



实体检索研究综述(1)
陆 伟1 张晓娟1 姜捷璞 2鞠 源1
(1.武汉大学信息资源研究中心;2.匹兹堡大学信息科学学院)
【摘 要】自INEX 2007设立XML Entity Ranking(INEXXER)任务以来,学术界对实体检索的探讨逐步由特定类型的实体上升到通用实体。其中,INEX 2007—2008设立的XER和TREC 2009设立的实体任务,分别为通用实体检索的方法和模型提供了经验性评价平台,促进了实体检索研究的发展。本文也将以这两大任务为主要线索,对实体检索研究的现状和进展进行系统的总结。论文分别从特定类型的实体检索研究、INEX中的实体检索任务、TREC中的实体检索任务、实体检索模型这四个方面对实体检索的相关研究进行了总结和评述。
【关键词】实体 实体检索 维基百科 INEX TREC
Review of Research on Entity Retrieval
Lu Wei1 Zhang Xiaojuan1 Jiang Jipu2 Ju Yuan1
(1.Center for Studies of Information Resources,Wuhan University; 2.School of Information Sciences,University of Pittsburgh)
【Abstract】Since INEX 2007 established XML Entity Rankingtrack(INEX-XER),the focus of research on Entity Retrieval has gradually been raised to the level of general entity from the level of special type of entity.Two common platforms have been provided for researchers to empirically assess methods and techniques devised for general entity retrieval by XER on INEX 2007—2008 and Entity Track on TREC 2009 respectively,which facilitated the development of the general Entity Retrieval.This paper systematically summarizes the progress and current situation of research on Entity Retrieval based on the two tracks.The paper introduces and observes the research related to Entity Retrieval from the following four aspects:the research on the retrieval of specific types of entity,Entity Track established by INEX,Entity Track established by TREC and Entity Retrieval model.
【Keywords】entity entity retrieval wikipedia INEX TREC
1 引言
传统的信息检索是基于文档级别的,即根据用户的查询返回与查询相关的文档。而Brode等[1]的研究表明,用户从搜索引擎中检索文档的目的往往是从文档中得到更为具体的信息,而不是文档本身。作为一种信息组织的单元,文档的粒度过大,而用户的信息需求是精细的,其感兴趣的可能是某实体,也就是说,实体作为一种广泛存在事物的统称,如人名、地名、组织名或者产品名等,可能是用户的检索目标。
实体检索(Entity Retrieval,Entity Search、Entity Finding或ObjectRetrieval,本文统称为实体检索),即根据用户的查询表达式在信息源中检索出相关类型的实体(人物、机构、地名、产品等)或实体属性。该问题是目前检索界探讨的热点话题,也是目前信息检索国际会议TREC、INEX等关注的焦点之一。
以2007年INEX(The Initiative for Evaluation of XML Retrieval)设立XML Entity Ranking(INEX-XER)任务作为时间分界,在此之前,研究者对实体检索的研究主要局限在特定类型的实体,如时刻检索[2]和TREC 2005设立的专家检索等;而在此后,学界对实体检索的探讨逐渐上升到通用实体的高度。
INEX XER基于维基百科数据集探讨了实体检索问题,并将其任务分为实体排序(EntityRanking)和列表补全(ListCompletion)两个子任务。TREC(TextREtrieval Conferences)于2009年设立实体任务(Entity Track),这是TREC 2008收尾的专家检索子任务的一种继续,其将实体的类型由人扩展到各种类型的实体,且在互联网中查找相关实体,并将实体关系引入对实体检索问题的探讨中。这两个会议针对实体检索问题分别为参与者提供了不同的查询和数据集,并对参与者返回的实验结果进行评测,促进了实体检索研究的发展。
本文探讨的是通用实体的检索问题。文章组织如下,先介绍特定类型的实体检索研究,再介绍INEX中的实体检索任务,接着介绍TREC中的实体检索任务,然后介绍实体检索模型,最后进行总结。
