



第三节 教育科研资料的分析
分析资料是对整理的资料作进一步的思维加工,通过分析推论得出研究结论。一般来说,对资料的分析有定性分析和定量分析两种,即从研究对象的量和质两个方面揭示问题的真相。描述性资料多采用定性分析,而选项性资料多采用定量分析。
一、定性分析(9)
定性分析是对事物质的规定性的认识,它是运用各种逻辑思维方法,对经过归类整理的大量的数据、文献、事实材料进行去粗取精、去伪存真,得出科学结论的分析。定性分析的主要逻辑思维方法有归因法、比较法、分析与综合法、归纳法、类比法。
(一)归因法
世界是一个无限复杂、互相联系与依赖的统一整体。任何教育现象的产生,都有一定原因,同样它也会引起一定的结果。教育活动就是一系列的因果联系。教育的因果联系不是研究者自己创造的,而是活动本身客观存在的。教育研究的目的在于揭示有关教育内部、教育外部及其相互关系的规律。研究者只有运用正确合适的方法研究搜集到的资料,才能揭示上述联系和规律。
怎样对资料进行因果分析,从而找到各现象之间的因果联系呢?逻辑学为人们提供了这样一些方法:求同法、差异法、共变法和剩余法。
1.求同法
求同法是在产生相同结果的不同现象中,寻找现象之间的共同性,从而确立共同性与相同结果之间存在着因果联系。比如,有资料显示,不同学生的学业成绩在发现式教学法的教学下都有了较大程度的提高,那么求同法就认为这种教学方法是学生学业成绩提高的原因。也就是不同的学生在相同的因素下产生了相同的结果,那么这个“相同的因素”与“同一结果”之间就存在必然的因果联系。
2.差异法
如果研究的教育现象出现的条件与它不出现的条件之间,只有一点不同,即在这一个条件下有某个教育现象出现,而在另一个条件下这个教育现象没有出现,那么,这个条件与所研究的教育现象之间就有因果联系。比如,在前面的例子中,如果对该班学生不采用发现式教学法而改用常规教学法,这样得到的资料是学生的学习成绩并没有得到显著提高。对于这种情况,用差异法分析,通过对比两种不同的教学法与学习成绩的不同变化,即可认为,因没有采用发现式教学法,学生的学业成绩没有显著提高,从而得出发现式教学法可以提高学生的学业成绩的结论。
3.共变法
如果每当某一教育现象发生一定程度的变化时,另一教育现象也随之发生一定程度的变化,那么,这两个教育现象之间就有因果联系。比如,前面的例子中,随着教学方法的改变,学生的学业成绩发生了变化,用共变法分析就可认为,教学方法与学业成绩存在着因果联系。
4.剩余法
如果我们已经知道某一个复杂的教育活动是另一个复杂的教育行为的原因,同时,还知道前面一个教育活动中的某一部分是后面教育行为中的某一部分教育行为的原因,那么,前面教育活动的其余部分与后面教育行为的其余部分就有因果联系。
另外,还要注意归因的复杂性在具体的教育问题中存在着大量的一因多果、一果多因或多因多果的现象。比如,学生学业成绩提高的原因,并不可能只是教学方式的转变,还可能有许多其他因素的作用。同样,一种教学方式的转变带来的肯定不仅仅是学生学业成绩的提高,还可能是学生学习习惯的改变等。总之,要对教育问题有全面准确的认识,就要注重多重归因分析。
(二)比较法
面对纷繁复杂的教育现象,研究者会发现它们之间总会有这样或那样的相似,但是人们还是能将它们区别开来,这就是因为有比较。所谓比较法是根据一定的标准,找出资料之间的差异点与共同点,以此来揭示各份资料所代表的教育现象之间的内在联系。比如,资料显示两个学习基础相差很远的学生在某一次考试中取得了同样的成绩,其原因是什么呢?这就需要对他们的学习方式、努力程度等进行比较。通过比较就可以发现学生的学习基础、学习方式或努力程度与学习效果的联系。
