



二、对总体的估计
抽样分布描述了当总体参数已知的情况下,样本统计量的分布情况是怎样的。但实际上,如果不通过普查,是难以知道总体参数的值的,往往需要用样本的数据对总体的情况进行估算。抽样分布就是对总体进行估算的依据。
对总体的估算方法有两种:点估计和区间估计。所谓点估计,就是直接把计算到的样本统计量的值当做相应的总体参数的值。例如,从一项全国电视观众的调查样本中计算出这些样本个体平均每天收看电视的时间是X=100分钟,就认为全国的电视观众平均每天收看电视的时间μ就是100分钟。点估计虽然能够把一个明确的值赋予给总体参数,但由于样本均值近似正态的波动性,所以这样估计让人觉得没有把握,不知道犯错误的可能性会有多大。而另一种估计方法则可以一定的把握来保证估计的正确性,这就是区间估计,它会在一定的把握下给出一个包含总体参数的置信区间。
(一)置信区间的概念
为了便于说明,首先来看一个例子:某个电视节目的收视率正在呈下降趋势,其制片人正面临着一个重大决策——对节目进行全面的改版,可是该节目长期以来已经拥有了一些固定的观众,节目改版又怕影响到这些观众。于是该制片人就决定,如果该节目的所有观众对改版的支持率不到50%,就不进行改版,因为改版后需要重新培养观众群。为了估计所有观众的支持率,他委托一家专业的媒介调查机构对其观众进行了一次电话访问,样本量为400人。可以把这个样本看成一个简单随机样本。电话访问的结果是:这400人之中有232人支持其节目改版,支持的比例是P=232/400=58%。这个比例大于50%,似乎是对改版有利的证据。
但是,该制片人学过统计学的知识,他和做调查的机构都清楚地了解:如果再抽一个400人的简单随机样本,无疑会得到不同的结果——也许会是60%或者51%,甚至是令人担心的47%。总体中真正支持改版的比例有多大?现在的58%又能说明什么问题呢?
我们已经知道,样本比例P服从一种正态分布。为了讨论方便,现在假定该节目的所有观众支持节目改版的比例π=55%,则样本比例P就服从π=55%、标准误差SE=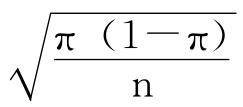 =0.025的正态分布,如图3—27所示。
=0.025的正态分布,如图3—27所示。
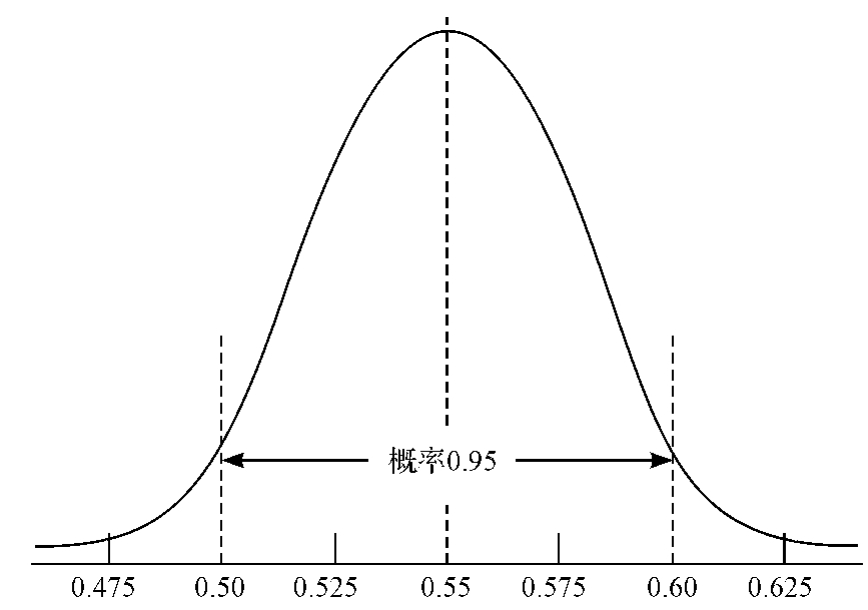