2 特定类型的实体检索研究
在20世纪90年代之前,信息检索领域主要探讨的是基于文档级别的检索,而在90年代中后期,人们对信息检索的兴趣已不再停留在文档级别。如TREC 1999设立问答系统(QA)任务,即通过分析用户提问,查找与之匹配的答案。其返回的可能是该问题的精确答案或者包含该答案的片段,而其精确答案可能就是相应的实体名。TREC 2003将问答系统的主要问题分为事实问题(Fact Question),列举问题(List Question)和定义问题(Definition Question),其中事实问题和列举问题分别关注的是这样的问题:“谁是美国现任总统”和“列举武汉地区的985高校”,对类似这样问题的回答采用了基于自然语言处理工具的实体排序方法[3],这可看作是实体检索中的特定例子。
另外,在早期,一些学者将实体表示为<属性,值>,并从数据库的角度探讨了实体检索的问题。如在2004年,Fang等[4]基于结构化数据,对实体检索进行了研究。同年,Sayyadian等[5]在结构化文本数据上对实体检索进行了研究,即结合关系数据库和文本检索两个领域来探讨实体检索问题。2005年,Nie等[6]探讨了一种基于对象级别来进行网络检索的新范式,即通过构建网络对象(如产品、组织、人、文章)图来给对象进行排序。基于前期的研究,Nie等[7][8]于2007年建立了面向对象的Libra学术检索系统[9]和Windows Live产品查询系统[10]。Libra能根据用户查询返回相关的对象(实体)如会议、论文或者作者。Windows Live产品查询系统能根据查询产品返回对象(实体)如该产品的出售商或者制造商。这两个系统分别实现了特定领域特定类型的实体检索。在2007年设立INEX XER之前,也曾有冠名为“实体检索”的文章。如Hu等[11]以专家检索和时间检索为例,探讨了一种基于监督式学习的实体排序方法。Petkova等[12]以专家检索为例来为文档中命名实体和查询词之间的依存性进行建模。Rode等[13][14][15]以专家检索为例采用基于图的相关性传递法对专家实体排序。但这些文章探讨的内容基本上还是特定类型的实体,并没有扩展到通用实体的高度。
专家检索是学术界探讨得最多的特定类型实体检索问题。专家检索是实体检索的一种特例,它要求返回的实体类型是具有特定专长的专家。在TREC 2005设立专家检索任务之前,虽已有对专家检索的探讨[16][17][18][19][20][21],但没引起检索界更多的关注。2005年TREC在企业任务中增设了专家检索子任务,其任务可以描述为:给定文档集,查询主题集和专家列表,并从这些专家列表中为每个查询主题查找相关专家。TREC 2005设立专家检索子任务后,为专家检索的技术和方法提供了一个经验性评价平台,吸引了来自国际数十个研究团体的关注和参与。近几年来,分别对专家检索算法、模型和评价进行了探讨,促进了专家检索领域的发展。专家检索的模型和方法为实体检索提供了良好的基础,如[22][23][24]利用专家检索中的语言模型来对维基百科中的实体进行排序,Santos等[25]将专家检索中的投票算法运用到了实体检索中。
3 INEX中的实体检索任务
2007年,INEX设立了XML Entity Ranking Track(INEX XER)任务[26],任务的主要目的是利用XML格式的维基百科文档为实体检索提供测试数据集,并要求参与者根据查询主题(见图1)返回与之相关的实体而非文档。该任务的目标是使通用实体检索的评价过程标准化,其基于这样的假设,实体相当于维基百科条目,即将实体的维基百科条目视为对实体的描述。INEX XER 2007—2008为参与者提供的数据集是经XML标签标注的维基百科网页[27]。基于维基百科数据集来探讨实体检索问题可以得到如下启示:①可以通过对实体对应的维基百科条目排序来获得对实体的排序;②维基百科中的锚文本可视为实体,可不借用命名实体识别工具就能获得文本中的命名实体;③维基百科自身的结构特点(如类目结构和链接结构)可以为实体排序、实体关系抽取、实体消歧提供一定的依据。
INEX为实体检索提供了相应的查询主题。如表1表示的是翻译后的INEX 2007实体排序中的一个查询,其中<title>字段中包含了查询词,<description>字段中包含了基于自然语言描述的用户信息需求,<narrative>字段对相关的实体答案做了详细的解释,<entities>字段中提供了与查询主题相关的实体,<categories>字段中提供了待查找实体的类别。该查询主题可以用于INEX-XER的两个子任务中。根据对查询中<categories>和<entities>两个字段的不同选择,如前所述,INEX的实体检索任务分为实体排序和列表补全。在实体排序任务的查询中有<categories>字段没有<entities>字段,而后者则反之。
表1 INEX 2007实体排序查询主题例子

3.1 实体排序任务
在实体排序中,其查询可以表示为<query,category>(query表示的是用自然语言描述的用户信息需求,Category表示的是目标实体所属类别)二元组,即给定查询主题和目标实体类别,查找出与查询主题相关且属于给定实体类别的实体。如“国家”作为实体类别,查询主题为“能够支付欧元的欧洲国家”,则需返回的实体为:德国、法国等。该任务中指明了实体类别,其意义在于不需像问答系统一样,首先还需对问题进行分析,识别出该问题的类型(即需要返回的答案类型)。相对未给定实体类别的查询来说,返回的是特定类型的实体,这样可以减少返回的实体数目,使其查找更加精确。
