



本体应用环境研究[1]
董 慧 姜 赢 王 菲
周义刚 俞思伟 徐国虎
(武汉大学信息资源研究中心)
【摘 要】 语义Web的框架已经提出若干年了,但是目前业界仍然缺乏能够走向实用的语义Web典型应用(Killing Application)。本文在分析其中原因的同时,从实用的角度提出了本体应用环境的概念与框架。本体应用环境以本体技术为核心,以知识管理为目标,较好地解决了各领域知识管理中的各种问题:知识组织、知识检索、知识管理、知识推理等。本体应用环境由三部分组成,即后台环境(数据源、知识库与规则库、半自动建库工具、本体推理)、前台环境(检索可视化、检索策略、领域分析器)和网络环境,本文重点论述本体分子理论、基于语义关系的本体推理、基于本体分子的动态知识检索机制以及本体应用环境的应用。它的成功应用为语义Web的前景和发展提供了一种可行的思路。
【关键词】 本体 本体分子 本体推理 检索机制 应用环境
Ontology Application Environment
Dong Hui Jing Ying Wang Fei Zhou Yigang Yu Siwei Xu Guohu
(Research Center of Information Resource,Wuhan University)
【Abstract】 The framework of Semantic Web has been presented for years,but there're now few killer applications in industry.This paper analyses the reasons and advancesa theory as well as a framework named Ontology Application Environment(OAE)from the aspect of real applications.Aiming at knowledge management,OAE makes ontology as the key technology.It resolves such knowledge management problems in many application domains as knowledge organization,knowledge retrieval,knowledge inference,etc.OAE is composed of three parts:back-stage environment,front-stage environment and web environment.This article would focuses om Ontology Molecule theory,ontology reasoning based on semantic relationship,dynamic knowledge retrieval mechanism based on Ontology Molecule and application of OAE,which provides a feasible approach for the development and the future of Semantic Web.
【Keywords】 ontology ontology elements ontology Reasoning Retrieval mechanism Application Environment
本体论是一哲学概念,用于描述事物的本质,在知识工程及其相关的应用领域获得广泛的关注。许多学科和研究领域都在使用“本体”这个术语,但存在不同的定义。我们认为,本体是对客观世界全部或某一部分的概念化和结构化的抽象[1]。概念化是对世界的一些抽象且简明化的观点。概念化对象是领域知识,包括概念的静态状态及其动态运动过程等知识。一个概念化对象可由部分表示领域,该领域中相关事物状态的集合和领域空间上的概念关系。在概念关系中有一个相当重要的子集——概念间的语义关系,它包括同义词关系、上下位关系和属性关系等。其中同义词关系表达了在相似数据源的一种等价关系,是一种对称关系;上下位关系是偏序关系,是一种不对称关系,具有转递性;属性关系表示一类事物包含于另一类事物。各个概念间复杂的语义关系构成了语义网络图概念。结构化是指系统内各个组成要素之间的相互联系、相互作用的框架。
随着语义网的发展,作为其核心技术的本体及其推理越来越受到专家学者的重视,在不同领域的应用越来越广泛。
1 本体应用环境框架
1.1 研究背景
语义Web的概念由提姆·伯纳丝·李(Tim Berners-Lee)在1998年首次提出[2]。在他看来,“语义网(Semantic Web)并非是另外一个独立的Web,而是现在的Web的一个延伸。2000年秋,国际万维网联盟W3C在美国波士顿召开年会,W3C总裁Tim Berners-Lee宣布语义网是W3C的三大研究主题之一[3]。随后W3C制定了语义Web体系结构标准,它是一个层次结构(Layer Cake),如图1所示,自底向上主要包括:
①URI/IRI:国际编码提供世界各种语言和符号的编码库,统一资源标识保证网上资源的唯一。这两个不仅仅是语义Web,而且已经是当前Web实现的技术保证。
②XML:XML Schema解决数据类型和定义数据结构的问题(Datatype and structure)。
③RDF/RDFS:RDF利用三元组的方式定义和描述网络资源和元数据。RDFS在RDF基础之上为RDF提供基本词表,它是一种原始的本体定义框架。
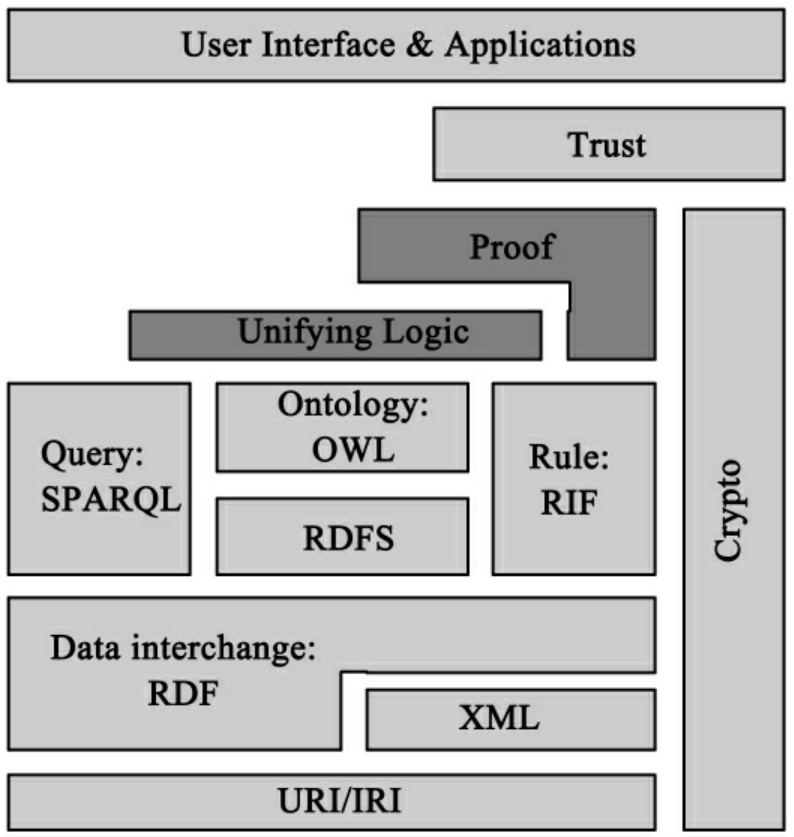
图1 语义Web框架
④OWL,Ontology:OWL以描述逻辑作为数学逻辑基础,并在RDFS基础上,提供更加强大复杂的基本词表,比如关于类、属性、关系的约束[4]。
⑤Unifying Logic:提供逻辑推理。即对于没有显式定义的知识进行推理。
⑥Proof:提供逻辑验证。它跟踪逻辑推理过程,对逻辑推理结果的正确性进行验证。
⑦Trust,Digital Signature:对下层所有的内容进行数字签名,使得用户信任语义Web处理的结果和质量。
⑧User Interface:应用级别的用户接口,或者与领域相关的应用程序。
1999年,W3C的研究小组提出了RDF(Resource Description Framework,资源描述框架)标准草案[5]。2001年,W3C又开始着手制定OWL(OWL Web Ontology Language)标准。2004年2月10日,W3C万维网联盟发布了RDF推荐标准和OWL推荐标准[6]。本体和语义Web的关系可以描述为:本体是语义Web体系结构中的一个层,语义Web利用本体解决Ontology层的语义问题。通常我们所说的本体层指的是OWL层,而OWL和RDF/RDFS都能在一定程度上表达语义,所以也可以说RDF和RDFS属于本体层。
语义Web的框架已经提出若干年了,但是目前其他领域却鲜有基于语义Web的典型应用[7]。大部分应用都是系统模型,很少投入实际的商业应用。例如Foaf这类模型能让人们感觉语义Web的新鲜,但是真正的语义Web离我们还比较遥远[8]。我们认为,语义Web框架在实际应用中存在一些问题:
①语义Web框架是一个理论模型,它趋于完善,但是侧重在理论框架结构而不是应用。
②语义Web框架中有一些层次很少在实际中用到,例如proof层和trust层应用范围太窄,不利于语义Web框架的实际应用。
③语义Web框架侧重于对现有Web的扩展,而对于知识管理这类实际应用前景广泛而非Web应用的内容则涉及较少。
④语义Web框架对于知识抽取、知识可视化、动态知识管理等实际问题没有提出相应的解决方案。
为此,我们提出本体应用环境的理论与框架,并在数字图书馆和数字档案馆等领域得到了应用,实践证明,本体应用环境的理论与框架具有可行性、可操作性和科学性。
本体应用环境以本体技术为核心,以知识管理为目标,较好地解决了各领域知识管理中的各种问题:知识组织、知识检索、知识管理、知识推理等。
1.2 框架结构
图2所描述的本体应用环境不是单向的层次结构,而是一个分为前台和后台用户的应用环境。后台环境为后台管理员提供本体库等的建立、维护工作。前台环境为用户提供检索策略和手段以及可视化显示;为实现多领域知识检索,提供了领域知识分析器。
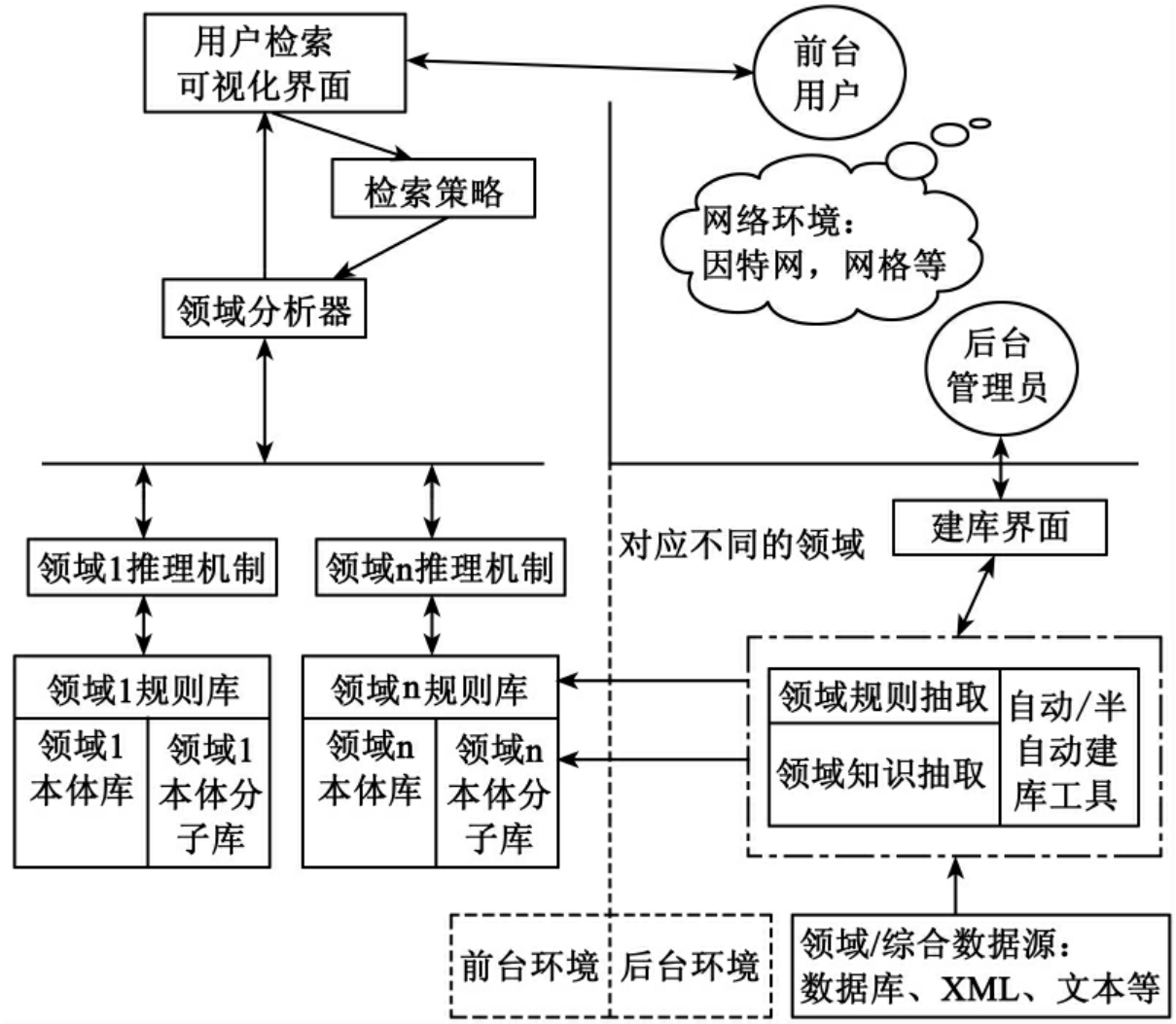
图2 本体应用环境框架
1.3 后台环境
后台环境是为管理员提供本体库的建立和维护、领域规则库的建立和维护、领域知识抽取等功能。采取Protégé开发组件作为各功能模块的插件[9]。
1.3.1 数据源
本体应用环境支持的数据源可以是:自由文本、XML、数据库、TIFF图片、PDF文档、Word文、Web网页等。
1.3.2 知识库与规则库
为了解决动态知识的管理和控制,提出了本体分子理论,本体分子指的是在本体基本元素(本体实例、三元组)基础之上,用唯一标识符标注,根据语义或者语用划分,无缺失、最小冗余的本体知识单元。本体分子是在本体基本元素和本体库之间的一个平衡点,它使得动态知识管理成为可能。一个本体分子由两个部分组成:核子和离子。本体分子通过核子来描述不变部分,通过离子来描述可变部分,能够较好地展现领域中的动态知识的演化过程和演化结果。一个本体分子可以没有离子,但是必须有且仅有一个核子。
规则库是存储本体推理规则的空间,推理规则是针对特定领域而制定的描述领域隐性知识的规则。在本体应用环境中,用Jena自定义推理规则实现。
1.3.3 半自动建库工具
我们开发的基于XML模式匹配的中文本体半自动构建系统——OntoLTCn[10],是本体应用环境中进行领域知识工具抽取的工具[11]。
OntoLTCn运用了中文词法分析技术,针对中文语言特点,利用统计学的方法,建立了适合中文文本的XML模式匹配规则。插件分为三个逻辑层:数据预处理层、本体抽取层和领域专家人工干预层。下层的处理步骤要依赖上层的处理结果,半自动建库过程由上层向下层依次进行[12]。
1.4 前台环境
前台环境是为用户提供服务的窗口。设计的环境符合J2EE标准的MVC体系结构,以及B/S模式的Web开发符合W3C制定的Web设计标准。用户能在前台环境下通过友好的界面方便快捷地进行知识检索。[13]
1.4.1 检索可视化
检索可视化,使用户操作更加直观、便捷。
我们采用了Touchgraph的TG图形组件[14]。它能显示大量数据所需要的技术:缩放(Zoom)与摇动(Pan),焦点/背景(Focus/Context)及递增性导航(Increamental Navigation)等。
本体分子可视化的目标是提供领域动态知识演变过程的可视化,采用Prefuse API[15]。
为解决不同对象的转换问题,可视化模型在Prefuse的基础上添加了数据对象映射层,负责本体和本体分子对象与Prefuse数据对象的互相映射转换。数据模型层沿用Prefuse本身的内容。抽象可视化数据模型层进行了二次开发,加入了具有本系统特色的颜色、字体、动画等抽象数据类。
1.4.2 检索策略
