



4.1 叙词表自动构建理论依据
(1)词汇控制理论
控制是情报检索语言的灵魂。控制是一种联系与调节,使事物之间、系统之间、部门之间相互作用、相互制约,克服随机因素,增进协调,追求和谐,从而达到预期的目的[1]。在叙词表的编制过程集中体现在词汇选择、同义词控制、词形控制及词间关系控制等方面。
对词汇选择的控制,指为了表达明确并保障检索效率,叙词表对选词原则、词汇类型、收词范围都有明确的规定。同义词控制指在表达相同概念的不同词汇和词组中,根据需要规定其中一个作为标引用词,即叙词,其余作为非叙词即入口词,使得一个概念对应一个叙词,从而把其他同义词和准同义词统一在该叙词之下,以便用户检索时,检索系统能够提取出包含此概念的所有相关文献。词形控制主要指对同形异义词和词义含糊的词汇的区分,以明确词义,避免误检。在叙词表中通常采用加限定词或注释的方法来说明词义。词间关系控制主要指对等同关系、属分关系和相关关系的词汇进行控制,便于扩缩检。
在以网络搜索引擎为代表的自然语言检索横行天下的今天,有人认为高度控制的情报检索语言将是明日黄花。事实上,基于字面匹配原理的自然语言检索已不可避免地暴露出其固有顽疾——它虽然具有较高的检全率,但检准率却很低下,漏检和误检现象普遍。而随着信息量不断激增,未来网络用户更希望能够得到高质量的准确信息,对检准率的要求会越来越高。利用规范化控制的叙词表是保证检准率的重要手段之一。第二章中“叙词表在网络环境中的应用现状和趋势”小节所列各项数据就是很好的证明。
但是,我们不得不承认对词汇的高度控制在一定程度上影响了叙词表的易用性,限制了其在网络检索中的应用。为了适应新的信息环境,叙词表的控制机制也需要作出适当调整,提高易用性和灵活度。网络检索的发展趋势不是完全不受控制的自然语言检索,而是主题语言和自然语言的一体化,能够取长补短,从而取得最好的检索效果。
(2)概念空间理论
概念及概念之间的语义关联表达了人类关于某一特定领域的知识框架系统,为词表自动构建提供了理论依据。
人类知识关于客观事物与抽象概念以及它们的关联纷繁复杂,不在同一个层面上,反映到主题词所代表的概念则表现为复杂的层次关系和网状关系。这些词所代表的概念连同词汇之间的关联就能反映某一特定领域的知识构架。根据Belkin的研究[2],信息检索用户在表达他们的信息需求时,都存在“知识不规则状态”(Anomalous States of Knowledge)。Belkin研制的文献检索系统把检索者的知识状态表达为词汇之间的关联网络,从该网络的结构和特点可以识别知识状态的不规则之处。由此他认为,某领域的词汇关联网络能够有效表达个体对该主题领域的知识状态。另外,许多人类记忆关联模型均采用了以主题相互连接的网络框架来表达知识,其中,Anderson关于人类记忆的理论最具代表性:人们记忆的并不是口头交流的确切措词,而是词汇的潜在含义。