而该任务中需关注的两大问题是:如何利用维基百科对实体进行排序;如何计算实体类别之间的相似性。
(1)基于维基百科的实体排序
INEX中对实体排序任务的探讨是基于维基百科数据集的,实体相当于维基百科条目,因此可利用传统的信息检索方法来判断维基百科与查询主题的相关性来获得对实体的排序。但另外的一些方法除利用维基百科条目还利用到了维基百科的链接结构或者类目结构实现对实体的排序。如Tsikrika等[28]利用相关性传递来对实体进行排序,基于这样的假设,即在某实体的维基百科条目中出现的其他实体是与该实体相关的。该方法的主要思想首先返回与查询相关的最初维基条目(实体),再以实体为节点,条目之间的链接关系为边构建实体图,在该图中进行相关性传递,最后通过查询中的实体类别或者该类别的子类别来筛选实体。该方法在INEX XER 2007测评中取得了最好的实验结果[29],但是该方法只考虑了与查询相关的最初实体集合,而没考虑最初集合之外的其他实体。Pehcevski等[30]基于这样的假设,即一个质量较好的实体网页应该有一些与该实体相关的网页链向了它,首先选择与查询主题相关的排名靠前的网页,再利用PageRank或者H its算法来分析这些网页与实体网页之间的链接情况,从而为实体进行排序。Cai等[31]利用了最普遍的链接排序算法,在该算法中,将每个网页当作一个单个节点,即使这个网页可能包含多个语义块。Demartini等[32]基于维基百科条目中的信息抽取该实体的<属性,值>,由于用户查找的实体也可用该实体的<属性,值>来表示,最后基于这二者的匹配关系来对实体进行排序。Kazama和Torisawa[33]利用了维基百科的外部知识来提高命名实体识别的准确度,即维基百科网页的首句表明了与该网页相关实体的类别,这些类别可作为实体类别标注的特征。Balog等[34]提出了基于实体类别和基于查询词建模的实体排序方法,最后根据返回的检索结果分别通过类别和查询词进行查询扩展,该实验表明基于类别的查询扩展取得的实验效果要好些。J-msen等[35]利用维基百科的类目结构对查询中给定的类别和候选实体的类别进行扩展。Pehcevski等[36]认为在实体附近的链接比其他位置的链接更与该实体相关。INEX XER 2007—2008测试结果表明,利用数据集的一些结构(类目结构、链接结构等)要比仅利用维基百科条目取得的实验结果好[37]。为了提高实验结果的性能,一些研究者还将语义和自然语言处理方法运用到实体排序中,如Demartini等[38][39]。
(2)类别相似性
该任务中,查找的实体除与查询主题相关外,且属于查询中给定的实体类别,则需采用一定的方法对实体类别相似性进行判断。Vercoustre等[40][41][42]提出了一种基于集合的计算类目之间相似性的方法如公式1,该方法基于这样的事实,即每个实体的维基百科网页给定了该维基百科条目的所属类别。
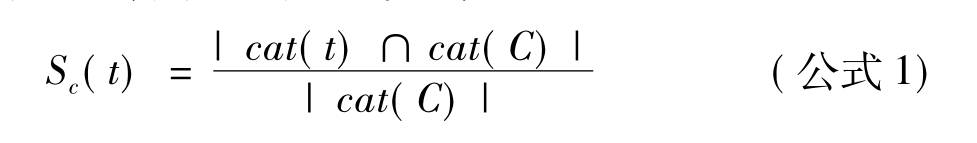
cat(t)表示检索到的目标实体的维基百科网页中所包含的类别集合,而cat(C)表示的是给定的类别集合,|cat(t)∩cat(C)|表示的是两集合交集中的元素个数。由于目标实体类别(即查询中给定的实体类别)一般范围比较宽泛,利用类别相似计算公式,被检索到的实体可能不属于该类别。Vercoustre等[43]针对该问题,基于维基百科的类目结构进行了类目扩展。Demartini等[44]利用YAGO来扩展类目集合,从而提供实体类型匹配的准确度。Tsikrika等[45]利用其子类目进行了类目扩展。
另外一种方法通过类别字面形式上的相似性来计算类别之间的相似性[46]。如“欧洲国家”与“国家”两个类别相似,因二者都包含了“国家”一词。则可以通过先对所有的实体类别名建立索引,再以类别名作为查询,利用信息检索方法来查找出与之相似的实体类别。
3.2 列表补全任务
在列表补全任务中,查询可以表示为<query,entities>二元组,其中query表示自然语言描述的用户信息需求,entities表示给定的与查询主题相关的实体例子。即给定查询主题和1至3个实体例子,要求返回与实体例子相似且与查询主题相关的实体,使得与查询主题相关的实体例子完备化。例如:给定查询主题“能够支付欧元的欧洲国家”和与查询主题相关的实体例子“德国、法国”,要求返回其他相关实体如荷兰、西班牙等。
上文中谈道,TREC 2003问答检索的主要问题分为事实问题、列举问题和定义问题,其中列举问题就是列举满足信息需求的不同答案例子,如列举出武汉地区的985高校;Rose等[47]指出列表补全是网络查询中一种较普遍的形式,如在搜索引擎中给定一些查询的例子,便于系统理解自己的检索目标;Ghahramani和Heller[48]提出了一种基于机器学习的列表补全方法;Google公司研发的一种小工具Google sets,根据用户输入的关键词,可把相关的关键字列出来,但列表补全任务与之不同的是除考虑了实体与实体之间的相似性外,还考虑实体与查询主题之间的相关性。
列表补全任务的意义在于:通过给定实体例子而非实体类别,对待返回实体进行限制,进而减少返回实体数目,提高检索的准确度。而该任务的难点就是如何计算实体例子与待返回实体之间的相似性以此来识别出符合条件的实体。目前常用的是基于共现和类别相似性的方法。
(1)基于共现的方法