检索策略是检索步骤的科学安排(retrieval strategy)。它是为实现检索目标而制订的全盘计划或方案,指导整个检索过程。本体应用环境在前台环境中提供多种检索途径,前台用户可以从中选择合适的检索策略进行检索。
1.4.3 领域分析器
本体一般解决的是某个领域问题,它通过描述领域内部知识来进行知识组织和知识检索。然而用户在使用基于本体的检索系统时,往往并不知道自己要检索的内容属于哪个领域,或者是跨领域知识。对于这些问题,本体应用环境提出了领域分析器解决的方案。
领域分析器的实现可以分为几个级别层次:
①初级阶段:系统提供一个领域列表,用户可以根据自己的理解选择特定的一个或若干个领域进行检索,检索的结果是这些领域结果的并集。
②中级阶段:系统后台有一个领域词表,它是领域和领域叙词的映射表。用户输入的关键词通过这个词表进行匹配,找到相应的领域之后,领域分析器再把检索请求分发到这个领域进行检索。
③高级阶段:系统后台有一个语义智能分析器,可以根据用户输入判断它所在的领域,甚至多个领域,然后把请求发送到这些领域进行分别检索,最后将检索结果返回给前台用户。
领域分析器的实现层次可以根据应用的需要进行选择,或者采取逐步实现的方式。
1.4.4 本体推理
推理是按某种策略由已知判断推出另一种判断的过程。运用本体展现领域知识中所蕴涵的大量事实和复杂关系,需要对本体库进行维护、更新、检测和知识发现,本体知识推理就是一个十分重要的技术手段。
本体推理主要包括基于描述逻辑的推理和基于规则的推理。
我们采用了基于TABLEAU和RETE算法的推理机制。其主要功能有:本体推理引擎、本体逻辑检测分析器、本体推理路径回溯分析器。
1.5 网络环境
网络环境是整个本体应用环境所需的网络基础条件,还包括用户和管理员在本体应用环境下进行实际操作的条件。
本体应用环境所支持的网络环境可以是Internet、局域网甚至网格环境。
2 本体分子理论
本体分子理论由六部分组成:本体分子定义和特征、本体分子形式化描述、本体分子结构、本体分子抽象概念、本体分子库构建和本体分子动态演化等。
2.1 本体分子定义和特征
2.1.1 本体分子的定义
物理分子认为:物质是由大量分子组成的。在这里我们所说的分子与化学中分子的含义是不完全相同的,物理分子把构成物体的分子、原子、离子等统称为分子。
原子的中心是一个微小的由核子(中子和质子)组成的原子核,占据了整个原子绝大部分的质量。离子是原子团或原子由于得失电子而形成的带电微粒。
原子核有聚合与裂变的特性。核聚变是两个轻核聚合成一个较重的核,而核裂变是一个重核分裂成两个较轻的核。
在处理动态知识组织和管理问题的时候,本体属性的变化与物理分子的特性非常类似,本体属性也有不变和可变的特性,不变的特性正如物理分子的原子核,原子核发生了变化,其物质本质特性也就发生了变化;同样,本体的根本属性发生变化了,原来的本体也就不复存在了。在动态知识演变过程中,往往会产生知识的突变,即由原来的知识演变成新的知识,原来的知识仍然存在,这就与核的裂变非常类似;同样,不同的知识通过演变也可能合成新的知识,这就类似核的聚合,本体分子概念正是由此而产生的。
所谓本体分子是指在本体基本元素(三元组、本体实例)基础之上,用唯一标识符标注,根据语用或者语义划分的、无缺失的、最小冗余的本体知识单元。本体分子是在本体基本元素和本体库之间的一个平衡点,它使得相对粗粒度知识管理成为可能。本体分子是动态知识及相对知识组织的一种工具,本体演化可以追踪本体分子的变化过程及其结果。
2.1.2 本体分子的特征
本体分子的特征主要有四点:
其一,本体分子是建立RDF/OWL之上的,并不能脱离现有主流的RDF/OWL本体而单独存在;其二,本体分子在划分知识单元的时候,既要保证无语义上的缺失,又要使得知识冗余最小化;其三,本体分子划分的依据是语用或者语义;其四,用唯一的标识符号来标识本体分子,是为了让本体分子在本体整合和本体推理等本体操作中有操作的标识或句柄。
2.1.3 本体分子与本体的关系
关于本体的概念,我们在前文中已经做过详细的阐述,这里只是简要地回顾一下。本体(ontology)是哲学中的一个概念,近年来越来越多地应用于数字资源的描述、组织与管理。人工智能领域经常引用Gruber在1993年的定义“概念体系的规范”(specification of conceptualization),1998年Studer等人在这个定义的基础上对本体的特点给出了一个较为明确的解释:“本体是对概念体系的明确的、形式化、可共享的规范说明。”我们认为:本体是对客观世界全部或某一部分的概念化和结构化的抽象。
本体从信息客体或信息对象出发,通过建立信息客体之间的概念联系和等级关系,将对信息客体的揭示深入到知识内涵的层次并实现对信息客体内在联系的推理。它的主要特点有:①本体赋予数据以含义(语义描述的基础);②本体使实体关系定义显性化;③本体使计算机能理解和处理语义。
本体在知识组织方面确实有一定的优势,它能更规范、更准确地描述概念含义以及概念之间的内在关联,可以构造丰富的概念间语义关系,形式化能力也很强,同时具有高度的知识推理能力,可以通过逻辑推理获取概念间的蕴含关系,很好地解决知识检索中的查全率和查准率问题及知识的共享和复用等问题。但是仅仅局限于解决绝对知识和静态知识组织的问题,而对于相对知识和动态知识,本体没办法通过描述逻辑进行直接描述,这对于本体在动态知识丰富的领域应用造成了障碍。
本体分子是在本体的基础之上,结合描述逻辑、图论等相关理论,用于解决动态知识及相对知识组织管理和控制的理论。本体分子不能脱离本体单独存在,本体分子只是本体理论的扩展与深化。
2.2 本体分子形式化描述
在W3C联盟制定的RDF抽象语义标准中,定义了U、B、L三个集合,其中定义U为本体库中所有的URI本体节点(URI reference)的集合,定义B为本体库中所有空白本体节点(RDF Blank Node)的集合,定义L为本体库中所有RDF文本(RDF Literal)的集合。并且U、B、L两两不相交。
定义V为U、B、L的并集:V=U∪B∪L
定义T=(U∪B)×U×V为RDF三元组(RDF Triple)的集合,RDF三元组t∈T。定义T的幂集G为RDF图(RDF Graph)的集合。
根据上述描述和我们对本体分子的定义,将本体分子形式描述如下:
本体分子核子c为:c=func_c(id_c,g_c),id_c∈U,g_c∈G
其中id_c为本体分子核子c的唯一标识符,g_c表示本体分子核子的范围,func_c是id_c和g_c的映射函数。
根据本体分子核子的定义,getId_c(c)=id_c,getGraph_c(id_c)=g_c分别表示本体分子核子标识符与本体分子核子范围的映射函数。
定义I_c为本体分子核子集合C的解释,任何一个本体分子核子c∈C,getId_c(c)都应该在解释I_c的词表中,而且满足:I_c(getId_c(c))=c
同理:
本体分子中一个离子o为:o=func_o(id_o,g_o),id_o∈U,g_o∈G
其中id_o为本体分子一个离子o的唯一标识符,g_o表示本体分子一个离子的范围,func_o是id_o和g_o的映射函数。
根据本体分子一个离子的定义,getId_o(o)=id_o,getGraph_o(id_o)=g_o分别表示本体分子一个离子标识符与本体分子一个离子范围的映射函数。
定义I_o为本体分子离子集合0的解释,任何一个本体分子离子o∈0,getId_o(o)都应该在解释I_o的词表中,而且满足:I_o(getId_o(o))=o
故:
本体分子m为:m=func_m(id_m,{c,0}),id_m∈U,c∈C,o∈0
本体分子理论对动态知识的形式化描述[2]:
由于本体库结构的局限性,无法描述动态知识变化的过程,将本体分子概念引入后,本体库扩展部分可以存放不同时间点上的知识,我们将时间连接起来作X轴,将变化的知识作Y轴,于是,构造了一个时间与知识的二维平面空间,即构成了本体分子的演化。其本体分子演化(evolution)的形式描述如下:
me=func_me(id_a,t), id_a∈A t∈T
其中id_a为该本体分子中变化的关键属性在时间t的值。
通过本体分子演化对动态知识变化过程的形式描述,我们可以看到,任何动态知识的演变都可用X、Y轴构成的二维空间来描述。大量信息构成的二维空间,所描述的曲线就是该动态知识变化的规律,若其核变了且曲线也变了,说明原来的知识已演变成另外全新的知识,或是与其他知识交叉的新知识。
2.3 本体分子的结构
本体分子的基本模型是进行本体分子的划分和本体演化的依据,而要解决本体分子的基本模型问题就要弄清楚本体分子的结构。
一个本体分子由两个部分组成,即核子和离子。本体分子通过核子来描述知识的不变部分,通过离子来描述知识的可变部分,这种描述能够较好地展现领域中动态知识的演化结果和演化过程。一个本体分子可以没有离子,但是必须有且仅有一个核子。
本体分子的核有如下几个特点:
首先,核子是本体分子中不可变的属性集合。其次,核子是反映本体所描述的客观世界的全部或某一部分结构化和概念化的真实含义。再次,当核子剧烈运动时,它可裂变为两个或多个分子;当核子很小时,可将多个分子聚合为一个分子。最后,核子是本体分子的一个重要组成部分,当本体描述静态知识时,核子就是本体唯一的组成部分。
如图3所示,本体分子是三元组集合,它包括不可变部分——“核子”,也就是图中的灰色部分,还包括可变部分——“离子”,也就是图中的黄色部分。图中有两个本体分子,它们拥有相同的“核子”,而“离子”不同,属于“同核”的本体分子,可以在“同核”本体分子组之间进行本体分子演化。
图3上面部分将一个三元组的主语扩展成一个本体分子,这个是为了解决知识的多粒度控制问题。本体分子结构的计算机实现可以采取“合成模式”设计,能够达到递归组合的效果,从而能够表达嵌套语义的多粒度知识。
2.4 本体分子中基本的抽象概念
在本体分子中定义了一系列基本的抽象概念,用来反映本体分子的基本数据结构,它们是维度(Dimension)、维度容器(DimesionContainer)、本体分子的核(CoreGraph)、本体分子的外围(OuterGraph)、本体分子(OntologyMolecule)和本体分子图(Dgraph)。这些概念间的关系如图4所示。
本体分子中的维度(Dimension)是在知识本质不发生变化的前提下,用来衡量知识内容随之变化的角度。这些不同的角度分别对应于不同的维度类,每种维度类可以进一步定义它所包含的具体的维度。维度可以是时间、地点,也可以是某个泛化的维度,如机构维、人物维。维度是本体分子理论中衡量知识是否为真的基本手段,是表达知识成立条件的基本工具。只有当查询条件中的维度存在于修饰语句的维度之内时,语句才为真。
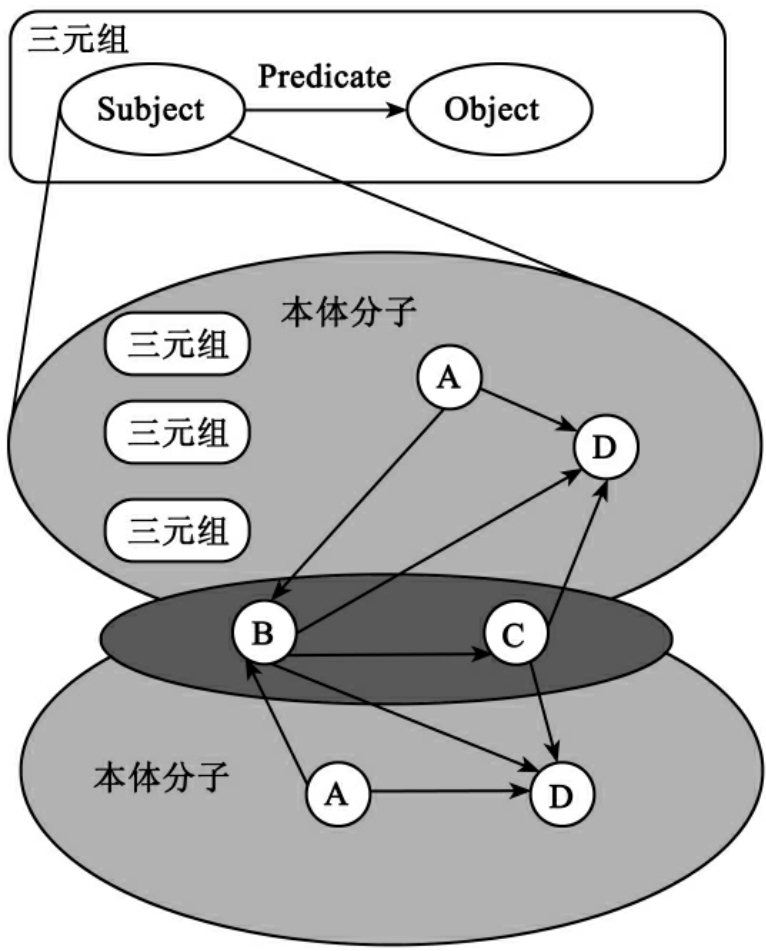
图3 本体分子结构示意图
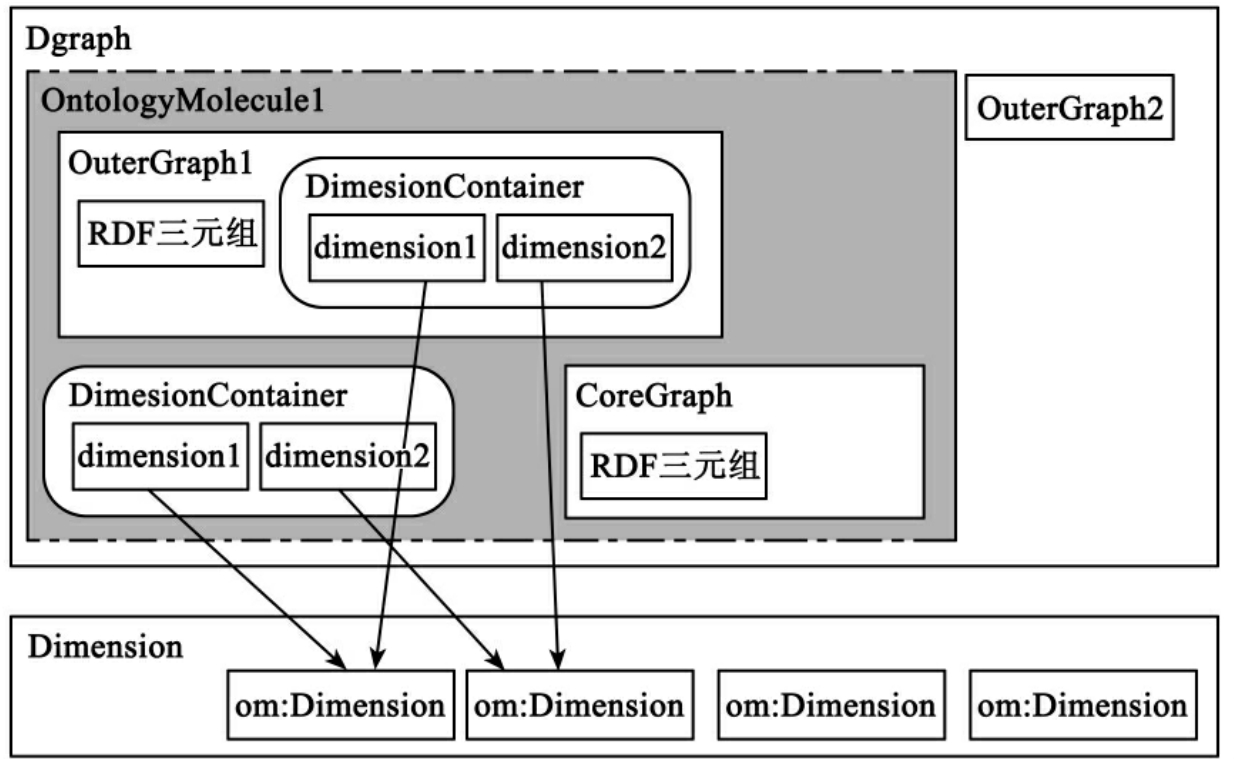
图4 本体分子中的基本概念的关系图
若干个从属于不同维度类的维度组成一个维度容器(DimesionContainer)。本体分子中的维度容器是管理维度的对象。维度并不直接与本体分子、本体分子的核或本体分子的外围发生关联,而是通过维度容器与本体分子中的其他对象发生联系。这种设计的原因是因为通常某个动态知识成立的条件是处在一个多维环境下的。比如某个事实是成立于特定的时间段和特定的地理范围。维度容器中可能存在一个或多个维度,也可能不存在任何维度。在验证知识的正确性时,需要逐个验证维度容器中的维度。以维度容器形式描绘的具体约束条件与RDF三元组结合,形成的动态三元组就是本体分子知识的最小单元。动态三元组表示RDF三元组在特定维度容器下为“真”这样的陈述。
