



4.4 多语种叙词本体的构建
叙词表对于构建表示和检索信息的主题索引具有十分重要的作用。目前国际多语种信息的交流越来越广泛,需要多语种叙词表来进行多语种标引和检索工作。这样用户就可以用母语或至少用其所熟悉的一种语言来进行信息检索等。因此编制多语种叙词对促进世界范围的信息交流具有重要作用。
多语种叙词表是在普通叙词表的术语及关系中,加入了不同语种的映射。本体是“一个概念模型的明确的规范说明”,在应用上,本体对概念及其关系的描述更加精细,这一点特别适合于多语种的映射。
研究叙词表新的构建理论与新的应用模式,直接将叙词表构建成叙词本体,有别于目前的主流研究思路,对促进本学科领域的同类理论研究有重要学术参考价值。按照上一节所提出的叙词本体的构建方法,本节以一个实验系统,即结合《中国图书馆分类主题词表》和《管理科学主题词表》中的情报学领域叙词来具体构建多语种叙词本体,从而详细地阐述叙词本体的建模过程。
4.4.1 确定多语种叙词本体的应用目的
构建多语种叙词本体,完全保留叙词表的功用,同时又全面地利用本体理论的研究成果,使之成为有效的跨语言语义词典,成为一种知识共享工具,极大地拓展应用领域。
多语种叙词本体可以成为跨语言信息检索的语料库,实现多语种信息的高效组织,提高用户检索的查全率和查准率。多语种叙词表也可以作为各个联机数据库的语料库。各联机数据库服务公司可以利用多语种叙词表来扩展他们的业务,使在用户对国内外期刊会议论文都有需求的情况下,输出满足用户需求的国内外命中的文献。
4.4.2 多语种叙词本体的整体设计
(1)设计概念范围
经过相关的信息收集及需求分析,结合实际情况,笔者选取了情报学领域为建立多语种叙词本体的对象。通过构建情报学叙词本体,探索、认识情报学学科的规律,为情报学叙词表、本体服务提供可以借鉴的框架和成果。整理现有的情报学知识体系,发现其中的缺陷与不足。利用本体的思想和方法可以重新检视知识体系,并且对其中的所有部分都进行严格的逻辑验证,从而发现现有知识体系中应当涉及但未能涉及的部分以及体系中存在的逻辑谬误,使得学科体系结构更为合理化。
(2)开发工具的选择(Protégé)
一个良好的本体编辑工具应能在本体建模过程中提供书写本体、一致性检查、可视化、查询、推理,以及将建模结果转换为不同本体语言表示格式等功能。
目前国际上已经有许多本体的建模工具,能够自动地生成各种不同形式的本体语言。如Ontolingua、OntoSaurus、Protégé、KAON、0ilEd等工具。其中由斯坦福大学医学院开发的Protégé,它是用Java开发的一个开放源码的本体编辑器。Protégé有良好的用户界面,容易学习使用,支持多重继承,对新数据进行一致性检查,并且具有很强的可扩展性。
由于Protégé所具有的优点,它基本上成为国内外众多本体研究机构的首选工具。在我们的本体编码过程中选择Protégé作为本体建模工具,用来构建初始的叙词本体。
(3)本体描述语言的确定(OWL)