Razmara等[49]在参加TREC的问答系统任务时指出列举问题中的答案与例子之间存在特定的关系,除了它们属于相同的实体类型外,还可能在句子中共现,或者共现在具有相同词汇或语法的不同句子中。Ahn等[50]和Kor等[51]通过分析识别两个或多个候选答案所出现的共同文本,并利用该共同文本来扩展候选答案例子列表。Google sets计算关键词之间的相关度时,也采用了基于共现的方法,即关键词在同一个网页中同时出现的概率。
基于具有相同属性或者类别的实体将会出现在同一个网页[52]或者相同网页的同一个列表或表格中的假设,在INEX实体检索会议中有参与者利用了维基百科的“List of”网页来获取候选实体[53]。
(2)基于类目相似性的方法
该方法基于这样的假设,越是相似的实体其所属类别越相似,如公式2所示:
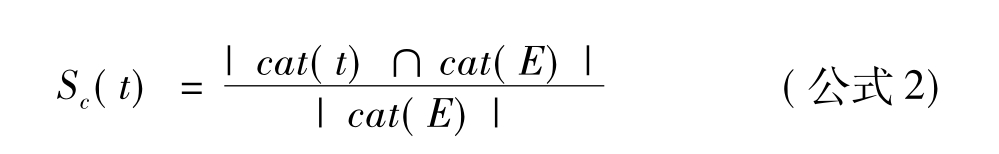
其中cat(t)表示的是目标实体的维基百科网页中的类别集合,cat(E)表示的是所有实体例子的维基百科网页中类别集合的并集,|cat(E)|表示集合cat(E)的元素个数。|cat(t)∩cat(E)|表示两集合交集的个数(即目标实体维基百科网页与实体例子维基百科网页中相同类别的个数)。Sc(t)的值越大,则目标实体与实体例子之间的相似性越大。
4 TREC中的实体任务
2009年TREC设立了实体任务,它是TREC 2008收尾的专家检索任务的一种继续。TREC实体任务的主要目的是在互联网中查找相关实体。其主要任务可以描述为:给定源实体(实体名和实体主页)、目标实体的类别和目标实体与源实体之间的关系,识别出与源实体具有特定关系且属于目标实体类别的实体,并返回该实体的主页[54]。TREC实体检索为参与者提供的数据集为ClubWeb 09(包括10亿个网页,10种语言)[55]的B类数据集,该数据集包含5000万个英文网页。相对于TREC专家检索任务的数据集来说,其范围从企业内部扩展到了互联网。而相对于INEX实体检索任务的数据集来说,一方面其数据集范围扩大,维基百科只是其数据集的一部分,对实体检索的探讨由维基百科扩展到互联网,且检索的实体不一定都有维基百科条目。另一方面,由于该数据集是未经标注的,则在任务中,参与者需采用一定的方法从中识别出实体。
TREC 2009实体任务为参与者提供了查询主题,其格式如表2所示。其中<entity_name>字段表示源实体名,<target_entity>表示目标实体类别,<narrative>用自然语言表示了源实体与目标实体之间的关系。
表2 TREC 2009实体任务的查询例子

总结TREC 2009的实体任务,参与者主要关注以下三个方面:实体识别,实体相关性判断,实体主页查找。
(1)实体识别
由于TREC的实体任务提供的是未经标注的文本,则参与者需从数据集中识别出实体。其中一些参与者采用命名实体识别工具(如斯坦福的命名实体识别工具)[56][57][58]识别实体,另一些参与者没采用命名实体识别方法,如Serdyukov等[59]利用维基百科识别出相应实体,再利用DBPedia,infoboxes,Yago和Wordnet对实体类型进行筛选。Kaptein等[60]和Bron等[61]在命名实体识别和实体类型筛选时,利用维基百科的结构。Fang等[62]利用问答系统中的表面文本模式定义源实体与目标实体之间的关系模板,依据模板来抽取实体。McCreadie等[63]采用了一种基于词典的命名实体识别方法,利用DBPedia建立命名实体词典。Fang等[64]认为网页中出现在网页同一列表或者表格中的实体可能具有相同的属性,则在进行实体抽取时考虑到了网页中的结构化信息如列表和表格。
(2)实体相关性判断
由于TREC 2009实体任务中的可能目标实体并不都具有维基百科主页,从而缺乏一种对实体进行有效描述的方法。基于支持信息的方法则是一种有效地建立实体与查询主题之间关系的方法。其主要思想是:首先利用查询主题检索出与之相关的文档或者文档片断,然后在这些支持信息中基于目标实体与查询主题,源实体或者目标实体与源实体之间的共现来判断实体与查询主题之间的相关性。Wang等[65]受专家检索方法的启发,采用两步检索模型,首先利用检索模型检索出与查询相关的文档,计算出文档与查询主题的相似性分数;其次,从第一步中返回的排序靠前的文档中识别出相关实体,然后计算实体与文档之间的相似性,综合这两步的相似性分数获得最后的实体排序。而在该方法中没考虑到实体关系和最后的实体消歧。Fang等[66]在对实体进行排序时,主要考虑到了三个层次的相关性,查询主题与支持文档之间的相关性,查询主题与支持文档中支持段落之间的相关性,分别从支持文档、支持文档段落、支持文档中的实体来对实体进行排序。该方法在TREC 2009实体任务的测评中取得了最好的实验结果。Zhai等[67]不但考虑源实体,目标实体和查询主题词之间的共现,还考虑到了目标实体,源实体以及目标实体与源实体之间关系的共现。Zheng等[68]指出支持信息不能过长也不能过短,过短则可能不会包含目标实体与原实体以及二者之间的关系,而过长则会包含一些与查询无关的噪音实体。Chen等[69]提出了EntityRank算法,该算法在实体检索中利用局部共现和全局可获得的信息来对实体进行排序,类似于专家检索中的两步查找方法。
判断实体与查询主题相关性的其他方法还有:Liu等[70]提出了相关实体查找的一个框架,该框架首先根据查询主题利用BM25模型检索出前5000个文档,然后从这些文档中抽取出锚文本和Title作为候选实体字符串,并为这些候选字符串建立描述文档,进而通过描述文档与查询主题的相关性来对实体进行排序; McCreadie等[71]在利用投票算法为实体进行排序时,首先查找出于实体相关的文档,这些文档类似于为实体建立的档案;此外,Vydiswaran等[72]在对实体排序时,还考虑到了实体关系。
