



6.1 因素重构分析方法
6.1.1 理论发展概述
因素重构分析是在系统重构分析基础上提出来的。系统重构分析最初称为“系统重构性分析” ,是美国纽约州立大学G. J. Kilir教授于1976—1980年在一般系统论创始人之一的控制论专家W. R. Ashby教授关于多维关系约束分析研究基础上提出的一种系统结果分析方法。20世纪80年代中后期,美国路易斯安那大学计算机系B. Jones教授提出了分级变量主子状态和用系统性态(行为)函数找出无偏重构的简洁方法。
20世纪80年代末至90年代初,我国学者舒光复提出了带逻辑关系重构的概念与初步理论,并运用于具有定性定量综合的复杂机械产品总体设计优化研究上;同时,进一步发展了B. Jones的方法,并将其与多元回归、多标准决策分析、多目标优化生成等方法相结合,建立了能够进行因素分析、优化、预测与评估的因素重构分析法,并研制了其计算机应用程序GENREC。舒光复与其合作者将其运用于水生生物生态、医药生物技术、建材工艺、社会—经济—环境—生态综合评价、市场策略分析、农作物病虫害预报、生产管理、人材需求预测等多方面,并取得了一定的成效。
舒光复与顾基发等合作者在Klir及Jones等人只包含分等级变量与数值信息的重构分析基础上,发展并建立了多类信息、多类知识混合变量因素重构分析方法,并在此基础上提出了综合集成因素重构分析。
6.1.2 基本原理
因素重构分析提供了一种简单而可行的寻找问题主要因素的方法,它不仅能给出主要因素水平或主要因素水平组,还能对全部因素水平按重要程度进行排序,并且给出重要程度的定量化数值,利用它可以进行综合评价与预测等。
因素重构分析方法通过分别计算各因素水平与指标水平构成的假设系统的性态函数值,将其与原系统性态函数进行比较,反映假设系统与原系统之间的接近程度。接近程度值越小,表示影响程度(相关性或相似性)越大;反之影响程度(相关性或相似性)越小。
对于因素之间存在交互影响的情况可以通过二元(三元或更高元)交互影响重构方法进行因素间的因素分析计算,本书计算过程中已经充分考虑到了这一点。
系统与原始数据系统的性态函数距离Ddh可以用绝对值距离、欧几里得距离、信息熵距离3类常用的数学关系计算。
绝对值距离为
![]()
欧几里得距离为
![]()
信息熵距离为
![]()
其中: fh(m)表示m因素的第h聚集状态的性态函数f值,fd(m)表示m因素的第d聚集状态的性态函数f值; Ω为因素可能组合的集合; Ddh表示为m因素的第h聚集状态和m因素的第d聚集状态的距离。
Ddh=0,表明该指标水平的一切变化均由该系统假设的因素水平决定,该因素水平是唯一因素水平; Ddh越大,因素水平对该指标水平影响越小。因此,假设系统与原始数据系统或总系统的性态函数分布函数间的距离是确定因素水平的重要程度的依据。
