,由于引文具有一定的滞后性,因而该研究所反映的主要是20世纪90年代至21世纪初我国情报学的研究状况,对于当前学科的研究现状和最新动态未能作出及时的反映。在书中所考察的这个时期,我国情报学经历了更名风潮,受到了新兴技术的冲击,并曾一度陷入研究的低谷。这些都应作为进一步分析该时间段学科研究的背景。
需要说明的是,从核心著者的选择,到同被引次数的统计,都是建立在引文分析的基础之上。由于我国学术论文引文著录的不规范,以及数据库完备性等问题,在分析结果中仍然存在一些偏差和无法作出满意解释的地方。通过ACA这种研究思路和分析手段,我们所得到的只是一种描述性的解说,而并非推论性的结论。我们在这里所做的也仅仅是一个尝试。未来的研究将会随着数据的积累和完善,学科自身的成熟,以及ACA方法的改进,得到更深的拓展。
2.我国情报学研究动向
20世纪90年代中期之后,网络和社会环境的变化,技术的推动以及学科交叉使情报学研究呈现出多元化的发展格局,出现了一系列具有代表性的研究主题,并产生了诸多新的学科生长点,极大地拓展了学科的研究领域。信息资源管理、知识管理、情报检索、数字图书馆、竞争情报等都成为情报学研究的主要内容。在这些主题中,知识管理、数字图书馆是新兴的问题;信息资源管理和竞争情报在20世纪80年代中后期就已经开始受到关注,在近几年中形成了研究的热潮;而情报检索最能体现出计算机和网络技术对于情报学的影响和渗透作用(51)。
为了追踪并反映情报学和信息技术应用领域的最新研究状况,中国国防科学技术信息学会于1995年编辑出版了《情报学进展》1994~1995年度评论(第一卷),到目前为止,已经出版了5卷,代表了国内情报学界的研究动向和研究水平。通过对《情报学进展》年度评论第1~5卷内容的回顾,可以对我国情报学研究有个大致的了解和把握(见表8-9)。
从主题分布来看,近10年来我国情报学研究比较集中的领域有情报学理论、信息检索、信息组织和信息服务,这四个主题的发文数占全部论文的一半以上,成为1994年来情报学研究成果最丰富的领域。文献计量学和数据库技术的研究也相对较为集中,一直以来也是情报学研究较多且著文颇丰的领域。其余如数字图书馆、电子出版物等则成为近几年图书馆学和情报学研究的两栖新兴领域(52)。
通过对年度评论的回顾,我们可以发现国内情报学研究的一些特点:①理论研究受到重视,这种关注表现为,在对以往研究成果总结的基础上,对学科理论进行重新的审视和提升,特别在认知观、知识化方面已引起共鸣,这无疑是情报学未来发展的趋势所向;②关于计量学的研究,除了继续深化对于一些基本定律的认识以外,已由文献计量向网络计量方向发展;③情报检索方面,受技术和网络的影响越来越大,并开始注重与用户的互动以及个性化服务的提供;④信息服务领域,由传统的一般性理论探讨转向网络这一特定环境下的实践;⑤一些交叉学科兴起并发展,如信息经济学、信息法学等,这与情报学研究背景的拓展有着密切的关系,同时也是学科交叉的体现;⑥技术专题的设置,显现出情报学学科的技术色彩。
进入21世纪后,情报学研究在已有的研究领域和热点的基础上,又表现出新的研究趋势。研究以纸质载体为主的文献单元,揭示文献内部的知识特征,是过去情报学研究的传统模式。随着信息技术的提升,对于知识单元进行深入研究便成为了可能。与此相对应地,情报学研究者正逐步打破学科壁垒,广泛地吸取其他学科的方法,将问题放置在更为广阔的社会背景之下,力求多角度多视野多方法地剖析社会中的各种情报现象。例如,运用领域分析方法考察情报学与社会学的关系,观照情报学社会层面的属性;从传播学的角度探讨网络环境下的信息交流新规则;借鉴心理学的理论与实验分析,从单纯的情报用户心理研究转向情报全过程的情报认知研究;通过经济学分析模型,研究信息资源的共享效率和优化配置。我们看到,一些原先独立分散的学科正在相互交叉、融合,这预示着多学科集成整合的发展趋势,也为我们勾勒出了一幅情报学研究的全方位图景(53)。
表8-9 《情报学进展》年度评论题录(第1~5卷)

续表

续表

资料来源:《情报学进展》年度评论(第1~5卷)。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











