



2.3.2 基于可视化技术的知识融合策略
基于可视化技术的知识融合是利用可视化技术表示知识融合过程中产生的知识并支持融合过程中的人机交互操作,借助人类强大的视觉处理能力增强知识融合过程中的人类认知能力,旨在更为有效地组合知识、系统化知识以产生新知识。人工智能技术的不断发展、知识挖掘的日益成熟以及知识数量的几何级增长,鉴于知识挖掘的自动化和智能化,知识融合的实现越来越依赖于知识挖掘的技术和方法,倾向于利用自动化手段完成知识融合。知识挖掘通常是从数据集中识别出有效的、新颖的、潜在有用的,以及最终可理解的模式的非平凡过程,其目的是将无序的信息变为有效的知识,知识挖掘是一个智能化、自动化的过程。知识挖掘产生的知识具有更高的结构化程度,而可视化技术得以应用的关键是为其提供易于映射为视图的数据结构。知识挖掘是一个不断反复的过程,中间会产生大量数据,同时需要知识专家参与其中,可视化技术的应用便于数据观察和动态操作。因此,可视化技术与知识挖掘的结合,可以将挖掘算法、布局算法、交互接口各自优势得到充分发挥,以从知识库中挖掘出更多知识。
基于可视化技术的知识融合策略如图2-10所示,整个知识融合过程是知识挖掘与知识可视化表示相互支撑融合出新知识的过程,知识专家利用基于可视化技术的知识融合平台参与到知识挖掘过程之中、对挖掘结果进行评价、并将产生的新知识存入知识库。
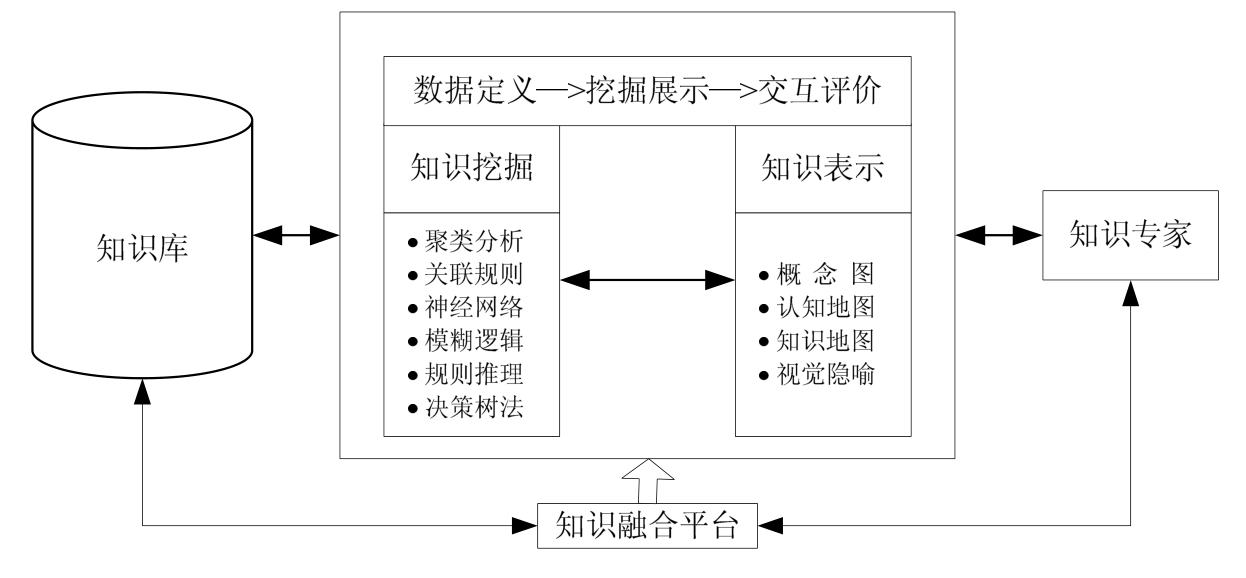
图2-10 基于可视化技术的知识融合策略
基于可视化技术的知识融合的实现策略分为三个步骤:首先,选择知识库中一定的知识集合作为知识挖掘的来源;其次,利用知识挖掘的相应算法以及可视化技术进行知识挖掘;最后,知识专家对知识挖掘的结果进行评价,认为可行时结束挖掘过程并将产生的新知识存储到知识库当中,以便对其进行重复利用。因此,基于可视化技术的知识融合实现的关键是利用知识挖掘技术和可视化技术将知识组合化、系统化并产生新知识。需要注意的是,知识表示与知识挖掘之间是双向的动态关系,可视化技术不仅提供一定的布局算法将知识挖掘产生的数据、知识展示出来让知识专家更为轻松地理解和把握产生的知识,还提供一定的交互机制来影响知识挖掘的过程,使得知识专家可以参与到知识挖掘的过程当中。因此,可视化技术对知识挖掘的作用不仅体现在知识挖掘的结果上,而且体现在知识挖掘的整个过程当中,即可视化技术的应用从整个过程中提高挖掘的效果和水平。由此可见,知识挖掘的过程在很大程度上制约知识融合的过程,而可视化技术则支撑知识挖掘的全过程。
