



七、大海捞针与沙里淘金
中国有句俗语叫“大海捞针”,通常我们用来形容难以办到,或者是根本办不到的事情。在互联网时代到来以前,用“大海捞针”这个俗语来形容查找一条信息的难度是再贴切不过了。
在计算机和网络诞生之前,人们获得信息的途径主要有以下几种:报纸、广播、电话、电影等等。当电视出现后,获取信息的范围扩大了,但仍然是单方面的、被动的。
人们对信息的需求,首先是根据自己的兴趣爱好、继而是根据自己从事的职业和专业取向去收集、获得、保留和积累这些信息和数据。在电子工具出现之前,人们利用笔记、抄写、资料卡片、目录标签等记录,保存和查找相关的信息。然而,这样的方式存储量小,收藏保存不容易,搜索查找烦琐,资料更新和补充困难。在这样的时代,图书馆、情报所、档案馆等就成了信息存储的中心单位,并形成了一整套信息加工和存储的方法,如编码、编目、分类、标签、索引、查找等等。当我们需要查找一本书或一条信息时,我们必须用人工的方法通过一整套烦琐的程序去搜索查找所需要的资料,既耗时又费力。人们幻想,也许有一天,会出现这样一种工具,能够帮助人们在浩瀚的信息海洋里快速地搜索到人们所需要的材料和信息,使人们实现“大海捞针”的梦想。
当历史进入到了21世纪后,借助于计算机和网络,人们幻想中的那种工具终于出现了,这就是信息搜索技术。它的出现,真正实现了人们在信息的海洋里“大海捞针”的梦想。
1.打开信息宝藏大门的钥匙
记得吗? 阿里巴巴打开宝藏的大门是记住了“芝麻开门”的密语,阿拉丁借助“神灯”可以满足自己的愿望,在人们的梦想里,出现了成百上千的“宝物”可以帮助人们获得所需要的东西,什么“金钥匙”、“宝葫芦”……今天,在网络上可以找到所需要的任何“宝藏”:信息。
然而,网络中的“宝藏”太多了,使人眼花缭乱。人们一旦进入互联网,将见到成千上万个,不!上百万个网络地址、上亿条信息。要在网络上浩如烟海的信息中找出自己所需的信息,并且能够阅读和显示有关数据和信息,就必须借助某些网络辅助工具和程序。这些工具包括了信息检索、信息浏览、信息编辑、信息处理等软件。Internet网中提供了如Gopher、WAIS、Navigator、Internet Explorer、Firefox、Google、Baidu、Sogou等各种信息搜索、查询、浏览的工具,这就是打开网络信息宝藏大门的钥匙。
这些网络信息工具是一种计算机软件,通常被人们称为“浏览器”(Browser)。浏览器是一类信息搜索工具,它们的目的在于让用户在自己的电脑上方便地、容易地检索、查询、获取网络上的各种信息资源,可以将用户的请求自动转换成网络中的特殊命令,在浏览器的提示下,用户只需选取自己感兴趣的信息资源,浏览器就会按照这个需求,搜索整个网络、甚至是遍布全世界的网络站点上的相关数据库,找到相关的信息并返回给用户。千里之外的信息在几分钟内就来到用户的身边,这些宝贵的信息资源真的如同宝物一样,给我们带来了巨大的效益,信息就是金钱、信息就是生命,在当今已是不辨自明的事了。
早期的“信息钥匙”是基于菜单式的,如Gopher,WAIS等,人们在使用中觉得不方便,慢慢地就不愿用它们了。而功能强大的“万能钥匙”、基于Web搜索引擎的浏览器,用户却爱不释手。目前,Navigator和IE是人们津津乐道的最佳浏览器。然而,信息的海洋是如此广阔,稍有不慎就会在航海中迷失方向,迷途的用户将很难找到自己所需要的内容,此时,必须借助一种导航灯。这就是网络“搜索引擎”。网络搜索引擎是一种“万能钥匙库”,它可以帮助用户找到他想要找的任何东西,用户甚至只需给出想要查询的一个主题词,就会很快得到回答。这样的“万能钥匙库”已经在万维网(WWW)中建立了很多很多。
找到海量信息中的宝藏,就需要得到信息的钥匙!