(3)实体主页查找
TREC 2009实体任务最后还需返回实体的主页。Serdyukov等[73]利用维基百科的外部链接来获得该实体的主页。Fang等[74]对维基百科之外的主页,采用回归的方法进行查找。Bron等[75]只是将维基百科网页作为实体,这样可以避免命名实体识别和主页查找的缺陷。在进行主页查找时,利用实体名作为查询,以此获得一些文档,最后根据文档URL与实体名之间的距离值,将分数高的文档作为实体的主页。Zheng等[76]将实体作为关键词,利用Dirichlet优化方法来对返回的网页进行排序,并将获得相关分数最高的网页作为该实体的主页。
5 实体检索模型
目前,实体检索任务中,还没有一种通用的排序模型。总结INEX 2007—2008与TREC 2009实体检索任务中所采用到的排序方法,可以分为基于语言模型的方法和基于非语言模型的方法。
5.1 基于语言模型的方法
语言模型早期用于特定类型的实检索(专家检索)中。专家检索问题的实质是:根据用户的查询q,返回与q相关的专家并排序返回给用户。依据查询似然的思想,专家排序可以看作是:用户在检索中提出的查询表达式q是针对某个特定的专家e生成的,而检索系统观察(接受)到用户提出的查询q后,其任务是预测可能生成q的专家并将其根据可能性大小排序返回给用户,即将专家按照p(e|q)排序,如公式3所示。
![]()
由于p(e)与p(q)对最后的排序无关,则p(e|q)正比于p(q|e),如公式4所示。
![]()
Cao[77]和Azzopardi[78]等最先在TREC 2005采用语言模型对专家检索进行建模,Balog[79]以此为基础提出以专家为中心的模型(如公式5)和以文档为中心的模型(如公式6),并使这两个模型成为当前专家检索领域的权威模型。它们为基于此的扩展和新方法的产生提供了理论基础。[80]
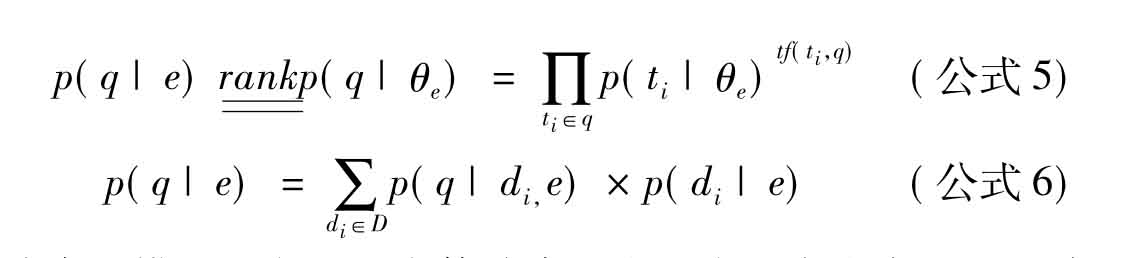
专家检索的模型和方法对实体检索具有重大的启发意义,可将专家检索模型运用到实体检索中。如Tsikrikia[81]将维基百科条目当作对实体的描述,并运用公式6来对实体进行排序。但实体检索与专家检索的不同之处在于,专家检索的实体类别是确定的,而实体检索的类别是不确定的。相对专家检索来说,在进行实体排序时需考虑到实体类别以及实体之间的关系等因素。公式7在实体排序中考虑到了实体类别:
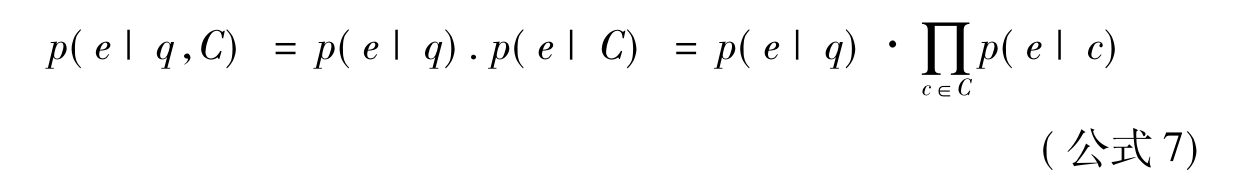
根据给定查询q和实体类别C对实体集合进行排序,即通过计算p(e|q,C)来对实体进行排序。假设q和C是条件独立的,且类目集合中的c是相互独立的,则在已知实体类别时,p(q|e)的计算方法类似于公式4,如公式8所示。
![]()
其中,n(t,q)表示查询词t出现在查询q中的次数。p(t|θe)表示实体e生成查询词的概率,一般可通过查询词与实体名之间的共现来计算。p(e|C)可用公式1计算。另外Jiang等[82]将专家检索模型运用到实体检索中,其考虑了INEX查询中的类别字段。Balog等[83]和Adafre等[84]在对实体排序时,也采用了类似以上的思想。
基于语言模型对实体排序考虑到了实体例子(或者说实体与实体之间的关系),如公式9所示。
![]()
其中p(e|q,C)的计算方法如公式8,而p(e|e')的计算方法采用了公式3。
公式8和公式9分别考虑了实体类别和实体关系来对实体排序,但这两种排序方法都是基于维基百科数据集的。也有一些研究者通过非维基百科数据集,基于语言模型且考虑实体类别、实体关系等因素来对实体进行排序。
Fang等[85]将问答系统中的层次相关模型运用到了实体检索中,如公式10所示。其中q表示的查询主题,d表示的支持文档,s表示的是支持文档段落,t表示的是识别类别。p(q|d)表示的查询主题与文档之间的相关性,p(q|s,d)表示的是查询主题与文档支持段落之间的相关性,p(e|q,t,s,d)表示的是在给定文档、文档段落、查询主题和实体类别的情况下,e是相关实体的概率。
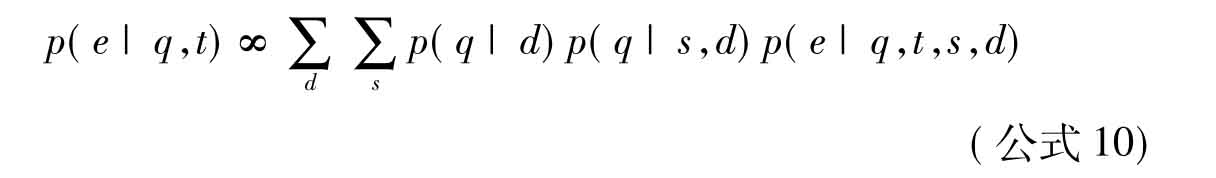
Bron等[88]在对实体排序时不但考虑了实体类别且考虑了实体与实体之间的关系,如公式11所示。
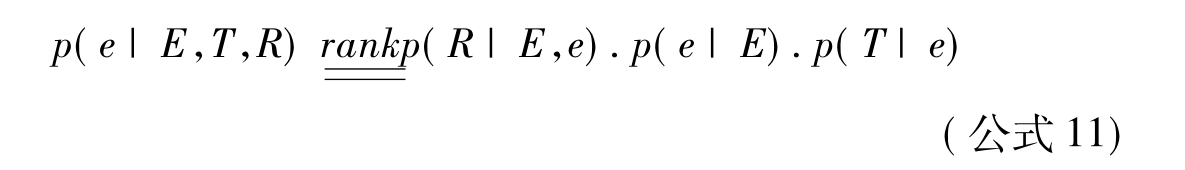
其中,p(e|E)利用源实体E与目标实体e之间的共现来计算。p(T|e)表示的是目标实体e属于实体类别T的概率。p(R|E,e)表示的是目标实体e与源实体E之间符合关系R的概率。Wang等[86]提出了两步检索模型。Liu等[87]认为p(e|q)的条件分布正比于P(e,q)的共同分布,且该概率分数最后由两种相关性现象来计算,一是源实体、目标实体和查询主题的共现;另外是源实体、目标实体和源实体与目标实体之间关系的共现。
5.2 非语言模型的方法
(1)基于支持文档建模
TREC中采用最多的是以支持文档或者支持文档片段来建立查询主题与实体之间的关系。如Wang等[74]提出公式12。
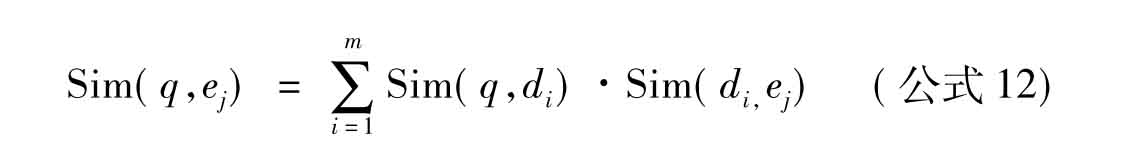
在该公式中Sim(q,di)表示文档与查询主题之间的相似性,可以利用传统的检索模型获得。Sim(di,ej)表示的实体与文档之间的相似性,即通过实体名为检索词,在与查询主题相关的文档中进行检索,从而获得实体与文档之间的相似。但是该方法没考虑到实体与实体之间的关系。
(2)投票算法(Voting Model)