本体分子的核(CoreGraph)是本体分子中的静态知识部分,本体分子核中的知识存在于默认维度容器下或存在某个特殊定义的维度容器下。定义在该维度容器下的知识在任何条件、任何维度下都为真,为静态知识。
本体分子的外围(OuterGraph)是本体分子中的动态知识或相对知识部分。本体分子外围中的知识成立于某个或某些特定的条件下。与本体分子的外围关联的维度对这个条件或多个条件进行限定。本体分子的外围和本体分子的核之间为函数对应关系。单个本体分子的外围只可能与某一个本体分子的核发生关联,但一个本体分子的核可能与多个本体分子的外围相关联。
一个本体分子由一个本体分子的核和一个本体分子的外围组成。图4中本体分子的核(CoreGraph)与其中一个本体分子的外围(OuterGraph1)组成一个本体分子(OntologyMolecule 1),图5中,还是这个本体分子的核(CoreGraph)与另外一个本体分子的外围(OuterGraph 2)组成另一个新的本体分子(OntologyMolecule 2),这两个不同的本体分子都与同一个本体分子的核相关联,都有自己的维度容器。
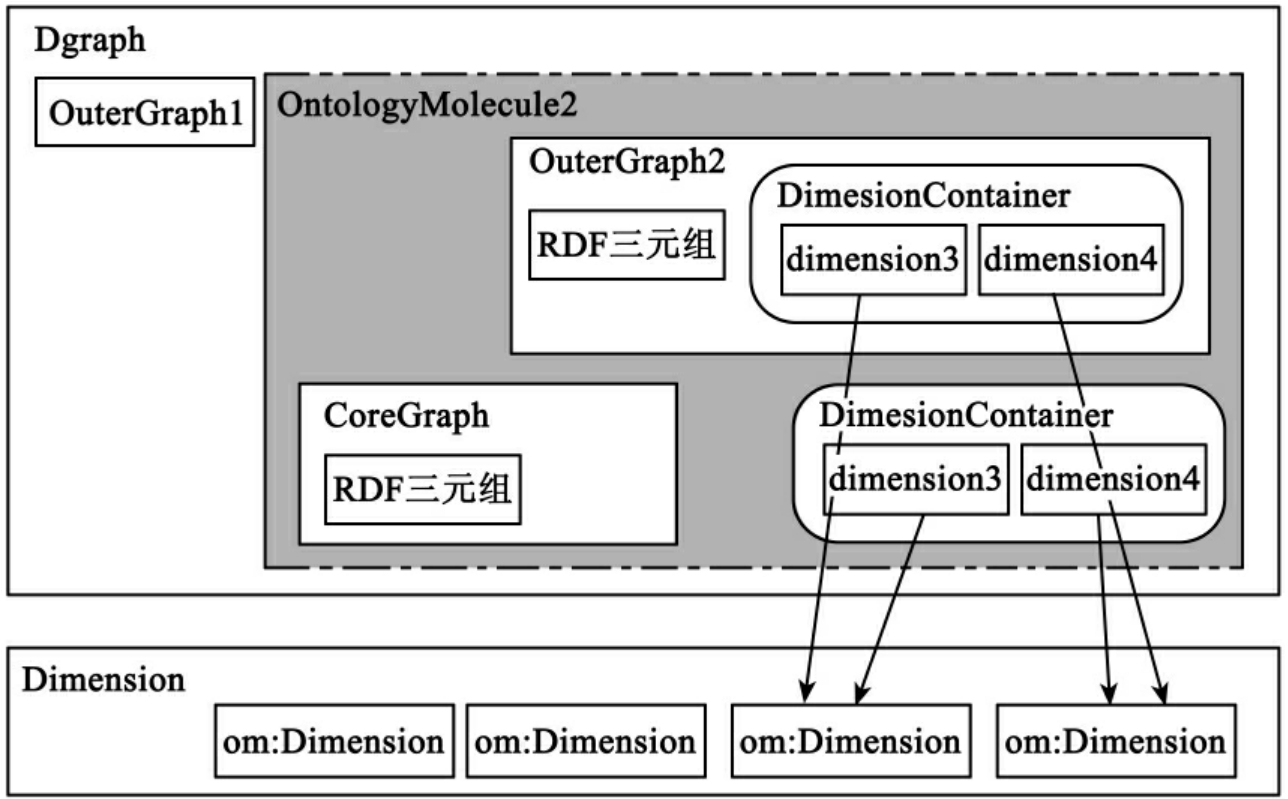
图5 本体分子中的基本概念的关系图
在实际中一个核子可能有多个外围,该核子和每个外围都形成了一个本体分子,一个核子和若干个外围组成了本体分子图(Dgraph)。本体分子图存在于某个特定的维度下,也拥有自己的维度容器。本体分子图的维度取决于本体分子的外围的维度。
2.5 本体分子库构建
2.5.1 本体分子库结构
本体库指的是按照W3C语义网标准规范,使用RDF/OWL这样的本体描述语言建立起来的知识库。本体分子是建立在本体基础之上的,所以本体分子库也是在本体库的基础之上进行的扩展。这种扩展主要体现在动态知识上。因此,本体分子库中往往包含本体库中所有关于静态三元组的内容。另外,本体分子库还包含本体库中无法表示的动态知识,这些动态知识主要是:动态三元组、三元组标识符、三元组维度。一个本体库是一个合法的本体分子库,它可以看作是只包含静态知识的本体分子库。而其中的动态知识虽然省缺为空,但它是合法的。
如图6所示,本体分子库结构分为两个部分,I区域表示的是本体静态知识集合,II区域表示的是本体分子动态知识集合。I区域中主要是基于RDF/OWL的静态三元组,它与普通的本体库一样,往往是一个静态的知识网络。I区域中有一个三元组Triple1,它在II区域中有对应的三元组Id(用菱形表示)。通过这个Id可以将这个三元组添加到本体分子中,使它成为一个动态三元组。例如II区域中有一个本体分子,它的核子是C(用圆形表示),它包含三个离子01、02、03(用圆角矩形表示)。根据领域知识的需要,可以将Id与这个本体分子的核子或离子进行关联,使之具有动态知识的含义。例如,如果Triple1是静态不变的知识,可以把它与核子C进行关联;如果Triple1只能在01这个环境下合法,那么可以把它与01进行关联。
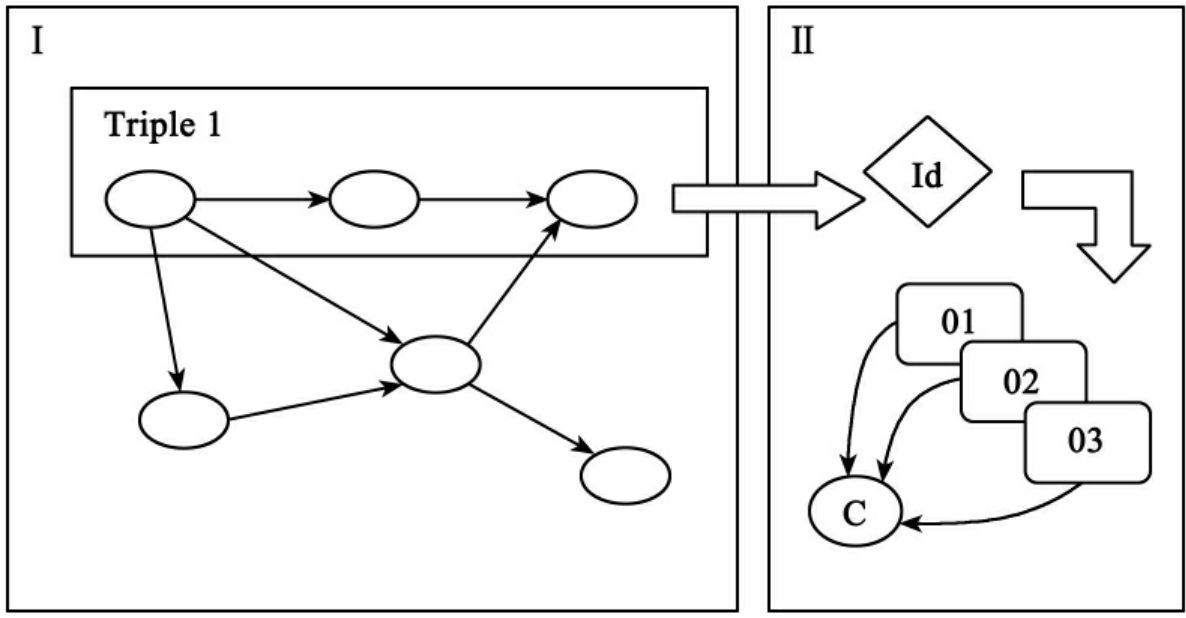
图6 本体分子库结构示意图
2.5.2 本体分子建库工具
本体库的构建有一批IDE工具支持,如Protégé、NeOn、KAON2、Altova Semantic Works等。这些工具大大减轻了手工本体建库的工作难度,使得本体建库成为一般领域专家能够胜任的工作。这些工具中有一些是商业软件,如Altova Semantic Works等,还有一些是免费开源的工具,如Protégé、NeOn等。这些开源工具有的还提供Plugin机制,可以针对具体功能需要进行扩展。
同样的,本体分子建库也需要这样的IDE工具来帮助领域专家建本体分子库。但是由于本体分子是笔者提出的一个全新理论,目前国内外没有任何可借鉴的工具可供参考。因此笔者针对该理论开发了一个本体分子建库的工具——OMProtegePlugin。这个工具本质上是一个Protégé插件[1],它通过扩展ProtegeOWLPlugin的方式来提供本体分子建库的功能。采取Protégé插件的方式是基于以下考虑:
(1)Protégé是一个基于Java Swing的开源工具,可以基于它做二次开发。
(2)Protégé提供便捷的插件扩展和管理机制。目前已经有大批Protégé插件可以证明它的框架的实用性。
(3)本体分子库中包含本体库静态三元组的部分,所以本体分子建库工具必须包含原有本体库的建库功能。而Protégé插件的形式,既能够保留原有Protégé的功能(如修改Class,添加Instance),又能够通过插件扩展功能,也就是管理动态知识的功能。
如图7所示,OMProtegePlugin的体系结构分为两层:抽象层(Abstract Layer)和实现层(Implement Layer)。抽象层是关于本体分子建库一些通用功能的集合,它主要包括:
· model包:本体分子库数据结构、事件机制。
· ui包:本体分子可视化建库widget,如slotwidget[2]和tabwidget[3]等。
而实现层是针对具体的本体分子存储方案的建库工具集合。在OMProtegePlugin的1.0版本中,实现层提供AllegroGraph存储方案的相关建库工具。也就是说本体分子存储在AllegroGraph[4]服务器中,而管理本体分子库的工具的具体代码是写在实现层的allegrograph包中。如图8所示,allegrograph包中主要包括model数据结构、parser本体分子解析等。
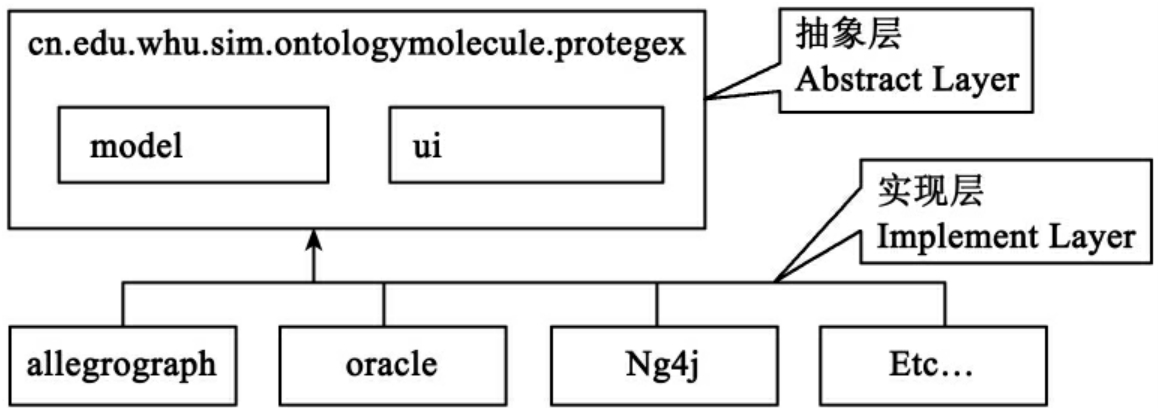
图7 OMProtegePlugin体系结构

图8 OMProtegePlugin包结构
这种分为抽象层和实现层的好处在于提供了一种通用的本体分子建库工具框架。在这个框架下,所有通用的功能都写在抽象层,可以被实现层共享使用。而实现层并没有绑定到某一个具体本体分子存储方案上,它可以通过继承抽象层的方式添加其他本体分子存储方案的实现层工具。除了AllegroGraph存储之外,还可以添加Oracle、NG4J等其他存储方案。而这些新的实现层工具的开发,也只需要开发通用层以外的实现层的特殊对接机制和存储机制。这正如JDBC标准和JDBC驱动一样:具体的数据库可以有很多种,如MySQL、Oracle、DB2等,每一种数据库也可以有多种驱动程序,但是操作数据库的方式都是JDBC标准,开发人员写的使用数据库的代码都是一样的(除了驱动程序类名和连接字符串)。要开发新的数据库驱动程序,只需要按照JDBC标准添加新的实现就行了。
根据本体分子建库的要求,OMProtegePlugin提供了如下管理本体分子库的功能:
(1)本体分子持久化
Protégé提供两种RDF本体持久化方案:文件方式和数据库方式。ProtegeOWLPlugin作为OWL管理的插件,也提供文件方式和数据库方式两种持久化方案。但是它们都只能持久化RDF/OWL这样的静态三元组,对于本体分子库中的动态知识,还需要建立新的持久化方案。
OMProtegePlugin在1.0版本中,实现层选用AllegroGraph作为存储服务器,提供本体分子库的存储。针对这个存储方案,笔者开发了基于AllegroGraph服务器的backend插件[6]——AllegroGraphKnowledgeBaseFactory。用户在选择持久化方案的时候,可以选择AllegroGraph KB这种backend来建立本体分子库。
(2)本体分子建库工程管理
如图9所示,本体分子建库工程的设置包括:Allegraph服务器地址、端口号、本体分子库目录和本体分子库名称。这种管理是通过AllegroGraphCreateProjectPlugin实现的,它本质上是Protégé提供的ProjectPlugin。另外,OMProtegePlugin在1.0版本中,提供了本体分子建库工程与其他普通本体库工程之间的转换:CreateAllegroGraph FromFileProjectPlugin,将owl file工程转换成AllegroGraph本体分子建库工程;Convert Project to Format菜单,将AllegroGraph本体分子建库工程转换成其他普通本体库工程(如file、database等)。这种转换会忽略掉原来本体分子库中的动态知识。
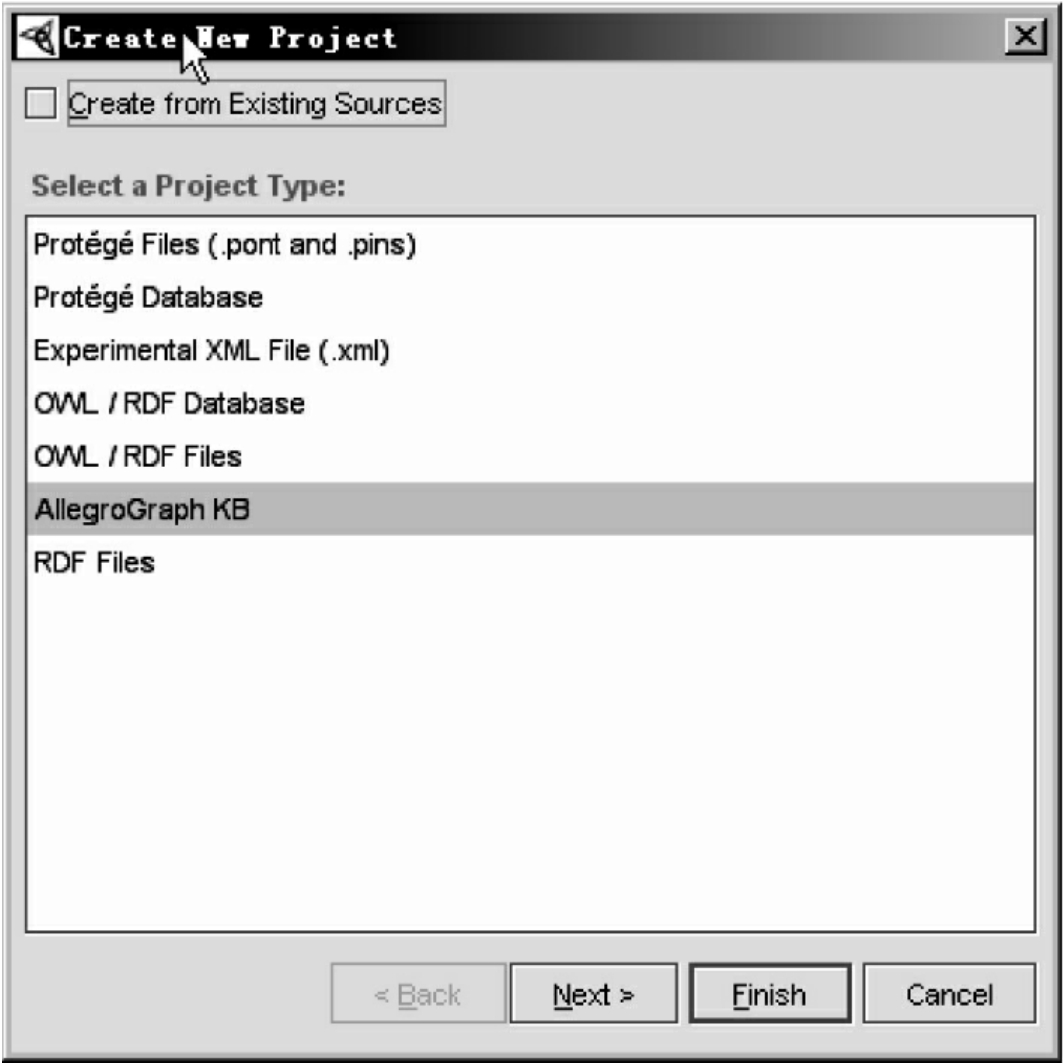
图9 AllegroGraphKnowledgeBaseFactory
(3)动态三元组的管理
动态三元组的管理的基础是动态维度的管理,例如添加时间维度,可以描述某个工厂在不同年度的汽车产量。在class browser中通过继承Dimension类,创建新的动态时间维度:TimeDimension。这个时间维度有三个实例,1983年、1990年以及EmptyDimensionContainer。其中EmptyDimensionContainer指的是空约束的任何时间状态。
建立好了动态时间,就可以使用这些时间实例创建动态三元组。假如,我们想要描述“GE公司是一个汽车厂,它1983年的生产量为5000辆,而到了1990年产量上升为8000辆”。如图10所示,首先我们新建CarFactory类,添加Products属性表示它的年产量(数据类型为float),然后新建CarFactory的实例GE。在GE的Products属性slotwidget里面,填写了两个数字值:5000辆对应的动态时间是1983年,8000辆对应的动态时间是1990年。
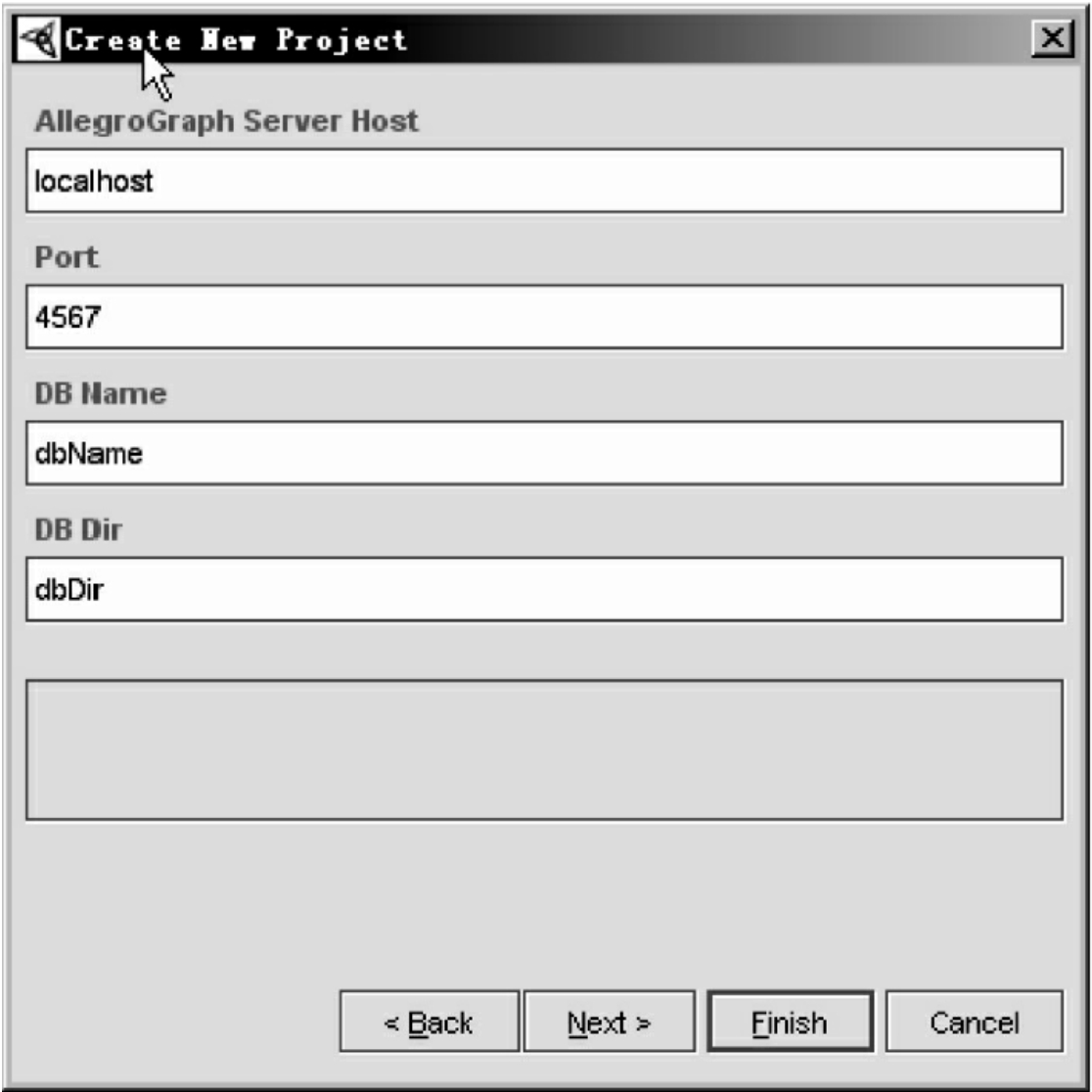
图10 本体分子工程管理
这个slotwidget不是普通的MultiLiteralWidget,它是笔者针对本体分子建库而开发的DimensionalMultiLiteralWidget插件。它与普通MultiLiteralWidget相比,多了一列DimensionContainer来放置动态维度(如动态时间,如图11所示)。添加了动态时间的三元组,从普通的静态三元组变成动态三元组,为本体分子、核子和离子的建立提供基础。值得注意的是,DimensionalMultiLiteralWidget所在的层是抽象层,它不依赖具体存储方案的变化而变化,可以重复使用。也就是说,如果本体分子服务器不再是AllegroGraph,而换成其他的如Oracle、Mysql等,DimensionalMultiLiteralWidget的使用完全不受影响,而且不需要任何修改就可以直接使用(见图12)。
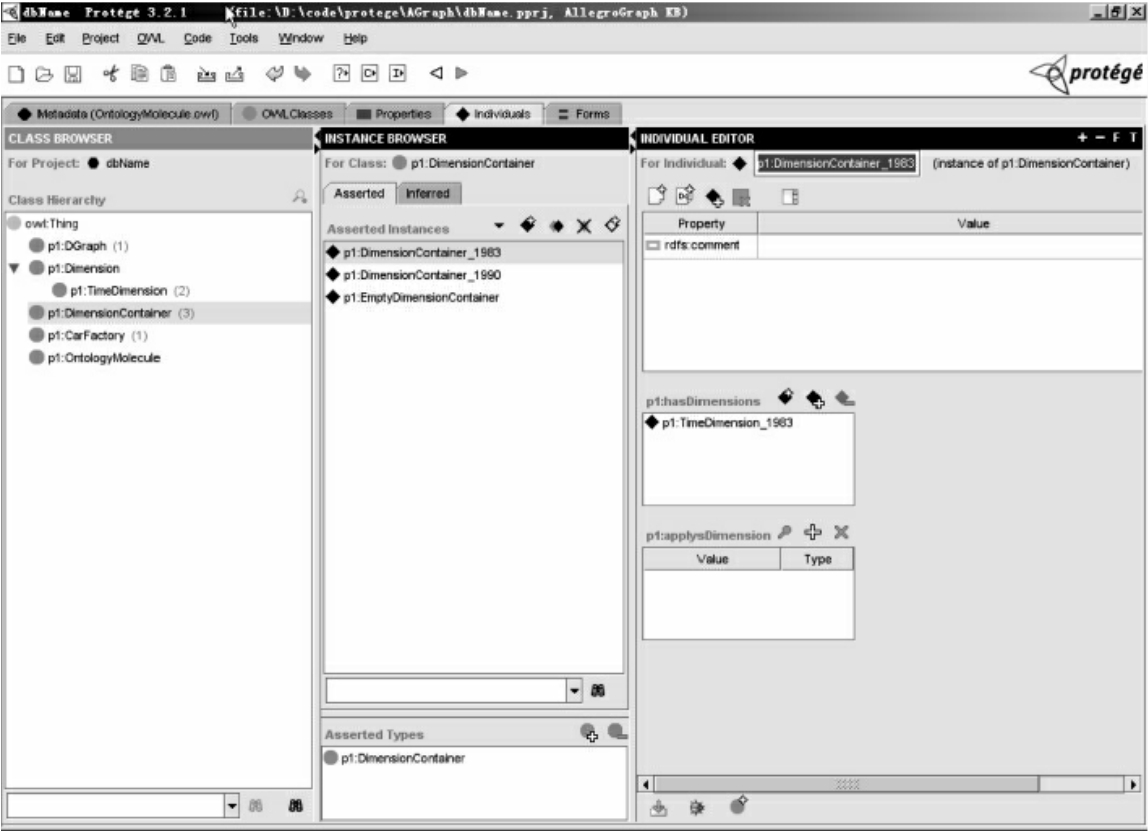
图11 动态时间的管理
(4)核子和离子的管理