本体的描述语言比较多,如XML,XML Schema,RDF,RDF Schema。其中XML(http://www.w3.org/XML/)提供了一种结构化文档的表层语法,但没有对这些文档的含义施加任何语义约束;而XML Schema(http://www.w3.org/XML/Schema)是一个约束XML文档结构和为XML扩充了数据类型的语言; RDF(http://www.w3.org/TR/2002/WD-rdf-concepts-20021108)是一个描述RDF资源的属性(property)和类(class)的词汇表,提供了关于这些属性和类的层次结构的语义。RDF是一个三元组,用(资源,资源所具有的属性,属性值,即主体-属性-客体)来表示。RDF表现的是一个数据模型,描述事物也即资源的属性,以及属性所具备的值。而OWL比RDF的含义更广,是RDF的扩张,即为我们提供了更广泛的定义RDFS词汇的功能,可以定义词汇之间的关系,类与类之间的关系,属性与属性之间的关系等。它旨在用于那些需要由应用程序而不是由人类来处理文档中信息的情形。OWL可被用来明确表示词汇表中术语的含义以及术语间的关系。如此表示的术语及术语间关系被称为本体(ontology)。OWL较之于XML,XML Schema,RDF,RDF Schema添加了更多的用于描述属性和类的词汇,例如类之间的不相交性(disjointness),基数(cardinality,刚好一个)、等价性、属性的更丰富类型、属性特征(例如对称性)以及枚举类型(enumerated classes)。因此在表达含义和语义方面,OWL比XML,RDF和RDFS有更多的表达手段,在Web上表达机器可理解内容的能力也比这些语言强。由于OWL的这种优势,我们的叙词本体采用OWL语言来描述本体。
本书第2章中介绍过网络本体语言的三个子语言: OWL Lite、OWL DL和OWL Full。这三个语言的表达能力和推理能力是逐渐增强的。这里在构建叙词本体选择的是OWL DL。OWL DL包含了所有网络本体语言的元素,在这三个子语言中拥有较强的表达性却又不失计算力,很符合本研究的要求。因为本文进行本体构建的目的是为了更准确、更完备地表达领域知识。所以语言的表达能力非常重要。OWL DL符合描述逻辑,同时又不失计算完整性,并能进行推理。综合考虑,OWL DL最符合需求。
(4)多语种构建方案的确定
根据前面对于多语种映射方案的讨论,这里将两种构建方法的实现过程都介绍给读者,以便根据具体项目的需求予以选择。构造方法的不同对后面叙词本体的演化机制有着很大的影响,方案的实现过程将在后面章节里面详细说明。
(5)相关原则
叙词本体的创建是一个工程问题,需要科学准则去指导这个创建过程。人们在总结已有成功和失败经验基础上,归纳出一些有用的本体创建准则,用于指导创建。韩韧、黄永忠等学者在《OWL本体构建方法的研究》中曾提到,最有影响的是T.R.Gruber在1995年提出了5条准则:
①明确性和客观性:本体应用自然语言对术语给出明确客观的语义定义。
②完整性:所给出的定义是完整的,能表达特定术语的含义。
③一致性:知识推理产生的结论与术语本身的含义不会产生矛盾。
④最大单项可扩展性:向本体中添加通用或专用的术语时,通常不需要修改已有的内容。
⑤最少约束:对待建模对象应该尽可能少地列出约束限定条件。
实际上,这5条设计准则在使用过程中往往需要进行权衡,难以全部满足。
