



9.2.1 风场模拟与改正
风是空气运动的表征,输送着不同属性的气团,产生热量和水分的交换,对气候的形成和变化有着重要作用。风场是指风向、风速的分布状况,不同的风场可表现不同的天气过程。按照大气运动系统的水平范围,可把大气运动分为大、中、小、微四类尺度。大尺度系统水平范围为几千千米,如大气长波、大型气旋和反气旋等;中尺度系统水平范围为几百千米,如台风、温带气旋;小尺度系统水平范围为几千米到几十千米,如雷暴、山谷风;微尺度系统水平范围为几百米至几千米,如龙卷风、积云单体等。
地球表面上的地形总体上可划分为平坦地形和复杂地形两大类,在复杂地形上的中小尺度风场的研究中,气流分布的影响因素很多,包括环境流场,近地层的物理过程,下垫面特征等。在地形较为复杂的地区,地面条件如地形起伏、海陆水陆交界、下垫面的地形条件、或者降水和云量的不均匀分布,都可能造成中、小尺度大气运动状况的改变。这种情况下的风场研究,地形的影响非常关键。
近年来,复杂地形条件下低空风场的研究日益受到人们的重视,在很多领域都进行了复杂地形条件下低空风场分析与模拟,并且取得了一定的成果。在风资源评估、气象预报、临近空间飞行器的设计、大气污染物浓度分布、森林火灾的控制等方面都有很多研究成果。风场的研究对于森林火灾的控制和预防有重要的意义。
目前,国内外对山地等复杂地形条件下的低空风场作了许多研究,主要分为预测模式和诊断模式。预测模式是基于时变的大气动力学模式方程建立的,给定初、边界条件,可以预测未来的气象状况。诊断模式主要是在离散点观测资料的基础上进行诊断,得到风场的高分辨率资料,是对过去或给定状态的静态描述。
(1)预测模式
预测模式在山地等复杂地形条件下的研究成果较多,如杨振斌等(2004年)对北京大学的准静力模式进行改进,实现了理想地形条件下的数值模拟。通过与准静力模式模拟比较,模式能够模拟气流遇到山体出现的阻塞、山顶加速、峡谷效应。陈东等(2005年)设计了基于有限元方法的中γ尺度复杂地形条件下的三维非静力边界层风场数值模式。对河南省登封市阳城工业区及周围地区进行了一小时的风场模拟,通过与观测站点实测风速比较,模式对峡谷地形的加速作用、山体的抬升与绕流均有较好的模拟。曾雪兰等(2008年)采用了NASA发布的3秒分辨率(90m)的SRTMDEM数据作为下垫面地形数据,利用中尺度大气模式MM5对以广东省为中心的风场进行了数值模拟,通过与观测站点实测风速比较,该方法对风速误差有所减少,但改善程度并不显著。
总的来说,预测模式是基于大气动力、热力学方程组建立的,物理意义清楚,能够模拟大、中尺度风场的运动、变化特征。体现了山地复杂地形对低空风场的部分影响。但和观测站点的实测风速比较,模式模拟精度有限,要求许多初、边界条件,且受温度、积云等气象因素影响,计算较为复杂,时间较长。
(2)诊断模式
对山地风场的诊断模式研究方法分为三类。
第一类是利用理论模式对过山气流湍流结构和应力变化进行探讨。袁春红等(2002年)应用GUIDE模式,综合考虑地表粗糙度、测风高度、地形参数等因子对风速的影响,对距山顶10m处10min平均最大风速和平均风速进行了模拟试验,取得了较高精度的模拟山地风速。王桂玲等(2006年)利用质量守恒风场调整模式和连续误差订正方法,对北京地区三维风场进行了模拟,分析了该地区冬、夏两季的近地层平均水平流场、垂直流场的变化和局部地形扰动状况,获得了复杂地形上的城市地区低层风场特征。
第二类方法是利用已有的气象站点实测风场资料进行插值来模拟山地风场。最基本的方式是采用距离为权重的内插方法:
![]()
![]()
其中,r为待求点与测站之间的距离,r为影响半径,m是大于1的整数。
该方法没有考虑山区复杂地形起伏对风场的影响。因此,余琦等(2001年)通过在权重函数中增加了一个反映地形起伏变化程度的因子h,将它与距离因子的结合形成新的权重函数对风场进行诊断,即:
![]()
其中,r为待求点与测站之间的距离,h则表示气象测点与待求点之间地形高度变化的总量。
这种诊断方法模式简单,计算时间短,考虑了地形的起伏变化对风矢量相关性的影响,因而适用于起伏地形上的风场计算。
随着GIS空间分析及建模技术的发展,近年来,山地风速受地形影响因素的模拟和订正有了较大的提高,充分利用DEM数据提取一些对山地低空风场具有影响的地形因子参与模拟分析。如史同广等(2007年)用垂直风速廓线方程得到平坦地形下的风速分布,在傅抱璞各种地形条件下不同部位2m高度的风速与开阔平坦地风速比值的研究成果基础上,结合海拔高度、坡度、坡向、坡位等地形要素对风速进行订正,实现了起伏地形条件下风速空间分布的模拟。高阳华等(2008年)基于余琦等提出的起伏地形条件下风场内插模型进行插值,再用垂直风速廓线方程对迎风坡的数据进行订正,模拟和分析了重庆市的风速分布。
第三类方法是利用雷达数据进行三维风场反演。蒋立辉(2006年)提出了针对激光雷达圆锥扫描的空间几何法反演风场。余艳梅(2008年)提出了一种基于风场均匀分布假设的VVP算法,对气象雷达三维风场进行了反演。雷达反演的风场具有很高的时空分辨率,但目前对多普勒风场反演技术的研究还有待于进一步加强。
但不论是预测模式还是诊断模式,这些方法中通常只考虑到了海拔对风场的影响,对于坡度、坡向等小地形因子对风场的影响研究较少,而对于微尺度和像元尺度山地风场模拟,特别是山地近地表风速的模拟研究中,小地形因子和其他气象因素的影响是不可忽略的。因此,综合利用GIS、RS技术来提高小地形因子等影响因素的提取精度,应用一些基于GIS的数量方法,如空间自回归分析、地理加权回归分析,以及一些非线性理论分析方法如神经网络法、支持向量机等研究方法可能会对微尺度和像元尺度山地风场模拟有所改进,提高山地风场的模拟精度。
①山地近地表风速影响因子及提取
a.主风方向效应指数

