



11.4 当前公共管理量化分析中存在的问题
调查研究是社会科学探究社会现象的基本方式,它以自填式问卷或结构式访问为主要手段,系统地、直接地收集研究对象的量化资料,并借助于现代统计科学与计算机程序对相关资料进行严格的统计分析,从而认识社会现象及其规律。调查研究的量化分析具有重要意义,“只有当社会世界能够用数学语言表示时,它的各个部分之间的确切关系才能得到证实……没有量化,公共管理研究就只能停留在印象主义的臆想和未经证实的见解这样一种水平上。因而也就无法进行重复研究,确立因果关系和提供证实的通则”。(8)但是,与此同时,调查研究中的各种问题与错误也屡见不鲜。这些问题的存在不仅严重影响了研究成果的信度与效度,而且也损害了学术研究的科学性与规范性。分析单位层次谬误、变量间伪相关/因果关系与基本统计技术误用是当前量化分析中存在的三类主要问题。这些问题有两个基本特征:其一是普遍性。它们经常散见于各类研究成果中,不仅普通研究者会犯这样的错误,而且在一些经典社会学家的著作中也不鲜见。其二是隐蔽性。如果缺乏足够的警惕与坚实的统计分析基础,研究者在量化分析的过程中会不自觉地犯上述种种错误。
11.4.1 分析单位层次谬误
分析单位是研究者所要调查和描述的对象,是研究的基本单位,研究的最终目的是将这些分析单位的特征汇集起来以描述它们组成的较大的集合体或解释某种社会现象。常见的分析单位主要包括个人、群体、组织、社区、社会产物,(9)其中,社会产物主要指各种类型的社会活动、社会关系、社会制度与社会产品。在一个具体的研究过程中,特别是三段论式的逻辑命题中,研究者所进行的分析单位必须保持前后一致。如果作为前提的或者原因的分析单位与作为结论的或者结果的分析单位之间存在脱节,就会出现分析单位的层次谬误。生态学谬误与简化论是分析单位层次谬误的两种主要类型,前者是指用一种高层次的分析单位做调查,却用另一种低层次的分析单位做结论,后者恰好与之相反,是用低层次的分析单位做调查,但是却用高层次的分析单位做结论,它们都是研究的分析单位出了问题,或者是分析单位偏移发生区位谬误,或者是分析单位扩大造成简化论。
生态学谬误也叫层次谬误或者区位谬误,是由社会学家William S.Robinson最先提出的。1950年之前,大部分数据都是以地区为单位的汇总数据,缺乏个人层次上的数据,但是社会学研究者却在地区层次的数据上得出关于个人行为特征的结论。这种倾向在以迪尔凯姆为代表的实证主义研究者身上表现得尤为明显,如《自杀论》一书中关于自杀者的数据都是基于地区、国家、宗教等高层次单位上的汇总数据,但却得出了很多以低层次单位个人为主体的结论。尽管这些结论不乏经典,甚至经检验也被人们承认,但是其分析层次上的生态学谬误是不容置疑的。此外,20世纪二三十年代芝加哥学派在人文区位学的基础上研究美国城市,也在不同程度上留下了生态学谬误的痕迹。正是针对这种现象,Robinson指出,如果社会科学的目的是了解人类的行为,那么,在方法论上就不能用这种汇总数据来推论个人行为。因此,要研究个人、家庭等低层次分析单位的情况,就必须收集个人、家庭等个体层面上的资料,而不能依靠政府提供的汇总数据。(10)