本体分子核子存放的是本体分子不变的知识,离子存放的是本体分子变化的知识。这些知识都是指动态三元组。图13展示了如何将动态三元组添加到本体分子的核子或离子中去。由于核子和离子都是DGraph的实例,首先新建一个OuterGraph_1983实例,它实质上是GE的1983年本体分子的离子。这个离子存放的是动态知识,而且动态时间规定在1983年,所以对于OuterGraph_1983动态维度属性添加了DimensionContainer_1983来做约束。
向OuterGraph_1983这个离子里面添加动态三元组之前,首先要选择符合条件的动态三元组。点击图13中的hasDStatements属性的添加按钮之后,出现图14搜索动态三元组的UI界面。通过这个界面,用户可以设置一些过滤条件。如图14所示,过滤条件为“时间维度为1983年,CarFactory类,属性Products的属性值超过0的动态三元组”。这个过滤条件正是OuterGraph_1983离子中动态三元组的条件。用户点击Search按钮,结果找到一个动态三元组,它表示GE公司1983年产量为5000辆汽车。用户再点击OK按钮,可以将这个动态三元组添加到OuterGraph_1983离子中,出现图14所示的hasDStatements属性值列表。
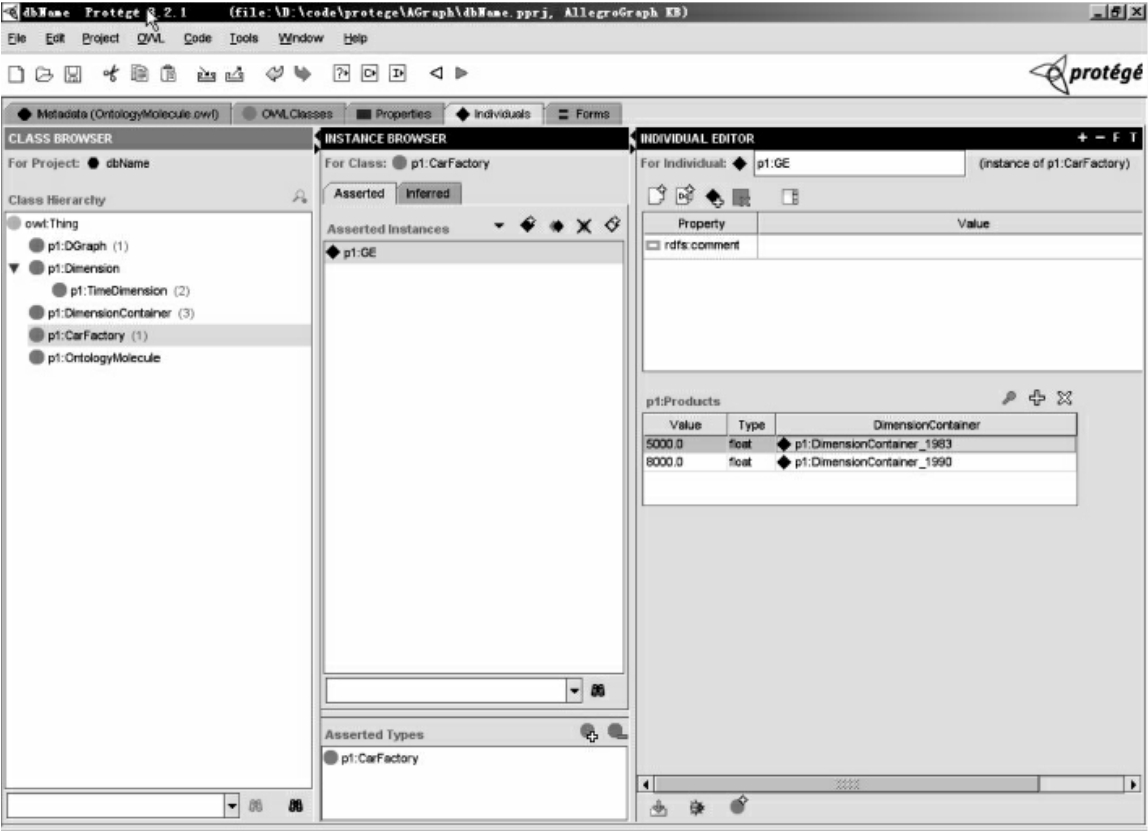
图12 动态三元组的建立
值得注意的是,选择动态三元组时如果时间维度与离子的时间维度不符合(包括不相等或不兼容),那么即使点击了OK按钮,这个动态三元组也不会添加到离子中去。这个就是OMProtegePlugin对动态知识的控制的一种方式,避免产生逻辑错误。
如图14所示,hasDStatements属性的UI接口,也是笔者开发的一个slotwidget:DGraphHasDimensionsSlotWidget。它能将动态三元组的subject、property、object和DimensionContainer通过列表的方式展现出来。并通过图14所示的UI接口来搜索和添加新的动态三元组。
(5)本体分子的管理
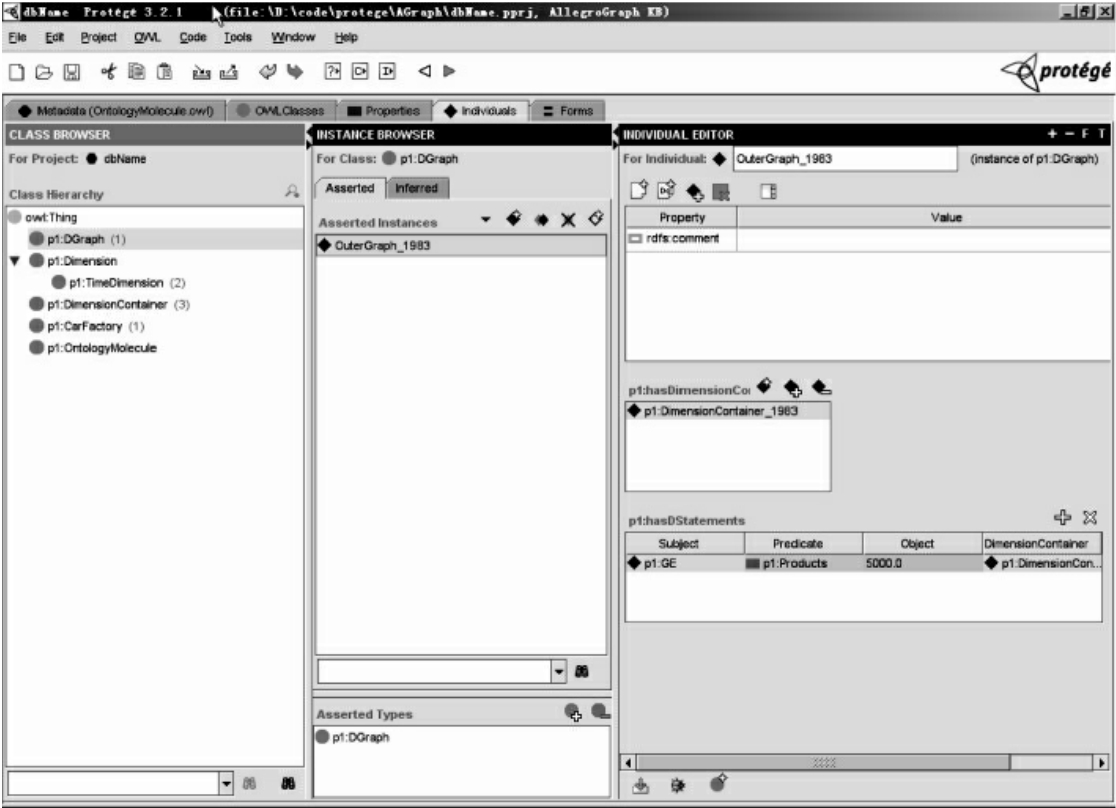
图13 核子和离子的管理
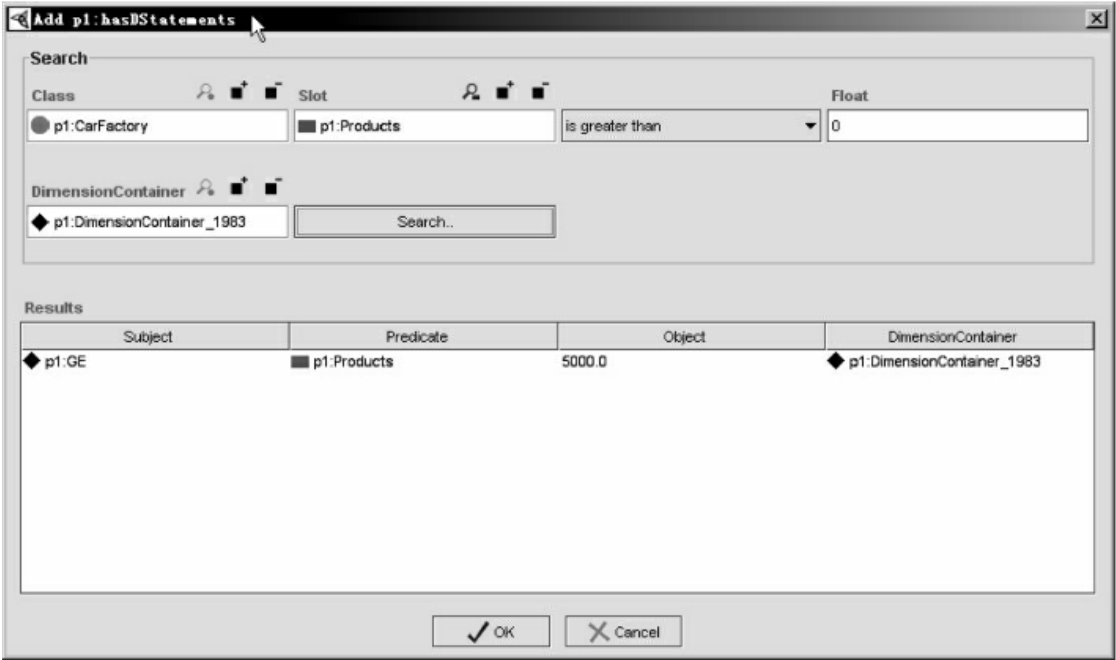
图14 选择动态三元组
由于本体分子OntologyMolecule本质上是一个OWL class,所以它的管理和其他普通OWL class的管理方式一样,故本文不再赘述。如图15所示,将OuterGraph_1983离子添加到GE_1983本体分子的hasOuterGraph属性中去。添加、删除核子到本体分子也是一样的操作。

图15 本体分子的管理
2.6 本体分子的动态知识演化
本体可以描述动态知识,即将变化后的知识影射到本体库,将原来描述的知识覆盖掉,所以,他不能描述知识演变的过程。引入本体分子理论以后,该问题就迎刃而解了,以本体分子的时间维度来描述随时间的变化而变化的知识演变过程。解决此问题首先必须解决本体分子的核与离子问题,即什么是知识的不变部分,什么是可变部分。确定可变与不可变有两种情况:一种是可认知的,这种情况较好解决,另一种是不可认知的,它需要通过较长时间对知识的收集和分析来确定。本体分子结构确定后,就得对可变部分进行分析找出其变化规律,并对其描述。
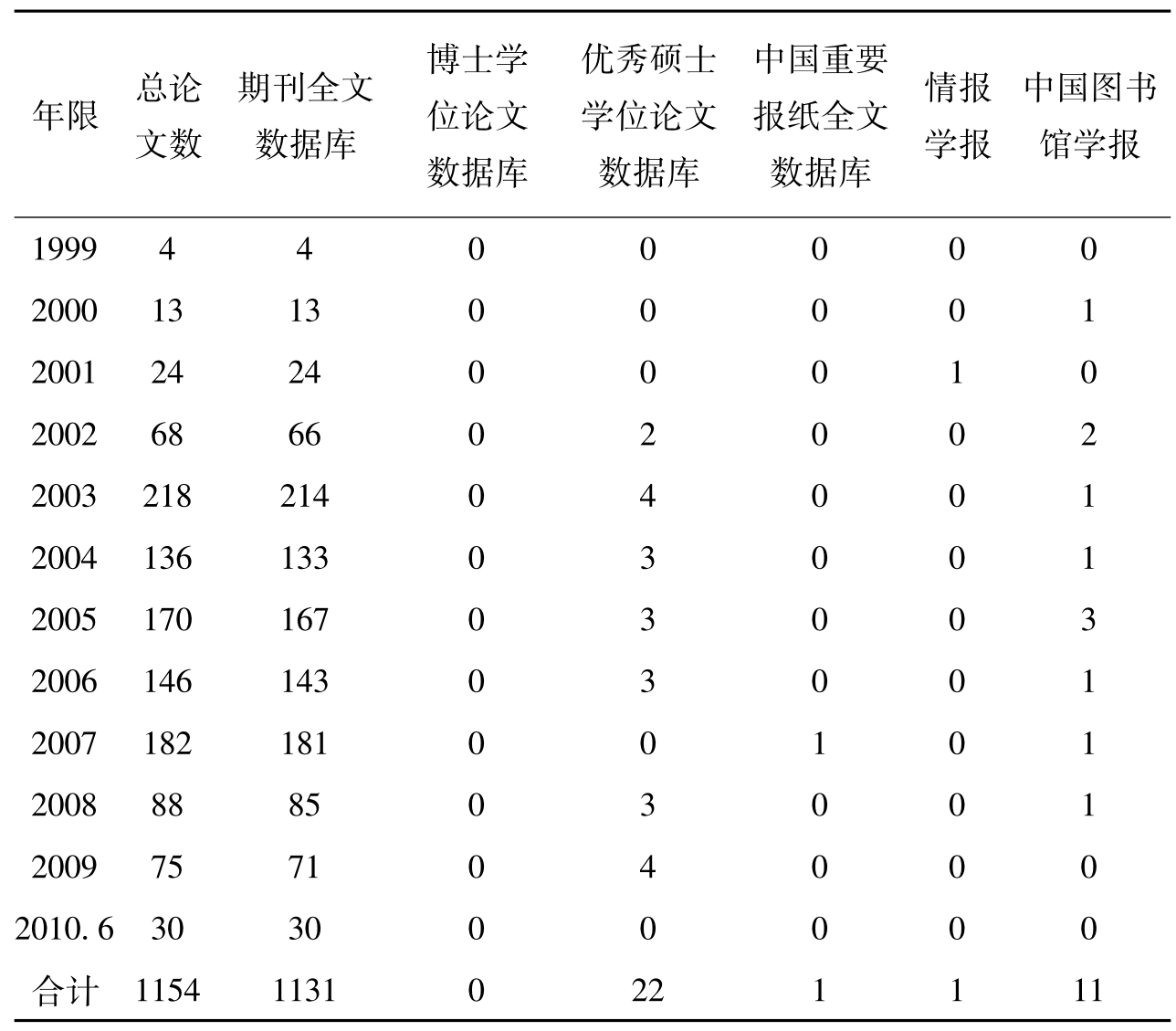
以《图书馆知识管理》为例说明这种演化过程。对中国期刊网,从1999年1月到2010年6月30日关于“图书馆知识管理”进行了检索,其间,发表相关论文共计1154篇,其中期刊全文数据库1131篇(情报学报1篇,中国图书馆学报11篇),优秀硕士学位论文数据库22篇,中国重要报纸全文数据库1篇。详见表1图书馆知识管理统计表。
表1 图书馆知识管理统计表(1999—2010-06-30)
1999年,韩莉在《图书馆论坛》发表题为《图书馆引进知识管理初探》[16]的文章,指出:“知识管理不同于信息管理,一般所说的信息管理主要侧重于信息的收集、分类、检索存储和传输等,对信息管理者的创新能力并没有提出特殊的要求。而知识管理型的组织是对外部需求作出迅速反应、通过运用内部资源、预测外部市场的发展方向及其变化,把信息资源与信息、信息与人、信息与过程联系起来,以进行大量创新。”此时,韩文还没提出知识管理的具体内容。
2000年,汤珊红在《现代图书情报技术》发表题为《新世纪图书馆知识管理的特征、内容及相应的实现技术》[17]的文章,指出:“知识管理应包含:①知识创新管理,②知识应用管理,③知识传播管理,④人力资源管理。”同年,刘茂生在“中国图书馆学报”,发表题为“图书馆知识管理管见”[18]的文章,指出:“知识经济时代图书馆知识管理的主要内容:①继续发展与创新图书馆学,②为知识科技创新服务,③不断完善图书馆知识管理系统。”
2001年,姜永常在《图书馆》,发表题为《再论图书馆的知识管理及其实施策略》[19]的文章,指出图书馆知识管理的内容应包括:“①知识创新管理,②知识应用管理,③知识传播管理,④人力资源管理,⑤知识营销管理。”同年,邱均平、沙勇忠、刘焕成在“情报资料工作”,发表题为《论数字图书馆的知识管理》[20]的文章,指出知识管理主要内容包括以下几个方面。“①知识创新,②知识组织,③知识开发,④知识服务:知识信息导航,知识信息评价,知识信息咨询,知识营销,⑤知识产权管理。”
2002年,王海娟在《图书与情报》,发表题为《图书馆的知识管理》[21]的文章,王文将“知识转化与创新”作为知识管理的理论基础,将图书馆的知识管理内容归纳为:显性知识的管理和隐性知识(馆员和读者)的管理两类。同年,王杏允、刘海燕在“经经济论坛”,发表题为《图书馆与知识管理》[22]的文章,指出图书馆知识管理的基本内容包括:“①知识创新管理,②人力资源管理,③知识传播管理,④知识应用管理,包括:为企业、政府、社会团体、科研机构建立虚拟图书馆或信息中心;信息化的知识服务;图书馆资源数字化。”李敏在《图书馆理论与实践》发表题为《论数字图书馆的知识管理》[23]的文章,指出数字图书馆知识管理的主要内容:“①知识创新,②知识组织,③知识开发,④知识服务:知识信息导航、知识信息评价、知识信息咨询、知识营销。”
2003年,张健萍在《情报科学》,发表题为《知识管理与图书馆》[24]的文章,指出:图书馆的知识管理包括:“①知识的识别、获取和积累,②创建新型组织:学习型组织、团队型组织、灵活的网络组织、边界模糊的虚拟组织、速度制胜的敏捷组织,③造就独特的组织文化,④创导新的评估方法。”同年,胡艳荣、欧群在《河南财政税务高等专科学校学报》,发表题为《谈图书馆知识管理》[25]的文章,指出图书馆知识管理的内容包括:“①知识创新管理,②知识组织与传播管理,③知识应用管理,④知识营销管理,⑤人力资源管理。”
2004年,崔波在《高校图书馆工作》,发表题为《论高校图书馆知识管理的内容和作用》[26]的文章,指出:图书馆知识管理的主要内容是:“①显性知识数字化为中心的知识创新和知识应用管理知识创新管理,②隐性知识资源的管理,③知识管理系统的开发建设,④图书馆管理创新的目标和特征。总之,知识管理的内容包括两个方面,即信息技术所提供的对数据和信息的处理能力和人的发明创造能力。同年,李刚在《常州工学院学报》,发表题为《高校图书馆知识管理研究综述》[27]的文章,指出图书馆知识管理包括:“①知识创新管理,②知识传播管理,③知识应用管理,④知识组织管理,⑤人力资源管理,⑥知识营销管理与应用管理。”
2005年,赵全红在《河北科技图苑》,发表题为《论图书馆知识管理的主要内容和实施策略》[28]的文章,指出图书馆知识管理的主要内容:“①知识创新管理,②知识组织管理,③人力资源管理,④知识应用管理,⑤知识传播管理,⑥知识营销管理。”
2006年,冯丽雅在《科技情报开发与经济》,发表题为《图书馆知识管理的主要内容及实施策略》[29]的文章,指出图书馆知识管理的主要内容为:“①知识交流与共享的宣传,②建立知识网络和创造适宜的环境以促进知识的交流与共享,③积累和扩大知识资源,④将图书馆的知识资源融入到服务和管理过程中。”同年,李轶在《科技广场》,发表题为《知识管理在图书馆中的应用》[30]的文章,指出知识管理的内容主要涉及下列几方面的知识活动:“①知识的产生与创新,②知识的获取与组织,③知识的传播与共享,④人力资源的管理,⑤知识基础设施的规划建设与管理。”
2007年,李力在《现代情报》,发表题为《现代图书馆知识管理的内容与实施策略研究》[31]的文章,指出现代图书馆知识管理的内容是“①知识创新管理,②知识组织与传播管理,③知识营销管理,④知识应用管理,⑤人力资源管理。”
2008年,朱华琴在《现代情报》,发表题为《关于图书馆知识管理的研究》[32]的文章,提出了图书馆知识管理的内容架构,其基本内容概括为:1个目的、1个基础、3个层面、4个过程、5个环节以及时间策略。即1个目的:持续知识创新,2个基础:基础结构建设、用户服务,3个层面:组织管理、团队管理和个人管理,4个过程:基础结构建设、信息资源建设、馆员队伍建设、用户服务,5个环节:知识创新、知识共享、知识转移、知识存储、知识生成。并指出“要着手:①知识创新管理,②知识组织管理,③知识开发与应用管理,④知识传播与服务管理,⑤人力资源管理,⑥知识营销管理,⑦拓展与创新图书馆学”七方面的工作。
2009年,丁学淑在《江西图书馆学刊》,发表题为《1999—2008年图书馆知识管理研究文献计量分析》[33]的文章,在图书馆知识管理研究趋势中指出,①未来趋势可能在客户知识管理,②学科馆员制度,③隐性知识管理等三方面会得到进一步发展。
2010年,杨云在《中华医学图书情报杂志》(2010年2月),发表题为《图书馆知识管理的特点和实施对策》[34]文章,指出图书馆知识管理的特点是:①以信息知识为基础,②以用户需求为重点,③以信息技术为支撑,④以知识创新为目标。
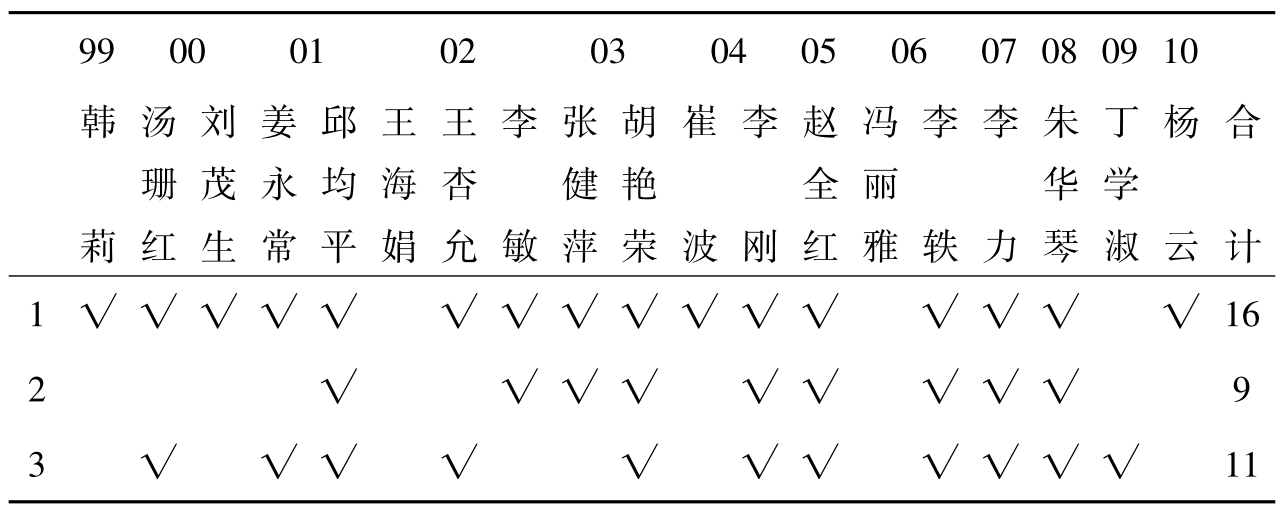
综上所述,各时期学者专家对图书馆知识管理内容的看法,见表2。
表2 各时期学者专家对图书馆知识管理的内容分析表
续表

注:1~13,为知识描述点条文,①知识创新管理,②知识组织管理,③人力资源管理,④知识应用管理,⑤知识传播管理,⑥知识营销管理,⑦知识产权管理,⑧知识开发,⑨知识服务,⑩显性知识管理和隐性知识管理, 知识交流与共享,
知识交流与共享, 交流平台建设与管理,
交流平台建设与管理, 知识资源建设。
知识资源建设。
由表2可见,综合各时期学者专家对图书馆知识管理的内容的看法,知识创新管理占84.2%,知识组织管理占47.3%,人力资源管理占57.8%,知识应用管理占52.6%,知识传播管理占47.3%,知识营销管理21%,知识产权管理5.2%,知识开发15.8%,知识服务15.8%,显性知识管理和隐性知识管理15.8%,知识交流与共享10.5%,交流平台建设与管理15.8%,知识资源建设5.2%。根据以上分析,知识管理的核心应该是“知识创新”,凡是在讨论知识管理内容时,“知识创新”就必不可少。这就是以“知识管理”为本体,其分子的核为“知识创新”。于是,我们管理和控制知识管理这个知识时,其他所增加的知识点,就是“知识管理”本体分子的离子,如图16所示。
图16 动态知识演化示意图