通过内插值(0与1之间) 、外插值(0与大于1的任意数之间)和线性或非线性变换可得各因素水平对各指标水平的重要程度值及其排序:
![]()
其中: FL,D为线性或非线性变换; Gf,n(vn)为第n因素的水平; Gc,l(wl)为第l指标的水平。
舒光复在B. Jones关于主子状态分析和其本人关于带逻辑条件重构研究的基础上,提出了综合集成重构分析方法,其原理如图6-1所示。图中左上方表示由各类数据加工后形成的连续变量、离散量、分级量组成的全系统或子系统聚集状态性态函数表。其中,全系统的可直接输入到图6-1中部的总系统聚集状态性态函数表中,而子系统的则经图右下角的子系统—全系统联合运算后输入总系统聚集状态函数表。
当有定性知识或专家经验时,如反映因素与指标间联系关系的定性知识,认识可从图6-1左下方结构信息与知识处输入子系统或全系统结构无向图(反映因果关系的信息输入到逻辑关系输入中) ;反映组元水平(如趋势、分等级关系)间逻辑关系及其他定性关系通过左下方的逻辑关系及定性关系输入处输入系统、全系统聚集状态,其中一部分与子系统、全系统结构无向图输入到子系统、全系统条件C-结构中。数学约束及其他数学关系在左下端输入子系统、全系统聚集状态性态函数表,这里一些子系统的专家经验的预构方案(想定)也可被输入。经子系统—全系统关系联合运算进入总系统聚集状态性态函数表。此处一些总系统的专家预构方案也可输入。得到总系统聚集状态性态函数表后,经重构性态函数分析,把上述输入的全部定性、定量的信息和知识综合为假设系统与原系统性态函数距离这样一个量化指标上。在此基础上可进行重构分析预测、预警、评估(特别是综合评价)优化与决策分析。
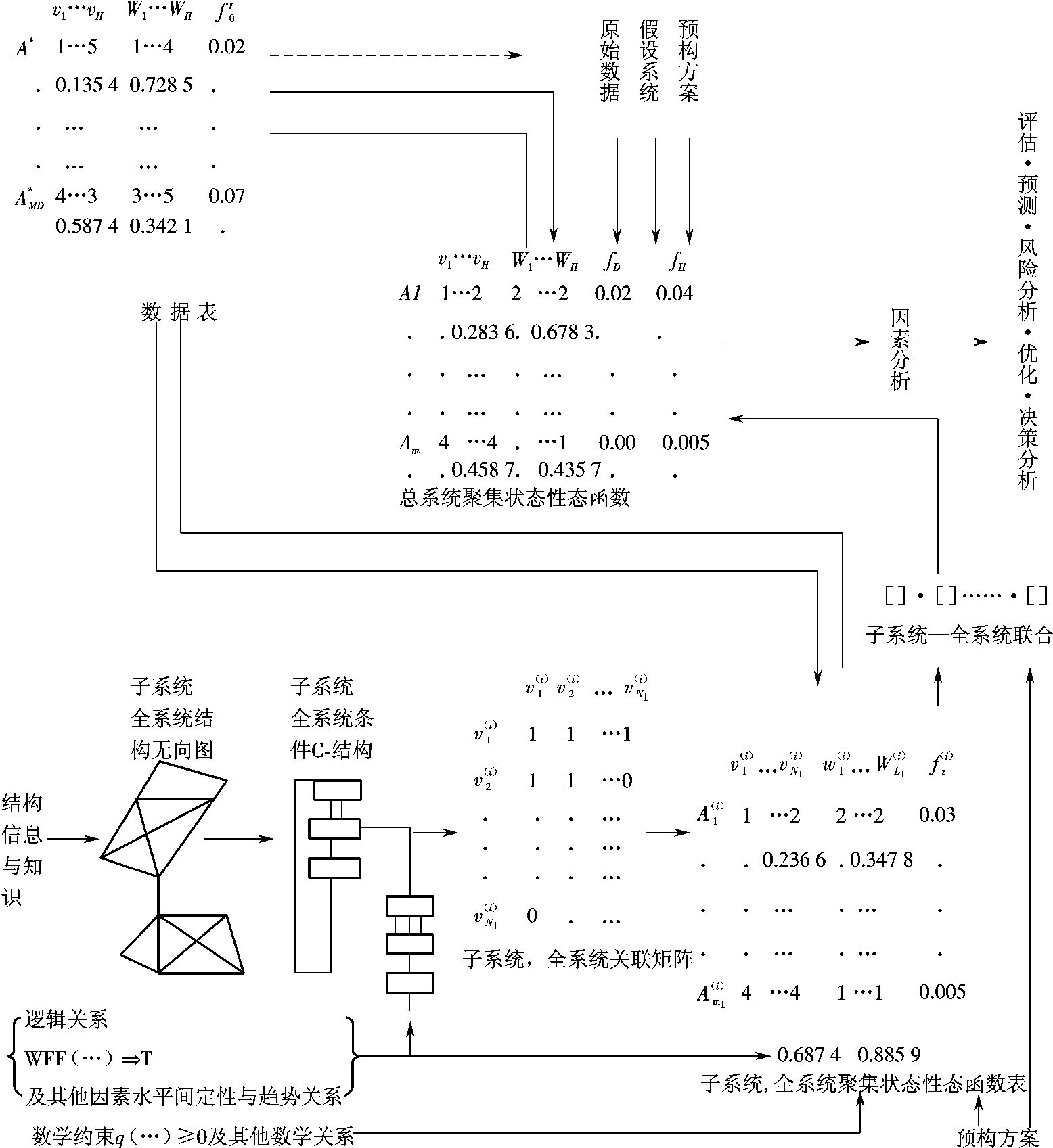
图6-1 定性—定量综合集成重构分析信息流
资料来源:舒光复,宏观经济与有关社会发展开放复杂巨系统及其综合集成研究,系统辩证学学报,2001,9(4)
因素重构分析的特点是在小样本下进行预测或者对系统进行评价。它与用一般的统计方法(需在大样本条件下进行预测或评价)相比,具有优越性。同时,因素重构能得到各因素之间影响的重要程度,另外,重构分析是在高、中、低3个水平下来考虑因素之间的接近程度,使预测结果或者评价结果表现为区间上的预测值或评价值。
6.1.3 适用性分析
因素重构分析方法目前被广泛应用于各个领域:人才发展规划中的人才增长率、人才质量、人才结构比例的预测;宏观经济问题的研究;资产管理的优化及评估;石油的选区及影响石油消费的社会因素;生物试验;水泥生产;心脏病的分类研究中的应用等。