生态学谬误作为一个概念已经提出了近60年,人们也收集了大量的基于个人、家庭等低层次分析单位的数据,但是,研究者在分析过程中仍然无法有效地规避层次谬误的陷阱。直到今天,类似的例子依然很多。如研究者通过量化分析发现,“城市的流动人口越多,城市的犯罪率越高”,但研究者不能由此得出“流动人口比非流动人口的犯罪率高”的结论。因为其调查资料是以城市为单位收集的,所得出的也只是有关城市的结论,而不是有关流动人口和非流动人口的结论。又如,当调查发现越穷的村庄生育率越高,研究者并不能立即推论为越穷的农民生的孩子越多。因为也有可能是穷村中较富裕的农民生的孩子多,才使得整个村子生育率升高。再如,调查发现黑人多的城市比黑人少的城市犯罪率高,研究者也不能由此得出黑人的犯罪率高的结论,因为分析单位的层次是城市,而不是种族,黑人多的城市犯罪率高也许是黑人多的城市中的白人犯罪多,而使得整个城市中的犯罪率增高。
与生态学谬误相对应的另一种分析单位层次错误就是简化论,也称还原论错误,如在社会研究中低层次分析单位得出关于高层次分析单位的结论,以个别现象解释集体现象,以个体层次资料揭示宏观层次的现象。如果说,生态学谬误是方法论集体主义的主要错误,那么,简化论就是方法论个体主义的主要表现。一般而言,生态学谬误与简化论常常出现于社会学研究中,在量化研究中前者出现的几率较高,而在质化研究中,后者容易发生。因此,对调查研究的量化分析而言,要高度警惕与提防生态学谬误。
11.4.2 伪相关/因果关系
公共管理量化分析的主要目标是确定变量间的关系,通常而言,变量间的关系主要有相关关系与因果关系两种。一个变量的变化影响着另一个变量的变化,这就是相关关系。如果两个变量之间不但存在相关关系,而且一个变量的变化会引起另一个变量的变化,那么这种关系就是因果关系。相关关系揭示了两个变量之间内在的联动关系,而因果关系不仅表明了变量间的共变性,而且还反映了两个变量间谁决定谁的关系。如果说,相关关系体现了变量间关系“怎么样”,那么,因果关系就说明了变量间关系的“为什么”。不论是相关关系还是因果关系,都是研究者揭示特定经济社会现象内在运行机制的主要手段。通过确定变量间存在的相关关系或者因果关系,人们可以有效地根据现有的条件与存在状态预测事件未来的发展趋势与变化方向,进而为人们采取干预措施、制定相应对策与改良社会提供依据。因此,寻找变量间的相关关系或因果关系就构成了社会学量化分析的重要使命。可以说,基本上所有的量化分析都是为了寻找变量间的相关关系或因果关系。