



第二节 一元线性回归分析
一、回归分析的特点
回归分析是应用统计方法寻找一数学方程,建立自变量与因变量之间的关系,并据以利用自变量的给定值来推算或估计因变量的值。对于回归分析来说,需要确定哪个是自变量,哪个是因变量。如人的身高与体重的关系,以身高为自变量,则以体重为因变量;反之若以体重为自变量,则以身高为因变量。但是有些现象的两个变量之间不能互换。例如,炉膛温度和出铁量,只能以炉膛温度为自变量,出铁量为因变量,分析炉膛温度对出铁量的影响,而反过来分析出铁量对炉膛温度的影响则没有意义。在回归分析中,要求因变量是随机变量,自变量是非随机变量,是给定的数值。
回归分析可分为线性回归(Linear regression)与非线性回归(Currilinear regression),对线性回归与非线性回归的区分有两种理解,一是按回归变量本身是否线性,即是否一次式来划分,例如,y=β0+β1x1+β2x2+β3x3+ε为三元线性回归方程,而y=β0+β1x+β2x2+β3x3+ε为一元三次非线性回归方程。二是按回归变量的参数即回归系数(Regression coefficient)是否线性来划分,例如,上例两式都是线性方程,因为它们的回归系数β1、β2、β3都是线性的(一次式),而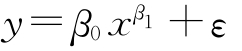 是非线性回归,因y不是两参数β0、β1的线性函数,β0与β1是用乘法和指数方法连在一起的。在应用研究中,常见到的是按变量是否一次性来划分线性与非线性回归方程,因此我们沿用这种观点。
是非线性回归,因y不是两参数β0、β1的线性函数,β0与β1是用乘法和指数方法连在一起的。在应用研究中,常见到的是按变量是否一次性来划分线性与非线性回归方程,因此我们沿用这种观点。
