



4.1 并行文献数据库的构建
以经济学科为例,大型中文文献数据库“中文社科报刊篇名数据库”、“部分图书馆制作的MARMARC”、“经济学科论文数据库”、“中文科技期刊数据库”、“中文图书检索系统(MARC)”等都收集经济学相关文献资料。这些文献数据库主要采用分类标引和主题标引,但是标引形式存在一定的差异(见表4-1)。
表4-1 我国包含经济信息的大型文献数据库
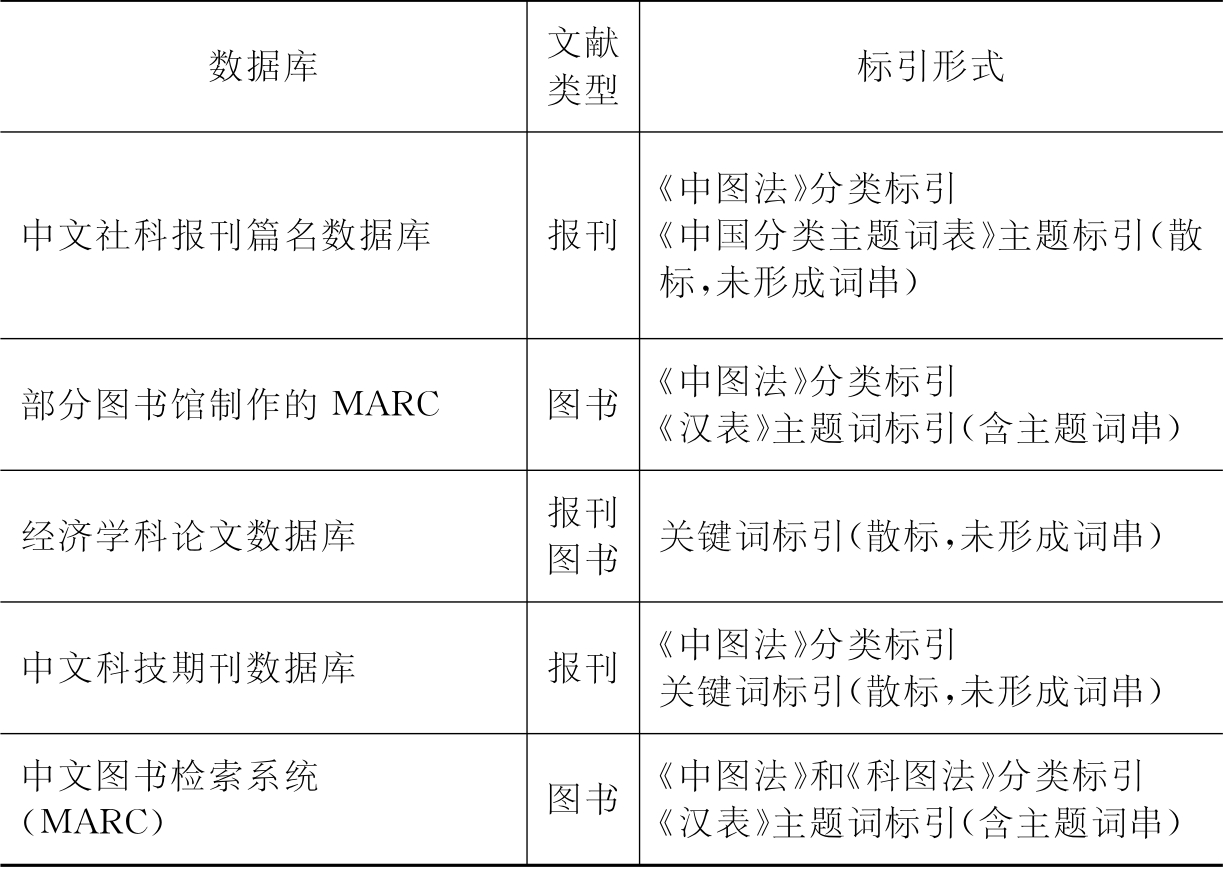
从主题标引的形式来看,上述文献数据库分为两种:一种是主题词串形式标引;一种是散标形式,未形成主题词串,也就是采用单个主题词标引。一般来说,单个主题词很难准确、完整地表达一个文献主题。在大多数情况下,只有采用主题词串形式才能满足标引和检索的需求。目前,我国只有中文图书检索系统(MARC)和部分图书馆制作的MARC数据库同时进行分类标引和含主题词串的主题标引。从理论上讲,这些标引数据均可以直接用于主题标引和分类标引的对应转换。但事实上难以奏效,主要是因为这些数据含有大量的无效数据,从而难以有效地指导主题标引和分类标引的对应转换。
从标引对象来看,中文MARC数据的标引对象主要是图书,光盘文献数据库的标引对象主要是报刊,后者的主题比书目文献要细化得多。因此,根据MARC标引数据生成的分类号—主题词对照数据库不能适应报刊文献的标引。一个能够有效地适应机器标引和检索的分类号—主题词转换系统,必须同时满足图书文献和报刊文献的标引转换和检索策略转换。而我国的报刊文献数据库往往只有分类标引、散标形式的关键词标引或主题词标引。根据这些数据库直接生成的分类号—主题词对照数据库难以用于报刊文献的分类标引与主题标引数据的转换。
