



9.7 概率模型的应用
在心理学研究中,概率模型已得到了广泛的应用。其主要原因在于,它可以解决许多“经典测试理论”(Classical Test Theory,CTT)所不能解决的问题。例如,可以在具体的模型框架下获取测试特征的测量数据,还可以诊断分析问卷的内部特性,并像结构方程那样测试验证模型和理论。另外,由于概率模型的随机独立性特征,还可以独立地同时测量多面参数,并用于拟合测试等,这些都是CTT无法比拟的。
然而,概率模型在运动心理学研究中的应用只是在20世纪80年代到90年代才开始的,而且一直没有引起研究人员的重视。直到1998年,Tenenbaum和Fogarty在Duda编辑的《运动与锻炼心理学测量进展》一书中发表了一篇题为《Rasch模型在运动与锻炼心理学中的应用》的论文,着重介绍了运用概率模型对体育任务与自我朝向问卷(TEOSQ)的分析过程。该论文成为当时该模型在运动心理学研究中具有代表性的应用文章之一。近年来,有关概率模型在运动心理学研究中的运用逐渐增多,主要研究内容涉及赛前焦虑、运动最佳体验、目标朝向、自我概念、认知努力、应急和内省的测量,以及锻炼不适等方面的测量和验证分析。另外,概率模型在运动成分与策略研究方面还用于运动能力的测量。特别值得一提的是,Strauss,Busch和Tenenbaum在Tenenbaum和Eklund最新编辑出版的《运动心理学手册》(2007年,第3版)中发表了一篇题为《运动心理学中的测量与验证新观点》(New Perspective on Measurement and Testing in Sport Psychology)的论文,较为详细地介绍了概率模型在运动心理学研究中的运用。
那么,什么是概率模型呢?所谓概率模型是指Rasch模型,是“项目反应理论”(Item Response Theory,IRT)的模型之一,由丹麦数学与教育家George Rasch在1960年提出。该模型在很大程度上克服了CTT模型不能同时估算独立的潜变量参数值的缺陷。在通常情况下,心理学研究主要考虑的问题之一是定义和描述心理的结构,以及探索一些非观察变量。例如,个体的焦虑、内省、智力、目标朝向、应急策略等。这些结构一般是通过测量、验证项目反应指标来实现构建分析的。一旦观测指标得以验证落实,心理的结构就会被确认。在概率模型中,心理结构表示为潜变量,描述了各因素相对独立的向量变化。原始的Rasch模型是IRT的单参数模型,也就是一个潜变量θv(表示为被试v的能力)和一个分成0/1记录的显变量组成的概率模式。其中P(XvⅠ=1)表示被试v成功完成任务Ⅰ的反应概率。Rasch模式中的0/1设计思路是把P(XvⅠ=1)分解成一个任务参数δⅠ(如难度)和一个被试参数θv(如被试能力)的线性组合。被试参数和任务参数都是同位的潜变量。由于概率限定在0与1之间的变化,所以原反应概率是通过对数表达式来反映的,其模型的函数表达式为:
![]()
也就是说,通常传统的方差模型中,被试v在任务Ⅰ上的可观察显变量X被额外地分解成非观察变量θ(真分数)和e(测量误差)。但是,在Rasch模型中,对数表达的反应概率等于被试能力θv与任务难度δⅠ之差(也就是表达式9.1)。把表达式(9.3)作一个简单的代换就得出了Rasch模型反应功能式:
![]()
