



专家检索研究综述[1]
陆 伟1 张晓娟1 姜捷璞2 韩曙光1
(1.武汉大学信息资源研究中心 2.匹兹堡大学信息科学学院图书情报系)
【摘 要】 TREC 2005增加了企业检索任务(Enterprise Track)并设立了专家检索子任务,为专家检索方法和技术的经验性评价提供了平台,着重从专家检索算法、模型和评价方法等几方面进行了探讨,极大地促进了专家检索研究的发展。本文即是在此背景下,对近年来专家检索研究的进展和现状进行的系统总结。论文分别从专家检索的数据集来源、专家检索方法、专家检索的排序方法、专家检索的效果评价四个方面对专家检索的相关研究进行了介绍和评述。
【关键词】 专家 专家专长 专家档案 专家证据 专家检索
Review of Research on Expert Search
Feicheng Ma1 Xiaoyu Li2
(1.Center for the Studies of Information Resources at Wuhan University, 2.School of Information Management at Wuhan University)
【Abstract】 Since TREC 2005 established Enterprise Track and Expert Search sub-task,a common platform has been provided for researchers to empirically assess methods and techniques devised for Expert Search.The algorithms、models、evaluation and other aspects hava been particularly discussed for Expert Search,which has greatly facilitated the development of the Expert Search Field.Based on this context,this paper systematically summarizes the progress and current situation of research on Expert Search.This paper introduces and observes the research related to Expert Search from the four aspects:the source of data sets、Expert Search methods、ranking algorithm and effectiveness evaluation.
【Keywords】 expert expertise expert profile expert evidence expert search
1 引言
进入21世纪,人类社会正在由信息社会迈向知识社会,掌握一定知识、经验和技能的人才将会成为企业和组织最宝贵的资源。各领域的专家是该领域知识的代表,所拥有的丰富且最新的该领域的专业知识、技能和经验是企业生存和发展最关键的因素。目前,一些企业和组织,为了提高自身的竞争优势,已经或者正在建立专家检索系统,利于有效地管理专家资源。
专家检索(亦称为专家查询,专家推荐,专长定位,专长识别[1])作为实体检索的一个特例,它要求返回的实体类型是具有特定专长(与查询主题相关的)的专家。由于专家检索在促进知识共享和交流,构建学术界和产业界的桥梁,知识管理等方面有重要的应用价值,近年来专家检索引起了学术界广泛兴趣。
作为Web track的后继项目,TREC(Text REtrieval Conferences)于2005年增加了企业检索任务(Enterprise Track),并设立了专家检索子任务。该子任务可以描述为:给定文档集,查询主题集和专家列表,并从这些专家列表中为每个查询主题查找相关专家。自设立专家检索子任务后,TREC为专家检索的方法和技术进行经验性评价提供了一个公共平台,近几年来,分别对专家检索算法、模型和评价进行了探讨,促进了专家检索领域的发展。
关于专家检索的任务,Yimam-Seid等[2]界定为以下两个方面:查找具有某专长的专家和查找专家所具有的专长。目前,检索界所探讨的专家检索一般是指前一个方面。本文所探讨的专家检索也是指查找具有某专长的专家,故本文中的专家检索主要任务可以描述为:利用企业或者组织内外能够表征专家专长的各种文档和资源,如电子邮件、报告、数据库文件和网页等,识别专家在某给定查询主题(领域)的专长(相关性)程度,并按程度高低排序显示专家结果列表的过程[3]。
本文组织如下:第二节介绍用于专家检索的数据集来源,第三节介绍专家检索的方法,第四节介绍专家检索排序,第五节介绍专家检索结果的评价,最后第六节对本文工作进行简要总结。
2 专家检索的数据集来源
一般来说,要实现专家检索需要两个必要条件:即专家列表和包含专家专长信息的数据集[4]。其中,数据集来源可以分为以下三类:
(1)传统数据库
专家检索的最初数据来源就是在组织中用一个数据库存储每个候选专家的技能和知识,这些信息都是用户手动添加进去的,其存在以下缺陷:首先,该数据库需要受手动创建和维护,因此费时费力;其次,专家的专长信息是不断更新的,而数据却不易更新[5][6],故数据库的信息往往是陈旧的;最后,利用这些数据库进行专家检索时对查询格式有固定的格式化要求,缺乏灵活性。
(2)企业内部网