有人统计,2005年中国人出的书是1949年以前出的所有书的总和,共计19万种。目前保持读书习惯的人仅占5%左右,我们怎么读书则成了信息时代人们遇到的一个问题。
信息时代的信息爆炸和信息快速交换,影响了人们的生活方式。社会戏称,人们在信息时代是一种快餐式的生存方式,复制型的生产方式和即兴式的思维方式。这都是因为一个因素:时间。
时间对每一个人都是一样公平的,而时间又是人们最难抓住和使用它的。在海量信息时代,对信息的获取、思考、处理和使用都需要时间,所有东西都关乎时间。因此,人们要学会最大限度地使用时间。
网络的普及将信息抛洒到更远的地方,让更多的人都能共享信息。当时间成为制约读书(报)的主要因素时,导致了人们对信息的阅读方式变成了“浅阅读”
“浅阅读”具有一种消费特征,即:快速、快感、快扔,也与人们读报纸杂志时的“读标题”相似。报刊标题国外通常称之为Highlight,就是“醒目”的标题,网络把Highlight发挥到了极致。网上的新闻、博客、语录都是这样的产物。现代人士认为,浅阅读,即浏览可以保持速度,保持与时代接轨,同时,给人带来一定程度的安全感。
浏览是海量信息时代的一种阅读方式,“浅阅读”并不是走马观花,而是看到自己喜爱的“花”和引起自己特别注意的“花”的时候,再停下来仔细欣赏和品味。自然,那就是细读、深读、品读的时候了。
朋友们,快到“万能钥匙库”中去拿到这些金钥匙吧,它会给你带来意想不到的惊喜、意想不到的“宝藏”!
2.谁为搜索装上引擎
“引擎”这个词你一定不会陌生。飞机之所以能在天上飞、火车之所以能在地上跑、轮船之所以能在海上行驶……它们都离不开一个给它们以动力的部件——发动机。
随着WWW的迅猛发展,目前互联网上的搜索引擎已经多达数百个,Google的信息数据库中存放的网页数量也已经多达40亿以上。要从浩若烟海的信息网络站点中存储的信息和数据中找到所需要的信息,用人工的方法是不可企及的,必须有一个工具,借助电脑的工具来帮助人们搜索、寻找和记录这些信息,把它们逐一地展示在用户面前。承担这种功能的工具被人们称为搜索引擎(Search Engine)。
如果我们把互联网看成是浩瀚的信息海洋,搜索引擎就是信息搜索的发动机。搜索引擎的出现,极大地提高了信息搜索的速度和质量。那么,谁是那个能工巧匠?谁为搜索装上了引擎呢?
1990年,当人们正在感叹从互联网上查找信息的艰难时,加拿大蒙特利尔McGill大学的学生Alan Emtage发明了Archie。这是一个利用文件名查询文件的信息系统,但它还不能算做真正意义上的搜索引擎。1993年,美国内华达州的SCS大学受Archie的启发开发出了与它非常相似的搜索工具Gopher,这个工具已具有检索网页的功能。
1993年6月,美国MIT的Matthew Gray开发了一个小程序叫做WWW Wanderer(WWW漫游者),用来统计WWW服务器的数量和捕获网址,这就是最早的搜索引擎。此后不久,一种名为“Computer Robot”(电脑机器人)的软件程序被开发出来。这种程序能像蜘蛛
一样在网络上爬来爬去,专门用于信息检索,被称做“网络蜘蛛”(Net Spider),诞生了利用程序在网络上自动获取并追溯网络链接的搜索引擎技术。这种搜索引擎技术可以自动分析、查找网络中具有一定访问量的网站,并根据网站中提供的“关键词”来自动将其进行分类、收录在本身的数据库中,当用户在其网站中输入一个特定的搜索关键词(Keyword)后,搜索引擎就会自动进入索引清单,将所有与搜索词相匹配的内容找出,并显示一个指向存放这些信息的连接清单供用户选择进入。

图1-5 网络蜘蛛:一种搜索软件
1994年,斯坦福大学的两名博士生David Filo和Gerry Yang(华裔学生杨志远)共同创办了超级目录索引Yahoo,成为最具现代意义的搜索引擎,此后的搜狐、新浪等都是这一时期的代表,它们的技术原理是通过将网络中不同类型的网站进行分门归类显示在主页上,人们可按分类一层层进入,最终就能很快找到所需的信息。
1998年,又有两个年轻人在美国加利福利亚州的硅谷(Silicon Valley)创造了一个具有时代意义的标志:Google。这两个年轻人便是美国斯坦福大学的学生,一个叫拉里·佩奇(Larry Page),一个叫塞尔吉·布林(Sergey Brin)(见图1-6)。他们有一个宏伟的想法:“要将全世界的信息汇集起来,让所有的用户都能够从我们这里方便地搜索到所需要的信息。”就是这个“敢为天下先”的思维,造就了当代信息搜索技术的帝国。
八年后(2006年4月12日),Google公司发布了其新的全球中文名称:“谷歌”,其含义为“播种和收获之歌”。这是Google唯一在非英语国家发布的名字,也是Google公司的现任董事长兼首席执行官埃里克·施密特(Eric Schmidt)访问中国期间正式发布这一名称的。Google的目标是“更好地组织全人类的知识”,在这样宏大的目标下,搜索引擎技术在不断地发展、增强和智能化。

图1-6 Google创始人
左:Larry Page,右:Sergey Brin
3.“大海捞针”与“沙里淘金”
搜索,是一种思路、一门技术,如何既快速又正确地找到所需要的信息,而且还要把它们汇集到一起?