但是,由于量化分析对相关关系或因果关系的判断主要是基于特定数据关系。因此,量化分析所得出的相关关系或因果关系首先是统计意义上的,也就是说,它未必是真实的相关关系。举例而言,统计数据显示,某地区汽车防冻液的销售量与高速公路上的汽车追尾数量呈正向相关关系。但这种相关关系并不可靠,两者之间并无内在联系,实际上,这两者都共同受到第三因素的影响,即气温低和路面结冰才是造成防冻液的销售量与汽车追尾数量增多的原因(王天夫,2006)。(11)这就是伪相关关系。由于研究者过于迷信问卷与种种量化分析技术,缺乏统计相关与逻辑上的真实相关的比较,常常把统计上的伪相关关系视为真实相关,从而形成各种误判。
忽略变量偏差(Omitted Variable Bias)是导致当前各类调查研究量化分析中伪相关/因果关系盛行的基本原因,而之所以出现忽略变量偏差是因为研究者研究的依据是“观察到的选择性”(Observed Selectivity)(谢宇,2002)。(12)事实上,从调查的抽样开始,到问卷的设计,直至最后的分析,无处不受到“选择性”影响。当这种“选择性”遗漏了重要偏差变量后,量化分析得出的结论也就缺乏可靠性了。下面是一个忽略变量偏差的典型例子,集中体现了伪相关/因果关系形成的逻辑(见表11-4)。
表11-4 住房拥挤对夫妻冲突的影响 (单位:%)
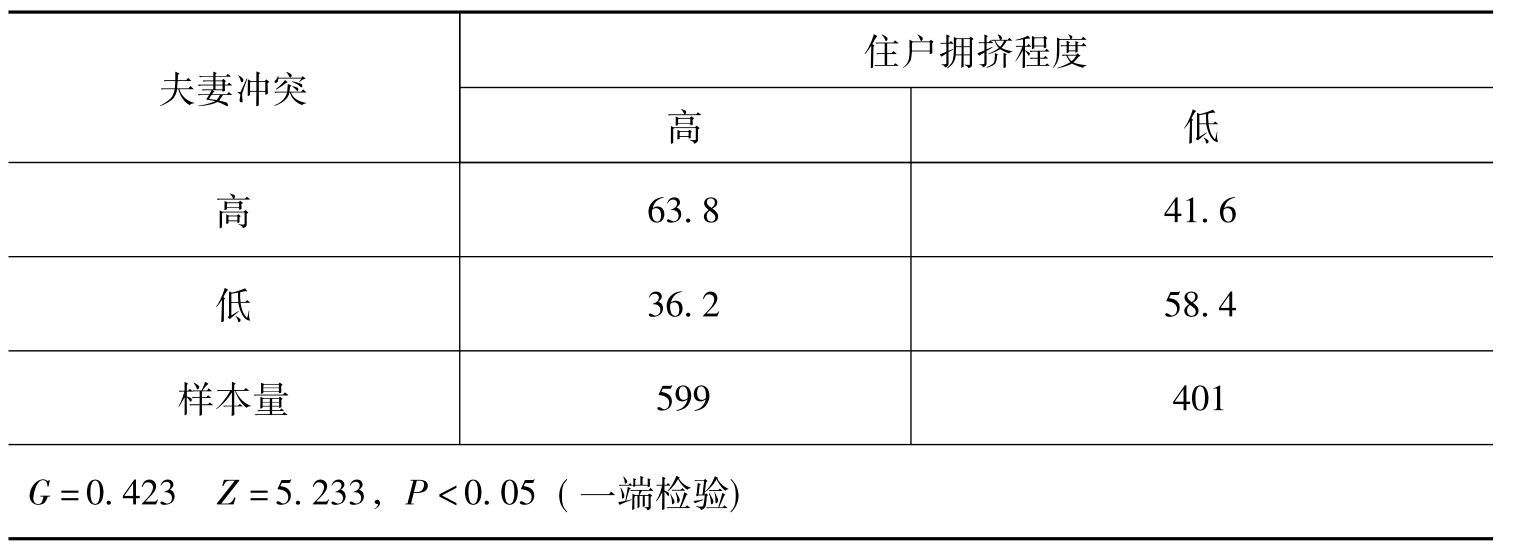
这是一项研究住房拥挤程度对夫妻间冲突影响的调查数据。(13)显然,两个定序变量之间的Gamma系数达到了0.423,通过了95%置信水平下的Z检验,从统计意义上看,家庭住房的拥挤程度与夫妻冲突呈正相关,家庭住房拥挤是造成夫妻冲突的原因之一。但是,进一步的研究表明,这种结论并不可靠,表11-5是控制了家庭经济水平后对夫妻冲突的影响情况。
表11-5 控制家庭经济水平后住房拥挤程度对夫妻冲突的影响 (单位:%)
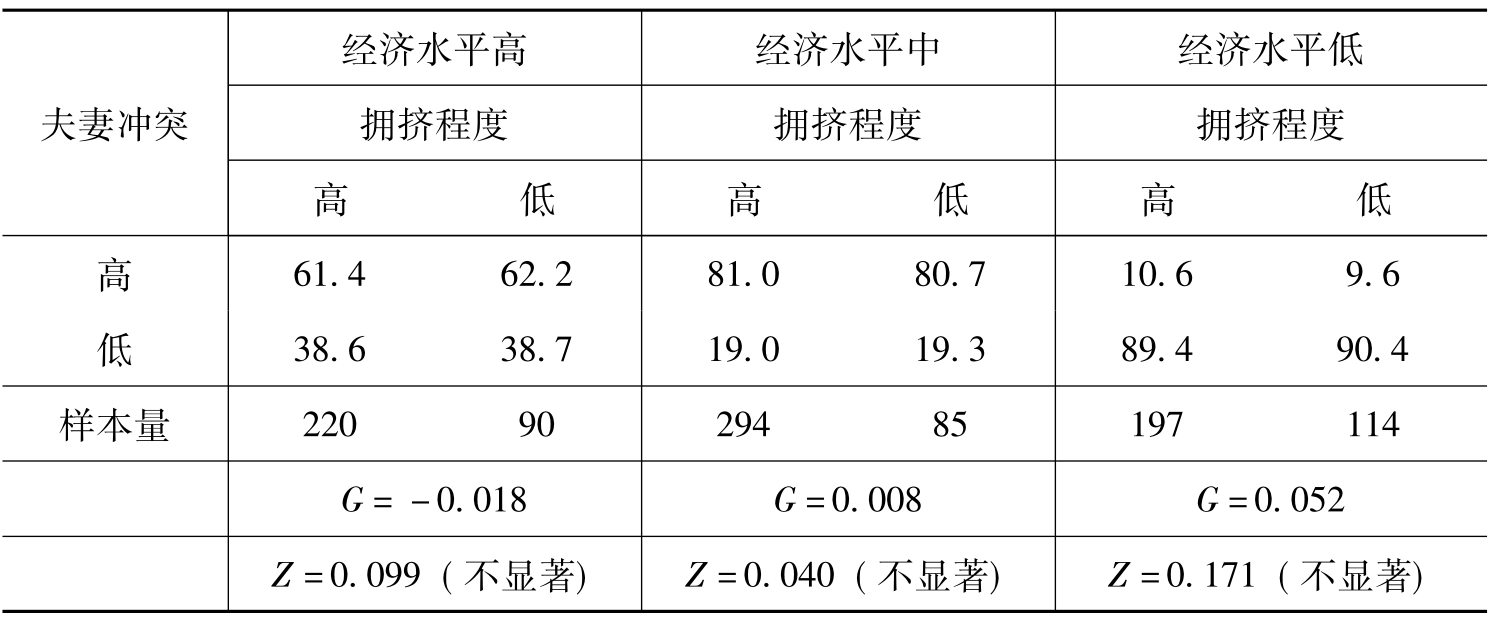
表11-5显示,在控制了家庭经济水平以后,无论在哪个经济水平,Gamma的绝对值都非常小,而且都没有通过95%置信水平下的Z检验。这说明,表11-1中所反映的统计上的因果决定关系是一种伪相关/因果关系,家庭住房拥挤并非导致夫妻冲突的原因。事实上,家庭经济水平状况是引起住房拥挤与夫妻冲突的共同原因。因为家庭经济条件差,不仅会导致住房拥挤,而且还会导致家庭成员之间的矛盾增多。
