



个性化信息服务研究进展[1]
陆 泉 胡慧丽 邓 晶 陈德照
(武汉大学信息资源研究中心)
【摘 要】 个性化信息服务是信息服务的主要研究方向之一,其研究及应用领域极其广泛。本文首先对个性化信息服务的研究内容和发展概况进行了分析,然后对个性化信息服务的方法体系、支撑技术和应用现状展开述评,最后总结了个性化服务应用的障碍因素,并对个性化服务的应用前景进行了展望。
【关键词】 个性化信息服务 方法体系 支撑技术 应用现状 发展趋势
The Progress on Studies of Personalized Information Service
Lu Quan Hu Huili Deng Jing Chen Dezhao
(Center for Studies of Information Resources,Wuhan University)
【Abstract】 Personalized information service has become one of the mainstreams of current information service studies,which has been widely studied and used in many fields.The paper first makes an analysis of the research contents and development of personalized information service,and then makes a review about its methodology,supporting technology and the status quo.Last it summarizes the barriers to the application of personalized information service and makes a prospect for its application.
【Keywords】 personalized information service methodology supporting technology status quo trend of development
1 引言
进入21世纪以来,人们面临的是一个提倡张扬个性、追求创新的时代。与之相适应的是,个性化信息服务经过了过去十多年的发展,无论在理论研究还是实践领域上都取得了很大的进展。个性化信息服务研究已经成为引领信息服务向纵深发展的一个重要课题,它是实践“用户至上”服务理念与“广、快、准、精”信息服务目标的重要保证。
1.1 个性化信息服务的概念和特点
1.1.1 个性化信息服务的概念
个性化信息服务是当前图书情报工作和信息检索服务领域的研究热点之一,其研究和应用受到了业界的广泛关注。它体现了对用户的人性化、知识化关怀,强调了信息服务的针对性、连续性和专业性,也是打造21世纪知识服务和知识创新体系的重要组成部分。
个性化信息服务又称个性化服务。迄今为止,对个性化服务尚未有公认的定义。不同学者在不同的研究背景下给出了不同的描述,也就是对“个性化服务”的定义有着“个性化观点”。其中具有代表性的有以下这些:
(1)个性化服务是通过一个有意义的一对一的关系来建立客户的忠诚度,通过了解每一个人的需求,从而正确有效地处理每个人在特定情况的需求(Riecken,2000)[1]。
(2)Blom(2000)将个性化服务定义为一个通过改变系统的功能、界面、信息内容以及独特性来增加系统与用户的关联性的过程[2]。通过个性化服务可以让用户对系统的态度产生积极的影响,提高他们重复使用系统的趋势(Blom and Monk,2003)[3]。个性化服务还可以促进用户自治,提高用户能力以及维持用户与其他人之间的紧密联系和关联[4]。
(3)个性化信息服务是基于信息用户的信息使用行为、习惯、偏好和特点,向用户提供满足其各种个性化需求的一种服务(史田华,2002)[5]。
(4)个性化信息服务是根据客户的特性提供具有针对性的信息内容和系统功能(薛菘,2002)[6]。
(5)个性化信息服务是指能够满足用户个人信息需求的一种服务,在某一特定的网上功能和服务方式中,通过用户自己设定网上信息来源方式、表现形式、特定网上功能及其他网上服务方式等,而能主动地向用户提供可能需要的信息服务(王悦,2002)[7]。
(6)个性化信息服务就是能够满足用户个性化信息需求的一种服务,它通过对用户信息需求、兴趣爱好、使用习惯和访问历史的收集分析,建立用户模型,并将用户模型应用于网上信息的过滤和排序,从而指导用户浏览、检索信息或向用户主动推送信息(李勇,2002)[8]。
(7)所谓个性化信息服务就是根据用户知识结构、信息需求、行为方式和心理倾向,有的放矢地为用户提供创造符合个性需求的信息服务环境,为其提供定向化的预定信息与服务,并帮助用户建立个人信息系统(于迎,2003)[9]。
(8)与以上(5)的观点类似,只不过指出网络个性化信息服务中作为互联网络使用者的个人目的是为了达到最为方便快捷地获取自己所需的网上信息服务内容(王富民,2003)[10]。
(9)个性化信息服务是一种调整信息和服务使之与个人或社区的独特需求相匹配的方法,它是以用户的任务、背景、历史、设备、信息需求、地点以及用户所处的环境为基础,以合适的方式向其提供合适的内容或服务(Callan,2003)[11]。
(10)个性化信息服务,首先应该是能够满足用户的个体信息需求的一种服务,即根据用户提出的明确要求提供信息服务,或通过对用户个性、使用习惯的分析而主动地向用户提供其可能需要的信息服务。其次,个性化信息服务也应该成为用户展现自我、宣传个性的一个窗口。具有一定个性的个体通常都有表现自我、表达自我,让他人了解自我的愿望。最后,个性化信息服务应该是一种培养个性,引导需求的服务,这样可以帮助个体培养个性、发现个性,引导需求,促进社会的多样性和多元化发展(丁浩,2005)[12]。
以上的这些概念尽管表述不一,但其核心内容基本上是一致的,即个性化信息服务是在了解用户的个性化需求的基础上提供有针对性的服务。
从用户的角度来看,个性化信息服务是用户可以对服务形式、内容、方式等提出符合自己兴趣和爱好的个性需求,从而获取符合自己个性需求的个性化服务。它强调的是个性化信息服务对用户需求的满足结果。
从信息服务机构的角度来看,个性化信息服务就是指针对不同用户的信息需求,满足用户不同需求的一个过程,也可以看成是一种信息服务机构和用户之间互动并体现服务价值的表现形式。它除注重服务的结果外,更主要强调的是个性化服务的过程,尤其是在整个服务过程中的一系列准备工作,包括对用户需求的挖掘及用户兴趣的发现,用户信息和信息资源的描述、信息服务技术方法和策略的制定等。
1.1.2 个性化信息服务的特点
个性化信息服务是一种面向用户深层心理需求的信息服务。它根据用户的知识结构、心理特征、信息需求和行为方式,创造出适应个人心理和行为的信息活动环境,充分激励用户的信息需求、支持用户习惯和行为方式,促进用户有效检索和获取信息,促进用户对信息的有效利用并在此基础上进行知识创新。与传统的信息服务相比,它有以下特点[13][14][15][16]:
(1)信息内容的针对性。个性化信息服务以用户为中心,通过研究用户的行为、兴趣、爱好和习惯来自动组织信息内容和调整服务模式,排除不相关信息的干扰,为其提供有针对性的且“量身定制”的个性化信息服务。
(2)传播方式的交互性。个性化信息服务是一种双向沟通的零距离信息服务[17]。个性化信息服务建立在互动的基础上,允许用户充分表达个性化需求和反馈对服务结果的评价;而系统可以根据用户的浏览情况,尽可能随时根据用户的反馈自动调整服务内容和服务方式,以迎合每个用户的需求和兴趣爱好,实现服务提供者与用户的交互。
(3)服务方式的灵活性。个性化信息服务系统不仅为用户提供符合其个性需求的各种信息,而且还按用户指定的服务方式、服务时间以及服务地点等来提供服务,为用户带来了时间和空间上的灵活性。
(4)服务理念的主动性。个性化服务从传统的“人找信息”转变为“信息找人”,通过采用先进的计算机、网络和通信技术,主动感知用户的使用规律和信息需求,及时将用户需要的信息推送给用户,从而突破时空界限,自动地为大范围、多层次的用户开展信息服务。其推送形式有频道推送、电子邮件推送、网页式推送和专用推送等形式。推送模型已经发展成为信息采集和传播的主流模式。
(5)智能性和高效性:个性化信息服务中采用了推理反馈、机器学习和智能代理等人工智能技术,能够通过跟踪和学习用户的兴趣偏好和使用模式,建立用户模型和信息模型,不断挖掘用户潜在的兴趣特征,实现信息的智能推荐和智能过滤,从而显著提高信息服务质量。
1.2 个性化信息服务的主要内容
个性化信息服务研究集成了许多新兴的计算机科学研究领域(如数据挖掘,人机交互等),以及已建立了计算机科学研究领域(如信息检索,数据库,图形学,数值分析等)。因此,个性化信息服务包括的内容十分庞杂,不同学者和组织有不同的认识和理解。这些研究有助于我们更好地认识个性化信息服务的内容。
文献[18]从服务方式的角度,将个性化信息服务分为3个方面的内容:服务时空的个性化,要求按用户信息需求的时空变换组织面向用户的服务;服务方式的个性化,要求按用户个体利用信息的方式来组织服务;服务内容的个性化,要求按用户信息需求认识和表达的个性特征组织服务。
文献[19]从用户的角度,系统阐述了个性化信息服务的主要内容包括用户研究、定制机制和推荐机制。
文献[20]认为个性化信息服务包括两方面内容:个性化信息和个性化服务。个性化信息是反映个体个性特征的一切信息,同时还包括个体特定的信息需求组合。个性化服务包括服务时空的个性化,服务方式的个性化和服务内容的个性化。个性化信息服务不仅能对用户提出的要求提供最贴切的信息服务,还能依据个体个性特征,主动收集个体可能感兴趣的信息,甚至预测个体可能的个性发展,提前收集相应的信息,最后以个性化方式显示给个体。
文献[21]从技术实现的角度,说明个性化信息服务涉及以下4个主要内容:信息资源描述、用户建模(User Modeling)、个性化信息推荐和系统的体系构建。
信息资源描述是进行个性化信息服务的前提条件。它主要是对各种信息资源的内容进行特征描述,最后用结构化的形式加以保存,作为文档的中间表示形式。
用户建模是个性化信息服务的核心内容,因为构造个性化信息服务系统首要任务是把用户的个性信息需求表达明确清晰,而用户模型则是将这一需求进行形式化描述的最好方法。用户模型准确地描述用户的兴趣,刻画用户的特征以及与其他用户之间的关系等,一般表示为一个用户描述文件(user profile)。通常用户的描述与资源的描述密切相关。用户模型中用户个性化特征信息需要先通过用户识别,再对用户兴趣挖掘才能得到。用户识别是个性化信息服务的基础,不能识别出用户,用户兴趣挖掘、个性化推荐都无从谈起。用户兴趣挖掘通常是根据用户自己制订的兴趣,或者系统提供示例让用户选择,并通过对用户选择的示例文档进行分析确定用户的兴趣。一般是通过人机交互和用户检索行为的挖掘两种方式获取用户的个性化信息,在此基础上建立用户信息库,通过长期的信息积累以及对信息的分析,可以获取用户的个性化需求特点从而建立用户模型。
个性化信息推荐是根据用户需求和喜好,为用户推荐可能感兴趣的信息。其原理是先通过个性化搜索引擎寻找相关信息,同时根据在用户模型库中寻找相应的用户兴趣集,利用已有的用户兴趣对搜索到的结果进行匹配,或者寻找具有相近兴趣的用户群而后相互推荐其感兴趣的信息,甚至还可以依据资源间的相似性给用户进行推荐。现有的个性化信息推荐机制主要有基于规则的推荐、基于内容的推荐、基于协同过滤的推荐。
个性化信息服务系统体系结构研究的重要问题就是用户文件存放在什么地方。根据用户描述文件存放位置的不同,个性化信息服务系统可分为3种体系结构[22]:①基于服务器端;②基于客户端;③基于代理端。如图1所示。
1.3 个性化信息服务的影响因素
关于个性化信息服务质量的评价不仅能反映服务机构提供给用户的信息产品和信息服务的优劣,还能反映个性化信息服务系统的高效与否,最终将促进个性化信息服务工作的不断改善与提高。目前关于个性化信息服务的评价,王日芬、吴小雷等学者的观点比较有代表性,他们认为影响个性化信息服务质量与效果的主要因素有:个性化信息服务过程、个性化信息服务系统、个性化信息服务技术和方法、宏观因素和微观因素5个方面[23]。
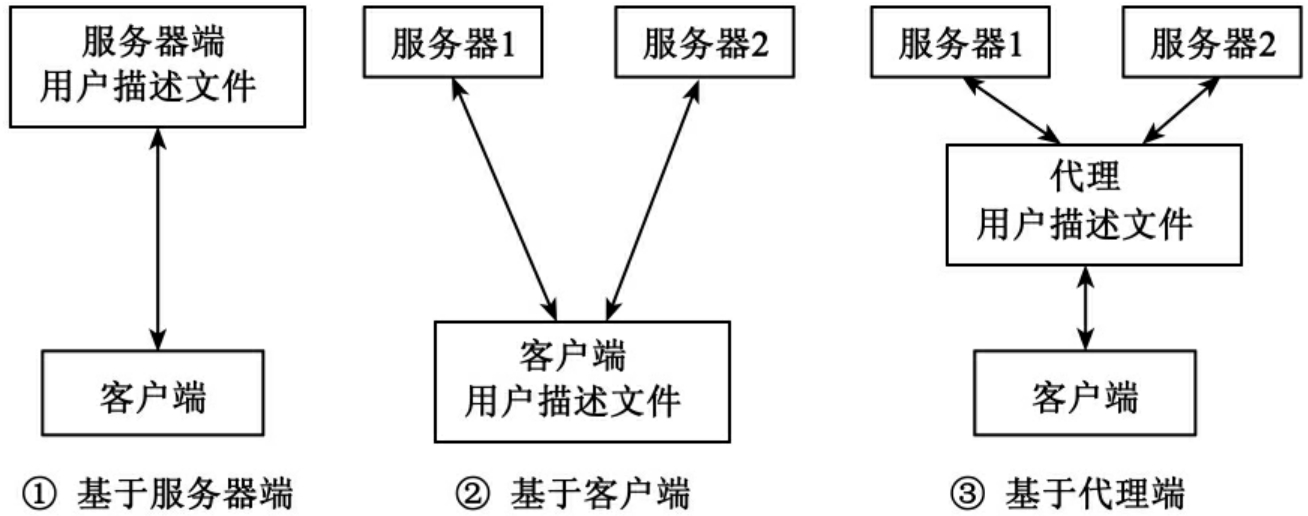
图1 个性化信息服务体系结构
1.3.1 个性化信息服务过程中的影响因素
个性化信息服务过程关系到用户需求库和信息资源库的建立、个性化信息系统的构建和运行。其主要影响因素包括:用户信息获取能力、用户需求特征提取能力、外部信息收集和处理能力、信息过滤匹配能力和用户反馈。
在个性化信息服务中,用户的个性化需求是信息服务的起点和归宿。能否全面、快速、准确地获取用户的需求信息,直接关系到信息服务的质量,影响着个性化信息系统的运行。所以,用户信息获取能力是个性化信息服务的关键影响因素;用户需求特征的提取是个性化信息服务过程中建立用户模型过程中的关键技术。所谓特征提取是指系统将用户特征向量提取出来归入用户的特征库中。特征提取能力越强,系统建立用户模型的能力就越强,系统对用户信息需求分析能力就越强,其提供的信息服务也就越容易让用户满意。外部信息收集与处理能力关系到个性化信息资源数据库的建设规模与质量,具有较强的收集与处理能力才能保证各种不同来源信息的获取与组织存储;信息过滤匹配时算法的合理性与相关性对个性化信息服务的影响都相当显著。不同方法的影响是不同的,比如使用用户历史记录分析法,不能发现用户的新兴趣或需求,而协作过滤法却可以做到。如同售后服务一样,用户反馈对个性化信息服务的影响也至关重要,这不仅能提高用户满意度,更是为改善个性化信息服务提供了重要依据。
1.3.2 个性化信息服务系统中的影响因素
从整个系统结构来说,系统的全面性、自动化程度、网络化程度都影响个性化信息服务的效果。全面性是指系统应该保存用户所有的使用行为;自动化即系统能自动将用户文档录入系统中;网络化的个性化信息服务系统,是指允许用户查询同伴的相关信息并共享它们之间的信息与经验。
从系统建设角度来讲,系统的建设思想是个性化信息服务的影响因素之一,建设思想的先进与否直接影响着个性化信息服务质量与效果的好坏,落后的建设思想或观念将导致信息服务的失败。当前个性化信息服务系统的建设应该由原来的追求信息数量向追求信息的质量转变,系统提供的服务应该由信息支持过渡到决策支持。另外,个性化信息服务系统的定位也相当重要,它影响着信息服务的质量。例如,个性化信息服务系统一般应该根据自己的能力向特定专业的用户提供特定的服务,这样,才能提高服务的权威性,提高服务的层次。
从数据信息在系统中的存储、组织、维护的角度来讲,数据信息在系统中的组织存储方式影响着个性化信息服务的效果。同时对数据信息有效地组织存储有利于系统对数据的管理和维护,提高系统运行的效率。
总的来说,在个性化信息服务系统结构中,系统的建设思想,系统的全面性、自动化、网络化程度,系统中信息数据的存储、组织方式在不同程度上影响着个性化信息服务的质量与效果。
1.3.3 个性化信息服务的技术方法影响因素
个性化服务的实现是在对信息资源进行收集、整理和分类的基础上,通过对用户信息需求、兴趣爱好和访问历史的收集、分析,建立用户模型并用于网上信息的过滤和排序,从而指导用户的浏览过程和信息检索,或者利用启发性的推荐算法向用户主动推荐信息。其中用户建模技术、信息描述与表达技术、信息推荐技术和个性化服务体系结构等相关技术,是实现个性化信息服务的基础保证;定制与推送技术、智能代理技术、挖掘技术、过滤技术、安全技术等是个性化信息服务的支撑技术。可以说技术是影响个性化信息服务最为关键的因素,个性化信息服务是建立在技术发展的基础上的,不管是个性化信息系统的构建,还是个性化信息服务的实现和改进,都离不开技术的支持。
1.3.4 个性化信息服务的宏观影响因素
个性化信息服务的宏观影响因素主要包括用户需求、用户接受个性化服务的意识、行业竞争的激烈程度、相关人才的储备、政策法规等。
用户需求是保证个性化服务产生与发展的基础,尤其是在当今信息存储量越来越大的环境中,用户想要找自己需要的信息是一项艰难而又复杂的任务,个性化信息服务需求的迫切性就不断显现。
用户接受和使用个性化信息服务的观念意识直接影响着对个性化信息服务系统的使用,倘若用户在寻找信息或寻求信息服务的过程中,压根没想到可以使用个性化信息服务,或不知怎么使用个性化信息服务系统,就将极大地影响个性化信息服务的对象范围。
信息服务行业越来越激烈的竞争有利也有弊,一方面有利于提高个性化信息服务的质量,另一方面也可能会误入恶性竞争以及信息服务者利润减少,从而导致许多力量弱小的信息服务商的退出,将影响到整个社会个性化信息服务的进程。
个性化信息服务相关的人才储备,无论是对个性化信息服务系统的建立和维护,还是对个性化信息服务支撑技术和方法的研究,都是至关重要的。任何行业都在一定程度上受政府制定的政策法规的影响,信息服务行业也不例外。
信息政策的制定和实施是社会化信息服务的需要。
1.3.5 个性化信息服务的微观影响因素
对于个性化信息服务机构来讲,个性化信息服务还受许多微观因素的影响。如Web资源的收集、获取与重组,实施的组织机构、服务定位、基础设施、服务人员素质、资金的支持等。
Web资源的收集获取与重组是个性化信息服务的基础。随着计算机网络与国际互联网的发展,网络已成为信息存储与传输的重要手段,其中Web资源已成为网络信息资源不可或缺的一部分。因此,对于Web资源的收集是信息收集中极为重要的一环。同样,对于Web资源的重组也是相当重要的,将收集到的Web资源以用户方便的形式组织起来,关系到个性化信息服务的质量与效果。
一般在一个组织机构中,机构组织设置的合理性将会提高组织的效率。同样在个性化信息服务机构中,其组织机构的合理设置将会在很大程度上提高个性化信息服务的效率。