搜索引擎是一个能够自动从因特网上搜集信息,经过一定整理后,提供给用户进行查询的系统。一般来说,搜索引擎总是由搜集器、分析器、索引器、检索器、用户接口等部件组成。所有这些都是为了一个目的:“无处不在的搜索”。
搜集器是搜索引擎的重要组成部分,就是一个计算机程序。它会定期地、自动地从Internet这张巨大的信息网络上搜索和摘取网页,检索、发现并搜集新的信息。它采用分布式和并行处理技术,以提高信息发现和更新的效率,每天可以搜集几百万甚至更多的网页。搜集器不停地运行,因为互联网上的信息更新很快,而且动态变化,需要对已经搜集过的旧信息进行更新,避免死链接和无效的链接。更新周期通常约为几周甚至几个月,索引数据库越大,更新也越困难。因此,网络蜘蛛也要排兵布阵,采用不同的搜集策略来对互联网上的信息进行遍历并下载。
分析器的主要功能是“分门别类”。它对搜集器搜集来的网页信息或者下载的文档进行分析,分门别类地建立索引。文档的分析技术一般包括:分词(抽取关键词)、过滤(保留需要的)、转换(类型转换等),这些分析技术与具体的语言以及系统的索引模型密切相关。
图1-7 Yahoo与Google搜索界面
索引器则是“按字索骥”。它配合分析器对分门别类的信息项进行处理,从中抽取出索引项,建立元数据索引项和内容索引项,前者与文档的语意内容无关,如姓名、网址、时间、编码、链接等,后者则用于反映文档内容,如关键词、权重、短语、单字等。而且,还要根据是英文、中文还是其他文字进行分类,最后生成文档库的索引表和索引数据库。索引数据库的格式是一种依赖于索引机制和算法的特殊数据存储格式,它的质量是信息检索系统成功的关键因素之一,而且应当是易于实现和维护、检索速度快、空间需求低。
检索器可就要进行沙里淘金了。它的功能是根据用户的查询在索引库中快速检出文档,进行文档与查询的相关度评价,对将要输出的结果进行排序,并将相关查找信息反馈给用户。检索器采用了集合理论模型、代数模型、概率模型和混合模型等多种信息技术,可以查询到文本信息中的任意字词,无论它们出现在什么地方。
人们会问:搜索引擎在哪里呢?其实,它运行和工作在专门的数据中心和信息中心中,它本身也可以以一种网站的方式体现出来,例如:Google和Baidu这样的网站。在这样的数据中心中,你能否想象成千上万台甚至数十万台计算机集合在一起同时运行的情景?这可不是耸人听闻。目前,大型互联网搜索引擎的数据中心一般要运行数千台甚至数十万台计算机。这些庞大的计算机群与一个小小的引擎相连,这个小巧的发动机驱动了庞大的机群,成为我们今天信息世界中的搜索动力机。这个动力机开始了这样一个工作过程:从互联网上抓取网页→建立索引数据库→在索引数据库中搜索→对搜索结果进行处理和排序。