图9.12 坡向分布图
地形条件是固定不变的,而风向则会因时因地而异。在山区坡向是影响近地表风速的一个重要因素,有很多学者进行了这方面的研究,如傅抱璞在南京方山的一个基本对称的馒头形小山上观测了离地面2m高度处的风速分布,得出了如下结论:当山顶的风速超过7m/s时,向风面底部的风速只有3~4m/s,而背风面底部的风速小于2m/s,同时与风向垂直的山岗两侧的风速比背风面底部和向风面底部的风速大,在山两侧的中部出现两个风速的次大值区(达到5~7m/s)。这表明在孤立小山上地面附近的风速分布是山顶最大,与风向垂直的两山腰次之,而背风坡底部最小。由此可见,坡向和主导风向之间的角度构成了影响山地近地表风速的一个关键因素,孙鹏森等在研究岷江流域上游地区降水空间分布中提出了主风方向效应指数(PWEI,Prevailing Wind-direction Effect Index),PWEI主要通过坡向和主导风向两个因子建立。
![]()
上式中,α为某点的坡向,β为主导风向。PWEI的值域区间为0~2,0~1之间为背风坡,1~2之间为迎风坡,当坡向为β时,PWEI达到最大值2.0。
基于DEM数据,提取研究区域的主风向效应指数。步骤如下:
1)基于DEM高程数据提取坡向数据,提取结果如图9.12所示;
2)研究区主导风向为西南风,取值为225;
3)根据上式,提取研究区域的主风方向效应指数,提取结果如图9.13所示;

