



“回归”一词是高尔登首先提出来的,随后,高尔登的学生皮尔逊(1857—1936)把回归的概念同数学的方法联系起来,把代表现象之间一般数量关系的统计模型叫做回归直线或回归曲线,从此诞生了统计上著名的回归理论。后来,回归这个词被泛指变量之间的一般数量关系。
现象之间的相关关系虽然不是严格的函数关系,但现象之间较为密切的相关关系我们可以通过函数表达式来近似反映,这种表达式根据相关现象的实际对应资料,运用数学的方法来建立,这种数学方法称为回归分析。其意思是:根据现象之间相关关系的形式,配合一条最适合的直线(或曲线),用这条直线(或曲线)反映它们之间数量变化的一般关系。本节仅讲直线,即当自变量发生一个量的变化时,因变量就一般会或平均会发生多大量的变化。例如,单位面积化肥使用量增加一千克,稻谷单产量会增产多少千克。反映现象间相关关系数量变化规律的这条直线就叫回归直线,表现这条直线的数学表达式称直线回归模型。它是推算预测因变量的经验数据模型。直线回归模型有一元线性回归模型(只反映两现象之间的相关关系)或多元线性回归模型(反映三个或三个以上现象之间的相关关系)。
回归分析从本质上讲,是指用一定的数学方程来拟合变量之间所存在的较为密切的相关关系,并使用一定的数学方法求解出方程中的未知参数,得到方程的具体表达式,然后借助于该函数关系式,依据自变量数值来估计因变量数值的一种统计分析技术。
回归分析的具体内容包括两个方面:
(一)确定现象之间相关关系的数学模型
回归分析的目的之一就是要根据一个现象的变动对另一个现象的变动做出数量上的判断,测定变量间的一般数量变化关系,即建立描述现象间相关关系的数学模型——回归方程,用函数关系式近似地表现相关关系,进而找出现象间相互依存关系数量上的规律性,作为判断、推算、预算的根据。
(二)测定数学模型的拟合度
数学模型是现象间相关关系的数量描述形式,模型拟合的精度直接影响着统计分析结论的准确性。因此,在模型建立后,需要对其精确度进行检验。统计上一般是通过计算估计标准误差来测定的。估计标准误差小,说明模型的拟合精度高,从而进行统计分析结论的可靠性就大,反之,估计标准误差大,说明模型拟合的精度低,则统计分析结论的可靠性就低。
相关分析和回归分析都是对现象之间的相关关系进行分析研究的统计技术,它们既相互区别,又存在密切关系。
它们的区别在于:其一,分析的内容及其深浅程度不同。相关分析是对现象之间是否存在相关关系以及相关关系的形态、密切程度等进行分析研究,是对相关关系所进行的初步的基本分析;回归分析是用数学模型来拟合变量之间的较为密切的相关关系,并求解模型的具体表达式,然后借助于该函数关系式进行变量间数值的推算,是对紧密的相关关系所进行的更进一步的分析。其二,分析过程中变量所处的地位不同。相关分析中,可以不区分自变量和因变量,所有变量都是随机变量,影响因素和被影响因素之间的关系是对等的;回归分析中,必须区分自变量和因变量,通常将影响因素作为自变量,被影响因素作为因变量,只有因变量是随机变量,自变量一般是给定量。
它们的联系在于:相关分析是回归分析的前提和基础,回归分析是相关分析的继续和深入。不经过相关分析,一般不可以直接进行回归分析,不然得出的分析结论可能就是错误的,依据这样的结论进行决策可能会造成无法估量的损失。如果通过相关分析得出变量之间存在着极为密切的相关关系,那么往往都要继续进行回归分析,通过回归分析得出的结论才更有意义。
在回归分析中,最简单的模型是只有一个因变量和一个自变量的线性回归模型。这一类模型就是一元线性回归模型,又称直线回归模型。
(一)构建一元线性回归模型应具备的条件
一般情况下,构建一元线型回归模型应具备以下几个条件:
(1)现象间确实存在数量上的相互依存关系。只有当两个变量存在比较密切的相关关系,所构建的回归模型才有意义,用此进行分析和预测才有价值。
(2)现象间存在线性相关关系。一元线性回归方程在图形上表现为一条直线,因此,只有当两个变量的相关关系表现为直线相关时,所配合的直线方程才是对客观现实的真实描述,才可用此进行统计分析。如果现象间的相关关系表现为曲线,却配合为直线,这必然会得出错误的分析结论。
(3)具备一定数量的变量观测值。回归直线方程是根据自变量和因变量的样本观测值求得的,因此,变量x和变量y,两者应有一定数量的对应观测值,这是构建直线方程的依据。如果观测值太少,受随机因素的影响较大,就不易观察出现象间的变动规律性,所求出的直线回归方程也就没有多大意义了。
(二)一元线性回归模型
若以x表示自变量,y表示因变量,则一元线性回归模型的基本形式为:
式中,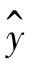 ——回归估计值;
——回归估计值;
a,b——未知参数,其中b为回归系数,它表示当自变量有一个单位变动时,因变量变动的平均值,b>0为增加量,b<0为减少量;b的符号与相关系数r的符号一致,r>0,则b>0,变量呈正相关关系;若r<0,则b<0,变量呈负相关关系,而a是一个与自变量初始有关的因变量的基础参考值。
