



二、我国外语类辞书编纂出版现代化的实践探索
改革开放30年间,我国外语类辞书编纂与出版的现代化进程不仅体现在相关理论的研究与探索,而且在辞书编纂与出版的具体实践方面也有了长足的进步。具体而言,我国外语类辞书编纂与出版现代化的实践探索与成果主要体现在服务于外语类辞书研编的语料库以及辞书编纂系统方面,同时辞书出版的现代化发展也不可忽视。
1﹒语料库相关实践探索成果
在语料库各种理念和设想的基础上,国内有关研究机构和出版社建设了一些英语单语和双语平行语料库并对相应的技术进行了积极的探索。下面简介已有的几个有代表性的语料库。
1.1 南京大学双语词典研究中心语料库(20)
(1)英语单语语料库。南京大学双语词典研究中心的英语单语语料库(NJU_BDRCMC)的语料来源为书本、杂志、电子出版物;涵盖文学、科普、新闻、经济、医学卫生、法律等题材;语言形式以书面语为主,口语为辅,口语材料主要为谈话采访和演讲等。为了向语料库使用者提供详细的语料信息,本语料库主要的一种存储方式是按照一条完整的记录存储在数据库中。由于语料库规模比较大,同时为了配合网络检索的需要,语料库的整条记录存储在MySQL数据库中,之所以选择MySQL,主要是MySQL具有下面的这些特点:
a.同时访问数据库的用户数量不受限制;
b.可以保存超过5 000万条记录;
c.是目前市场上现有产品中运行速度最快的数据库系统;
d.用户权限设置简单、有效。
MySQL存储的每条语料的记录由以下内容组成[ti:文章标题]、[st:文章副标题]、[au:文章作者]、[pb:文章出版单位]、[pd:文章出版时间]、[ct:文章国别代码](国别代码表:美国1、英国2、加拿大3、澳大利亚4、新西兰5、南非6、爱尔兰7、印度8、埃及9、新加坡10、菲律宾11、中国12、日本13、德国14、法国15、意大利16、以色列17、冰岛18、墨西哥19)、[ma:文章题材代码](题材代码表:文学1、科普2、新闻3、历史4、政治5、经济6、文化7、体育8、艺术9、自然10、医学卫生11、法律12、军事13、其他14)、[sy:文章体裁代码](体裁代码表:小说1、散文2、传记3、评论4、说明5、其他6)、[pt:文章类型代码](类型代码表:书1、报纸2、杂志3、因特网4、声像制品5、其他6)、[co:一段的内容]。单语语料库目前共有5 128 040条记录,根据程序统计,词例总数为102 364 744次,即南京大学双语词典研究中心英语单语语料库总规模为102 364 744词次。具体的南京大学双语词典研究中心英语单语语料库见图4-5。

图4-5 南京大学英语单语语料库存储样例
(2)英汉双语平行语料库。考虑到双语辞书研编以及双语辞书编纂出版数字化研发的多种科研需求,南京大学双语词典研究中心英汉双语平行语料库的素材一方面来源于南京大学双语词典中心拥有自主知识产权的双语辞书标准数据以及英汉双语对照文献,另一方面也面向网络获取了大量的英汉双语平行对语料。下面主要介绍一下该中心面向网络的英汉双语平行语料对获取的相关情况。
随着文本挖掘和网页抓取技术的迅速发展,基于网络的英汉双语平行语料对自动获取越来越受到研究者的关注。叶莎妮和吕雅娟(2008)利用URL命名相似性获取双语候选网页自动发现命名规律从而获取更多可靠的双语候选网页,同时侧重双语句对之间的互译性,有效地提高了双语平行句对抽取的召回率和准确率。该研究仅仅获取了句子对,对于短语对、术语对和词汇对则没有涉及。吴琳和魏星(2009)利用欧洲专利局的URL命名特点获取专利英文著录信息的详细网页实现网页的批量下载,采用正则匹配表达式提取出网页上的专利英文著录信息,与中文著录数据合并后存入数据库中。该文主要是获取专利领域的英汉双语平行语料对,对于其他领域和通用的英汉双语平行语料对则没有涉及。程岚岚(2008)提出了一种使用正则表达式的术语对抽取方法,在获取网页源文件的基础上,依据已定义的正则表达式从中抽取出正确的术语对。该方法的可移植性相对比较差,没有获取较复杂的短语对和句子对。张永臣基于从网络中获取的非平行英汉语料,提出了利用词间关系矩阵法从特定领域非平行语料中抽取双语词典的方法,由于种子词对英汉对照词汇对的抽取影响较大,获取的英汉对照词汇对质量并不高。
根据获取英汉双语平行语料对的实验数据总结的经验,一个完整的获取英汉双语平行语料对的流程大致包括下面几个部分:首先,确定抓取的网站,根据具体的研究需要和网络资源随机调查,初步确定所抓取网站。其次,制定抓取词汇底表,基于大规模语料库的统计数据结合人工内省的方法增加相应的词汇知识,确定具体的抓取词汇底表。再次,利用网络抓取工具自动获取含有英汉双语平行语料对资源的网页,在自动抓取的过程中,根据具体的抓取需要适当添加一些人工干预。最后,英汉双语平行语料对的提取、去重和入库,从大规模网页中提取英汉双语平行语料对,在去重的基础上把英汉双语平行语料对自动存储到数据库中。上面的基本流程可以用图4 6简单地描述出来。

图4-6 英汉双语平行语料对获取整体流程
南京大学双语词典研究中心英汉双语平行语料库(NJU_BDRCBC)共1 916 121对英汉平行句对,英语词例共84 681 689次,汉语词例数共128 587 247次,即总规模为213 268 936词次。具体的英汉双语平行语料库样例见图4 7。
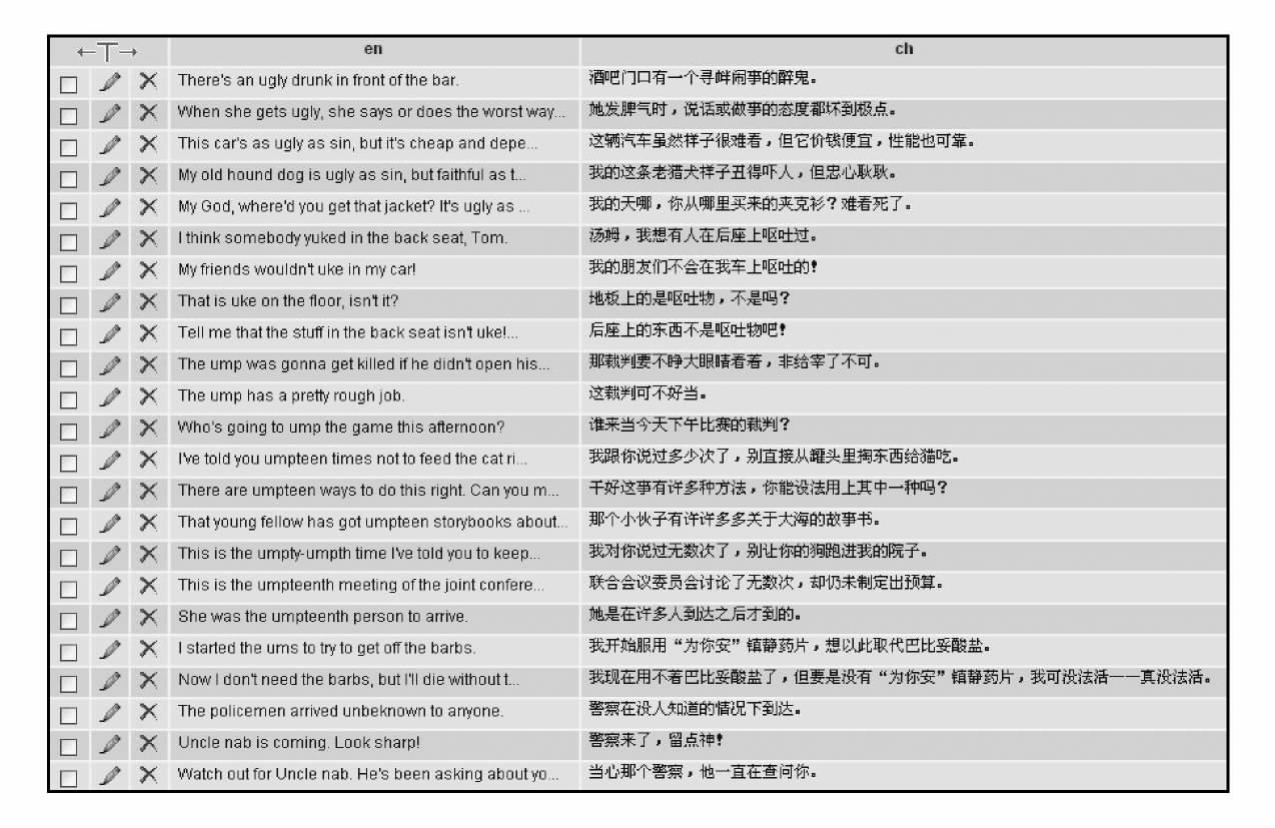
图4-7 南京大学双语词典研究中心英汉双语平行语料库样例
1.2 北京大学计算语言学研究所双语平行语料库(21)
2003年起北京大学计算语言学研究所参加了863课题研制《中文平台总体技术研究与基础数据库建设》的工作,承担了其中的子课题《汉英/汉日多语语料库》的研制工作。子课题的研制目标是建设大型的汉英、汉日双语语料库,为机器翻译等应用系统的研发提供基础资源和标准的评测语料,具体研制目标为建立汉英句子级对齐语料20万句对;建立汉日句子级对齐语料2万句对;建立汉英词汇级对齐语料1万句对。
构建汉英/汉日双语平行语料库涉及双语原始语料收集、整理、筛选、加工和组织。为了更好地开展这项工作,保证语料库的质量和规模,并且合理、有效地推进语料库建设,需要一个相对完整、便于操作的语料库构建流程。为此,北京大学计算语言学研究所对双语语料本身以及语料的整理和加工等项任务进行了考察,分析问题的复杂性,构建了一个双语平行语料库构建流程的模型,并为流程的各个环节开发了相应的辅助工具,形成了一个双语语料库构建和处理工具集。按照此模型,汉英/汉日双语平行语料库的构建主要按照下列七个步骤进行:
(1)汉英/汉日原始语料的收集
(2)汉英/汉日语料的筛选和整理
(3)对语料进行句子级的对齐处理
(4)句子级对齐结果的人工校对
(5)对语料进行词汇级对齐处理
(6)词汇级对齐结果的人工校对
(7)重复检查、结果提取和格式转换
以下为汉英双语句对齐语料样例:
000001请出示护照和登机牌。
Passport and Embarkation Card,please.