个性化信息服务机构的自身实力即其服务目标、基础设施、人员素质、资金的支持也影响着个性化信息服务的质量与效果。随着个性化信息服务的发展,个性化信息服务将会向专业化发展,其服务的目标就显得相当重要,服务机构应该根据自身的基础设施、人员素质以及资金情况来确定服务的范围和项目,在充分挖掘自身实力的基础上,向特定的用户提供有效而又高质量的信息服务。
2 个性化信息服务的研究和发展
2.1 个性化信息服务的发展历程
2.1.1 国外个性化信息服务的发展历程
国外关于个性化信息服务的研究很多,开始也比较早。1995年至1997年,美国人工智能协会春季会议(AAAI)、国际人工智能联合大会(IJCAI)、ACM智能用户接口会议(ACMIUI)和国际WWW大会等重要会议发表了多篇个性化服务原型系统的论文,其中卡耐基·梅隆大学的Robert Armstrong提出的个性化导航系统Web-Watcher[24]、斯坦福大学的Marko Balabanovic等人推出的个性化推荐系统LIRA[25]和Henry Lieberman提出的个性化导航智能体Letizia[26]这三个系统被公认为个性化信息服务发展初期最经典的系统,它们标志着个性化服务研究的开始。
此后,个性化服务开始受到学术界广泛关注。1996年,卡耐基·梅隆大学的Dunja Mladenic在Web-Watcher[27]的基础上进行改进,提出了个性化推荐系统Personal Web watcher[28]。同年,著名的网络公司Yahoo!推出了个性化服务My Yahoo[29]。1997年,斯坦福大学的Marko Balabanovic和Yoav Shoham推出了基于内容和合作方式的个性化推荐系统Fab[30]。同年3月,Communications of the ACM组织了个性化推荐系统的专题报道,标志着个性化服务已经为技术界高度重视。
1999年,德国Dresden技术大学的Tanja Joerding实现了个性化电子商务原型系统TELLIM[31];麻省理工学院的Henry Lieberman提出了基于合作方式的个性化导航系统Let'browser[32]。同年,美国图书馆与信息技术联合会(LITA)10位著名的数字图书馆专家在一次讨论会上,把个性化服务列为数字图书馆发展的七大趋势之首。
2000年,NEC研究院的Kurt D.Bollacker等人为搜索引擎CiteSeer[33]增加了个性化推荐功能,个性化服务开始向全球发展。同年4月,以美国为主的多国个性化研究机构和网络公司成立了个性化协会,旨在推动个性化服务的发展,同时提出了保护个性化服务中涉及的用户隐私。2000年8月,Communications of the ACM再次组织了个性化服务专刊,个性化服务的研究已经进入快速发展阶段。
2001年,商业领域也开始了个性化研究。纽约大学的Gediminas Adomavicius和Alexander Tuzhilin实现了个性化电子商务网站的用户建模系统。IBM公司在其电子商务平台Websphere[34]中增加了个性化功能,以利于商家开发个性化电子商务网站。NEC研究院的Eric Glover等人提出了个性化元搜索引擎原型系统Inquirus2[35],该引擎可以根据用户输入的偏好优化查询关键词,并对搜索引擎返回的结果进行排序。
随着个性化信息服务技术的广泛研究和成熟,个性化信息服务从学术研究走向了应用。很多公司纷纷推出个性化推荐系统,提供个性化服务。很多公司如Microsoft,IBM,Google等,均推出了个性化功能;很多电子商务网站也注意到了个性化服务的巨大商机,如网上零售系统Amazon[36],Ebay[37],BestBuy[38],Expedia[39]也都推出了个性化服务功能。它们根据用户提供的兴趣爱好或分析用户的消费记录及反馈意见,运用信息推送技术进行网上产品的推荐和营销,已经获得巨大的商业成功。
个性化服务在图书情报领域也取得了相应发展,美国和英国图书馆界开始研制开发数字图书馆个性化服务系统,并取得初步成果。其中MyLibrary是数字图书馆个性化服务的典型方案,用户可自行定制个性化网络信息资源列表、馆藏资源更新通知、期刊目录、期刊全文服务、文献目录、数字资源等。据统计,目前美国共有四十多所大学提供数字图书馆个性化服务,如美国康奈尔大学图书馆、北卡罗莱纳州立大学以及洛杉矶国际研究实验室研究图书馆等。
2.1.2 国内个性化信息服务的发展历程
我国的个性化信息服务研究是从相关技术的研究开始的。1999年清华大学的路海明等在文献[40]中提出基于多Agent混合智能实现个性化推荐。此后我国对个性化信息服务也提出了一些原型系统,如清华大学的冯翱等人在文献[41]中提出基于Agent的个性化信息过滤系统Open Bookmark;南京大学的潘金贵等人在文献[42]中提出个性化信息搜集智能体DOLTRI-Agent。徐振宁等在文献[43]中探讨了基于本体论实现个性化信息检索的技术。谭琼在文献[44]中也讨论了实现个性化搜索引擎的方法。
随着网络环境的日益成熟,一些学者在个性化信息服务中引入了网络技术。2007年,王艳等在文献[45]中提出一种基于Web挖掘技术的个性化实现策略,改进经典的算法以建立用户动态的兴趣特征模型。该模型建成后,信息主动推送模块定期地将新增资源信息自动发送到用户的个性化终端,充分体现了信息服务的主动性和动态性。同年,作者李桂贞等在文献[46]中传统信息推送技术和信息拉取技术的基础上,探讨了将二者优点融合的智能信息推拉技术(IIPP),并阐述了基于该技术的主动信息服务系统。该系统融合了服务的主动性和个性化,从而可为用户提供主动的个性化服务。
在图书情报领域,很多大学图书馆也相继推出了比较成熟个性化信息服务系统,例如浙江大学图书馆、中国人民大学图书馆、清华大学图书馆、厦门大学图书馆、华中科技大学图书馆、中国科学院文献情报中心等单位[47]。以中国科学院文献情报中心制作的中国科学文献服务系统(Science China)为例,该系统包括3个特色数据库:中国科学引文数据库、现期目次数据库和中国学科文献数据库,实现了信息的有效集成。以此为基础,针对用户特定需求开展定题服务、文献检索、学科资源导航、网络咨询等服务,是一个功能比较完善的个性化信息服务平台。一些信息门户也相继推出了个性化信息服务,如新浪网等。
2.2 个性化信息服务的研究热点分析
2.2.1 文献统计分析反映的个性化信息服务的研究主题
文献[48]中采用文献计量学中的词频统计分析方法,对我国2007年以前个性化信息服务相关的专业论文和相关文献进行统计分析,从统计学的角度反映了我国近几年研究的热点问题有以下几个:
(1)用户研究。包括用户信息需求行为的研究、获取用户信息的方法和技术以及用户建模技术的研究。
(2)个性化信息服务模式的研究。包括服务方式和服务模式等。随着研究的深入,人们发现对不同的用户类型采用不同的服务模式提供个性化服务更为有效,这就促使研究人员探讨提供个性化服务的各种模式。
(3)信息资源研究。信息资源是开展个性化信息服务的基础,建立一个反映信息的各种载体和媒介之间的互动体系,不仅要加强传统馆藏建设,更要重视网络信息的建设,以便构建一个广阔的动态信息资源体系。
(4)应用领域研究。在应用研究上,数字图书馆的个性化信息服务和Internet中具有商业性质的个性化信息服务仍是近几年研究的热点。并且网络已成为广大医务工作者传递信息、获取信息、交流信息的重要途径。如何将网上大量的科技文献用于临床、教学、康复及科研,使专业技术人员及时、准确、全面地查找到所需的信息,实现网络环境下医院图书馆个性化信息服务,已成为当前备受关注的问题。
(5)技术研究。我国关于个性化信息服务的技术研究主要集中在Agent智能代理技术、信息推送技术和定制技术等3个方面。其中智能Agent技术是技术研究的热点。Agent作为融合了人工智能(AI)技术的新一代搜索引擎,是目前个性化主动服务研究中的热点和前沿。智能Agent是具有感知能力、问题求解能力和与外界进行通信能力的一个自主性抽象实体,它全面涵盖了用户需求的定义、分析和存储以及信息的输入、需求匹配和结果发送各个方面。Agent除保留了现有搜索引擎的快速检索、相关度排序等功能外,还增加了用户角色登记、用户兴趣自动识别、内容的语义理解、智能化信息过滤和推送等多种功能。由于它采用自然语言理解技术进行信息检索,对知识具有一定的分析和处理能力,故将信息检索从目前基于关键词层面提高到基于知识(或概念)的层面,能从众多资源中过滤出对用户最有价值的信息。随着语义网络以及概念搜索技术的进一步发展,智能Agent给传统的信息服务内容和服务模式带来一场革命性的变化。
2.2.2 其他学者提出的个性化信息服务的相关研究主题
文献[49]通过对个性化服务研究调查,提出了三个有代表性的研究主题:个性化信息推荐;社会网络的开发和利用;个性化信息的获取。
(1)个性化信息推荐。包括基于规则的推荐、基于内容的推荐、基于协同过滤的推荐以及基于混合过滤的推荐。其中基于历史情境的上下文感知个性化推荐是当前研究的热点。基于情境模型的个性化服务模式是充分利用用户的历史信息行为,通过上下文感知来调整和改善个性化服务结果[50]。
(2)社会网络的开发和利用,这一主题的主要思想是个性化服务的挖掘、个性化服务模式以及个性化服务的开发。将用户信息的描述作为输入,产生了人与人之间连接的社会网络模型。利用用户之间链接分析来开发和利用现在的社会网络和小世界网络,通过“转介链(用户与用户之间的关联)”来进行个性化推荐;反之,通过网络结构挖掘和建模可以帮助我们更好地识别网络社会。社会网络的使用不断扩大,涉及很多的领域例如数字图书馆和一些面向公共服务的机构。
(3)个性化信息的获取。个性化信息的获取是将一个或多个用户的个性化描述和一个适合所有用户的模型作为输入,输出一个与用户观点更匹配的定制模型。该主题是从用户的角度出发,根据用户不同的兴趣、需求、喜好以及客户端的功能来采用合适的个性化方法和应用程序。它包括系统建模,系统内容重组和组织的技术和方法,系统或用户界面的构造以及个性化定制的界面和功能。利用本体来描述用户个性化信息并提出获取用户个性化信息的方法是当前研究热点[51]。
文献[52]评述了电子商务个性化推荐领域中的研究热点问题包括稀疏问题(sparsity)、冷开始问题、奇异发现问题(serendipity)、健壮性分析和评价数据模型。
(1)稀疏问题是指因为每个用户一般都只对很少的项目作出评价,导致整个数据阵变得非常稀疏,一般都在1%以下,这种情况带来的问题是得到用户间的相似性不准确,邻居用户不可靠。目前,大多采用机器学习中的分类概念来解决稀疏问题,用初始评价矩阵的奇异值分解(singular value decomposition)维度压缩技术去抽取一些本质的特征,利用评价数据阵中的潜在结构可极大地减少维数,使数据变得更为稠密。
(2)冷开始问题也称第一评价问题(first rater)或新项目问题(new-item),如果一个新项目没有人去评价它,或都不去评价它,则这个项目肯定得不到推荐,推荐系统也就失去了作用。目前,解决的办法主要是组合各种方法,最为常用的是组合协同过滤和基于内容的推荐。
(3)奇异发现问题指的是,系统要推荐给用户的,是用户真正不知道的东西,如果推荐的东西用户本来就很熟悉,推荐效果就很不好。解决这个问题的整体思路,一是用关联规则的思想;二是嵌入关于项目的知识,其本质是一个基于内容的推荐和协同过滤的混合系统。
(4)有时商家为了竞争的需要,破坏竞争对手的推荐系统,人为地制造假数据。这就需要对系统的健壮性进行分析,结合相关分析模型,推算出在考虑假数据的情况下推荐正确的概率。
(5)评价数据模型,典型的都是在一张用户/项目而为的数据表上进行的,也有的采取多维数据模型。
2.3 个性化信息服务的发展趋势
2.3.1 数字图书馆个性化信息服务的发展趋势
当前,许多关于数字图书馆的个性化的应用如MyLibrary,很大程度致力于使用一种合理和简单易懂的方式来应用个性化推荐系统,但这些个性化应用方案并没有真正提升数字图书馆的价值,也没有将数字图书馆带入一个更高的水平。下一代的数字图书馆应该是可以向更多类型的用户提供更广泛的个性化服务。对于数字图书馆个性化信息服务的未来和发展趋势许多学者进行了分析与展望。
文献[53]总结为以下几点:①系统的服务功能及其与用户的交互性不断增强;②进一步贯彻以用户为中心的原则;③Mylibrary系统与垂直门户网站相结合提供服务;④发展团体定制服务等。
文献[54]总结为:①以用户为中心,加强用户研究;②增强主动性和智能性,完善信息服务系统;③内容服务精品化,服务内容和服务范围专业化。
文献[55]认为其发展方向:一是以用户为中心,不断增强系统的服务功能及其与用户的交互性,能提供足够的弹性来实现用户创建自己的信息集合的功能,并能实现图书馆员和用户之间附加的、同步的交流模式,如增添新的交流渠道,包括实时在线聊天、电话、视频会议等,使用户将更多的时间用在评价数据、信息或知识的价值上。二是提高对用户动态需求模型的研制水平,使系统能跟踪用户行为,学习、记忆用户兴趣,描述用户的兴趣特征来建立个性化用户模型。三是进一步研制高质量和高效率的信息过滤方法,以实现网络信息资源与用户需求的高匹配。此外,在技术上要求更具有安全、可靠、高效的运行功能。
文献[56]认为My Library的发展趋势是:①提高系统的交互性;②综合利用基于内容和基于协作的过滤技术;③提供集体定制的信息服务。
文献[57]总结了其发展趋势,主要是:①确立以用户为中心的设计原则;②资源与服务更加动态开放,具有更强的可重组性;③通过对资源的动态过滤和定制,帮助用户构建个性化的客户端服务集成系统;④功能目标从信息管理向知识管理转移。
文献[58]指出随着知识产权的重视,数字图书馆个性化信息服务中的版权问题,隐私保护问题,安全问题将会日益成为关注的焦点和研究趋势之一。
文献[59]中认为发展趋势主要表现在以下几个方面:①将更注重面向用户组织信息资源;②从用户体验的角度来看,系统的易用性是个性化服务发展必须考虑的因素;③学科馆员服务有利于用户更好地利用数字图书馆的各项服务,是数字图书馆个性化服务的特色服务;④为了提高利用率,个性化服务将与用户日常的工作或学习融合,成为用户工作、学习或生活的一部分,并因此获得更大的发展空间。
文献[60]中总结图书馆个性化服务发展趋势为:①个性化需求将成为新的发展趋向;②转变服务观念;③主动型服务;④以网络信息服务为中心的业务流程重组。
文献[61]认为高校图书馆用户个性化信息服务的发展趋势有:①公益服务与有偿服务相结合的规范化并行机制;②从文献单元服务深入知识单元服务;③为用户提供定制个性化网站服务;④合作式数字参考咨询服务发展势头良好。
文献[62]认为其发展趋势有:①手机图书馆;②基于维基的学科百科服务;③图书馆博客服务;④实时交互式参考咨询服务。
近年来,随着泛在知识、泛在网络、泛在智能环境的形成与发展,用户的需求发生了较大的变化,他们不仅希望可以随时随地根据需要多途径、多渠道,方便快捷、成本低廉,无缝地获取各种资源,并且要求提供的服务更加个性化、专业化、开放化、主动化、多样化、可视化、人性化和知识化。图书馆要适应这一变化,一定要突破传统图书馆服务的限制,通过网络和多元化的方式将服务延伸到任何有用户的地方,即建立泛在图书馆(ubiquitous library),它是指一种可以随时随地进行信息获取服务的图书馆[63],创建起一种以用户为中心的、预示未来发展的服务模式——泛在服务模式,拓展图书馆的生存空间和发展空间。泛在图书馆是真正以用户为中心,可以随时随地的为用户提供个性化服务,并且将有更多的用户可以享受到图书馆的泛在服务[64]。
2.3.2 网站个性化信息服务发展趋势
随着网络的发展,个性化技术在网站中得到广泛的应用,特别是在一些具有商业性质的网站。强大的市场需求推动了个性化服务理论与技术在电子商务领域的广泛应用,但并没有达到理论与技术完全融合的程度,表现出两种极端趋势:一是过分地强调技术上的实现,仅将新兴的信息技术僵硬地套用于电子商务网站上,功能上并不满足个性化服务的要求;二是理论探讨无法通过技术实现,简单地将其他领域并不适用于电子商务的理论通用化,造成理论脱离实践。
在日趋激烈的竞争环境下,电子商务网站要想有效地保留用户、防止用户流失、提高销售量,就必须实现个性化服务,即在不同的情境下,对不同用户投其所好,采取不同的服务策略,主动提供不同的服务内容。如通过电子商务网站向客户提供需求的个性化定制、信息的个性化定制、对个性化商品的需要等相关个性化服务,将电子商务网站的浏览者转变为购买者,更好地吸引新的访问者,提高电子商务网站的交叉销售能力和电子商务网站的忠诚度。这其中蕴含的巨大商机又催动了一个新兴行业——购物搜索的迅速成长。这反过来也将促进Internet上的个性化信息服务的研究,促使具有商业性质的网站个性化信息服务的研究得到更大的发展。
文献[64]指出个性化信息服务的发展趋势为:①分布式环境下个性化和互操作;②个性化系统的评价指标:形成新的评价方法和评价标准(考虑社会学因素和经济因素);③信息的个性化推荐模型,理论,模式和语言;④更多的提供个性化的信息设备;⑤用户信息互动。
文献[65]指出个性化电子商务研究的主要方向是:①快速准确建立用户建模。在尊重用户个人隐私的情况下尽可能多的捕获用户的工作环境、经历、对社区的贡献以及个人偏好;②个性化推荐研究,包括用户短暂的和持久的需求研究、长期与短期的需求研究、混合客户-服务器个性化架构研究;③用户交互将成为个性化信息系统的一个组成部分;④提供更强更多形式的用户隐私保护方法,更好的平衡隐私保护的效果和个性化服务的质量;⑤Web2.0模式下的电子商务个性化服务模式也将是未来的研究热点。
3 个性化信息服务方法体系
个性化信息服务是以用户为中心,通过对信息资源的整合,根据用户的个性化需求,向不同用户提供不同信息的服务体系。个性化信息服务改变了传统的“我提供什么,用户接受什么”服务机制,成为“用户需要什么,我提供什么”的服务体系[66]。因此个性化信息服务方法体系涉及信息资源建设,用户需求表达与获取等方面,基于用户的兴趣、行为的用户库与资源库的匹配是个性化信息服务方法体系的构成要素。
3.1 面向个性化信息服务的信息资源建设