图9.13 主风方向效应指数分布图
b.坡度
地表面任一点的坡度是指过该点的切平面与水平面的夹角。坡度表示了地表面在该点的倾斜程度。地面上每一点都有坡度,它是一个微分的概念,是地表曲面函数z=f(x,y)在东西,南北方向的高程变化率的函数。实际应用中,坡度有两种表示方法:
1)坡度(degree of slope):即水平面与地形面之间夹角。
2)坡度百分比(percent of slope):即高程增量(rise)与水平增量(run)之比的百分数。
基于DEM高程数据提取研究区坡度,提取结果如图9.14所示:

图9.14 坡度分布图
c.海拔
在山地中,坡地上的风随着海拔高度的抬升而增大。为了反映纯粹海拔高度的影响,一些文献分析了山区风速与海拔高度的关系,并给出了关系式。李兆元、傅抱璞选取了全国16个附近有平地观测站作对比的山顶观测站的风速资料,求出山顶风速与山下平地风速的比值与二者相对高差h的关系,得到下式:
![]()
上述结果表明山区海拔对风速的影响比较重要。
本文所用高程数据由1∶5万地形图数字化后生成,研究区海拔分布如图9.15所示:

图9.15 海拔分布图
d.平面曲率
地面曲率是对地形表面一点扭曲变化程度的定量化度量因子,地面曲率在垂直和水平两个方向上的分量分别称为平面曲率和剖面曲率。剖面曲率是对地面坡度沿最大坡降方向地面高程变化率的度量,平面曲率描述的是地表曲面沿水平方向的弯曲、变化情况,也就是该点所在的地面等高线的弯曲程度。平面曲率为正值意味着该单元表面向上凸出,曲率为负值则意味着表面下凹,曲率为0时则意味着表面为平面。
基于DEM高程数据提取研究区平面曲率,提取结果如下图9.16所示:

图9.16 平面曲率分布图
e.风速采样方案
风速采样的目的是模拟模型的建立和检验,采样点的数目和分布、模型建立方法是影响模拟效果的关键因素。考虑采样点的数目受限于仪器条件,不能对研究区域进行大量采样,利用正交试验对研究区域进行采样设计,选出试验条件中代表性较强的试验点。
1)正交试验简介
正交试验设计法(Orthogonal experimental design)最早由日本质量管理专家田口玄一提出,称为国际标准型(田口型)正交试验法,是研究多因素多水平的一种试验设计方法。在多因素优化试验中,利用数理统计与正交性原理,从大量的试验点中挑选有代表性和典型性的试验点,这些有代表性的试验点具备了“均匀分散,齐整可比”的特点,应用“正交表”科学合理地安排试验,是用尽量少的试验得到最优试验结果的一种试验设计方法。例如做一个三因素三水平的试验,按全面试验要求,须进行33=27种组合的试验,且尚未考虑每一组合的重复数。若按L9(33)正交表安排试验,只需做9次,按L18(37)正交表也仅需进行18次试验,显然大大减少了工作量。因而正交试验设计在很多领域的研究中已经得到广泛应用。
2)采样方案设计
通过查阅山地近地表风速模拟研究的相关文献及实地考察,风速采样方案中影响因子为:主风方向效应指数、海拔、坡度和平面曲率。主风向效应指数因子取四个水平,其余每一个因子取两个水平。考虑到模型建立和检验,样本容量及L8(41×24)正交试验表的要求,将模型建立采样点由8个增至32个,另外设计8个采样点用于模型的检验。模型建立采样点试验方案如表9.1所示:
表9.1 模型建立采样点试验方案

续表9.1

利用叠加分析工具在研究区找到32个风速采样点,具体流程如下图9.17所示:

图9.17 风速采样点设计流程图
研究区内模型建立采样点和模型检验采样点的分布如下图9.18所示:

图9.18 风速采样点分布图
3)研究区风速采样数据
测风仪使用美国Kestrel3000手持气象站,该类型气象站对风速反映时间为1秒,测量范围为0.4~40.0m/s,分辨率为0.1,精度为3%。测量当天天气预报为西南风二级,近地表风速资料为采样点距地面2米的10min平均风速值。以下是该仪器的风速参数:
①模式:3秒平均值,开机3秒最大值/开机平均值。
②单位:海里/小时(KT)、米/秒(m/s)、千米/小时(km/h)、英里/小时(MPH)、英尺/分钟(FPM)、波弗特(B)。
③精度:+/-3%或者在最小有效数位上+/-1。
④灵敏度:5°时-1%,10°时-2 %,10°~15°时-3%。
⑤校正偏移:使用100小时后小于2 %(7米/秒、14海里/小时、25千米/小时、16英里/小时或者1400英尺/分钟条件下)。
⑥最小速度:0.3米/秒、0.6海里/小时、1.0千米/小时、0.7英里/小时、59.0英尺/分钟。
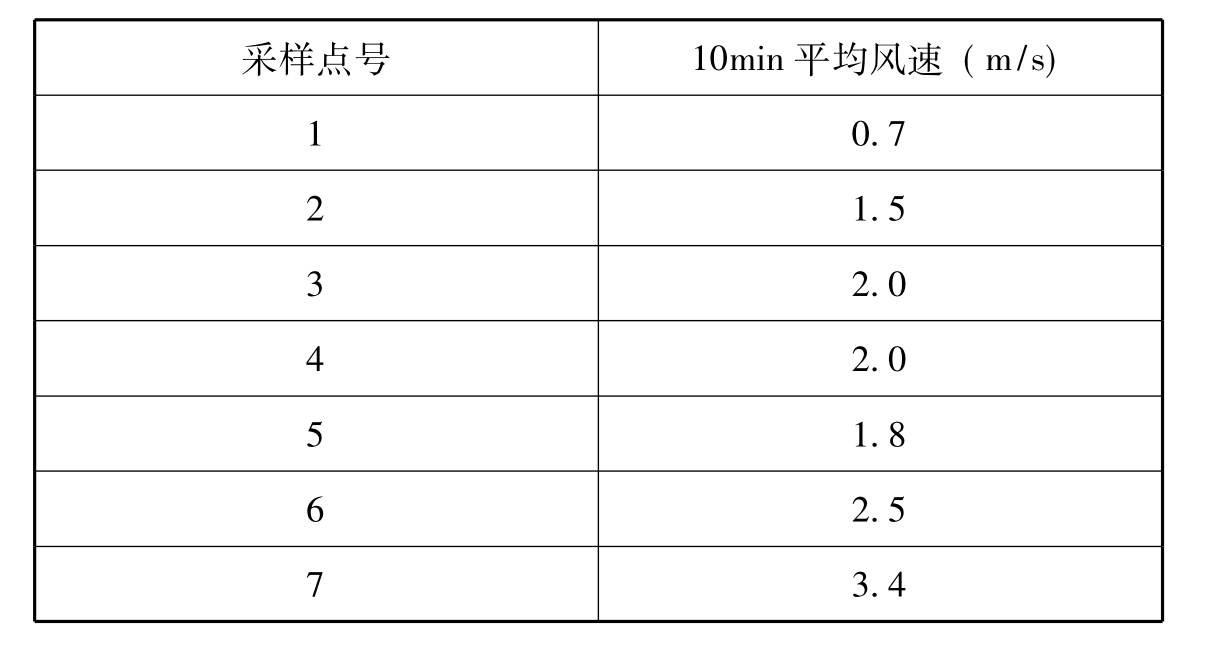
模型建立采样点风速数据如下表9.22:
表9.2 模型建立采样点风速数据

