



三、复制动态机制(RD)
ESS只能描述系统的局部动态性质而与系统的全局动态过程无关,然而,更准确的描述一个系统的动态性质就必须仔细考察整个系统的调整过程。演化博弈专家对群体行为调整过程进行了广泛而深入的研究,提出很多群体行为调整机制,但最为广泛应用的是Taylor&Jonker(2)于1978年提出来的复制者动态方程(Replicator Dynamic,简称RD)。RD在经济领域的应用极其广泛,学者们运用RD对社会习俗、制度、行为规范等一系列社会经济问题进行了成功的研究。为了说明RD,我们回到上述的重复动态博弈模型,因为φt(s)代表在阶段t采取纯策略s的参与人集合,所以:
在t阶段采用纯策略s的期望收益为:
![]()
于是整个群体的平均期望收益为:
![]()
根据演化博弈理论的设定,有限理性的参与人有一定的统计分析能力和对不同策略收益具有事后判断能力,收益较差的参与人会发现这种差异,并学习模仿高收益参与人的策略,因此参与人类型的比例随时间而变化,是时间的函数。但比例随时间调整的速度取决于两个因素:一是模仿学习对象的数量大小(即相关类型参与人的比例);二是模仿对象的成功程度(用模仿对象的策略收益表示)。
于是有以下的连续时间动态模型:
(2)式对时间求导,有
将(5)式带入,我们得到:
![]()
复制动态与演化稳定策略(ESS&RD)一起构成了演化博弈论中最核心的一对概念,它们分别表现演化博弈的稳定状态和向这种稳定状态的动态收敛过程。对于任何两个策略的对称博弈,当某一策略是一个ESS,且仅当该策略所对应的复制动态(RD)不动,点是渐进稳定(Asymptotically Stable)的。所谓渐进稳定是指对于任何复制动态下不动点状态的微小偏离都将在t→∞中得到消除。这实际上为我们提供了判断演化稳定策略的方法。考虑一个群体对称博弈的实例,每个人采取纯策略A或B,每对策略组合的收益状况定义如下:
π(A,A)=3π(B,B)=1π(A,B)=π(B,A)=0
首先,考虑一个接近x*=0的人群状态x=x*+ε=ε,其中ε>0以保证x>0,因为x*是一个常数,所以有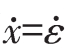 。于是我们得到:
。于是我们得到:
由于ε是一个微小变量,即ε≤1,线性化上式,有:
上式的解为:
![]()
这意味着任何对均衡状态的微小偏离都会在一个动态过程中被消除。换句话说,x*=0是渐进稳定的。
现在我们考虑x*=1的极近状态x=x*-ε=1-ε。线性化得到:
![]()
上式的解为:
ε(t)=ε0e-3t
所以x*=1也是渐进稳定的。最后我们考虑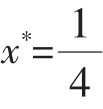 的极近状态
的极近状态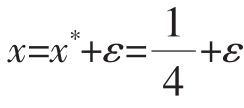 ,于是我们得到:
,于是我们得到:
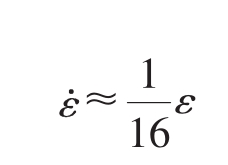
上式解为:
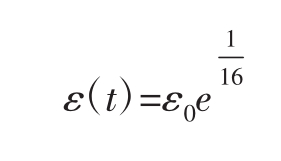
所以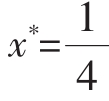 不是渐进稳定的,因此它也不是一个ESS。
不是渐进稳定的,因此它也不是一个ESS。
最后,对于演化博弈论,这里再给出几个重要引理,它们对于后文的分析和理解是必要的,但限于篇幅,这里省去证明过程。
引理1:演化稳定策略必然是纳什均衡,只有严格的(即唯一的)纳什均衡才能由演化稳定策略得出。
引理2:模仿者动态的一个稳定状态是一纳什均衡解,更一般地说,具有源于内部路径限制的任何稳态都是纳什均衡。反之,对于任何一个非纳什均衡,存在ε>0,所有内部路径最终将从该稳态的ε领域内清除。
【注释】
(1)这四种学习机制的归纳来自于Peyton Young(1998),见培顿·扬(2002)。
(2)见韦布尔(Weibull,JorgenW.)(2006)。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