在线性回归分析中,对一个因变量与一个自变量的回归称一元线性回归(Linear regression),而一个变量与多个自变量的回归称多元线性回归(Multiple linear regression)。我们首先讨论一元线性回归。
二、一元线性回归方程
如果随机变量y随自变量X的变化而变化,且呈简单线性关系,则y依x变化的规律可用一元线性回归方程表示。由于随机因素的干扰,y与x线性关系中包含随机误差项ε,即有:y=β0+β1x+ε。
例7-1:钢铁工业固定资产投资总额与钢产量之间有较密切的关系。现将某钢铁公司1993~2002年的有关资料列于表7-1。
表7-1 某钢铁公司固定资产投资总额及钢产量统计表
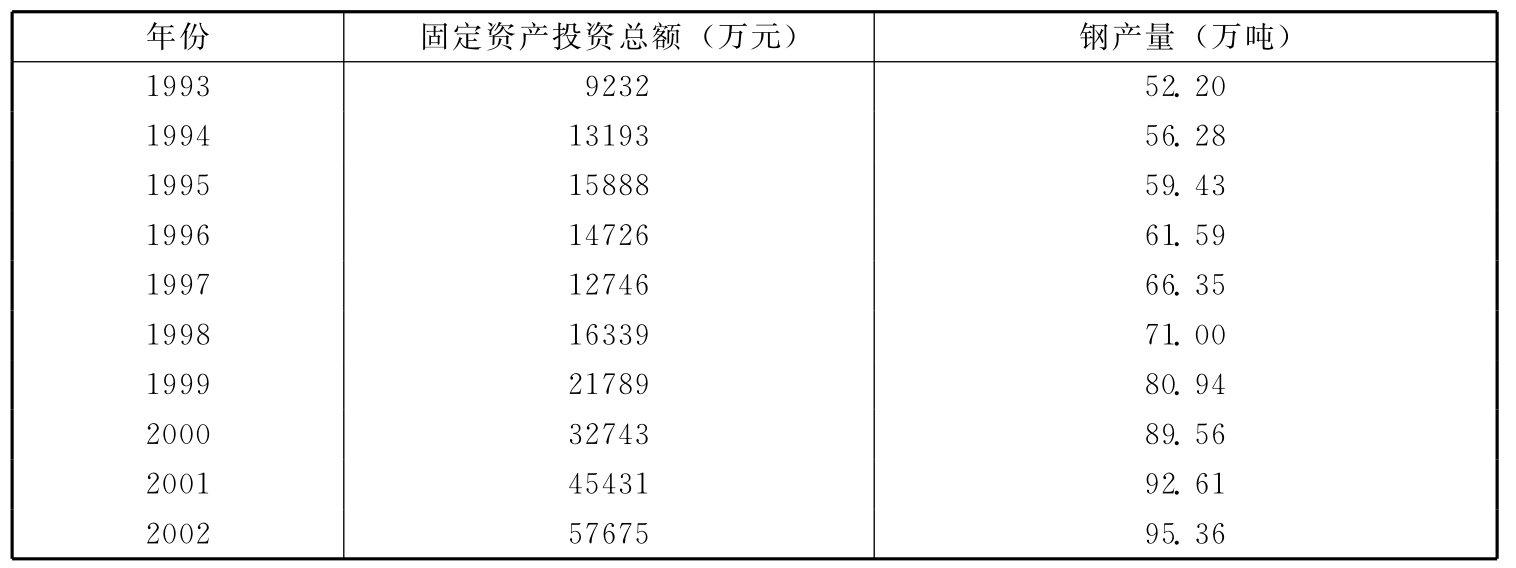
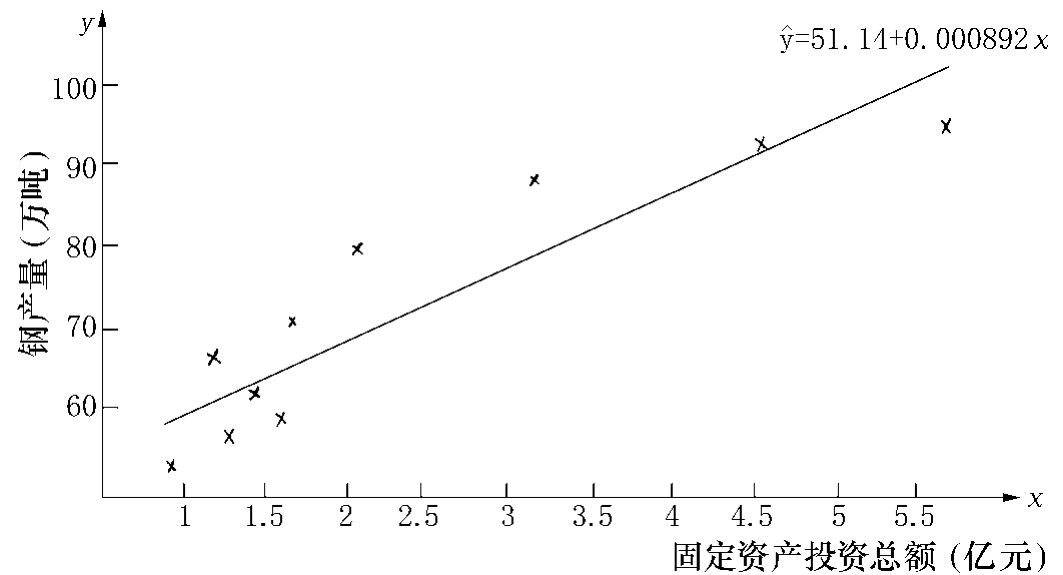
图7-1 1993~2002年某钢铁公司固定资产投资总额与钢产量散点图与回归线
计算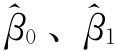 可有不同的方法,统计中使用最多的是最小平方法,或称普通最小二乘估计(Ordinary Lease Square Estimation,简记为OLSE),就是通过要求各散点到回归线的距离平方和最小来求得回归线,这时所求的回归线是最适线。即
可有不同的方法,统计中使用最多的是最小平方法,或称普通最小二乘估计(Ordinary Lease Square Estimation,简记为OLSE),就是通过要求各散点到回归线的距离平方和最小来求得回归线,这时所求的回归线是最适线。即
![]()
将回归方程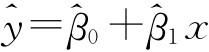 代入Q有:
代入Q有:
![]()