其中,e=2. 71为Euler常数。这样,潜变量与反应概率的关系通常由一个任务特征曲线(ICC)来表示(见图9-4)。当被试参数在量上增加时,正确完成任务的反应概率就会增加。图9.4中曲线变化分别趋近0与1,但非平分该线。任务难度标记为X轴,当P(XvⅠ=1)等于0. 5时,任务难度正好与被试参数θ值相等(也就是X轴上θ=δ=0)。这样,任务难度参数大于该点时,曲线向右趋近平行;当任务难度指数小于该点时,曲线向左趋近平行。曲线的平行和非平分特性是由于每个任务都有一个1的倾率。
在实际中,模型的数学表达式描述了被试正确完成任务和该任务可以被某个被试正确完成的概率。当理论的概率与实际测量的概率发生偏离时,其结果表示了数据不能拟合理论的数学模型。Rasch模型的这些基本特征为研究提供了实验和问卷的信、效度证据。Strauss等在这个模型下归纳了运动心理学研究中的同类模型应用,其中包括了评估模型(rating scale model)、离散模型(dispersion model)、部分记分模型(partial credit model)、定序反应模型(graded response model)等。另外,有的研究还运用了Rasch模型的扩展形式。其中包括原模型加上任务难度多参数的扩展模型、双参数模型(the two-parameter model)和多参数模型(themany-faceted rasch model)等。这些概率模型具有一个共同的特征,就是反映研究对象的特质,所以,Strauss等把这类模型归纳为“潜特质模型”(latent trait model)。
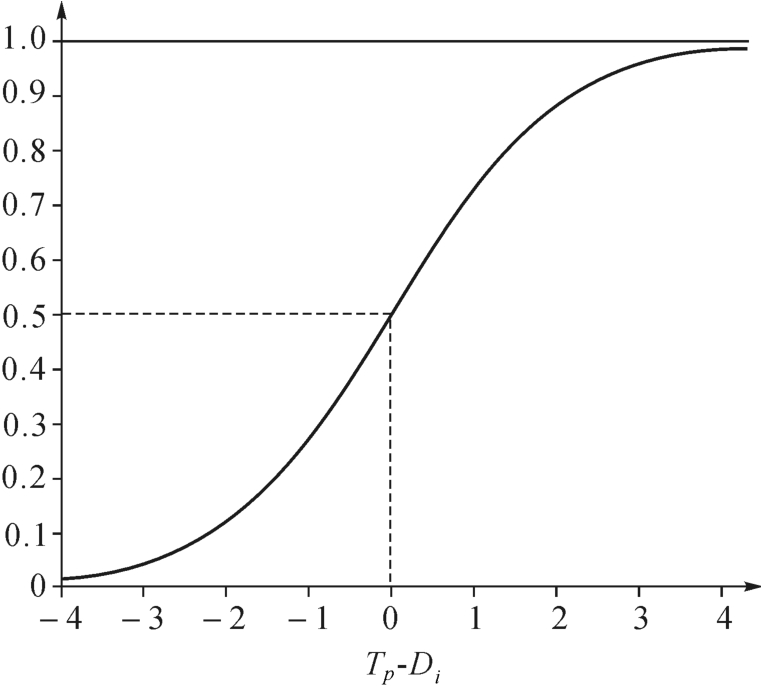
图9-4 某项任务特征曲线
与“潜特质模型”相反的另一类模型是“潜类模型”(latent class model)。其潜变量是基于分类和定性的评估。该类模型主要依赖于三个简单的假设,也就是,对于测量离散的显变量P来说,假设1是所有样本构成有限量的离散和穷尽亚类群或潜类群;假设2是反应概率表现为分类特性;假设3是潜类群中的任务(也就是显变量)是随机独立的。这种潜类分析可用于发现类别或类型。在不同类别之间,被试的区别是基于定性的概念。在每个类别中,被试也不可能以定量的概念来加以区别。这样,在一个分级潜类模型中,被试v的反应概率则被定义为:
![]()
其中,G表示亚群数量或潜类级;π是一个概率参数,定义类别G的大小;πⅠ\g是在类别G中成功完成任务Ⅰ的概率。基于这个模型的分析主要是拟合测试和被试与任务拟合统计等。总之,就目前的情景看,虽然因素分析和CTT在运动心理学研究中是常用的分析工具,特别是在心理诊断和相关研究中,这些方法基本成了实证科学的标准工具,但是这些工具也有它们的局限,特别是在决定因素数量、选择适合的方法等方面都存在着一些问题和缺陷。也就是说,CCT和因素分析只能对样本和任务的结果进行推断。而概率模型的最大优点是直接分析被试对任务的反应。
需要指出的是,概率模型具有这样的功能是因为它基于两个反应变量的关系可解释为潜变量的通则效应假设。所以,此种情况下的概率模式只有在拟合效度被确认的条件下才可得出结论。如果忽略或者拟合不成功,数据的结论效度将低于CCT和因素分析的方法。最后,Strauss等还提醒,运用该模型分析,样本应考虑足够大的量,以保证数据的稳定性和估计参数的准确性。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