信息资源建设作为个性化信息服务的重要部分,对个性化信息服务质量有重要影响。信息资源建设与用户的个性化需求是密切相关的,资源建设应围绕个性化,方便个性化信息服务的开展。
3.1.1 面向个性化信息资源的描述
信息资源描述的规范性关乎个性化信息服务的程度,信息资源的描述与用户描述密切相关,一定程度上信息资源的描述是根据用户描述来进行组织的,以更好的与用户的需求进行匹配。信息资源的描述可以用两种方式来表达:基于内容的方法和基于分类的方法。
①基于内容的方法是指从资源本身中抽取信息来描述和表示资源。常用的方法为加权关键词矢量法,这种方法需要对文章的关键词进行特征提取与匹配,关键词的提取需要对文档分类、切分,然后利用停用词表来筛选出有意义的、相关度较高的词,关键词常用特征提取方法有信息增量方法和X2统计方法,提取关键词的特征值后需要利用tf-idf方法对其赋予权重[67]。
②基于分类的方法是指将资源进行分类,利用类别来描述资源,这样可以按类别将特定资源提供给特定的用户。资源的类别可以通过预先定义和聚类产生,对于一般资源如果不能直接划分类别时,才需要对其进行聚类,以得到所需要的类型[68]。文本分类对于分类方法至关重要,常见的分类方法有朴素贝叶斯、K-最近邻方法和支持向量机等。[69]
随着网络化的发展,信息资源形式多样化,不仅仅包括印刷型文献,还包括网络型文献,视听型文献[70],其中以数字信息资源为代表的网络信息资源成为主导资源,文献[71]详细介绍了网络信息资源描述的重要性和必要性,并构建了一种基于多维属性集合的网络信息资源描述模型,该模型从网络状态监控和服务质量保障角度出发,对网络资源的属性进行分析,然后对网络信息资源进行分解、分类。网络资源分为物理资源和逻辑资源两种,这样可以实现物理信息和逻辑信息的有机结合。网络资源模型包括ID(R)(网络资源全局标识)、PR(R)(网络资源的物理资源集合)、LR(R)(网络资源的逻辑集合)、Rule(R)(网络资源使用规则集合)和Domain(R)(网络资源位置属性集合)五个元素组成。五元组的集合实现了不同类型、不同属性的网络信息资源对外接口一致,这样网络信息资源就可以得到统一描述。
在信息爆炸的今天,泛在信息使得信息资源的描述更加困难,而普适资源的描述出现服务化、语义化、用户化和随机化的需求[72]。文献[72]提出了针对普适资源的描述方法,包括支持语义描述的OWL-S、OWL-S+和OWL-SP方法。其中,OWL-S是从语义层次和服务角度来对信息资源的属性和功能进行描述,提供一种共享框架;OWL-S+是从弥补OWL-S的局限性出发,针对用户需求、OWL-S的模型和本体进行用户的扩展、完善,包括对用户的选择行为、偏好、约束等。这样信息资源可以恰当的描述和表达用户的需求,为开展个性化信息服务提供基础;OWL-SP通过概率模型来解决普适资源中不确定性因素,使信息资源的描述更加具体化。
3.1.2 面向个性化的信息资源整合原则、要求与策略
进行个性化信息服务需要根据用户的需求对信息资源进行整合,而随着信息资源数量的增长,载体形式的多样化,信息资源的整合变得更加困难。个性化信息服务的前提是要满足用户的个性化需求,因此在信息资源整合过程中要充分考虑用户的需求。信息资源整合可以从数据集中、信息集成、资源整合和信息机构合作与融合几个层面来进行。文献[73]提出以用户为中心,识别用户主体及需求,根据用户需求进行信息资源的整合,并提出信息资源整合的策略:制定信息资源整合的战略,明确机构内外部信息环境与信息需求,信息资源整合设计,配置人力、技术、设备资源,搭建信息资源整合系统平台。因此,文献[74]提出了个性化信息服务的原则:
①以用户需求为中心的原则。信息资源整合要从用户角度出发,充分调查用户的信息需求,配置相应的服务技术和管理。在信息资源的建设中应准确反映用户需求,充分保障用户参与。
②系统化原则。信息资源整合必须呈一个体系,即通过系统规划,考虑信息的生命周期,来进行信息资源整合。在个性化信息服务过程中,考虑信息的层次性和周期性,系统地进行信息资源的整合,以满足不同的用户需求。
③开放性原则。面向个性化服务的信息资源整合最终目的是实现资源的共享,通过利用国内外已有资源、技术提高信息资源组织、整合的效益。坚持开放性原则,加强各信息机构、服务系统、信息产业链的合作,实现信息资源共享,是信息资源整合的重要原则之一。
④易用性原则。信息资源的整合以用户为出发点,要考虑不同用户的需求,因此在整合过程中要求尽量简单易用,尽量减少用户的负担,具体要从界面的易用性入手:界面显示信息清晰、操作方便,提供即时确切的信息。
⑤平衡原则。面向个性化的信息资源整合要充分考虑信息资源变化时的情况,平衡原则要求平衡处理好变与稳,“链接资源”和“本地资源”等的关系,保证存取与拥有的比例。
文献[75]提出了信息资源整合的6个原则:整体性原则,即保持信息资源对象学科的完整性;针对性原则,即信息资源整合时要有目的性;层次性原则,即信息资源与用户需求的层次性对应;科学性原则,即对信息资源整合的对象、内容、方法进行科学论证;最优化原则,即运用一定的技术手段和方法进行信息资源的整合,得到最好的服务效果;动态性原则,即根据用户需求的变化和信息资源的更变,信息资源整合时注重动态平衡。
信息资源整合过程中有各种要求,文献[76]面向个性化服务的信息资源整合要求:建立用户服务的发展模型,即要与以用户为中心的集成信息服务与个性化定制服务相结合;资源的组织要标准化,即要求在信息资源的加工、描述等过程中注重标准和规范,以保证信息资源的可使用性,互操作性,可持续性;技术要规范,即进行信息资源的整合、组织过程中,对所用的技术进行标准化规范,包括信息系统的标准规范,信息资源加工与描述,信息检索标准等的规范;信息活动要求规范,即在信息资源的采集、加工、转换、信息整合、导航等信息活动过程中,进行规范化规定。通过这些要求和规范,经整合后的信息资源更能为用户提供给个性化服务。
信息资源的整合策略指如何以有效途径来进行信息资源的整合,当前面向个性化服务的信息资源整合对象主要是数字资源,文献[77]从知识管理角度提出数字信息资源三种整合策略:基于主题的信息资源整合,即通过主题词将关联信息聚类整合;面向问题的信息资源整合,即用户提出问题,服务系统根据问题提出一组解决方案,而信息资源的整合也是基于这个问题的;基于知识地图的信息资源整合策略,即先将知识分解成知识单元,然后进行知识单元的关联,形成知识地图,基于知识地图的信息资源整合策略强调知识间的关联性。文献[78]提出面向用户的信息资源整合策略:信息收集和转换;信息的有效存储和管理;按照用户需求进行分布。这种策略要求对用户需求信息的收集、获取,然后进行动态存储、管理。
3.1.3 面向个性化的信息资源整合模型
面向个性的信息资源整合模型是一个将分散的资源组织成有序的、智能的、综合的系统体系,文献[79]提出三维的信息资源组织模型:资源维,服务维,应用维,如图2所示。其中,资源维显示资源的结构类型,包括结构化、半结构化和非结构化;服务维表示信息资源整合的利用率;应用维反映的是信息资源的应用层次。这个三维模型从数据层、中间层和应用层来对信息资源进行整合,数据层整合的是现有的信息资源,对其重新组织,加工。中间层包括检索入口层和元数据层,分别针对同构系统和异构系统来进行整合。应用层是信息资源整合中的最高层,将各种应用进行集成,包括学科导航,知识门户等,以更好的为用户提供服务。
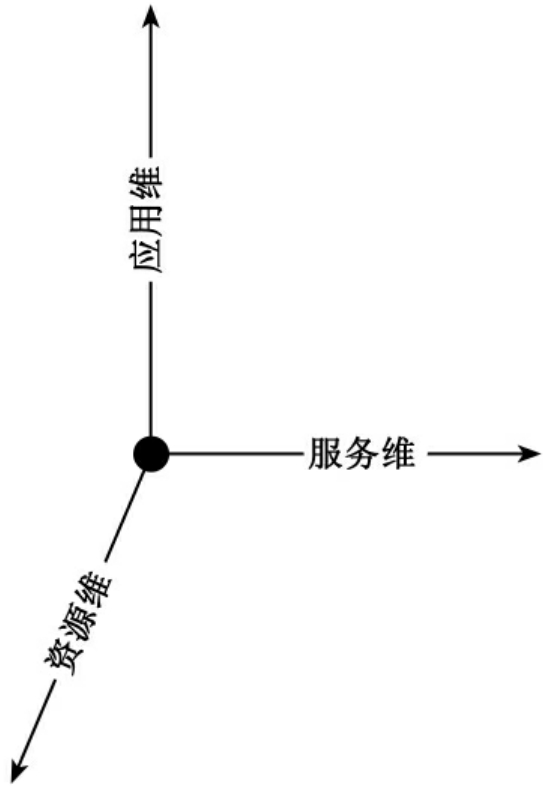
图2 信息资源整合维度图
文献[80]提出了基于实体—关系—问题的信息资源整合模型,该模型构建时引入了P,即问题,更好的体现了目标和驱动因素,在构建时需要首先明确系统设计的范围和作用边界,然后根据需求确定系统的目标,最后根据目标问题确定解决方案,用实体、关系来解决问题。E-R-P的信息资源整合模型的构建过程就是对用户的需求、问题求解的过程。
文献[81]从RDF的角度出发,提出了个性化的信息资源整合模型。RDF是一种标准化的元数据语言,该模型通过基于RDF的资源描述、Agent搜索与信息过滤、信息映射、逻辑显示、自动更新等过程实现信息资源的整合,数据模型包括资源、属性和声明三部分组成。该模型引入了Agent模块,可以帮助人们在服务、异构、不确定性环境中识别复杂模式,对于个性化信息服务来说,减轻了用户负担。分布式的信息资源集成使个性化信息服务更为容易。
3.1.4 面向个性化信息服务的信息资源建设的发展趋势
面向个性化信息服务的信息资源建设要始终把握个性化的特点,从用户角度出发进行信息资源的整合、建设,以满足用户的个性化需求。当前信息资源建设中出现以下几个问题[82]:没有科学系统的规划,信息资源建设系统性不强;信息资源建设体系的标准性、规范性不强,造成信息资源共享存在困难;资源的开放性不足,没有统一的整合机制;信息资源建设中对于信息的动态性考虑不足,需要注重动态虚拟链接资源的可靠性和稳定性,同时注意及时更新。
文献[83]认为面向个性化的信息资源建设的发展趋势为由面向资源到面向用户,体现了以用户为中心的原则,充分考虑用户的需求,保证用户的参与,更好的满足用户的各种需求,同时由于用户的参与信息资源建设过程也会加快。总之,面向个性化信息服务的信息资源建设的发展趋势必须要有用户的全过程参与,尽量的体现和考虑用户的需求,以进行个性化服务。
面对信息量的剧增,信息资源的多样化,面向个性化信息服务的信息资源建设的发展将着手于泛在信息资源的建设,据此文献[84]中提到了信息共享空间的构建,通过综合实体空间、虚拟资源和技术来提供一站式服务。信息共享空间基本模型包括实体层,虚拟层和支持层,强调用户的参与,以用户为中心,进行信息资源建设模型的构建[85]。
3.2 面向个性化的用户兴趣特征获取
正确及时地获取用户的特征,表达出用户的需求可以更准确的向用户提供个性化信息服务。用户特征的获取首先需要对用户的需求进行表达,以获取用户的行为、兴趣爱好等特征信息。用户的兴趣、偏好影响用户的信息行为,进而影响个性化信息服务,对用户兴趣、偏好特征的获取是构建用户模型,进行个性化信息服务的前提。文献[86]认为用户的兴趣偏好对个性化信息服务的影响主要体现在对个性化服务内容、服务方式和个性化信息服务层次方面,而用户兴趣偏好导致了行为特征呈现个体性、社会性、随机性和选择性特点,对用户兴趣偏好的特征获取可以通过日志分析、Cookie分析和智能代理分析来进行。
3.2.1 面向个性化的用户描述
①用户描述文件的创建和表达。为了更好的表达和了解用户,需要对用户创建描述文件,用户描述文件描述的是用户的特征以及用户与用户之间的关系。从内容上看,用户描述文件可以划分为基于兴趣和基于行为两种,其中基于兴趣的用户描述文件包括加权矢量型,类型层次结构型,加权语义网型,书签和目录结构等。用户描述文件的表达方式通常有用户静态信息、URLs等几种[87]。用户描述文件的创建和表达首先需要解决数据源问题,即用户描述文件需要从哪里获取哪些数据,用户的个性化信息来源一般分为隐含的用户反馈和明确的用户反馈。隐含的用户信息反馈获取用户信息是通过监视用户在Web页面的浏览、停留、点击等行为进行日志分析得到的,明确的用户信息反馈获取用户信息是通过用户参与,由用户提供来实现的。用户描述文件的表达包括概念上的表示方法和物理上的存储方法。
②用户描述文件的组织方法。用户描述文件一般用文件、关系数据库等来组织[88],其组织原则要规范化,以便用户特征的获取。因此在用户描述文件进行组织时需要用元数据如XML的RDF等来组织。XML的优点用结构化数据来描述,特征获取更容易、便捷。
3.2.2 基于WWW缓存的用户兴趣特征获取
WWW缓存可以通过客户端、代理端和服务端来进行用户信息的搜集、存储,对这些关于用户的信息进行分析挖掘可以提取用户的兴趣特征。运用Web挖掘等技术对用户信息进行处理分析是构建用户模型的关键,Web挖掘过程一般分成数据预处理如清洗数据等,模式发现和模式分析三个阶段,Web挖掘通常分成Web结构挖掘、Web内容挖掘、Web使用挖掘三类。文献[89]从WWW缓存角度出发,使用Web挖掘技术对用户的兴趣偏好特征进行提取,并对长期兴趣和短期兴趣进行建模,其过程首先从WWW缓存的页面中提取文本内容,然后对文本进行分词切分,采用TFIDF方法对文本内容进行特征提取,最后根据提取的特征对文本进行聚类分析,依据相似度来提取用户的长期兴趣和短期兴趣特征。
基于WWW缓存的用户兴趣特征提取是一种静态信息提取方法,分析简单、有参照性,然而用户的兴趣是在变化的,WWW缓存的数据应经常保持更新,同时要既能反映用户的短期兴趣,也能保持长期兴趣的特征,这样就可以根据用户的兴趣偏好特点,向用户提供个性化信息服务。
3.2.3 基于文本信息过滤的兴趣偏好特征获取
文本信息过滤系统将文本进行特征提取,聚类分析等途径来获取用户的兴趣特征,传统的文本信息过滤系统是以个人兴趣作为依据的,难以准确表达用户短期的情景兴趣信息。文献[90]提出了面向情境兴趣的文本信息过滤系统模型,这种过滤系统由偏好表述模块、用户偏好组织、反馈处理模块、用户界面、信息提供模块、信息处理模块、热点推荐和过滤模块组成,如图3所示。其中偏好表述模块通常用空间向量模型来表示,共有五个元组:关键词、权值、时间、类别和新奇度,即<Keywords,Value,Date,Category,Novelty>。将文本过滤系统与动态变化的个人情境兴趣结合起来,可以更实际地反映用户的兴趣偏好特征,有效地拟合用户短时间内特定的信息需求。对于个性化信息服务而言,可以提高服务效率和服务的针对性。
3.2.4 基于本体的用户兴趣偏好特征获取
基于本体用户模型的用户兴趣获取是指用本体建模元语表示用户兴趣,然后根据本体的概念、属性、规则来提取用户的特征。文献[91]提出基于本体的用户兴趣特征提取方法,通过采用动态机器学习机制获取用户兴趣,建立本体的用户兴趣模型,建立该模型需要首先建立参考本体,包括对本体的领域、覆盖范围,收集分析领域专家知识等,然后对用户兴趣知识进行初步学习,对用户兴趣模型进行挖掘和完善。基于本体的用户兴趣特征提取可以实现隐性用户兴趣的发现和利用,以满足用户的个性化需求。这种方法有效提高了个性化信息服务的质量。

图3 面向情景兴趣的文本过滤系统
文献[92]从个性化语义网角度提出了用户本体模型,该模型将用户的基本需求看作领域本体,通过概念、关系来获取用户的兴趣领域本体。模型由五个元组组成,即领域本体的概念,领域本体的语义关系,概念之间的函数关系,领域本体概念和语义关系的权重。基于本体语义网用户兴趣特征获取通过利用概念和语义网的关系使获取的用户兴趣特征更为准确。
3.2.5 基于软约束的用户兴趣偏好特征获取
软约束是在传统约束的基础上对每个约束变量取值组合附加一个特定片续集的值,以表示偏好水平、成本、确定性水平等。基于软约束的用户兴趣偏好特征获取,是综合考虑各个约束,并对各个约束的附加值进行抽象概括,以更好表达用户需求。文献[93]提出基于软约束理论的用户兴趣偏好模型:将各种用户反馈的偏好信息表示成软约束,每个偏好模型被表示成不同约束满足问题,然后根据模型的改变对偏好约束进行调整,形成约束序列,每个约束序列成为一个约束集合。基于软约束理论,用户兴趣偏好特征提取过程就是对软约束满足问题求最优解的过程,而用户兴趣偏好特征提取需要经过基于实例的递增式两阶段获取:即第一阶段针对用户的偏好粗略提出几个方案,并对方案评价,获取参数值;第二阶段利用第一阶段的反馈信息精练用户的偏好模型。基于软约束理论将用户偏好信息的获取、表示、用户兴趣偏好建模过程联系起来,更好的获取用户的兴趣特征信息,提高个性化信息服务的水平。用户满意约束问题实质是对一系列约束进行值的评估,通过用户的兴趣约束进行分析来提取和挖掘用户的兴趣特征[94]。
3.2.6 基于信息心理—行为分析的用户兴趣特征获取
用户的信息心理决定用户的信息行为,用户的行为反映出用户的兴趣特征,基于信息心理—行为分析可以较准确挖掘和提取用户兴趣特征。文献[95]运用内驱力理论解释说明用户的浏览等行为,以确定用户对相关领域信息是否感兴趣,并用多元线性回归模型描述其相关性。文章将用户对网页的感兴趣程度及网页兴趣度用0~1的实数表示,用户的行为则反映用户兴趣度,通过观察用户行为如点击行为,保存、标记书签的动作,查询行为动作来确定是否感兴趣,并根据浏览网页时间长短、点击次数等参数对用户兴趣度给定一个实数值。然后对各种参数值采用回归分析,挖掘到用户的兴趣。在个性化信息服务中,对用户的信息心理、行为分析是获取用户兴趣特征的重要方法之一,也能更准确反映和表达用户的兴趣。用户对信息的需求、消费通过一定的信息心理来表现[96],通过信息心理—行为分析来获取用户兴趣特征,可以提高消费水平,更好的开展个性化信息服务。
3.3 面向个性化的用户模型表示方法
用户模型的建构是个性化信息服务的核心,模型构建过程能从有关用户的兴趣和行为的信息中归纳出表示用户需求的模型,这个需要对用户兴趣、偏好等特征进行准确识别与描述。用户模型不是面向具体的个体,而是面向所有特定数据结构,形式化的用户描述。对用户模型的表示是构建用户模型,进行个性化信息服务的保证,也决定了用户模型反映用户真实信息的能力和计算能力。常见的用户模型表示法有以下几种:
3.3.1 主题表示法
主题表示法是以用户感兴趣的信息主题来表示用户模型的方法,这需要与具体的应用领域结合。在Yahoo的个性化入口MyYahoo是以用户选择的网站栏目来表示用户模型,模型将用户选择的栏目作为定制项保存,成为MyYahoo推荐的主题依据[97]。用主题表示用户模型需要用户的参与,呈现的是用户粗略需求,对于细化的用户需求需要进一步挖掘、获取。
3.3.2 用户Bookmark表示法
用户Bookmark表示法是指以用户保存的站点或页面的Bookmark来表示用户模型的方法。用户Bookmark一般表示的是用户感兴趣的有价值的东西,在浏览网页时,用户会将感兴趣的页面或网站以Bookmark的形式保存起来,Bookmark反映的是用户感兴趣的主题,这就是用户Bookmark来表示用户模型的依据。比较典型的以用户Bookmark表示用户模型的个性化系统有SiteSeer[98],Open Bookmark,网上Bookmark服务系统等。
3.3.3 关键词列表表示法
