



二、“维基”时代我国外语类辞书编纂出版现代化的构想
辞书编纂出版现代化的核心理念是数字化,这也是“维基”时代辞书编纂出版的基本实践模式。我国外语类辞书编纂出版经过改革开放30年的长足发展,已经在数字化转型方面有了基本的经验积累和一些初步的尝试。关于未来我国外语类辞书编纂出版现代化的发展构想,我们应该基于百科全书(Wiki)编纂的特点和文本挖掘的相关技术和知识,从双语辞书编纂出版的本质内涵和基本特征出发来进行考虑。下面我们以英汉双语辞书为典型类别对我国外语类辞书编纂出版的数字化提出一些初步的技术构想。具体的构想见图4-24(42)。
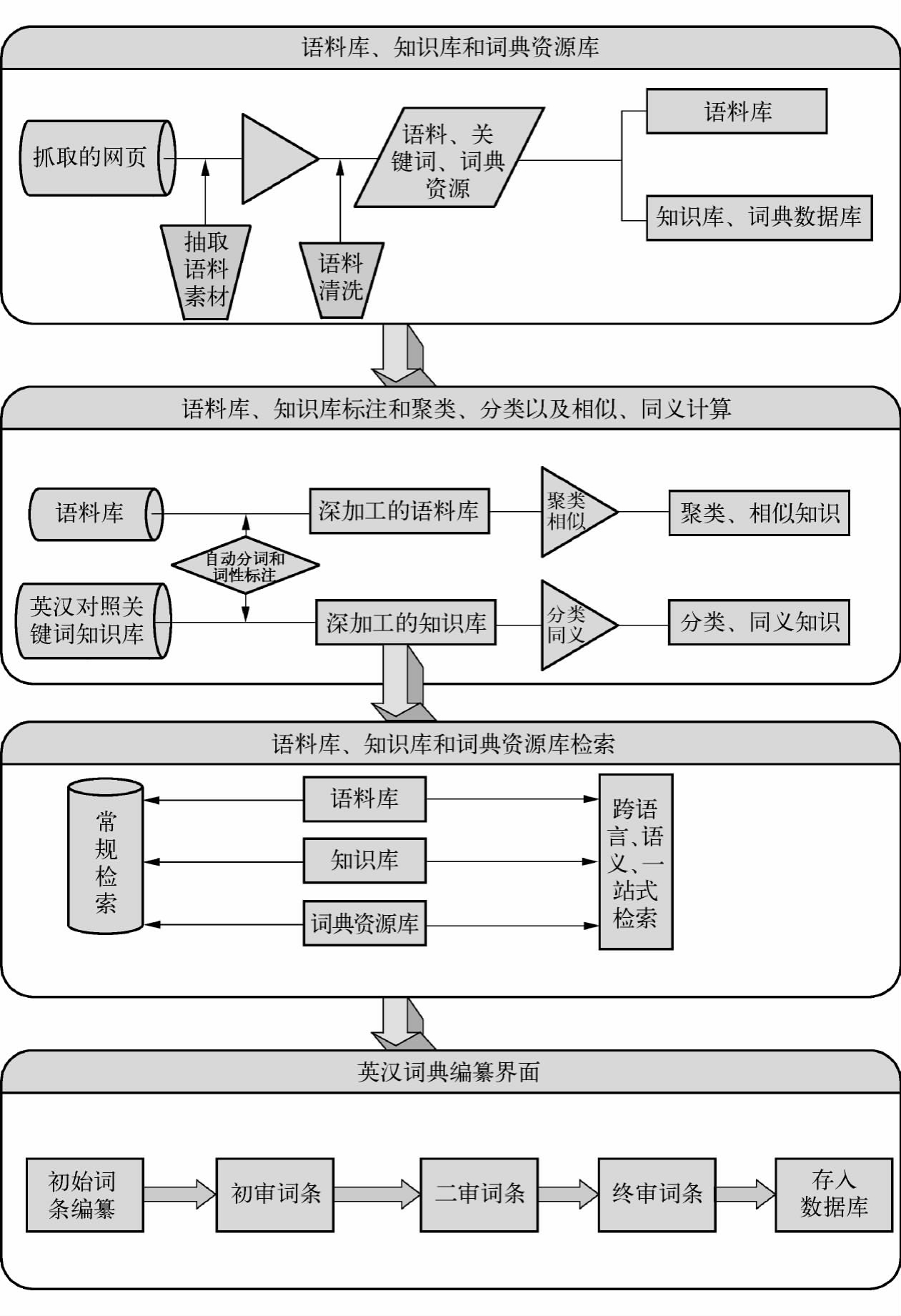
图4-24 “维基”时代英汉双语辞书编纂的设想图
1﹒语料库的构建
基于Web 2.0的网络上拥有海量的语料素材的特点,“维基”时代的双语辞书编纂的语料主要面向网络获取,具体的获取过程如下:
首先,使用网络抓取工具从拥有海量信息的网络上抓取含有汉语单语、英语单语和英汉双语平行语料对的网页。其次,设计抽取程序从抓取网页中提取汉语单语、英语单语和英汉双语语料素材。然后,对获取的汉语单语、英语单语和英汉双语语料进行后续整理,如去重、格式转换等。基本构建汉语单语、英语单语和英汉双语语料库。
2﹒英汉对照关键词知识库的构建和辞书资源的获取
基于学术研究的目的,从大量的学术期刊中提取英汉对照关键词、英汉对照标题、英汉对照摘要等数据,经过合并、去重和编码转化等数据清洗,构建由英语关键词、英语对应汉语关键词、英语关键词语境、英语对应汉语关键词语境、学科领属组成的英汉对照关键词知识库。获取网络上的英语、汉语和英汉双语辞书资源,并按照一定的格式对词目、释义和例句进行整理和加工,构建辞书资源库。整合网络上的英汉双语在线辞书中的资源,从中获取词汇、短语和句子以及段落的知识并通过文本挖掘、自然语言处理的技术来构建英汉双语词典知识库。
3﹒语料库和知识库的自动标注