例如,肖永霖、杨桂荣和李瑞萍在《理论探讨》,发表题为《我国图书馆知识管理研究近况》的文章,关于知识管理文中引用了刘茂生、盛小平、汤珊红、姜永常等人的观点,并阐述了自己对其看法。引文是肖文不可修改的部分,就其刘、盛、汤、姜等人对知识管理内容的共同部分——知识创新,就是肖文论述知识管理的核,肖文中论述自己观点的部分就是知识管理增加部分——知识管理的离子,也就是肖文中对知识管理的知识创新扩展有特色的条文。
关于动态知识变化过程和知识管理核变化产生的裂变,请看图17,图18和图19。
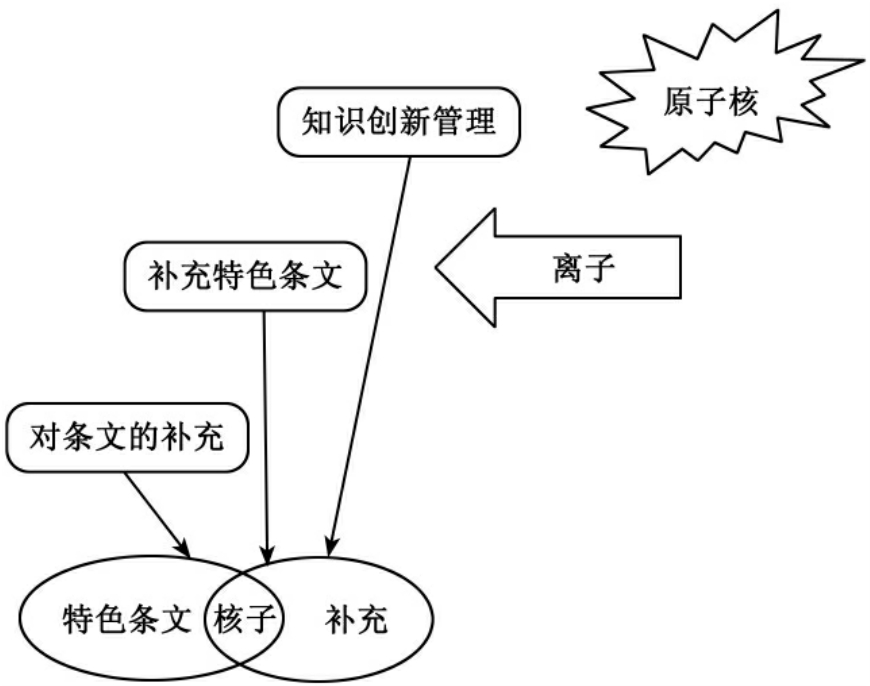
图17 动态知识变化过程图
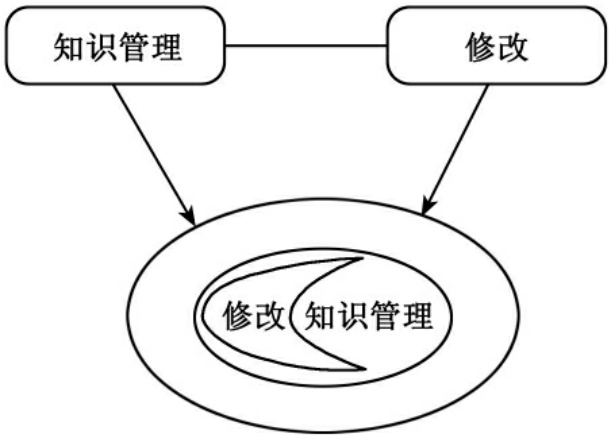
图18 修改核裂变图
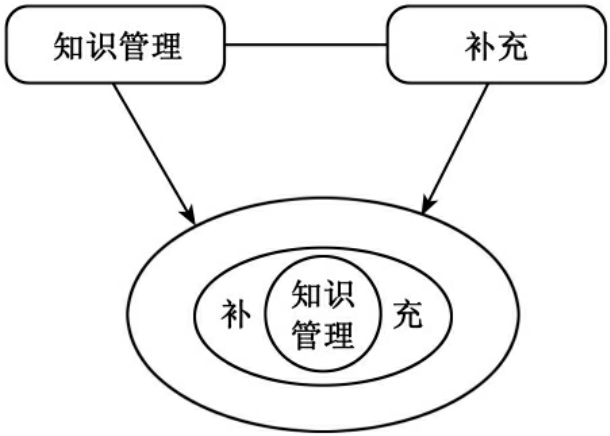
图19 补充核裂变图
3 基于语义关系的本体推理
本体知识工程主要包括知识获取、知识表示和知识推理等内容。知识推理被认为是本体知识工程的高级阶段,实现的好坏在很大程度上取决于能否对领域本体知识库中的语义关系进行准确分析,提炼出推理规则,并采用合适的本体规则描述语言进行形式化和优化[35],本文以国家自然基金委资助项目“基于本体的数字图书馆信息检索模型研究”为例进行研究。
3.1 领域本体语义关系解构
语义关系构成了本体库的骨架,是概念之间以及实例之间联系的桥梁。本体知识库对领域知识描述的准确与详尽程度,以及在本体知识库中进行知识推理的效率在一定程度上都取决于领域本体中语义关系的解构。
在本体工程中,有4种类型的关系对于理论研究和实际应用非常重要。一类是处于不同逻辑层次上的概念之间的种属关系Is—a relation;一类是不同逻辑层次的概念与其概念外延个体的实例关系(Instance—of relation);再就是处于同一逻辑层次概念或不同逻辑层次概念的实例之间关系(Instance—Instance rela—tion);其四是反映不同抽象程度的关系之间的父子关系(SubAttribute—ofrelation)关系。
3.1.1 ls-a关系
Is-a关系是典型的概念之间的二元关系,用于指出事物间抽象概念上的隶属关系,它形成了概念之间的逻辑层次分类结构,类似于面向对象中的父类和子类之间的关系。概念是本体的主要成分,可分解为内涵和外延两部分。概念内涵反映的是事物的本质特征,概念外延反映的是事物所指的范围。一个概念的内涵包括它所有的性质,外延包括它所有的实例。本文所指的实例非常明确,就是Gangemi与Guarino等学者文献中所指的“最终实例”,本文所指的概念都是指抽象的非实例概念。
对于给定概念C1与C2内涵和外延,Is-a关系的形式化定义如下:对于本体概念集Sc中的概念C1.C2∈Sc,如果概念C1的内涵I(C1)包含C2的内涵I(C2),并且概念C1的外延包含于C2的外延,即E(C1)属于E(C2),则称概念C1和C2之间的关系为种属关系,记作ls—a(C1,C2),概念C1常称为子概念或种概念,而概念C2相应的称为父概念或属概念。
人们进行本体蕴涵知识推理时主要考虑基本关系的对称性、传递性和可逆性以及基本关系的语义复合运算。根据关系的对称性、传递性和可逆性的形式化定义,可知种属关系不满足对称性,但具有传递性。
在国共合作本体库中,我们抽象了6种父概念:人物、组织、时间、地点、资源、事件,然后采用自顶向下的办法,建立Is—a关系。经过对概念模型中的概念进行二义性消除、同层次概念间互不相交以及并集覆盖整个父类概念范围的处理,最后得到3层Is-a结构的国共合作历史领域本体类模型。
3.1.2 Instance-of关系
Instance-of关系是典型的概念及其实例之间的二元关系,类似于面向对象中的类和对象之间的关系。假设概念集Sc中的任意概念C的概念外延集为E(C);对于E(C)中的任一元素Ci∈E(C),如果Ci的外延集E(Ci)={Ci},则称Ci为概念C的实例,而概念C的实例集Sin(C)定义为S(c)={x|x∈E(c)∧E(x)={x}}。上述关于实例的形式定义就从概念的外延上将概念的子概念与实例区别开来了。对于给定概念C及其实例集元素e,Instance-of关系的形式化定义如下:对于概念C及其实例集Sic,实例集Sic中的元素e(e∈Sic)和概念C之间的关系称为实例关系,记作Instanceof(e,C)。
实例关系既不具有对称性和可逆性,也不具有传递性。但是从概念的内涵与外延可知,实例和概念之间有很好的性质与属性继承。在国共合作本体知识库中,概念和个体之间是严格按照Instance-of进行组织,概念的定义主要包括数据属性、属性值的类型以及对象属性(关系);实例将继承概念的数据属性和对象属性,并且给出属性值。国共合作领域本体库中包括了6个本体类,161个一级子类和二级子类,创建了13129个实例。
3.1.3 Instance-Instance关系
在本体的实际应用中,除了Is-a关系和Instance-of关系,更复杂的是根据特定领域具体情况定义的归属于同一概念或不同概念的实例之间的语义关系。
对于实例x1与x2以及关系R,Instance-Instance关系的形式化定义为:如果对于本体概念A的实例集Sa中某一实例X1∈Sa,本体概念B的实例集Sb中至少存在一个实例X2∈Sb,满足R关系,即R(X1,X2),则称关系R为概念A和B实例之间关系。
在国共合作领域本体中,针对人物、组织、事件、时间与地点以及资源六大类的实例定义了复杂的实例之间关系。同类实例之间或不同类实例之间都存在复杂的语义关系,其中比较繁杂的是人物关系和实例之间的包含关系。
在国共合作本体库里定义了两大类人物实例关系:婚姻血缘关系和社会交际关系。前者主要包括夫妻关系、兄弟姐妹关系、为人长辈、为人后代、为人父母、为人子女等7种基本关系;后者主要包括因为教育、同乡、同事、友情交际等因素存在的人际关系。这既考虑了语义描述的粒度,也兼顾了关系的扩展性。但以上定义的关系还不足以展现出国共合作波澜壮阔的历史长河中数以千万计的人物之间的复杂联系,它们只是我们定义的基本关系;若考虑人物的性别、出生年龄、职务等属性,可以通过规则推理出更多更复杂的人物关系。
在国共合作领域本体库中,实例之间的包含关系是一个复杂的关系集,这些包含关系的实质是Part-whole关系的逆关系。我们借鉴关于Part-whole关系的WCH分类的语义分析尺度[36]国共合作本体知识库中包含了5种类型的part-whole逆关系:
component-composite关系,如组织与组织之间的隶属关系;
Member-collection关系,比如人物与组织之间的成员构成关系;
Portion-mass关系,比如时间段与时间段之间的被包含关系;
Place-area关系,比如地点与地点之间的被包含关系;
Feature-activity关系,比如事件与事件之间的子事件关系。
3.1.4 SubAttribute-of关系
SubAtribute-of关系是典型的关系之间的二元关系,用于指出关系之间抽象层次上的隶属关系,它形成了关系之间的逻辑层次结构。对于给定关系R与R2,SubAtribute-of关系的形式化定义为:对于本体关系集S中的关系R,R2∈S,如果关系R上的实例对集R(x,Y)中的任意一实例对x,Yi)必定存在R2关系,但对于关系R2上的实例对集R2(m,n)中的任意一实例对(Ii,nj)却不一定存在关系R,或换言之实例对集(x,y)cR2(m,n),则之间的关系为SubAttribute-of关系,记作SubAttribute-of(R1,R2),关系R常称为子关系,而关系R2相应地称为父关系。
SubAttribute-of关系不满足对称性,但有自反性、反对称性和传递性。在国共合作领域本体中,SubAt-tribute-of关系主要存在于人物之间关系以及组织之间的关系之中,比如说祖父关系、祖母关系与祖父母关系之间都存在SubAtribute-of关系。SubAttribute-of关系表达的语义只能由子关系向父关系泛化,其语义如果从父关系向子关系具体化的话就不一定正确。存在SubAttribute-of关系的两个关系描述的知识一般不处于同一抽象层面上,一般而言,子关系描述的信息更加具体,信息的具体程度与子关系的层次是对应的。
3.2 领域本体推理规则的定义
领域本体知识推理的思想是将领域知识构建在某种本体语言形式化的ABox和TBox上,然后考虑本体语义关系来构造领域公理所蕴涵的产生式规则,并将形式化的规则与定义好的本体类与属性结构和声明的事实断言按一定的搜索策略进行规则模式匹配。因此在进行领域本体知识推理时,规则的定义和表示显得尤为重要。
3.2.1 ls-a关系推理规则
Is-a关系不满足对称性,但有自反性、反对称性和传递性。基于Is-a关系的知识推理规则(类自然语言描述)如下:
传递性规则:(Is-a(C1,C2)∧Is-a(C2,C3))→Is-a(C1,C3)
对象属性继承规则:(Is-a(C1,C2)∧HasAttribute(C2,A))→HasAttribute(C1,A)
数据属性继承规则:(Is-a(C1,C1)∧HasProperty(C2,P))→HasProperty(C1,P)
实例传递归属规则:(Is-a(C1,C2)∧Ins tan ce-of(e,C1))→tance-of(e,C2)
父子类互逆关系规则:SubClassOf(C1,C2)→superClassOf(C2,C1)
国共合作领域本体库中定义的161个一级和二级子类和其6个顶级父类之间都存在以上推理规则。Is-a关系的传递性规则主要用于确定多个概念之间的父子层次关系,实例的传递归属规则可对概念的实例进行检查,属性继承规则用于子类对父类属性的继承。
3.2.2 Instance-of关系推理规则
基于实例关系的知识推理是通过继承规则实现的。
对象属性继承规则:(Instance-of(e,C)∧HasAttribute(C,A))→HasAttribute(e,A)
数据属性继承规则:(Instance-of(e,C)∧HasProperty(C,P))→HasProperty(e,P)
国共合作领域本体中声明的事件实例、资源实例、组织实例、人物实例、地点实例、时间实例以及角色类实例都与其对象类之间满足对象属性继承规则和数据属性继承规则。Instance-of关系的对象属性继承规则可用来推导实例与其他对象实例之间可能存在的关系,数据属性继承规则可用来确定实例所具有的本质属性,Instance-of关系推理规则的运用可避免本体知识的冗余描述。
3.2.3 Instance-Instance关系推理规则
国共合作领域本体库中数以万计的实例之间的关系,是通过108种基本的实例关系来描述的。这108种实例关系主要包括人物关系、组织发展演变关系、资源相关关系、事件因果先发关系、地理邻近包含关系、时间先后包含关系等。实例与实例之间的关系推理是整个领域本体蕴涵知识发现推理的重心。
Instance-Instance关系推理规则包括实例之间关系简单规则和组合规则两大类。
(1)Instance-Instance关系简单规则