关键词列表表示法是指以用户感兴趣的关键词来表示用户模型的方法,关键词的获得可以通过用户指定,也可以通过学习算法获得。用户指定的关键词是由用户显示指定的,根据用户反馈、tag等途径获取用户兴趣,建立用户模型。学习算法获取用户感兴趣的关键词列表是通过文本分类特征提取实现的,需要训练样本得到特征集合。典型的关键词列表表示用户模型的个性化系统有WebWatcher[99]。WebWatcher服务系统主要由代理服务器和学习器两部分组成,代理服务器保存的是访问过的URL地址,学习器通过训练提供系统的用户模型。
3.3.4 粗、细兴趣粒度表示法
用户兴趣按粗粒度可以划分为感兴趣类(IC)和不感兴趣类(NIC),用户兴趣细粒度划分不是简单的划分感兴趣和不感兴趣,而是按照对兴趣的理解划分为不同的兴趣类。用户兴趣的信息粒度决定用户模型的兴趣粒度,粗兴趣粒度实现用户建模较简单、直观,但需要正、负例集对学习算法进行训练,粗略的划分降低了用户需求的精度,正负例集的获取是以牺牲用户正常浏览为代价的。文献[100]提出了面向客户端细粒度兴趣用户建模方法,方法对用户的兴趣进行了细分,用分类的资料、论文和页面作为训练例集,同时用k邻近分类器对未知页面进行判断,模型包括5个元组:用户兴趣的特征子集T,特征子空间T,k个感兴趣类与不感兴趣类的集合C,感兴趣类代表点的关系R,映射关系f。采用细粒度表示用户模型,更好地表示用户需求。
文献[101]提出了面向个性化的无需反例集的用户模型表示法,这种方法是用户兴趣粒度表示方法的补充,不要在学习算法训练中引入反例集,不需要用户提供不感兴趣页面。只需从细粒度层次对用户感兴趣页面进行训练,特征用户兴趣的特征子集,构成用户模型。
3.3.5 空间向量表示法
向量空间模型表示法指用关键词向量空间中向量来表示用户模型的方法,向量空间模型表示法需要对文档中的关键词根据TFIDF算法计算权重,以区分用户兴趣度,构建用户模型。用户模型会随着用户感兴趣文档的增加而增大,这样会需要大量的物理空间和计算开销。基于向量空间表示用户模型的关键是关键词的选择,以便准确表达用户需求。常见的向量空间用户模型表示的系统有:LIRA[102],Syskill&Webert[103],PWW[104],WebMate[105],NewsDude[106]等。
3.3.6 基于神经网络(BP)的表示方法
基于神经网络的用户模型表示方法是指当网络稳定后,以网络连接权重所特征化的网络状态来表示用户模型的方法。基于神经网络的用户模型表示是将用户兴趣、偏好作为网络的输入状态,而把从输入的兴趣、偏好假设中抽取挖掘出适用用户兴趣的模式类,然后对模式类与用户的兴趣进行关联,网络输入与输出间的连接状态用网络的连接权重描述。文献[107]详细介绍了成长型单元结构(GCS)神经网络的用户模型建构过程,为了保证神经网络用户模型的典型性和代表性,需要首先用训练好的GCS对兴趣类进行划分,然后用样本进行训练。基于神经网络模型表示方法反映了信息间的关联,而不是简单用关键词列表来表示,但却依赖神经网络类别和算法。
3.3.7 基于用户—项目评价矩阵表示方法
基于用户—项目评价矩阵表示方法是指一个m×n型矩阵来表示用户模型的方法。其中m为用户数,n为项目/产品数,矩阵中每个元素rij代表用户i对项目j的评价,评价值的大小代表用户对其偏好程度,该方法通常用于协同过滤推荐系统中,如Grouplens[108]。基于用户—项目评价矩阵的用户模型表示简单、直观,但缺乏对用户兴趣适应能力,对于动态用户兴趣来说,难以反映最新的用户兴趣特点[109]。
3.3.8 基于示例的表示方法
基于示例的表示法是在用户给定的示例文本的基础上,利用特征项的类别区分度,抽取能够表现用户兴趣的项作为用户信息需求模型基本特征项集的表示方法。基于示例的用户模型表示方法需要首先对文本类别的特征进行抽取,包括能够表现用户感兴趣和不感兴趣的特征项,文本特征项的抽取是示例建模的关键步骤;其次要对文本的类别进行判别,并赋予权重值,权重值赋予的依据是用户感兴趣的相关度。文献[110]提出并建构基于示例的用户模型,模型逻辑表示为:(<t1,w1>,<t2,w2>,…,<tn,wn>)即是由一系列特征项的集合,每一个特征项有特征词和权重组成。基于示例的用户模型表示方法,利用用户给定的相关文本集和不相关文本集进行分析挖掘,利用项的类别区分度来筛选基本特征项集,然后进行判别分析,赋予权重,形成逻辑模型,这种表示方法以统计为基础,使用面较广。
3.3.9 基于本体的表示方法
基于本体的表示法是对用户的基本概念、信息、需求进行表示表述的方法,利用本体论知识来对用户模型进行表示可以使描述更规范、可靠,提高个性化服务系统的联想能力和精确性[111]。基于本体的用户模型表示法包括3个元组:用户的基本背景信息I,包括姓名、性别、年龄、学历等;用户信息的个性化领域本体O;用户的个性化需求R。基于本体用户模型表示法在更深层次表示、描述用户的信息需求,更准确、直观。
3.3.10 基于软约束满足理论表示方法
基于软约束满足理论的用户模型表示方法,是指通过软约束理论对用户的兴趣偏好特征进行挖掘、获取,建立用户模型的方法。系统在向用户提供个性化服务的过程中,需要考虑用户的个性化需求,用户的每一个兴趣偏好都成为一个软约束,对这些软约束条件进行模型构建求解,使软约束得到满足的过程就是用户模型构建过程。基于软约束满足理论用户模型的表示方法,需要对用户的兴趣偏好等约束条件进行考虑,包括对问题偏好的模糊性等问题。基于软约束满足理论的用户模型表示是将用户的偏好定量化,转化成运筹问题进行求解,优化,以使资源与用户需求的匹配达到最优化。基于软约束满足理论的用户模型表示方法需要进一步的研究,包括求解算法的设计,偏好获取过程的设计等[112]。
3.4 个性化信息服务体系构建
3.4.1 个性化信息服务的体系结构
个性化信息服务体系包括用户、资源和推荐方式的系统,具体目标是根据用户的需求,对信息资源进行整合,通过定制、推送等多种模式向用户提供服务,以满足用户的个性化需求。个性化服务体系构建需要对用户、资源进行描述,选择用户模型表示方法,构建包括用户、资源在内的模型,然后推荐给用户其所需要的信息。根据用户描述文件所存放的位置,将个性化服务体系结构划分为3种[113]:
①基于客户端的服务体系结构。这种体系结构将用户描述文件放在用户浏览器端,通过对用户浏览行为等信息的获取进行分析,提供服务。这种体系结构既可以在服务器端也可在客户端实现个性化定制服务,优点是支持用户描述文件在不同Web应用之间共享,缺点是只能进行基于内容的过滤。常见的系统有Point Casework[114]等。
②基于服务器端的服务体系结构。这种体系结构将用户描述文件放在服务器端,避免了用户描述文件的传输,支持基于内容的过滤和基于协作的过滤,但却造成用户描述文件不能在不同的Web应用之间共享。常见的基于服务器端的系统有Syskill&Webert、Letizia等。
③基于代理端的服务体系结构。这种体系结构是将用户描述文件放在代理服务器端,保证个性化服务在服务器端和代理端上都能实现,优点是支持内容过滤、协作过滤,支持用户在描述文件在不同Web应用之间共享,缺点是需要传输用户描述文件。常见的基于代理端的服务系统有Personal Webwatcher等。
个性化服务体系结构有用户、用户信息收集、资源、用户模型、个性化服务几个模块组成,首先经过用户信息收集模块,收集用户信息,然后进行用户的建模,根据用户模型与资源的匹配,向用户提供服务,然后根据用户的信息反馈,对用户信息进行更新,修改模型,以提供给用户更高质量的信息服务。
3.4.2 个性化信息服务体系构建过程
个性化信息服务体系的基本模型是获取用户的个性化信息需求,对信息资源进行面向用户的整合,然后提供给用户所需要的信息,以满足其个性化的信息需求。个性化信息服务体系构建包括用户模型构建,信息资源重组,用户需求与信息资源匹配[115]。
①用户模型构建。用户模型构建是个性化信息服务的基础和保证,构建用户模型需要对用户的信息进行描述,运用数据挖掘等技术对用户兴趣特征进行提取,然后通过主题、Bookmark方法进行用户模型表示,利用学习算法和训练集来构建用户模型。常见的用户模型构建方法有三种:用户手工定制建模,即用户自己手工输入或选择用户建模方法;示例用户建模,即用户提供与自己兴趣相关的示例及其类别来建立用户模型;自动用户建模,即根据用户的浏览内容和浏览行为自动构建用户模型和建模过程用户无须提供信息的建模方法。用户模型的构建过程中,首要考虑的因素是用户的识别。用户分为注册用户和非注册用户,因而用户识别可分为显示识别和隐式识别,对于那些注册用户可以通过用户提供的信息进行识别,而那些无法获取用户信息的用户识别需要通过IP地址,代理服务器缓存的方法进行用户识别。文献[116]提出了基于Cookie技术和启发式规则的用户识别算法,该算法结合IP地址,启发式规则,Cookie技术来确定、识别用户,提高了识别效率。用户模型的构建是个性化信息服务体系必要的构建过程,针对用户需求不同,采用不同方法对用户模型进行构建,文献[117]提出一种基于空间向量模型的用户模型表示即动态学习算法,对用户建模特征进行了选择,将词频法和TF-IDF结合形成词性标注信息,获取用户兴趣信息建立个性化信息服务模型。文献[118]采用模糊贝叶斯算法,结合Agent技术,建立用户动态预测模型,采用贝叶斯算法构建个性化服务模型,可以反映用户的动态兴趣和信息需求。
②信息资源组织。信息资源的组织包括信息资源的描述,信息资源的整合,通过对信息资源的规范化描述,根据不同形式的信息资源采用不同整合策略,其原则是要有系统性,面向用户,反映用户的动态需求。信息资源组织的功能是接受用户的信息需求后,查询、分析用户需求信息的存在位置,然后采取相应的信息资源整合策略。前面已经介绍了信息资源组织的原则、策略、模型等,根据用户需求的不同,信息资源组织的方式也就不同。文献[119]提出了基于统一内容定位(UCL)的个性化信息服务模型构建方法,正是从信息资源组织角度,通过信息组织、过滤、浏览帮助用户获取到所需要的信息。基于UCL的个性化服务模型采用ID3算法识别挖掘用户的兴趣,通过多级代理服务实现个性化信息服务。
③匹配引擎进行匹配。个性化服务系统通过用户提供或者跟踪挖掘用户信息建立用户信息库,在用户需求的基础上进行信息资源的重组、整合,形成资源库。个性化服务系统就是根据用户的信息需求库与资源库的匹配,向用户提供个性化信息资源推荐列表,其过程如图4所示。在个性化信息服务体系中,利用匹配引擎进行匹配、过滤是一个重要环节。首先匹配引擎根据从用户信息库中取出用户兴趣的特征向量,对从信息资源库中的文本资源信息进行过滤,将用户兴趣向量中特征词能够索引到的文本资源信息放入待匹配列表,然后计算待匹配列表中文本与用户兴趣的相似度,将符合要求的信息推荐给用户。在匹配过程中,用户兴趣特征获取,用户兴趣的更新、用户模型的表示显得尤为重要,同时信息资源也需要根据用户的需求进行整合、建设,以提高匹配效率。匹配中最重要的是进行文本信息与用户兴趣特征向量的相似度计算,一般用余弦夹角来度量资源文本d和用户兴趣向量h之间的相似度:
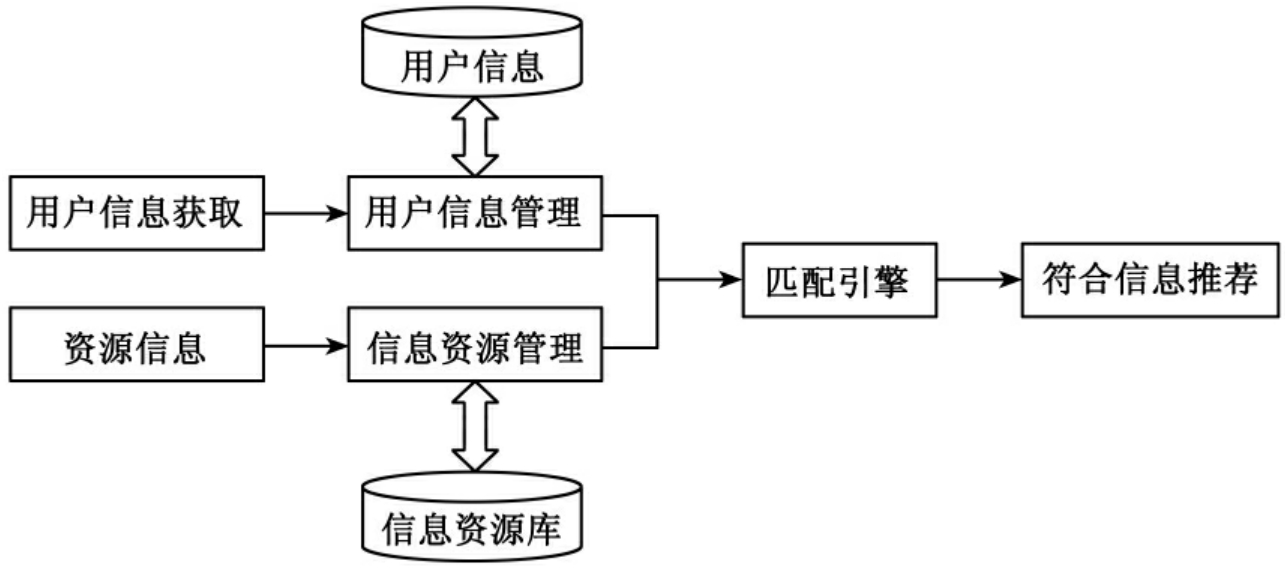
图4 个性化信息服务体系示意图
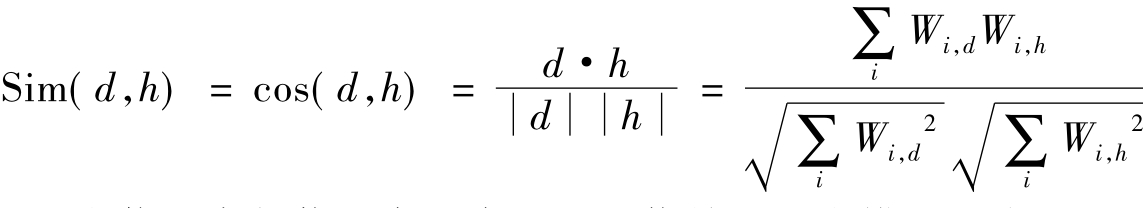
用户信息库与信息资源库的匹配依赖于用户模型的表示,不同的用户模型表示方法对应不同的匹配算法,例如关键词列表表示法适合用向量空间模型、布尔模型或概率模型进行匹配,主题表示法可以用KNN、TFIDF分类器、贝叶斯分类算法进行过滤、匹配[120]。随着机器学习技术的发展,神经网络、决策树、向量机等引入匹配算法中,可以反映用户动态兴趣变化,以获得更精确地匹配。
④符合用户需求的信息推荐。用户信息库与信息资源库的匹配需要进行相似度计算,设定一个阈值,当相似度大于阈值时将相关文档输出推荐列表推荐给用户。符合用户需求的信息推荐是在前几个步骤基础上进行的,推荐信息的质量与用户兴趣特征获取、用户模型表示、信息资源整合程度以及匹配算法的选择是相关的。在进行个性化推荐中需要考虑用户的特征、用户需求信息与信息资源相似性等隐私,以推荐给用户最大相关度信息。针对不同的用户,根据所采用的推荐技术可以将信息推荐方式可分为以下几种[121]:
a)基于规则的个性化推荐。基于规则的个性化推荐是指通过设定规则来实现个性化的信息推荐,规则来源于用户定制,也可以利用用户的静态信息或用户动态属性信息通过关联规则的挖掘技术来制定。基于规则的个性化推荐是根据用户已阅读感兴趣的内容推算出用户还没有阅读到的感兴趣内容,推荐给用户,规则本质是IF-THEN语句,即根据及时获取的用户动态兴趣特征来将相关的其他信息资源向用户进行推荐。基于规则的个性化推荐的缺点是随着规则数量的增多,基于规则的推荐系统的管理变得很困难。常见的基于规则的个性化推荐系统有ILOG,WebSphere等。
b)基于内容过滤的个性化推荐。基于内容过滤的个性化推荐是指将信息资源与用户兴趣特征进行比较,计算相似度,向用户推荐相关的信息资源,这样可以将更新的信息资源及时与用户的特征库进行匹配,推荐给用户相关信息资源。其优点是简单、有效,缺点是资源内容的风格和品质难以区分,推荐给用户的只是用户已有兴趣相似的资源。常见的基于内容过滤的个性化推荐系统有LIRA、Web Personalizer,CiteSeer等。
c)基于协作过滤的个性化推荐。这种推荐方式是根据用户的相似性来推荐资源,其基本问题是进行用户聚类,通过用户描述文件的比较分析、聚类,根据同类用户的相似性向用户推荐新的感兴趣内容,实现依赖于用户的评价,用户的特征获取和聚类分析。其实现仍然依赖于用户兴趣特征的获取,用户兴趣库与信息资源库的匹配。这种推荐方式的缺点是在系统使用初期,由于对信息资源的评价较少,难以利用评价发现相似用户;随用户数量的增多,系统性能会降低,常见的基于协作过滤的个性化信息服务推荐系统有Web Watcher,LikeMinds,Firefly等。
在信息推荐过程需要根据不同的需要选择不同的信息推荐方式,且每一种推荐方式都依赖于用户兴趣特征的获取,用户兴趣库与信息资源库的匹配,这几种方式可以使用户及时获取动态信息资源。
个性化服务体系构建需要经过上述4个过程,服务体系在运行过程中需要考虑用户兴趣的动态变化以及信息资源的更新,所以系统需要从用户那获取信息反馈,或者用户模型构建过程保证用户的参与,这样可以对系统进行修改完善,对用户模型进行更新、改进,进而提供更高质量的服务,形成一个从用户需求表达到用户需求信息提供的循环过程,满足用户的个性化动态信息需求。其中个性化信息推荐依赖于其他过程,也是个性化信息服务的最终实现形式,根据不同应用可以选择不同的推荐方式以保证用户的需求得到满足。
3.4.3 个性化信息服务体系模式介绍
个性化信息服务模式是指个性化信息服务的内容或种类,是一种服务策略。通常个性化信息服务模式有以下几种[122]:
①个性化定制服务。这种模式是指用户根据自己的兴趣和需求向系统定制所需要的信息资源,个性化定制包括内容定制、界面定制、检索定制等。个性化定制可以直接获取用户的需求信息,是一种拉取式服务,这种模式下的系统可以赋予用户不同权限,不同的风格界面,这样不同用户可以访问到不同资源,以满足不同的个性化需求。
②个性化信息推送服务。个性化信息推送服务模式是系统首先进行用户信息的收集,然后将资源推送给有需求的用户。个性化信息推送服务是一种主动式服务,这种模式下用户可以向系统提供自己感兴趣信息,也可以向系统输入请求,系统通过频道式、邮件式等方式定时向用户提供服务。
③呼叫中心服务。这种模式是一种基于计算机电话集成技术,对通信网和计算机网进行多功能集成的综合的信息服务系统。这种模式下用户可以通过电话、传真、Modem拨号等方式接入系统,在系统帮助下访问数据库,获取用户所需要的信息资源。呼叫中心服务模式现在一般应用到图书馆中,尽量满足用户的信息需求。
④垂直门户服务。垂直门户服务模式是通过将互联网上某一特定专题信息资源进行收集,然后挖掘、加工,以满足专业用户的深入信息需求,其特点是对网上特定信息资源进行收集、鉴别、过滤、组织、评论,附带有专业搜索引擎。这种模式可以让一些专业用户获取更深层次的信息。垂直门户服务又称专题门户服务,即满足专业用户的信息需求,主要应用于图书馆,以满足不同背景、不同专业的用户的需求。
在当前网络化时代,因特网个性化信息服务是个性化信息服务的重要发展方向,对因特网下个性化信息服务模式的研究,有助于用户获取个性化需求信息的有效性。文献[123]提出了因特网个性化信息服务的几种模式:以用户为中心的智能化系统(HCIS),信息推送服务,检索帮助服务,呼叫中心服务,信息的专题门户服务。其中,HCIS服务模式以用户为中心,充分考虑每一个用户的需求,能让用户根据面临的问题与系统交互;帮助检索服务模式可以帮助用户轻易地进入搜索系统数据资源的主题领域与内容范围。个性化信息服务在网络化时代下,将更多的体现网络化特征,以网络为载体,开展个性化信息服务。文献[124]提出了因特网个性化信息服务的新模式,包括面向用户的个性化信息助理(PISA)和面向主题的主题信息代理(SIA),这种模式可以充分表达用户信息需求,信息查询目的性强,效率更高。
4 个性化信息服务支撑技术
个性化信息服务需要技术的支撑,尤其在网络环境下,信息资源形式和数量的增多,用户个性化信息需求强烈,计算机技术、信息技术以及各种存储技术是开展个性化信息服务的保证。通常个性化信息服务的支撑技术有以下几种:
4.1 面向个性化服务数据挖掘技术
数据挖掘技术是指以数据库和机器学习为基础,从大量的、有噪声的、模糊的、随机数据中,挖掘抽取出隐含的、潜在的有用的信息和知识的过程[125]。其中,数据库等存储技术是数据挖掘技术的关键,挖掘过程需要机器推理、学习等实现。面向个性化信息服务的数据挖掘过程需要以用户为中心,了解用户的需要,然后针对用户特定的需求,对数据库中数据进行挖掘、过滤等方式进行处理,以满足用户的个性化需求。数据挖掘技术是个性化信息服务的关键技术之一,可以对信息资源进行深层次挖掘,对用户需求进行更高层次分析,提供给用户高质量服务。