从企业的内部公开网站上获得的企业内部网页、企业内部邮件、企业内部文档、简历、个人主页等可以作为专家专长信息的来源。如TREC 2005—2008为专家检索子任务提供了两种数据集,即W3C语料库和CERC语料库,它们都来自于企业内部网站。
①W3C语料库。TREC 2005和TREC 2006使用的专家检索数据集是在2004年6月从W3C(Wide Web Consortium)的公开网站(*.w3c.org)上抓取的,其数据集的详细信息如表1所示:
表1 W3C数据集[7]
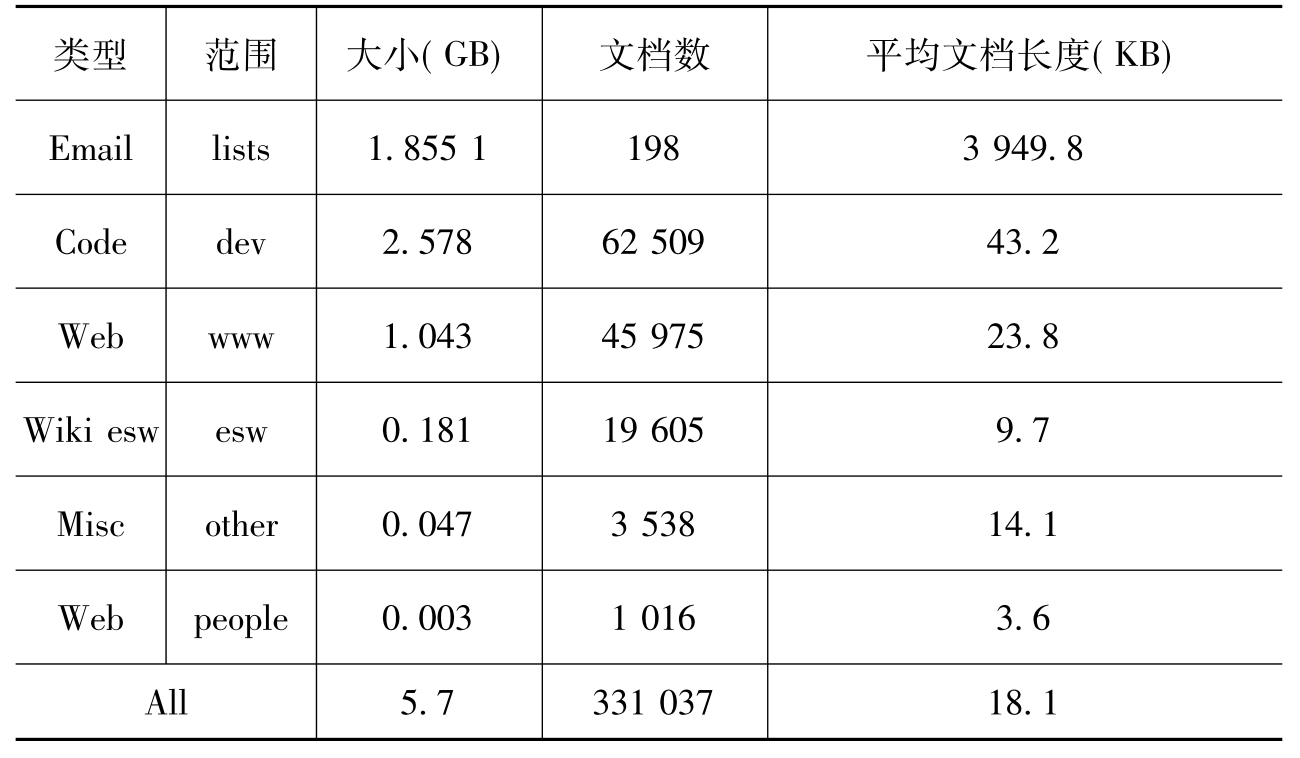
此外,在这两次的专家检索任务中,W3C给参与者提供了包含1 092个候选专家的列表,在候选专家列表中包括了专家的全名和邮件地址。
②CERC语料库。TREC 2007和TREC 2008的CERC(CSIRO Enterprise Research Collection)数据集,是于2007年3月从CSIRO的公开网站(*.csiro.au)上抓取的。该数据集共4.2G,包括了370715个文档,含7900000个超链接,其中95%的网页至少包含一个外链接,且这些外链接包含锚文本[8]。Jiang等[9]指出,CERC中大约89%的文档是网页,4%的文档是pdf、word、rtf、ppt和excel格式的,剩下的文档则是多媒体、xml和log等格式的。CSIRO没有给参与者提供候选专家列表[10],而只是提供了CSIRO员工邮件地址的一个模板:firstname.lastname@csiro.au(如:Ming.Wang@csiro.au),所以参与者需在数据集中识别出专家的特征信息(如姓名与邮件地址)。
(3)外部数据源
W3C语料库和CERC语料库中的数据集都是企业内部网站上抓取的,但基于这样的一个假设,真正的专家不应该只是在企业或者组织内部有名望,其在可查询到的网络空间(如新闻,博客,学术图书馆)中也可能具有一定的声誉[11]。TREC 2008以来,研究者们尝试扩展数据集的来源,即从企业内部网扩展到互联网[12][13]。也就是说在建立专家档案时不但要考虑企业内部网上的专家证据也要考虑外部网站上的专家证据。把这些从企业内部网之外所获得的专家证据来源称为外部数据源。如一些学术数据库,专利网站或者新闻网站等,都是专家证据的很好来源。Jennifer等[14]利用google scholar检索出候选专家的出版物来补充专家档案中候选专家的专长信息;Serdyukov等[15]将整个互联网作为专家证据的来源。Balog等[16]创建了Uvt数据集,该数据集是从荷兰蒂尔堡大学网站抓取的多语种信息,获得了多语种的专家证据。Jiang等[17]利用搜索引擎搜索专家或者专家的相关信息,并将搜索引擎的返回结果作为专家证据的外部数据集。
3 专家检索方法
早在2005年TREC会议设立专家检索任务之前,其他领域的学者们已对专家检索方法进行了探讨,但并未在检索学界得到较多的关注。早在1988年,Streeter等就通过潜语义标引对研究团体的研究成果(文献)建立索引作为团体专长的一种描述,从而实现自动化的专家检索系统[18]。Schwartz等通过电子邮件交互提取出一个专家网络,并通过该网络寻找具有相同兴趣或专长的专家[19]。Krulwich等利用讨论组中专家的交流提出了一种具备专家推荐能力的智能中介来向讨论组中的询问者推荐可解答问题的专家[20]。Pikrakis等[21]和Cohen等[22]分别利用专家访问互联网的日志和专家访问本地文件的日志,结合被访问网页和文档的主题,来实现类似于专家检索的功能。Mattox等[23]通过对MITRE公司内部网络中的文档和专家建立联系,提取专家专长的表示,从而实现专家检索。Liu等提出了一种利用RDF(资源描述框架)描述专长的形式,并利用了高等院校中常见的专长资源(专家主页、学术文献、科技报告)来检索专家[24]。
目前,在专家检索领域仍没有一种通用的方法,通过分析近几年来TREC专家检索任务中采用的方法,本文将近几年来参与者所采用的方法分为以下四类:基于专家档案的方法、基于文档的方法、基于窗口的方法和基于图的方法[25]。
3.1 基于专家档案的专家检索
基于专家档案的专家检索大体思想是:专家的专长可以通过用一些词语来描述,从各种异构的数据集中抽取出描述专家专长的词,构成对候选专家的个人描述文档。图1描述的是基于专家档案法的专家检索流程图,从图1中可知:先从各种数据集合中抽取与专家相关的信息,构建各候选专家的个人描述文档,然后对这些描述文档建立索引,最后根据查询主题对这些文档进行排序,从而可得到候选专家的专长得分。
Craswell等[27]在2001年提出用每个专家所在文档中的词语组合成一个虚拟文档(该文档包含了候选专家的知识),最后利用传统的信息检索方法给这些虚拟文档排序。这种方法可以被归为基于档案的专家检索方法,但该方法将每个文档同等对待,缺乏可行性。Liu等[28]在2005年提出的利用RDF(资源描述框架)构建专家档案的方法也可归为此类。在TREC 2005上,一些参与者就采用了创建专家档案的方法:Macdonald等通过给专家在个人主页、邮件线程、语料库中的出现频次加权来建立专家档案。Fu等[29]提出了一种文档重组方法,该方法能识别各种对候选专家的描述,重组来自不同媒体格式的相关信息,形成候选专家的档案,且证明了建立专家档案能够减少用户查询的空间。Zhu等[30]通过文档集(如该专家所发送的邮件)来表示候选专家,再通过不同信息检索模型(向量空间模型和隐语义模型)来计算文档集与检索主题之间的相似性。Azzopardi等[31]根据每个候选专家的姓名和邮件地址来抽取专家信息,然后依据这些信息给每个候选专家建立档案,其实验结果显示,其检索性能好坏关键取决于识别专家姓名的能力。