所谓Instance-Instance关系简单规则就是单纯考虑108种基本实例关系本身的对称性与传递性及其相互之间的互逆性等3种性质来确定的简单推理规则。运用实例之间关系简单规则对本体知识库推理后,并没有扩展本体库中的对象属性,而只是在原有关系的基础上新增了事实断言。在定义实例之间108种基本关系的简单推理规则时,先并不考虑基本关系的定义域与值域,将基本关系抽象,单纯考虑关系的传递性、互逆性、对称性来确定泛化的推理规则,然后在对规则进行形式化描述的后续工作中,才考虑关系的具体语义,将泛化规则具体化。实例之间关系简单规则的泛化形式为:
对称关系推理规则:(SymAttribute(A)∧A(e1,e2))→A(e2,e1)
传递关系推理规则:(TraAttribute(A)∧A(e1,e2)∧A(e2,e3))→A(e1,e3)
互逆关系推理规则:(AthAttribute(A1,A2)∧A1(e1,e2))→A2(e2,e1)
SymAttribute(A)表示关系(对象属性)A具有对称性,是对称关系类的一个实例。TraAttribute(A)表示关系A具有传递性,是传递关系类的一个实例。而AthAttribute(A1,A2)表示对象属性A1与A2是互逆关系。ei(i∈N)表示本体实例。据粗略统计,在国共合作领域本体108种基本关系中,有8种具有对称性,23种具有传递性,14对关系之间存在互逆关系。
(2)Instance-Instance关系组合规则
所谓的Instance-Instance关系组合规则就是指在考虑基本关系的定义域与值域所表达的语义知识之间的内在联系,对多种基本关系表达式进行一定的逻辑运算或对数据属性值进行一定的比较运算,并考虑基本关系的互逆性、传递性等性质而构造出新的实例之间关系,并在新的实例之间关系上断言事实的复杂推理规则。在国共合作领域本体中,我们定义了事件时间组合推理规则集、事件地点组合关系规则集、基本婚姻血缘关系组合的家族关系推理规则集、资源人物组合关系规则集等一系列的Instance-Instance关系组合规则63条。其中家族关系组合推理规则示例(妯娌关系推理规则)是:
IndiviActor(X)∧IndiviActor(Y)∧IndiviActor(Z)∧IndiviActor(W)∧beWifeOf(X,Y)∧beWifeOf(Z,W)∧beBrotherOf(Y,W)→beSisterlnLaw(X,Z)
通过Instance-Instance关系组合规则推理,国共合作领域本体库仅关系定义就由108种基本关系增加到208种,而断言事实的增加更是数以万计。In-stance-Instance关系组合规则推理对领域本体知识库扩展的程度和对领域蕴涵知识发掘的深度,是Instance-Instance关系简单规则推理不可比拟的。
3.2.4 SubAttribute-of关系推理规则
SubAttribute-of关系是典型的关系(对象属性)之间的二元关系,用于指出事物关系属性上的隶属关系,它形成了关系之间的逻辑层次分类结构。SubAttribute-of关系不满足对称性,但有自反性、反对称性和传递性,因此基于SubA ttribute-of关系的知识推理规则如下:
传递性规则:(SubAttributeof(A1,A1)∧SubAttributeof(A2,A3))→SubAttributeof(A1,A3)
属性外延规则:(HasAttribute(C,A1)∧SubAttributeof(A1,A2))→HasAttribute(C,A2)
属性外延泛化规则:(Al(e1,e2))∧SubAttributeof(A1,A2))→A2(e1,e2)
父子属性互逆关系规则:SubAttributeof(A1,A2)→SuperAttributeof(A2,A1)
在属性外延泛化规则中,A1(e1,e2)表示实例e1具有对象属性A1,其值为e2。属性传递规则主要用于确定多个对象属性之间的层次关系,在推理过程中,一般作为中间规则,供其他规则推理调用。属性外延规则主要用于判断多个对象属性与单个类之间的语义关系。属性外延泛化规则用于判断两个实例在两个父子对象属性层次上的关系。在SubAttribute-of关系中,最重要的是在考虑实例的数据属性的基础上,再结合关系的父子层次结构,来推理获取更加详细具体的两个实例之间关系,并且实例关系信息的详细具体程度与子关系的层次是对应的。在国共合作领域本体库中,有21对关系之间存在着直接的SubAttribute-of关系。
4 基于本体分子的动态知识检索机制
4.1 动态知识检索模型
动态知识组织的目标是为动态知识整序并最终为用户提供动态知识。而动态知识检索是为用户提供动态知识的一种方便、快捷的方式。知识组织是用户检索并获取信息的基础,采用不同的知识组织的方法及不同的知识组织工具会有完全不同的知识服务。良好的、深度的知识组织是向用户提供高质量的、智能的、个性化的、基于内容的知识服务的前提。本体分子作为一种新型的知识组织工具,为解决动态知识的组织问题并为用户直接呈现动态知识的演变过程检索提供了一种新思路。基于本体分子的动态知识检索是将知识按照本体分子的方式组织、存储,并根据用户的需求找出相关知识的动态变化的过程和结果。
知识检索的产生和发展一方面来源于用户对知识检索的需求,另一方面来源于信息检索理论与实践的发展与完善[37]动态知识检索正是产生于用户对知识的动态变化过程及结果的直接呈现的一种需求,而本体分子技术恰好也是对本体技术的发展,用来支持动态知识的检索。
基于本体分子的知识组织模型在对资源对象的整理、加工、描述、表示及持久化等方面都有自己的特征,这使得基于本体分子的动态知识检索与基于本体的知识检索也不相同。基于本体分子的动态知识检索的基本设计思路可以总结如下:
(1)按照系统需求,在领域专家的帮助下,对相关领域资源进行领域相关的本体库及本体分子库的构建。
(2)通过Lucene建立相关元数据与本体库的索引。
(3)用户通过检索界面获取初始查询结果集,经过排序后,返回给用户。
(4)点击某条初始查询结果,触发本体检索引擎,通过本体及本体分子库检索出相关的实例。检索的结果通过可视化工具可视化后,再返回给用户。
根据动态知识组织的目标和基于本体分子的动态知识检索的设计思路,笔者提出了一个基于本体分子的动态知识检索模型,如图20所示。
基于本体分子的动态知识检索模型共分成5个部分:知识的获取、本体分子库的构建、用户查询和结果反馈、Lucene检索引擎、知识的可视化。下面分章节详细介绍每个部分。
4.2 知识的获取
知识的获取主要是对知识源进行收集,并根据需求及领域特征对收集的知识源进行分析,归纳出知识抽取规则,再应用此规则从大批文档中抽取出需要的数据信息,并把这些信息转化为相应文档的元数据,从而为后面构建本体分子库以及建立Lucene索引做好了准备。知识获取的过程或多或少地都要用到自然语言处理技术(NLP),不同领域以及不同的需求都会采取不同的处理方式。
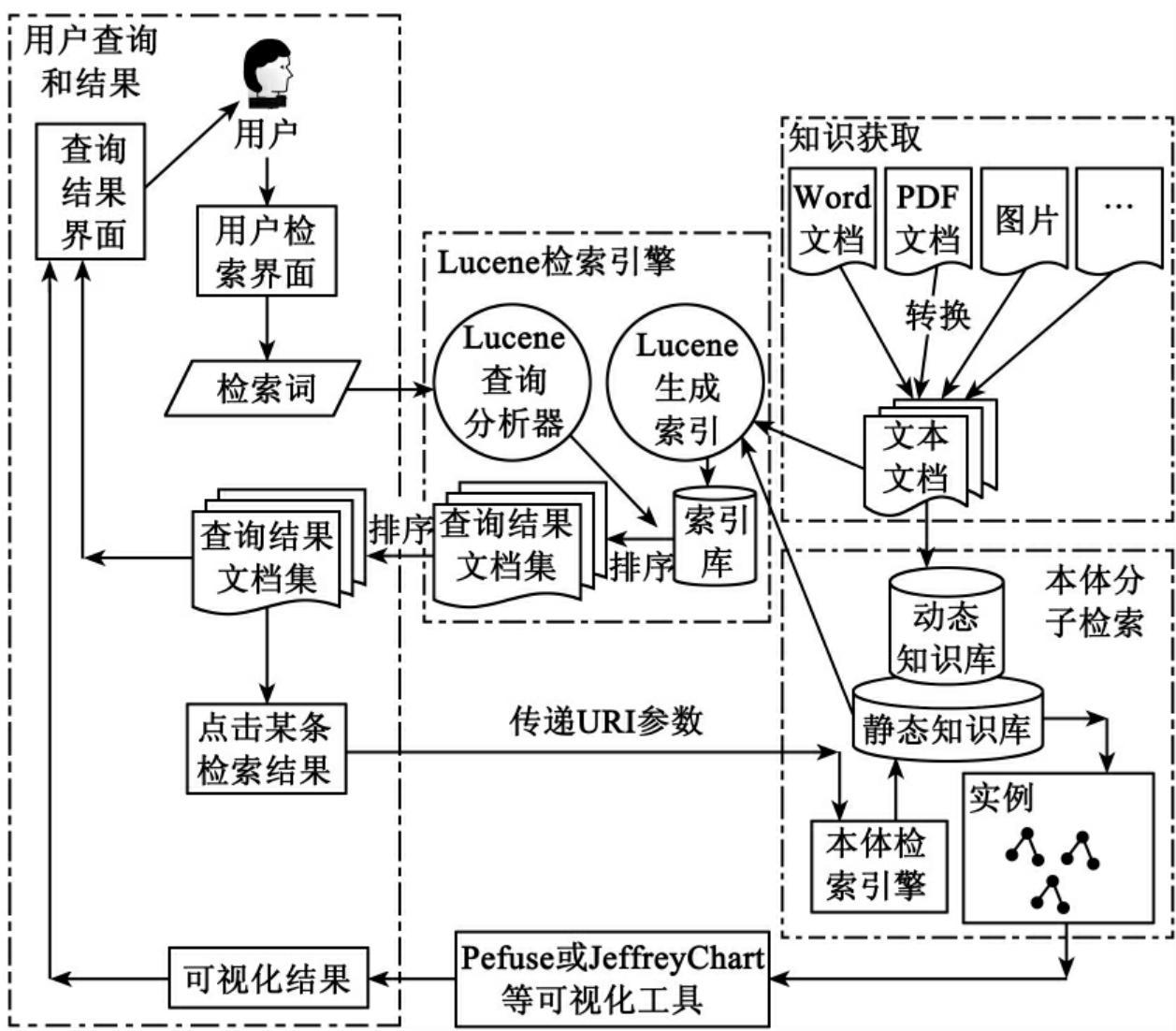
图20 基于本体分子的动态知识检索模型
4.3 Lucene检索引擎
4.3.1 Lucene简介
Lucene[38]pache软件基金会Jakarta项目组的一个子项目,是一个开放源代码的高性能全文检索引擎工具包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
已经默认实现了一套强大的查询引擎,用户无需自己编写代码即使系统可获得强大的查询能力,Lucene的查询实现中默认实现了布尔操作、模糊查询(Fuzzy Search)、分组查询等。
4.3.2 建立Lucene索引
为了对文档进行索引,Lucene提供了五个基础的类,它们分别是Document,Field,Analyzer,Index Writer,Directory。下面我们分别介绍一下这五个类的用途。[39]
(1)Document
Document是用来描述文档的,这里的文档可以指一个HTML页面,一封电子邮件,或者是一个文本文件。一个Document对象是由多个Field对象组成的。可以把一个Document对象想象成数据库中的一个记录,而每个Field对象就是记录的一个字段。
(2)Field
Field对象是用来描述一个文档的某个属性的,比如一封电子邮件的标题和内容可以用两个Field对象分别描述。
(3)Analyzer
在一个文档被索引之前,首先需要对文档内容进行分词处理,这部分工作就是由Analyzer来做的。Analyzer类是一个抽象类,它有多个实现。针对不同的语言和应用需要选择适合的Analyzer。Analyzer把分词后的内容交给Index Writer来建立索引。
(4)Index Writer
Index Writer是Lucene用来创建索引的一个核心的类,其作用是把一个个的Document对象加到索引中来。
(5)Directory
这个类代表了Lucene的索引的存储的位置,这是一个抽象类,它目前有两个实现,第一个是FSDirectory,它表示一个存储在文件系统中的索引的位置。第二个是RAMDirectory,它表示一个存储在内存当中的索引的位置。
图21就是Lucene的索引文件的概念结构。Lucene索引index由若干段(segment)组成,每一段由若干的文档(document)组成,每一个文档由若干的域(field)组成,每一个域由若干的项(term)组成。项是最小的索引概念单位,它直接代表了一个字符串以及其在文件中的位置、出现次数等信息。域是一个关联的元组,由一个域名和一个域值组成,域名是一个字串,域值是一个项,比如将“标题”和实际标题的项组成的域。文档是提取了某个文件中的所有信息之后的结果,这些组成了段,或者称为一个子索引。子索引可以组合为索引,也可以合并为一个新的包含了所有合并项内部元素的子索引。我们可以清楚地看出,Lucene的索引结构在概念上即为传统的倒排索引结构[40]。

图21 Lucene索引文件概念结构图
4.3.3 Lucene检索引擎在动态知识检索中的应用
Lucene以其开放源代码的特性、优异的索引结构等优点获得了越来越多的应用。在基于本体分子的动态知识组织模型中也充分应用了Lucene的这一优势。
利用Lucene开发包为文档库和本体库建立索引,为文档库建立索引后,就可以通过Lucene检索引擎对文档库进行基于关键词匹配的全文检索,为本体库建立索引后,可以使通过关键词匹配检索到的结果与本体库中相应的URI建立映射关系,为下一步基于本体分子库的关联检索及动态知识演变过程检索做好准备。
5 本体应用环境的应用
本体应用环境是一个完整的且可组装的架构,它能够有效指导基于本体的应用系统的设计与实现。而在应用本体应用环境的具体领域时,又可灵活地组装。例如,只有静态知识的系统,本体分子库就是本体库,和开发一般的本体应用系统一样;对于既有静态知识又有动态知识的系统,就需要加入扩展部分的框架。下面介绍的两个实例正是这两种应用的代表。
5.1 基于本体的数字图书馆信息检索模型研究
“基于本体的数字图书馆信息检索模型研究”,是我们承担的国家自然科学基金资助项目(批准号:70373047)。该项目研究以历史领域(国共两党第二次合作时期)为突破口,将本体应用环境应用于数字图书馆领域,解决了对人物、事件等复杂关系的揭示与检索问题;通过推理机制丰富了本体库的内涵,完善了知识发现、组织、管理功能,提高了知识检索深度;本体可视化颇具特色,描述形式丰富多样、形象生动,静态和动态的可视化方式使用户操作更加直观、便捷。