求Q对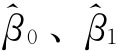 的偏导数并令其为0,即
的偏导数并令其为0,即
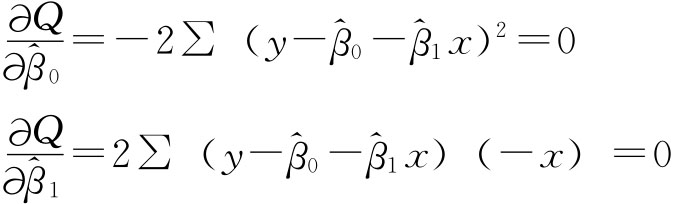
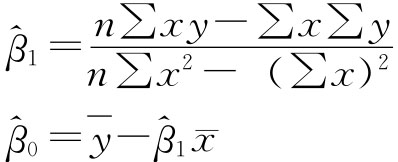
![]()
这说明回归线通过点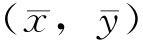 ,这是我们做回归直线的图形时应当注意的。
,这是我们做回归直线的图形时应当注意的。
若将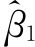 式的子项、母项分别除以n,则:
式的子项、母项分别除以n,则:
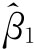 式子项:
式子项:
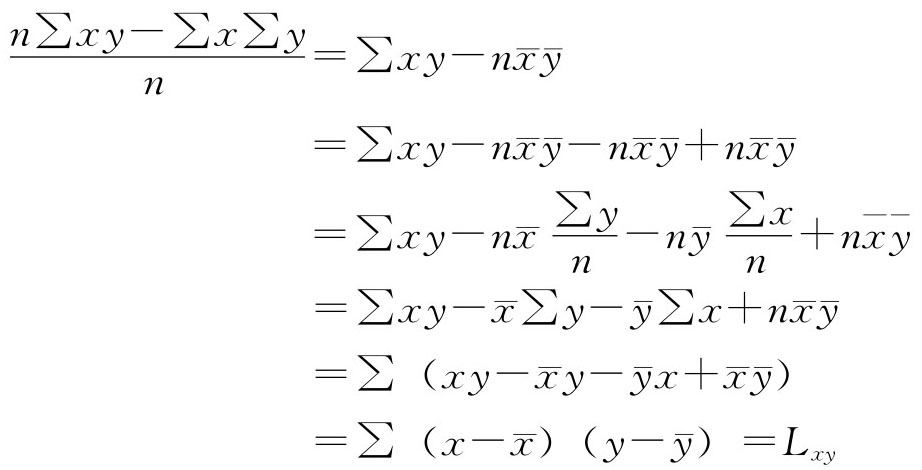
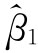 式母项:
式母项:
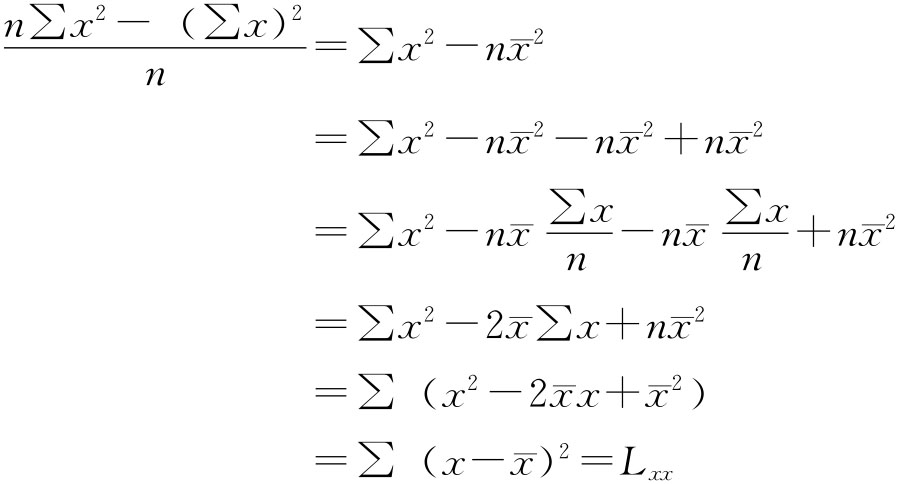
故 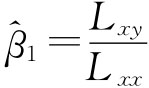
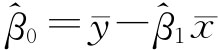
根据例7-1资料,计算回归系数估计值的计算步骤可列表进行,其计算步骤如下(见表7-2):
表7-2 回归系数估计值计算表

由表7-2可知:
∑x=239762 ∑y=725.32
∑x2=8095238086 ∑y2=54903.26 ∑xy=19484694.37
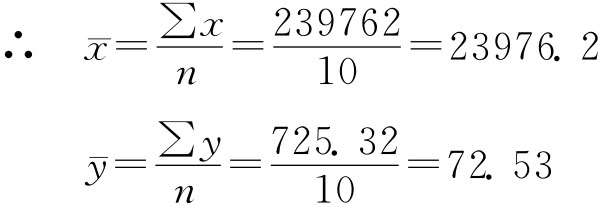
则

故:
所求回归方程为:
![]()