Macdonal等[88]提出了一种基于文档模型的投票算法,该算法把实体检索看成是一个投票过程,当检索出一个与查询主题相关,且与候选实体相关的文档时,则认为该文档为该实体进行投票,最后依据每个候选实体所得票数之和进行排序。Macdonal等[89]最初将12种投票方法运用到了专家排序中,实验结果显示,expCombMNZ是最好的投票方法。在TREC 2009的实体任务中,其也采用了该投票算法,如公式13所示。
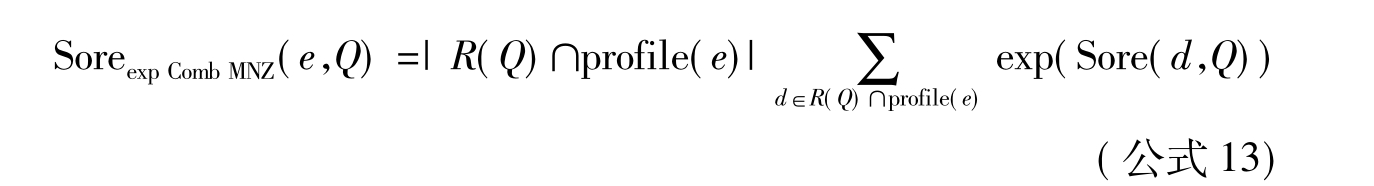
其中,R(Q)表示的是与查询Q相关且排序后的文档集,SoreexpCombMNZ(e,Q)表示的是给定查询Q和实体e的相关性分数。Profile(e)表示含有实体e的文档集,Score(d,Q)表示实体在文档集R(Q)中的相关性分数。|R(Q)∩profile(e)|表示同时存在于实体档案和R(Q)中的文档数。
6 总结
本文详细介绍了特定类型的实体检索、INEX中的实体检索任务、TREC中的实体检索任务和实体检索模型。从上文可以看出,近年来实体检索在检索方法和检索模型等方面取得了进展。但总体来说,目前学界尤其是国内对通用情况下的实体检索研究还处于起步阶段,相关研究成果还不是很多,如在中国期刊网内以“实体检索”为题名查询词的文献为零,十分相关的中文专家检索文献[90][91][92][93][94]也很少。
尽管前期专家检索的相关研究成果为实体检索打下了良好的基础,提供了可供借鉴的研究成果,但在关联实体和属性的识别,尤其是通用实体相关性建模中如何集成类目识别模型都有待于进一步的深入研究,当前在这一方面的解决方案大多是经验性的,没有对其建模。此外,由于INEX实体检索数据集和TREC数据集对Wikipedia的特殊依赖性,使得当前对实体检索的研究距离真实和通用的环境尚有距离。则今后的实体检索研究的发展方向:①由维基百科扩展到通用环境中。②对实体类别和实体关系等建模进行研究。③更多地结合其他领域如问答系统、信息抽取、语义网等已有的技术和方法。
【注释】
[1]Broder,A..A Taxonomy of Web Search[J].SIGIR Forum,2002,36(2):3-10.
[2][11]Hu,G.,Liu,J.,Li,H.,Cao,H.,Nie,J.,Gao,J..A Supervised Learning Approach to Entity Search[C].Proceedings of the 3rd Asia Information Retrieval Symposium(AIRS 2006),Singapore,2006:54-66.
[3][13]Rode,H..From Document to Entity Retrieval:Improving Precision and Performance ofFocused TextSearch[D].PhD Thesis,Niversity of Twente Publications,2008.
[4]Fang,H.,Sinha,R.,Wu,W.,Doan,A.,Zhai,C..Entity RetrievalOver Structured Data[N].TechnicalReport,University of Illinois atUrbana-Champaign,Department of Computer Science,Jan.2004.
[5]Sayyadian,M.,Shakery,A.,Doan,A.,Zhai,C..Toward Enti-ty Retrieval over Structured and Text Data[C].Proceedings of the Joint Workshops on XML,IR,and DB,Sheffield,United Kingdom,2004:47-54.
[6]Nie,Z.,Zhang,Y.,Wen,JR.,Ma,WY..Object-Level Ranking:Bringing Order to Web Objects[C].Proceedings of the 16th International Conference on World Wide Web,2005.
[7]Nie,Z.,Zhang,Y.,Wen,JR.,Ma,WY..Object-levelVertical Search[C].Proceeding of3rd Biennial Conference on Innovative Data Systems Research(CIDR),2007.
[8]Nie,Z.,Zhang,Y.,Wen,JR.,Ma,WY..Web Object Retrieva[C]Proceedings of the 18th International Conference on World Wide Web,2007.
[9]http://libra.msra.cn[EB/OL].
[10]http://products.live.com[EB/OL].
[12]Petkova,D.,Croft,W.B..Proximity-based Document Representation for Named Entity Retrieval[C].Proceedings of the 16th ACM Conference on Conference on Information and Knowledge Management(CIKM'07),Lisbon,Portugal,2007:731-740.