主题(Proposition)是代表着承载含义的命题(Assertion)的最小知识单元。记忆能用这样的主题网络表达出来,能引导到特定信息的关联路径强度决定发散激活的程度。此发散激活理论(Spreading Activation)影响了许多以语义网络为基础的信息检索系统的设计。Chen所提出的词表自动构建理论和方法均基于该理论,把词表视为一个语义网络,应用人工智能领域的发散激活算法,找出某个节点(概念)的强相关概念[3]。
词表可以视为一个“概念空间”,一个类似人类词语联想模式的网络,网络的节点是各种词语、术语或概念。而概念之间的联系由带有权重的边来表示。这些研究为词表自动构建提供了理论依据。
(3)语言学理论
语言学的现有理论为情报检索语言的研究提供了理论规范。我国著名语言学家赵世开认为,编制一部具有准确性和高效性的检索主题词表需要语言学家协同有关专家共同研究[4]。在叙词表自动构建研究中,汉语字面相似性特点和汉语行文特点,为实现自动识别词间关系提供重要的线索和依据。
汉语相关词汇在构词上具有字面相似的特点,为实现汉语词表自动构建提供了有效途径。根据相关汉语词汇往往含有相同词素这一汉语构词特点,可以实现按词素聚集相关词汇,辅助识别具有相关关系和同义关系的词汇。词素是构成词的最小单位,是不能再分割的意义单元。一个词素一般由一到两个汉字组成,个别由多个汉字组成,如:乌鲁木齐。一个词由一个或多个词素构成。根据汉语构词特点,一般来说,拥有相同词素的词汇或词组具有某种语义关联,存在聚类现象(字面成簇现象),如:税、税务、税收、所得税等等。汉语的字面成族特点在情报检索中具有重要的应用价值。张琪玉教授曾撰文讨论利用字面相似特点聚类词汇可以构造粗泛的词簇[5],宋明亮曾将字面相似聚类法应用于后控制词表的动态维护[6]。
有学者统计,汉语叙词表词族内的词与族首词词根完全相同或部分相同的比例高达80%[7]。叙词表是根据主题词的主题概念属性聚类成族,如果能充分利用汉语词汇具有字面成族的特点,将是辅助词汇聚类的好办法。
表4-1 各叙词表词族字面成族情况[8]
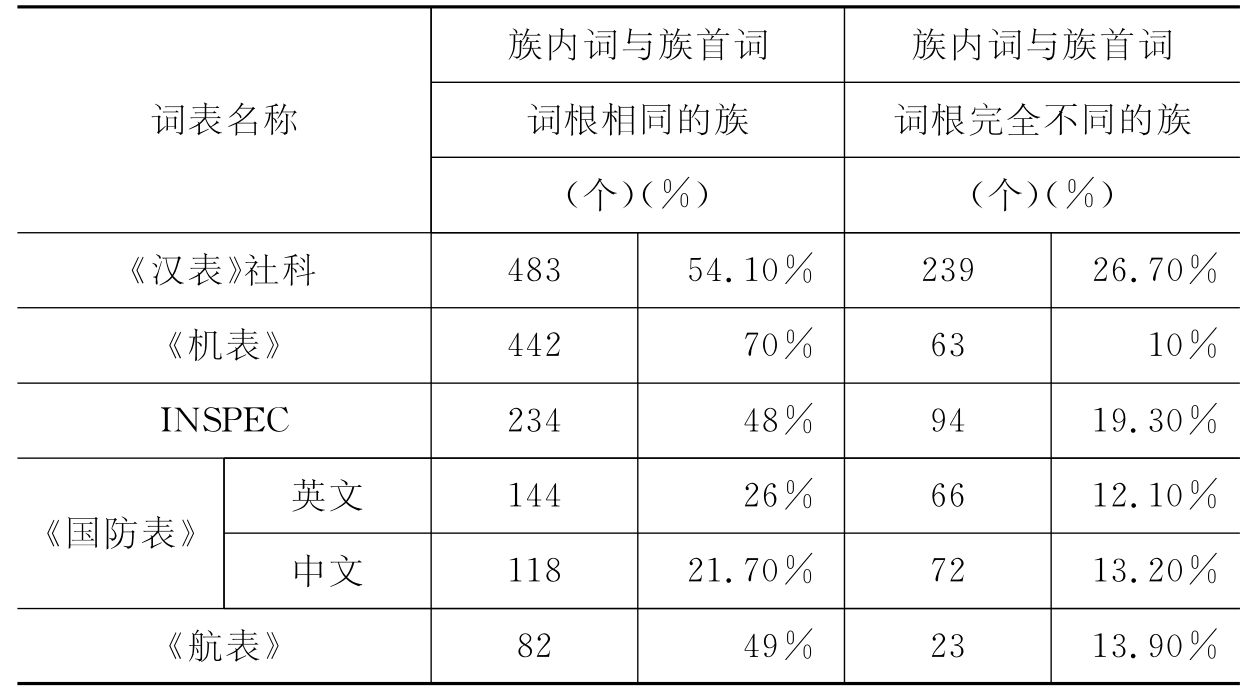
另外,具有相同词素的词汇往往在语义上是相关的,如“税收管理”与“税收检查”可以切分为词素“税收”、“管理”和“检查”。据此设计词素相似度系数的计算方法,可以据此识别相关词汇。
利用汉语字面相似的特点实现词汇的聚类,只能粗略地把一些字面上相似的词或词组聚集在一起,但因有些语义相关的词汇并无字面相似特点,如“田赋”和“农业税”,因此,单纯依靠字面相似性聚类词汇是不可行的,只能作为一种计算机辅助聚类途径,而真正的词聚类应该是词语概念层面上的聚类。