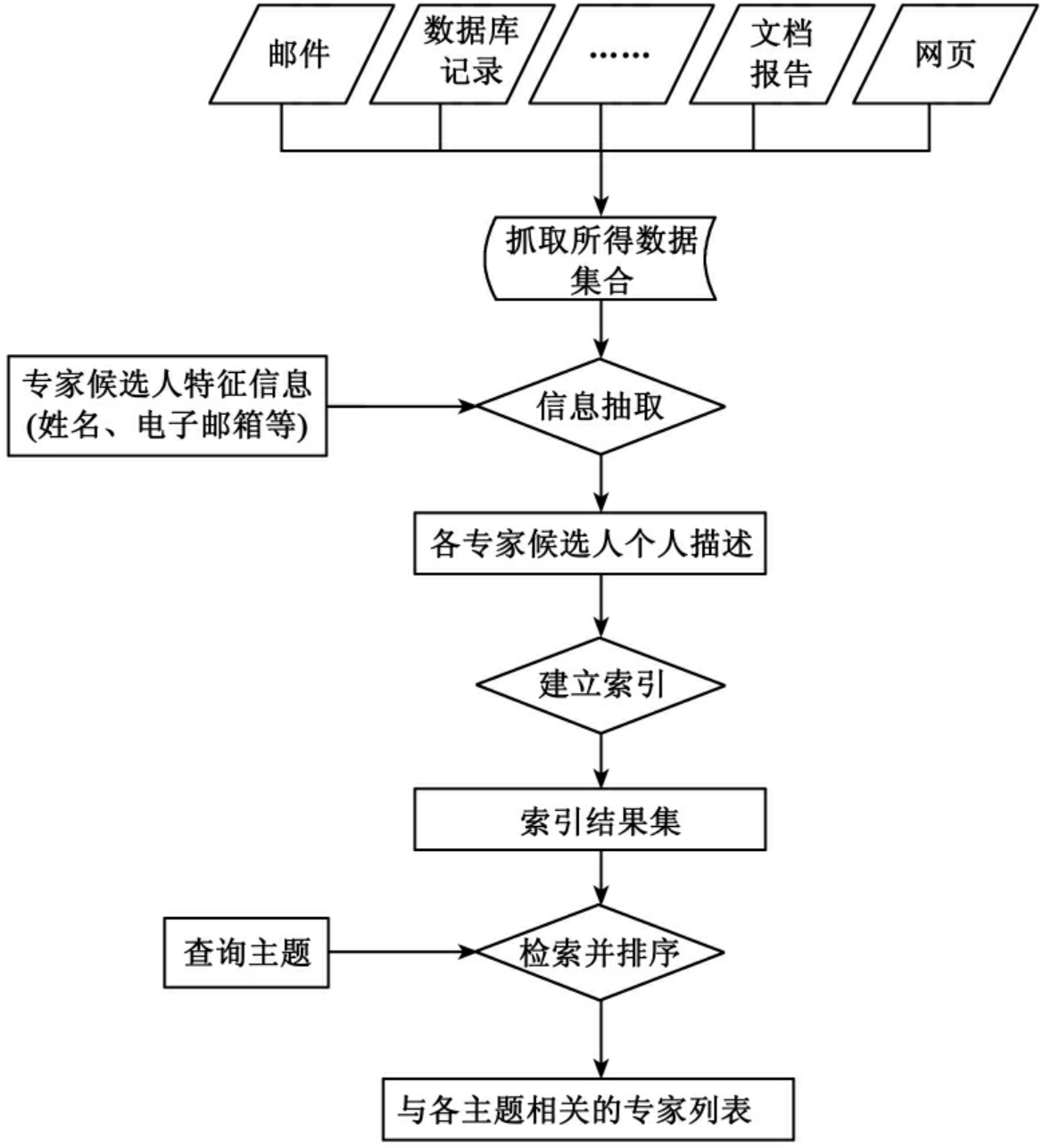
图1 基于专家档案的专家检索流程[26]
2006年,Balog在参加TREC 2006的专家检索任务中,提出了专家语言模型,利用信息检索中的语言模型计算专家档案产生查询的概率,以此来给专家排序。Liu等[32]在基于社区的问答服务中研究了专家检索。并通过构建不同大小的专家档案来进行研究,最后他们得出这样的结论,专家档案中包含的专家证据越多则越能提高检索性能。Petkova和Croft在构建专家档案时,根据文档的格式将其分组,并依据每组中文档对专家档案的贡献给文档加权[33]。Balog和Rijke将专家档案分为两部分,即包括专家所擅长领域的“主题档案”和包括专家合作网络的“社会档案”,且在给每个候选专家建立档案时进行了过滤,当该专家在某个学科领域里是排名靠前的专家时,该学科领域才被包含在该专家的档案中,这就使得在检索时可以返回该领域较有名气的专家,从而减少了冗余度[34],但也使得漏检的概率大大增加。Aleman-Meza[35]提出了在构建专家档案时,结合语义网络词典来对专家的专长、所在机构、联系方式、社会关系和合作网络等信息进行描述,进而能够在一定的语义层次上进行专家检索。
目前对基于专家档案的专家检索方法探讨主要集中在以下两个方面:
(1)专家证据的质量
基于专家档案的专家检索方法大体思想是:专家档案的质量决定了专家检索系统的质量[36][37],而专家档案的质量是由专家证据的质量和专家证据的结合方式来决定的。目前,对基于专家档案的研究主要集中在对专家证据质量的探讨。
专家证据来源于文档,而对专家证据质量的探讨利用了文档质量的一些概念,而文档质量这一概念来源于网络信息检索领域中,故采用了衡量网络文档的一些方法来衡量专家证据的质量。在专家检索中,主要通过文档形式和文档内容来衡量其质量。衡量文档形式的方式如专家证据来源文档或者网页的链接(一般只考虑入链),URL地址长度等。内容上主要是考虑候选专家姓名或者邮件地址与查询主题词之间的距离。对这方面研究具有代表性的是Macdonald,他在文献[38]中,利用投票模型来识别高质量的专家证据,并提出:链接越多的文档专家证据,质量越高;URL越短的网页越有可能是候选专家的个人主页,个人主页上一般都注明了候选专家的个人兴趣爱好,故能提供高质量的专家证据;查询主题与专家姓名共现次数越多的文档,提供的专家证据质量越高,并利用投票模型来计算候选专家姓名和查询主题之间的距离。
(2)查询扩展
基于专家档案的方法实质上是将专家与查询主题之间的关系转换为文档与查询主题之间的关系。为了提高专家检索的准确度,一些研究者已将用于文档检索中的查询扩展运用到了专家检索中[39][40]。即在检索时,将排名靠前的专家档案作为伪相关集,进而利用伪相关集来扩展最初的查询并为查询主题词重新设置权值。
Macdonald和Qunis通过给相关性很大的文档中主题词加权来选择扩展词[41],由于候选专家的档案和支持文档中包括了候选专家其他的与查询主题不相关的专家领域,如果将这个文档作为查询扩展,则其他不相关的专长领域会影响到查询扩展的效果,从而使得最后扩展的查询主题失去了原有意思(即跑题)。Macdonald在文献[42]中提出,将与查询主题相关性很大的文档作为查询扩展集,可以有效避免查询扩展中的跑题(topic drift)。Peng等[43]将检索结果相关性排名前20的文档中出现频次前20的检索主题词作为查询扩展词。
跑题(topic drift)是将查询扩展运用到专家检索不可避免的现象,目前有一些衡量专家档案中跑题发生次数[44]的方法,但还未提出一些衡量跑题(topic drift)是何时与如何发生的方法。总之,查询扩展在专家检索中的成功运用有助于发现相似专家,也有助于在组织中自动创建“专长路线图”。
3.2 基于文档的专家检索方法
该方法基于这样的假设,一个专家出现在与查询主题相关的文档中,则该专家可能是与查询主题相关的专家,且出现的文档与查询主题的相关性越大,则是专家的可能性也就越大。基于文档的专家检索方法就是将候选专家与查询主题之间的关系转化为查询主题与文档之间的关系。目前,研究者认为基于文档权重归并的专家检索方法比基于专家档案的检索方法更有效[46],主要是因为用于估算与候选专家相关度的文本内容比专家档案中文本内容的歧义要少,因此信息的模糊性也较低[47]。
图2是基于文档的专家检索流程图,从图2可知,该方法首先利用一般信息检索模型(如向量空间模型、概率模型、语言模型等)检索出与查询相关的文档,然后根据文档与查询的相关性给文档赋一定的权值,最后通过归并专家的相关文档权值来计算该专家的专长得分,并根据该得分为专家排序。
基于文档的专家检索在研究候选专家与查询主题之间相关性时,主要通过文档来传递这种相关性。目前主要是通过以下两种方式来实现这种相关性传递:
(1)一步相关性传递
一步相关性传递是基于这样的假设:即当用户查询到与主题相关的文档时,则用户就会停止其查询行为。候选专家与文档之间的一步相关性传递就是指当用户从文档集中检索到专家后,其查询行为就会停止,即当相关性从文档传递给候选专家后,则相关性传递就停止了。基于文档权重归并的专家检索方法就是一步相关性传递的,它主要探讨以下几个问题:①支持文档的相关性,即在计算支持文档的权重时,一般是通过各种信息检索模型来计算文档与查询主题相似度。②查询词与候选专家的共现,这里所指查询词与候选专家的共现,主要是指查询主题中的主题词与表示专家的特征信息(如专家的姓名、邮件地址等)文档中的共现情况,如共现频次,共现距离等问题。③专家得分的计算,目前通常利用文档权重的线性归并获得候选专家的得分[48]。
(2)多步相关性传递