“基于本体的数字图书馆信息检索模型研究”,从知识管理这个角度看,由于历史资源是一个不变的知识集合,所以它要解决的只是静态知识的管理问题,因此,系统的本体应用环境框架,是一个无本体分子的静态知识管理模型,如图22所示。
后台环境中的数据源来自《国共合作通史五卷本》和《中国革命历史文献采集标准》等,近百万字。这些数据的特点是:
(1)国共合作领域知识属于人文历史学科,这个学科内的知识大部分都是已经发生过的静态知识。
(2)国共合作历史时期时间跨度长,内容繁多,史料浩瀚,但为了集中表现合作特点,我们选择了第二次合作期间的人和事。
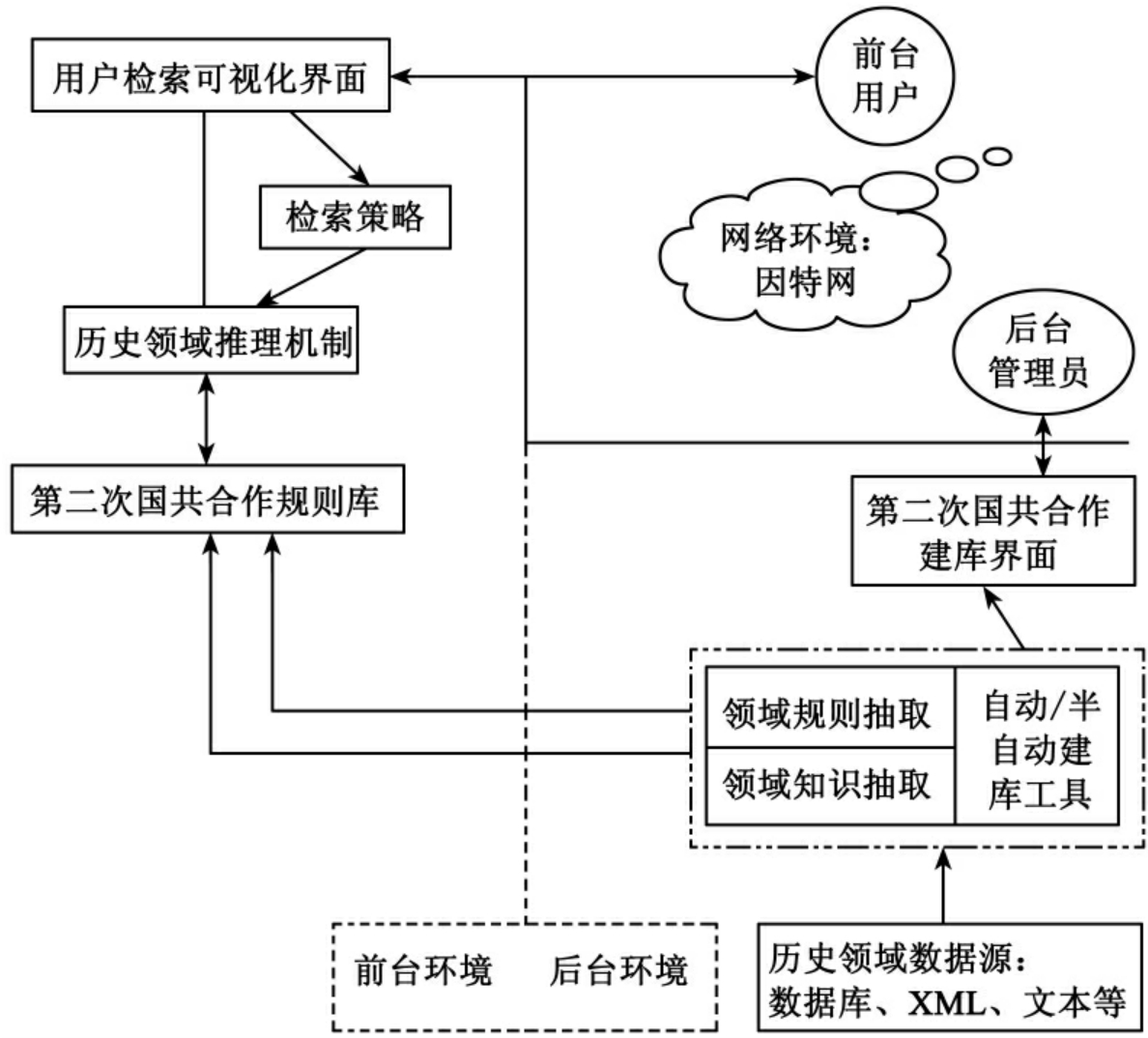
图22 基于一个领域静态知识管理的本体应用框架图
(3)国共两党关系纷繁复杂,牵扯甚广。
为了描述这段特定历史阶段的知识,项目采取OWL本体技术构建了本体知识库,并通过Jena自定规则技术构建了推理规则库。
本体库包括了167个本体类(其中核心类有六个:事件(Event)、资源(Resource)、组织(OrgActor)、人物(IndiviActor)、时间(Time)、地点(Location)、108个关系属性、100个推理属性和13838个实例,其中事件本体实例769个,资源本体实例683个,组织本体实例984个,人物本体实例2137个,地点本体实例1026个,时间本体实例3645个,角色类实例2838个,其他类实例4567个。平均关系复杂度为5。推理规则库包含静态规则102条,动态规则5条,推理规则库包括人物关系推理规则54条,地理方位关系推理规则15条,事件发展演变关系推理规则14条,资源关系推理规则4条,与时间有关推理规则16条,组织演变规则4条。
在知识推理方面,根据本体的推理机制可在两类中进行选择:即基于逻辑的领域知识检测推理和基于关系的蕴涵知识发现推理。基于逻辑的领域知识检测推理,主要是在OWL语言的逻辑基础-描述逻辑的基础上,运用TABLEAU算法,对我们前期所构建的国共关系领域的概念层次、声明的实例以及实例间复杂的语义关系进行检测,以保证本体库结构的逻辑一致性和知识描述的正确性,为后续的蕴涵知识推理、本体库的拓展以及与其他领域本体库的集成提供逻辑保证。基于关系的蕴涵知识发现推理的主要思想就是在国共合作领域本体库的概念层次与属性关系的基础上,采取规则推理策略,在本体库中进行模式匹配。在推理过程中,主要考虑概念与概念之间关系(超类、子类、成员、部分等关系)、概念与个体关系(实例关系)、实例与实例的关系(亲缘、同事、相关、包含关系等)以及对象属性关系(父子、传递、互逆、对称关系等)。在蕴涵知识发现推理中,可以判断一个个体是否是某个或多个类的实例、判断某个类中所有的实例、判断两个实例之间的关系、判断与某个实例有特定关系的实例、类(属性)的层次体系结构推理等,根据本项目的特点和领域专家的建议,我们选择了基于关系的蕴涵知识发现推理,并建立了107条推理规则(图23)。
前台环境的检索入口主要包括:列表检索、本体检索、关系检索(可选择关系的深度为1到5)、推理检索、回溯检索等。
由于本项目是针对历史这个特定领域,不需要领域分析器的方法将检索请求分配到各个领域。
本体推理检索是本系统最有特色的一个检索方式,这种知识层次的推理是以往任何一种信息层次的数据库系统所无法做到的。系统除了提供本体推理检索的结果之外,还对本体推理路径进行回溯,即利用文本和可视化相结合的方式展现推理过程。如图23所示,“曾祖母”关系的边呈黄色,表明它已经被展开。展开之后视图中出现了三条粉红色的边,这三条边把“毛新宇”、“毛岸青”、“毛泽东”、“文七妹”这四个本体连接了起来。我们把鼠标放到任何一个粉红色的边上来查看它的标签,显示的结果是“子女有”。通过这种可视化的表现方式,用户能够形象地了解推理的过程:由于“文七妹”的“子女有”“毛泽东”,“毛泽东”的“子女有”“毛岸青”,“毛岸青”的“子女有”“毛新宇”,而且“文七妹”是女性,所以推理出“毛新宇”的“曾祖母”是“文七妹”。另外,在展开推理关系之后,在系统的中间部分还显示出“推理路径回溯”的相关文字说明,主要包括“推理规则”和“推理依据”。
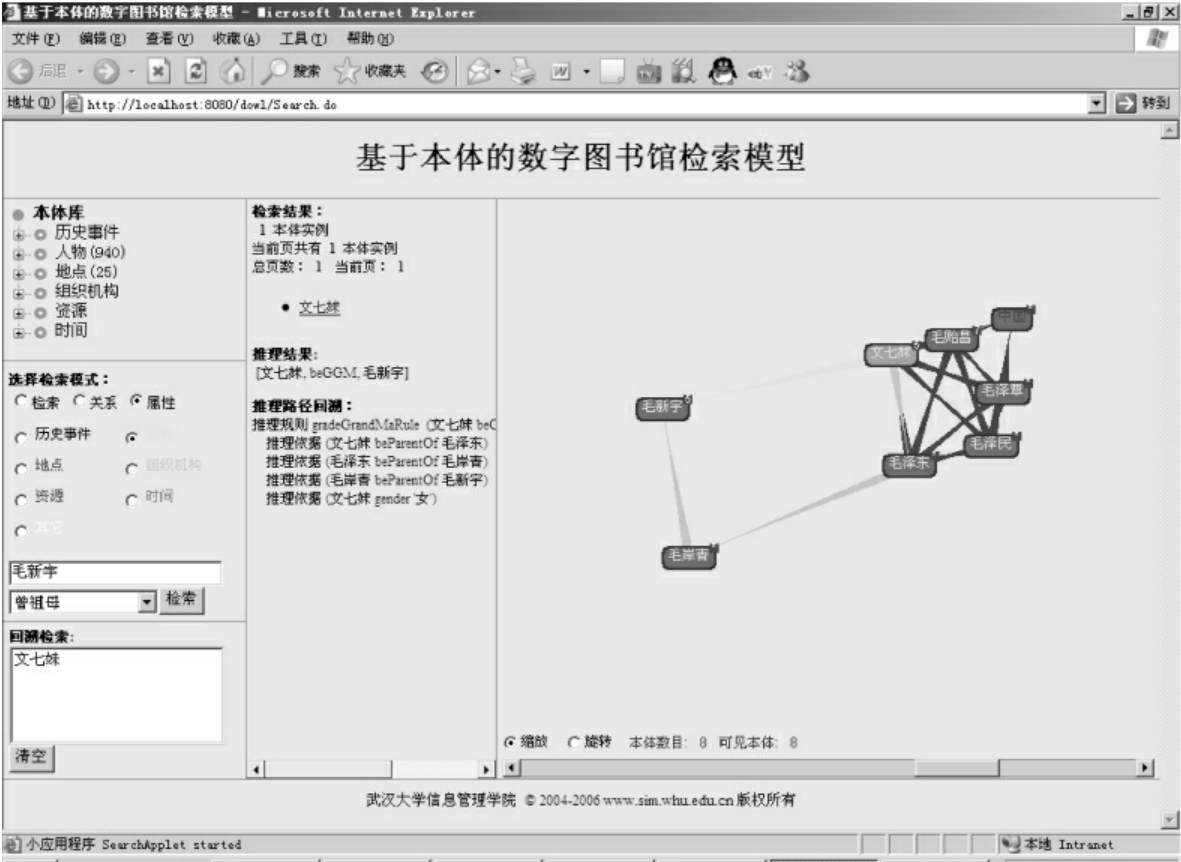
图23 本体推理以及本体推理路径回溯
5.2 基于数字图书馆的本体演化和知识管理研究
“基于数字图书馆的本体演化和知识管理研究(批准号:70773087)”,是国家自然科学基金资助项目,即本课题的研究项目,该项目以数字图书馆在电子政务中的应用为背景,研究电子公文应用过程中知识管理及其演变。因此,该项目与前一个项目相比是不同的,他们对知识的管理属不同类型,该项目知识管理的内容不仅仅有静态知识,更重要的还有动态知识,即采用了本体分子理论对知识管理的方法,其本体应用环境框架如图24所示。
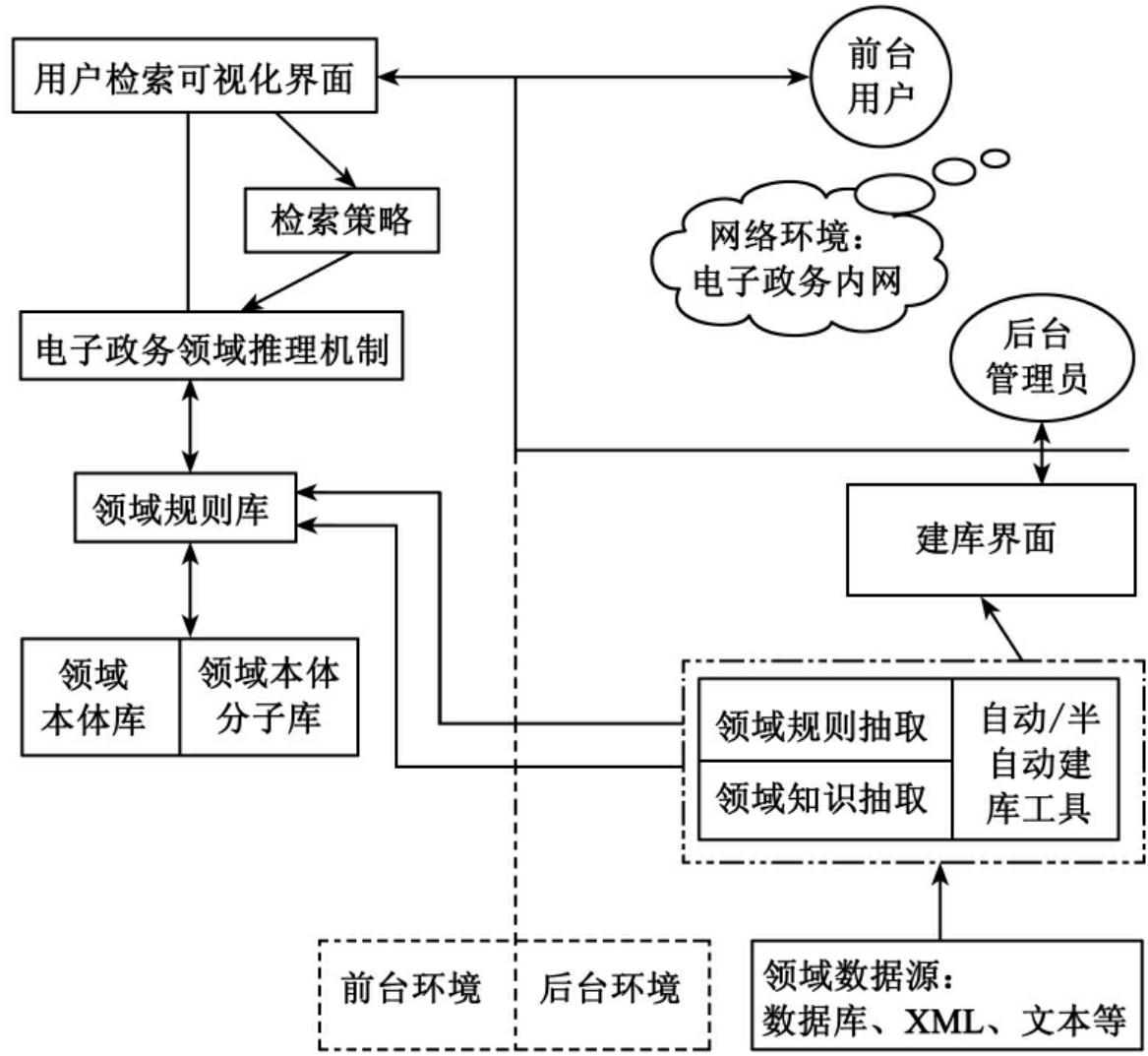
图24 基于一个领域动态知识管理的本体应用框架图
本项目关于静态知识的采集、组织、存储等与一般本体库的建设一样,它所不同的是关于动态知识采集、组织和存储方法及措施。本项目提出了“知识组织四层模型MRID”,即元数据层、知识表示层、知识表示层和动态知识层。动态知识主要是:动态三元组、三元组标识符和三元组维度构成。根据本体分子理论开发了一个本体分子建库的工具——OMProtegePlugin,该工具具有:本体分子持久化、本体分子建库工程、动态三元组、核子和离子和本体分子等管理功能。这些功能较好地完成了对动态知识的管理,并建立了动态与静态知识间的互动机制。以上研究内容在本系列论文Ⅱ——动态知识组织中,进行了详细论述,在此不再赘述。目前,本项目的电子政务公文本体库包含了25个本体类、17个关系属性和26128个实例,其中文件类11887个实例,条目类13821个实例,问题类7个实例,组织机构类402个实例,问题反映类11个实例;电子政务公文本体分子库包含了45个本体分子、25个核子和45个离子。核子中的三元组个数平均约为20个;离子中的三元组个数平均约为50个。
数字图书馆在电子政务中的应用,其知识管理必须遵循该领域的规则。规则就是制定推理机制的核心,例如,中央下发的文件(本项目研究的文件属非密级文件),对省级政府来说,是无权进行任何修改的。省级制定的文件在执行中可进行修改、补充,甚至对整个文件或某些条文进行更正等。根据规则,将中央文件和省级贯彻中央文件精神可构成的一个本体分子,如图25所示。
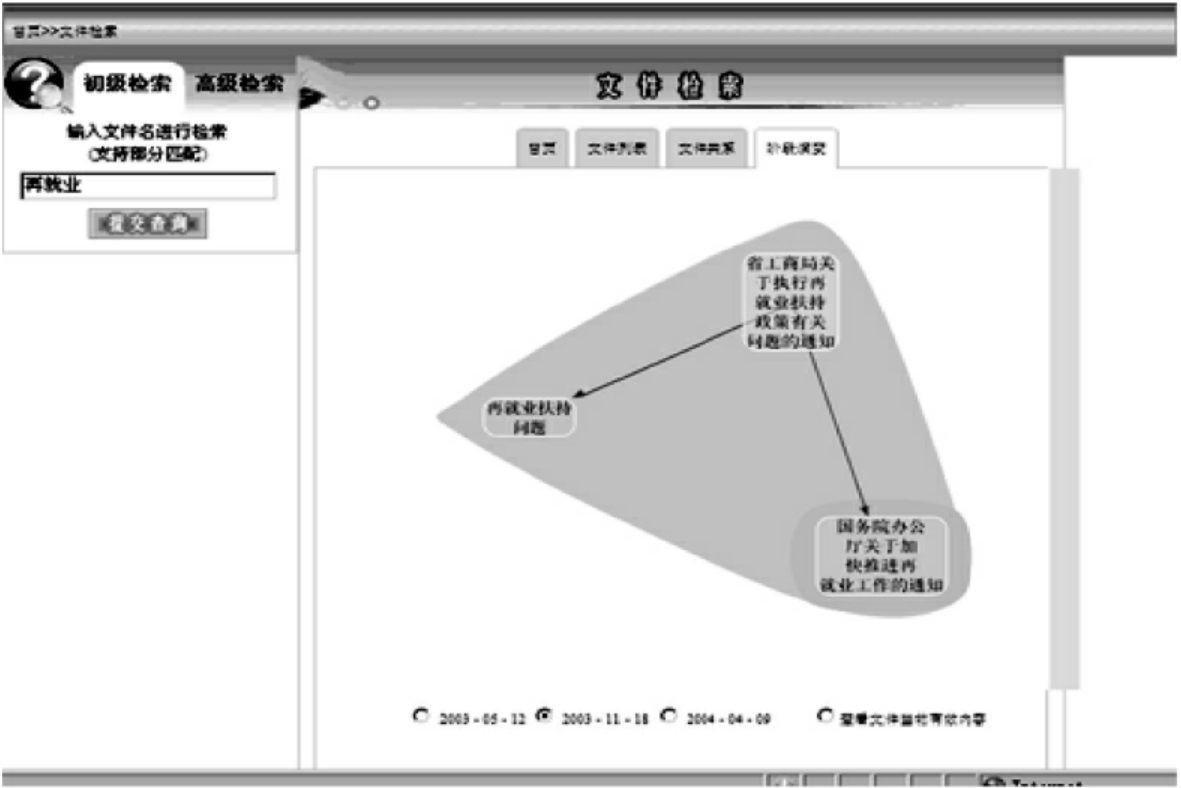
图25 本体分子示意图
前台检索策略,用户可以选择“一般检索”和“高级检索”两种方式检索文件,一般检索是使用关键词匹配文件名,高级检索进行更多的元数据匹配(如:发布者、检索号、责任人等)。用户检索到文件之后,还可以选择“文件关系检索”、“条目检索”、“条目关系检索”、“文件阶段演变检索”和“条目演变检索”等。
“文件关系检索”、“条目检索”、“条目关系检索”等都是针对知识库中静态知识的检索,后两种针对动态知识的检索:
“文件阶段演变检索”是指对于本体分子描述的文件变化动态过程的检索。例如,对于“再就业”问题,中央以及湖北省制定了相关政策和规定。如图25所示的单选按钮,它包括三个演化阶段:
· 2003-05-12:中央制定了《国务院办公厅关于加快推进再就业工作的通知》
· 2003-11-18:湖北省在“再就业”这个问题上,贯彻了中央制定的《国务院办公厅关于加快推进再就业工作的通知》精神,结合本地特殊情况制定了《省工商局关于执行再就业扶持政策有关问题的通知》
· 2004-04-09:湖北省由于某些原因,制定了《省工商局关于执行再就业扶持政策有关问题的补充通知》,对上一个文件作了补充。
用户通过点击单选按钮选择时间阶段,进而检索出关于“再就业”问题各个不同时间阶段电子公文的演化过程。
图25所示的是该演化过程中第二个阶段的内容。它包括两个本体分子,一个橙色聚集和一个褐色聚集。对于褐色那个本体分子,它的“核子”是《国务院办公厅关于加快推进再就业工作的通知》这个文件,因为这个文件是中央制定的,对于湖北省来说是不能修改的。而它的“离子”(《省工商局关于执行再就业扶持政策有关问题的通知》)是具地方特色的可变部分。
针对电子公文的随时间的变化在原来的基础上产生相应变化的情况,系统提供“条目演化检索”检索功能。整个过程运用不同的线条颜色代表了保留,继承,修改,删除等文件的多种关系。
6 结语
在国家自然基金委资助的“基于本体的数字图书馆信息检索模型研究”项目中,我们较好地解决了中文的本体建库、本体检索、本体推理和本体可视化,并提供了通用程序接口,建立了一个可操作的本体平台。特别是在中文本体领域多种检索模型、推理机制和本体应用结合等方面具有创新性,达到国际领先水平(湖北省科技厅科技成果鉴定意见)。研究中我们也遇到了本体技术本身无法解决的问题,如基于本体的知识管理存在三方面的不足:(1)动态知识问题,(2)相对知识问题,(3)多粒度知识问题。动态知识的控制和管理就是一个较大的问题,如何表现动态知识的动态过程等问题,为此,提出了本体分子理论,实践证明该理论的确能解决知识管理中一些问题。本体分子理论的创建了一个新的本体运行环境,即本体应用环境。本文对该环境的重要部分,即本体分子理论、基于语义关系的本体推理和基于本体分子的动态知识检索机制进行了论述,并对应用该环境的两个项目进行了实例分析。
从两个应用项目可以看出,不论是静态知识还是动态知识,本体应用环境都能够较好地建立整个应用系统。本体应用环境的主要优势在于:
①本体应用环境是一个完整的体系结构,不仅包括理论基础,还包括可实际应用的API组件。
②本体应用环境中的本体分子理论和组件可以很好地解决动态知识问题,它是对本体理论的补充和扩展。
③本体应用环境面向实用,不要求全部实现框架中的所有组件,用户可以根据领域需求自主选择和组装部分组件。这种松散耦合的灵活架构能够满足大部分领域应用。
为了完善该环境,我们还有许多工作要做,特别是对其形式化的描述、算法的论证和应用到使用系统等。
【参考文献】
[1]董慧,赵霞.基于语义网的本体转换模型研究[J].情报学报,2006(2):36-42.
[2]Tim Berners-Lee,James Hendler & Ora Lassila.The Semantic Web[J].Scientific American,2001(5).
[3]W3C.Semantic Web Activity Statement.W3C Publication[EB/ OL].[2007-07-05].http:∥www.w3.org/2001/sw/Activity.
[4]OWL Web Ontology Language Reference[EB/OL].[2007-07-05].http://www.w3.org/TR/owl-ref/.
[5]Lassila,O.,Swick,R.(1999).Resource Description Framework(RDF)Model and Syntax Specification.[EB/OL].[2007-07-05].http://www.w3.org/TR/rdf-syntax-grammar/.