经过数十年的发展,搜索引擎已经成为一种被大众消费的商品了,因而,随着不同消费需求的出现,今天的搜索引擎真可谓品种繁多,琳琅满目。它们各有所长、各具特色。除了我们上面刚刚提到的网页搜索引擎以外,人们还开发了多种多样、形形色色的信息搜索引擎。这些搜索引擎有:新闻搜索、音乐搜索、图像搜索、商务(商机)搜索、专利搜索、软件搜索、游戏搜索、法律搜索等等。
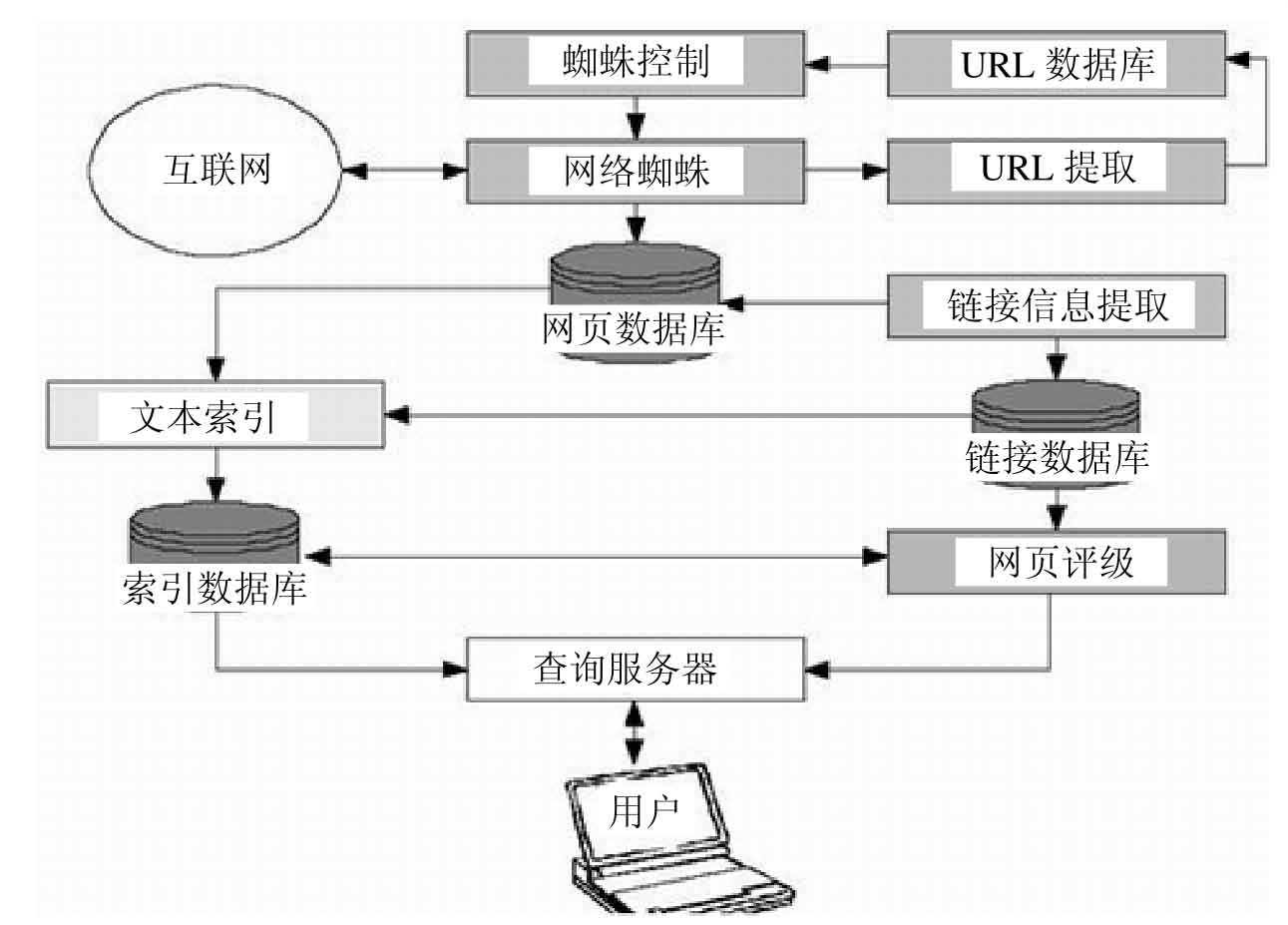
图1-8 搜索引擎的系统架构
然而,对中国大众而言最重要的信息搜索工具莫过于使用中文的搜索引擎,用自己的母语来搜索、分析和显示也是最方便和易用的。“众里寻她千百度”,不是吗?“百度”,这个搜索引擎的名称就在中国的大地上响起,把中文搜索引擎的潮流推向了高潮。世界上曾经对中国互联网络的兴起进行了评述,他们认为,当这个占世界人口四分之一的大国的家庭进入网络世界后,信息的搜索、寻找和应用将会是一个巨大的商机。而要让中国人方便地使用互联网并迅速地查找信息,中文搜索和中外文互译就成为未来最重要的搜索方式,百度正是适应和抓住了这个机会。
搜索引擎在中国已经成为互联网的第二大应用,仅次于电子邮件,但在不久的将来,搜索引擎将成为中文网民最常使用的服务,中文搜索的信息流量将成为世界上最大的网络流量,互联网也将成为世界上最大的一个市场。随着对信息的依赖,人们更加依赖搜索工具(引擎)来寻找信息,因为网上的信息越来越多,而且还在爆炸性地增长。信息的海洋会将浏览网页的时间全部淹没掉,所以必须依赖于搜索引擎进行导航。而且,更多的中文信息内容将分类化、门户化,中文搜索引擎的索引量也将超过20亿。
读者会问,有这么多的搜索引擎,我应当用哪个呢?通常,人们会首先采用已知的主流搜索引擎,如Google,中文搜索引擎Baidu。如果用户要进行特殊的信息搜索,可以采用专业分类、领域分类、个性分类、行业分类等搜索方式,把搜索的范围局限在一个较小的范围内,这样,搜索的速度、有效性会大大提高。这些主流搜索速度快、内容多、资源广。目前,著名的中文搜索引擎有:谷歌(http://www.google.com)、百度(http://www.baidu. com)、一搜(http://www.yisou.com)、中搜(http://www.zhongsou. com)、搜狐(http://www.sohu.com)、搜狗(http://www.sogou.com)、雅虎(http://www.yahoo.com)、QQ搜索(http://search.qq.com)等。而英文搜索引擎则成百上千了。