图3—27 大小为400的SRS中,支持节目改版的观众的比例的抽样分布(分布的中心是0.55,P落在左右2个标准差范围内的概率是0.95)
该分布具有正态分布的任何性质,如68.3—95—99.7规则中的“有95%的取值落在左右距均值2个(严格说是1.96个)标准差的范围内”,即“从该节目所有观众的总体所抽出来的大小为400人的一个SRS,其P值会在均值π左右各两个标准误差范围内(0.50~0.60)的概率是95%”。
不过这里分布的中心0.55是一个假定的数,实际上分布的中心π是未知的(如果已知,就不用作调查并屈就用样本比例去估计了)。但是不管这个比例π是否已知,样本比例P都会围绕着它正态波动,且仍然具有“其P值在均值π左右各两个标准误差范围内波动的概率是95%”。
此处的概率95%应当这样理解:从总体中不停地抽取一个个400人的随机样本,得到的P1,P2,P3…中,会有95%的值落在距π左右各两个标准误差范围内。我们再来看图3—28。
图3—28下部的一个个小黑点相当于重复抽样时每次得到的P值,从小黑点向左右各画出2SE的距离,形成一个区间。从图中可以看出,如果一个P值落在了上部所画的正态分布中(π-2SE,π+2SE)的区间内,则以该P值构造的区间(P-2SE,P+2SE)就会包含π值,如图中的各个用实线作出的区间;如果一个P值落在了正态分布中(π-2SE,π+2SE)的区间外,则以该P值构造的区间(P-2SE,P+2SE)就不会包含π值,如图中的两个用虚线作出的区间。现在已经知道P值会落在(π-2SE,π+2SE)之间的概率是95%,也就是说,重复抽样100次,会有95次的P值都会落在(π-2SE,π+2SE)中。
对于从一个调查样本中得到的P值58%,会有95%的机会落在区间(π-2SE,π+2SE)中,因此以它构造的区间(58%-2SE,58%+2SE)就会有95%的机会包含总体的π。这样得到的区间就叫做总体π的95%的置信区间。其中95%就叫做置信度或置信水平,也就是把握度的意思,即所构造的区间有95%的把握会包含真正的总体比例π。
对95%的把握,只有两种可能的结果:一是真正的π就在(P-2SE,P+2SE)之间;二是他抽中的样本是少数几个P不在(π-2SE,π+2SE)之中的样本之一,这样的话,他的运气实在不好,因为只有5%的样本才会这样,也就是说,这样的事情在20次中只会发生1次。