采用比较法分析资料其实也是一种联系分析法,它可以避免孤立地分析和理解某一份资料或资料的某一方面,从而更好地揭示所有资料的内在联系。只有在相互联系和比较中,才能全面准确地认识某一事物,从而对资料所代表的各种教育现象作出评价。
事物及事物之间联系的多样性决定了比较法的多样性。从时间上看,有纵向比较和横向比较;从性质上看,有同类比较和相异比较;此外,还有问题比较、综合比较等。针对不同的资料,应选择不同的比较法。比如对一个学生学习态度的转变的研究,就可采用纵向比较法来比较他在不同时期学习的动机、条件因素,从而找出学习态度变化的原因。
运用比较法应注意以下几个问题。
(1)两种资料是否具有可比性。可比性是指在同一关系下进行比较,这是事物之间进行比较的前提。比如前面说的两个学习基础相差很远的学生,他们在某一次考试中取得了同样的成绩的例子,对他们比较的前提是“同样的考试成绩”,或者是“他们是同年级的学生”,也就是说,研究者不能用学生甲的数学成绩与学生乙的英语成绩,或者用甲第一次的成绩与乙第二次的成绩进行比较。
(2)比较范围的广泛性与确定性。两种不同的资料可比较的内容往往不止一点,但是在某个具体的研究中,研究者应确定“比较什么”。
(3)比较是在同一关系下进行的。要对资料中重要的方面进行比较,不要因某种表面上的相同而忽略实质上的差异,也不要因表面上的差异而忽略实质上的相同。如果只将现象上偶然性的东西进行比较,就容易得出错误的结论。
(4)比较的作用是有限的。通过比较不同的资料,找出它们之间的异同,这是教育研究希望达到的目的之一。但是因为比较往往是针对某一方面进行的,所以也有可能造成片面性,影响比较的信度。
(三)分析与综合法
分析,就是“分而析之”。分析法就是对所搜集的每一份或每一类资料进行研究的逻辑方法。它把所要研究的各份或各类资料抽取出来,脱离其他因素的影响。它是一种暂时孤立的对资料的研究。它着重研究各份资料所代表的事件产生的背景、原因及所蕴藏的意义、价值。不断的分析可以深入细致地研究各份资料或文献,弄清各种资料或文献的意义与作用,从而从根本上把握全部资料。比如,在某个班的学生对教师采用发现式教学法的看法的资料中,有学生认为发现式教学法很好,有学生则认为一般。这时,如果研究者采取一一具体考察每一个学生对发现式教学法的看法的方式进行研究,这就是分析法。这样不仅可以研究细节,为从总体上把握事物积累材料,还可有效地避免有些研究者在分析资料时想当然或“笼而统之的”的错误做法。但这种方法也有其不足,主要表现在它着眼于局部考察,并有可能在抽取、割裂其他因素的过程中形成认识上的孤立、静止、片面性。综合法就可以弥补这种局限。
综合法是将所有搜集到的资料联系起来进行认识和研究。这种方法认为所搜集的资料是一个有机联系的整体。通常所搜集的资料表面上是杂乱无序的。资料综合就是变无序为有序,寻找不同资料之间有机联系的过程。上面说的那个例子,用分析法对不同学生的看法进行一一考察,的确可使研究者对每个学生与那种教学方式之间的关系有深入的了解,但是研究者还无法获得全班学生对那种教学方式的总的看法及其原因。这就需要运用综合法。综合并不是将所有学生的不同看法进行“加法运算”,而是从教学活动整体上去理解和综合。这样就可以得到全班学生的总的看法。综合法也同样存在不足,如果没有分析法作为基础,综合就会是“笼而统之”。
总之,为了避免分析与综合的局限性,研究者最好采取在分析之中综合,在综合之中分析的办法。
(四)归纳法