因素重构分析中的因素分析解决了各因素、指标之间的逻辑与数学关系的复杂性问题,这是其他数学模型、经济研究方法难以实现的。与其他优化方法相比,它具有以下特点。
(1)不需要十分准确的数据。只需对因素和指标分出等级的高低、好坏就可以进行分析计算,因此适用于数量关系不十分确定的复杂系统的评价和预测问题。
(2)不需要大量的历史数据,也不需要按严格规定的方案进行试验,可以根据现有掌握的或预构的方案进行计算。对于包含几十个因素或几十个指标的复杂系统,只要选择5至6种,甚至4至5种不同因素水平组合的聚集状态就可以进行重构分析计算。
(3)计算简便迅速。只要把聚集状态性态函数表有关数据按应用程序使用说明的要求输入即可算出结果,并可以显示或打印少量最重要的因素水平,也可以按指标、因素水平的编号输出等。
因素重构分析方法在我国最近又有了新的发展,我国系统科学工作者提出了混合变量系统重构分析方法。该方法既可以把不准确的分等级数据输入到程序中,也可以把多种不同具体准确值的实验数据输入到程序中进行计算,从而可进一步充分利用数据信息获得更好的结果。
该方法在计算软件上也有了进一步改进。研究人员可以把实验数据直接输入到数据库中,进行自动等级划分并直接在屏幕或计算结果文件中看到因素分析结果与优化结果。如此实验人员可以非常方便、迅速地得到实验数据的因素分析与优化结果,免去了较烦琐的分等级、从因素分析结果中找最优解等大量人工计算工作,也更易于掌握方法的应用。
企业安全文化评价在国内尚处于探索阶段,缺少相应的历史数据和资料,本书构建的安全文化和安全氛围指标体系具有定性指标和定量指标相结合的特点,并且很多定性指标的量化数据依靠调研人员采用现场观察、访谈等方法获取,因而具有一定的不确定性和模糊性,因素重构法的特点和功能可以帮助研究人员在上述条件下对企业安全文化进行合理科学的评估,以期达到理想的评估结果。
综上分析,因素重构分析方法的适用条件和优势与企业安全文化评价的需求具有良好的契合性,因此,利用因素重构方法对企业安全文化和企业安全氛围进行评价具有很好的适用性。
6.1.4 基本算法与步骤
(1)按照每个指标在各评估样本上的取值分别确定三个水平值,使得所有样本取值均匀分布在由这三个水平值确定的两个区间内。
(2)根据确定的区间和水平值分别计算样本空间中的各指标与各水平值的接近程度:
![]()
其中,Φk,i为第T个样本中第k个指标与max Φk,i的接近程度,而与min Φk,i的接近程度为1- Φk,i,i代表第i个区间(i =1,2) ,Φk(T)为第T个样本中第k个指标的具体数值,max Φk,i为Φk(T)所在区间的上界,min Φk,i为Φk(T)所在区间的下界。
(3)根据各水平值及其与各指标接近程度值确定聚集状态性态函数表。
(4)将聚集状态性态函数表中的数据输入GENREC重构分析软件的文件中,运行软件。
