



7.3 《中图法》知识库的构建技术
《中图法》知识库的构建面临以下几个难题:
(1)异构数据的整合。知识库原始数据主要来源于四类数据:①原始类表数据,如《中图法》类目索引、《中分表》中分类号-主题词对应表;②规范标引数据,即用《中图法》和《汉表》规范标引的书目数据,如上海图书馆的《全国报刊索引数据库》、北京图书馆、上海图书馆等的中文图书MARC数据;③自由标引数据,即包含《中图法》类号和散标自由词的书目数据,如重庆维普的《中文科技期刊数据库》;④题名库数据,从文献数据库的标引数据中取出题名和分类号构建而成。这四种数据描述的格式不同,有的是MARC,有的是文本,有的是数据表,词串之间的间隔符有空格、短横、冒号等还有全半角之分。如何对这些数据进行整合,构建原始库,是首先要解决的问题。
(2)一对多、多对多关系的筛选。原始数据中分类号与主题词或词串之间包含一对多,多对一和多对多的关系,而本系统中必须设法为每一个词串确定一个唯一的分类号。
(3)标引词串与知识库中的词串的相符性比较。实际上二者完全匹配的几率是比较低的,所以本系统采用词汇相似度计算来实现概念标引、概念定类。如何从语义的角度来比较两个词或词串之间的相似度,而不是单纯从字面角度匹配,是我们通过《中图法》知识库实现主题规范和自动分类亟须解决的难题。
针对上述难题,《中图法》知识库在其编制和使用过程中采用以下几个关键技术[4][5]:
(1)采用计算语言学的方法完成词表的构建。知识库原始数据主要来源于上述四类数据,首先要对这四类数据进行手工采集合并、删错去重,构建出原始库。原始库中包括类号与类名词、类号与主题词、类号与关键词的对应,从中分别抽取语词以及类号与语词的对应来构建知识库中的词表和词典。在知识库中以分类号-关键词串对应表的构建最为关键,以计算语言学的方法来确定类号与词串之间的对应关系又是该对应表构造的关键技术。主要通过类目频次、词串频次、类号与词串共现频次的统计,采用数据挖掘中关联规则发现的两个参数——支持度和置信度来建立类号与词串的对应关系。
所谓支持度表示分类号和词串在整个原始库中同时出现的频度,即共现频次。共现频次越大表示越多的标引员认可该分类号和词串之间的概念对应,那么这样的标引结果就可以认为具有普遍的正确性。支持度计算公式如下:
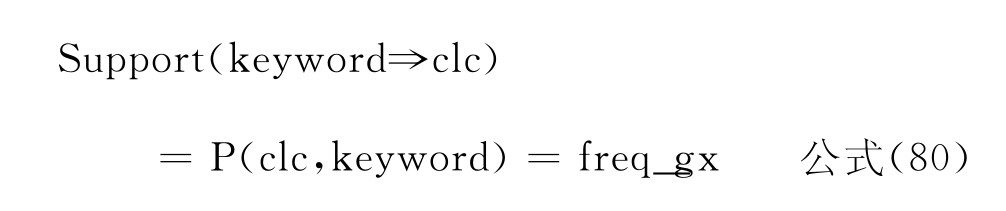
其中,P(clc,keyword)表示在原始库中分类号和词串同时出现在一条记录中的概率;可用分类号和词串的共现频次freq_gx表示;一般认为,支持度≥2表示该分类号与词串有概念上的对应关系,即有两人次以上认可这种对应关系。支持度越大表示这两者之间概念对应关系成立的可能性越大。置信度则表示在出现该分类号的前提下出现该词串的概率,计算公式如下:

![]()
其中,P(clc,keyword)表示在原始库中分类号和词串同时出现在一条记录中的频度;即分类号和词串的共现频次freq_gx;P(keyword)表示该词串在整个原始库中出现的概率;可用该词串在整个原始库中出现的频次freq_keyword表示。同时满足最小支持度阈值和最小置信度阈值的规则称为强规则。当某一分类号和词串之间的支持度和置信度分别超过设定的阈值,则认为两者之间有很强的关联,即概念上的对应关系,以此来建立类号与词串的概念对应关系。
(2)通过相关度度量解决分类号与词串的多对一和多对多关系。在原始库中分类号与词串之间是一对多、多对一、多对多的关系,为给每一个词串确定一个唯一的分类号,需要度量分类号与词串之间的相关度。测量分类号与词串相关性的方法有多种,如信息对数量度法(IM)、极大似然法(LogL)、Dice测度等。我们基本采用Dice测度来计算词串对应的最佳类号。

其中:Dice表示分类号与词串的并发概率,从而确定两者之间的关联度;P(clc)表示该分类号在整个原始库中出现的概率,可用其在原始库中出现的频次freq_clc表示;P(keyword)表示该词串在整个原始库中出现的概率;可用其在原始库中出现的频次freq_keyword表示;P(clc,keyword)表示该分类号和词串在整个原始库同时出现的概率,可用其共现频次freq_gx表示。
在一个词串对应多个分类号的情况下,Dice值最大的记录表示该记录对应的分类号是该词串对应的最佳类号。
(3)构建义类词典进行词相似度的计算。主题标引从关键词转向正式主题词、自动分类中词串相似度匹配以及概念检索都离不开同义词的识别,因此需要在《同义词词林》[6]的基础上构造一个义类词典,通过语义编码从概念上识别同义词,而不是简单地通过字面相似度来识别同义词,是提高系统性能的关键之一。
《同义词词林》是一部按词汇语义分类的汉语词典,共14个大类、94个中类、1 428个小类,以树型结构来表示词的语义关系。以它为基础,经过适当调整和编码,就可以构造出一部义类词典。《同义词词林》以单元词为主,其中大多可以作为构成复合词的词素。用它构建的义类词典一方面可以直接识别以单元词形式出现的同义词,另一方面以其作为语义工具,可以挖掘出以复合词形式出现的同义词和同义词组。
构造义类词典时,首先将词汇的字面形式按其构成词素分解转换成语义代码,以《同义词词林》分类体系作为语义编码体系。
[语义编码]=>(大类)(中类)(小类)(小组),其中:

例如:“商业”的语义编码为[Di180203],其对应的大类、中类、小类、小组的编号分别为:(D)、(Di)、(Di1802)、(Di180203),其中“D”表示大类“抽象事物”,“Di”表示中类“社会政法”,“Di1802”表示小类Di18“事业行业工程”下的词群“行业”,“Di180203”则表示小组“商业”。
有了义类词典,就可以对待识别的语词进行语义分析,把所有的词素归入相应的语义体系的结点之中,然后可以计算两个语词之间的语义距离,从而识别同义词和准同义词,实现从关键词向主题词的转换,并计算两个词串的相似度实现分类算法。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