一步相关性传递没有考虑到候选专家之间的联系和与候选专家有间接关系的文档。其实,当用户在文档中检索到候选专家后,他并不会停下来,而是通过该专家推荐其他的与查询主题相关的文档来查找这些文档中新的专家,即当文档把相关性传递给候选专家后,相关性传递不会终止,还会通过该专家推荐的文档将相关性传递给其他候选专家。基于此,Serdyukov等[49][50]提出了在大的企业或者内部网络中建立由候选专家,组织文档和它们之间相互联系构成的“专长图”,通过该图来研究候选专家与文档之间的联系。采用该方法能识别出文档中没有直接提到的但与查询主题相关的专家。
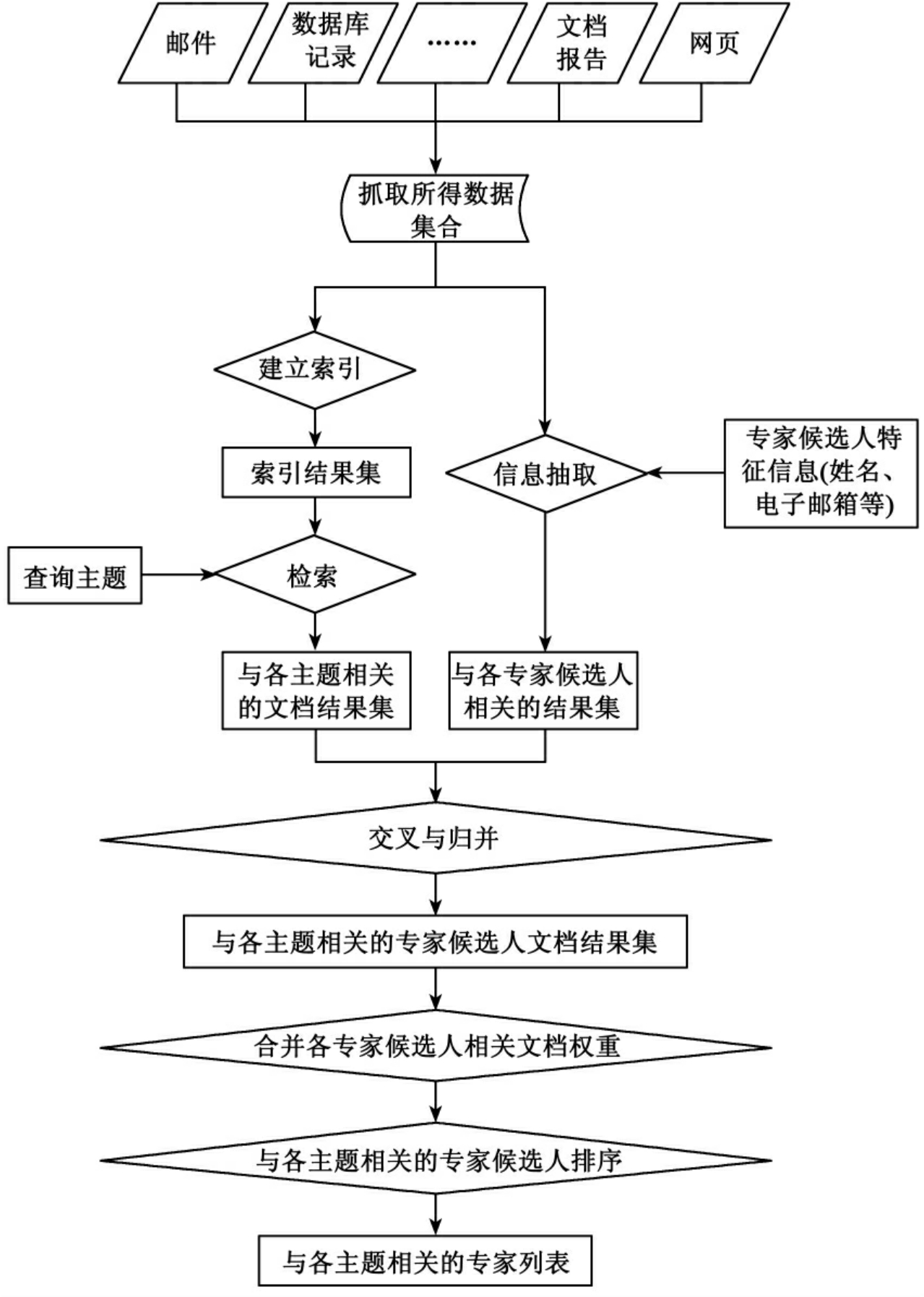
图2 基于文档的专家检索流程[45]
3.3 基于窗口的专家检索方法
目前,一些学者们为了减少与候选专家不是很相关的文档的相关性传递,尝试采用基于窗口的专家检索方法。该方法的主要思想是:出现在专家姓名和邮件地址附近的信息比出现在其他位置的信息与专家更相关。
2005年以前,已有一些学者将该方法有效地运用到文档检索中。Moffat等[51]提出,进行文档检索时,不返回整个文档,而返回只与查询相关文档的部分内容;Conrad等[52]则通过名字等特征信息周围大小固定的窗口来对人进行描述,并进一步查找实体之间的联系;Cao等[53]研究候选专家与查询主题词之间的共现模型时,通过对比基于文档的共现和基于窗口的共现子模型,得出后一个子模型优于前一个子模型,这为后面参与者采用基于窗口的专家检索方法提供了依据。
基于窗口的专家检索主要有两种方法:一种方法,只考虑固定大小的窗口中文本内容,如Lu等[54]在参加TREC 2006会议时,采用窗口来建立候选专家的描述。其基本思想是:利用专家姓名或者邮件地址附近的信息创建专家的档案;在TREC 2008年,Balog和Rijke等通过设置不同大小的窗口扩展了该模型[55]。另一种方法,考虑在与候选专家相关的文档中,查询词和候选专家的相关性与文档中该查询词和表示专家姓名与邮件地址的词之间的词距离存在依存性,并利用距离公式探讨二者之间的这种依存性[56]。
3.4 基于图的专家检索方法
该方法基于这样的假设,即个体之间所发送的信息能够指示他在特定领域的专长。其主要思想是:在图G(v,e)(其中v表示图G中的节点,e表示图G中的边)中候选专家作为节点,专家之间的联系作为边,而这种联系可能是一种问答关系或者是合作关系。可利用社会网络分析专家之间的联系,并进一步识别出专家。
基于图的专家检索方法是基于文档的专家检索的一个子系列[57]。在基于候选专家之间的问答或者合作关系建立的社会网络中,可以有效地识别出某个组织或企业内的相关专家。该方法早期主要是通过候选专家之间电子邮件的交流来分析专家之间的联系[57][58],并通过利用HITS算法计算每个候选专家的得分[60][61]。如McLeanA等[62]提出了利用图的结构在项目小组成员之间传递专家证据,进而识别出专家。Campbel等[63]提出了基于图的查找方法,该方法不但考虑了邮件的内容,还考虑了邮件之间的交流形式,并通过HITS算法来分析邮件撰写者与邮件接收者之间的连接;Amored等[64]对这种邮件交流方法做了一些改进,先用HITS算法识别专家社区,再进一步在专家社区中识别专家;Zhang等[65]利用学术网络来表现候选专家之间的合著关系,并据此识别出潜在的专家及其个人详细信息(如联系方式等)。
目前主要有两种建立图的方式:
(1)基于电子邮件构建图
基于候选专家之间发送和接收邮件来建立图是最普遍的一种方式。该方法的大体思想是:利用候选专家之间的邮件收发情况建立网络图,图中的节点由邮件发送者和接收者构成,他们之间的邮件收发关系作为图中的有向边(即从发送者指向接受者),建立图后,即可采用社会网络中的相关算法评估候选专家的相关度。如Campbell等[66]基于入度用HITS[67]算法为候选专家排序;Zhang等[68]研究了如何从因专业问题讨论发送和接收邮件建立的连接中识别出与查询无关的专家;Balog则试图利用图去查找隐含的专家和专家的详细信息[69];也有学者采用聚类算法,将图分为几个社区,在每个社区中去识别专家[70]。不过Chen等[71]在比较了基于文档的检索方法和基于HITS的专家检索排序方法,发现前者优于后者,不过,两者结合后的效果如何,仍有待更深入的研究。
邮件是体现组织或者企业内人与人之间交流的一种很好方式,也是专家检索研究的一种很好的语料,但是它的内容可能涉及一些个人隐私或者保密的信息[72],因此语料的构建有较大的难度。
(2)基于博客构建图
博客已经成为网上一种流行的信息发布和交流方式,其也被用于组织内或者企业内信息交流的平台,但与邮件不同的是,博客上的信息一般都是可以共享的信息,很少涉及隐私问题,因此用博客构建专家检索语料库比邮件更容易。Kolari等[73]认为博客也可以作为专家证据的来源,他们通过分析IBM内部网络的博客来识别企业内的专家,该方法的大体思想是:根据博客之间的相互评论和博客之间的链接来建立网络图G(v,e)(其中v表示撰写博客的人,e表示的是博主之间的关联),再利用相应的算法计算节点的中心度,识别出专家。
4 专家检索排序方法
目前,仍没有一种通用的专家检索排序方法,通过分析参与者在TREC 2005—2008所采用的排序方法,可以将其排序方法分为基于语言模型的方法和基于非语言模型的方法。
4.1 基于语言模型的排序方法
专家检索问题的实质是:根据用户的查询q,返回与q相关的专家并排序返回给用户。依据查询似然的思想,专家排序可以看作是:用户在检索中提出的查询表达式q是针对某个特定的专家e生成的,而检索系统观察(接受)到用户提出的查询q后,其任务是预测可能生成q的专家并将其根据可能性大小排序返回给用户,即将专家按照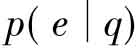 排序,模型如(式1):