以《中文社科报刊篇名数据库》、《国家新书目》(MARC)和《中文科技期刊数据库》三种较有代表性的大型报刊文献数据库为实验样本,生成分类号—主题词(串)对照数据库,以建立分类表与叙词表转换系统。实验样本包括:
(1)《中文社科报刊篇名数据库》(简称“上海库”):由上海图书馆文达信息公司《全国报刊索引》编辑部负责研制和编辑。1993—1997年数据库共收录全国哲学社会科学期刊4 500种,报纸170余种,基本上覆盖了全国邮发和非邮发的报刊。内容涉及马列主义、毛泽东思想、哲学、社会科学和人文科学等各个学科,数据量超过90万条。使用《中图法》进行分类标引,参照《中国分类主题词表》进行散标形式的主题标引。
(2)《中文图书检索系统》(MARC):由北京图书馆等单位制作,收录了1975—1997年的图书馆文献,数据量超过49万条,包括社会科学和自然科学。采用《中图法》和《科图法》进行分类标引,采用《汉表》进行主题词串形式的主题标引。
(3)《中文科技期刊数据库》(简称“中刊库”):由国家科委西南信息中心编制。1989年开始创建,收录期刊约6 000余种,数据达200多万条,其中经济类数据达20万条。中刊库已成为我国一个大型的综合性文献检索系统。使用《中图法》进行分类标引,采用散标形式的关键词进行主题标引。