在这里,家庭经济水平就是分析中被忽略的偏差变量。正是对它的忽视导致人们掩盖了真实的相关关系/因果关系。一般而言,忽略变量偏差的形成需要具备两个向度上的条件:其一,被忽略的变量对因变量即结果变量具有重要影响;其二,被忽略的变量对自变量即原因变量存在重要影响(谢宇,2002)。在本例中,经济条件对作为自变量的“住房拥挤”的“因”与作为因变量的“夫妻冲突”的“果”都产生了影响。显然,这再一次告诉我们,量化统计分析反映的仅仅是理论模型的数学关系,它可能与真实的相关关系/因果关系一致,也可能是一种伪相关/因果关系。由于社会研究的特殊性,无论是在样本选择还是在变量分析上,都难以穷尽所有对象与所有影响因素,因此,被忽略的偏差变量总会以某种形式隐藏于研究者的分析过程中。当这种忽略的偏差变量对研究影响较小时,尚不会对研究者的研究结论形成挑战,但是,如果被忽略的偏差变量是至关重要的因素,那么,它就有可能从根本上动摇研究者的立论基础。因此,研究者必须对研究中各种隐蔽性的偏差变量予以高度关注,才有可能把被忽略的偏差变量的影响降到最低,实现研究的科学性与规范性。
11.4.3 基本统计技术误用
公共管理量化分析是调查研究的核心,主要研究结论也都是基于统计分析的结果,但是,在当前的统计分析中,由于种种原因,特别是很多公共管理研究者缺乏系统的统计学知识训练,使得调查研究量化分析中出现了许多常识性错误。一般而言,量化分析的技术性错误或瑕疵主要表现在研究方法交代不详、基本概念混乱不清、假设检验适用错误等三个层面。
1.研究方法交代不详
在公共管理调查研究中,数据质量是量化分析的生命。质量低下的数据不仅会导致研究者分析过程的困难,而且在错误数据基础上得出的结论也会导致实践活动的南辕北辙。只有高质量的调查数据才能保证研究过程的流畅性,也才能得出科学的研究结论。这也是人们为什么要看研究者研究方法的基本原因。无论是农村社会学研究,还是城市社会学研究,抑或其他社会学研究中,大部分的数据资料都是研究者自己设计、收集来的,数据来源的多样化使得数据质量参差不齐,缺乏可比性,因此,对大部分研究者来说,研究方法成为判断数据质量的一个有效窗口。一般而言,研究方法的介绍至少要包括抽样方法、主要变量与研究假设、资料收集方法以及量化分析的统计软件情况等方面。对专业研究者来说,研究结论固然重要,但更重要的是你的研究方法是否规范。通过阅读研究方法,人们就可以对研究者研究质量有一个基本、大致的评价。但是,目前除了《社会学研究》、《中国社会科学》、《社会》等专业性社会学期刊上量化分析的研究方法介绍相对充分外,大部分调查研究或者缺少对研究方法的交代,或者研究方法的交代语焉不详,让人们难以对相关研究的科学性做出进一步的判断。
研究方法交代不详也体现在具体的研究分析过程中,对统计软件中关键性的统计量缺乏充分说明。如在研究论文中进行统计推论时只是给出检验结果,并没有给出检验方法;对需要区分单双侧的t检验、u检验未注明检验是单侧还是双侧;进行显著性检验时只给出P值,而未给出统计量。事实上,正确的统计分析方法、具体的统计量值与P值是实现准确推断结论的重要依据,三者缺一不可。此外,在用t检验和方差分析处理定量资料时,由于t检验和方差分析都属于参数检验方法,进行检验需要满足一定的前提条件,如正态分布等,大部分的研究者也缺乏相应的考察与交代。
