



6.4.3 知识库规模的确定
本书随机选取中文文本自动标引和分类用测试网页(包括中国经济信息网、中国资讯行、华泰证券网、中国财经网等网站的网页)共200篇,对知识库进行实际标引(测试中本书设定的语义相似度阈值为0.5),测试知识库的漏标率和标引正确率,以确定合理的知识库容量。
在测试中引入如下两个衡量标准:

其中:分类正确的标准是分类结果与人工分类结果进行比较,类号达到三级或三级以上相符的情况,都归入分类正确的记录中去。
自动分类中,方案一是将提取出的概念词串与分类知识库中每条记录中的主题词字段进行语义相似度计算。关于语义相似度的计算,详见本书第7章。
方案二是先将概念词串与分类知识库中每条记录中的主题词字段进行字面匹配,如果在知识库匹配不到对应的记录,则将概念词串与分类知识库中每条记录中的主题词字段进行语义相似度的匹配。例如对编号为cib_12的文本进行自动分类时,采用方案二的计算过程是:将提取的概念词串(此例提取结果为:“农民—人均—现金收入—出售—百分点—农产品”)与分类知识库中每条记录中的主题词字段进行字面匹配,没有匹配到对应的主题词串,接着将概念词串与分类知识库中每条记录中的主题词字段进行语义相似度的匹配,找到了最佳匹配词串为“农民—人均收入—收入分配”,并赋予文本对应的分类号“F323.8”,这样便完成了该文本的自动分类。
根据实际的测试结果(见表6-9),考虑到分类的准确性、覆盖性和运行效率,本书采用简单字面匹配结合语义相似度方法,利用强规则(min_sup=1/N,min_conf=0),相关度(取最大Dice值)过滤所得到规模为8万和50万的分类知识库作为文本自动标引和分类系统的分类知识库。其中选用50万容量的分类知识库主要是为了降低漏检率,在系统运行中,先进行8万容量知识库的匹配,如找不到最佳分类号,则接着运行50万容量的知识库。
表6-9 分类知识库实际标引测试对照表
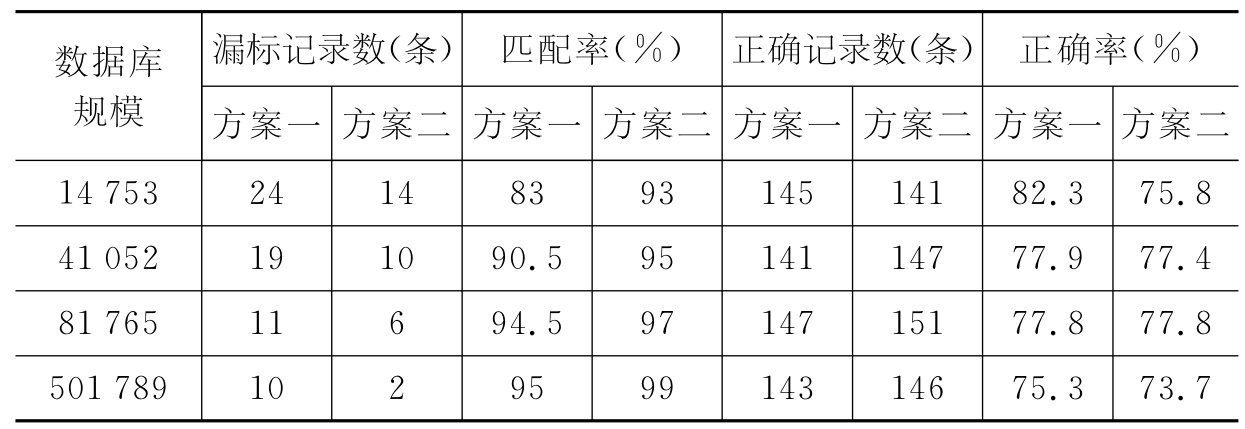
注:方案一是指语义相似度匹配方法,方案二是指简单字面匹配结合语义相似度匹配的方法。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