根据这个方程式,把10年的固定资产投资总额的实际值(x)逐项代入,就可算出对应的钢产量估计值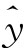 (见表7-2末栏),并可在散点图上画出回归直线(见图7-1),这条直线的斜率为0.000892,表示某钢铁公司的钢铁工业固定资产投资总额每增加1万元,钢产量平均增加8.92吨。
(见表7-2末栏),并可在散点图上画出回归直线(见图7-1),这条直线的斜率为0.000892,表示某钢铁公司的钢铁工业固定资产投资总额每增加1万元,钢产量平均增加8.92吨。
三、估计标准误差
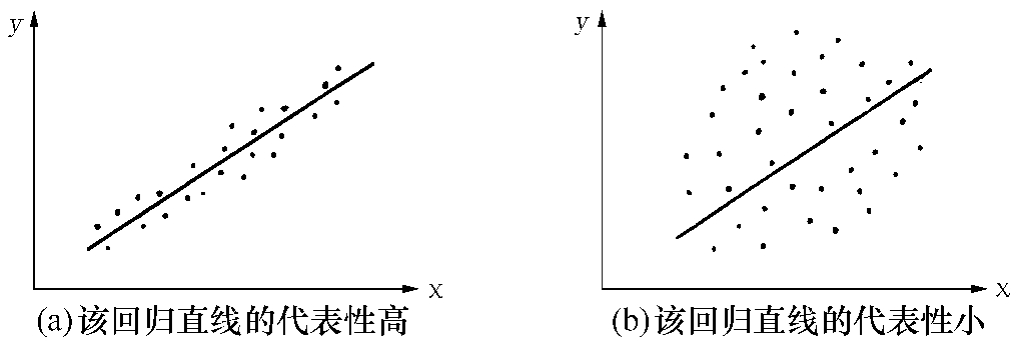
图7-2 数据点的分散程度与回归直线代表性的对照
估计标准误差就是用来反映与y之间估计误差大小,说明估计值准确程度的统计指标,记为Sy,意思是各观察值与估计值估计误差的平均值。
![]()
式中:n-2表示自由度,因为n个数据点在求得回归系数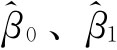 后,受两个正规方程的限制,丧失了两个自由度,因此用n-2。
后,受两个正规方程的限制,丧失了两个自由度,因此用n-2。
为了进一步说明估计标准误差,下面对随机变量y的总变差进行分析。
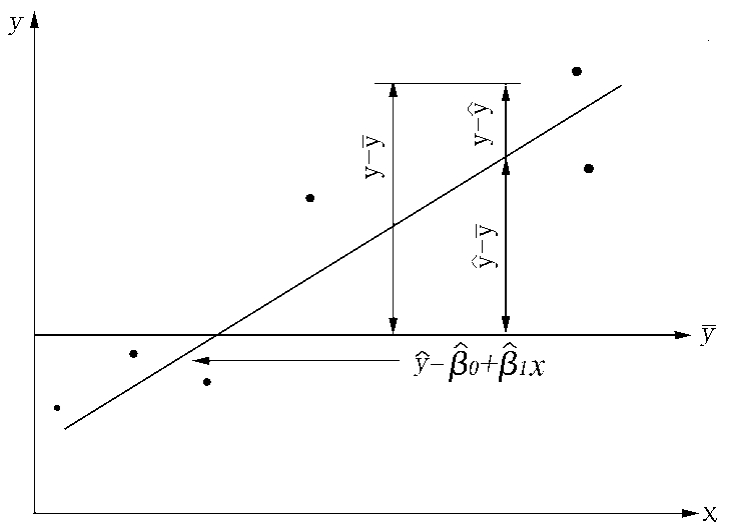
图7-3 总变差分解图
![]()
所以总变差:
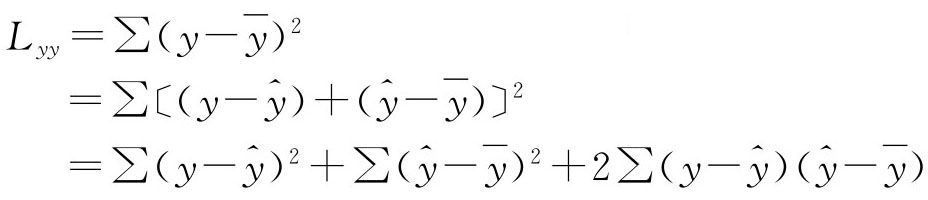
上式中:

总变差、回归变差、剩余变差的关系式可写为:
![]()
回归变差与剩余变差的计算:
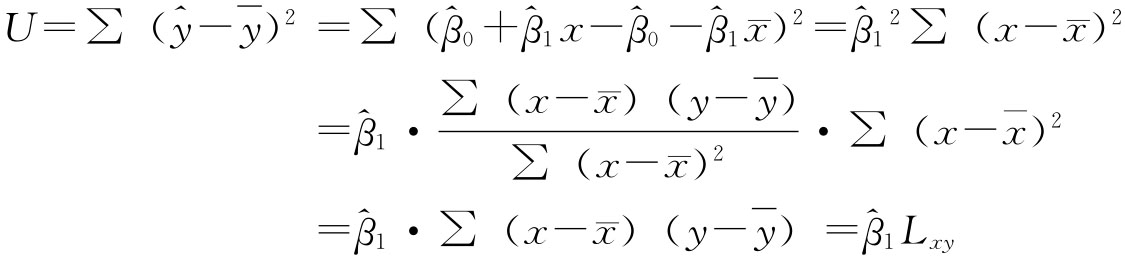