知识挖掘的一般过程是:①定义目标,对问题进行深入分析确定可能的解决途径和结果评测方法;②创建目标数据集,根据定义的目标收集有关的数据,在一个或多个知识专家及知识发现工具的帮助下选择一组要进行分析的初始数据;③数据预处理,对提取出的数据进行合法性检查并清理含有错误的数据,利用可获取的资源处理噪声数据,并确定缺少数据的处理办法;④数据工程,在数据挖掘过程中,探索问题的不同解决方案时,数据引擎需要多次形成针对某任务的数据库;⑤算法选取,根据数据及所要解决的问题选择合适的数据挖掘算法,并确定如何在数据上使用相应算法;⑥数据挖掘,通过应用一个或多个数据挖掘算法对处理后的数据进行模式提取;⑦结果解释与评估,对学习结果的评估取决于所要解决的问题,由知识专家对发现模式的新颖性和有效性进行评估,并决定是否用新的属性或实例重复前面的步骤;⑧优化,对结果的优化可能需要对处理过程的某些阶段进行优化,此过程中,知识专家的参与非常重要;⑨结果的使用,知识被具体化并在实际工作中应用(Fayyad,1996)。
2.3.2.1 聚类分析
聚类分析的数据对象没有已知的类标记,根据所处理数据的属性,按照“最大化类内的相似性、最小化类间的相似性”原则进行分组,分类约束,每组中的对象拥有唯一的类标志,同类对象间有较大的相似性,不同类对象间有较大的差异,聚类分析是无监督的学习过程。
在数据空间A中,数据X由N个数据点(或数据对象)组成,数据点xi=(xi1,xi2,…,xid),xi的每个属性(或特征、维度)xij可以是数值型,也可以是枚举型的。数据集X相当于一个N×D的矩阵,聚类分析的目的就是把数据集X划分为k个分割Cm(m=1,2,…,k),也可能有些对象不属于任何一个分割,这些称为噪声Cn。所有这些分割与噪声的并集就是数据X,并且这些分割之间没有分割。可以用以下公式表示:
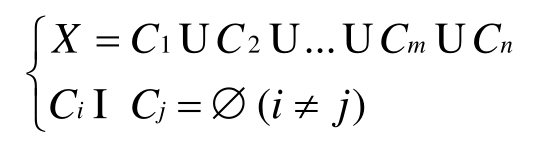
聚类算法依赖于数据点之间的距离或相似性的定义,Minkowski模型给出了距离的一般定义法(Chen.C,2004):
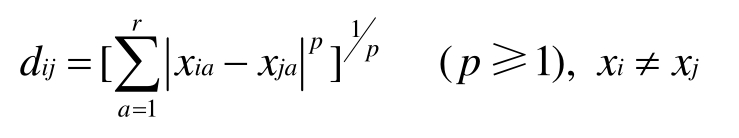
这里数据点用两个向量xi和xj表示,从该模型中可以导出多种距离的定义,如p=2时是欧几里得距离,p=∞时是Dominance距离。常见的聚类算法有K-均值聚类、层次聚类以及基于神经网络的聚类等。层次聚类是合并小的聚类为大的聚类,不必事先说明聚类的数量。K-均值聚类算法能够处理大的数据集,但聚类数量需要事先说明。
(1)K-均值聚类
K-均值聚类是基于某种准则将数据划分为K个簇。典型的准则有K-平均距离算法以及K-中心点算法。
K-平均距离算法的处理过程:首先,随机选择k个对象作为初始的k个簇的质心;然后,将其余对象根据其与各个簇质心的距离分配到最近的簇;再重新计算每个簇的质心;这个过程不断重复,直到目标函数最小化。通常采用的目标函数形式为平均误差准则函数:

其中,p表示第i个簇中的所有非质心点对象,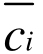 表示簇ci的质心,即平均值。E表示数据集中所有对象的平均误差之和。这个目标函数使生成的簇尽可能地紧凑和独立。
表示簇ci的质心,即平均值。E表示数据集中所有对象的平均误差之和。这个目标函数使生成的簇尽可能地紧凑和独立。
K-中心点算法不是将平均值作为判断聚类质量的准则,而是选用簇中位置最中心的对象,其基本过程是:首先,随机选择k个对象作为中心点;接着,将剩下来的对象分配给与其距离最近的中心点所在的簇;反复用非中心点对象代替中心点对象,重新划分从而改进聚类质量。聚类的效果用所有对象与其中心对象的相异度来判断:

其中,p表示第i个簇中的所有非中心点对象,ci是相应簇的中心对象。当中心点对象发生改变时,该簇内的其他对象也会发生隶属关系的变化,因此中心对象变化时,需要将所有的非中心点对象重新分配到与其距离最近的中心点对象。
(2)基于神经网络的聚类
神经网络方法中用于聚类的方法主要是自组织地图(Self-organizing Map,SOM),它是由芬兰教授Kohonen首先提出,与其他聚类方法相比,SOM网络的优点在于可以实现实时学习,网络具有自稳定性,不需要外界给出评价函数,能够识别向量空间中最有意义的特征,抗噪音能力强(Kohonen.T.,1982)。
SOM属于无监督的神经网络算法,模仿了人脑神经的相关属性。人脑由大量的神经元组成,但彼此作用不同,处于不同部位的神经元有着不同的分工。对于不同的输入,只有对应的区域会形成最敏感的刺激效果。部位的区域分工不同,各自对输入模式的不同特征敏感。Kohonen解释该现象为神经网络邻近的各个神经元通过侧向交互作用彼此相互竞争,自适应地发展成检测不同信息的特殊监测器,这就是自组织特征映射的含义。通过构造一个输出区域模拟人的大脑区域,当有一个输入时,将它与每一个输出子区域相互作用,结果最强的子区域指出该输入属于该类。
SOM的工作原理是将任意维输入模式在输出层映射成一维取二维离散图形,并保持其拓扑结构不变。此外,网络通过对输入模式的反复学习,可以使权重向量空间与输入模式的概率分布趋于一致,即权重向量空间能反映输入模式的统计特征。这种自组织聚类过程是系统自主、无监督的条件下完成的。SOM网络的竞争层各神经元竞争对输入模式的响应机会,最后仅一个神经元成为竞争的胜者,并对那些获胜神经元有关的各权重朝着更有利于它竞争的方向调整,即以获胜神经元为中心,对近邻的神经元表现出正向刺激侧反馈。这样,应用侧反馈原理,在每个获胜神经元附近形成一个“聚类区”,学习的结果总是使聚类区内各神经元的权重向量保持与输入向量逼近的趋势,从而使具有相近特性的输入向量聚集在一起。
SOM的一般算法如下:
Step1:初始化网络连接权值Yi(可取一个较小的随机值),一般要求所有L个链接值初始向量应各不相同。如果相同的话,在Step3中将不能获得得胜者,从而使学习进行不下去。初始化初始邻域Vk,邻域是指以获胜神经元k为中心,包含若干神经元的区域范围。可设置一个较大的初始邻域;初始化学习率参数η的初始值。
Step2:将一个给定的输入向量Xj加载到网络上。
Step3:计算输入向量Xj与每一个权值向量Yi的最小距离(如欧氏距离),并选择得胜神经元k。得胜的度量根据具体应用定义为不同的形式,如反映相似程度高的距离最小者。
k=min arg{d(Yi,Xj)}
Step4:更新所选结点及其邻域结点的连接权值。
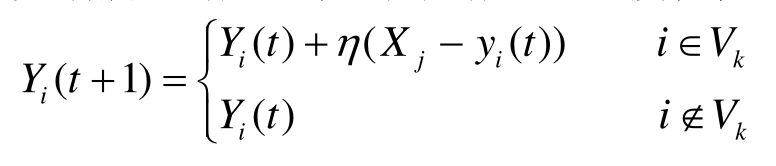
Step5:重复步骤Step2,直到满足终止准则。
其中,t为学习迭代次数,η为学习率参数,Vk从围绕得胜者神经元的邻域,Step 4中是学习迭代次数t的函数。
2.3.2.2 关联规则
关联规则是反映<属性-值>对频繁地在给定的数据集中一起出现的条件,广泛应用于事务数据的分析。目前已经有大量的改进关联规则算法,且关联对象规则发现的对象已经扩展到关系数据库、空间数据库和多媒体数据库。规则的支持度(Support)和置信度(Confidence)是关联规则的兴趣度的客观度量。
设 是二进制文字的集合,其中的元素称为项(Item)。记D为交易(Transaction)T的集合,这里交易T是项的集合,并且T⊆I。对应每一个交易有唯一的标志,如交易号,记作TID。设X是一个I中项的集合,如果X⊆T,那么称交易T包含X。
是二进制文字的集合,其中的元素称为项(Item)。记D为交易(Transaction)T的集合,这里交易T是项的集合,并且T⊆I。对应每一个交易有唯一的标志,如交易号,记作TID。设X是一个I中项的集合,如果X⊆T,那么称交易T包含X。
关联规则定义:一个关联规则是形如X⇒Y的蕴涵式,这里X⊆I,Y⊆I,并且X∩Y=φ。
支持度定义:规则X⇒Y在交易数据库D中的支持度是交易集中包含X和Y的交易数与所有交易数之比,记为support(X⇒Y),即:
support(X⇒Y)=|T:X∪Y⊆T,T∈D|/|D|
置信度定义:规则X⇒Y在交易集中的置信度是指包含X和Y的交易数与包含X的交易数之比,记为confidence(X⇒Y),即:
confidence(X⇒Y)=|T:X∪Y⊆T,T∈D|/|T:X⊆T,T∈D|
频繁项目集(Frequent Itemset)定义:所有支持度大于用户给定的最小支持度的项集。
强关联规则定义:同时满足用户给定的最小支持度和最小置信度的关联规则。
关联规则挖掘的两个步骤:①找出所有的频繁项目集;②由频繁项集产生强关联规则。典型的算法有Apriori算法,为生成所有频繁项集Apriori算法使用了递归方法(Agrawal.R.,1993),其核心思想是:

首先扫描一次数据库,产生频繁1项集L1;然后进行循环,在第k次循环中,首先由频繁k-1项集进行自连接和剪枝产生候选频繁k项集Ck,然后使用Hash函数把Ck存储到一棵树上,扫描数据库,对每一个交易T使用同样的Hash函数,计算出该交易T内包含哪些候选频繁k项集,并对这些候选频繁k项集的支持数加1,如果某个候选频繁k项集的支持数大于或等于最小支持数,则该候选频繁k项集为频繁k项集;该循环直到不再产生候选频繁k项集结束。
2.3.2.3 概念图挖掘
概念图作为一种有效的知识表示和组织工具,可以用以导航知识。用以知识导航的概念图一般是由知识专家构建的,但是,概念图也可以利用人工智能、信息检索、文本挖掘等领域的技术自动构建,即从数据库、知识库中挖掘出概念图来。Chen(2006)等认为概念图的自动构建关键在于概念自动抽取和概念之间关系的确定,需要文本挖掘技术作支撑,他们利用文本挖掘技术从文献中自动生成了电子学习领域的概念图,具体的挖掘流程是:①文献信息检索,从期刊和会议论文集中检索相关文献作为数据源;②概念项抽取,将检索出的文献中的每个关键词作为一个概念项;③关键词标引,根据计算要求对关键词进行标引;④概念间关联度计算;⑤概念图绘制。挖掘流程如图2-11所示。

图2-11 概念图挖掘流程
概念项的抽取以及概念间关联度的计算需要一定的理论假设。
概念项抽取基于以下假设:文献中的每个关键词均代表一个概念。但是,每个作者选用的关键词常常不一致,即针对同一概念使用不同的关键词。因此,需要进行关键词清洗、缩写词映射、词根还原等处理。
概念间关联度的确定根据以下假设:①在同一篇文献出现的两个关键词,关联性强;②两个关键词在同一个句子中出现的频率越高,关联性越强;③在同一句子中,两个关键词之间的距离越短(中间间隔的字符越少),关联性越强。
基于以上假设,计算两个关键词之间的关联度公式如下:

RS(Ki,Kj)表示关键词i和j的关联度,nij表示关键词i和j在同一个句子里出现的频率。 是两个关键词之间的平均距离,即两个关键词距离之和与关键词在同一句子中出现的总次数的比值,计算公式如下:
是两个关键词之间的平均距离,即两个关键词距离之和与关键词在同一句子中出现的总次数的比值,计算公式如下:

上述方法利用文本挖掘技术,自动挖掘出电子学习领域的概念图。该方法利用关键词作为概念图中概念的来源,同时给出了基于共现分析原理的关键词之间关联度的计算方法。但对概念之间的层次关系挖掘不足。
吴江宁(2007)等则提出了基于主题地图的多层次文献组织模型(TMDOM),通过从文献内容中概化出主题并定义主题之间的关联,将领域内主要的概念及其关联以合理的层次结构体现出来,以实现对文献资源的组织。其实质也是从文献资源中自动挖掘出概念图。她们提出了利用“多阶段层次聚类”方法进行主题概念的概化。在传统的凝聚型层次聚类中,将原始文本聚为几个类别后即停止,但如果所得类别的概念覆盖范围比较小,则应继续聚类;或者,如果所得类别的覆盖范围比较大,则应修改聚类终止条件。在多阶段层次聚类中,传统凝聚型层次聚类只是其中的一个阶段,整个聚类过程是传统凝聚型层次聚类的不断重复,后一次聚类在前一次聚类结果的基础上进行。这样,可以得到不同层次上的类别及其之间的聚合关系。通过多阶段层次聚类,可以确定模型的结构,接着建立主题地图。主题地图建立主要是确定主题及其之间的关联,包括确定主题、同层主题之间关联、相邻两层主题之间的关联等步骤。其中,第1层主题是文献的标题,第2层到第n层的主题是由人工确定的。因此,该方法并不是完全自动化的,是需要人工参与的。但是,该方法使用了文本聚类的思想,通过对文献的多次聚类,寻找概念及概念之间的关联关系,即概念之间关系确定由文献资源决定,而且挖掘了概念之间的多级层次关系。
Sue(2004)等提出了从学习者已有的测试记录中自动挖掘概念图的方法,即两阶段概念图构建法(Two-Phase Concept Map Construction)。阶段1预处理测试记录,利用模糊集理论,将学习者的数值测试记录转换为符号型,利用教育理论中的非参照项目分析(Item Analysis for Norm-Referencing)对其进行精化处理,并利用数据挖掘技术寻找级模糊关联规则(Grade Fuzzy Association Rules)。在阶段2中,利用多种原则类型进一步分析挖掘得到的规则,并提出了一个算法自动构建概念图。该方法基于模糊集理论,使用了比较复杂的算法分阶段完成了概念图的自动构建。其中,也需要教育专家的参与,而且是基于学习者以往的测试记录,而不是一般的文献资源,因此适应性不强。
2.3.2.4 认知地图挖掘
认知地图具有强大的知识表示能力,它一般是通过问卷调查、头脑风暴、样本学习等方法借助专家经验进行构建,但也有学者提出基于客观数据资源的自动构建方法。例如,陈庄(2007)等提出了基于数据资源挖掘认知地图的方法,该方法采用了神经网络思想,具体挖掘流程如图2-12所示。其中,数据库初始化的功能是整理不规范、不标准甚至零乱的客观数据资源,从中提炼出关键的属性变量(即字段变量,图中为m个节点N1,N2,…,Nm)及其规范化值(即数据库记录值);神经元激活函数的功能是模拟人的认知过程,变量xj,yj分别为神经元Nj的输入、输出,dj为实际输出(即数据库记录值),ej为实际输出与理论输出的误差,该误差与其他神经元经认知后产生的误差一并构成优化模型的输入,目标就是通过“学习算法”调整权重系数wij(i,j=1,2,…,m,i≠j),使“优化模型”的目标函数达到最小。

图2-12 认知地图挖掘流程
该方法假设每个节点Nj均受其他节点Ni(i≠j)的影响(即Ni与Nj产生因果关系),其影响程度为wij。若某节点Ni对Nj不产生影响,则wij=0;而节点与其自身也不产生因果关系,即wii=0。m个节点的组成的认知地图可以视为一层神经元网络图,如图2-13所示,m个节点则为m个神经元。
图2-13 认知地图的一层神经元网络表示
根据一层神经元网络形式(即挖掘得到的认知地图)可以转化为以下邻接矩阵W:

根据邻接矩阵W,可以将其转化为关联矩阵V:

由关联矩阵V即可构建认知地图,值为1时表示正相关,为0时表示不相关,为−1时表示负相关。

免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