排序,模型如(式1):
对于一次确定的专家检索过程而言,查询q对每个专家e都是确定的,因此p(q)与排序无关,则如(式2):
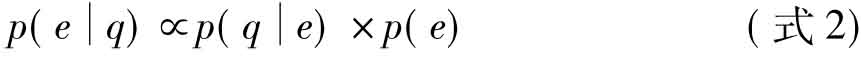
p(e)则是每个专家的先验概率,可用来结合专家权重优先级等因素。在这里,假设p(e)是均匀分布的,即与排序无关。因此,也可以用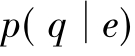 对专家排序,则如(式3):
对专家排序,则如(式3):

在TREC 2005中,Cao等[74]和Azzopardi等[75]介绍了两种用于专家检索任务的语言模型。它们被Balog等[76]解释为候选专家模型(模型1)和文档模型(模型2)。这是目前较常用的专家检索模型框架,它们为基于此的扩展和新方法的产生提供了理论基础。
(1)专家语言模型(模型1)
模型1基于的是Craswell等[77]提出的虚拟文档方法,Fang等[78]将该模型称为基于专家档案的模型,Petkova和Croft则将其称为查询独立法(Query-Independent Approach)[79]。
该模型的主要思路为:根据每个专家e,估算一个专家语言模型,利用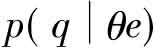 ,计算专家θe产生q的概率,如(式4):
,计算专家θe产生q的概率,如(式4):
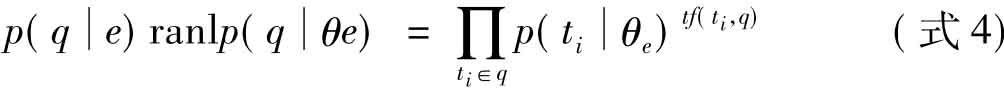
通常情况下,查询q是通过一系列词来表示的,tf(ti,q)表示ti出现在查询q中的词频。该公式假设各个词ti从θe中发生的事件是相互独立的。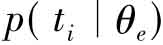 表示的是候选专家e写某种东西的概率。若一个候选专家对某方面谈论得越多,则他(她)越有可能是这方面的专家。给定候选专家e,生成查询q类似于询问该专家是否有可能写了与查询主题相关的东西。关于
表示的是候选专家e写某种东西的概率。若一个候选专家对某方面谈论得越多,则他(她)越有可能是这方面的专家。给定候选专家e,生成查询q类似于询问该专家是否有可能写了与查询主题相关的东西。关于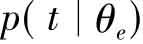 ,可以认为θe是由与专家e主题相关的索引词分布模型和背景语言模型
,可以认为θe是由与专家e主题相关的索引词分布模型和背景语言模型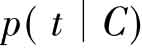 的插值,如(式5):
的插值,如(式5):
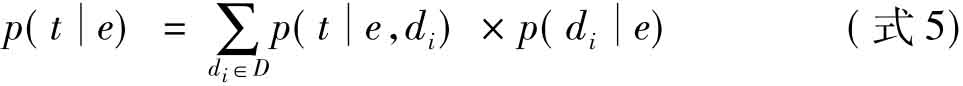
Petkova[80]提出的层次语言模型和Cao等[81]提出的概率方法没有考虑文档级的专家证据,而是基于窗口研究专家证据。Petkova和Croft介绍了一种新的文档表示方法,该方法强调了与实体邻近的文本内容,并给文档中的命名实体和查询词之间的依存建模,提出了一种基于位置信息的、以候选专家为中心的文档表示方法,该方法类似于基于窗口的模型[82]。Balog等[83]对此进行了扩展,并试图从万维网中获得专家证据。
(2)文档语言模型(模型2)
该模型假定候选专家与查询之间是相互独立的。该模型将查询的生成过程看成如下两个步骤:选择与候选专家e相关的文档di;在di中,用户针对文档中专家的相关信息提出查询q。于是查询q的生成过程被划分到各个文档di中去,如(式6):
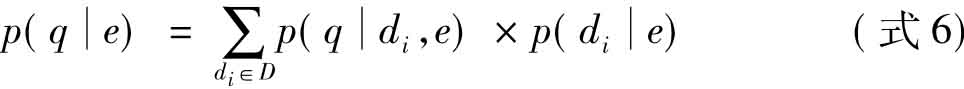
该思想可以表达为:查询q是针对每个文档di生成的。在该模型中,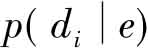 的计算与模型1是相同的。而
的计算与模型1是相同的。而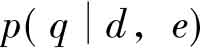 的计算可以简化为
的计算可以简化为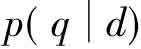 ,相对于模型1,模型2|的优点在于可以对查询词之间的依存进行建模,而模型1由于首先引入索引词之间的独立假设,因此无法对索引词之间的依存性进行考察。而模型2保留了完整的查询q和每个文档di,从而可以利用各种文本检索中考察查询索引词依存的方法。
,相对于模型1,模型2|的优点在于可以对查询词之间的依存进行建模,而模型1由于首先引入索引词之间的独立假设,因此无法对索引词之间的依存性进行考察。而模型2保留了完整的查询q和每个文档di,从而可以利用各种文本检索中考察查询索引词依存的方法。
Balog等[84]的实验表明模型1优于模型2,然而目前大多数的专家检索模型仍沿用了模型2的框架。Petkova和Croft对该框架进行了另外的扩充,它们采用了伪相关反馈(即查询扩展),对查询主题进行建模,用于排序文档和候选专家[85];Fang等[86]不是从文档级别而是从段落或者文档片段来考虑文档与候选专家之间的关系;Zhu等[87]利用该模型时,考虑了文档级别和文档的内部结构;Macdonald等[88]和Petkova等[89]提出了一种计算检索词与候选专家之间依存性的方法;Petkova等[90]详述了候选专家—文档之间的关系;Serdyukov等[91]研究了专家检索中相关性传递;Fang等[92]也提出了一个类似的基本框架,把相关性模型运用到专家检索中,利用语言模型直接对专家检索的相关性问题进行建模,并使用概率排序原则进行排序。上述特点使得Fang等人的框架在立意上高于Balog等人,但具体到实现方法上仍然采用了类似模型2的手段。