使用规则和机器学习的方法,开发自动分词和词性标注的软件,对语料库和知识库中的汉语进行自动分词和词性标注,对相应的英语进行自动词性标注。同时使用文本挖掘中的知识自动抽取的方法和技术从各语料库、词典知识库中提取英汉对应知识,如术语对、短语结构对等。
4﹒语料和英汉关键词的自动聚类、分类和相似度计算
把获取的汉语语料、英语语料和英汉平行语料使用文本挖掘中的聚类算法进行聚类,从而初步完成对各种语料的分类。按照学科类别,基于英汉对照关键词知识库,使用支持向量机模型训练出英汉对照关键词分类模型。基于上述的聚类和分类,对于输入的查询内容进行自动分类,从而提高查询词的检索效率。基于中文和英文的有关语义资源,使用各种语义计算方法,计算出语料库中与检索句子在语法、语义和语用上最相似的句子,同时使用各形态下的模式匹配、词面相似度算法,获取检索词汇的同义词,从而向辞书编纂者提供更加丰富和有效的语言知识。
5﹒语料库、知识库和辞书资源库的检索和统计
提供语料库、知识库和辞书资源库的关键词检索、关键词和词性结合检索、例句长度检索、搭配检索、形态变换检索等常规检索。在英汉双语平行语料库和英汉对照关键词知识库的基础上,提供跨语言检索和语义检索,同时基于百科全书(Wiki)的特点,整合所有的语料、知识库和辞书资源库提供一站式互动检索,提高双语词典编纂者获取语言资源的效率。基于文本挖掘和计算词典学的技术和知识,获取词汇的词频、搭配度、互信息、T值(43)、卡方值(44)等常规的统计数据,为词典编纂者确定词条提供一定的参考。
6﹒辞书编纂界面的设计
基于维基百科全书(Wiki)的编纂优势特点,考虑到语料库、知识库和辞书资源库检索的界面交互性比较强的特性,开发互动性强、开放度高的广域网的英汉双语辞书编纂界面。辞书编纂的功能与普通的英汉双语词典编纂界面基本相似,其主要如下:根据不同的权限分配给初始词条编纂者、初审、二审和主编相应的词条。词典各级别的编纂者有权对词条进行修改、增加和删除;初审、二审的词条临时存放在服务器的数据库中,可以被调用和修改,终审词条存储到数据库中,不能被调用和修改。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