现在,剩下的工作就是如何计算这个置信区间大小的问题了。我们知道,当π已知时,可以用π计算P的抽样分布的标准误差SE=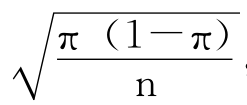 ,但是现在π是未知的,我们只能用一个值去代替π,而能找到的最好替代值也就是样本的比例P了。所以由一个P值构造的关于π的95%的置信区间就是
,但是现在π是未知的,我们只能用一个值去代替π,而能找到的最好替代值也就是样本的比例P了。所以由一个P值构造的关于π的95%的置信区间就是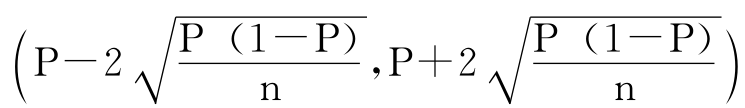 ,表示为:
,表示为:
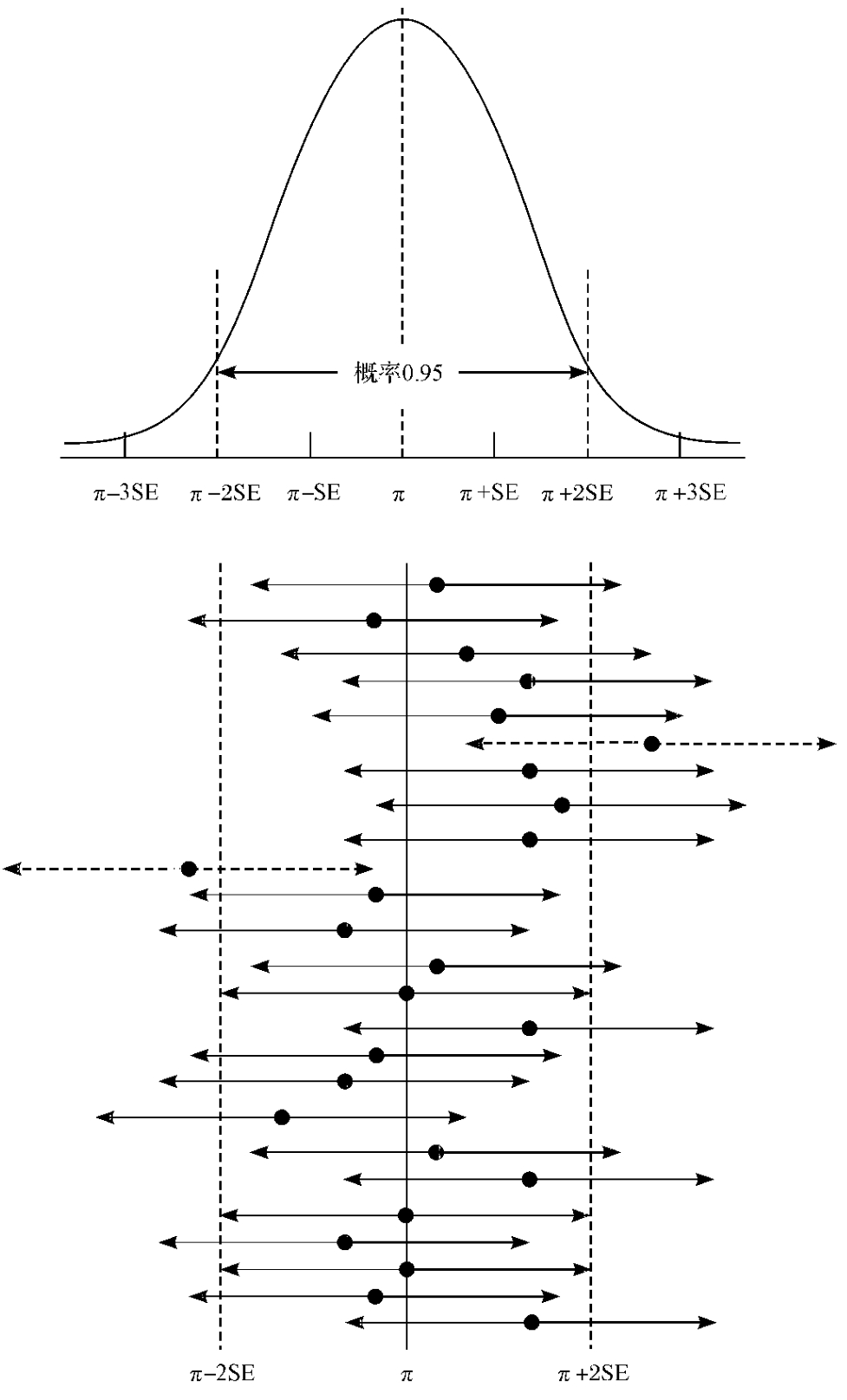
图3—28 重复抽样得到的置信区间的变化(这样的区间中有95%会包含真正的π值)
![]()
根据样本比例58%构造的关于总体π的95%的置信区间就是:
π=P±2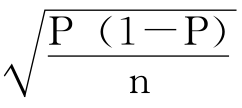
=0.58±2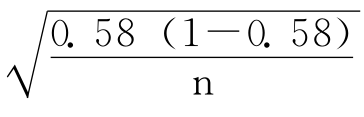
=0.58±0.049
即(53.1%,62.9%),也就是说,在95%的把握下,该节目的全部观众支持节目改版的比例在53.1%到62.9%之间。这个比例大于50%,制片人就可以去做改版的工作了。
不过对于改版这个重大决策,制片人认为更小心一点才好,他不满意只有95%的把握,他要求有99%以上的把握。根据正态分布的性质,我们可以认识到“从该节目所有观众的总体所抽出来的大小为400人的一个SRS,其P值会在均值π左右各3个标准误差范围内的概率是99.7%”。用同样的方法,则可以计算出关于π的99.7%的置信区间是:
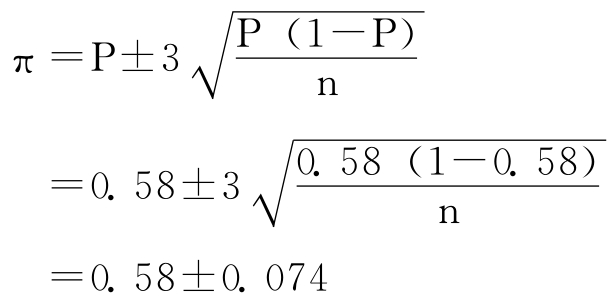
即(50.6%,65.4%),也就是说,在99.7%的把握下,该节目的全部观众支持节目改版的比例仍大于50%,这下制片人就完全放心了。
通过比较可以发现,在99.7%把握下构造的置信区间(50.6%,65.4%)比在95%的把握下构造的置信区间(53.1%,62.9%)要宽。一般来说,在把握度和置信区间宽度之间,没有办法做到两全其美。如果要从同一个样本中要求较高的置信度,就必须接受较宽的区间范围,除非在调查时增加样本量。当样本量增加时,抽样分布的标准误差变小,样本量越大,置信区间就越窄。