000002利物浦队的防守队员正在拦截史密斯。
Liverpool’s defender is tackling Smith.
000003有可乐吗?
Do you have Coke?
000004我不是故意冒犯你的。
I don’t mean to offend you.
000005我要用快件寄这封信。
I’d like to send this letter by express mail.
000006银钱兑换处在哪里?
Where is the money exchange?
000007请给我兑换一些面额较少的钱币好吗?
Could you break this bill into smaller change?
000008请把时间表给我看一下。
May I see the schedule?
000009我能在这儿稍停一下吗?
Can I park here just for a second?
000010裁判工作人员进场。
Officials march in.
000011我要一份菠萝汁、一个煮鸡蛋和烤面包,还有茶。
I’ll have a pineapple juice,a boiled egg with toast and tea,please.
000012现在托马斯正紧盯着皮克森。
Now,Thomas is marking Pixon closely.
以下是汉日句对齐语料样例:
00001按此办理。
このよう処理いたす。
00002按此做合同。
これにて契約書を作成する。
00003按发票价格另加10%投保。
インボイス価格に10%加えて付保する。
00004按季结账。
四半期ごとに決済をする。
00005按时装运。
期日通り船積みする。
00006按现价再减百分之二。
現価格よりさらに2%値引きする。
00007包装受潮。
包装が濡れている。
00008必须事先征得我方同意。
必ず事前に当社の同意を得なければならない。
00009对因此而给贵方造成的麻烦,再一次表示歉意。
本件で貴方に多大のご迷惑をおかけたことを重ねてお詫び申し上げます。
00010不得不按合同规定取消订货。
契約の規定により注文を取り消さざるをえなくなります。
00011请收到后马上回信。
お受け取り次第ご返事くださるようお願いします。
1.3 中国科学院汉英平行语料库(22)
在国家973子课题的支持下,中国科学院的研究者对中英文篇章对齐的双语文本进行了段落对齐、句子对齐加工,建立了一个大规模具有统一标准和规范的、多领域、多体裁、句子级对齐的双语语言信息和知识库。该课题的主要研究内容如下:(1)借助互联网等其他媒体搜集中英文篇章级对齐的双语文本,并进行必要的预处理;(2)参照都柏林核元数据元素集制订了双语语料文本标注规范,在973标准讨论会上进行讨论通过;(3)大规模文本句子对齐方法:面向多领域、多体裁,采用基于双语词典的句子对齐方法进行了文本对齐,并对如何提高对齐精度做了进一步的研究和探讨;(4)自动评价:对双语文本句子对齐结果实现自动评价。可见,无论从语料规模还是从对齐的程度上看,中国科学院的汉英平行语料库都达到了较高的水平,对辅助机器翻译、双语词典编纂和双语语言知识获取都有重要的意义。
上述中国科学院参照都柏林核元数据元素集制订的《双语语料库标注规范》,其具体的文件头和文件体信息见表4 1和表4 2。
表4-1 文件头信息

续 表

表4-2 文件体信息
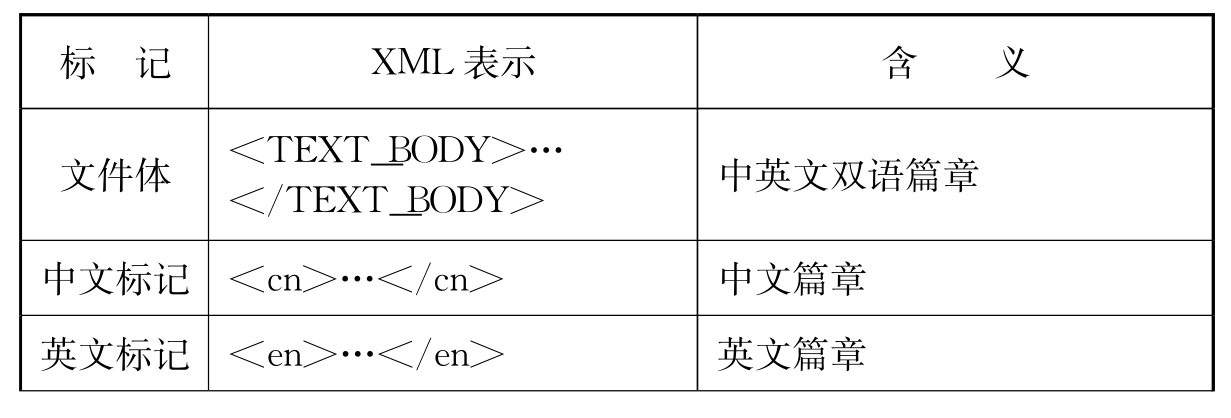
续 表

为了进一步说明文件头和文件体的信息以及让读者更好地了解该语料,下面给出一个具体的例证:
<TEXT_HEAD>
<TITLE>00001江泽民同志在党的十六大上所作报告全文
#Full text of Jiang Zemin’s report at 16th
Party congress on Nov.8,2002</TITLE>
<SUBJECT>politics</SUBJECT>
<CREATOR>中科院自动化所</CREATOR>
<AUTHOR>江泽民</AUTHOR>
<DESCRIPTION>十六大报告</DESCRIPTION>
<PUBLISHER>ChineseLDC</PUBLISHER>
<CONTRIBUTOR>xxxx</CONTRIBUTOR>
<DATE>2003 01 03</DATE>
<FORMAT>text</FORMAT>
<TYPE>02020</TYPE>
<IDENTIFIER>xxxx<IDENTIFIER>
<SOURCE>中国外交部网站<SOURCE>
<RIGH TS>xxxx</RIGH TS>
<AREA>大陆</AREA>
</TEXT_HEAD>
<TEXT_BODY>
<cn>
<p id=1><a id=1.1><s id=1>改革开放取得丰硕成果。</s></a><a id=2.2><s id=2>社会主义市场经济体制初步建立。</s><s id=3>公有制经济进一步壮大,国有企业改革稳步推进。</s></a><a id=3.1><s id=4>个体、私营等非公有制经济较快发展。</s></a><a id=4.1><s id=5>市场体系建设全面展开,宏观调控体系不断完善,政府职能转变步伐加快。</s></a><a id=5.1><s id=6>财税、金融、流通、住房和政府机构等改革继续深化。</s></a><a id=6.1><s id=7>开放型经济迅速发展,商品和服务贸易、资本流动规模显著扩大。
</s></a></p>
</cn>
<en>
<p id=1><a id=1.1><s id=1>Reform and opening up have yielded substantial results.</s></a><a id=2.1><s id=2>The socialist market economy has taken shape initially,furthermore,the public sector of the economy has expanded and steady progress has been made in the reform of state‐owned enterprises.</s></a><a id=3.1><s id=3>Self‐employed or private enterprises and other non‐public sectors of the economy have developed fairly fast.</s></a><a id=4.3><s id=4>The work of building up the market system has been in full swing.</s><s id=5>The macro‐control system has improved constantly.</s><s id=6>The pace of change in government functions has been quickened.</s></a><a id=5.1><s id=7>Reform in finance,taxation,banking,distribution,housing,government institutions and other areas has continued to deepen.</s></a><a id=6.2><s id=8>The open economy has developed swiftly.</s><s id=9>Trade in commodities and services and capital flow have grown markedly.