综合分析模型1和模型2,以及分别建立在模型1和模型2基础上的其他模型,都考虑到了候选专家和文档之间的联系,目前,也有学者将模型1和模型2结合起来,如Serdyukov等提出了将专家语言模型和文档语言模型结合起来的person-centric方法。
4.2 其他模型
(1)CDD(Candidate Description Document)模型
该模型借鉴了概率模型的思想,对每个文档中专家共现文档片段的相关性进行加权,并将片段归并为专家档案。在各种异构数据集中抽取对候选专家的描述并形成候选专家的描述文档(CDD),因此给定查询,候选专家是专家的概率可以定义为专家的描述文档与查询的匹配概率,如(式7):
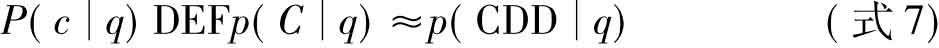
其中,c表示的是候选专家,C表示的是候选专家c的理想描述文档。在该模型中找到了三个决定CDD与查询主题相关性的三个启发式方法:
①专长强度(EI):候选专家所拥有的与查询主题相关的知识总量。
②专长区分(ED):候选专家所拥有的专长能将该专家与其他专家区分开来的程度。
③有效专长比(EEP):与查询主题有关的知识与候选专家所拥有的所有知识之比。
利用上述三个指标,计算权值,并根据权值的大小给每个候选专家描述文档进行排序,如(式8):
W=EI×ED×EEP (式8)
Fu等采用该模型取得了良好的检索效果,但是由于他们在实验中还采用了其他的辅助方法,故无法对CDD模型和基于语言模型方法的专家检索效果进行客观的评价与比较。
(2)投票模型
Macdonald等[93]提出了一种基于文档模型的投票算法,该算法把专家检索看成是一个投票过程,当检索出一个与查询主题相关,且与候选专家相关的文档时,则认为该文档为该专家进行投票,最后依据每个候选专家所得票数之和进行排序。在文献[94]中将12种投票方法运用到了专家排序中,实验结果显示,expCombMNZ是最好的投票方法,如(式9):
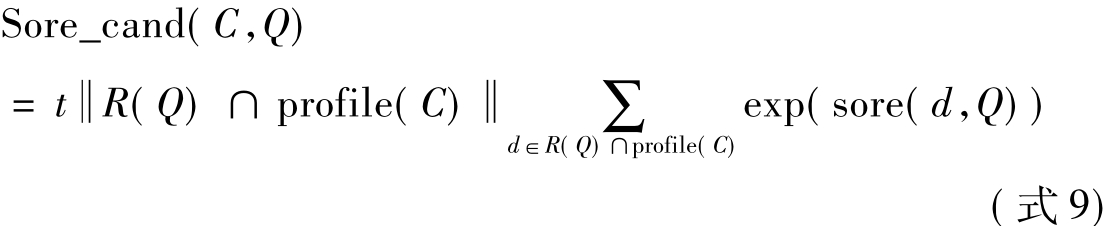
R(Q)表示的是与查询Q相关且排序后的文档集,Score_cand(C,Q)表示的是给定查询Q,候选专家C的相关性分数。profile(C)表示含有候选专家C的文档集,Score(d,Q)表示候选专家在文档集R(Q)中的相关性分数。||R(Q)∩profile(C)||表示同时存在于候选专家档案和R(Q)中的文档数。该模型类似于Balog等[95]提出的模型2。目前研究结果表明,基于语言模型的专家检索在效果上优于投票模型。
5 专家检索效果的评价
专家检索的评价比文档检索效果的评价要困难,主要是因为在文档检索中,评论者能够通过阅读文档来判断文档与查询之间的相似性。但专家检索返回的只是一些专家名,无法直接通过这些专家名判断其与查询主题的相关性。
5.1 专家检索的三种评价方法
目前主要采取如下三种方法评价专家与查询主题的相关性:
(1)原有实况(Pre-Existing Ground Truth):该方法基于事实评价专家和查询主题的相关性。如在TREC 2005的专家检索任务中,查询主题就是W3C工作组的名字,要求参与系统能够预测每个工作组的成员。该方法的评价依赖于候选专家已知的分组情况,当系统采用了非工作组名的其他词汇构成查询时,则不能用该方法进行评价。
(2)支持文档证据(Supporting Evidence):这是TREC 2006专家检索任务中提出的一种方法。该方法要求每个参与系统返回一些与候选专家专长相关且排序的一些支持文档。通过判断支持文档与查询主题之间的相关性来评价该参与系统的性能。相关性评价分为以下两步:首先,要求参与评估的人在做出评论之前,阅读检索系统给每个候选专家返回的支持文档,评估者依据该支持文档与查询主题之间的相关性给该文档加上标志,最后综合分析每个评估者对每个候选专家支持文档的评价情况,获得该专家检索系统的检索准确度。
(3)候选专家问卷调查:询问数据集中每个候选专家是否拥有与查询主题相关的专长。该方法不适合数据集中有大量候选专家的情况,且评估者也不可能了解每个候选专家的兴趣。TREC 2007的专家检索任务就是通过运用该方法的一种衍生方法在中小型企业环境中进行评价。
5.2 评价指标
类似于传统的文档检索系统,可以通过采用传统检索评价指标如准确率和召回率及其扩展来评价专家检索系统的准确性。TREC专家检索采用的就是传统的TREC评价指标,如MAP、R-Precision、P@k等,关于这些指标,本文不再赘述。
6 结束语
本文详细介绍了专家检索的数据集来源、专家检索方法、专家检索模型及评价方法。从上文可以看出,经过多年的努力,专家检索研究取得了很大进展。TREC始于2005年的专家检索任务经过四年的成功召开,于2008年终止。然而,这并不意味着专家检索研究的终结,实际上TREC 2009的实体检索任务(Entity Search track)就可以被认为是专家检索任务的一种延续,它通过以下两个方面对专家检索进行了扩展:①检索的类型从人扩展到各种实体;②数据集的来源从企业内部网扩展到互联网。目前,学者们正在研究如何将专家检索的方法和模型运用到实体检索中。此外,在多源异构数据集的使用与整合、语义分类词表及本体的引入、社会网络对专家专长的影响、专家专长的演化等方面,仍有待于进一步的深入研究。
【注释】
[1][10][26]Serdyukov,P..Search for Expertise Going Beyond Direct Evidence[R].2009.