网络化时代,信息资源的数字化以及网络化存储,面向个性化的数据挖掘技术更多的应用于网络,通过Web挖掘实现个性化信息服务。Web挖掘是针对网络用户的注册信息,浏览行为信息,反馈信息,站点文档等信息进行抽取分析的,其过程分成三个阶段:预处理,即对收集的数据进行初步处理,如清除脏数据等;模式挖掘,即用不同的Web挖掘算法发现用户访问模式;模式分析,即从模式挖掘的模式集合中选择出有意义的模式[126]。
为了提高个性化信息服务的质量,数据挖掘技术将与其他技术结合,共同支撑个性化信息服务的开展。与人工智能技术的结合,运用机器学习、知识发现等技术,解决个性化系统领域中许多问题,会促进个性化系统的发展。与交互式多媒体技术结合,将支持海量多媒体数据流的内容挖掘,使其更能满足用户需要[127]。
4.2 面向个性化的信息过滤技术
个性化信息服务需要获取用户的兴趣等特征信息,然后根据需求对信息资源进行整合,将符合用户需求的信息推荐给用户,在整个服务过程中,需要利用信息过滤技术对用户信息进行获取,抽取信息资源的特征词以便进行整合,同时反馈给用户进行个性化推荐过程中,需要利用信息过滤技术对信息进行优化,这样才能保证个性化信息服务的针对性和高效性。面向个性化信息过滤技术可以分为基于内容的过滤和基于协作的过滤两种。其中协作过滤是指根据用户之间或资源之间的相似性进行过滤,以获取所需信息。协同过滤一般分为两类[128][129]:基于用户的协同过滤,即将对同一项目评分相似的用户认为是一类,根据用户的最近邻居,对用户进行聚类、过滤分析[130];基于项目的协同过滤,即根据用户对若干不同的项目的相似性来过滤、分析用户对项目评价特征,以预测用户对其他项目的评分[131]。随着用户数和项目数的增多,面向个性化的协同过滤算法,也随之增大,在协同过滤中,需要对用户或项目进行聚类,常见的聚类算法有[132]:EM算法,k-means聚类算法,Gibbs Sampling方法,模糊聚类方法等。文献[133]提出了一种基于时间加权的协同过滤算法,解决了由于兴趣动态变化推荐不佳的问题,提高了推荐系统的服务质量。
根据不同的信息需求,面向个性化的信息过滤有不同的模型,常见的信息过滤模型有[134][138]:
①基于智能Agent的网络信息过滤模型。该模型有知识库、规则库、推理机以及各Agent之间的通信协议构成。当用户发出信息请求时,Agent就会在知识库中查找是否有用户以前的相似信息,如果有,就将以前的记录返回给用户,如果没有,系统就会生成一定的搜索规则,搜索生成信息数据库,然后利用推理机制推理出用户的潜在需求,以提供服务。在信息过滤过程中,知识库是各种关系数据库的结合,通过知识库的匹配、过滤,返回给用户所需要的信息。
②自适应信息过滤模型。自适应信息过滤模型指首先根据少量用户的需求信息构建需求模板,然后通过在过滤中自主学习用户的反馈信息来增强和完善模板的准确性。文献[135]提出基于增量学习和阈值优化的自适应信息过滤模型,即首先运用增量学习方法对少量相关文档进行学习,然后采用改进的文档词频方法抽取特征词,完善模板,最后结合概率模型和文档正例分布统计方法实现阈值优化,这种模型适应了在线信息过滤的需求,提高了系统整体性能。文献[136]提出基于特征选择的自适应信息过滤模型,该模型引入特征选择技术,对用户模板进行动态调整,构建出自适应的单模块和多模块系统,这种模型能准确表达用户的兴趣信息。
③基于Rough集理论信息过滤模型。Rough集理论是一种有效分析和处理不精确、不一致和不完整信息并发现隐含知识,揭示潜在规律的数学工具。基于Rough集理论信息过滤模型需要首先对网页等内容进行分词处理,对分词结果进行特征提取,计算权重,建立决策表,然后用基于Rough集理论的属性约简算法对决策表进行约简,得到规则集,这种模型方法,降低了信息冗余度,提高了准确率,对于个性化信息服务来说,可提高服务质量,提供给用户更准确信息。
④基于向量空间(SVM)的信息过滤模型。文献[137]在传统信息过滤技术基础上,针对动态用户兴趣信息,提出了基于向量空间的信息过滤模型,该模型由分词模块,特征选择模块,文本表示模块,训练SVM模块,过滤模块和反馈模块构成。其中在反馈学习中,引入了SVM的增量学习算法,优化了信息过滤系统的性能。
面向个性化的信息过滤技术在个性化信息服务中起到重要作用,随着用户需求的增加,信息量的增大,对信息进行过滤,以满足用户的特定需求成为一种迫切需要,面向个性化的信息过滤技术更多注重用户兴趣及表示,用户兴趣的动态变化等,在以后发展过程中,信息过滤技术将为个性化信息服务提供更大帮助。
4.3 面向个性化的信息推送技术[139]
面向个性化推送技术是指服务器根据预先规定的设置文件,有目的性的按时将用户感兴趣信息发送到用户计算机中的技术,这种技术需要用户首先根据自己的信息需求,设定所需要的信息频道,然后服务系统根据用户的需求,定时推送信息服务。面向个性化的信息推送技术可以有以下几种实现方式:邮件方式,即用电子邮件方式主动将用户感兴趣信息推送给列表中注册的用户;客户代理方式,即使用客户代理定期对Web站点搜索,收集更新信息反馈给用户;频道方式,即首先Push服务器收集信息形成频道内容推送给用户,然后客户部件将接收到的数据进行处理,推送给用户。个性化推送技术的流程是:首先根据用户提交的信息需求建立用户需求管理数据库;然后根据从网上搜集来的信息,经过分类整理,建立信息库;最后利用推送服务器把信息库中符合用户需求的信息按照一定方式在适当的时间推送给用户。
面向个性化的信息推送技术是个性化信息服务的关键技术之一,在个性化服务过程中,Push服务器不仅把信息返回给用户,还要能够根据用户设定的频道、特定的需求,及时主动地向用户推送更新的动态信息。面对信息量巨大,类型繁多的形势,面向个性化信息服务的信息推送技术的发展将结合人工智能技术,知识发现技术,Internet即数据库技术,以便提高推送的效率和质量,更好地满足用户的个性化需求。
4.4 面向个性化的智能代理技术[140]
面向个性化的智能代理技术是指通过跟踪用户的信息活动,自动挖掘、捕捉用户的兴趣偏好,代替用户访问信息资源,而不需要或很少需要用户的干预、指导。面向个性化的智能代理技术能实现以下功能:智能搜索功能,即通过分析用户的信息需求,自动查找搜索用户需要的信息;导航、帮助功能,即通过系统自动存储、查找,告诉用户所需信息资源的位置,并帮助用户查找相应信息资源;信息过滤功能,即根据用户的需求条件,对推荐的信息资源进行过滤处理,提供给用户有用的信息;知识挖掘功能,即对相关信息经过聚类、分类整理后,从大量数据中提取有价值信息和知识;信息推送功能,即把经过智能处理后的信息资源及时推送给相应的用户。面向个性化的智能代理技术实现方法通常有信息抽取法,信息过滤法和信息共享法三种。
面向个性化的智能代理技术提高了信息检索和推送的准确率,弥补了传统搜索引擎针对性差的不足,通过及时获取用户的兴趣、偏好特征,提高信息检索的自主性和灵活性。面向个性化服务的智能代理技术在发展过程中由于智能的机械性,需要注意用户需求信息的准确性,用户的隐私安全等问题,需要实时、更多的与用户沟通,以及时反映用户的信息需求,有针对性向用户提供个性化服务。
4.5 面向个性化的Web数据库技术及网页动态生成技术
Web数据库技术是指在网络环境下使用数据库技术,对网络上用户兴趣、偏好等信息以数据形式存储,更好地对用户信息进行管理,而动态网页生成技术是指将用户的信息以动态网页的形式呈现。面向个性化的Web数据库技术及动态网页生成技术是伴随着计算机技术、网络技术发展起来的,是个性化信息服务发展的重要支撑技术,也是个性化信息服务发展的要求。
由于数据技术的数据存储具有语法严谨,面向对象,机器易理解,实体-属性-联系的结构简明等优点,Web数据技术使得信息资源更容易获取[141],对于个性化信息服务而言,简化对用户等信息的获取、存储,服务效率更高。Web数据库技术通常采用3层或多层体系结构:即前端使用客户机浏览器技术向Web服务器发送请求,Web服务器通过中间件对数据库执行查询等操作,然后反馈给用户相应的信息,如图5所示Web数据库技术具有跨平台的优点,统一标准HTML使Web数据库具有强大适应性。动态网页生成技术主要用ASP,JSP等技术,对用户的数据动态生成网页(图5)。
在Internet技术普及的今天,Web数据库技术及动态网页生成技术为个性化信息服务提供强大技术支撑,为网络用户的个性化信息需求提供便利服务。
![]()
图5 Web数据库技术结构
4.6 面向个性化的信息检索技术
个性化信息服务中,用户提交用户请求后需要对数据库中信息进行检索,反馈给用户所需要的信息。个性化信息检索技术是指针对不同用户的不同需求提供个性化检索结果的技术。随着Internet技术的发展,信息资源的增多,用户对个性化信息检索的需求越来越强烈,而传统的搜索引擎在相关匹配,用户使用上显现不足,无法满足用户的个性化需求,个性化信息检索也就成为一种必然。面向个性化的信息检索技术是在充分挖掘、表达用户兴趣、偏好等信息需求的基础上,对信息资源进行深度检索,将最有价值、最相关的信息反馈给相应的用户,其原理为:用户选择主题,提出查询请求,然后用户个性Agent确定用户兴趣,经搜索程序查找相关信息后,过滤、相关度排序,反馈给用户[142]。
面向个性化信息检索的实现需要对用户的兴趣、行为、偏好等特征进行识别,构建用户模型,以更好的表达用户需求,然后使用信息代理Agent确定用户的个人兴趣偏好,并应用检索过程。个性化需求对信息检索的要求越来越高,需要利用信息检索技术对用户的兴趣等特征进行根本性识别,然后针对特定领域、特定专题信息进行深度检索,这样用户的个性化需求才得以满足。基于此,文献[143]对基于本体的个性化信息检索进行了研究分析,从本体的角度,对表示用户的关键词进行概念表述,考虑词与词的关系,词与词的上下位关系来进行信息检索,可以推荐给用户潜在的兴趣,提高了信息检索的质量。文献[144]针对传统搜索引擎检索面窄,无法满足用户个性化需求的缺点,对垂直搜索引擎技术进行了研究。垂直搜索引擎从搜索引擎基本原理出发,通过个性化需求的组织,垂直搜索引擎个性化体系构建,结合用户兴趣模型来进行检索,以满足用户的个性化需求。垂直搜索引擎可以为用户提供针对特定领域,特定人群的信息检索服务,提高了检索的针对性。
面向个性化的信息检索技术是个性化信息服务的保证,尤其在“信息爆炸”的今天,信息资源增长迅速,提供个性化的信息检索服务才能满足用户的个性化需求。随着信息技术的发展,信息检索将更能体现个性化特点,在发展过程中,面向个性化的信息检索应考虑以下几点[145]:用户动态兴趣的获取及特征识别;检索结果的计算性能;用户界面的友好、简易等。
4.7 面向个性化的实时参考咨询技术
在信息过载的时代,人们面对大量的信息,在获取所需信息的过程中,会面临很多问题。面向个性化的实时参考咨询技术是指利用网络技术、计算机技术、通信技术等在虚拟环境下,咨询专家对用户咨询的问题进行即时回答,并与用户讨论的技术。这种技术支撑下,用户可以获取相应专家的解答,针对性强,实时性好,保证与用户的交互,这样个性化信息服务的质量更高。目前实时参考咨询技术主要应用于图书馆,大多是基于chat技术来实现的,常见的咨询系统有:专业的实时咨询系统,如Virtual Reference Toolkit,24/7 Reference等;自主开发的在线实时交互系统,这是一种基于动态网页技术来实现的;基于实时交流软件的实时参考咨询系统,如QQ、MSN等,可以实现聊天、文件传送等服务。
面向个性化的实时参考咨询技术主要是针对网上信息,基于网络技术、通信技术来开展个性化服务的。文献[146]针对网上信息大量化、数字化的特点,提出了网上实时参考咨询系统的设计,系统采用了XML,HTTP技术,隐藏帧刷新技术,框架结构等技术,主要模块由数据层,控制层和应用层组成。系统注重用户的反馈调查,以更好反映、满足用户的个性化需求。
实时参考咨询服务当前的发展处于初期阶段,主要限制瓶颈是没有足够的技术支撑,如何有效获取用户的咨询,然后及时将用户所需信息推送给用户是一个问题,基于Web的用户呼叫中心软件成为实时参考咨询技术的主要应用模式[147]。实时参考咨询技术研究目前主要以数字参考咨询为主,其发展趋势为[148]:基于知识库网上多咨询台的分布式实时合作系统,即将基于FAQ数据库管理作为知识库管理,开发基于集团或联盟的分布式多咨询台实时合作咨询系统;Web呼叫中心,即解答知识库咨询,网页推送等功能的实现;基于视频传送的虚拟咨询实时解答系统,这种系统可以方面用户与咨询员面对面交流,交互性能好。
4.8 面向个性化的信息门户技术
面向个性化的门户技术是综合性广、实用性强的技术,用户根据自己的兴趣设定频道,通过个性化门户入口实现定制等形式的服务。面向个性化门户技术目前由于开放性、完整性的缺陷,很多功能没有得到实现,目前个性化门户技术主要应用于图书馆。
面向个性化的门户技术可实现用户的专用信息的获取,对个性化信息服务来说,门户技术是一个强大的支持。一个良好的门户应该满足以下要求[149]:用户界面友好,简单、易操作;组织性要好,以方便查找;具有智能服务性,即用户所需的服务无需依赖管理员;可扩展,即支持新的数据格式和访问方式;安全性要好,即能识别用户;兼容性要好,能支持来源不同、结构不同的数据。门户技术的发展会使个性化信息服务的质量得以提高,服务更有效。
4.9 面向个性化的隐私保护技术
个性化信息服务的过程就是信息的挖掘、筛选、过滤、传送的过程,这个过程中隐私保护必须予以考虑,从用户信息的收集到相关信息反馈给用户无不涉及信息的安全。面向个性化的隐私保护技术是指在保护用户隐私的前提下,开展个性化信息服务的技术,其目标是既能满足用户的个性化需求,向用户提供个性化服务,又能有效保护用户的隐私。面向个性化隐私保护技术是有效个性化信息服务的保证。
当前面向个性化的隐私保护关键技术有:匿名技术,即通过隐藏、不收集用户的敏感信息,允许用户提交数据而不暴露身份的技术,如K-匿名技术等;关联规则中的隐私保护技术,包括数据干扰、查询限制等;协同过滤中隐私保护技术,通常有密码学等技术。文献[150]对个性化信息服务中的隐私保护技术进行了综述、总结,对隐私保护技术的发展趋势进行了展望:重点是深入研究协同过滤中隐私保护技术;隐私保护的标准化;隐私保护的性能问题;个性化推荐与隐私保护技术结合。面向个性化的隐私保护技术的发展应该以用户为出发点,在充分了解用户的需求、意愿前提下,进行个性化服务,使用户最大程度的满意。
5 个性化信息服务的应用
随着Internet技术的迅猛发展和Internet资源的快速增长,个性化技术的研究已经在科学领域脱颖而出。目前,个性化服务已经成为网络技术和智能信息处理中的研究热点。经过近几年的不断发展,虽然个性化服务技术还不太成熟,但已经实实在在地走进了我们的生活,并在有限的条件下给我们带来了新的视点,为广大用户和企业带来了明显的价值。
5.1 应用中的“个性化”理念
随着Internet的发展,当今社会已经进入信息“爆炸”的时代,传统图书情报部门大量的资源数字化也极大地增加了网上信息资源规模。在浩如烟海的信息世界中,我们需要认真考虑:图书情报部门怎样利用自己的优势,带领人们在信息海洋中摸索出正确的方向,并充分利用自己的宝贵资源,为用户提供个性化信息服务[151]。目前“个性化”这一理念已经广泛地渗透到社会各领域,正改变着服务方式,从以往的“我提供什么,用户接受什么”到“用户需要什么,我就提供什么”[152]。王知津教授在《论信息服务十大走向》[153]一文中指出:网络信息环境下的信息服务有十大走向:服务理念从信息本位走向用户本位、服务目标从信息资源走向问题求解、服务对象从大众服务走向细分市场、服务内容从信息服务走向知识服务、服务方式从单一化走向多元化、服务人员从专业型走向复合型、服务环境从物理空间走向虚拟空间、服务时间从有限走向无限、用户角色从被动走向参与、用户经历从功能走向体验。由此看出,“个性化服务”已经在信息服务领域占有一席之地。
近几年,相关学者就对个性化信息服务在各个领域的前景做了分析[154]:未来的八大领域—电信、银行、证券、保险、水利、民航、电力、教育将不遗余力地建设网络,采用个性化应用服务。时至今日,个性化已在相关领域得到了成熟的应用,具体我们将在下面详细介绍。
关于个性化信息服务的概念,尽管表述不一,但其核心内容基本是一致的,即个性化信息服务是在了解用户的个性化需求的基础上提供针对性的服务。个性化信息服务将“用户至上”这一理念的贯彻落实变为可能。个性化信息服务的目标一般具有以下几点:
(1)与用户的双向沟通更加便捷。个性化信息服务系统不仅要提供友好界面,而且要方便用户交互,方便用户描述自己的需求,方便用户反馈对服务结果的评价。要能够跟踪与了解用户的习惯、爱好、兴趣和需求,以便改进服务内容与服务方式,为其提供“量身定制”的个性化信息服务。
(2)服务内容更加集中,更加丰富。个性化服务系统可以为用户提供并集中最接近其个性需求的各种信息资源,排除不相关信息的干扰,极大地节约了用户从信息海洋中搜寻的时间。它提供的信息内容极为丰富,信息类型包括全文数据库、书目数据库、事实与数值型数据库、各类电子文本、各类参考资料、各种资源链接及信息服务人员实时提供的信息等。
(3)服务方式更加灵活多样。不仅要为用户提供更加准确的信息,而且还要能够按照用户指定的方式进行服务,如满足用户对信息的显示方式、提供方式(纸质、电子版、网络版、电子邮件等)的要求,以及服务时间、服务地点等要求。
(4)更为注重主动性与时效性。个性化服务系统能够保证信息的时效性,并且能够主动将符合用户特点与需求的信息及时推送给用户。
(5)使用更加方便。在用户创建用户名和密码后,可以在任何地方通过互联网浏览器登录系统。
个性化服务的提出给信息服务理念、服务方式、服务内容带来了深远的影响,对提高信息服务水平起到了强大的推动作用。具体讲,包括以下几个方面[155]:
(1)个性化信息服务能真正满足用户的多样化需求,是培养个性、表现个性的服务。用户的信息需求丰富多彩,信息获取技术千差万别,用相同的用户界面和服务方式并不能适应用户的需求。个性化服务可以协助用户智能化获取信息资源,能有效克服传统收藏、组织和使用信息资源方式中的被动性、局限性和时效性差的问题。