从两个数据库中下载F83和F82金融银行类的所有记录(共52 323条记录,其中上海库37 654条,中刊库14 669条),抽取出《中图法》分类号、主题词或者关键词字段,生成源数据库,部分记录参见附录一。中刊库采用关键词标引,故将所有主题词和关键词统称为标引词。其记录格式如表4-2所示。
表4-2 中刊库标引样例

*注:中刊库标引词间隔符号为空格。
进行主题标引和关键词标引时,通常按一定的次序来组织标引词,形成标引款目。但一个分类号往往只与其中的一个标引词或几个标引词的组合(即标引词串)相对应。例如:
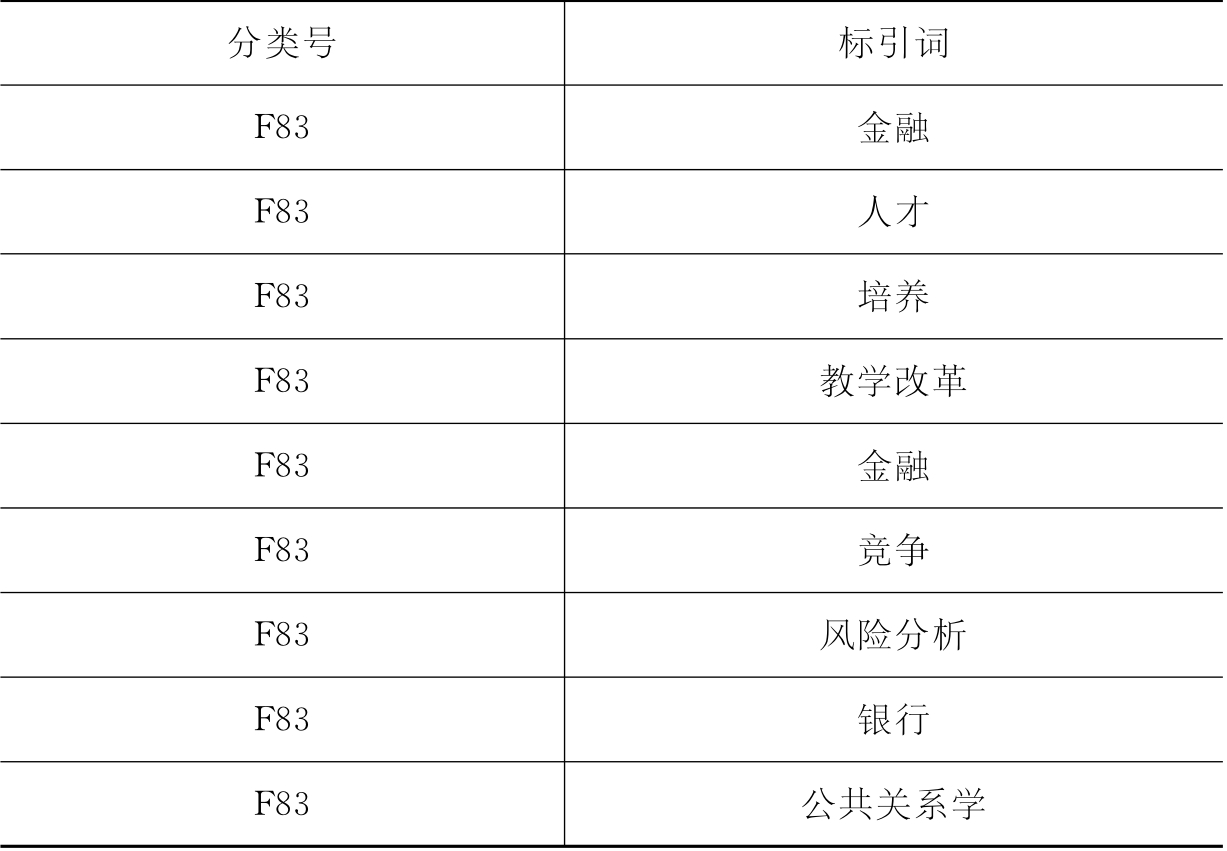
标引款目 F83 金融;人才;培养;教学改革
标引款目中,只有“金融”、“人才”和“培养”三个标引词组合与F83类是直接对应的。基于上述假设,按照下面四种模式将每条记录的分类号与该条记录的标引词进行匹配,生成四个样本库:
(1)样本库1(YBK1):分类号与每个标引词一一匹配(181 023条记录)。YBK1记录格式见表4-3。
表4-3 样本库1的数据样例
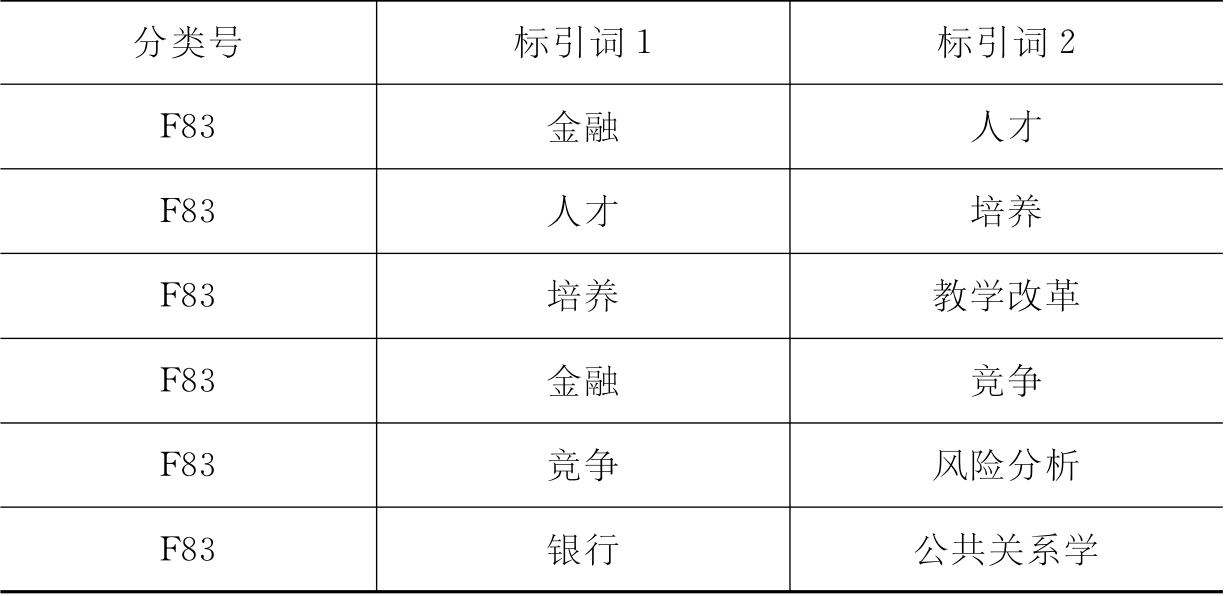
(2)样本库2(YBK2):分类号与所有两个相邻标引词组成的词串进行匹配(129 369条记录)。YBK2记录格式见表4-4。
表4-4 样本库2的数据样例
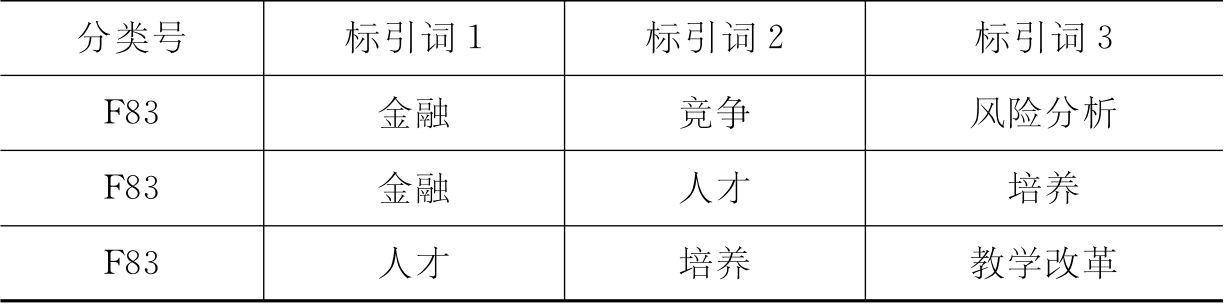
(3)样本库3(YBK3):分类号与所有三个相邻标引词组成的词串进行匹配(77 699条记录)。YBK3记录格式见表4-5。
表4-5 样本库3的数据样例