[6]McGuinness,D.L.,Van Harmelen,F..OWL Web Ontology Language Overview[EB/OL].[2007-07-05].http://www.w3.org/TR/owl-features/.
[7]John Davies,Frank van Harmelen & Dieter Fensel.Towards the Semantic Web:Ontology-driven Knowledge Management.[M].John Wiley & Sons.2002.
[8]Brickley,D.,Miller,L..FOAF:the“friend of a friend”vocabulary.[EB/OL].[2008-01-02].http://xmlns.com/foaf/0.1/.
[9]Knublauch,H.,Fergerson,R.W.,Noy,N.,Musen,M.A..The Protégé OWL Plugin:An Open Development Environment for Semantic Web Applications[C].Third International Semantic Web Conference(ISWC 2004).
[10]Buitelaar,P.,Olejnik,D.,Sintek,M..OntoLT:A Protege Plug-in for Ontology Extractionfrom Text.Proceedings of the International Semantic Web Conference(ISWC 2003).
[11]Celjuska,D.,Vargas-Vera,M..Ontosophie:A Semi-automatic System for Ontology Population from Text.International Conference on Natural Language Processing(ICON 2004).
[12]Soderland,S.(1997).Learning to Extract Text-based Information from the World Wide Web[C].Proceedings of Third International Conference on Knowledge Discovery and Data Mining.(KDD 97).
[13]Jeffrey Zeldman.Designing with Web Standards[M].New Riders Publishing,Thousand Oaks,CA,2003.
[14]TouchGraph LLC.TouchGraph[EB/OL].[2008-01-02].http://www.touchgraph.com/.
[15]Jeffrey Heer.Prefuse:Toolkit Structure Introduction[EB/OL].[2007-02-25].http://prefuse.org/doc/manual/introduction/structure/.
[16]韩莉.图书馆引进知识管理初探[J].图书馆论坛,1999(3),56-57.
[17]汤珊红,新世纪图书馆知识管理的特征、内容及相应的实现技术[J].现代图书情报技术,2000(2):3-6.
[18]刘茂生.图书馆知识管理管见[J].中国图书馆学报,2000(4).
[19]姜永常.再论图书馆的知识管理及其实施策略.图书馆,2001(1):26-28.
[20]邱均平、沙勇忠、刘焕成.论数字图书馆的知识管理[J].情报资料工作,2001(5):5-7.
[21]王海娟.图书馆与知识管理[J].图书馆的知识管理.图书与情报,2002(3):2-4.
[22]王杏允、刘海燕.图书馆与知识管理[J].经济论坛,2002(14):30.
[23]李敏.论数字图书馆的知识管理[J].图书馆理论与实践,2002(4):5-7.
[24]张健萍.知识管理与图书馆.情报科学,2003(9):932-934.
[25]胡艳荣、欧群.谈图书馆知识管理[J].河南财政税务高等专科学校学报,2003(1):52-54.
[26]崔波.论高校图书馆知识管理的内容和作用[J].高校图书馆工作,2004(4):13-17.
[27]李刚.高校图书馆知识管理研究综述[J].常州工学院学报,2004(5):93-96.
[28]赵全红.论图书馆知识管理的主要内容和实施策略[J].河北科技图苑,2005(4):28-31.
[29]冯丽雅.图书馆知识管理的主要内容及实施策略[J].科技情报开发与经济,2006(6):38.
[30]李轶.知识管理在图书馆中的应用[J].科技广场,2006(7):87.
[31]李力.现代图书馆知识管理的内容与实施策略研究[J].现代情报,2007(3):96-99.
[32]朱华琴.关于图书馆知识管理的研究[J].现代情报,2008(2):108.
[33]丁学淑.1999—2008年图书馆知识管理研究文献计量分析[J].江西图书馆学刊,2009(4):122-128.
[34]杨云.图书馆知识管理的特点和实施对策[J].华医学图书情报杂志,2010(2):17-19.
[35]Neches,R.,et al.Enabling Technology for Knowledge Sharing[J].AI Magazine,12(3).
[36]InstOn,M.,Chaffin,R.,Herrmann,D..A Taxonomy of Part. Whole Relations[J].Cognitive Science,1987(11).
[37]王兰成,曾琼.基于本体的知识检索模型及呈现技术研究[J].图书情报工作,2009(3):98-100.
[38]what is lucene[EB/OL].[2009-08-22].http://lucene.apache.org/.
[39]周登朋.初识Lucene[EB/OL].[2009-08-22].http://www.ibm.com/developerworks/cn/java/j-lo-lucenel/.
[40]董祥千.搜索引擎设计分析与结果聚类改进[D].电子科技大学硕士学位论文,2007.
【作者介绍】
董慧,男,武汉大学信息管理学院教授、博士生导师、武汉大学信息资源研究中心研究员、中国电子商务咨询专家委员会专家、湖北省电子政务专家组专家、国家自然基金委员会项目评议人、教育部科技奖励评审专家,享受国务院特殊津贴。从事信息管理与信息系统、数字图书馆工程、本体与数字图书馆、语义网和网格等领域的教学与科研工作20余年。

先后主持国家自然基金委、国家社会科学基金委、教育部、国家档案局、湖北省人民政府、宜昌市人民政府和有关单位资助项目十多项,其中国家自然基金项目“基于本体的数字图书馆信息检索模型研究(批准号:70373047)”获得优秀成果奖,同时,还获得高等学校科学研究优秀成果奖(人文社会科学)三等奖,国家档案局优秀科技成果二等奖、多项三等奖,湖北省科技进步二等奖、三等奖、湖北省教学成果一等奖等。发表论文100余篇,出版著作8部。
董慧教授将本体引入情报学、图书馆学、档案学,并得以应用。在本体应用研究领域,为解决动态知识管理和控制问题,提出了本体分子理论,丰富了本体应用领域的基础理论研究,受到了海内外专家学者的高度重视,获得极高评价。专家们认为:“基于本体的数字图书馆检索模型研究(国家自然基金项目)”的“研究成果系统、完整,总体上处于国际先进水平,特别是在中文本体领域多种检索模型、推理机制和本体应用结合等方面具有创新性,达到国际领先水平(湖北省科技厅科技成果鉴定会评语)”。将本体应用档案学,得到了同行专家的高度评价,认为档案学理论,我国自己提出来的还很少,而“档案本体分子论”的提出应该是一个很大的创新,实践上也比较超前(“知识管理技术方法在数字档案馆建设中的应用研究[国家档案局资助项目]”国家档案局科技成果鉴定会评语)。
姜赢,男,1981年生,博士,研究方向为本体应用,参加了国家自然基金委、教育部、国家档案局等资助的多项课题的研究,参与了“十一五”国家重点图书——《本体与数字图书馆》的编写工作,撰写相关论文30多篇。获得第12届欧洲数字图书馆国际会议(ECDL 2008)最佳学生论文奖(Best Student Paper Award),国家自然基金项目“基于本体的数字图书馆信息检索模型研究”获得优秀成果奖,同时,还获得高等学校科学研究优秀成果奖(人文社会科学)三等奖,国家档案局优秀科技成果二等奖、多项三等奖,湖北省科技进步三等奖以及获国家档案局优秀科技成果二等奖等。在本体应用研究方面成果突出。
王菲,女,1976年出生,武汉大学讲师,博士,研究方向是情报学(信息系统工程),参加了国家自然基金委、教育部、国家档案局等资助的多项课题的研究,参与了“十一五”国家重点图书——《本体与数字图书馆》的编写工作,撰写相关论文多篇。曾获国家档案局优秀科技成果二等奖等。在知识组织和数据库建设方面的研究取得了突破性的进展,且在实际应用方面取得成果。
周义刚,女,1977年生,博士,曾任湖北大学图书馆技术部主任,湖北省高校图工委自动化专业委员会委员、湖北省高校数字图书馆项目系统组委员。参与了国家自然科学基金委、教育部和国家档案局等资助的多项课题的研究。发表相关论文9篇,其中1篇国内权威、1篇被EI检索、5篇被ISTP检索、2篇收录CSSCI。在动态知识组织模型和动态知识检索等方面的研究有所突破,特别是在理论模型的探讨上突出。
俞思伟,男,1966年生,武汉大学中南医院副主任技师,武汉大学信息资源研究中心研究员(兼职)。华中理工大学计算机学院计算机应用专业毕业,工学学士;武汉大学信息管理学院研究生毕业,管理学硕士;武汉大学信息管理学院博士。现任中华医学会医学教育分会信息技术学组组长,中国医院协会信息专业委员会委员、中国医药信息学会专家委员会委员、《医学信息》杂志编委。1989年起从事医院信息系统的开发和研究工作,具有丰富的医院信息系统开发和建设经验。在信息系统开发和管理、知识管理、电子政务建设等方面具有较深的造诣。参与多项国家自然科学基金、社会科学基金等项目的研究工作,对当前信息管理领域的前沿性技术和理论有相当的把握,在权威、核心杂志及国际、全国性学术会议上发表论文30余篇。
徐国虎,男,1977年生,博士,研究方向为本体推理,参加了国家自然基金委、教育部、国家档案局等资助的多项课题的研究,参与了“十一五”国家重点图书——《本体与数字图书馆》的编写工作,出版著作一部,发表相关论文11篇,获得高等学校科学研究优秀成果奖(人文社会科学)三等奖,国家档案局优秀科技成果三等奖,湖北省科技进步二等奖、三等奖等。在本体推理研究方面提出了许多具有创新性的看法,得到了同行专家的肯定。
【注释】
[1]本文属国家自然科学基金资助项目“基于数字图书馆的本体演化与知识管理研究”(批准号:70773087,2008—2010)成果之一。
[2]董慧,姜赢,高巾等.基于数字图书馆的本体演化和知识管理研究Ⅰ——本体分子理论[J].情报学报,2009(3):323-330.
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