模型检验采样点风速如下表9.3所示:
表9.3 模型检验采样点风速数据
4)研究区山地近地表风速模拟
在本文中采用基于点的空间插值方法模拟研究区山地近地表风速,采用趋势面分析和回归分析进行整体插值,采用反距离加权和规则样条函数进行局部插值,并对不同方法得到的模拟结果进行分析比对。
f.趋势面分析
1)采样数据正态分布检验
首先对风速采样数据作探索性数据分析,表9.4为采样数据在SPSS中的正态分布分析结果。
表9.4 正态分布检验表

注a:a Lilliefors Significance Correction
图9.19为采样数据的正态QQPlot分布图:

图9.19 正态QQPlot分布图
从分析结果可以看出,风速采样数据在95%的置信区间内,不符合正态分布。
对风速采样数据取自然对数后作探索性数据分析,表9.5为转换后的风速采样数据在SPSS中的正态分布分析结果。
表9.5 正态分布检验表

注a:*This is alower bound of the true significance.
注b:a Lilliefors Significance Correction
图9.20为转换后的风速采样数据的正态QQPlot分布图。

图9.20 正态QQ Plot分布图
从分析结果可以看出,对风速采样数据取自然对数后,在95%的置信区间内,数据呈正态分布。
2)趋势面分析
趋势面分析是用多项式模型拟合已知数据点:
z=f(x,y)
这里属性数值z被认为是坐标x和y的函数。
图9.21为研究区风速采样数据的自然对数在东西方向和南北方向的趋势图。

图9.21 趋势面分析图
对上图分析后可以发现,图9.21显示采样数据的自然对数在东西方向具有明显的倒U形状趋势,在南北方向基本具有从南向北减少的趋势。
在ARCGIS中用采样数据的自然对数进行三次趋势面插值,图9.22是根据趋势面计算得到的研究区近地表风速分布。

图9.22 研究区10分钟平均近地表风速趋势面
3)模拟精度检验
为了对模拟结果的准确性进行检验,分别对模型建立采样点和检测采样点采用均方根误差(root mean squared error,RMSE)和相对平均误差(mean relative error,MRE)进行检验。
均方根误差和相对平均误差的表达式分别为:

上式中,Zi为第i个采样点的实际观测值,^Zi为第i个采样点的模拟值,两值越小,模拟效果越好。
从研究区10分钟平均近地表风速趋势面中提取模型建立点和检测点的风速模拟值,模型检测采样点风速测量值和模拟值的比较见图9.23。

图9.23 模型检测点风速测量值和模拟值的比较(三次趋势面)
表9.6 MSE和MRE检验指标值比对

从图9.22可以看出研究区10分钟平均近地表风速的模拟值在0.1~3.1之间,南部区域风速相对较大,并呈现出由南向北逐渐减小,东西方向上中间风速大,从中间向两边逐渐减小的趋势。但模拟结果没有反映出近地表风速和海拔及坡向等地形因子的关联性,并且模拟数据的变化范围比实测数据的变化范围明显偏小。
从图9.23和表9.6中可以看出三次趋势面插值对研究区风速的模拟效果较差,模型检测采样点的模拟值与实际测量值相差较大,多数点比实际测量值偏小。
j.OLS回归模型
1)影响因子提取及模型建立
一般的回归模型用矩阵形式表示为:
y=Xβ+ε
式中,y是因变量,写成n个观察值的向量形式;X代表m个自变量,每个自变量有n个观察值,所以是一个n×m的矩阵;β是对应于m个自变量的回归系数,ε也写作向量形式,是随机误差向量,或称残差向量,残差向量的分布要求是相互独立的且中值为0。
山地近地表风速OLS回归模型的建立过程如下图9.24所示:

图9.24 OLS回归模型建立流程图
使用ARCGIS9.2的Extract values to points工具提取采样点的主风方向效应指数、海拔、坡度和平面曲率等地形影响因子,提取结果如下:
表9.7 模型建立采样点地形因子