当然,人们要寻找到自己所需要的信息有一个心理的承受力,如果在计算机上键入一个搜索的关键字,半天都得不到回应,或者搜索出的信息成千上万,却与要找的信息相差太远,人们会对搜索引擎持怀疑态度。因此,搜索的基本问题仍然是准、全、新和快。“准”是第一个要保证的,必须利用先进的搜索算法,使搜索的方向、领域、范围、比对关系、特征属性等尽可能地接近用户给出的关键词或者指定内容,使找到的信息对用户有用。“全”是考虑怎么样来提高搜索引擎中索引的大小,尽可能全面地收集到各个网站或者数据库中的内容。“新”则是搜索到的信息应当是最新的,或者最好是按照时间关联排列的信息,并给出日期或时间参考的搜索结果。而“快”既是用户期望的,也是搜索引擎开发者期望的,速度慢的搜索是很难被接受的,也很快会被淘汰。当然,搜索引擎还要同时考虑稳定性、工具性、本地文化性等问题。人们有可能在不觉察的情况下使用搜索引擎服务,以自己熟悉的语言和方式进行搜索,使用操作也更加简单、方便,易用。
4.让我们搜索未来
目前的搜索引擎对用户提供的是搜索到的网站和相关信息,但用户还必须点击含有该信息的网站再去看这些信息,为了解决用户的“二次”甚至“三次”点击现象,未来的搜索引擎会发生一个很大的转变。一个是搜索引擎会成为一种“答案引擎”,也就是说,我要找的东西经过搜索引擎得到的就是相关的答案,而不是中间的结果,或者是相关的“链接”,也不会是当找着了一个信息再点一下看原来的信息,而是直接获得答案、获得信息、获得知识。另一个是“无处不在的搜索”,不管用户在任何地方,只要需要寻找和搜索信息时都可以利用身边的任何数码设备:手机、PDA、智能移动终端、笔记本电脑、UMPC等进入搜索引擎,通过有线或者无线的方式进行信息搜索、查寻。基于领域和类型的内容也将会在搜索引擎里提供,如音乐、图片、产品、本地搜索等,还会扩展到旅游、人物、旅行、购物等等。此外,配合搜索还会提供其他丰富的功能,例如:字典、辞典、翻译、阅读等。
未来的搜索引擎将会是一个什么样子呢?读者朋友不妨去访问一个称为“概念搜索”的网站(http://www.msdewey.com),里面有一个被称为概念型的搜索引擎叫做“Ms. Dewey”,这是微软公司在搜索领域的新奉献,用户的整个搜索过程将在一位“虚拟主持人”的带领下去找到你所想要的信息,整个搜索过程都是在这位美丽女士的引导下完成。通过主持人富有表情的动作和引导,启发用户输入查询请求。这项新的搜索引擎新颖而有趣,使网站具有更多的互动性,也减少了搜索者在等待中的烦恼。
我们已经知道,第一代搜索引擎采用的基本方法是由网页制作人自行建立网站名称、网站内容的文字摘要,并将其加入到搜索引擎的资料库中。搜索引擎根据用户键入的信息进行匹配、排序和显示。其最大的缺点是无法针对网页内容进行全文搜索,而且,它也必须由网页制作者自行键入供搜索的资料。
第二代搜索引擎采取的基本方法是使用一个程序在网络上获取资料,自动将得到的结果存入资料库中。其优点是不需要网站制作人单独键入供搜索的信息,理论上可以将任意网站的所有网页加入到搜索资料库中。但是它最大的缺点是搜索到的结果太多,实际上使用者仍然难以找到真正想要的资料,而资料数据库容量则不断膨胀,呈爆炸趋势。如何从庞大的资料库中精确地找到正确的资料,已经成为下一代搜索技术的竞争要点。