(5)根据软件的输出结果,计算指标水平的聚集状态重要程度的最大值和最小值:
![]()
![]()
其中,edc*=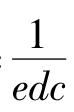 ,edc称为假设系统的性态函数与原系统的性态函数的信息熵距离,Ln为水平标号,Ωfn称为n个指标的全部水平标号集合,K为样本空间个数,Lk为指标的标号,n为指标个数,l(l =1,2,3)表示水平情况。
,edc称为假设系统的性态函数与原系统的性态函数的信息熵距离,Ln为水平标号,Ωfn称为n个指标的全部水平标号集合,K为样本空间个数,Lk为指标的标号,n为指标个数,l(l =1,2,3)表示水平情况。
(6)计算拟评估样本对各指标水平的聚集状态重要程度和值:
![]()
其中,fl表示评估样本在l(l = 1,2,3)水平情况中对各指标的聚集状态重要程度和值,K表示一共选择了K个样本作为参考,Lk(t)为评价样本的指标标号,n表示在每一个样本中均选择了n个指标作为参考,Ln(t)为评价样本的水平标号。
(7)计算各评价水平值在拟评估样本中的呈现程度:
![]()
(8)计算拟评价样本的最终评价结果。
①评价为低水平时,可选用公式:
![]()
其中,W为样本的评价值,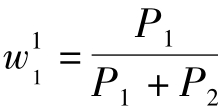 为E0的权重值,
为E0的权重值,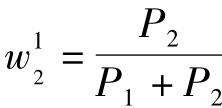 为E1的权重值,E0为低水平的下界,E1为中水平的中值,即(中水平下界+中水平上界) /2。
为E1的权重值,E0为低水平的下界,E1为中水平的中值,即(中水平下界+中水平上界) /2。
②评价为中水平时,可选用公式:
![]()
其中,E2为高水平上界值,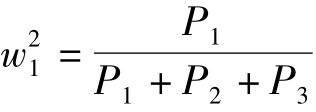 为E0的权重值
为E0的权重值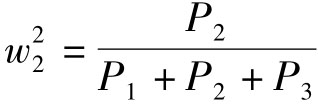 为E1的权重值,
为E1的权重值,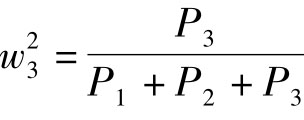 为E2的权重值。
为E2的权重值。
③评价为高水平时,可选用公式:
![]()
其中,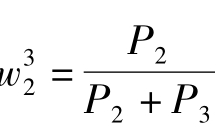 为E1的权重值,
为E1的权重值,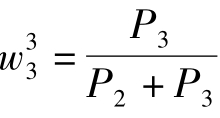 为E2的权重值。
为E2的权重值。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