续表9.7

表9.8 模型检验采样点地形因子

山区近地表风速受小地形影响较大,近地表风速的空间分布可以表示为:
y=F(pwei,elev,slope,plan_curv)
上式中,y为10min平均风速的自然对数,pwei为主风方向效应指数,elev为海拔高度,slope为坡度,plan_curv为平面曲率,以10min平均风速的自然对数为因变量,以pwei,elev,slope,plan_curv为自变量,在SPSS中采用逐步回归法建立多元线性回归模型:
y=-12.561+0.609pwei+0.005elev+0.169plan_curv
其复相关系数R=0.902,F=40.631,在α=0.05的水平上回归效果显著。
2)模拟结果及模拟精度检验
应用上式得到研究区距地面2m的10min平均近地表风速分布图,如图9.25所示。

图9.25 研究区10min平均近地表风速分布图(OLS回归)
从研究区10min平均近地表风速分布图(OLS回归)中提取模型建立点和检测点的风速模拟值,模型检测采样点风速测量值和模拟值的比较见图9.26。

图9.26 模型检测点风速测量值和模拟值的比较(OLS回归)
表9.12 RMSE和MRE检验指标值比对

从图9.26可以看出研究区10min平均近地表风速的模拟值在0.3~6.6之间,地理分布上具有明显的差异。南坡、西南坡、西坡海拔较高的区域风速较大,风速较小的区域主要集中在研究区东北部北坡、东北坡、东坡等背风坡,图中还可以看出研究区近地表风速的分布与主风方向效应指数和海拔具有很强的关联性,风速从迎风坡到背风坡逐渐减小,在迎风坡上,风速随海拔高度的增加而增大。
从图9.26和表9.12中可以看出OLS回归模型对研究区风速的模拟效果良好,与二次趋势面模拟相比OLS回归模型的模拟值与实际测量值的差值明显较小。
k.空间回归分析
1)空间回归模型简介
在变量没有空间自相关的情况下,即空间上相互独立时,可以使用通常的OLS回归模型来进行分析。如果变量的观察值存在空间自相关时,则需要使用空间回归模型来解决空间自相关的情况。空间回归模型分为两类,第一类为空间滞后模型,或称为空间自回归模型,模型的右边加了一个“自变量”,是因变量y邻域的平均值,即y的空间滞后,用矩阵W表示空间权重,空间滞后可以表示为Wy,空间回归的滞后模型可以表示为:
y=ρWy+Xβ+ε
其中,ρ为空间滞后变量的回归系数,其他变量和参数与上式定义相同。第二类考虑到空间自相关的回归模型为空间残差模型,或SAR模型。空间滞后模型强调因变量在空间上是自相关的,而空间残差模型把残差看做空间上自相关,模型表述为:
y=Xβ+μ
其中,残差又可用它的空间滞后来表示,也就是:
π=λWμ+ε
其中,λ为空间残差自回归系数,剩余的第二个残差项ε是相互独立的随机误差。
2)风速采样数据空间聚类分析
利用ARCGIS的spatial statistics tools计算风速采样数据的全局聚类检验指数,计算结果如表9.13所示:
表9.13 风速采样数据的全局聚类分析结果(n=32)