可见,有了回归系数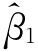 ,回归变差就可以通过上式求得。至于剩余变差可按下式求得:
,回归变差就可以通过上式求得。至于剩余变差可按下式求得:
![]()
则
![]()
根据例7-1的资料代入上式得:
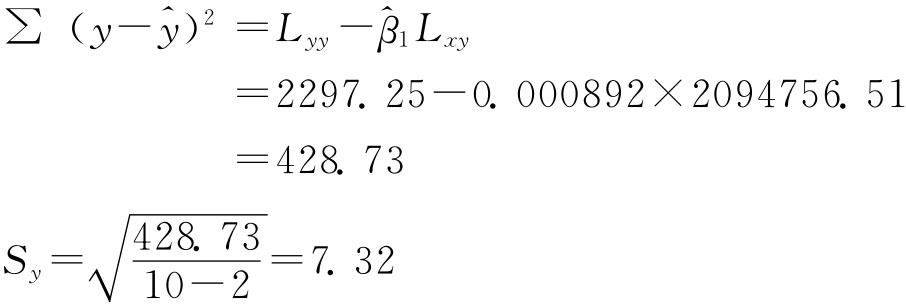
四、回归方程的显著性检验(Significance tests)
估计标准误差的大小可以反映回归直线的精确度,即x与y之间的线性相关程度。但判定估计标准误差的大小要有一个基准,即当估计标准误差为多少时我们就可以认为回归方程的线性关系显著,回归直线具有代表性。数理统计学中选取统计量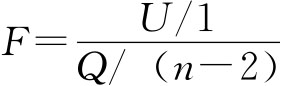 即U与Q的比例大小来体现x与y的线性相关关系的相对大小。根据F值的大小来判定回归直线的斜率β1是否等于0,即假设H0:β1=0,如果否定了H0,也即判定x与y间有线性相关关系。那么在什么情况下否定H0呢?数理统计中可以证明,在假设H0成立时,统计量F服从自由度为1,n-2的F分布,因此对于给定的检验标准α(即显著性水平),查自由度为1,n-2的F分布分位数表,得临界值Fα(1,n-2),将其与算得的F值进行比较,如果F>Fα(1,n-2)则否定假设“H0:β1=0”,即认为x,y间具有显著的线性相关关系,否则假设H0是相容的,即没有理由认为x,y间存在显著的线性相关关系。
即U与Q的比例大小来体现x与y的线性相关关系的相对大小。根据F值的大小来判定回归直线的斜率β1是否等于0,即假设H0:β1=0,如果否定了H0,也即判定x与y间有线性相关关系。那么在什么情况下否定H0呢?