</s></a></p>
</en>
</TEXT_BODY>
1.4 北京外国语大学双语平行语料库(23)
在教育部人文社科重点研究基地的“双语平行语料库的创建及应用研究(2000—2003)”这一重大研究项目支持下,王克非负责构建了汉英和汉日两个平行语料库。两个双语平行语料库的基本情况如下:(1)国内首家2 000万字的日汉对译文本语料库。目前2 000万字的平行对应语料分文学与非文学、汉译日和日译汉存放,做到段级对齐,应用研制的检索工具可对汉日语料做各种词语、短语、句型和搭配上的检索;(2)世界最大的3 000万字词的通用型汉英平行语料库。此库设计为4个子库,即“百科语料库”(抽样提取语料,分15大类别适当配置,文科约75,理科约25)、“翻译文本库”(全本收录,包括一本多译,含创作性文本和描述性文本)、“双语语句库”(收录对译短语、句子,取自各种文本)和“专科语料库”。目前3 000万字词语料已基本做到句级对齐,其中2 000万字词语料已完成最终校对、标注、双语链接,可进行词语、词频、短语、搭配、句型等多种检索。北京外国语大学中国外语教育研究中心的双语平行语料库的特点如下:(1)整个语料库可分可合;分开可开展单项研究,如百科语料库、双语句库有利于双语词典研编,专科语料库有利于自动翻译研究,翻译文本库有利于翻译文体和翻译教学研究;合则可在大规模语料基础上进行词频、搭配、对应词、句型、语体、文体等方面研究;(2)此语料库区分4种语料:英/日语原文、汉语原文、英/日语译文、汉语译文,可分别进行单语研究、双语对比研究、原文与译文语言对比研究;(3)利用此双语语料库可搜寻大量的对应词语、短语,丰富英/日—汉、汉—英/日双语词典的编纂。北京外国语大学中国外语教育研究中心的平行语料样例见图4-8。

图4-8 北京外国语大学中国外语教育研究中心的平行语料检索样例(24)
2﹒词典编纂系统研发探索与成果(25)
词典编纂系统的开发尤其是涉及双语的词典编纂系统相对来说比构建语料库要复杂得多。但在计算机、计算语言学和计算词典学的知识和技术推动下,结合双语词典编纂的具体实践需求,国内的一些研究机构进行了初步尝试并取得了一定的效果。
2.1 南京大学双语词典研究中心(26)
南京大学双语词典研究中心在总结多年双语辞书研编工作经验的基础上,先后开发了CONULEXID和NULEXID编纂系统。下面简单介绍一下CONULEXID升级后的NULEXID编纂系统的相关内容。目前开发完成的NULEXID系统采用了client/server结构,在中文版Windows 2000 Server网络系统环境下,基于大型数据库管理系统IBM DB2开发。系统采用了MVC模型,通过VB来获得可视化前端支持。在服务器端通过IBM DB2访问代理程序响应客户请求,对数据库进行各种操作。NULEXID的设计功能分为四大部分:
(1)双语词典编纂,包括双语词典在线查询,双语词典在线编辑,双语词典自动生成,双语词典信息统计。
(2)英文原文语料,包括文章信息在线查询,文章信息在线统计,文章例句在线查询,文章自动词性标注,经典译文记忆存储,英语词频统计。
(3)双语词典信息批量入库,即纯文本形式或带有方正系统排版格式的词典文件均可以批量入库。
(4)输出功能,即可将数据库中语料信息以文本方式或自定义格式输出,以便后期出版。
词典编纂者是NULEXID系统最重要的用户之一。系统为他们提供了对语料库内文章进行检索统计、对语料库内词典进行查询统计,以及远程编写词典等多种服务。具体见图4 9。