根据多元函数求极值的定理,使用最小平方法,可得到求解参数a和b的标准联立方程组为:
式中,n——数据的项数。
其他符号与前相同。
解联立方程组可得:
例8-3 根据表8-2所示的居民家庭的月可支配收入和消费支出的调查资料,进行一元线性回归分析确定直线回归方程。
根据消费支出与可支配收入之间关系,令消费支出为因变量y,可支配收入为自变量x,则如表8-8所示。
表8-8 直线回归方程参数计算表
上式说明该社区2010年居民月可支配收入x每增加1百元,消费支出y就平均增加0.717 7百元;在月可支配收入x为0的情况下,消费支出y为-0.208 9百元。根据这个方程,可以估计该社区居民月可支配收入对消费支出的影响,估计的结果表明该社区居民月消费支出随可支配收入的增加而增加。
估计标准误差是用来说明直线回归方程代表性大小的统计分析指标,又称回归标准误差。
直线回归方程是在直线相关条件下反映两个变量之间一般数量关系的数学模型。根据直线回归方程,可以由自变量的给定值推算因变量的值。但是,推算出的因变量数值并不是一个精确数值,而是一个估计值。这就是说,由回归方程进行预测是存在误差的。误差越大,说明拟合的直线回归方程越不精确;误差越小,说明拟合的直线回归方程越精确,即代表性越大。因此,直线回归方程求出后,有必要对其拟合精度进行检测。估计标准误差就是进行这种检测的统计分析指标。
估计标准误差的计算方法主要有两种:一是定义公式,二是简捷公式。
定义公式为:
式中,syx——估计标准误差;
y——因变量实际值;
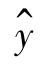 ——因变量估计值;
——因变量估计值;
n——相关数列的项数;
m——回归方程中未知参数个数。
按照上面的定义公式计算标准误差十分烦琐,运算量较大,因为它需要计算出因变量y所有的估计值。在实践中,在已知直线回归方程的情况下,通常用下面的简捷公式计算估计标准误差:
例8-4 仍采用表8-2所示的资料说明估计标准误差的计算方法。估计标准误差计算表如表8-9所示。
表8-9 估计标准误差计算表
根据定义公式有:
可见两个公式计算的结果是一致的。当然,有时两种方法计算结果不完全一致,这是由计算过程中小数的取舍造成的少许出入。
回归方程的最有效用途就是在给定自变量数值x=x0的前提下,用来推算因变量的数值y=y0。按照估计的准确程度不同,分为点估计与区间估计两种方法。
点估计方法是指将自变量数值x=x0代入回归方程,用计算的回归估计值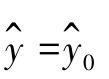 直接作为因变量y0的估计值。
直接作为因变量y0的估计值。
区间估计方法是指以回归估计值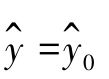 为基础,得出因变量y0在一定概率保证下可能取值的一个区间范围。这个区间也叫置信区间,对应的概率也叫置信度。当因变量y为正态分布,且n较大(n≥30)时,置信区间的一般形式为:
为基础,得出因变量y0在一定概率保证下可能取值的一个区间范围。这个区间也叫置信区间,对应的概率也叫置信度。当因变量y为正态分布,且n较大(n≥30)时,置信区间的一般形式为: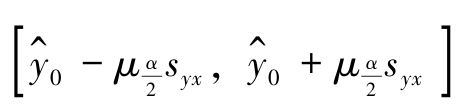 ,其中
,其中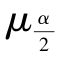 表示与置信度对应的标准正态概率双侧临界值,其他符号与前相同。
表示与置信度对应的标准正态概率双侧临界值,其他符号与前相同。
例8-5 接例8-4所示,假设同一社区某居民家庭2010年月可支配收入为11万元,在95%的概率保证下,估计其消费支出。
y0=-0.208 9+0.717 7×11≈7.69(百元) (点估计)
y0=7.69±1.96×3.55(百元)
即y0在0.73~14.65百元(区间估计)。
这种利用回归方程进行的估计在日常社会经济生活中经常用到,它是一种重要的管理工具。值得注意的是,回归方程只能以自变量x推算因变量y,而不能反过来以因变量y推算自变量x。如例8-5中,仅能依据可支配收入去推算消费支出。在互为因果关系的变量之间或者变量之间因果关系不明显时,可以根据研究问题的需要,分别建立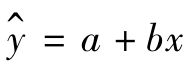 和x=c+dy两个一元线性回归方程,利用后者就可以根据y推算x。当然,这两个回归方程的意义是不同的,切不可滥用。
和x=c+dy两个一元线性回归方程,利用后者就可以根据y推算x。当然,这两个回归方程的意义是不同的,切不可滥用。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