目前,搜索引擎已经从第二代向第三代进步,被称为“智能搜索”。这种未来搜索技术的目标是从数据库、网页、文档或音频和视频剪辑中自动提取信息,识别人名、地点、组织、日期、金额并且寻找其中的关联性,并且能够更加高效地理解用户所提供的关键词以反馈用户更加有效的结果。
智能搜索的基本方法是通过对搜索内容相关性的自动学习,提高搜索结果的可用度。其中的一个例子是基于内容的搜索,具有人工智能和智能判别模型的搜索。例如:问答搜索,即用问答替代关键词,例如:“电子科技大学历任校长是谁?”,得到的将是准确的、有价值的信息,而不是铺天盖地的冗余信息。这类搜索方式有人戏称为“占卜式”搜索。另一个是采用“模式识别”搜索方法,可找出在内容上最接近的数据提供给用户,避免传统“关键词检索”造成的漏检情况。用户常常很难用具体而明确的关键词来描述自己想找的东西,而搜索出来的结果大部分与这个关键词并没有太大关系。采用“模式识别”搜索方法,可找出在内容上最接近的数据。
帮助用户发现信息是未来搜索引擎的重要功能,人们已经逐渐认识到,传统的信息搜索只不过就是“搜索”(Search),而现代的信息搜索已经大大超过了“Search”的概念,拓展为“信息发现”(Discover)。这种基于“模式识别”算法的搜索引擎可以让用户找到一些事前他们不知道的信息,使搜索到的信息产生一种“聚类”效果,这才是人们所期望得到的有价值、有相关性的信息,也正是信息搜索“从搜索到发现”的革命性变革。例如,用户想要知道“本月最热门的IT新闻事件有哪些”,采用Discover类型引擎的“聚类”功能就可以得到近乎完美的答案。目前,人类研究的信息搜索技术有四个方向:关键字搜索、模式识别、语义分析、神经网络。除了关键词搜索比较成熟外,其他三项技术还处于待开发状态。
所以,我们可以说:“搜索”不是最终目的,“发现”也只是搜索过程中知识和智能的增强,而将抽取最需要的信息进行“信息集成”,通过“智能分析”搭建一种知识管理平台才是信息搜索的应用方向。
读者朋友,你们也可以想一想是否有更新颖的信息搜索的想法、搜索方式、搜索技术呢?我们期待你们的回答。
未来的搜索将知道用户要找什么样的信息,懂得用户要问的问题,并立即给出用户想要的答案。要实现这样的目标,信息搜索技术就将带有人工智能。最终的搜索引擎将懂得所有的事情,具备人工智能的搜索引擎将成为现实。因为,技术的改变要比预测的还要快!而且,新的搜索技术已经初见端倪。
让我们搜索未来!
让我们搜索未来的我们!
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