数理统计中可以证明,在假设H0成立时,统计量F服从自由度为1,n-2的F分布,因此对于给定的检验标准α(即显著性水平),查自由度为1,n-2的F分布分位数表,得临界值Fα(1,n-2),将其与算得的F值进行比较,如果F>Fα(1,n-2)则否定假设“H0:β1=0”,即认为x,y间具有显著的线性相关关系,否则假设H0是相容的,即没有理由认为x,y间存在显著的线性相关关系。
例7-2:以例7-1关于钢铁工业固定资产投资总额与钢产量为例,进一步检验这两个变量在显著性水平α=0.05时线性相关关系是否显著。
已知: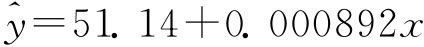
Lxx=2346656422
Lyy=2297.25
Lxy=2094756.51
n-2=10-2=8
则:
![]()
Q=Lyy-U=2297.25-1868.52=428.73
![]()
查附录二表5bF分布表,F0.05(1,8)=5.32
由于34.87>5.32,所以否定假设H0:β1=0,即认为钢铁工业固定资产投资总额与钢产量之间存在着显著的线性相关关系。
五、利用回归方程进行预测与控制
如果回归方程显著性高,则可利用它对因变量y做预测和控制。
预测就是根据自变量x的某一已知值x0,估计因变量y的相应值y0的可能范围。
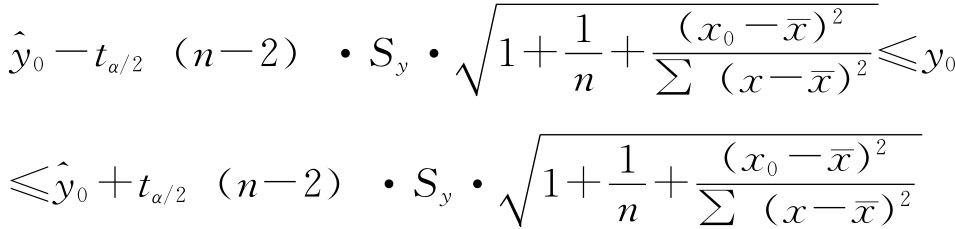
当x0取值在 附近,n又比较大时,y0在1-α置信水平下的预测区间为:
附近,n又比较大时,y0在1-α置信水平下的预测区间为:
![]()
实际应用时,常常采用这一区间作为因变量y相对应于自变量x0的回归预测区间。
例7-3:根据例7-1建立的回归方程,取固定资产投资额x0=16000万元,求在置信水平为95%时钢产量的预测区间。
解:根据例7-1计算有:
![]()
由置信水平1-α=95%,自由度=n-2=8,查t分布表得
tα/2(n-2)=t0.025(8)=2.306