[2]Yimam-Seid,D.,Kobsa,A..Expert Finding Systems for Organizations:Problem and Domain Analysis and the DEMOIR Approach[J].Journal of Organizational Computing and Electronic Commerce,2003,13(1):1-24.
[3]陆伟,赵浩镇.基于文档权重归并法的企业专家检索[J].现代图书情报技术,2008(7):38-42.
[4][88]Macdonald,C.,Ounis,I..Voting Techniques for Expert Search[J].Springer,2008,16(3):259-280.
[5]Davenport,TH,Prusak,L..Working Knowledge:How Organizations Manage What They Know[J].Harvard Business School Press,Boston,MA,1998.
[6]Maron,ME,Curry,S.,Thompson,P..An Inductive Search System:Theory,Design and Implementation[J].IEEE Transaction on Systems,Man and Cybernetics,1986,16(1):21-28.
[7][8][12]Balog,K.,Soboro,I.,Thomas,P.,Craswell,N..Overview of the TREC 2008 Enterprise Track[R].
[9][48]Jiepu,J.,Wei,L.,Dan,L..CSIR at TREC 2007 Expert Search Task[C].Proceedings of the 16th Text Retrieval Conference,2007.
[11][13][15]Serdyukov,P.,Robin,A.,Hiemstra,D..University of Twente at the TREC 2008 Enterprise Track:Using the Global Web as an Expertise Evidence Source[C].Proceedings of the 2008 Text REtrieval Conference(TREC 2008),Gaithersburg,MD,2008.
[14]Chu-Carroll,J.,Averboch,G.,Duboue,P.,Gondek,D.,Murdock,JM.,Prager,J.,Hoffmann,J.,Wiebe,J..IBM in TREC 2006 Enterprise Tack[C].Proceedings of the 15th Text Retrieval Conference,2006.
[16]Balog,K.,Bogers,T.,Azzopardi,L.,de Rijke,M.,van den,Bosch,A..Broad Expertise Retrieval in Sparse Data Environments[C].Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Informaion Retrieval,Amsterdam,Netherlands,2007:551-558.
[17]Jiang,J.,S.H.,Lu,W..Expertise Retrieval Using Search Engine Results[C].Proceedings of the 16th Text Retrieval Conference,2008.
[18]Streeter,LA.,Lochbaum,KE..An Expert/expert Locating System Based on Automatic Representation of Semantic Structure[C].Proceedings of the 4th IEEE Conference on Artificial Intelligence Applications,San Diego,California,USA,1988:345-349.
[19]Schwartz,MF.,Wood DCM.Discovering Shared Interests Using Graph Analysis[J].Communications of the ACM,1993,36(8):78-89.
[20]Krulwich,B.,Burkey,C..The Contact Finder Agent:Answering Bulletin Board Questions with Referrals[C].Proceedings of the 13th National Conference on Artificial Intelligence(AAAI'96),Portland,Oregon,1996:10-15.
[21]Pikrakis,A.,Bitsikas,T.,Sfakianakis,S.,Hatzopoulos,M.,De Roure,DC.,Hall,W.,Reich,S.,Hill,GJ.,Stairmand,M..Memoir-software Agents for Finding Similar Users by Trails[C].Proceedings of the 3rd International Conference on the Practical Applications of Intelligent Agents and Multi-Agent Technology(PAAM'98),London,UK,1998:453-466.
[22]Cohen,AL.,Maglio,PP.,Barrett,R..The Expertise Browser:How to Leverage Distributed Organizational Knowledge[C].Proceedings of the Workshop on Collaborative and Cooperative Information Seeking in Digital Information Environments,Conference on Computer-Supported Cooperative Work,Seattle,USA,1998.
[23]Mattox,D.,Maybury,M.,Morey,D..Enterprise Expert and Knowledge Discovery[C].Proceedings of the 8th International Conference on Human-Computer Interaction(HCI'99),Munich,Germany,1999:303-307.
[24][28]Liu,P.,Curson,J.,Dew,P..Use of RDF for Expertise Matching within Academia[J].Knowledge and Information Systems,2005,8(1):103-130.
[26][45]陆伟,韩曙光.组织专家系统的设计与实现[J].情报学报,2008(5).
[27][77]Craswell,N.,Hawking,D.,Vercoustre,A-M.,et al..P@ noptic Expert:Searching for Experts not Just for Documents[C].Ausweb Poster Proceedings,Queensland,Australia,2001.
[29]Fu,Y.,Yu,W.,Li,Y.,Liu,Y.,Zhang,M.,Ma,S..THUIR at TREC 2005:Enterprise Track[C].Proceedings of the 14th Text REtrieval Conference(TREC 2005),Gaithersburg,MD,USA,2005.
[30]Zhu,W.,Song,M.,Allen,RB..TREC 2005 Enterprise Track Results from Drexel[C].Proceedings of the 14th Text REtrieval Conference(TREC 2005),Gaithersburg,MD,USA,2005.
[31][75]Azzopardi,L.,Balog,K.,de Rijke,M..Language Modeling Approaches for Enterprise Tasks[C].Proceedings of the 14th Text REtrieval Conference(TREC 2005),2005.
[32]Liu,X.,Croft,WB.,Koll,M..Finding Experts in Communitybased Question-answering Services[C].Schek,H-J.,Fuhr,N.,Chowdhury,A.eds..Proceedings of ACM CIKM 2005,ACM Press,Bremen,2005:315-316.
[33][39][79][80][85]Petkova,D.,Croft,WB..Hierarchical Language Models for Expert Finding in Enterprise Corpora[J].International Journal of Artificial Intelligence Tools,2008,17(1).
[34]Balog,K.,de Rijke,M..Determining Expert Profiles(With an Application to Expert Finding)[J].2007.
[35]Aleman-Meza,B.,Bojars,U.,Boley,H.,Breslin,JG.,Mochol,M.,et al..Combining RDF Vocabularies for Expert Finding[J].Springer,2007:235-250.
[36]Balog,K.,de Rijke,M..Finding Experts and Their Details in E-mail Corpora[C].Proceedings of the 15th International Conference on World Wide Web,2006:1035-1036.