4.4.3 词间关系的预处理
这一步是基于叙词表建立叙词本体的最核心、最关键的步骤,是叙词本体建立的基础。虽然叙词表的叙词和叙词间的关系有明确的语义,这使得叙词表可以作为向叙词本体转换的基础。但是大部分的叙词表所表述的词间关系太过宽泛,不能达到本体中精确的语义的要求。因此,从叙词表向叙词本体模型转换的第一步,也是最关键的一步,就是对叙词表中的叙词及叙词间的关系进行预处理和精炼。通过对叙词表中叙词及词间关系进行预处理和精炼,将叙词转变成领域本体中的概念,将叙词表中宽泛、不准确的词间关系精炼为明确的概念间关系,使叙词表真正成为转换成叙词本体或作为叙词本体建设的基础资源。这里我们参考《中国图书馆分类主题词表》和《管理科学主题词表》对叙词及词间关系进行预处理。
4.4.4 多语种叙词本体的详细设计
(1)定义类和类的等级体系
首先根据叙词表确定该领域与最重要的概念相关的其他重要概念,以建立核心概念集。由于我们是参照《中图法》思想来定义我们的类体系结构,因此我们采用自顶向下法来构建,即将《中图法》中的学科体系结构嵌入到这个叙词本体中,充当叙词本体的主干结构。对于其中不足部分进行添加和修改。根据叙词本体的定义以及结构,我们可以以《中国图书馆分类主题词表》为蓝本来构建叙词本体。《中国图书馆分类主题词表》主表中的左部分是分类法,给出了学科分类,右部分则是对应于该分类的叙词。因此,我们可以用学科分类来构建叙词本体中的概念C,用叙词来构建叙词本体中的术语I。
Protégé构建的本体描述的是某个特定领域中重要的概念和联系;这样不仅为该领域提供了一部词汇表,同时也为词表中词语含义提供了一种计算机可操作的规范。Protégé构建本体时,客观世界或某个领域是用类(Classes)来划分的,而且允许在最低层类别之下添加实例(Instances),通过定义属性(Properties)将相关的类和实例联系起来,然后用图形表示出来,显示类和实例,并表示出它们之间的各种关系。目前Protégé提供了几个插件来实现可视化功能,例如TGVizTab采用的是网状图结构(见图4-4),将类、实例、属性节点与节点相连,形成一张动态的语义相关的网络。

图4-4 网状图结构参考刘俊、李华等学者的《叙词表词间关系可视化实验研究》)
通过构建情报学叙词本体的整体框架,使大家了解Protégé建立OWL的基础用法。本实验系统采用的是Protégé3.3beta版本,其安装文件可以在Standford大学的网站http:// protege.stanford.edu上下载得到。
步骤1:建立新的项目。打开Protege,然后会出现对话框,点击Create New Project,出现Create New Project对话框后,在提示框选择生成文件的格式,见图4-5(a)。本研究选择OWL Flies(.owl or. rdf)后,点击Next,选择OWL DL语言,见图4-5(b)。
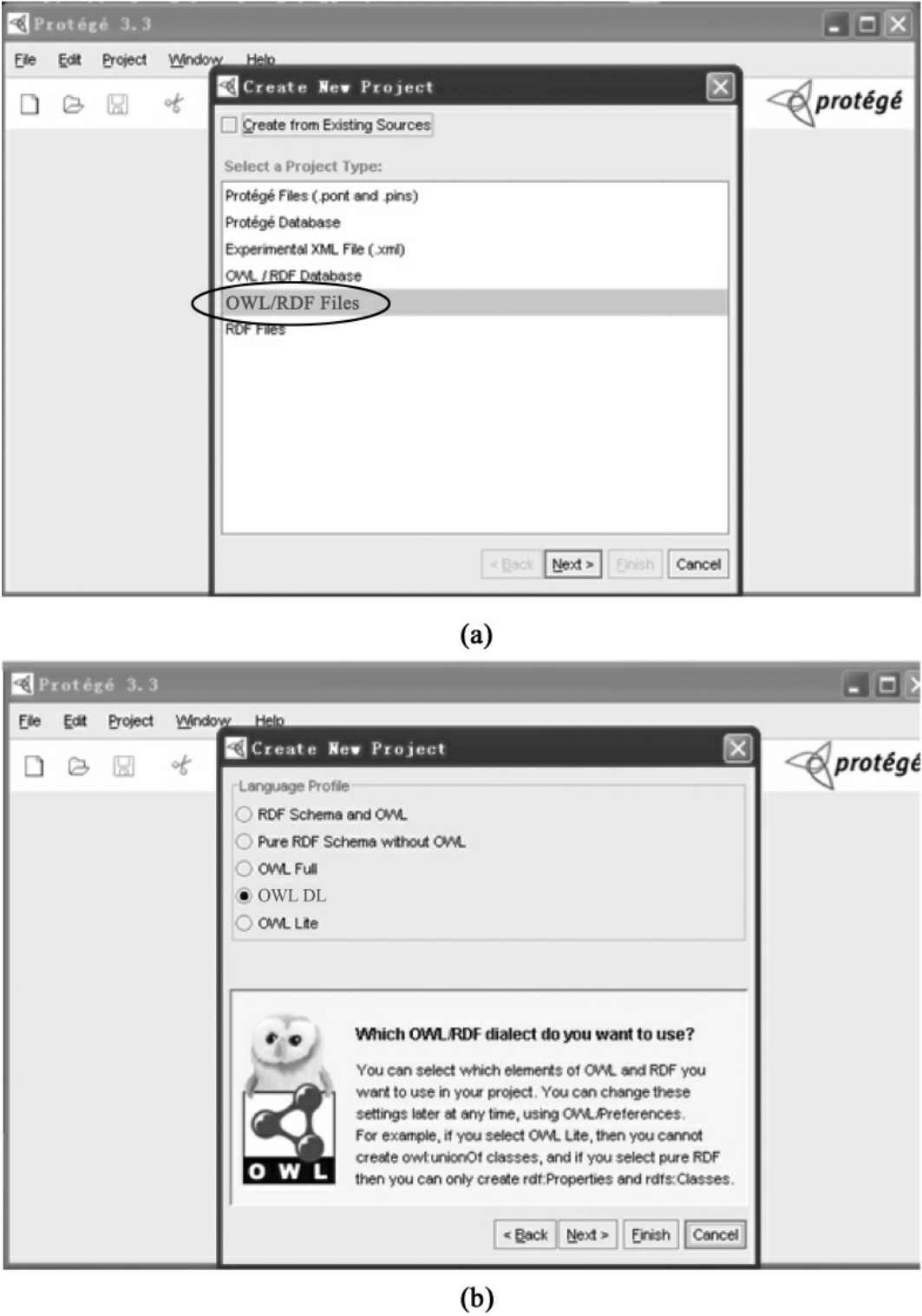
图4-5 在Protégé中建立新项目