[14]Rode,H.,Serdyukov,P.,H iemstra,D.,Zaragoza,H..Entity Ranking on Graphs:Studies on Expert Finding[J].2007
[15]Zaragoza,H..Ranking Very Many Typed Entities on Wikipedia[C].Proceedings of the Sixteenth ACM Conference on Conference on Information and Knowledge Management,2007:1015-1018.
[16]Streeter,L.A.,Lochbaum,K.E..An Expert/Expert Locating System Based on Automatic Representation of Semantic Structure[C].Proceedings of the 4th IEEE Conference on Artificial Intelligence Applications,San Diego,California,USA,1988:345-349.
[17]Campbell,C.S,Maglio,P.P.,Cozz,A.,Dom,B..ExpertiseIdentification Using E-mail Communications[C],CILM'03,2003.
[18]Deerwester,S.,Dumais,S.T.,Fumas,G.W.,Landauer,T.K.,Harshman,R..Indexing by Latent Structure Analysis[J].Journal of the American Society fo Information Sciences,1990:391-407.
[19]Dom,B.,Eiron,I.,Cozzi,A.,Yi,Z..Graph-Based Ranking Algorithms for E-mail Expertise Analysis[C].Proc.of the 8th ACM SIGMOD Workshop on Research Issues in Data Mining and Knowledge Discovery,2003.
[20]McDonald,D.W..Evaluating Expertise Recommendations[C].Proc.of the ACM 2001 International Conference on Supporting Group Work(GROUP'01),Boulder,CO,2001.
[21]Mattox,D.,Maybury,M.,Morey,D..Enterprise Expert and Knowledge Discovery[C].Proceedings of the HCI International'99.
[22][82]Jiang,J.,Lu,W.,Rong,X.,Gao,Y..Adapting Language Modeling Methods for Expert Search to Rank Wikipedia Entities[J].Springer,2009:264-272.
[23][28][45][81]Tsikrika,T.,Serdyukov,P.,Rode,H.,Westerveld,T..Structured Document Retrieval,Mutlimedia Retrieval,and Entity Ranking Using PF/Tijah[J].Springer,2008:306-320.
[24][34][83]Balog,K.,Bron,M.,Rijke,M.De.Categorybased Query Modeling for Entity Search[J].Springer Berlin/Heidelberg,2010:319-331.
[25][88]RLT Santos,Macdonald,C.,Ounis,I..Voting for Related Entities[C].Proceedings of the Eighteenth Text R Etrieval Conference(TREC 2009),Gaithersburg,MD,2009.
[27]Demartini,G.,A.de V ries,Iofciu,T.,Zhu,J..Overview of the INEX 2008 Entity Ranking Track[J].Springer,2008:243-252.[29][37][26]A.de V ries,Vercoustre,A.M.,Thom,J.,Craswell,N..Overview of the INEX 2007 Entity Ranking Track[J].Springer,2008:245-251.
[30]Pehcevski,J.,Vercoustre,A.-M.,Thom,J.A..Exploiting Locality ofWikipedia Links in Entity Ranking[J]//Macdonald,C.,Ounis,I.,Plachouras,V.,Ruthven,I.,White,R.W.,eds..ECIR 2008.Springer,Heidelberg,2008(4956):258-269.
[31]Cai,D.,He,X.,Wen,JR.,Ma,WY..Block-level Link Analysis[C].Proceedings of the 27th ACM International Conference on Research and Development in Information Retrieval,Sheffield,UK,2004:440-447.
[32]Demartini,G.,Firan,CS.,Iofciu,T.,K restel,R.,Nejdl,W..A Model forRanking Entities and Its Application to Wikipedia[C].Proceedings of The Latin-American Web Conference(LA-WEB 2008)(2008)
[33]Kazama,J.,Torisawa,K..Exploiting Wikipedia as External Knowledge for Named Entity Recognition[C].Proceedings of the 2007 Joint Conference on EMNLP and CoNLL,Prague,The Czech Republic,2007:698-707.
[35]Zhu,J.,Vries,A.P.,Demartini,G..Evaluating Relation Retrieval for Entities and Experts[C].Proceedings of SIGIR 2008,2008.
[36][52]Pehcevski,J.,Vercoustre,AM.,Thom,J..Exploiting Locality of Wikipedia Links in Entity Ranking[J].Springer-Verlag Berlin,2008:258-269.
[38][44][53]Demartini,G.,Firan,C.,Iofciu,T.,Nejdl,W..Semantically Enhanced Entity Ranking[J]//Bailey,J.,Maier,D.,Schewe,K.-D.,Thalheim,B.,Wang,X.S.,eds..W ISE 2008.LNCS,Springer,Heidelberg,2008(5175):176-188.
[39]Demartini,G.,Firan,C.S.,Iofciu,T.,Krestel,R.,Nejdl,W..A Model forRanking Entities and ItsApplication toWikipedia[J].Web Congress,Latin American,2008:29-38.
[40][43][46]Vercoustre,AM.,Pehcevski,J.,Thom,J.A.. Using Wikipedia Categories and Links in Entity Ranking[J].Springer Berlin/Heidelberg,2008:321-335.
[41]Vercoustre,A.,Thom,J.A.,Pehcevski,J..Entity Ranking in Wikipedia[C].Proceedings of the 2008 ACM Symposium on Applied Computing(SAC 2008),Fortaleza,Ceara,Brazil,2008.
[42]Weerkamp,W.,He,J.,Balog,K.,Meij,E..A Generative Language Modeling Approach for Ranking Entities[C].In Geva et al.,2008:292-299.
[47]Rose,D.E.,Levinson,D..Understanding User Goals in Web Search[J].InWWW'04,2004:13-19.
[48]Ghahramani,Z.,Heller,K.A..Bayesian sets[J].NIPS 2005.