(2)个性化信息服务是信息服务发展的方向,是推动信息服务水平的强大动力。新的信息时代的到来和信息革命对人类社会的冲击,是展现个性、倡导创造力的一个崭新契机。因此,只有个性化的信息服务才能在信息时代中站稳脚跟,才有可能使信息服务业得到迅速有效的发展,而图书馆也可以借此改变其信息服务的被动局面。
(3)个性化信息服务有助于推动我国信息化建设。从全社会的信息化的发展来看,个性化信息服务引导用户的信息需求,吸引用户步入信息世界,成为信息的使用者和提供者,从最基础的层次上推动全社会的信息化建设,加速信息社会的成长。
5.2 个性化信息服务应用现状
现阶段的个性化信息服务比较广泛地应用在数字图书馆、网络学习、新闻传播及电子商务等领域,当然也有其他的行业的相关应用。
5.2.1 数字图书馆
图书馆作为人类知识交流的载体,其作用是不言而喻的。数字图书馆是网络环境下现代信息技术发展与人类信息知识需求发展相结合的产物,她是一个庞大的数字化资料库,包括现有馆藏的数字化形式,新采购的封装型电子出版物、全文数据库,通过因特网采购或下载的网络电子出版物及其他免费资源等,以及与此相关的提供远程服务的信息检索系统。从业务内容的角度,我们将其功能描述为五个方面:数字化信息的采集、数字化信息的存储与管理、数字化信息的访问与查询、数字化信息的传送与发布、数字化信息的权限管理[156]。
读者对于信息、知识的多样化、个性化的需求不断增大,因此,迫切要求数字图书馆能够根据读者的特点提供服务,即提供个性化的服务模式,个性化服务是培养个性、引导需求的服务,是图书馆在网络和数字信息环境下,提高服务质量,赢得发展机遇的重要选择。其实质是通过掌握读者个体知识结构与群体知识结构的差异。提供完善读者个体知识结构所需的信息和知识,实现高效的知识转移,提供优质的知识服务[157]。
随着个性化技术的进一步发展,如用户建模技术、信息过滤技术、数据挖掘技术、信息推送技术、智能Agent技术、个性化推荐技术等,这些个性化技术也应用到数字图书馆面向用户的信息服务中,解决面向服务中的个性化问题[158]。今天,运用这些技术,数字图书馆可为用户提供两类个性化信息服务——个性化定制和个性化推荐,运用个性化定制服务技术,可以让用户去创建和维护自己的个性化网页,数字图书馆定期自动提供个性化的信息服务,使之能适应数字图书馆用户多样化的需求,也有助于把图书馆的专业信息资源和学科馆员的专门服务提供给相应的用户,在很大程度上改进了数字化资源的利用效率,也大大提高了数字图书馆的服务质量[159]。目前,数字图书馆个性化定制服务在国外已经形成了初步成果,有代表性的比如美国康奈尔大学图书馆的My Library、北卡罗莱纳州立大学图书馆开发的MyLibrary@NCState及英国混合图书馆项目的Headline PIE等。Mylibrary系统在用户类型复杂、信息资源丰富的大馆,具有较高的运行效率,国内许多数字图书馆的研究都在效仿My Library的服务模式,2000年初,社会科学基金资助的“基于Web的数字图书馆定制服务系统”项目开始研究开发实用的图书馆个性化定制系统。而各高校图书馆也先后开始这方面的研究与应用,清华大学、人民大学、浙江大学等图书馆引入或开发的图书馆个性化服务已经投入应用。此外,图书馆自动化集成系统商也开始关注个性化定制服务,今后开发的图书馆自动化集成系统将可能包含个性化定制服务功能。
信息推送服务是数字图书馆提供的一种主动化的服务方式。像广大用户熟知的“邮件订阅”,就是一种典型的信息推送服务。信息推送主要依靠推荐系统,此系统不仅能够根据用户的特征提供具有针对性的信息,还能够通过对用户专业特征,研究兴趣的智能分析而主动地向用户推荐其可能需要的信息[160]。这方面的技术国外已经相当成熟,如Siteseer[161],且很早就提出了推荐系统,如图6所示[162],但此应用在数字图书馆上还是初步,特别是国内,发展相对滞后。
数字图书馆的个性化服务不仅仅只体现在技术改进上,在内容形式上也逐渐凸显出个性化的特征。如数字图书馆在设计时要考虑服务的对象,采取可满足用户特定信息需要的个性化信息服务模式,提供用于获取和支配信息资源的书目工具,用户与数字图书馆的深层次交流可以借助书目情报的交换来完成[163]。还有人提出图书馆引进博客,为馆员与读者提供交流的平台和信息导航,做好参考咨询服务,进行学术项目研究等[164]。再者,可以从用户界面考虑,发展多通道、多媒体的智能用户界面,目前,这种理想的智能用户界面在短期内不能实现的,国外也还只是处于预测研究和探索的阶段[165]。

图6 数字图书馆中的推荐系统
5.2.2 远程教育
远程教育是个性化信息服务典型应用之一,随着计算机、多媒体技术的飞速发展和广泛应用,远程教育(E-Learning)突破了传统教学方式的物理限制,为更多的人提供了丰富的学习资源和方便、灵活的教学环境。网络教育逐渐成为人们获取知识,实现终身学习的重要手段。
近年来,我国现代远程教育已经取得了很大进展,特别是在广播电视大学领域,如河南电大[166]以远程教育、系统办学为主要特色,该校2006年选择了Cenwave网络多媒体实时交互系统,通过Cenwave网络多媒体实时交互平台为全省电大各教学管理部门及学校、老师、学生之间搭建一个覆盖全省跨地区的网络多媒体实时交互平台;多人语音、多路视频、共享白板、共享电子文档、文件传输、即时文字等多种交流方式。在网络上构建多个虚拟的网络会议室或网络教室,从而实现如精品课堂直播、远程教学辅导、远程教师培训、网络视频会议、学术研讨网络会议、学生毕业答辩等多方面的应用,满足网络课堂直播及远程实时辅导答疑等远程教育培训、省电大管理部门和所属分校的网络视频会议等。
在网络环境下,个性化服务是一种网络信息服务的方式,个性化服务的根本就是尊重用户,研究用户的行为习惯与兴趣,为用户选择更需要的资源,提供更好的服务。网络课程作为目前网络教育的重要资源,以其独特的魅力走进网络教育教学之中。根据网络课程的特点,所设计的个性化服务体系一般应具有以下结构,如图7所示[167]。

图7 网络课程中个性化服务体系结构
网络课程的主要对象是学生,是辅助学生学习的平台,所以网络课程中所要搜集的信息主要包括用户登记的信息和用户日志信息,形成用户档案文件,这样能够更好地了解掌握用户的行为,并针对不同的用户制定不同的服务策略。
上述是从接收者角度考虑,如果从资源角度来讲,个性化服务中不可避免地要涉及共享和重复利用教学资源的问题。但是远程教育由于缺乏统一的标准和技术手段,不同的系统使用不同的文档格式,各自开发独立的资源系统,系统平台、数据库、数据结构、类型定义、资源描述以及资源的最终形态都有很大差异,造成了网上资源分散和不规范的现状。文献[168]提出现阶段正在研究采用XML来描述资源,XML的最大特点是能够以开放的方式结构化地表示数据信息,利用XML描述资源可以从本质上改变资源的描述方式,对资源的格式标准的统一、资源的扩展性、灵活性和个性化特性等带来了根本性的革新。而且近来形成了一系列的标准,包括SCORM,IMS,LOM和AICC等。其中LOM(Learning Object Metadata)[169]通过扩展库使得索引和搜索成为学习对象的目标,以便更好共享资源,然而它的缺陷在于描述学习对象时缺少语义理解。
在远程教育平台中,为了解决学习控制、个性化的引导、调节等而导致平均学习效率低下的问题,文献[170]提出一种基于知识点架构的个性化课程导学模型,它是实时地定制出适合于学习者个体的学习内容。目前,Ontology主要应用于信息检索、信息集成、知识获取等方面,在远程教育中,基于Ontology的数据挖掘也仍有很大的应用前景。它多采用实时、真实的数据来更新全局路径和原始Ontology的策略来提高导学的效率,该方法提高了学习者的学习积极性和学习质量。
5.2.3 新闻传媒
网络新闻服务是传统新闻媒体在网络空间力量的延伸,比起传统新闻更具有时效性。现在新闻的服务方式也逐渐从“拉”向“推”转变,如RSS阅读器的应用。RSS阅读器是一种软件或是说一个程序,这种软件可以自由读取RSS和Atom两种规范格式的文档[171]。打个比方说:可以读取RSS和Atom文档的RSS阅读器就如同一份自己订制的报纸。每个人可以将自己感兴趣的网站和栏目地址集中在一个页面,这个页面就是RSS阅读器的界面。通过这个页面就可浏览和监视这些网站的情况,一旦哪个网站有新内容发布就随时报告,显示新信息的标题和摘要,甚至全文。这些信息可以是文本,还可以是图片、音乐、视频。另一种意义上,RSS阅读器就像一个临时标签,能够时时记录个人浏览的历史记录。它以每个使用者的阅读历史判断信息的新旧,用户阅读过的就被认定为旧信息,未被阅读的被当作新信息。因此,这些网站每一次更新的记录(未读的)都不会被错过,即使用户好几天才有机会上一次网。现在尽管RSS技术在美国已进入互联网主流领域。Yahoo!,Amazon.com,Ebay.com等巨头纷纷把自己的新闻、产品信息等转换成RSS格式,以满足快速增长的RSS用户需求。但在中国,RSS近年才出现,如Google阅读器、Netvibes、抓虾、新浪点点通、周博通等,它们一般自定义标签,显示新闻摘要或标题,拓展性和交互性强。但到目前为止,大多数人对RSS还并不熟悉。由于RSS提供自定义式的个性化服务,可以很好的将广告和推销置之门外,也避免了订阅邮件时带来的垃圾邮件,所以RSS阅读器得到了很多人的欢迎。甚至有人这样描述:“RSS不是一个技术名词或标准名称,而是一个‘新媒体’的概念。这个‘新媒体’因其更好的时效性、个性化、可操作性和互动性而对传统平面媒体和互联网媒体产生着革命性的冲击。”
近年来,网络新闻服务更重视从传统的文字模式向图片、音频、视频以及新闻动画等多媒体新闻模式转变,这样就为读者的个性化需求带来挑战。
从提供方来说,目前研究几种在应用集成上所采用的是Web服务技术,基于Web页的网络新闻服务是目前网络新闻服务最普遍方式。对这种方式下个性化新闻服务研究融合了数据仓库技术、数据挖掘技术、WWW技术、信息检索技术、移动计算技术以及多媒体技术,图8是一个应用Web服务架构提供网络新闻服务的示意图[172]:
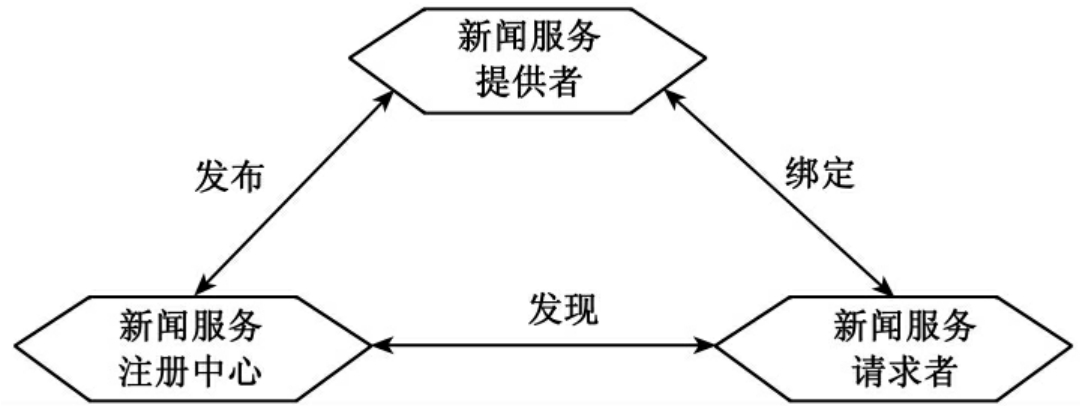
图8 基于Web服务架构的网络新闻服务
新闻请求者可以是新闻单位或者读者个人,新闻提供者可以是新闻单位,新闻单位的远程服务器以及自由撰稿人,新闻注册中心是被业界公认的提供新闻注册、目录内容管理以及新闻发现匹配的机构。按照Web服务的一般流程,新闻请求者和新闻提供者的交易通过新闻注册中心的发现服务联系起来,不再是传统的新闻请求者和提供者之间的交互。由于新闻单位可以是新闻请求者,因此各新闻机构之间新闻的交流和共享可以统一在这个框架内进行。现代信息社会更注重与读者交流,这使得新闻服务模式也进一步发生变化,更多的研究人员将目光投向以Java和XML编程模式支持读者个性化新闻定制和阅读交互机制,从而提出了基于XML标准的Web Service的架构模式,把它作为新闻服务的客户端,提高了个性化网络新闻定制和阅读的交互性[173]。
从接收方即用户来讲,相关研究多集中在信息接收效率及交互模式的研究上,其中交互式流媒体点播应用是热点,现有交互式流媒体系统中各对象统计特性的研究,主要是对远程教育系统中的学生交互行为的分析,从而对教学资源布局,教学方式改革等有重要参考作用[174]。伴随移动信息服务的飞速发展,个性化新闻推荐也得到了发展,有人运用智能信息处理对每个移动用户的新闻访问行为序列进行跟踪、记录、建模和分析,将个性化特征归类存储,实现了实时地个性化新闻推荐。也可以对新闻内容进行信息抽取,进一步考虑新闻节点的内容和用户访问行为序列的相关性,以更好提供智能化的信息服务[175]。
5.2.4 电子商务
电子商务个性化是指电子商务企业向客户提供个性化服务,主要包括:需求的个性化定制、信息的个性化定制和对个性化商品的需要。电子商务个性化在改善顾客关系、培养顾客忠诚度以及增加网上销售方面具有明显的效果,经常看到一些公司或网站关于个性化服务的宣传,比如定制自己感兴趣的信息内容、选择自己喜欢的网页背景色、根据自己的需要设置信息的接收方式等[176]。
基于电子商务的众多个性化服务为交易各方主权的实现提供了有效地依托,其中,个性化定制信息需求和个性化增值服务将成为其发展的重要方向。目前关于电子商务个性化服务的研究大多数集中于B2C领域,主要满足终端消费者的个性化需求,内容包括网上商店的营销、购物搜索服务等[177]。
电子商务的发展模式对企业服务提出了许多新要求,其中,最为突出的一个问题就是商品选购的个性化推荐问题,为用户推荐符合兴趣爱好的商品。它最大优点在于能收集用户兴趣并根据用户兴趣偏好为用户主动做出个性化的推荐,而且系统给出的推荐是实时更新的,这意味着用户每次登录网站系统所给出的推荐都是动态变化的。一般推荐类型有四种:基于规则的系统,基于内容过滤系统、基于协作过滤系统,这些前文已做详细介绍,这里不再赘述。一般说来,推荐系统在电子商务活动中的作用可以归纳为以下几点:帮助用户检索有用信息、促进销售、个性化的服务,提高客户忠诚度。目前国内的电子商务网站在这方面的实践尚处在初级的阶段[178]。国外相对来说就比较成熟了,如耐克公司为顾客提供个性化服务的网站——Nikeid.com,在这个网站上,顾客们可以根据自己喜好选择材料、样式,提出自己的个性需求。据统计,个性化网站建成后的一年内,耐克公司这项订购个性运动鞋的销售额仅在美国就上升了18%,业绩达到近6亿美元。Amazon是一个虚拟的网上书店,提供先进的个性化推荐功能,能为不同兴趣偏好的用户自动推荐符合其兴趣需要的书籍,它能对顾客购买过的东西进行自动分析,然后因人而异地提出合适的建议。
电子商务在技术上也用到了现行先进技术,文献[179]提出了面向服务计算,可作为SOA的一个直接产品,以解决电子商务服务与信息技术支持的问题。文献[180]提出了基于本体理论的个性化建议,组织在线商品类术语,建立本体推理算法,本体推理显示出可以改善用户分析,预测用户的偏好,提高建议的准确性的功能。在移动商务方面,许多公司已投资数十亿美元来加强移动电子商务硬件和软件平台的功能,泛在环境下的个性化信息服务势在必行[181]。
5.2.5 其他领域
近年,个性化服务也越来越广泛地应用到其他领域。在农业上,越来越多的人认识到科学致富的重要性,渐渐地计算机技术也融入农业生产中。我国农业信息化建设远没有达到其推进农业发展的要求。农业个性化信息服务理念是根据我国现阶段的国情提出的,它是利用广大农民现有的信息设备条件,向农民提供不同方式和不同内容的农业信息服务。其着手农业当前,服务农业长远。有人很早就论述了数字化图书馆在农业高科技人才培养、农业信息资源利用、信息服务和现代化农业生产中的重要服务功能。例如为农业科研生产人员提供个性化定制服务,是指按农业科研生产人员要求定制特殊用户界面、根据用户的需求搜寻并提供符合用户需要的特定信息、用电子邮件向注册用户发送最新农业科技信息和生产信息,使用户及时获得有价值的信息等。文献[182]还介绍了一种可以为农业科研生产者提供交互智能化参考咨询服务。农业个性化信息服务体系与广大农民用户进行交流的方式如互联网、手机短信、语音电话及电视广播等,是随着科技手段的不断更新而变化的。而且广大农民对互联网从接受到认识,再到应用也是需要一个较长的过程的。国外在这些方面的应用就广泛多了,文献[183]对相关方面做了详细介绍。美国发展农业信息化是以政府为主体、区域信息机构为主线,形成国家、地区、州三级农业信息网。印度从农村信息需求入手,结合行政体系,采取公私合营模式走出一条农业信息化服务的新路。日本则是因地制宜的发展应用型农业信息化的典型代表,建立了区域农业信息化体系;欧盟则在大力发挥官方的作用下,利用管家技术发展农业信息化。加拿大在其农业发达的情况下,大力发展精确农业,使农业成为全国支柱性产业。文献[184]提出运用全球定位系统(GPS)、个人数字助理(PDA),创建一个电脑化的树库存的果树管理,并通过个人电脑运行定制的地理信息软件(GIS),然后自动检索图像数据,再加上遥感图像的技术使得用户能更详细了解个别树木的成长情况。
除了农业以外,还有医疗、旅游业。如电子病历,它并不是纸张病历的简单电子化,其实质为一个具备诸多医疗功能的智能型计算机系统,这个系统具备向使用者提供患者医疗信息;提示和警示医疗人员;给予临床决策服务;连接管理、书刊目录、临床基础知识以及其他设备的基本功能。由于电子病历可以为医务人员提供及时准确的信息,可以及时便捷地实现患者医疗信息的共享,更好地服务于患者,同时也服务于医院的现代化管理,因此电子病历[185]一经诞生便显示了强大的生命力的应用实质跟在电子商务中的应用类似,只不过资源对象不同而已,它是利用某一信息平台将涉及食、住、行、游、购、娱六大方面的旅游服务集成在一起,使各行业间信息更顺畅的流通,然后具有推荐功能的电子商务平台可根据用户个人资料、兴趣、用户日志等信息来推断其需求偏好,过滤掉相关性差的信息,再到旅游产品数据库中寻找匹配信息,从而将符合用户兴趣的相关产品信息推荐给用户[186]。
5.3 影响个性化服务应用障碍研究
个性化服务经过了十多年的发展,无论是在实践领域还是在理论研究上都取得了很大的进展,然而仍然存在一些问题,如用户需求的表达与理解问题、知识产权与隐私保护问题、标准问题、反馈问题以及用户识别等。具体来讲,有下列障碍[187]:
5.3.1 用户需求的表达与理解问题
在实际情况中,用户需求的表达和理解却是不完全的,主要原因有两点:用户自身表达的信息不完全和系统对信息需求的理解不完全。
5.3.2 知识产权与隐私保护问题
信息服务为用户提供了信息下载服务,这在促进信息共享、减少用户获取信息的成本的同时,也出现了严重的恶意下载等一系列侵权问题,严重的侵犯了创作者的合法权益,同时也打击了人们创作的热情。
5.3.3 标准问题
一方面是技术层面,开展个性化信息服务需要统一的标准以解决互操作问题,同时也可与国际接轨;另一方面是宏观规划与组织,要尽快制定规划,避免重复建设,造成资源浪费。