步骤2:建立类。Protégé的主页面会出现,OWL Classes(OWL类),Properties(属性),Forms(表单),Individuals(个体),Metedata(元类)这几个标签。我们选择OWL Classes来编辑。在Asserted Hierarchy(添加阶层)中,会有所有类的超类OWL Thing上点击As-serted Hierarchy旁边的Create subclass,见图4-6(a),或者在OWL Thing,点击右键选择Create subclass,会出现Protege自动定义名为Class_ 1的类。在右边的CLASS EDITOR(类编辑器)的Name选项中,输入“科学_科学研究”对该类重命名,见图4-6(b)。
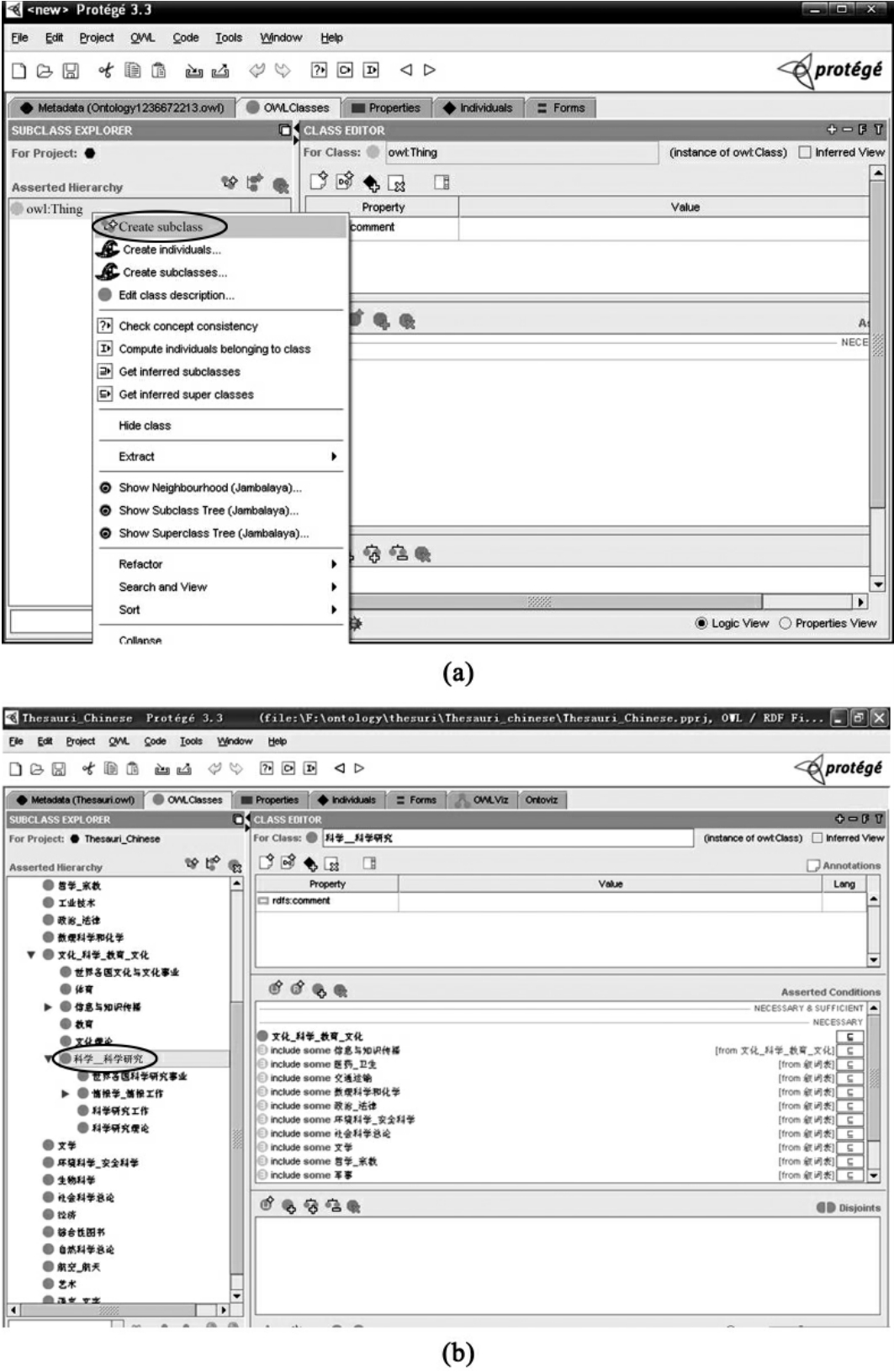
图4-6 在Protégé中创建类
步骤3:建立科学_科学研究的子类,在科学_科学研究点击上右键,选择Create subclass,并按照上述方法将其名字变为相应的子类名字。
步骤4:然后按照上面的方法,建立Science and Science Research的其他子类,以及子类的子类。状态如图4-7所示。
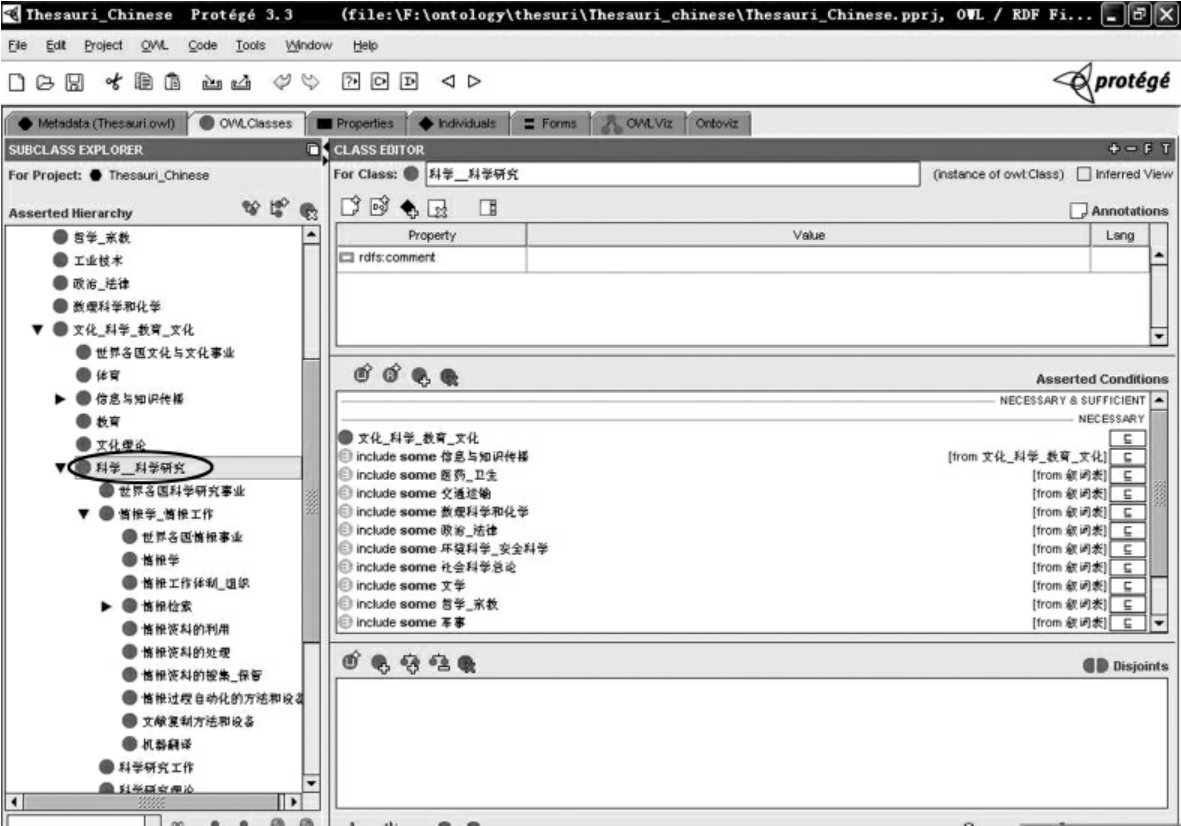
图4-7 在Protégé中建立子类
其中,概念之间的定义方式如下:
<rdfs:Class rdf:about="http://www.domain2. com#情报学与情报工作">
<rdfs:subClassOf rdf: resource="http://www.domain2. com#科学_科学研究"/>
</rdfs:Class>
(2)定义类的属性
图4-8是属性的编辑界面,可以在左边的浏览框中新建属性,然后在右端的编辑框对这个属性作限定。在编辑框中选择这个属性的使用范围,也可以设定属性的性质。从图中可以看到右下角有一些选项,如Transticive代表这个属性可以传递,InverseFunetional代表这个属性是可逆的。可以在下面的Domain和Range框选定其应用的范围。Protégé中已经存在五个注释类的属性如下: owl: versionlnfo,rdfs: label,rdfs: comment,rdfs: seeAlso,rdfs: isDefinedBy。

图4-8 Protégé中属性编辑界面
类只是描述了一个框架,一定程度上,还不能够确切地描述一个领域。因此还需要继续定义这个类的内部结构。在上述步骤中,我们已经确定了一些重要术语,那么我们接下来的任务就是确定哪些可以成为其中类的属性了。
类的属性包括数据类型属性和对象属性。数据类型属性(DataType Property)在本实验系统中包括叙词含义描述has description,叙词的中图分类号has class number,以及其他的一些信息。
类的内在属性确定后,还需要确定类之间的关系,又被称为“外在属性”。本书将接下来介绍如何在类之间建立关系。属性的一个重要功能就是描述概念间关系或实例间关系,在Protégé中关系也是通过属性来表示的。Protégé自定义了一些比较普遍的描述性的关系,在图中列出了大部分Protégé自定义的关系。