在如图4 9所示的登录画面中键入正确的登录名及登录密码后,即可进入NULEXID系统主画面,如需进行相应设置,按如下示意图4 10进行设置。
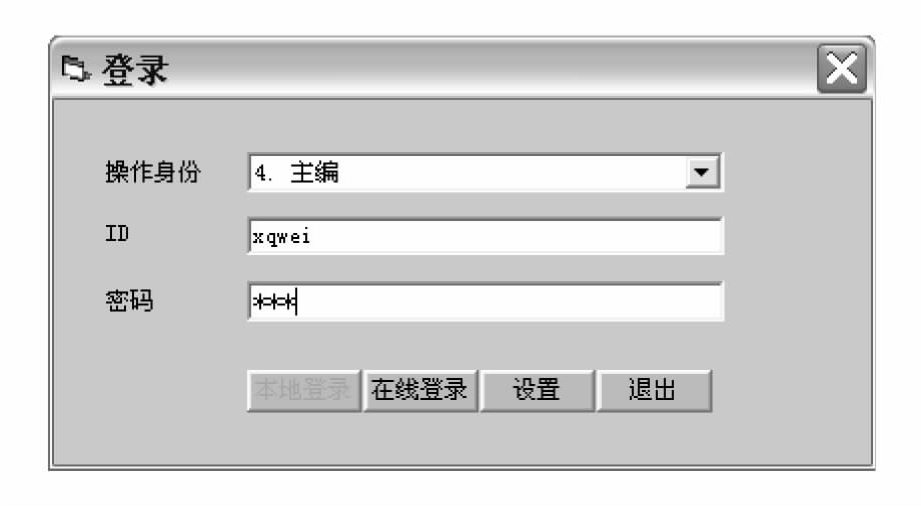
图4-9 NULEXID词典编纂系统编纂登录界面
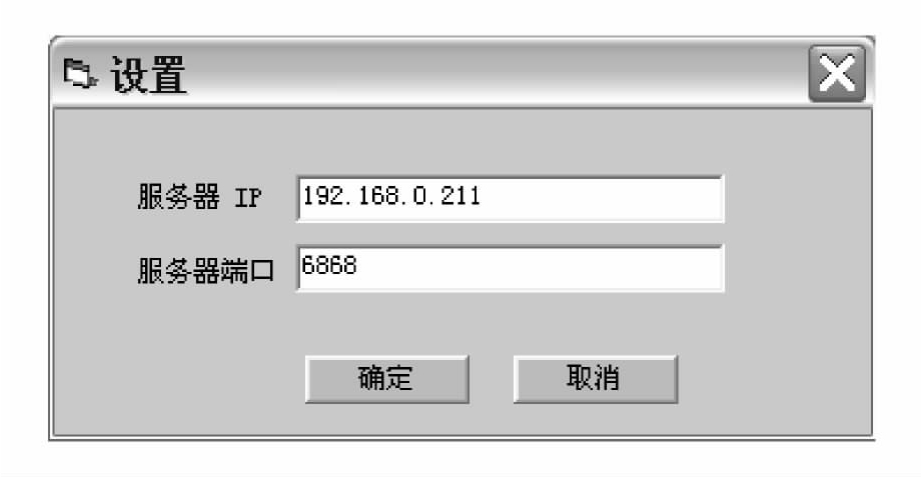
图4-10 NULEXID词典编纂系统登录设置
词典编纂是NULEXID系统最为重要的功能之一,它可以实现编辑的无纸化词典编纂、远程网络词典编纂,以及对语料库资料的实时查询和调用。点击导航栏中的词典选择,将出现图4-11的画面。
编辑必须在词典选择的下拉框中选择需要进行编写的词典,一次登录只能对一部词典进行写操作。系统在编辑登录时已通过编辑ID号确定其具有编写权限的词典,选择错误将不予执行。所选词典的简介信息显示在屏幕右侧的文本框内。词条状态共分六项:新词条,编辑中,初审中,二审中,终审中,定编。除定编词条外,无论词条处于何种状态,编辑都有权对自己的工作进行修改,系统将实时对修改内容进行再存储。以编写新词条为例,点击该词条,系统进入词条的编写画面。编辑可以直接点击词性、释义或者例证进入相应的编写画面,具体请见图4 12和图4 13。
图4-11 NULEXID词典编纂系统导航界面

图4-12 NULEXID词典编纂系统词条分配界面
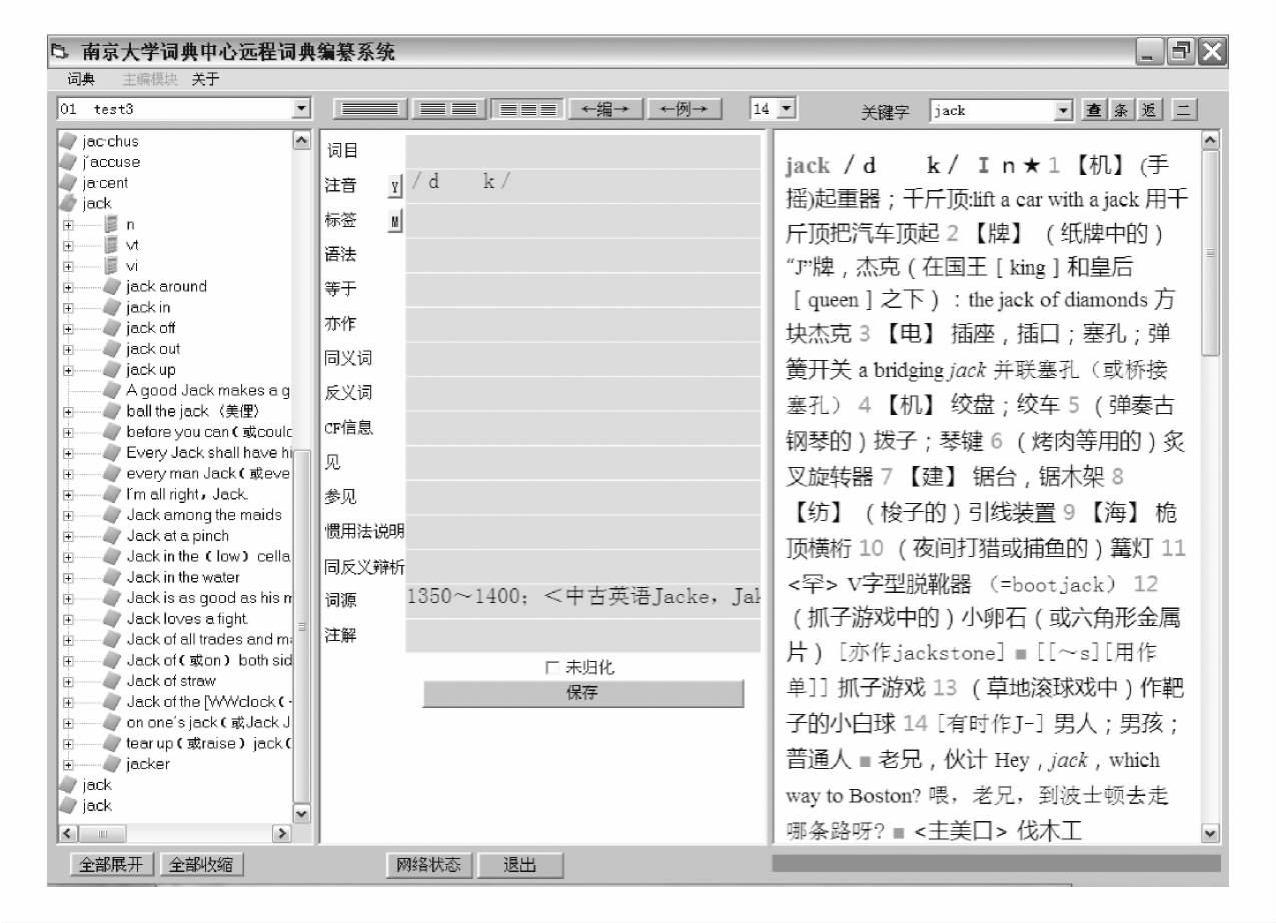
图4-13 NULEXID词典编纂系统词条编纂界面
如某部词典将条目的不同词性都单独列出,则对于jack一词来说,就存在两个词条,“jack_”上标1为名词词条,“jack_”上标2为动词词条。标签选择框共分为三类:语体标签、语域标签、学科标签。点击添加释义,系统进行释义编辑的画面见图4 14、4 15和4 16。
如图4-16,当词目及词性均已确定,编辑需在中文释义框中填入中文释义;有特殊语法用法说明的填入语法用法说明框。点击添加例证,进入例句选择画面,具体见图4-17。
词条初审的权限在词典建立之初便已确定,只有当词条的编辑将其提交初审后,具有该词条初审权限的编辑才会在点击菜单条中的词条初审后,看到等待审核的词条,具体见图4-18。
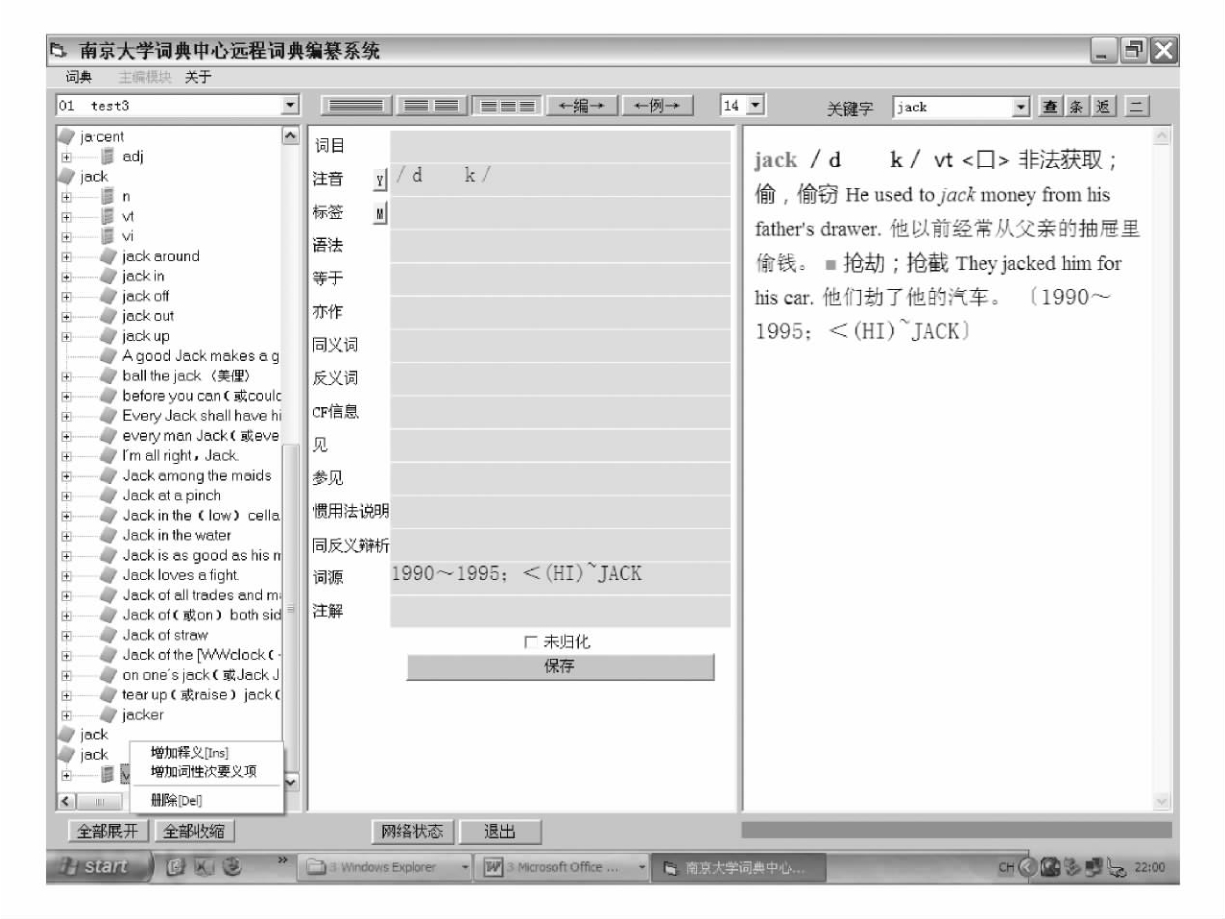
图4-14 NULEXID词典编纂系统具体编纂界面(一)
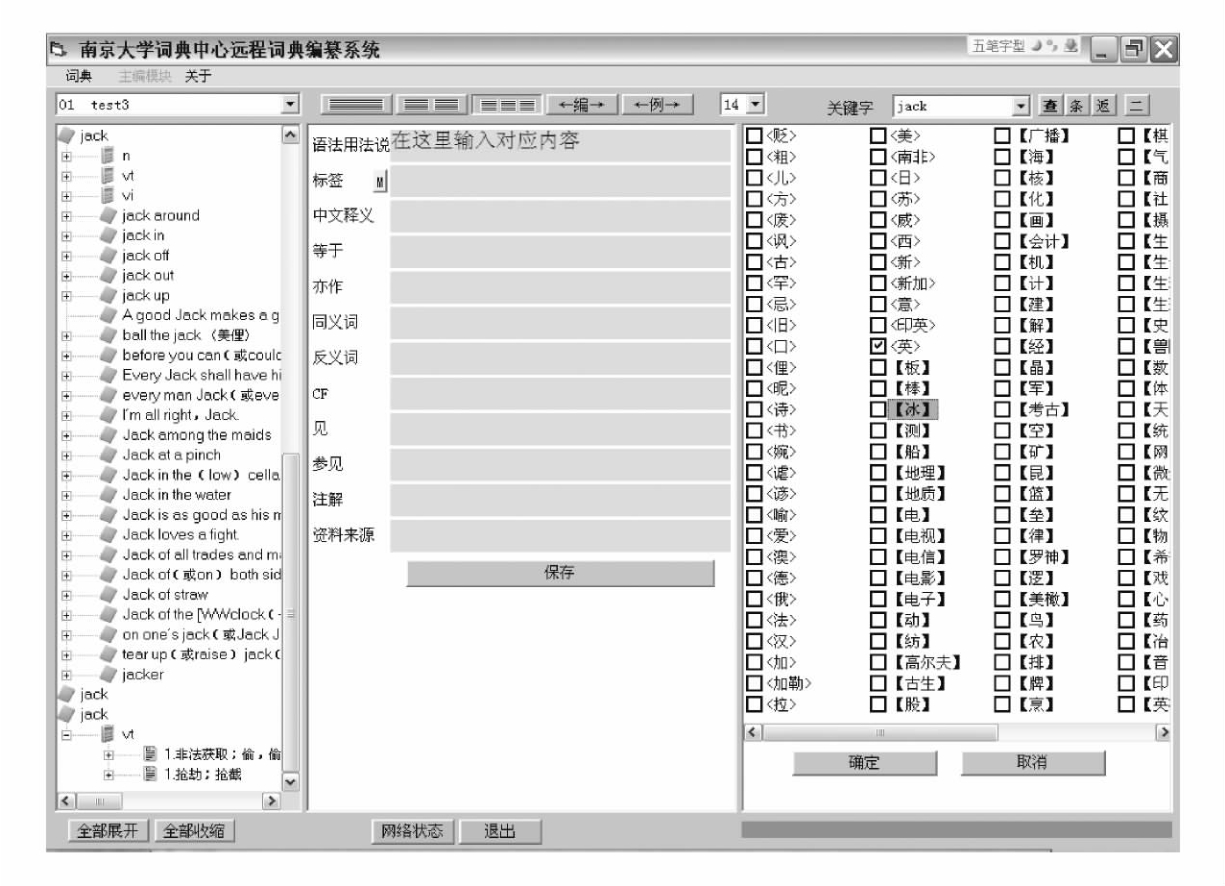
图4-15 NULEXID词典编纂系统具体编纂界面(二)

图4-16 NULEXID词典编纂系统具体编纂界面(三)

图4-17 NULEXID词典编纂系统具体编纂界面(四)

图4-18 NULEXID词典编纂系统初审登录界面
系统列出的等待初审的词条及其编辑名称。点击词目超链接,系统将调出该词条的详细信息,初审编辑不可以对词条内容进行任意的修改。点击通过审核,则该词条进入词条二审的流程,将出现在组长词条二审功能的列表中,同时从初审列表中消失。
初审编辑虽然不可以修改词条内容,但可以通过内部消息交流的方式,向原编者发送意见,令其修改后再提交初审。具体操作为点击编辑姓名超链接,系统弹出撰写新消息的窗口。词条二审的权限在各编辑小组的组长,只有当初审编辑将词条通过审核后,组长才能够在点击导航栏中的词条二审后看到等待二审的词条,其画面同词条初审。不具有组长权限的编辑在导航栏中没有词条二审功能,具体见图4-19:
图4-19 NULEXID词典编纂系统二审登录界面
2.2 广东外语外贸大学词典研究中心(27)
针对目前词典编纂出版存在的各种问题,融合词典编纂出版经验,广东外语外贸大学的刘辉开发了“基于语料库的WEB词典编纂&自动生成系统(简称Dict Generator系统)”。该词典编纂系统是一种网络软件,基于三层C/S结构技术开发,为了减少网络通信量,降低服务器负荷,系统功能层主要实现在客户端。Dict Generator系统对用户而言可以利用单独的客户端GUI界面进行操作,也可以通过浏览器进行操作。一般来说词典数据的输入查询通过浏览器进行,而词典的审定通过独立客户端进行。系统总体结构内容如下:
(1)系统表示层是用户接口部分,担负着人机交互功能,即用户和系统的对话功能。它用于检查用户从键盘等输入的数据,现实系统输出数据等。Dict Generator系统的表示层宿主系统一般为Windows2000以上版本操作系统,对用户比较直观。
(2)系统功能层实现具体的业务处理逻辑。Dict Generator系统功能层主要担负着接收表示层数据,通过分析处理后和数据层通信(例如存储词典体数据);同时也负责将服务器端对用户的请求结果进行逻辑处理后反馈给表示层(例如词典查询结果的反馈)。
(3)系统数据层就是DBMS,负责管理对数据库数据的读写。DBMS能迅速执行大量数据的更新和检索。数据层和表示层的通讯依靠功能层来实现,在功能层通过程序来控制数据完整性,实现事务提交以及回滚。整体框架见图4-20。

图4-20 广东外语外贸大学词典研究中心双语词典编纂系统功能框架
2.3 北京外国语大学中国外语教育中心(28)
在“取代纸笔、全程应用、使用方便”这一理念下,陈国华和熊文新设计开发了服务于《中国学生英语学习词典》编纂的词典编纂系统。该系统在windows环境下,利用C#制作出前端用户界面,编者只需通过程序依据编辑体例提供的各种输入框中键入相关信息内容,系统在后台自动记录用户输入的信息内容并将其保存到数据库特定表的特定记录中。
系统工作界面主要可分为数据浏览区、词条编辑区和反馈显示区三部分。数据浏览区提供对数据库记录(对应于词典中的词条)的基本增删改操作,实现对指定检索条件下的特定类(如词类、词语起始字母)等的词条检索以及词条在数据库库首、库尾及向前、向后的位置定位;词条编辑区针对当前处于活动状态的词条可以进行任一字段的信息编辑,包括各信息描述项的增、删、改操作以及同一类型多个信息容块的顺序调整(如义项或例证的调序);反馈显示区用来显示活动状态的词条依据词典编辑体例的格式化信息内容。词典编写是一个实时纠偏的过程,编者对于所编写词条应该了然于胸。为使编写人员能够随时自我检查词条的编辑质量,系统利用RichEdit控件,依据词典语法实现了一个读取数据库内容并动态显示当前词条的反馈界面。其实质是建立一个良好的人机交互环境。由于系统在接受用户词条编写时,考虑到描述信息的完整性,采用了完全模板形式。为防止用户在对词典编写体例理解不透的情况,这种设计有可能导致用户误输入错误信息,因此在每完成一个词条编写的同时,系统将在反馈显示区展现当前词条在最终词典中的版面形式。编者可以直观地发现可能存在的错误,并回到数据编辑区有针对性地在有错误的操作区重新编写该词条。编纂系统的具体样例见图4-21:
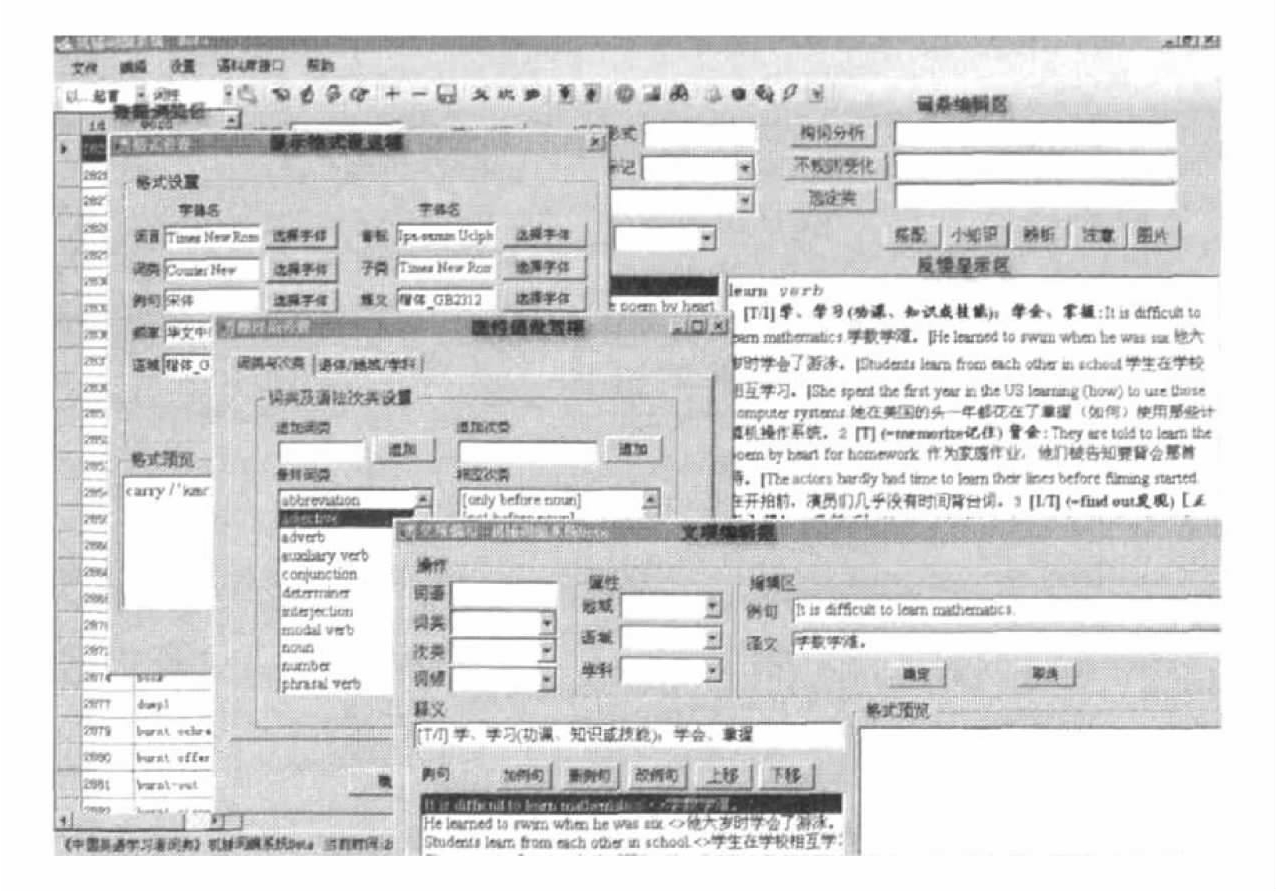
图4-21 北京外国语大学中国外语教育中心词典编纂系统图样
2.4 北京大学计算语言学研究所(29)
北京大学计算语言学研究所的常宝宝对双语词典编纂系统的开发进行了积极的探索,并为“编纂平台”设定了11项功能目标。(1)语料库的定制和索引:针对为具体词典编纂项目定制的语料库提供索引,为高效检索和统计提供支持;(2)参考词典的定制和索引:平台允许用户为某个具体词典编纂项目指定参考词典,并为用户高效检索参考词典提供索引支持;(3)词典编纂项目管理:项目负责人可以根据编纂需要,决定参加编写的工作人员,并为词典编纂项目创建项目组,落实项目的具体编纂工作;(4)条目的生成和管理:“编纂平台”允许词典项目负责人或从语料库中据统计结果得到条目表,或从其他来源得到条目表,或自行设计条目表;(5)释义词表的生成和管理:“编纂平台”允许项目负责人为某词典编纂项目制定有限释义词表。该词表可以由语料库选择高频词构成,也可以由项目负责人自行设计。(6)词典编纂任务管理:“编纂平台”以“任务”的形式管理词典编纂人员的各项工作;(7)编纂平台用户管理:根据不同的权限分为系统管理员、项目负责人和词典编纂人员;(8)词典微观结构的定制和管理:为了使平台具有通用性,项目负责人可以针对特定的词典编纂项目定制特定的词条结构模板;(9)词典编纂工作台:通过该工作台,编写人员可以很方便地查询语料库以及参考词典;(10)语料库检索:语料库检索是“编纂平台”的核心功能;(11)搭配信息统计分析:“编纂平台”可基于语料库统计出某个词的可能的搭配词、这些搭配词与该词共现的频度、搭配词与该词的搭配强度。具体的双语词典编纂平台的结构图见图4-22:
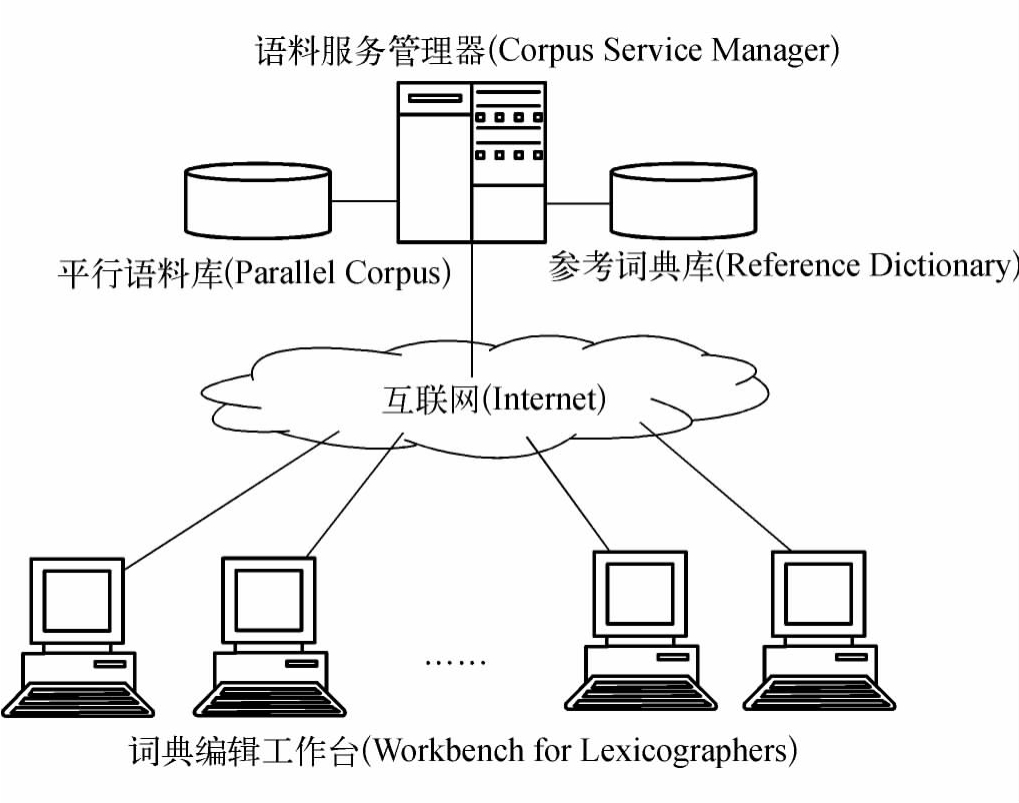
图4-22 北京大学计算语言学研究所双语词典编纂平台的结构图
2.5 教育部语言文字应用研究所(30)
在“利用大规模语料库、辞书数据库等资源,结合语言处理技术,依托知识获取语义计算等理论方法,计算机辅助辞书编纂可以达到新的高度”这一理念下,“基于语料库的数字化辞书编纂平台研制”作为国家863计划项目“中文信息处理应用基础研究”的子课题,由靳光瑾任课题组组长负责完成。该辞书编纂平台以国家语言文字工作委员会大规模现代汉语语料库为基础,以语义计算理论为核心,以数字化典范辞书为出发点,利用语言信息处理计算机技术等,研制辞书的知识获取、自动生成、检查检测、审核评价等技术和集成化的辅助操作平台,突破传统的辞书编纂概念,建立一种新型的辞书编纂模式。词典编纂系统的功能主要如下:基于语义计算理论的数字化辞书生成系统:以语义计算理论为核心,利用语言处理技术,根据不同的用户对象、领域、辞书规模等信息,按照用户可定义的辞书模板,重组生成新的辞书框架,并在此基础上通过语料库更新原有的释义和例证,为编纂人员提供新辞书的基本内容。语料库是真实语言文字的集合,基于语料库的辞书编纂更强调辞书内容、释义、例证的真实性,拉近辞书内容与用户的距离,使得辞书编纂更贴近用户需要;辞书雷同检查和冲突检测技术:以经典辞书(或指定辞书)为基础,检查其他辞书与其在词表、概念释义、例证等的相似程度,高度相似则视为雷同;辞书的规范性检查:以国家已经发布的语言文字标准为基础,检查辞书中是否存在与规范标准不一致或有冲突的内容。规范性检查试图提高辞书的整体质量水平。具体的流程见图4 23。