(二)几种常用的置信区间
虽然置信区间的概念自始至终是一致的,但根据所估计的总体参数不同,估计的公式各不相同。下面就给出几种常用置信区间的计算公式。
1.总体比例的置信区间
在上例中,已经介绍了总体比例π的95%的置信区间和99.7%的置信区间的计算公式,现在要关心的是对于任意的置信度1-α(α是介于0和1之间的一个正数),置信区间应该如何计算。
根据正态分布的性质,对于任何一个0到1之间的概率C,可以反查附录Ⅱ得到一个数Z0,使得Z变量分布在均值0左右两侧各Z0个标准差范围内的概率是C,Z0就叫做正态分布的临界值(critical value)。当C=1-α时,标准正态分布的右侧尾部概率是α/2,所以常用Zα/2来表示这个临界值,如图3—29所示。当求95%的置信区间时,我们应该用数值1.96(上例中用的2是1.96的近似值),实际上就是临界值Z0.025。
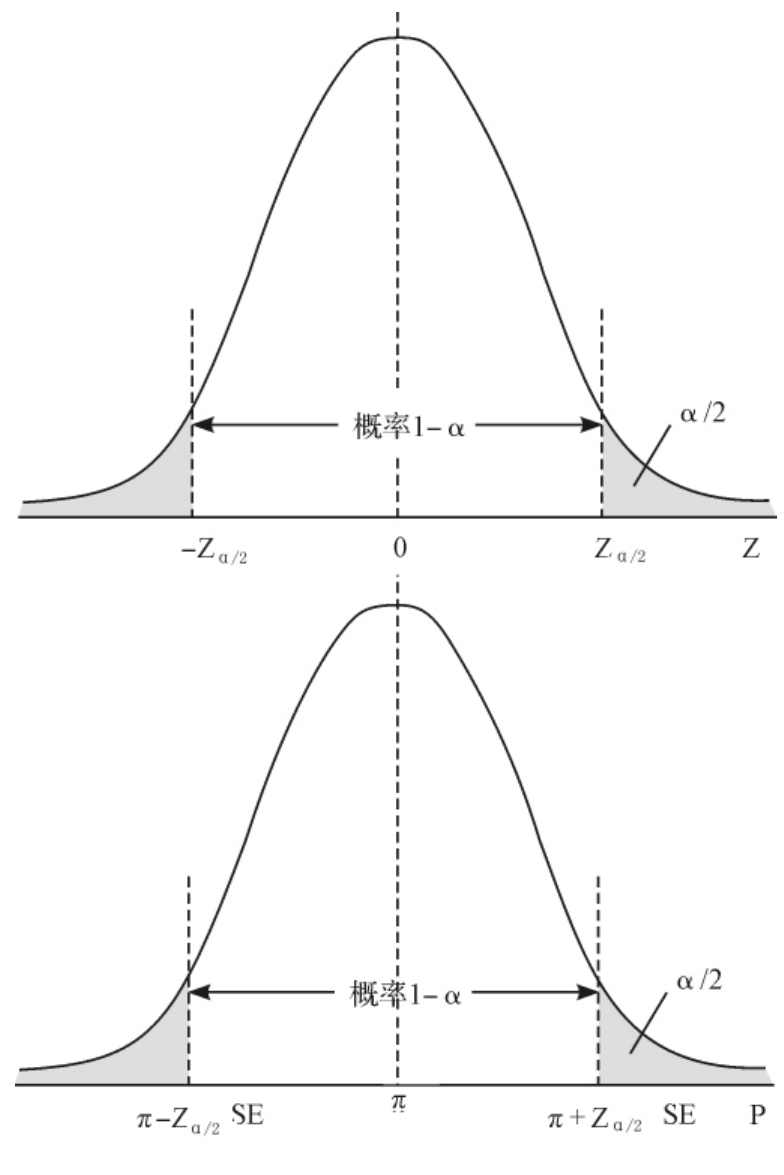
图3—29 正态分布的临界值
从图3—29中可以看到,样本比例P的值在π的Zα/2个标准误差范围内的概率是1-α,这就是说,从样本比例P往左右各延伸Zα/2个标准误差所得到的区间会包括未知的π值的概率是1-α,并用P代替π计算标准误差SE(用P计算的是标准误差SE的估计值),就产生了下面的公式:
总体中具有某种特征的单位所占的比例是π,从总体中抽取大小为n的SRS,当n足够大的时候,π的置信度为1-α的置信区间是:
π=P±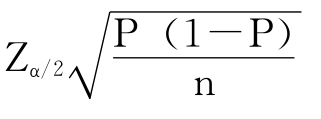
需要注意的是,只有当样本是简单随机样本SRS,而且n>120时,这个公式才适用,因为这时才能用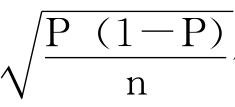 估计标准误差SE。
估计标准误差SE。
2.总体均值的置信区间
总体均值的置信区间估计因研究的问题和已知条件不同而用不同的方法。
(1)当总体标准差σ已知时。根据样本均值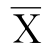 的抽样分布,对于给定的置信度1-α,可以查附录Ⅱ得出相应的临界值Zα/2。π的置信度为1-α的置信区间的计算公式:
的抽样分布,对于给定的置信度1-α,可以查附录Ⅱ得出相应的临界值Zα/2。π的置信度为1-α的置信区间的计算公式:
![]()
式中,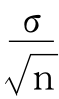 是标准误差SE,常用来表示抽样误差,
是标准误差SE,常用来表示抽样误差,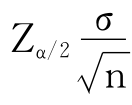 为一定倍数的抽样误差,称为极限误差,或误差范围、误差允许量,用Δ表示,其意义是对给定的置信度进行区间估计时所允许的最大误差。
为一定倍数的抽样误差,称为极限误差,或误差范围、误差允许量,用Δ表示,其意义是对给定的置信度进行区间估计时所允许的最大误差。
(2)当总体标准差未知时。实际上,总体均值μ未知,而总体标准差σ已知的情况是不常有的,通常的情况是μ和σ都是未知的。这时可用样本标准差S来代替总体标准差σ,而根据t分布计算置信区间。为了构造总体均值μ的置信区间,令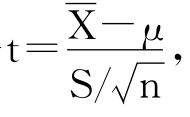 随机变量t服从自由度为n-1的t分布,即t~t(n-1)。附录Ⅲ列出了不同自由度的t分布的临界值点。当样本量n>120时,t分布非常接近正态分布,可以按正态分布看待。图3—30比较了t分布和标准正态分布。
随机变量t服从自由度为n-1的t分布,即t~t(n-1)。附录Ⅲ列出了不同自由度的t分布的临界值点。当样本量n>120时,t分布非常接近正态分布,可以按正态分布看待。图3—30比较了t分布和标准正态分布。
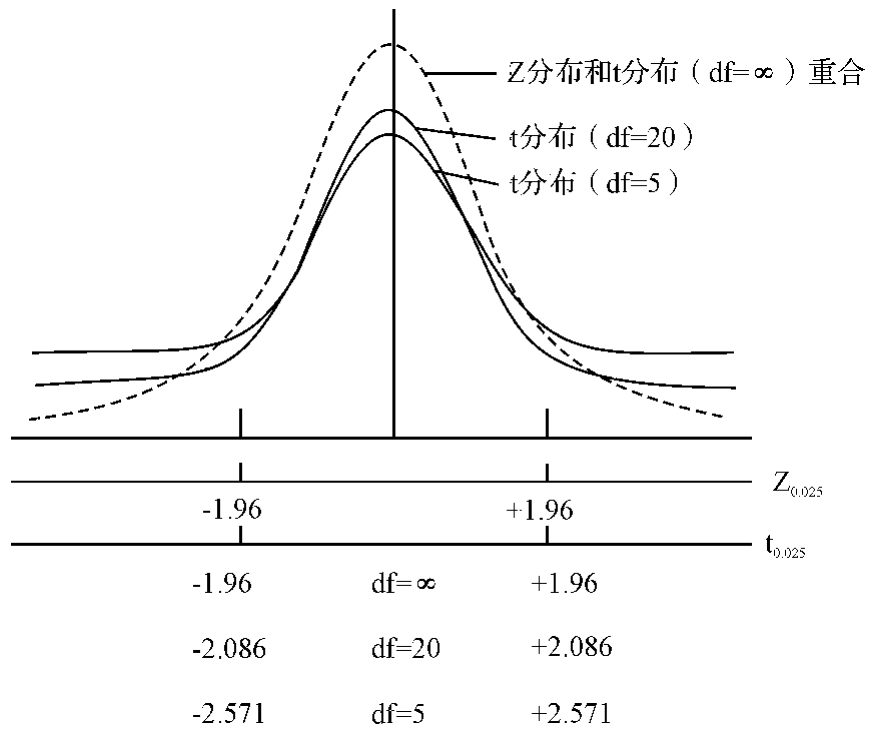
图3—30 t分布和标准正态分布的比较
给定置信度1-α,可以查t分布的临界值表得出自由度为n-1的t分布的临界值tα/2。μ的置信度为1-α的置信区间的计算公式为:
![]()
3.两个总体均值之差μ1-μ2的置信区间
假定两个样本来自两个相互独立的总体,样本量分别为n1和n2。
(1)当两个总体的标准差σ1和σ2已知时。已知X1-X2服从均值为μ1-μ2,标准误差SE=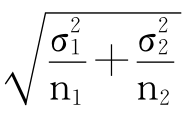 的正态分布,则两个总体均值之差μ1-μ2为1-α的置信区间为:
的正态分布,则两个总体均值之差μ1-μ2为1-α的置信区间为:
μ1-μ2=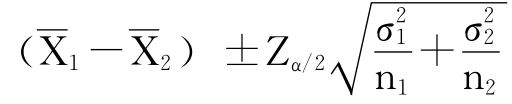
(2)当两个总体的标准差未知但相等时。设总体的标准差σ1=σ2=σ。已知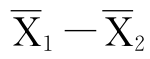 服从均值为μ1-μ2,标准误差SE=
服从均值为μ1-μ2,标准误差SE=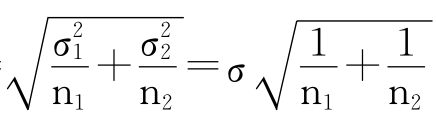 的正态分布。令
的正态分布。令
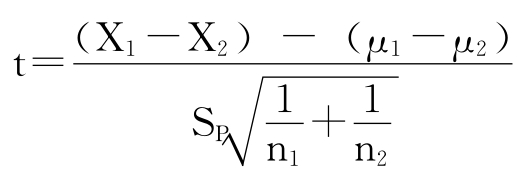
其中:
![]()
SP是总体标准差σ的一个估计量,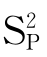 称为联合方差。可以证明,这样构造的t服从自由度为n1+n2-2的t分布。因此,μ1-μ2的置信度为1-α的置信区间为:
称为联合方差。可以证明,这样构造的t服从自由度为n1+n2-2的t分布。因此,μ1-μ2的置信度为1-α的置信区间为:
![]()
(3)配对样本总体均值之差的置信区间。前两种求两个总体均值之差μ1-μ2的置信区间的方法都只适合于两个独立样本的情况。所谓独立样本有两层含义:一是指每个样本内部各元素相互独立,即在抽样时,一个样本单位的抽取不影响下一个样本单位的抽取机会;二是指两个样本组也必须是独立的,即一个样本组的抽取方式与另一个样本组无关。
配对样本是两个高度相关的样本,它们可以是对同一样本的某一特征进行两次不同测试而产生的,也可以是在同一研究中由特征相似的样本两两配对产生的,比如使用双胞胎等。在这种情况下,许多除了研究者感兴趣的特征以外的其他变量基本上都保持不变,便于将注意力集中到研究者所关心的问题上,而且常常可以得出更精确的结果。在媒介研究中,尤其是用实验法进行研究时,使用配对样本是十分有意义的。
在构造两个样本之差的置信区间时,研究者将配对样本当做同一个样本来对待。即首先求出配对样本的两两之差D=X2-X1,一旦求出这些差值,用来求这些差值的原始数据就可以不用了。然后,把这些差值D看成是一个单一的样本求置信区间,即先计算这些差值的平均值D,然后按构造单样本总体均值μ的置信区间的方法去构造总体均值之差Δ=μ1-μ2的置信度为1-α的置信区间:
![]()
采用配对样本有什么好处呢?用一个例子可进行说明。
研究者想测试一则广告对提高某品牌美誉度的作用,他们抽取了40人的随机样本,随机分为A、B两组。A组不看广告,直接对某品牌进行评分:B组先看广告,然后再对该品牌进行评分。评分的结果如表3—10所示。
表3—10 两组受试者对广告品牌的评分
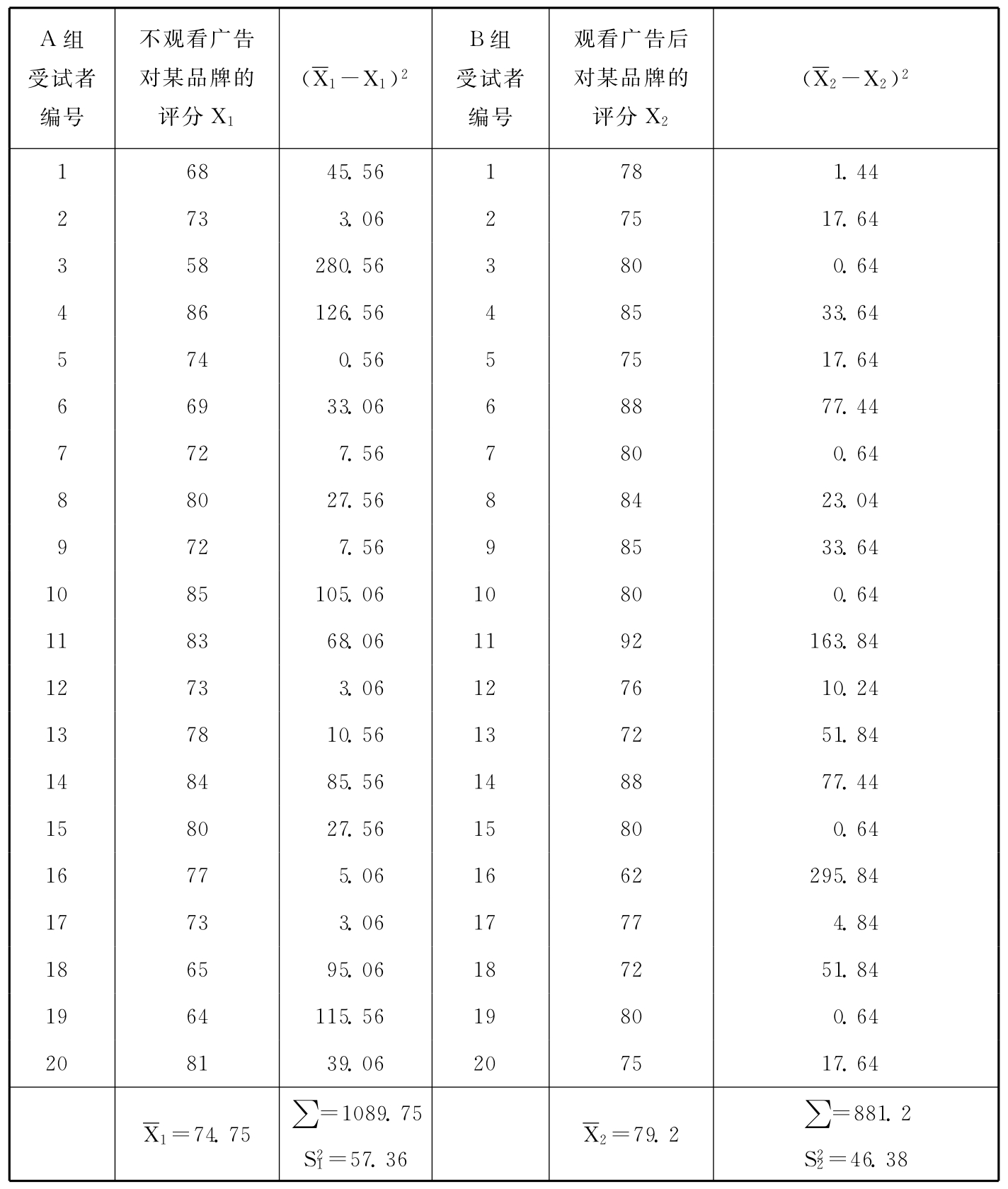
考察这则广告是否有效果,可以计算两次评分总体均值的置信区间,现计算其95%的置信区间。因为看广告前后的评分来自两个独立的样本,所以只能采用两个独立总体均值之差置信区间的公式:
![]()
根据表3—10可以得到:
![]()
查附录Ⅲ的t分布临界值点可知:
t0.025≈2.021(df=38)
则
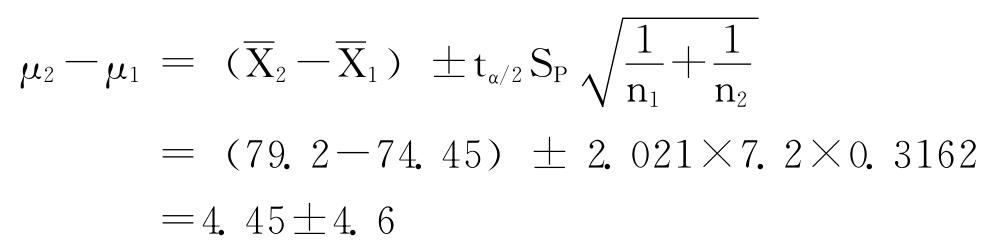
可以看出,在95%的把握下,看广告前后受试者对广告品牌评分的总体均值之差μ1-μ2在区间(-0.15,9.05)中。也就是说μ1-μ2可能是正值,也可能是负值或0,所以没有理由认为观看广告的人的评分高于没有观看广告的人的评分。没有更进一步的证据之前,现在只能接受广告对提高品牌美誉度方面没有效果这样的事实(即使这个事实可能是错的)。
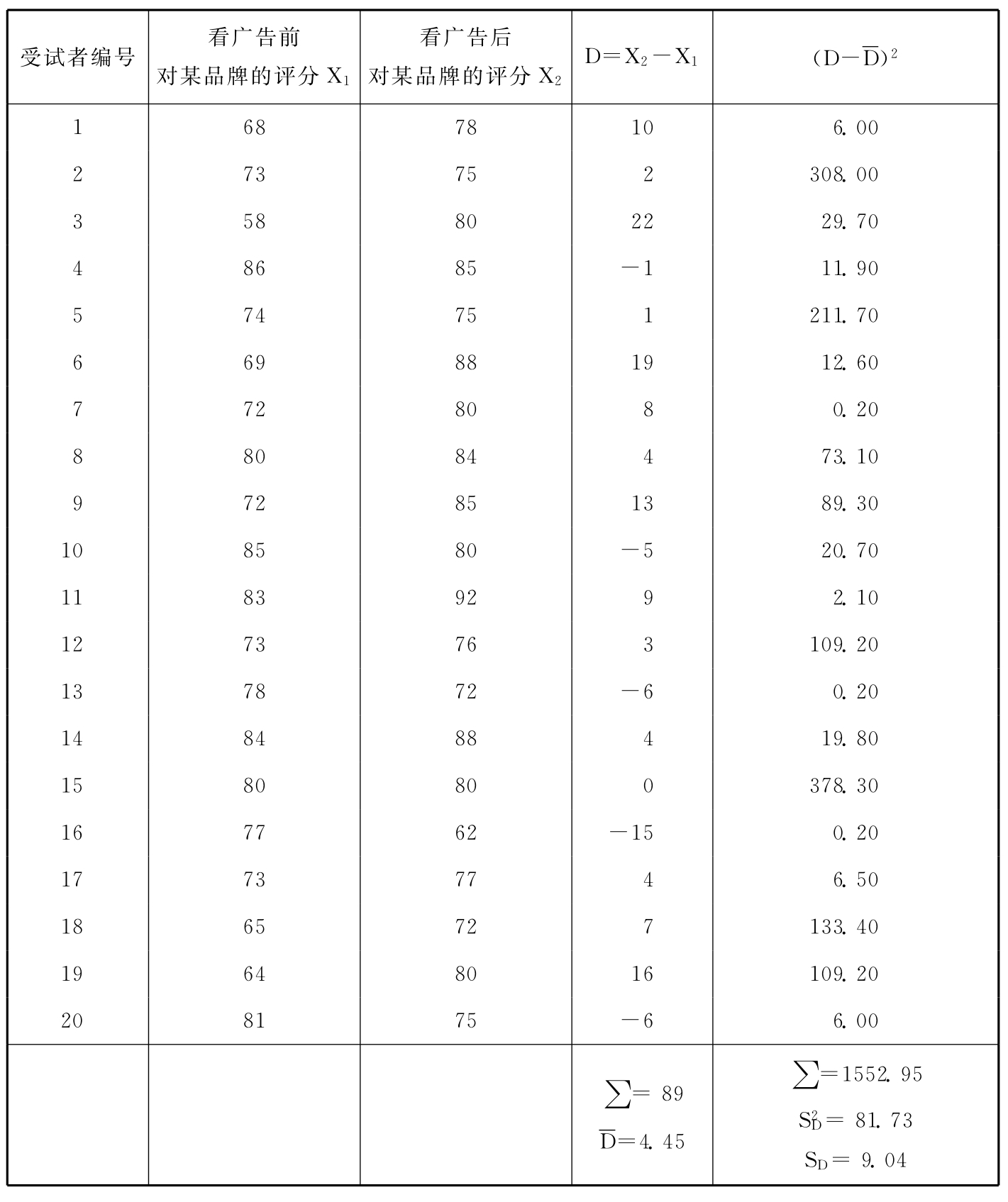
现在,假如上述数据是来自一个配对样本的,即研究者只随机抽取了20名受试者,先让他们对某品牌进行评分,然后再让他们看广告,之后再对该品牌进行评分。则可按计算配对样本总体均值之差的公式计算前后两次评分的差别,如表3—11所示。
查附录Ⅲ的t分布临界值点可知:t0.025≈2.093(df=19)
则两次评分总体均值之差的95%的置信区间是:
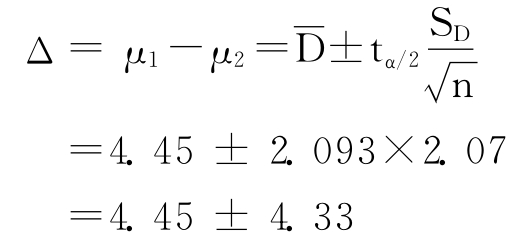
即在95%的把握下,两次评分的总体均值之差是大于0的。可以看出,用来自配对样本的数据计算总体均值之差的置信区间比用来自独立样本的数据计算的置信区间窄,这是因为配对以后使得许多外部变量都保持不变,使得研究者可以对所研究变量的总体均值之差更加有把握。很明显,如果有可能的话,在实验设计中使用配对样本是很有好处的。
表3—11 同一组样本在看广告前后对广告品牌的评分