建立对象属性。新建一个ObjectProperty(注意不是DataProperty)选择Properties标签,建立一个对象属性(owl: ObjectProperty) S(属),然后再建立一个属性F(分),它是属性S的逆关系(owl: inverseOf),在右下角Inverser框中选择S属性,如图4-9、图4-10所示。
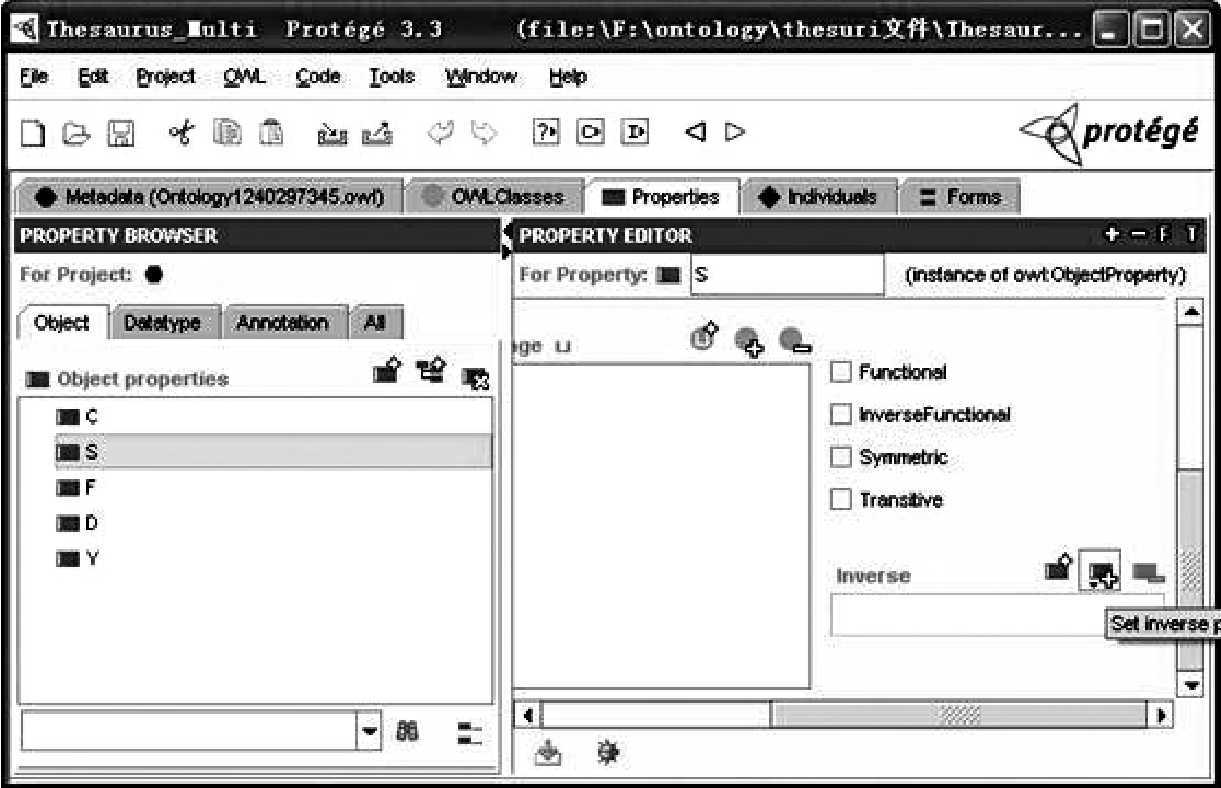
图4-9 建立对象属性
其他的对象属性建立过程与上述步骤类似,这里不再重复的介绍。建立数据类型属性。新建一个Data Property。选择Properties标签,建立一个数据类型属性(owl: DataProperty)。数据类型属性(DataType Property)在本实验系统中包括叙词含义描述has description,叙词的中图分类号has class number,以及其他的一些信息。
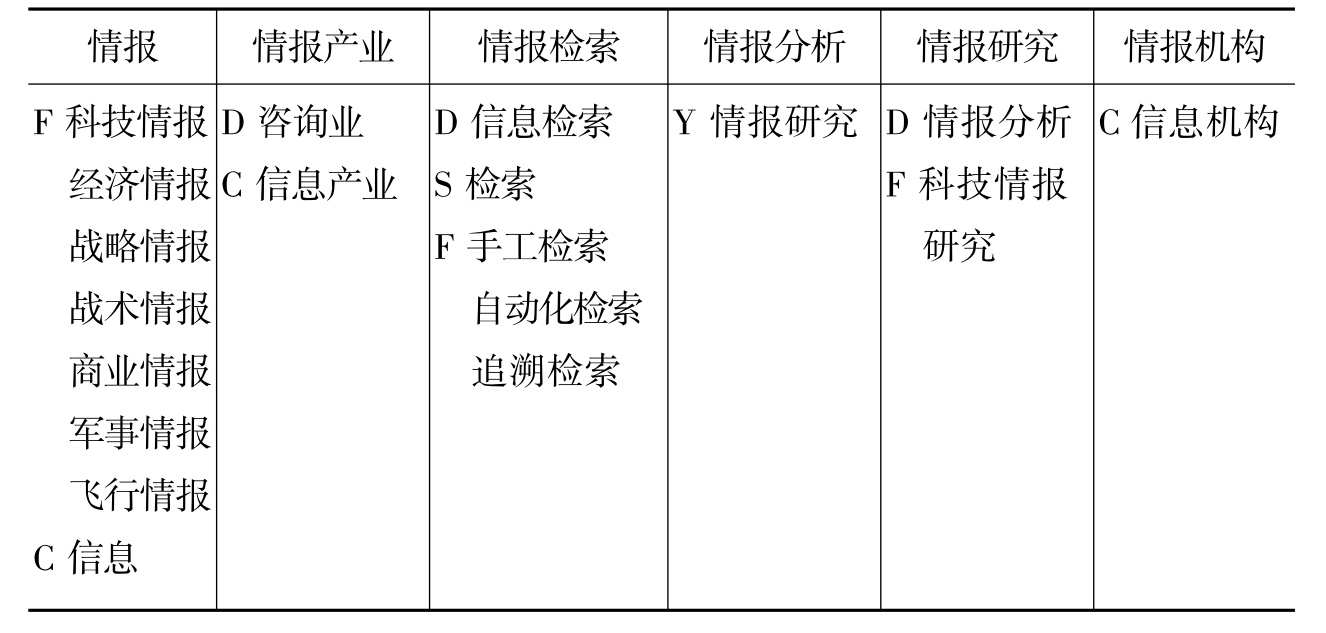
虽然叙词本体可以继承本体自定义无限概念关系的特性,但是为了让叙词本体不至于太过复杂,我们决定目前的研究范围还是仅限于“用,代,属,分,参”这五种基本关系和语种关系,概念关系的预处理和确定参照《管理科学主题词表》(见表4-5)。
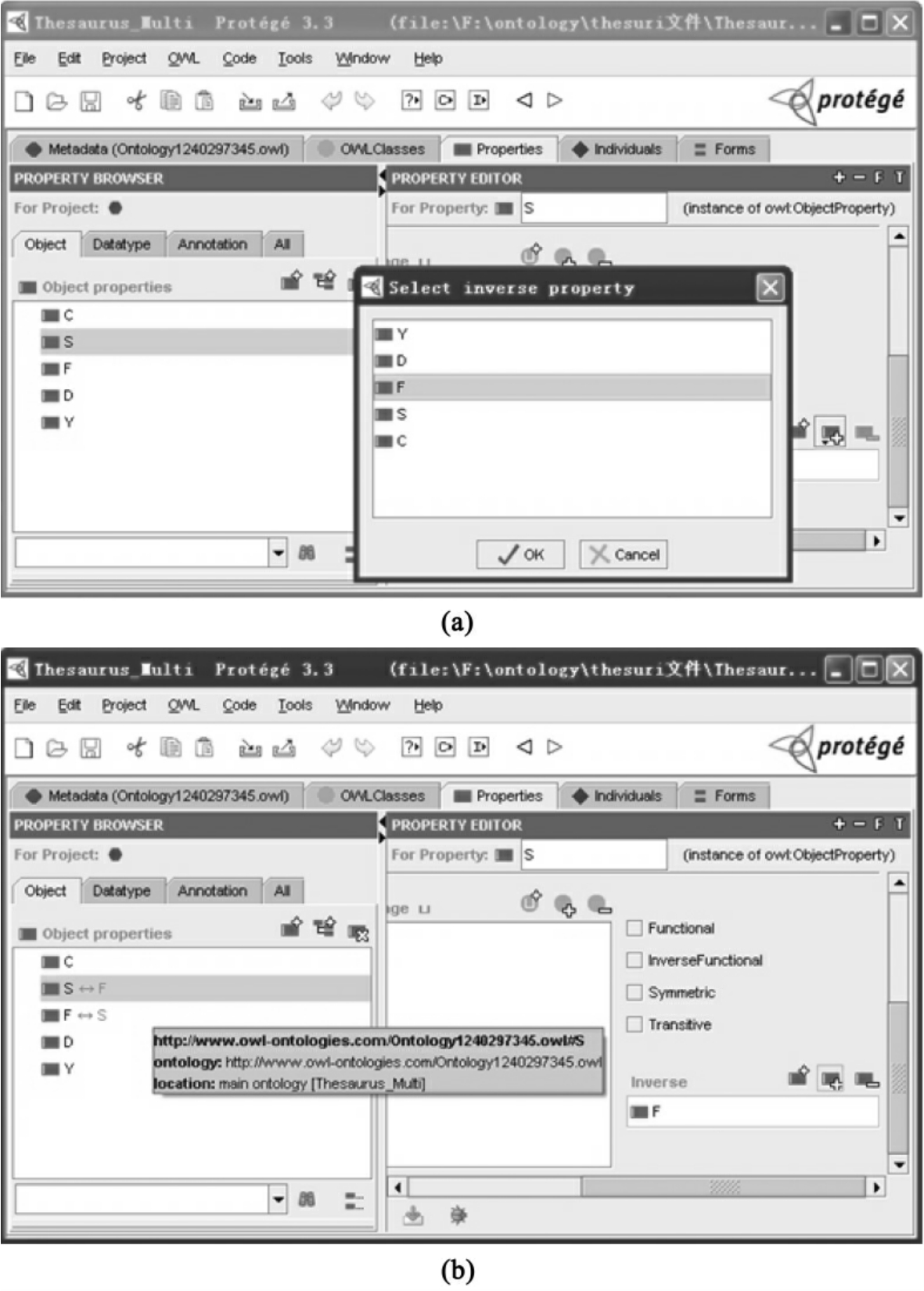
图4-10 建立属性间的互逆关系
表4-5 《管理科学主题词表》中部分叙词及词间关系
①上下位关系
Protégé系统提供了一个基本大类owl: Thing,在此类之下,允许用户自定义各大类,再一级级细分出小类,最后一级小类之下可以添加具体实例。由于这里选取的都是抽象名词(见表4-5),没有实例名词,因而在Protégé中编辑叙词表时,一个叙词就作为一个类。这样类的上下位关系就反映着叙词间的等级关系。
②等同关系
Protégé提供两种类型属性:对象属性(Object Property)和数据属性(Datatype Property)。对象属性用来表示类或实例之间的相互联系,即关系,包含翻转属性、传递属性、对称属性和函数属性四种类型。数据属性反映的是某类或实例本身具有的属性,例如图书的数据属性有开本、页码等。不难看出,在表现叙词间等同关系和相关关系时,需要定义对象属性。只要在属性编辑页面中选定一种对象属性,然后再添加该属性的定义域和值域,就可将存在此类关系的类或实例联系起来。
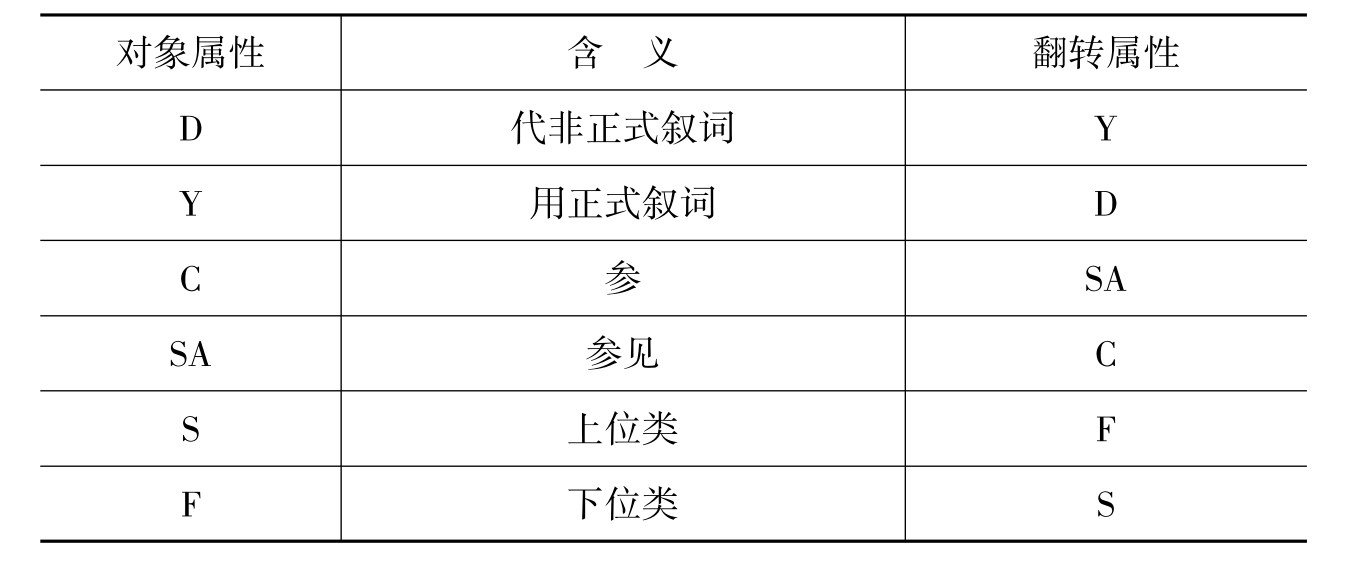
《管理科学主题词表》在处理同义词时,通常指定其中一个常用的词语为正式叙词,其余词均为非正式叙词,表示方法为“正式叙词D非正式叙词,非正式叙词Y正式叙词”。根据D和Y的互逆关系,在Protégé属性界面中新建两个对象属性D和Y,并定义Y是D的翻转属性。只要类1用属性D联系到类2,系统就自动地从类2用属性Y联系到类1。参考刘俊、李华等学者编写的论文《叙词表词间关系可视化实验研究》,笔者画出了对象属性设置的表4-6。
表4-6 对象属性设置
③相关关系