2.基本概念混乱不清
(1)标准差与标准误
标准差与标准误是既有联系又有区别的两个基本统计概念。“均数±标准差”反映的是观测值在样本均数附近的波动情况。标准差小,说明抽样样本同质性较强、重现性好、离散度小;而“均数±标准误”反映的则是在相同条件下的重复研究中,样本均数与总体均数的接近程度,标准误小,说明调查研究的样本代表性较高、稳定性较好。可以看出,“均数±标准差”说明的是在某一个具体样本中某个指标各变量值的变异情况;而“均数±标准误”反映的是抽样样本反映总体的能力。“均数±标准差”要求样本资料服从正态分布,因此,在使用这种表示方法时,特别是当标准差大于均数时要先对资料进行正态性检验。以“均数±标准误”取代“均数±标准差”,或者是因为不清楚二者的含义与区别而误用,或者是利用标准误比标准差小,可造成样本服从正态分布的假象,以满足样本正态性需求而故意为之。
(2)P值显著性检验
在利用统计数据得出研究结论时,需要对P值进行显著性水平检验,从而在原假设“H0∶μ=μ0”与备择假设“H1∶μ≠μ0”之间做出判断与选择。但是,由于没有深刻理解P>0.05、P<0.05及P<0.01的统计学含义,经常会出现结论错置的局面,如在“P>0.05”时认为“有差异”,而把“P<0.05、P<0.01”视为无“差异”。此外,针对P值比较95%与99%两个水平得出“无显著性差异”、“有显著性差异”及“有非常显著性差异”等的结论。这些都是对P值检验的误解。事实上,统计学上讲的“差异”是指比较的总体间有无差异,而非样本间有无差异。正确的含义是,当P<0.05时,可以认为比较的总体间无差异的概率小于0.05,故可认为在统计学上比较的总体间有差异,表述为“差异有统计学意义”;而当P<0.01时,在统计学上更有理由认为比较的总体间有差异,但仍旧表述为“差异有统计学意义”。此外,如前所述,必须要注意统计学分析结论的有限性,警惕可能得出“伪相关/因果关系”结论。
3.假设检验适用错误
(1)χ2检验适用错误
在量化统计分析中,数据是有层次的,连续性数据与非连续性数据在处理方法上是根本不同的,即使同为非连续性数据,定类数据与定序数据也有不同的适用范围。在现有的spss分析中,χ2检验就是用来处理定类变量与定类变量之间关系的一个基本方法,也是社会学研究中使用得比较多的一种方法。显然,χ2检验并非处理定性资料的万能工具,只有少数列联表资料在特定的分析目的和具备特定的前提条件时才可以运用χ2检验处理定类数据资料。一般而言,χ2检验适用错误主要表现在两个方面:
其一,误用χ2检验分析指标变量有序的资料。在分析两个变量关系时,如果自变量或者因变量其中一个指标变量是定序及以上层次变量,那么就不能适用χ2检验。一般而言,适合分析单向有序(即“定类变量+定序变量”组合)列联表资料的统计分析方法有秩和检验或Ridit分析。
其二,误用χ2检验回答相关问题。χ2检验只能回答“二维列联表中各行上的频率分布是否相同”的问题,并不能说明两个变量之间的相关性是否具有统计学意义。“双向有序且属性不同”(“定序变量+定序变量”组合)的列联表资料可以选用Spearman等级相关分析。
此外,要区分Spearman等级相关分析与Pearson相关分析的差异。前者适用于“定序变量+定序变量”组合,而后者要求两个变量均为定量变量,而且属于“双变量正态分布数据”。错用Pearson相关分析定序变量数据,可能会出现与采用Spearman秩相关分析完全相反的结论。
(2)t检验适用错误
t检验法是定量变量均值差异假设检验的一种常用方法。当方差未知时,可以用之检验一个正态总体或两个正态总体的均值检验假设问题,也可以用来检验成对数据的均值假设问题,主要有单样本t检验、独立样本t检验与配对t检验。单样本t检验是用样本均数代表的未知总体均数和已知总体均数进行比较,来观察此组样本与总体的差异性;独立样本t检验主要用于两样本均数比较;配对样本t检验主要用于进行配对设计的差值均数与总体均数0进行比较。无论哪种类型的t检验,都必须满足特定的前提条件。单样本检验要求样本资料服从正态分布,同时必须给出一个标准值或总体均值以及提供一组定量的观测结果;配对样本检验要求每对数据的差值必须服从正态分布;独立样本检验要求个体之间相互独立,两组资料均取自正态分布的总体,并满足方差齐性。只有具备这些前提条件,计算出来的t统计量才服从t分布,满足t检验以t分布作为其理论依据的要求。
对研究者来说,t检验适用错误主要有三种形式:其一,未能有效区分单样本t检验、独立样本t检验与配对t检验之间的联系与区别,造成适用范围混乱。其二,误用t检验进行多样本均数间的两两比较。由于此时样本数量≥3,如果继续采用t检验对样本之间进行两两比较,就导致出现第一类错误的概率α增大。现假设有三个抽样样本,采用t检验两两比较就会出现三个对比组,若检验水准α=0.05,那么,犯第一类错误的概率为1-(1-α)3= 0.143,远远大于设定的0.05。因此,不能对多样本进行t检验,而应在方差分析的基础上进行SNK的q检验进行两两比较。其三,在两样本t检验中要用到F检验,判断两总体方差是否相同,即方差齐性。如果两总体方差齐性,那么可以直接适用t检验,样本所属总体平均数的差异来源于组间方差;如果总体方差不齐,那么可以采用t检验或变量变换或秩和检验等方法,样本所属总体平均数差异显著可能部分归因于各样本组内方差不同。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。