[37][89][93][94]Macdonald,C.,Ounis,I..Voting for Candidates:The Voting Model for Expert Search[C].Proceedings of the 15th ACM International Conference on Information and Knowledge Management,2006:387-396.
[38]Macdonald,C.,Hannah,D.,Ounis,I..High Quality Expertise Evidence for Expert Search[J].Springer,2008:283-295.
[40][41][42][44]Macdonald,C.,Ounis,I..Expertise Drift and Query Expansion in Expert Search[C].Proceedings of the 16th ACM Conference on Conference on Information and Knowledge Managemen,Lisboa,Portugal.,2007:341-350.
[43]Peng,Y.,Mao,M..Blind Relevance Feedback with Wikipedia:Enterprise Track[C].Proceedings of the 17th Text REtrieval Conference(TREC 2008).
[46][84]Balog,K.,Azzopardi,L.,de Rijke,M..Formal Models for Rxpert Finding in Enterprise Corpora[C].SIGIR 2006:Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,2006:43-50.
[47][59]Serdyukov,P.,Hiemstra,D..Modeling Documents as Mixtures of Persons for Expert Finding[J].Springer,2008:309-320.
[49]Serdyukov,P.,Rode,H.,Hiemstra,D..Modeling Multi-step Relevance Propagation for Expert Finding[C].Proceeding of the 17th ACM Conference on Information and Knowledge Management,2008:1133-1142.
[50]Serdyukov,P.,Rode,H.,Hiemstra,D..Modeling Expert Finding as an Absorbing Random Walk[C].Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,2008:797-798.
[51][54]Lu,W.,Robertson,S.,Macfarlane,A.,Zhao,H..Windowbased Enterprise Expert Search[C].Proceedings of the 15th Text REtrieval Conference(TREC 2006),2006.
[52]Conrad,JG.,Utt,MH..A System for Discovering Relationships by Feature Extraction From Text Databases[C].Proceedings of the ACM Conference on Research and Development in Information Retrieval(SIGIR),1994:260-270.
[53][74][81]Cao,Y.,Liu,J.,Bao,S.,Li,H..Research on Expert Search at Enterprise Track of TREC 2005[C].Proceedings of the 14th Text REtrieval Conference(TREC 2005),2005.
[55]Balog,K.,de Rijke,M..Combining Candidate and Document Models for Expert Search[C].Proceedings of the 2008 Text Retrieval Conference(TREC 2008),Gaithersburg,MD,2008.
[56][82][90]Petkova,D.,Croft,WB..Proximity-Based Document Representation for Named Entity Retrieval[C].Proceedings of the 16th ACM Conference on Conference on Information and Knowledge Management(CIKM'07),Lisbon,Portugal,2007:731-740.
[57]Maybury,M.,D'Amore,R.,House,D..Expert Finding for Collaborative Virtual Environments[J].Communication of the ACM,2001:55-56.
[58]Sihn,W.,Heeren,F..Xpertfinder—expert Finding within Specified Subject Areas through Analysis of E-mail Communication[C].Proceedings of Euromedia 2001:279-283.
[60]Campbell,CS.,Maglio,PP.,Cozzi,A.,et al..Expertise Identification Using Email Communications[C].Proceedings of ACM CIKM 2003.ACM Press,New Orleans,2003:528-531.
[61]Wang,J.,Chen,Z.,Tao,L.,Ma,WY.,Wenyin,L..Ranking User's Relevance to a Topic through Link Analysis on Web Logs[C].Proceedings of WIDM 2002 Workshop,McLean,VA,2002:49-54.
[62]McLean,A.,Vercoustre,AM.,Wu,M..Enterprise People Finder:Combining Evidence from Web Pages and Corporate Data[C]//Hawking,D.,Bruza,P.,Thom,J.eds.Proceedings of the 8th Australasian Document Computing Symposium(ADCS'03),2003.
[63][66]Campbell,CS.,Maglio,P.P.,Cozzi,A.,Dom,B..Expertise Identification Using Email Communications[C].CIKM 2003:Proceedings of the Twelfth International Conference on Information and Knowledge Management,2003:528-531.
[64]D'Amore,R..Expertise Community Detection[C].SIGIR'04:Proceedings of the 27th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,2004:498-499.
[65]Zhang,J.,Tang,J.,Li,J..Expert Finding in a Social Network [J].Springer,2007:1066-1069.
[67]Hiemstra,D.,de Jong FMG.Statistical Language Models and Information Retrieval[J].Natural Language Processing Really Meets Retrieval.Glot International,2001,5(8):288-293.
[68]Zhang,J.,Ackerman,MS.,Adamic,L..Expertise Networks in Online Communities:Structure and Algorithms[C].WWW 2007:Proceedings of the 16th International Conference on World Wide Web,2007:221-230.
[69]Balog,K.,de Rijke,M..Finding Experts and Their Details in E-mail Corpora[C].The Proceedings of the 15th International Conference on World Wide Web,2006.
[70][71]Xiong,J.,Tan,S.,Chen,H.,Shen,H.,Cheng,X..Social Network Structure Behind the Mailing Lists:ICT-IIIS at TREC 2006 Expert Finding Track[C].Proceedings of the 15th Text REtrieval Conference(TREC 2006),2006.
[72][73]Kolari,P.,Finin,T.,Kelly,L.,Yesha,Y..Expert Search Using Internal Corporate Blogs[C].Future Challenges in Expertise Retrieval.SIGIR 2008 Workshop,July 24,Singapore,2008.
[76][95]Balog,K.,Azzopardi,L.,de Rijke,M..Formal Models for Expert Finding in Enterprise Cor-Pora[C].Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval(SIGIR'06),Seattle,Washington,USA,2006:43-50.
[78][86][92]Fang,H.,Zhai,C..Probabilistic Models for Expert Finding[C].Proceedings of the 29th Annual European Conference on Information Retrieval Research(ECIR'07),Rome,Italy,2007:418-430.
[83]Balog,K.,de Rijke,M..Non-Local Evidence for Expert Finding[C].Proceedings of the 17th ACM Conference on Conference on Information and Knowledge Management,Napa Valley,California,USA,2008:731-740.
[87]Zhu,J.,Song,D.,Rüger,S.,Eisenstadt,M.,Motta,E..The Open University at TREC 2006 Enterprise Track Expert Search Task[C].Proceedings of the 16th Text Retrieval Conference(TREC 2006),2006.
[91]Serdyukov,P.,Rode,H.,Hiemstra,D..Modeling Multistep Relevance Propagation for Expert Finding[C].Proceedings of 17th ACM Conference on Information and Knowledge Management(CIKM'08),Napa Valley,California,USA,2008:1133-1142.
【作者简介】

陆伟,男,1974年生,教授,博士生导师,研究方向:信息检索、数据挖掘和知识管理,近年先后在国内外发表论文50余篇,其中SSCI/SCI索引论文5篇。
张晓娟,女,2009级情报学在读硕士研究生,研究方向:信息检索。
姜捷璞,男,1986年生,匹兹堡大学在读博士生,研究方向:信息检索,已发表论文7篇。
韩曙光,男,1987年生,硕士研究生,研究方向:信息检索,已发表论文6篇。
【注释】
[1]本文为教育部人文社会科学规划项目“专家专长智能识别与检索系统实现研究”(项目编号:09yja870021)成果之一。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。