上述五个辞书编纂系统中,南京大学双语词典研究中心、广东外语外贸大学词典学研究中心以及北京外国语大学中国外语教育研究中心的相关编纂系统的研发均出于外语类辞书研编的实际需求,有较好的实践针对性,可谓是为双语辞书“量身定做”的编纂系统。相比之下,北京大学计算语言学研究所和教育部语言文字应用研究所研发的相关辞书编纂系统则更多考虑辞书编纂的普适性,即可以同时服务于汉语和外语类辞书的研编。由于双语和单语辞书的编纂有着各自鲜明的个性特征,其相应的具体编纂需求也必然存在诸多差异,因此,在未来的辞书编纂系统研发工作中,结合辞书类型研编的具体实践需求充分细化挖掘是需要引起辞书编纂系统研发者更多关注的,它将直接影响到编纂系统的实用性。
3﹒辞书出版的数字化探索与成果
在辞书数字化理念探究的前提下,基于计算机、计算语言学和计算词典学的知识和技术,国内的相关公司和出版机构对掌上电子词典、个人电脑词典、在线词典和手机词典等数字化出版实践也进行了积极的探索,取得了一些值得关注的重要进展和相关成果。在这些辞书数字化成果当中,外语类辞书所占比例很大。事实上,我国辞书出版的数字化探索与相关成果最先并且也主要是从外语类辞书这个方面展开的。此后的汉语辞书数字化出版,在很大程度上是受到了外语类辞书数字化发展的积极影响与促进。
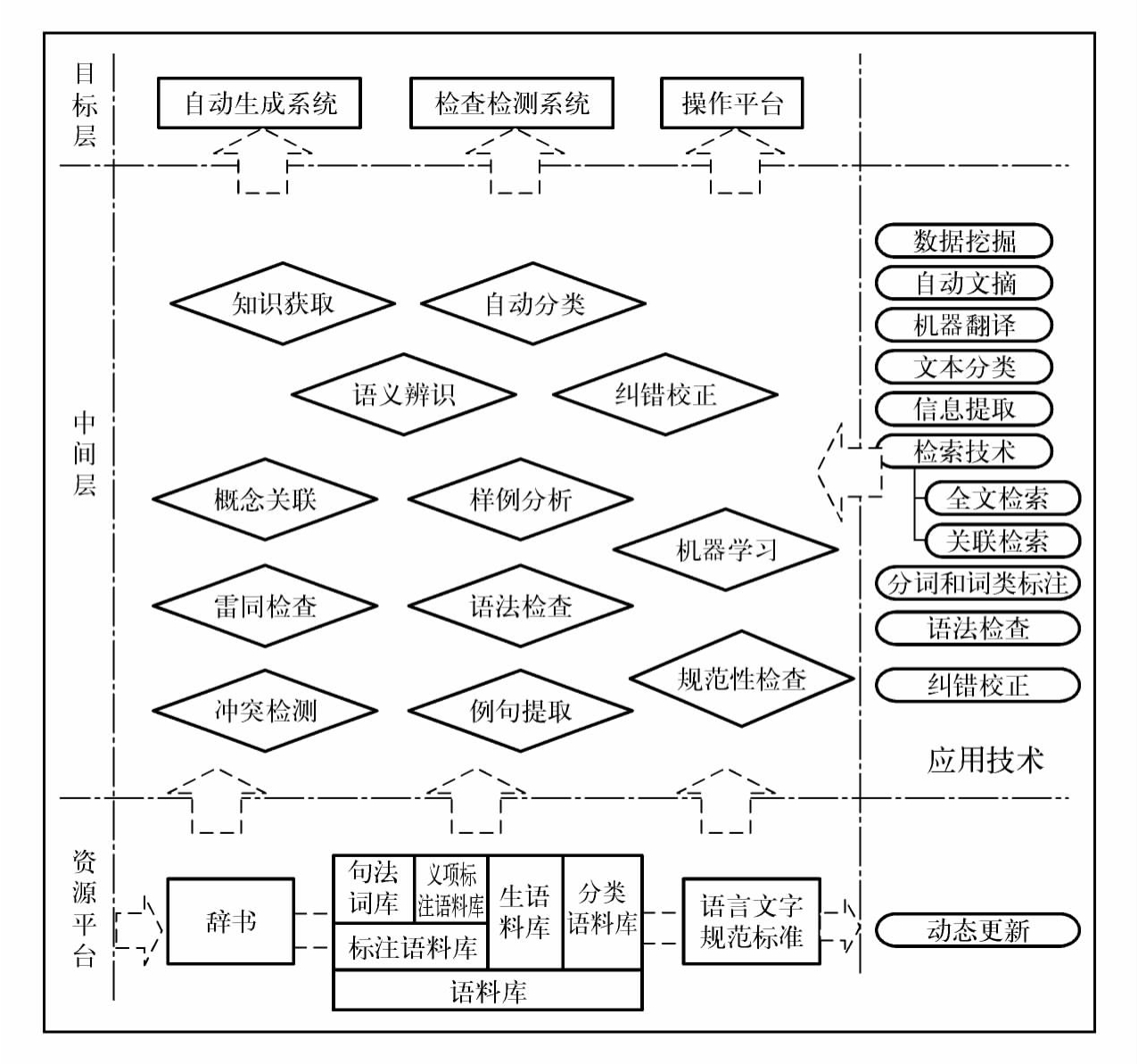
图4-23 教育部语言文字应用研究所数字化辞书编纂系统结构概要图
我国的掌上电子词典于20世纪80年代末兴起,经过20多年的迅速发展,已经取得了令人瞩目的成就。根据掌上电子词典发展的历史沿革及相应阶段的标志性事件与特征,我国掌上电子词典走过了从起步阶段、早期发展阶段、快速发展阶段到平稳发展阶段等四个发展阶段。中国掌上电子词典起步于20世纪80年代末到90年代初。这个阶段的特点是发展缓慢,掌上电子词典的品牌比较少,基本上也就是“莱丝康”、“伟易达”、“电译通”、“好易通”和“快译通”这些品牌,而且只能进行简单的单词查询,功能比较单一(31);掌上电子词典的各种功能从90年代中期起不断得到改善,增加的功能主要有PDA功能、数码录音功能、夜光显示功能以及真人发音功能,比较有代表性的掌上电子词典是文曲星的多功能普及型电子词典PC220(32);中国掌上电子词典从20世纪90年代末期开始进入了发展的快车道。“文曲星”、“快译通”、“好易通”、“名人”、“诺亚舟”、“好记星”、“联想”、“步步高”和“快易典”等各电子词典品牌厂商在词典功能的多样化、词典收词容量的丰富、所收录词典的权威性以及产品价格等各方面展开了一系列的激烈竞争,先后经历了“好易通”CD3、“快译通”EC 1900、“名人”IQ138和“文曲星”PC200及PC260于1998年的商战,“文曲星”、“好易通”和“快译通”在1999—2001年的“三足鼎立”,2001年PDA市场称雄以及2002—2005年掌上电子词典“战国时代”激烈竞争阶段;经过高速发展后,掌上电子词典迎来了市场逐步规范、功能进一步完善、发展多元化的平稳发展阶段。
个人电脑词典也就是光盘版电子词典在我国兴起得比较晚,真正的光盘版电子词典是在1993年左右上海朗道科技发展有限公司开发的《朗道词典》。比较有代表性的光盘版电子词典还有中国大百科全书出版社与台湾棣南公司联合推出的光盘版《中华百科全书》、汉语大词典出版社和商务印书馆(香港)有限公司合作出版的光盘1.0版《汉语大词典》,其他比较知名的光盘版电子词典还有《即时通英汉汉英双向词典》、《新世纪汉英科技大词典》、《Dr.eye译典通》、《金山词霸》、《着迷词王2001》、《东方大典》、《多媒体汉字字典》等。