相关关系C是一种特殊的翻转属性,是一种自逆关系。笔者新建一种对象属性SA(See Also)(见表4-6)作为属性C的翻转属性,这样叙词1若与叙词2相关,可以从叙词1用属性C联系到叙词2,相应地叙词2用属性SA反向联系到叙词1。在此基础上,与等同关系可视化操作一样,为每一组相关关系建立一对翻转子属性,并相应定义每个子属性的定义域和值域,即添加有相关关系的两类或多个类。
④自定义词间关系
在《汉表》中等级关系只包括属种关系,而并未揭示整体与部分的关系以及列举关系。而利用Protégé的属性设置功能,我们就可以自定义一对翻转属性BTP和NTP来揭示整体—部分关系,同时通过在类下设置实例(instance)就可以来揭示列举关系(BTI和NTI)。BTP和NTP是ANSI/NISO Z39.19-2005标准中建议使用的,BTP是Broader Term(Partitive)的缩写,NTP是Narrower Term(Partitive)的缩写。其中BTP指向包括各组成部分的整体,NTP指向构成整体的组成部分。例如,数据库是信息系统的一个重要组成部分,可以表示为:数据库BTP信息系统,信息系统NTP数据库。由于Protégé可以在最底层的类下添加实例,因而很容易实现列举关系的可视化,不再赘述。
叙词概念之间的关系用、代、属、分、参、族作为概念间的关系定义:
<owl:ObjectProperty rdf:ID="D">
<owl:inverseOf>
<owl:ObjectProperty rdf:ID="Y"/>
</owl:inverseOf>
<rdfs:range rdf: resource="http://www.domain2. com#科学_科学研究"/>
<rdfs:domain rdf:resource="http://www.domain2. com#科学_科学研究"/>
</owl:ObjectProperty>
<owl:ObjectProperty rdf:ID="Z">
<rdfs:range rdf:resource="http://www.domain2. com#科学_科学研究"/>
<rdfs:domain rdf:resource="http://www.domain2.com#科学_科学研究"/>
</owl:ObjectProperty>
<owl:ObjectProperty rdf:ID="S">
<owl:inverseOf>
<owl:ObjectProperty rdf:ID="F"/>
</owl:inverseOf>
<rdfs:range rdf:resource="http://www.domain2. com#科学_科学研究"/>
<rdfs:domain rdf:resource="http://www.domain2. com#科学_科学研究"/>
</owl:ObjectProperty>
<owl:ObjectProperty rdf:about="#F">
<owl:inverseOf rdf:resource="#S"/>
<rdfs:range rdf:resource="http://www.domain2.com#科学_科学研究"/>