近几年来,我国的一些远程教育学校在应用ISO9000标准进行质量管理方面作了一些尝试。然而,纵观全局,并没有达到预期效果。究其根本,主要在于对远程教育这一特殊领域的职能及产品、顾客的特殊性认识不够,对在远程教育领域实施标准化质量管理存在的问题认识不足,导致应用中流于形式,盲目套用[188]。
5.3.4 反馈问题
现有的系统缺乏与用户的互动,无法获知用户对服务的反馈。现在的系统设计却忽视了用户的反馈,仅仅将信息推送给用户。
5.3.5 用户识别问题
现今的个性化服务多采用口令识别方式。通过调查问卷、填写表格以及对用户行为的跟踪与监视来建立用户信息模型,这是一个长期、动态的过程,然而不可否认的是同一台主机可能有多个用户,若用浏览器识别方式势必会造成用户信息模型不准确,个性化信息服务无法准确实现。
5.3.6 技术问题
在技术方面,个性化服务技术的研究比较分散,大多数是从理论上探讨各种个性化服务的技术,对这些技术之间的关联、集成应用的探讨较少。虽然有的技术已相当成熟,但与个性化服务实践结合并取得实际应用效果的不多,因此,如何集成各种技术以实行更好的个性化服务是今后应当关注的重要问题。
5.3.7 信息组织与整合问题
随着信息的网络化,人们寻求信息更多的趋向于专业化、课题化、个性化。面对庞杂的信息资源,系统通常是提供简单的网址引导,加工深度浅,资源间的知识关联度不高,缺乏基于内容的组织管理,对于信息的分类整理也不精确,各个网站标准不一样,划分的结果也不尽相同。对于网站的简单链接不能直接汇聚用户所需要的信息,用户同样需要从各个网站中提取和选择对自己有用的信息。虽然系统的简单组织已经减少了人们搜集和组织信息的成本,但要满足用户个性化、专深化的信息需求还远远不够。
除此以外,还有其他一些非主导因素,如宣传、广告因素,信息需求的迫切性与信息接收的被动性,多层次需求与提供单一性服务的矛盾等[189]。
由此可以看出,影响个性化信息服务的因素很多,目前,个性化信息服务支撑技术的不成熟以及个性化信息服务研究型人才的匮乏,已成为个性化信息服务的一大瓶颈。因此,现阶段个性化服务机构必须根据目前个性化信息服务的整个大环境以及自身的实力等因素,加快个性化信息服务研究型人才的培养,并不断跟踪国内外新技术的发展,这样才能紧跟信息化的浪潮,为社会和人民提供越来越有效的个性化信息服务[190]。
5.4 个性化服务的应用前景
在Web信息服务方面,个性化信息服务的思想在国外网站设计与发展中已经盛行,但它们为用户提供的通常只是一般性的消息,不能满足用户寻找专业知识的需求。下一代个性化服务不再仅仅停留于大众化的娱乐性或专业性资讯类信息的提供,而是把用户的许多个人业务处理也加入服务的范畴。这种新的个性化信息服务将成为一种深入用户个人生活、工作各个层面的辅助性工具,是以往很多分别实现各种功能工具的一种集成环境。要实现这种集成化的信息服务,需要信息服务机构与其他相关部门在技术上与业务上的合作,而且由于我国的信息应用水平还不是很高,因此,这一进步需要一个相当长的时期。
个性化服务本身就是“以用户为中心”思想的具体体现。个性化服务最关键的是推荐系统,一个完整的推荐系统由3个部分组成:收集用户信息的行为记录模块,分析用户喜好的模型分析模块和推荐算法模块。推荐系统可以分为如下几类:协同过滤(collaborative filtering)系统;基于内容(content-based)的推荐系统;混合(hybrid)推荐系统以及最近兴起的基于用户—产品二部图网络结构(network-based)的推荐系统。基于网络结构的推荐算法不考虑用户和产品的内容特征,而仅仅把它们看成抽象的节点,所有算法利用的信息都藏在用户和产品的选择关系之中。用户—产品二部图(bipartite network)建立用户—产品关联关系,它实际是基于网络结构的推荐算法的基础,基于网络结构的算法开辟了推荐算法研究的新方向[191]。
网络的发展为实现个性化的信息服务奠定了坚实的物质基础,在网络环境下,个性化服务的对象也从过去个别的重点对象发展为广泛的各类对象,针对个性化服务新的特征,我们可以看出个性化网络服务技术的几个发展趋势:个性化网络信息定制技术趋于成熟;个性化网络信息推送技术走向完善;个性化网络信息的Web挖掘技术向纵深方向发展;个性化网络信息检索技术走向高度智能化[192]。有人运用SC(服务协同)技术,它是一种高粒度、高抽象性、高灵活性的新型的中间件技术。在原有系统的基础上,结合业务过程管理技术和个性化服务系统的特点,增加了SC生成层,对传统的个性化服务系统进行了改进,提出了一种适用于用户个性化需求服务的基于个性化服务系统[193]。另一方面,个性化系统对界面的要求也越来越高,据国外媒体报道,谷歌已经宣布,对谷歌“自定义搜索”(Custom Search)服务进行升级,推出更加个性化的用户界面,同时丰富搜索结果。谷歌的“自定义搜索”服务可以为网站内容发布商在其网站内创建谷歌搜索栏,并提供具有针对性的搜索结果。另外,升级之后,谷歌“自定义搜索”还可以在搜索结果中提供小幅图片和命令提示键。例如,一个书籍自定义搜索可以包括书籍的封面图片,同时提供书籍的下载链接等点击选项[194]。
泛在(Ubiquitous)信息社会也称未来信息社会,随着IT技术的不断发展,其被普遍认为是人类未来的生活模式。普适计算(Ubiquitous computing)是实现泛在的一项关键技术,其最显著的特征是把计算从桌面转换到随时随地,扩大了服务范围和个人移动性[195]。将普适计算的模式运用于数字图书馆,人们可以在任何时间、任何场所,获取图书馆的信息资源和得到信息咨询服务。把普适计算引入到数字图书馆的建设过程中,将极大地优化图书馆应用环境,扩展了数字图书馆的服务。普适计算使数字图书馆实现按需学习成为可能。学习者可以在任何地方,任何时间,得到他们所需要数字图书馆所具有的文档、数据和视频等各种学习信息。这些信息的获取是基于学习者自身的需求的,因此学习是一种自我导向的过程,是一个适量学习的过程[196]。真正实现个性化服务中“所得即所需”的理念。而在远程教育领域的应用也大有前途,在普适计算框架下,进行远程学习的学员摆脱了桌面计算下十分被动的吸收知识的学习模式。普适计算下的随时随地和透明性服务,信息空间和智能空间高度的融合,智能教室的研究,改变了传统远程教育中教师和学生相互分离的情况,实现了在远程教育中师生尽管不在同一空间也能面对面进行交流,让学生充分感受到真实课堂的气氛,这无疑能促进远程教学质量的提高。因此,普适计算用于远程教育的相关研究,必将带来教育技术的新发展[197]。
继“e-Business”、“随需应变”、“创新”等一系列理念之后,IBM终于全面揭开新理念——“智慧的地球”的面纱,将它推到了聚光灯前。“智慧的地球”的目标是让世界的运转更加智能化,涉及个人、企业、组织、政府、自然和社会之间的互动,而他们之间的任何互动都将是提高性能、效率和生产力的机会[198]。在服务内容变得更加复杂时,图书情报机构可集中精力充分发掘信息资源,改善服务方式,发挥个性化信息服务优势,使得社会越来越智能化也越来越人性化。
【参考文献】
[1]Riecken,D..Personalized Views of Personalization[J].Communicationsof the ACM,2000,43(8):27-28.
[2]Blom,J.Personalization—a Taxonomy[C].CHI 2000 Conference on Human Factors in Computing Systems,New York:ACM,2000:313-314.
[3]Blom,J.,Monk,A.F..Theory of Personalization of Appearance:Why Users Personalize Their PCs and Mobile Phones[J].Human-Computer Interaction,2003,18(3):193-228.
[4]Oulasvirta,A.,Blom,J..Motivation in Personalization Behavior[J].Interacting with Computers,2008,20(1):1-16.
[5]史田华.因特网个性化信息服务[J].情报资料工作,2002(1):31-38.
[6]薛菘.基于Web数据库平台的图书馆个性化服务:My Library[J].图书情报工作,2002(8):22.
[7]王悦.新信息环境下图书馆的个性化信息服务刍议[J].图书情报工作,2002(8):17.
[8]李勇,徐振宁,张维明.Internet个性化信息服务研究综述[J].计算机工程与应用,2002(19):183-188.
[9]于迎,仲超生,网络环境下的个性化信息服务研究[J],图书馆工作研究,2003(1):37-39.
[10]王富民,新时期图书馆信息个性化服务初探[J],图书馆论坛,2003(5):118-120.
[11]Callan,J.,Smeaton,A.,Beaulieu,M.,Borlund,P.,Brusilovsky,P.,Chalmers,M.,et al..Personalization and Recommender Systems in Digital Libraries[EB/OL].Joint NSF-EU DELOS Working Group Report,http://www.ercim.org/publications/workshop-reports.
[12]丁浩,林云,Internet上的个性化信息服务[J],计算机系统应用,2005(8):36-39.
[13]胡昌平,邓胜利著.信息服务与用户[M].武汉:武汉大学出版社,2008:281.
[14]樊国萍.我国个性化信息服务研究综述[J],新世纪图书馆,2005(5):22-25.
[15]司徒俊峰,曹树金.面向个性化服务的信息组织本体模式[J],情报理论与实践,2009,32(11):93-97.
[16]周珍妮,夏南强.浅议因特网个性化信息服务存在的问题及其对策[J],图书与情报,2008(5):59-63.
[17]吴真明.试析网络环境下的个性化信息服务[J].图书情报知识,2003(6):66-67.
[18]胡昌平,邓胜利著.信息服务与用户[M].武汉:武汉大学出版社,2008:279.
[19]易天舒,赵瑞雪,赵鹏举.数字环境下个性化信息服务研究[J].农业图书情报学刊,2005,17(12):43-46.
[20]卢共平.数字图书馆的个性化信息服务[J].图书情报工作,2002(8):10-12.
[21]李春等.个性化服务研究综述[J].计算机应用研究,2009,26(11):4001-4005,4009.
[22]曾春,刑春晓,周立柱.个性化服务技术综述[J].软件学报,2002,13(10):1952-1961.
[23]王曰芬,吴小雷.个性化信息服务的影响因素与评价研究[J].情报科学,2005(8):1183-1186.
[24]Robert Armstrong,Dayne Freitag,Thorsten Joachims,Tom Mitchell.Web Watcher:A Learning Apprentice for the World Wide Web[J].School of Computer Science,Carnegie Mellon University,March 19,1997.
[25]Balabanovic,M.,Shoham Y..Learning Information Retrieval Agents:Experiments with Automated Web Browsing[C].Proceedings of the AAAI Spring Symposium Series on Information Gathering from Heterogeneous,Distributed Environments,March,1995:13-18.
[26]Henry Lieberman.Letizia:An Agent That Assists Web Browsing[C]//Burke,R.,ed..Proceedings of the International Joint Conference on Artificial Intelligence.Menlo Park,CA:AAAI Press,1995:924-929.
[27]Joachims,T.,Freitag,D.,Mitchell,T..Web Watcher:a Tour Guide for the World Wide Web[C]//Georgeff,M.P.,Pollack,E.M.,eds..Proceedings of the International Joint Conference on Artificial Intelligence.San Francisco:Morgan Kaufmann Publishers,1997:770-777.
[28]Mladenic,D..Machine Learning for Better Web Browsing[C]//Rogers,S.,Iba,W.,eds..AAAI 2000 Spring Symposium Technical Reports on Adaptive User Interfaces.Menlo Park,CA:AAAI Press,2000:82-84.
[29]http://my.yahoo.com[EB/OL].
[30]Balabanovic M..Shoham Y..Fab:Content-Based,Collaborative Recommendation Communications of the ACM,1997,40(3):66-72.
[31]Tanja Joerding.A Temporary User Modeling Approach for Adaptive Shopping on the Web[C/OL].Proceedings of the 2nd Workshop on Adaptive System and User Modeling on the WWW.1999,http://wwwis.win.tue.nl/asum99/joerding.html.
[32]Lieberman,H.,Dyke,N.V.,Vivacqua,A..Let's Browse:a Collaborative Browsing Agent[J].Knowledge-Based Systems,1999(12):427-431.
[33]Bollacher K.D.,Lawrence,S.,Giles,C.L..Discovering Relevant Scientific Literature on the Web[J].IEEE Intelligent Systems,2000,15(2):42-47.
[34]WebSphere:http://www.ibm.com/websphere.
[35]http://inquirus.nj.nec.com/i2/inq2.pl[EB/OL].
[36]http://www.amazon.com/[EB/OL].
[37]http://www.ebay.cn/[EB/OL].
[38]http://www.bestbuy.com/[EB/OL].
[39]http://www.expeida.com/[EB/OL].
[40]路海明,卢增祥.基于多Agent混合智能实现个性化信息推荐[J].高技术通讯,2001,11(4):28-31.
[41]冯翱,刘斌,卢增祥,路海明,王普,李衍达.Open Bookmark——基于Agent的信息过滤系统[J].清华大学学报,2001,(3):56-58.
[42]潘金贵,胡学联.一个个性化的信息搜集Agent的设计与实现[J].软件学报,2001,12(7):1074-1079.
[43]徐振宁,张维明,陈文伟.基于Ontology的智能信息检索[J].计算机科学,2001,28(6):21-26.
[44]谭琼,李晓黎,史忠植.一种实现搜索引擎个性化服务的方法[J].计算机科学,2002,29(1):23-25.
[45]王艳,张帆,杨炳儒.基于Web挖掘的数字图书馆个性化技术研究[J].情报杂志,2007(1):37-38,42.
[46]李桂贞,郑建明.基于智能信息推拉技术的数字图书馆主动信息服务[J].情报杂志,2007(2):65-67.
[47]王欣,江芸.国内外数字图书馆个性化信息服务系统剖析[J].图书馆工作与研究,2008(11):62-65.
[48]石德万,莫均超.基于词频统计的个性化信息服务研究热点分析[J].情报探索,2007(7):14-16.
[49]Saverio Perugini,Marcos Andr'e Gonc,alves.Recommendation and Personalization:A Survey[R].May,2002.
[50]Jongyi Hong,Eui-Ho Suh,Junyoung Kim,SuYeon Kim.Contextaware System for Proactive Personalized Service Based on Context History[J].Expert Systems with Applications,2009(36):7448-7457.
[51]Xing Jiang,Ah-Hwee Tan.Learning and Inferencing in User Ontology for Personalized Semantic Web Search[J].Information Science,2009(179):2794-2808.
[52]余力,刘鲁.电子商务个性化推荐研究[J],计算机集成制造系统,2004(10):1306-1313.
[53]王翠萍.国内外图书馆Mylibrary个性化服务系统比较研究[J].情报资料工作,2004(3):67-70.