4.两个总体比例之差的置信区间
设两个总体比例分别为π1和π2,从两总体中独立地各自抽取一个样本,样本容量分别为n1和n2。当样本量足够大时,样本比例之差P1-P2近似服从均值为π1-π2,标准误差SE=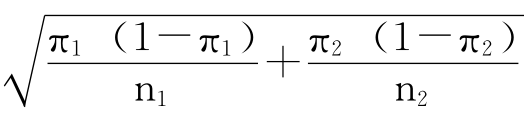 的正态分布。因为π1和π2都是未知的,所以SE要用P1和P2估计:
的正态分布。因为π1和π2都是未知的,所以SE要用P1和P2估计:
SE的估计值=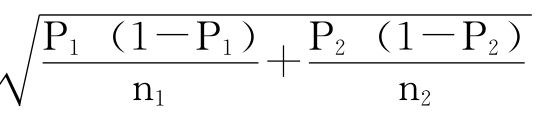
因此,π1-π2的1-α的置信区间是:
π1-π2=(P1-P2)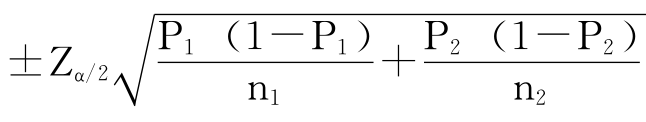
5.单侧置信区间
在许多实际问题中,我们只关心总体值所在范围的上限或下限,在这种情况下,最好是构造一个置信度为1-α的单侧置信区间,将可能犯错误的α全部放在正态曲线的左侧或右侧,如图3—31所示。
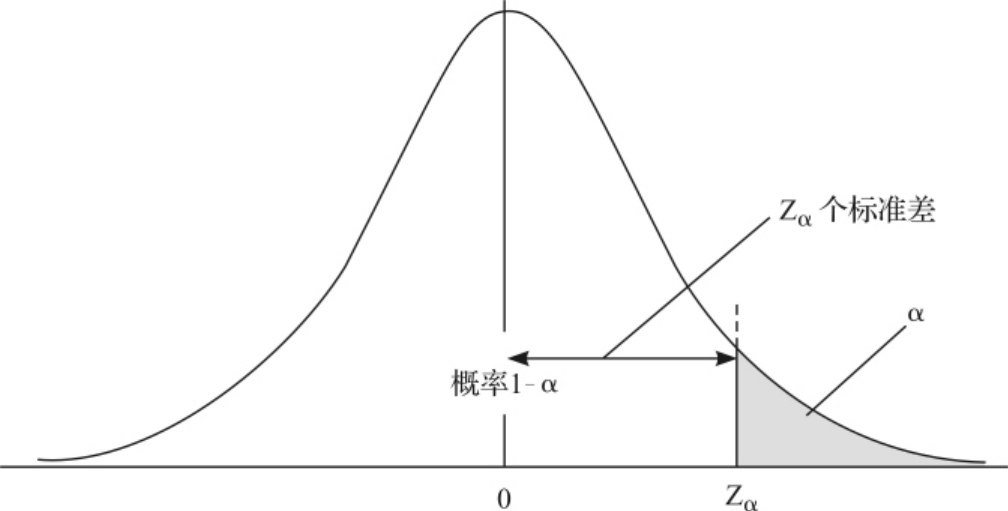
图3—31 单侧置信区间
单侧置信区间可以由相应的双侧置信区间调整,例如:
![]()
其含义是在1-α的置信度下,总体均值至少是某个数值。
![]()
其含义是在1-α的置信度下,总体均值至多是某个数值。
同样可以用类似的方法得到其他总体参数的单侧置信区间,这里不再一一说明。下面用一个例子来说明单侧置信区间的应用。
在讲置信区间概念的时候,提到某节目的制片人想根据样本比例58%获得是否应该进行改版的信息。其实这位制片人关心的是总体中支持改版的人的比例的下限,即至少会有多大比例的人支持改版,而上限他是不用考虑的。实际上只要构造一个单侧的置信区间就可以了。现在就来构造一个95%的单侧置信区间:
![]()
也就是在95%的置信度下,全部观众中至少有53.9%的比例会支持改版。
如果他仍然不放心,可以构造一个99%的单侧置信区间:
![]()
也就是说,在99%的信心下,至少有52.2%的观众会支持改版。这些结果应该使这位制片人放心了,因为在较大的把握下,全部观众的支持率并没有低于50%。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