<rdfs:domain rdf:resource="http://www.domain2. com#科学_科学研究"/>
</owl:ObjectProperty>
<owl:ObjectProperty rdf:about="#Y">
<rdfs:domain rdf:resource="http://www.domain2. com#科学_科学研究"/>
<rdfs:range rdf:resource="http://www.domain2. com#科学_科学研究"/>
<owl:inverseOf rdf:resource="#D"/>
</owl:ObjectProperty>
<owl:DatatypeProperty rdf:about="http://www.domain2. com#hasChineseTerm">
<rdfs: range rdf: resource=" http://www.w3.org/2001/ XMLSchema#string"/>
<rdfs:domain rdf:resource="http://www.domain2. com#科学_科学研究"/>
</owl:DatatypeProperty>
<owl:SymmetricProperty rdf:ID="C">
<owl:inverseOf rdf:resource="#C"/><rdf:type rdf:resource="http://www.w3.org/2002/07/owl# ObjectProperty"/>
<rdfs:domain rdf:resource="http://www.domain2. com#科学_科学研究"/>
<rdfs: range rdf:resource="http://www.domain2. com#科学_科学研究"/>
</owl:SymmetricProperty>代是可以逆转的,定义成逆反属性,而属、分也是可以逆转的,因此也定义成逆反属性,而参为对称的,因此定义成对称属性。而所有的对象属性的值域和定义域都是所有的概念,因此为最上位类的概念。
隶属于某种概念的(叙词)术语在本体中则以概念实例的形式呈现,用OWL表示如下:
<thes:情报检索rdf:about="http://www.domain2.com#查全率">
<thes:hasChineseTerm rdf:datatype="http://
www.w3.org/2001/XMLSchema#string">查全率
</thes:hasChineseTerm>
</thes:情报检索>
这表示查全率是情报检索的一个叙词,其中thes:hasChinese-Term是查全率的一个值属性,而<thes:hasChineseTerm></thes: hasChineseTerm>之间的查全率是属性值。这样做的好处是:可以增加更多的值属性来描述此叙词,比如用英语来描述这个术语,就可以增加一个值属性<thes:hasEnglishTerm>,用法和中文的用法一样。这样有助于构建多语种叙词本体。
⑤语种关系