(4)样本库4(YBK4):分类号与所有四个相邻标引词组成的词串进行匹配(35 084条记录)。YBK4记录格式见表4-6。
表4-6 样本库4的数据样例

四个样本库具有以下特点:
●重复记录多;
●每条记录的标引词字段须看成一个标引词串;
●每个分类号对应着多个不同标引词(串);
●每个标引词(串)对应着多个不同的分类号。
以样本数据库为数据源建立分类号—主题词对照数据库,需要解决两个问题:一是为每个不同的标引词(串)确定一个正确的分类号;二是从四个样本库中筛选出与F83学科各个类目有关的标引词(串)。由于样本库中分类号与标引词(串)是多对多的关系,要为每个不同标引词(串)确定一个分类号,从统计学的角度看,可以依据二者的关联程度进行判断。相关程度越大,二者同时出现的概率就越高,其正确率也最高。对同一标引词(串)来说,它可能对应着多个分类号,但可以通过计算它与各个分类号的相关程度,选择相关程度最大的分类号作为该标引词(串)的正确分类号(假设前提是每个标引词或标引词串只能归属某一个类号)。
统计学上有多种方法用以测定两个事件的关联程度,最常用的有两种方法:信息对数量度(IM)和最大似然估计法(LogL)。法国的B.Dialle专家曾在自动翻译系统中用IM和LogL方法测定文本中两个相邻词汇的相关程度,并比较了两种方法的应用效果[1]。法国的V.D.Goetz曾用LogL方法删除LCSH与DDC对照数据库中的错误记录[2][3]。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