汉语行文特点也为词间关系识别提供了有效途径。中文文献尤其是词典等工具书是领域词表收词的重要来源,其对词汇的定义等描述方式也为词间关系识别提供了重要线索。中文词汇的定义方式具有相似的模式,例如采用同义词进行定义的方式常存在以下标志性语词:“亦称…”,“也称…”,“简称…”,“…的简称”,“俗称…”等。另外也存在用下位词定义概念上较为宽泛的上位词的情况,如:“…包括…”,“例如…”等。陆勇在其硕士论文中采用了模式匹配的方法[9],在机器学习这些模式以及人工总结模式的基础上,可以识别提取出领域内常用的名词、术语以及它们之间的关系,并通过试验证明该方法简单实用,值得推广。
(4)系统论原理
所谓“系统”是指由相互联系、相互依赖的若干组成部分结合而成的具有特定功能的有机整体。从系统的观点出发,着重从整理与部分(要素)之间、整体与外部环境的相互联系、相互作用、相互制约的关系中综合地、精确地考察对象,以达到最佳地处理问题的一种方法[10]。①系统的整体性原则强调要素与系统之间是一个整体、不可分割;要素与环境及各要素之间相互联系与作用,而使系统呈现出各单一要素所不具备的整体功能。②系统的联系性原则强调系统内部各要素之间的联系,并通过这种联系与相互作用来实现其整体功能、体现其整体属性;强调系统与外部环境之间的联系,并认为一定的环境是系统存在、发展和发挥其功能的重要条件,且系统在和外部环境相互联系与作用的过程中必然会发生物质、能量和信息的相互交换。③系统的有序性原则认为系统是多级别、多层次的有机结构,有序性越高,结构与功能就越优化。④系统的动态性原则强调系统随时间而发生变化的规律,要求人们必须以动态的和发展的眼光和思维去认识、考察和把握一个系统及其分要素和子系统。
一部领域叙词表就是一个完整的领域知识系统。它由若干概念按照一定方式组合而成,概念之间存在各种相互关系,对概念相互关系的揭示和组织方式影响整个叙词表功能的有效发挥。叙词表作为一个整体具有一定功能,当应用到信息检索系统这个大环境中时,它起到一种桥梁作用,通过与检索者和文献对象之间的信息交换来完成整个信息检索过程。
系统论原理可有效指导叙词表自动构建。系统的整体性原则指导收词和选词过程尽量使词表收全学科领域的概念,并充分揭示概念之间的关系,形成领域知识概念体系,满足用户的信息检索需求;系统的联系性原则指导叙词表构建时要充分揭示概念之间的族性和等级关系、等同关系和相关关系,使得词表能够反映人类头脑中的概念空间体系,同时词表应该具有兼容性,支持互操作,提高标引质量和检索效率;系统的有序性原则指导所构建的词表,能够以不同方式如字顺表、词族索引、范畴索引、分类表、轮排索引对概念进行序化和优化,便于检索使用;根据系统的动态性原则,需要考虑词表是一个动态的有机体,随着学科领域知识的增长和变化,其核心概念体系也会发生变化,叙词表需要具有开放性和新词识别功能,易于修改和维护。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