[49]Razmara,M.,Kosseim,L..Answering List Questions Using Cooccurrence and Clustering[C].Proceedings of the Sixth Text REtrieval Conference(TREC 2007),2007.
[50]Ahn,K.,Bos,J.,Curran,J.R.,Kor,D.,Nissim,M.,Webber,B..Question Answering with QED at TREC-2005[C].Proceedings of the 14th Text Retrieval Conference(TREC-14),Gaithersburg,USA,November.NIST.
[51]Kor,K.W..Improving Answer Precision and Recall of List Questions[D].Master's Thesis,School of Informatics,Universityof Edinburgh,2005.
[54]http://ilps.science.uva.nl/trec-entity/[EB/OL].
[55]http://boston.lti.cs.cmu.edu/Data/clueweb09/[EB/OL].
[56][65][86]Guo,J.,Chen,G.,Xu,W.,Wang,Z.,Liu,D..BUPT at TREC 2009:Entity Track[C].Proceedings of the Eighteenth Text REtrieval Conference(TREC 2009),Gaithers-burg,MD,2009.
[57][68][76]Zheng,W.,Gottipati,S.,Jiang,J.,Fang,H.. UDEL/SMU at TREC 2009 Entity Track[C].Proceedings of the Eighteenth Text REtrieval Conference(TREC 2009),Gaithersburg,MD,2009.
[58][72]Vinod Vydiswaran,VG.,Ganesan,K.,Lv,Y.,He,J.,Zhai,CX..Finding Related Entities by Retrieving Relations:UIUC atTREC 2009 Entity Track[C].Proceedings of the Eighteenth Text REtrieval Conference(TREC 2009),Gaithersburg,MD,2009.
[59][73]Serdyukov,P.,A de Vries.Delft University at the TREC 2009 Entity Track:Ranking Wikipedia Entities[C].Proceedings of the Eighteenth TextREtrievalConference(TREC 2009),Gaithersburg,MD,2009.
[60]Kaptein,R.,Koolen,M.,Kamps,J..Experiments with Result Diversity and Entity Ranking:Text,Anchors,Links,and Wikipedia[C].Proceedings of the Eighteenth Text REtrieval Conference(TREC 2009),Gaithersburg,MD,2009.
[61][75]Bron,M.,Balog,K.,Rijke,M..Related Entity Finding Based on Co-Occurrence[C].Proceedings of the Eighteenth Text REtrieval Conference(TREC 2009),Gaithersburg,MD,2009.
[62][64][66][74][85]Fang,Y.,Si,L.,Yu,Z.,Xian,Y.,Xu,Y..Entity Retrieval by Hierarchical Relevance Model,Exploiting the Structure of Tables and Learning Homepage Classifiers[C].Proceedings of the Eighteenth Text REtrieval Conference(TREC 2009),Gaithersburg,MD,2009.
[63][71]McCreadie,R.,MacDonald,C.,Ounis,I.,Peng,J.,Santos,RL..University ofGlasgow at TREC 2009:Experiments with Terrier[C].Proceedings of the Eighteenth Text REtrieval Conference(TREC 2009),Gaithersburg,MD,2009.
[67][70][87]Liu,Y.,Xu,H.,Cheng,X.,Zhai,H.,Guo,J..A Novel Framework for Related Entities Finding:ICTNET at TREC 2009 Entity Track.[C].Proceedings of the Eighteenth Text REtrieval Conference(TREC 2009),Gaithersburg,MD,2009.
[69]Cheng,T.,Yan,X.,Chang,K.,-C..Entity Rank:Searching Entities Directly and Holistically[C].Proc.of VLDB,2007: 387-398.
[77]Cao,Y.,Liu,J.,Bao,S.,Li,H..Research on Expert Search at Enterprise Track of TREC 2005[C].Proceedings of TREC,2005.
[78]Azzopardi,L.,Balog,K.,M.de Rijke..Rijke,M.de..Language Modeling Approaches for Enterprise Tasks[C].Proceedings of TREC 2005.
[79]Balog,K.,M.de Rijke..Associating People and Documents[C].Proceedings of ECIR 2008,Glasgow,Scotland,2008: 296-308.
[80]Balog,K.,Azzopardi,L.,M.de Rijke.Formal Models for Expert Finding in Enterprise Corpora[C].Proceeding of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval(SIGIR 2006),Seattle,Washington,USA,2006:43-50.
[84]Adafre,S.F.,M.de Rijke,Sang,ETK..Entity retrieval[C].Proceedings ofRANLP,2007.
[89]Macdonald,C.,Ounis,I..Voting for Candidates:The Voting Model for Expert Search[C].Proceedings of the 15th ACM International Conference on Information and Knowledge Management,2006:387-396.
[90]刘萍.我国专家信息资源检索现状研究[J].情报理论与实践,2007(5):311-313.
[91]陆伟,韩曙光.组织专家的检索系统设计与实现[J].情报学报,2008(5),38-42.
[92]陆伟,陈武,韩曙光.专家检索及热点探测系统设计与实现[J].情报杂志,2009(12):113-117.
[93]陆伟,赵浩镇.基于文档权重归并法的企业专家检索[J].现代图书情报技术,2008(7):38-42.
[94]李晨.网络搜索引擎与专家检索系统框架和模型研究[D].北京:北京邮电大学硕士论文,2009.
【作者简介】

陆伟,男,1974年生,教授,博士生导师,研究方向为信息检索、数据挖掘和知识管理,近年先后在国内外发表论文50余篇,其中SSCI/SCI索引论文5篇。
张晓娟,女,2009级情报学在读硕士研究生,研究方向为信息检索。
姜捷璞,男,1986年生,匹兹堡大学在读博士生,研究方向为信息检索,已发表论文7篇。
鞠源,男,1988年生,在读硕士研究生,研究方向为信息检索。
【注释】
(1)本文为教育部人文社会科学规划项目“专家专长智能识别与检索系统实现研究”(项目编号:09yja870021)成果之一。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