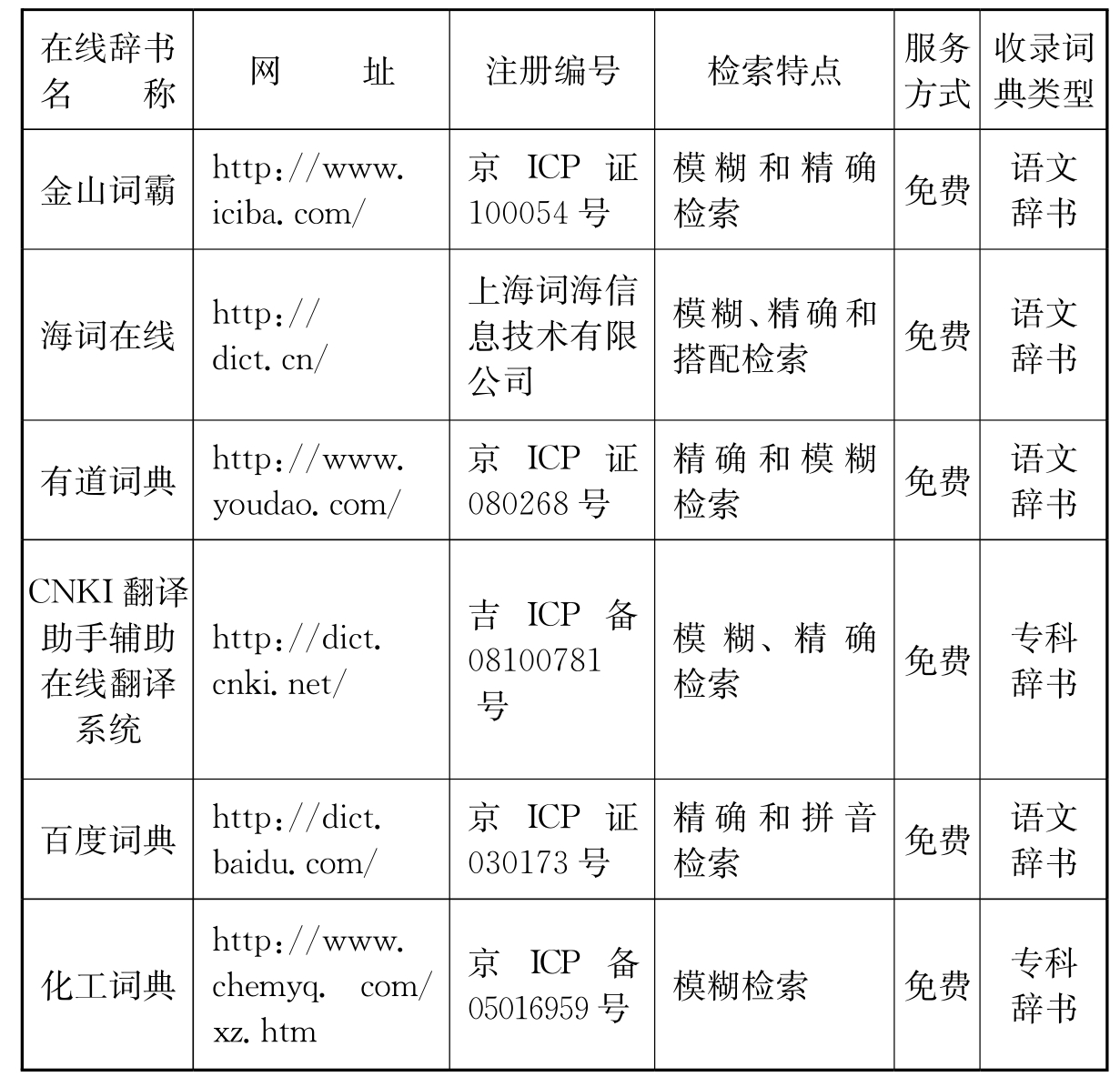
随着20世纪90年代末至21世纪初中国大陆的互联网日新月异的发展,在线辞书也得到了全方位、多层次的发展。在线辞书之所以得到如此快的发展,是因为其自身的一些特殊优势。(1)检索的多样性和智能化:在线类辞书一般情况下都是多部辞书的集合,它们借助计算机、计算词典学的技术和知识提供了多样性的查询方式,如精确查询、模糊查询、分类查询、搭配查询、拼音查询等。同时,在线类辞书的检索入口多并且比较方便;(2)检索返回结果丰富:由于在线类辞书数据库的庞大和检索条件丰富,当输入某个检索词的时候,在线辞书不但会给出该词基本的释义,而且会给出该词出现的语境、网络释义以及百科知识;(3)检索结果呈现形式的科学性:纸质版辞书通常只能提供给读者某一查询词固定的信息内容(33),而与该词有关的同义、反义和上下语义等语言信息则往往因篇幅等因素而不直接提供或呈现。而集合多部辞书的在线类辞书就独具优势,能够很便利地提供该词条相关的丰富语言信息;(4)在线辞书的良好开放性和互动性:在线类辞书的开放性和互动性是针对辞书的使用和编纂来说的,作为网络一个组成部分的在线辞书充分体现了网络的开放性,用户基本上可以任意访问相关的在线类辞书。用户同时还可以创建相关的词条、提供有关的例证,而在线类辞书的编辑则会针对用户上传的有关词条、例证进行筛选。使用较多的国内双语在线辞书见表4-3。
表4-3 在线辞书举例
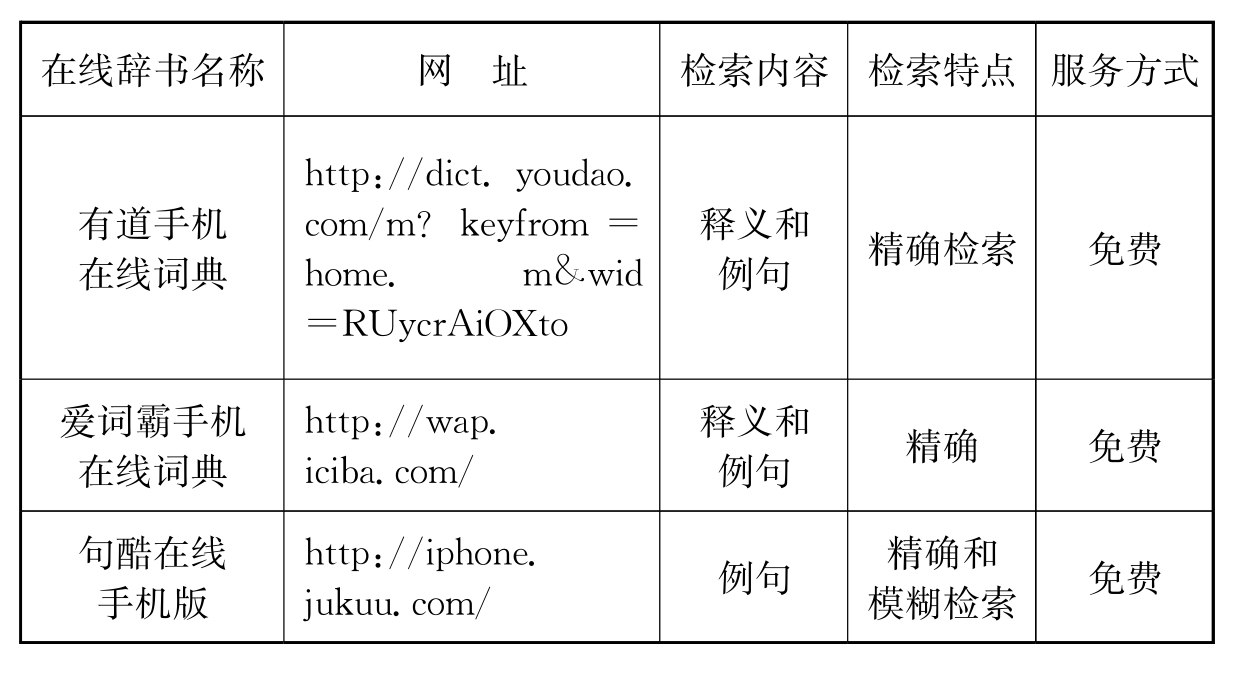
新世纪以来,随着3G技术的快速发展以及手机功能的日益多样性,手机词典作为一种新型时尚的辞书数字化载体得到了较快的发展,并且日益受到广大手机用户尤其是年轻用户的青睐。手机词典的内容也主要涉及外语类辞书。国内目前做得相对比较好的手机词典具体见表4-4。
表4-4 手机在线词典
综上所述,我国改革开放30年间,得益于各相关领域的技术进步和辞书编纂出版数字化理念的推陈出新,外语类辞书的数字化发展可谓一日千里,令人目不暇接。此外,值得关注的是,近期我国在另一种新型数字化辞书载体方面也有了初步成功的尝试,即相关电子书(e‐book(34))的研发生产。电子书主要是将书的内容制作成电子版后,放在网上出售。购买者用信用卡或电子货币付款后,即可下载使用专用浏览器在计算机、其他可以添加阅读器应用的工具,如手机、电子书阅读器上离线阅读。这种把词典尤其是综合性和百科类词典存储其中的电子书被称为词典电子书。对于词典电子书,已有一些研究和探索。但目前这方面的创新主要是在汉语类辞书方面。2010年,上海世纪出版集团以集单字、词语、百科于一体的大型综合性词典——《辞海》为基础的“辞海悦读器”(35)的推出无疑在中国词典电子书发展历程中具有里程碑的意义。“辞海悦读器”不仅全球唯一完整内置《辞海》(第六版),更集成了《中华文化通志》十典百志101卷以及后续加入的世纪出版集团多种权威工具书,权威的华文智识平台,通过辞海搜索引擎,让读者轻松畅游,形成智慧海洋。因此,我们相信也非常期待我国外语类辞书在词典电子书这个新载体方面很快有同样的发展。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