a.建立等同关系基于概念,用“等同关系”把不同语种的叙词联系起来。界面右下角是“Asserted Conditions”框,其中包含“NECESSARY”项和“NECESSARY&SUFFICIENT”,而该框的右上角有三个按钮,分别可以添加表达式、限制和具名类。首先选定“情报”,然后选“NECESSARY&SUFFICIENT”,最后点击“Add named class”。然后,在弹出框中选择“Information”,按确定键,即可把“情报”和“Information”等同起来,结果如图4-11(a),图4-11(b),图4-11(c)。可以看到在类检索框和“Asserted Conditions”框均显示出来。
b.语种属性定义语种属性,是采用的固定中心方法,即以某一种语言为中心语言,以此语言构成叙词表,其他语种作为实例的一个属性。这里将中文作为中心语言,其他语种作为实例的一个属性。首先在属性编辑界面,建立对象属性hasEnglishTerm,以叙词“情报”为例,多语种关系的建立如图4-12(a),图4-12(b),图4-12(c)所示。

图4-11 基于概念的多语种等同
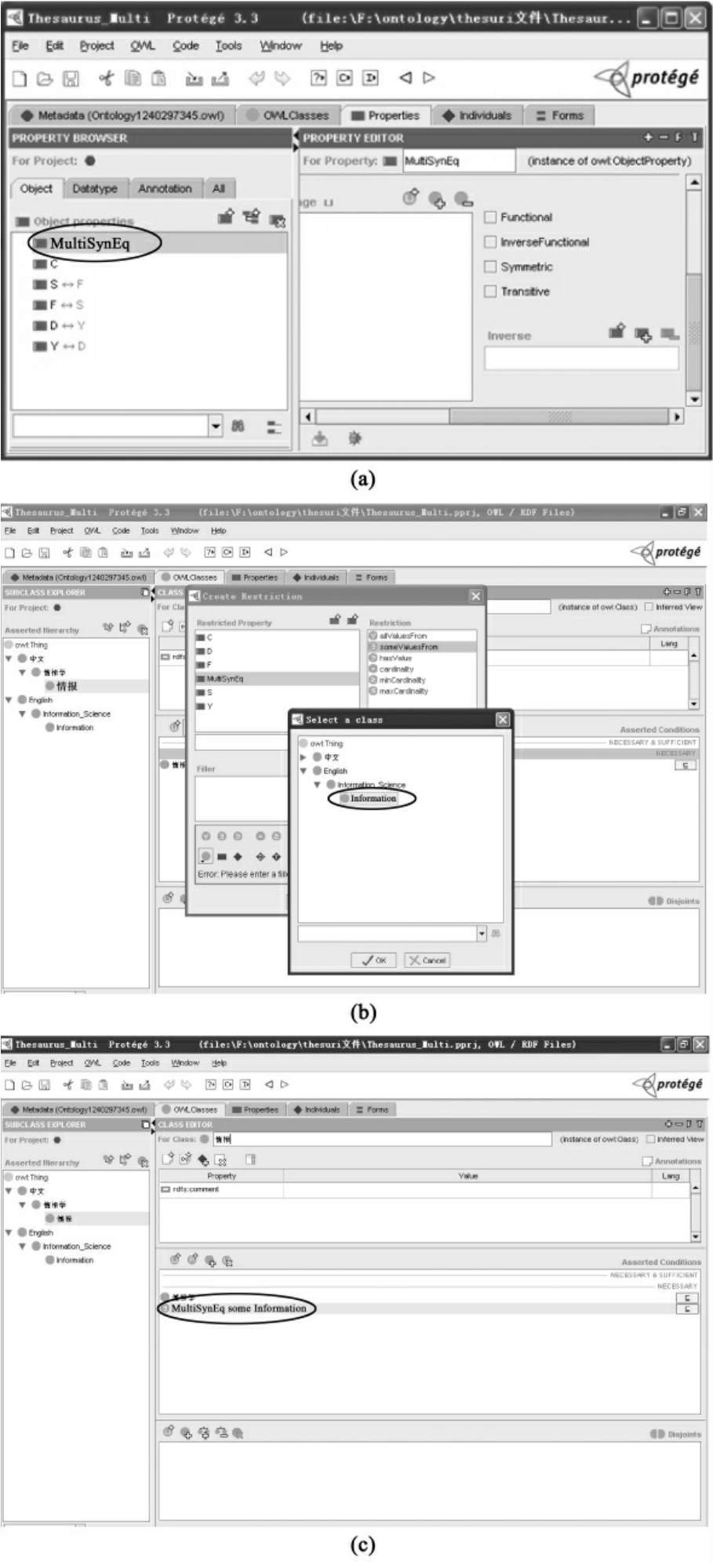
图4-12 语种属性的建立
(3)创建实例
实例是本体的重要组成部分,可以在Protégé工具中为类添加实例。在完成了上述定义后,我们的最后阶段是将这些类实例化。图中的菱形图标代表Individuals框,点击该图标就可以进入实例界面进行编辑。例如,为“情报检索”添加一个实例“专题检索”。首先,在CLASS BROWSER框中选择“情报检索”,然后在INSTANCE EDITOR中对这个实例进行编辑,可以为它取名、定义等。结果如图4-13所示。
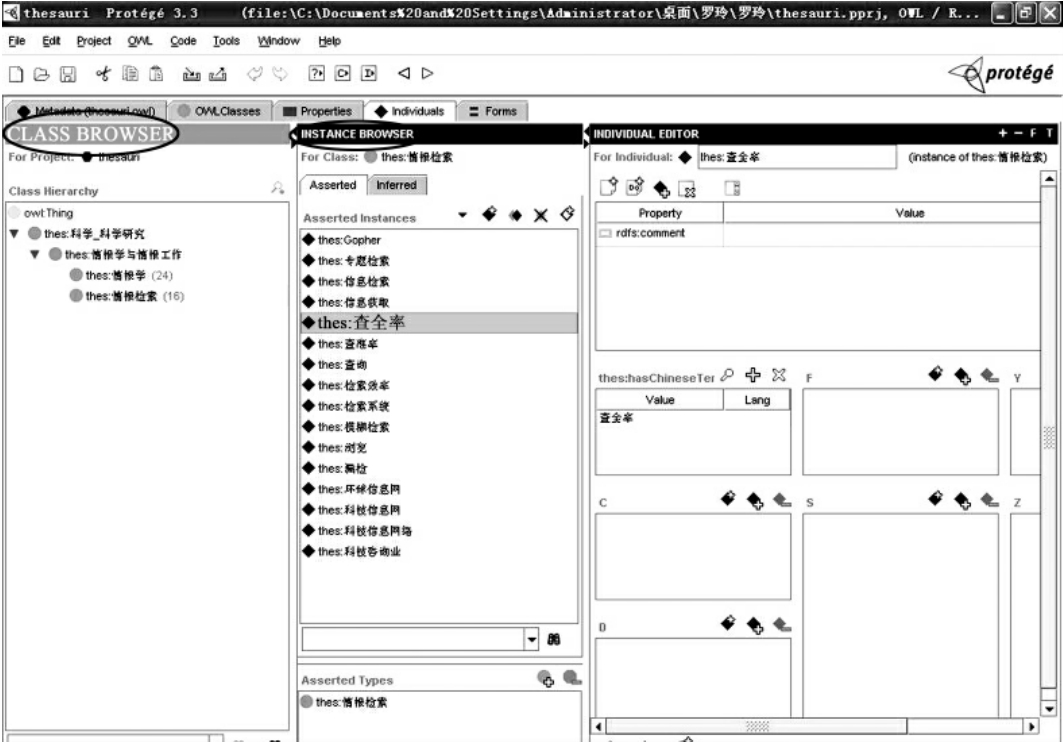
图4-13 创建实例
4.4.5 叙词本体的表示
首先,我们根据《中国图书馆分类主题词表》构建了“科学与科学研究”类目下的一部分叙词,由于是实验系统,因此我们并没有将所有的分类和术语都创建起来,而是选择了其中的一部分。其结构如图4-14所示。
在图4-14中,左边区域为叙词本体的类属结构:科学—科学研究→情报学与情报工作→情报学,情报检索;而中间区域则是类目下的实例,这里就是属于该类目的叙词,从图中可以看到,情报学下有24个叙词,而信息检索下有15个叙词;最右边是中间叙词所对应的关系,包括用(Y),代(D),属(S),分(F),参(C),族(Z)以及值属性,如中文术语等。
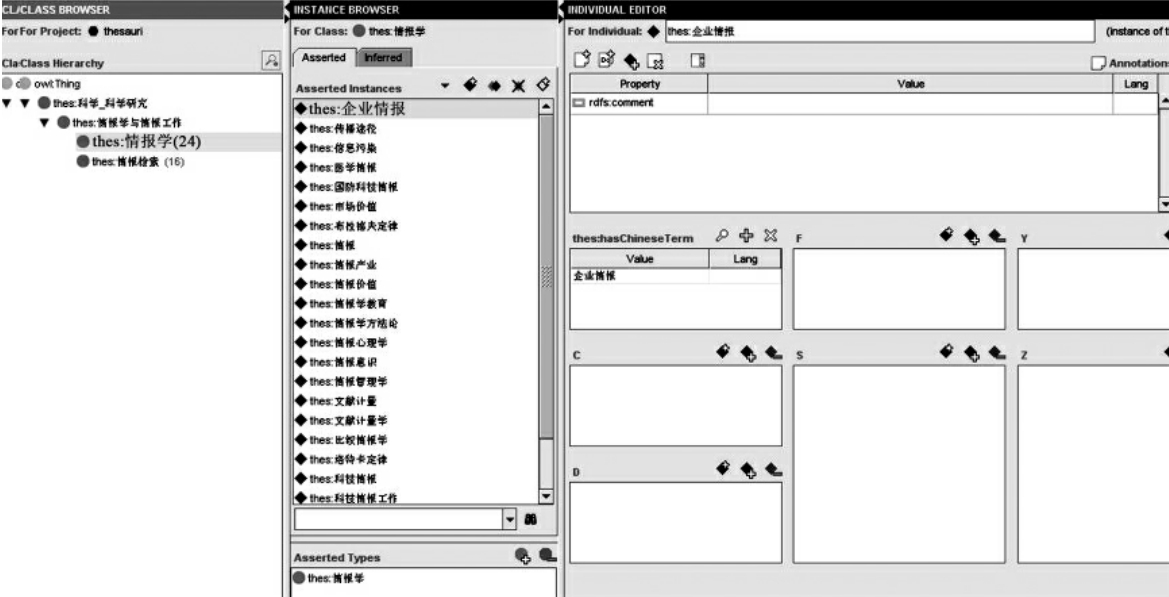
图4-14用Protégé构建的叙词本体结构
4.4.6 多语种叙词本体的评价
利用《中国图书馆分类主题词表》和《管理科学主题词表》构建的情报学叙词本体,有非常好的可扩展性和权威性,也可以很方便地对其进行扩展。接下来的工作是请熟悉该领域的专家对这个叙词本体进行评价,评价内容包括类、属性以及类之间关系的明确性和准确性,提出指导意见,根据所提出的指导意见返回到前面,重新对其进行反复修改,直至最后形成情报学叙词本体原型。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