[54]周虹,孙明节.浅议网络环境下图书馆个性化信息服务[J].西
华师范大学学报:哲社版,2004(4):151-153.
[55]郑辉.21世纪图书馆服务新模式[J].现代情报,2004(3):151-152.
[56]曹树金等.论图书馆个性化服务的几个基本问题[J].大学图书馆学报,2005(6):33-39.
[57]张玲,孙坦.数字图书馆个性化信息服务的演变与发展[J].图书情报工作,2005(1):41-44.
[58]杨宝洪.数字图书馆个性化信息服务面临的几个现实问题[J].现代情报,2007(9):94-96.
[59]李阳晖.数字图书馆的个性化服务发展趋势分析[J].图书馆论坛,2008,28(4):109-112.
[60]王爱娟,论网络环境下图书馆信息服务的个性化及发展趋势[J].现代情报,2007(12):141-142.
[61]焦玉英,陈瑜.基于Web的高校图书馆用户个性化信息服务[J].图书馆学刊,2009(1):1-4.
[62]冯晖,晏臻恺.图书馆服务的个性化趋势[J].图书馆理论与实践,2009(9):14-16.
[63]陈清文.泛在图书馆的特征[J].图书馆杂志,2008(3):12-14.
[64]蔡冰.论图书馆泛在服务模式实现的路径和方式[J],图书馆工作研究,2009,53(13):74-77.
[65]邵波,宋继伟.国内外电子商务个性化服务研究分析[J].情报杂志,2008(7):78-80.
[66]Deng,H.,Li,W.,Agrawal,DP..Routing Security in Wireless Adhoc Networks[J].IEEE Communication Magazine,2002,40(10):70-75.
[67]程显静.新形势下如何提升高校图书馆服务水平[J].内江科技,2009(9):75-76.
[68]嵇智辉,倪宏,匡振国.网络资源描述和组织方法研究[J].计算机工程与应用,2009,45(8):90-92.
[69]王海鹏,周兴社,张涛.面向普适计算环境的资源描述方法[J].计算机工程与应用,2009,45(3):20-23.
[70]胡昌平,邓胜利.基于用户体验的信息资源整合分析[J].情报学报,2006,4(2):231-235.
[71]胡昌平,王翠萍.基于个性化服务的信息资源组织目标、原则与规范[J].图书馆论坛,2004,12(6):137-141.
[72]章成志,苏新宁.信息资源整合的建模与实现方法研究[J].现代图书情报技术,2005(10):60-63.
[73]邓三鸿,金莹,秦嘉杭.基于知识管理的数字资源整合策略[J].情报科学,2006(10):1489-1493.
[74]李枫林,胡昌平.面向用户的网络信息资源整合策略[J].中国图书馆学报,2004(5):47-49.
[75]王宁,韩胜菊,李怀明等.基于实体—关系—问题建模体系的信息资源整合建模研究[J].大连理工大学学报,2007,3(2):295-300.
[76]鲁舟,朱国进.基于RDF的个性化资源集成模型的研究与应用[J].计算机应用研究,2005(10):69-73.
[77]崔瑞琴,孟连生.数字信息资源整合问题研究[J].图书情报工作,2007(7):35-37.
[78]汪会玲,刘高勇.从面向资源的信息资源整合到面向用户的信息资源整合[J].图书情报工作,2005(7):45-48.
[79]孙波.泛在知识环境下我国图书馆信息资源建设策略研究[D].长春:东北师范大学,2009.
[80]陈代春,叶文清.信息共享空间:高校图书馆服务发展新趋势[J].图书馆学刊,2008(4):83-86.
[81]胡昌平,邵其赶,孙高岭.个性化信息服务中的用户偏好与行为分析[J].情报理论与实践,2008,31(1):4-6.
[82]吴辉娟,袁方.个性化服务技术研究[J].计算机技术与发展,2006,2(2):32-35.
[83]索红光,杨涛.基于WWW缓存的用户长期兴趣发现[J].计算机系统应用,2006(12):59-61.
[84]宗胜,徐博艺.面向情境兴趣的文本信息过滤系统[J].情报科学,2007,7(7):1085-1088.
[85]左晖,张玉峰,艾丹祥.个性化知识服务中基于Ontology的用户兴趣挖掘研究[J].情报学报,2008,2(1):18-23.
[86]Xing Jiang,Ah-Hwee Tan.Learning and Inferencing in User Ontology for Personalized Semantic Web Search[J].Information Science,2009(179):2794-2808.
[87]雷莹,冯玉强.基于软约束满足理论的用户偏好建模方法[J].华南理工大学学报,2008,4(4):115-121.
[88]Javier Larrosa,Thomas Schiex.Solving weighted CSP by Maintaing Arc Consistency[J].Artificial Intelligence,2004:1-29.
[89]付关友,朱征宇.个性化服务中基于行为分析的用户兴趣建模[J].计算机工程与科学,2005,27(12):76-78.
[90]刘海霞,李后卿.信息消费心理及行为分析[J].情报杂志,2004(2):52-53.
[91]应晓敏.面向Internet个性化服务的用户建模技术研究[D].长沙:国防科学技术大学,2003.
[92]Rucker J.,Polanco,M.J..Siteseer:Personalized Navigation for the Web[C].Communications of the ACM,March 1997,40(3):73-75.
[93]Joachims,T.,Freitag,D.,Mitchell,T..Web Watcher:A Tour Guide for the World Wide Web[J].Artificial Intelligence,Japan.1997:8.
[94]应晓敏,刘明,窦文华.一种面向个性化服务的客户端细粒度用户建模方法[J].计算机工程与科学,2003,25(6):39-53.
[95]应晓敏,刘明,窦文华.一种面向个性化服务的无需反例集的用户建模方法[J].国防科技大学学报,2004,24(3):68-71.
[96]Balabanovie,M.,Shoharn,Y..Learning Information Retrieval Agents:Experiments With Automated Web Browsing[C].Proceedings of the AAAI Spring Symposium Series on Information Gathering from Heterogeneous,Distributed Environments,March,1995:13-18.
[97]Pazzani,M.,Muramatsu,J.,Billsus,D..Syskill&Webert:Identifying Interesting Web Sites[C].Proceedings of the 13th National Conference on Artificial Intelligence,Menlo Park.California,1996:54-61.
[98]Mladenic,D..Personal WebWatcher:Design and Implementation[R].Technical Report IJS-DP-7472,Dept of Intelligent Systems,J.Stefan Institude.
[99]Chen,L.,Sycara,K..WebMate:A Personal Agent for Browsing and Searching[C].Proceedings of the 2nd International Conference on Autonomous Agents and Multi Agents Systems. Minneapolis MN,May 10-13,1998.
[100]Billsus,D.,Pazzani,M..A Hbrid User Model for News Story Classification[C].Proceedings of the 7th International Conference on User Modeling(UM'99).Baff,Canda:98-108.
[101]吴丽花,刘鲁.一种基于神经网络的信息推荐方法[J].计算机工程与应用,2005(25):13-15.
[102]Konstan,A.et al..GroupLens:Applying Collaborative Filtering to Usenet News[J].Communication of the ACM,1997,40(3):77-87.
[103]吴丽花,刘鲁.个性化推荐系统用户建模技术综述[J].情报学报,2006,25(1):55-62.
[104]李业丽,林鸿飞,姚天顺.基于示例的用户信息需求模型的获取与表示[J].计算机工程与应用,2000,(9):11-18.
[105]武成岗,焦文品,田启家等.基于本体论和多主体的信息检索服务器[J].计算机研究与应用,2001,38(6):641-647.
[106]Lieberman,H..Letizia an Agent That Assists Web Browsing[C].Proc of International Joint Conference on Artificial Intelligence.Menlo Park,CA:AAA I Press,1995:924-929.
[107]赵庆峰.个性化信息服务系统理想模型的构建[J].情报杂志,2006,(2):14-17.
[108]卢喜利,周军,周月鹏.基于Cookie技术和启发式规则的用户识别算法[J].微计算机应用,2009,30(11):1-6.
[109]林霜梅,汪更生,陈弈秋.个性化推荐系统中的用户建模即特征选择[J].计算机工程,2007,33(17):196-199.
[110]黄光球,魏芳.基于贝叶斯动态预测模型的商品推荐方法[J].电子商务与物流,2007,24(5):133-135.
[111]Guihua Liu,Jianguo Ma.Personalized Information Service Model of Data Broadcasting Based on UCL[J].Intelligent Information Technology Application,2008(2):323-327.
[112]苏贵洋,马颖华,李建华.一种基于内容的信息过滤改进模型[J].上海交通大学学报,2004,38(12):2030-2034.
[113]丁蔚,倪波.因特网信息服务新模式[J].情报理论与实践,2000(2):132-135.
[114]杨风雷,阎保平.Web用户行为模式挖掘研究[J].微电子学与计算机,2008,25(11):146-149.
[115]冯是聪,单松巍,张志刚等.基于Web挖掘的个性化技术研究[J].计算机工程与设计,2004,25(1):4-6.
[116]Breese,J.,Hecherman,D.,Kadie,C..Empirical Analysis of Predictive A lgorithms for Collaborative Filtering[C].Proceedings of the 14th Conference on Uncertainty in Artificial Intelligence,1998,43-52.
[117]Deng Ai-lin,Zhu Yang-yong,Shi Bai-le.A Collaborative Filtering Recommendation Algorithm Based on Item Rating Prediction[J].Journal of Software,2003,14(9):1621-1628.
[118]A Rewar,B.,Karypis,G.,Konstan,J.,et al..Analysis of Recommendation A lgorithms for E-commerce[C].Processing of 2nd ACM Conference on Electronic Commerce,2000,158-167.
[119]Kim,BM.,LIQ,Park,CS.,et al..A New Approach for Combing Content-based and Collaborative Filters[J].Journal of Intelligent Information System,2006,27(1):79-91.
[120]马宏伟,张光卫,李鹏.协同过滤算法综述[J].小型微型计算机系统,2009,30(7):1282-1288.
[121]丛晓琪,杨怀珍,刘枚莲.基于时间加权的协同过滤算法研究[J].计算机应用与软件,2009,26(8):120-122.
[122]崔虹燕.基于智能Agent的网络信息过滤研究[J].兰州工业高等专科学校学报,2008,15(1):23-26.
[123]王金宝.基于增量学习和阈值优化的自适应信息过滤研究[J].计算机应用,2006,26(5):1109-1111.
[124]马玉春,孙冰.基于特征选择的自适应信息过滤研究[J].计算机工程,2006,32(5):172-174.
[125]周洪利.基于SVM的网络信息过滤研究[D].济南:山东师范大学,2008.
[126]吕静.基于Rough集理论的信息过滤研究[D].南昌:南昌大学,2007.
[127]郝亚玲.Push技术:网上个性化信息服务的实现[J].情报杂志,2002(10):55-57.
[128]程风刚.基于Agent的个性化信息服务模型的构建[J].计算机时代,2009(10):3-4.
[129]谷斌.基于Web数据库技术的动态网页发布[J].情报科学,2002,20(3):320-323.
[130]李爱明,刘冰.个性化信息检索系统的用户模型研究[J].情报杂志,2007(3):121-126.
[131]尹红丽.基于本体的个性化信息检索系统模型研究[D].济南:山东大学,2006.
[132]钟辉新.基于垂直搜索引的个性化信息服务探索[J].情报杂志,2008(1).
[133]李树青.个性化信息检索技术综述[J].情报理论与实践,2009,32(5):107-112.
[134]杨和东,吕世灵,张志平.网上实时参考咨询系统的设计与实现[J].情报学报,2006,25(1):94-98.
[135]Our Experiment in Online[EB/OL].[2009-04].Real-time Reference.http://www.infotoday.com/cilmag/apr01/broughton.htm.
[136]朱渝.实时参考咨询服务在国内开展的现状与分析[J].四川理工学院学报,2006,21(1):113-114.
[137]尹凯华,熊璋,吴晶.个性化服务中隐私保护技术综述[J].计算机应用研究,2008,25(7):1922-1926.
[138]北京国信贝斯软件有限公司.iBASE IGF:为图书情报部门建立个性化信息服务提供动力[J].中国信息导报,2001(5):58-59.
[139]毛军.网络环境下的个性化信息服务[J].计算机周刊,2001(44):15.
[140]王知津,徐芳.论信息服务十大走向[J].中国图书馆学报,2008,35(179):52-58.
[141]黄涌.网络建设个性化应用服务是未来——2002年八大行业IT应用市场回顾与展望[J].中国计算机用户,2003(1):8-9.
[142]夏立新等.数字图书馆导论[M].武汉:湖北人民出版社,2004:21-24.
[143]潘启灵.个性化服务是高校图书馆的生命之源[J].现代情报,2007(7):175-179.
[144]李阳晖,杨燕,黄萍莉.数字图书馆个性化服务的发展动因分析[J].情报科学,2008,26(4):520-524.
[145]孙晓希.数字图书馆个性化服务研究[J].科教文汇,2008(12):285-286.
[146]谢琳惠.推荐系统在高校图书馆的应用研究[J].现代情报,2006(11):72-74.
[147]James Rucker,Marcos J.Polanco..Personalized Navigation for the Web[J].Communications of the ACM,73-75.
[148]Giuseppe Amato,Umberto Straccia.User Profile Modeling and Applications to Digital Libraries[J].Istituto diElaborazione dell' Informazione,184-197.
[149]胡一女.基于网络环境的个性化数目研究[J].图书馆学研究,2008(7):48-51.
[150]覃凤兰.个性化服务:博客在高校图书馆的应用[J].现代情报,2007(4):171-173.
[151]王翠,郑春厚.以用户为中心的数字图书馆用户界面发展研究[J].探索与交流,2008(7):63-66.
[152]http://info.edu.hc360.com/2009/09/030605185183.shtml[EB/ OL].
[153]王丽影,刘媛媛,李建英.个性化服务在网络课程中的应用研究[J].办公自动化杂志,2009(166):36-51.
[154]汪仲阳,吉逸.基于XML的远程教育资源描述和管理系统的设计[J].计算机应用,2004,24(6):171-173.
[155]Ming Che Lee,Kun Tsai,ding Yen Ye.A Service-Based Framework for Personalized Learning Objects Retrieval and Recommendation[J].ICWL,2006:336-351.
[156]陈清华,丁鹏,金晶.学习指导的设计与实现[J].计算机仿真,2008,25(10):275-279.
[157]http://baike.baidu.com/view/721.htm?fr=ala0_1_1[EB/OL].
[158]赵杰.个性化网络新闻服务中用户兴趣学习算法的研究[D].济南:山东大学,2006.
[159]史永,王宜用,王东梅.基于Web Service的个性化网络新闻订阅[J].计算机工程,2006,32(10):283-285.
[160]刘威,程文青.流媒体点播中用户交互式行为建模[J].电子与信息学报,2007,29(9):2252-2256.
[161]张瑞华,周延泉,王枞,等.移动终端离线浏览系统的新闻推荐服务研究[J].2006,29(6):21-24.
[162]余力,等.电子商务个性化——理论、方法与应用[M].北京:清华大学出版社,2007:53-63.
[163]刘玎,蔡建峰,张识宇.基于个性化需求与个性化服务的B2B电子交易平台的构建[J].情报科学,2007,25(6):886-890.
[164]周惠宏,柳益君,张尉青,等.推荐技术在电子商务中的运用综述[J].计算机应用研究,2004(1):8-12.
[165]Qing Li,Jing Zhao.A Customer-Centric Service Framework for B2C Website Design:from a Service Computing Perspective[Z].The Sixth International Conference on E-Business,Wuhan.
[166]Siping He,Meiqi Fang.Personalized Recommendation Based on Ontology Inference in e-Commerce[Z].International Conference on Management of e-Commerce and e-Government,2008.
[167]Shuk,Ying.,Sai Ho Kwok.The Attraction of Personalized Service for Users in Mobile Commerce:An Empirical Study[J].ACM SIGecom Exchanges,3(4):10-18.
[168]赵晓光.数字化图书馆建设及其农业科技服务功能[J].安徽农业科学,2006,34(1):180-191.
[169]岳广飞,何明祥.关于我国农业个性化信息服务体系的构想[J].农业网络信息,2009(3):7-10.
[170]Roger J.Tait,Tony J.Allen,Nasser Sherkat.An Electronic Tree Inventory for Arboriculture Management[J].Knowledge-Based Systems,2009(22):552-556.
[171]齐爱民.电子病历与患者个人医疗信息的法律保护[J].社会科学家,2007(5):10-13.
[172]郭炜,高琳琦.电子旅游中间商的个性化信息服务模式研究[J].情报科学,2006,24(5):732-735.
[173]高利容.ISO9000在远程教育质量管理中的应用障碍与对策[J].教育管理,2009(4):63-65.
[174]郑恺煌.网络环境下影响高校图书馆个性化服务的因素[J].图书馆服务,2004(6):28-29.
[175]刘建国,周涛,王秉宏.个性化推荐系统的研究进展[J].自然科学进展,2009,19(1):1-15.
[176]张立彬,赵麟.个性化网络信息服务技术发展的新走向[J].情报科学,2007,25(7):1103-1108.
[177]邢文生,于亚征,李希臣.基于SC的个性化服务系统的研究与设计[J].电子工程师,2007,33(6):55-57.
[178]谷歌升级自定义搜索,推出个性化用户界面[EB/OL].[2009-10-27].http://www.techweb.com.cn/news/2009-10-27/454865.shtml.
[179]K.EI-Khatib,Zhen E.Zhang,Hadibi,N.,Bochmann,G.v..Personal and service mobility in ubiquitous computing environments[J].Wireless Communications and Mobile Computing,2004(4):595-607.
[180]王丽华.普适计算对数字图书馆发展的影响[J].图书馆学研究,2008(6):25-27.
[181]王英彦,邹霞,曾瑞.论基于普适计算框架下远程教育之远景[J].现代远距离教育,2007(6):62-65.
[182]刘琪.智慧地球:触摸信息化的本质[N].中国信息化,[2009-03].
作者简介

陆泉,男,1975年11月出生,汉族,工学博士,现任武汉大学信息管理学院副教授,硕士生导师,武汉大学信息资源研究中心与中国科学评价研究中心兼职研究员,中国信息系统学会CNAIS会员。近年来发表学术论文30余篇,其中20余篇被SCI、EI或ISTP索引;出版专著1部,教材3部;主持或参与国家及省部级项目8项,参加并实际负责大型横向项目多个。主要研究领域为:信息系统理论与方法、信息服务与用户研究、商务智能与决策支持系统、网络信息检索理论与信息服务系统等。
胡慧丽,女,1982年12月出生,武汉大学情报学专业2008级硕士研究生,计算机科学与技术专业工学学士。发表核心期刊及国家会议论文3篇,研究方向为信息检索、信息服务与用户研究。
邓晶,女,1986年10月出生,武汉大学信息管理学院情报学专业2009级硕士研究生,发表核心期刊论文2篇,研究方向为信息服务与用户研究。
陈德照,男,1987年出生,2006年至2010年就读于武汉大学信息管理学院信息管理与信息系统专业,2010年保送武汉大学信息管理学院管理科学与工程专业硕士研究生。发表核心期刊及国家会议论文2篇,研究方向为管理优化与决策支持。
【注释】
[1]本文系教育部人文社会科学研究项目青年基金项目(批准号09yjc870020)、武汉大学自主科研项目(批准号09ZZKY100)及教育部人文社会科学重点研究基地基金(批准号08JJD870225)研究成果。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











