



23.1 概率语言模型
第二十二章中给我们提供了语言的一个逻辑模型:我们用CFG和DCG来刻画一个字符串是否属于某种语言。在本节中,我们将介绍一些概率模型。概率模型有不少优点。它们能够很方便地利用数据进行训练:学习只是计算发生次数的问题(允许因为样本规模小而产生的误差)。同时,这些概率模型更鲁棒(因为它们能够接受任意的字符串,即使出现的概率很低),它们反映了这样一个事实:并不是100%的说话者在哪些语句确实是某语言的一部分的问题上都能达成一致的;它们还能用于排歧——概率可以被用于选择最可能的解释。
概率语言模型为一个(可能是无限的)字符串集合定义了概率分布。我们已经见过用于语音识别(第 15.6 节)的二元和三元语言模型就是概率模型的样例。一元模型为词典中的每个词语分配了一个概率P(w)。该模型假设词语的选择是独立的,所以一个字符串的概率就是组成该字符串的所有词语的概率乘积,即 Πi P(wi)。下面这个包含20个词语的序列是用本书中词语的一元模型随机生成的:
logical are as are confusion a may right tries agent goal the was diesel more object then information-gathering search is
二元模型在给定前一个词语的条件下,给每个词语分配一个概率P(wi|wi−1)。图15.21中列出了一些这样的二元模型概率。本书的一个二元模型生成了下面这个随机序列:
planning purely diagnostic expert systems are very similar computational approach would be represented compactly using tic tac toe a predicate
一般而言,一个n元模型以前n − 1个词语为条件,分配概率P(wi|wi −(n−1)… wi−1)。本书的一个三元模型生成了下面这个随机序列:
planning and scheduling are integrated the success of naive bayes model is just a possible prior source by that time
即使采用如此小规模的样本,在近似英语语言以及近似一本人工智能教材的主题方面,三元模型显然强于二元模型(二元模型又强于一元模型)。所有的模型自身也是一致的:对于一个由模型生成的随机字符串,三元模型赋予它10−10的概率,二元模型是10−29,而一元模型是10−59。
由于只有近50万的词语,本书包含的数据不足以产生一个好的二元模型,更不用说是三元模型了。在本书的词典中大约有15 000个不同的词语,因此二元模型包含了大约15 0002= 2.25亿个词对。无疑其中至少99.8%的词对出现次数是0,但是我们并不希望我们的模型说所有这些次数为0的词语对都是不可能的。我们需要用某种方式的平滑来处理这些为0的值。最简单的方法被称为加1平滑:我们给每个可能的二元组的计数加1。这样,如果语料库中有N个词语,而且有B个可能的二元组,那么每个实际次数为c的二元组则会被赋予一个概率估计(c+1) / (N+B)。这种方法消除了n元模型中0概率的问题,但是给每个二元组的次数刚好增加1的假设是值得怀疑的,而且可能导致较差的估计。
另一种平滑方法是线性插值平滑,该方法用线性插值将三元模型、二元模型和一元模型结合起来。我们定义我们的概率估计如下:
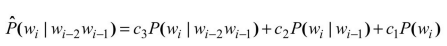
其中c3+c2+c1=1。参数ci可以是固定的,或者可以利用EM算法对其进行训练。让ci的取值依赖于n元模型的计数值是可能的,所以我们可以为从更高阶的计数值得到的概率估计设置更高的权值。
我们评价一种语言模型的方法如下:首先,把你的语料分割为训练语料库和测试语料库。根据训练数据确定模型的参数。然后,通过模型计算赋予测试语料库的概率;概率越高越好。这个方法存在的一个问题是对于长字符串而言P(words)相当小。这个数量可能会引起浮点下溢,或者很难读出来。所以,我们可以计算测试词语串的模型混乱度(perplexity)来取代概率:
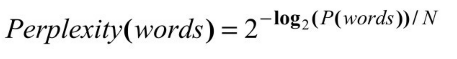
其中N是words的个数。混乱度越低,模型越好。一个给每个词语赋予1 / k概率的n元模型的混乱度是k。你可以把混乱度当作平均分支因子。
作为n元模型能够做什么的一个例子,考虑分词的任务:在没有空格的文本中找到词语的边界。这项工作对于日语和中文这类书写时词语之间没有空格的语言是必要的,不过我们假设大多数读者更习惯于英语。下面这个语句
Itiseasytoreadwordswithoutspaces
对我们来说实际上很容易读懂。你也许认为这是因为我们拥有关于英语句法、语义和语用的全部知识。我们将说明一个简单的一元词语模型可以很容易地对该语句进行编码。
在前面,我们已经看到Viterbi公式(15.9)是如何通过一个词语概率网格解决寻找最可能序列的问题。图23.1是一个专门为分词问题设计的Viterbi算法的版本。它把一个一元词语概率分布P(word)和一个字符串作为输入。然后,对于该字符串的每个位置i,该算法在best[i]中保存从开始位置延伸到i的最可能字符串的概率。同时它也在words[i]中保存产生这个最佳概率的以i为结束位置的字符串。一旦该算法用动态规划的方式建立了best和words数组,它就会通过words从后向前找到最佳路径。在这种情况下,利用本书中的一元模型,那些词语的最佳序列实际上是“It is easy to read words without spaces(阅读没有空格的词语是容易的)”,其概率是 10−25。比较这个序列中的一部分,例如“easy”的一元概率是2.6×10−4,而“e as y”的概率则很低,只有9.8×10−12,尽管词语e和y在本书的公式中相当常见。类似地,我们有
P(“without”)=0.0004
P(“with”)=0.005;P(“out”)=0.0008
P(“with out”)=0.005×0.0008 = 0.000004
因此,根据一元模型,“without”的概率是“with out”的100倍。
在本节中,我们已经讨论了针对词语的n元模型,不过还有很多n元模型的应用是针对其它单元的,诸如字符或者是词性标注等。

图23.1 一个基于Viterbi的词语切分算法。给定一个去除了空格的词语串,它恢复最可能的分词方案
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