注a:**表示0.01的显著度
注b:*表示0.05的显著度
从表中可以看出,两种全局聚类指数都表明风速采样数据在空间分布上存在集聚性,其统计显著性高于5%。
3)空间回归分析
进行研究区10min平均近地表风速的分析,因变量为风速采样数据的自然对数值。利用GeoDa软件分别进行OLS回归分析、空间滞后回归和空间残差回归三种分析模型,结果见表9.14。
表9.14 风速采样数据的OLS回归和空间回归分析结果(n=32)
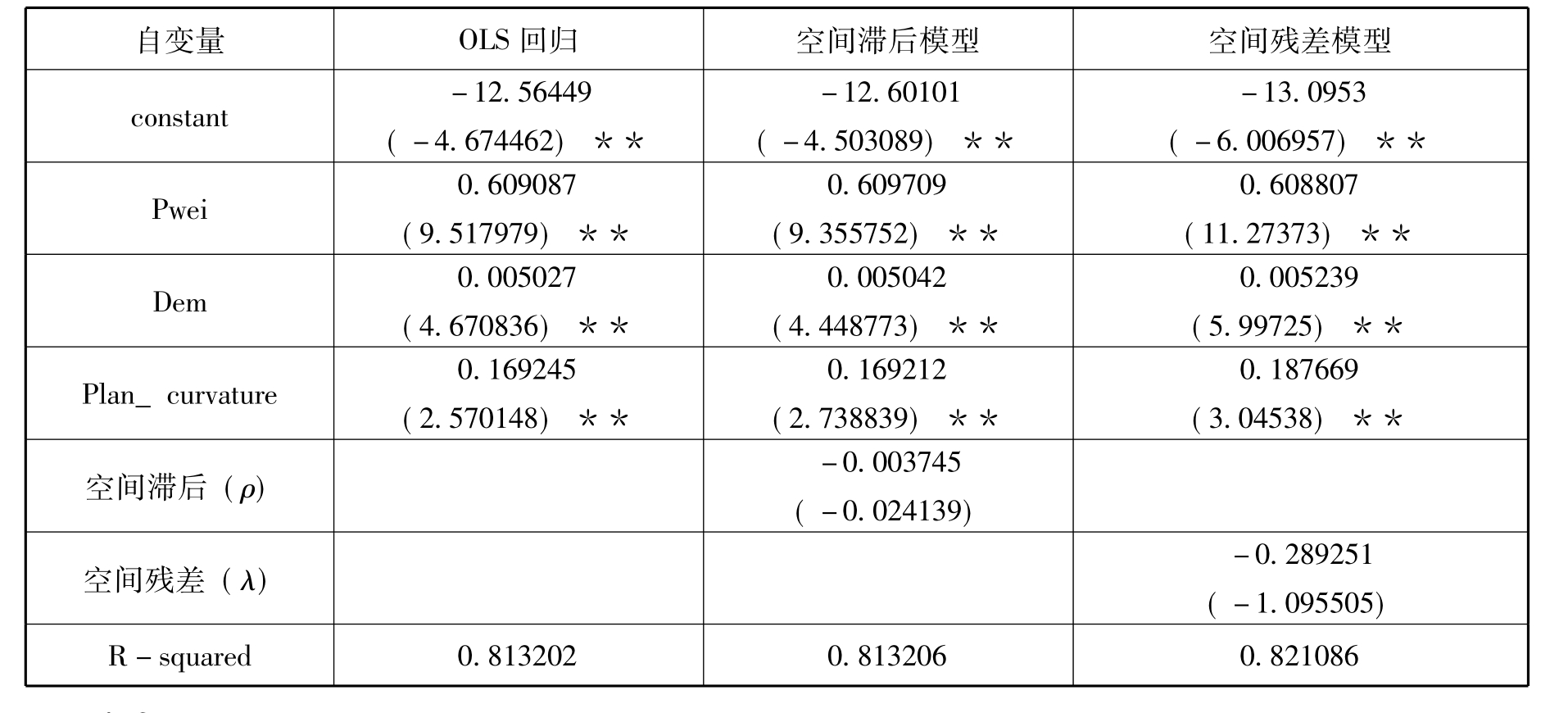
注a:括号内为z值
注b:**表示0.01的显著度
注c:*表示0.05的显著度
从表9.14可以看出,在研究区的10min平均近地表风速的空间回归分析中,对应于空间滞后参数和空间残差参数的Z统计值在0.05的统计显著性水平内均不显著,而且空间回归方程的决定系数和OLS回归方程的决定系数并没有太大的区别,表明不需要用空间回归方程来替代OLS回归方程。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