且当x0=16000时:
∴钢产量y0的预测区间为:
![]()
即:
也就是说,我们可以95%的概率保证,当固定资产投资额为16000万元时,钢产量在47.52万吨与83.30万吨之间。
控制则是预测的反问题,即要求观测值在某区间(y1,y2)内取值时,问x应控制在什么范围内。也即要求以一定的置信度求出相应的x1、x2,使得x1<x<x2时,x所对应的观测值y落在(y1,y2)内。如当置信度为95.45%时,可利用
![]()
解出x1,x2作为控制x的上下限。显然,要实现控制,必须使区间(y1,y2)的长度小于4Sy,即应有y2-y1<4Sy。
六、对总体回归方程参数的区间估计
若显著性水平为α,则β1的1-α的置信区间为:
![]()
若显著性水平为α,则β0的1-α的置信区间为:
![]()
例如,在显著性水平α=0.05时,利用例7-1中的资料及计算结果对总体回归方程参数β0、β1进行估计。
参数β0的估计:
α=0.05时,tα/2(n-2)=t0.025(8)=2.306
由前知:
Sy=7.32 ∑x2=8095238086 Lxx=2346656422
故
![]()
则
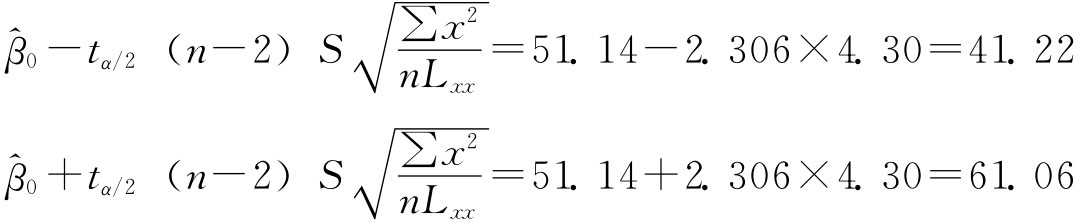
即
41.22≤β0≤61.06
参数β1的估计:
![]()
则
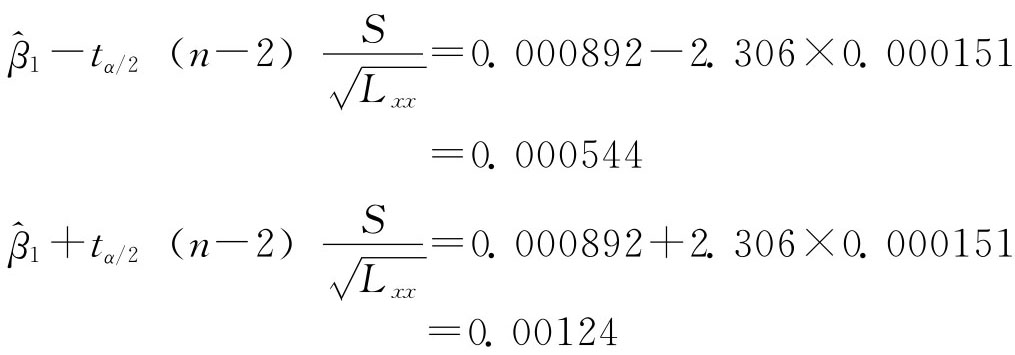
即
0.000544≤β1≤0.00124
因此,有95%的把握确信总体回归方程参数β0落在41.22~61.06之间;参数β1落在0.000544~0.00124之间。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。