上面所举的例子中,如果研究者通过资料了解到此班有45人,其中有35人认为发现式教学法很好,那么,就可能得出结论——发现式教学法是一种比较受学生欢迎的教学方法。这一过程就是归纳推理,它的前提是一些关于个别事物或现象的判断,而结论却是关于此类事物或现象的普遍性判断。这是从个别到一般的认识的飞跃。但是,一方面,归纳推理是有根据的,因为在客观事物中,个别与普遍既是对立的,又是统一的,个别表现着普遍,普遍表现于个别之中;另一方面,归纳推理是必要的,因为无论教育科学研究课题是怎样小或多么大,研究者不可能穷尽关于课题的所有资料。没有归纳推理、假设,教育研究的结论就没有适应性。
这种分析方法得到的结论只是某一类教育活动的共同性,不一定是本质,所以结论往往是知其然而不知其所以然。比如,上面研究者判断了发现式教学法是受欢迎的,但如果研究者不再作细致的归因分析,就不会了解为什么那种教学法会受欢迎。也就是说,归纳法不能替代归因分析。同时,归纳法只是一种概率推理,如果将结论无限制推广就可能会不正确。
(五)类比法
类比法是根据两个(类)对象有些相同特点,推出它们的其他特点也可能相同。比如,研究者从资料中得到,研究型学习提高了学生甲的学业成绩,由于学生乙与学生甲的学习能力、学习方法、学习兴趣等都很相似,所以就可以推断出研究型学习也可以提高学生乙的学业成绩。从已知推出未知是这种分析方法与归纳法的共同点。它们的不同之处是,归纳法是从个别到一般,而类比法是从一类到另一类。类比法的可靠性取决于类比的两个(类)对象之间的相似程度。相似程度越高,类比就越可靠。虽然类比的可靠性不大,但它在发现规律、提出理论假说方面起重要作用。资料分析的特点就是这样的,即源于资料但高于资料。
二、定量分析
定量分析是研究事物的量的规定性的认识活动,能从量上为研究结论提供依据。定量分析中最基本的是统计分析。“统计这个术语在教育研究中有多种含义,统计最基本的含义可能是指‘信息数值’。”然而,“统计还有一种比‘信息数值’更广泛的含义,即进行数据分析的理论、方法和方法论”(10)。统计分析主要包括基础分析、相关分析、推断统计分析、方差分析、因素分析和回归分析。
(一)基础分析
基础分析就是把教育一定时期的有关的所有信息综合在一起,根据教育学、统计学等学科的基本原理,通过对决定教育的基本要素(如教育经费投入、教育政策变化等)的分析,找出教育的内在价值,并与目前教育实际价值作比较,从而得出最终结论。基础分析属于宏观经济学范畴,最大优点是其科学性与严谨性,因果关系明确。
1.基础分析的优缺点
基础分析的优点主要有两个:一是能够比较全面地把握教育的基本走势,为教育改革提供决策参考;二是应用起来相对简单,适合不同层次的研究者使用。
基础分析的缺点主要有两个:一是预测的时间跨度相对较长,对当前教育改革的指导作用比较弱;二是预测的精确度相对较低,还需要其他方面的分析才具有实践操作性。
基于基础分析的优缺点,基础分析主要适用于以下几个方面:一是周期相对比较长的教育预测;二是相对成熟的教育改革;三是适用于预测精确度要求不高的领域。
2.基础分析的内容
1)算术平均数
算术平均数,简称“平均数”,也叫“均数”或“均值”,是表示一系列数据或统计总体的平均特征的值,反映一组数据的集中趋势和平均水平。具体来说,算术平均数是指一组数据中各个分数的和除以这组数据的总次数所得的商。样本平均数常用符号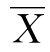 表示,其定义公式为:
表示,其定义公式为:
![]()
式中:X1,X2,X3,…,XN分别表示随机变量X的各个数据;N表示数据的个数。
2)标准差和方差
标准差和方差是最常用的差异数量,它们是量度上的一段区间(或区间的平方),代表分布的离散程度。(11)
标准差表示一组数据内部差异情况或者离散程度,样本的标准差常用字母S表示。标准差大,说明该组数据内部差异大;标准差小,说明该组数据内部差异小。将标准差与平均数结合起来分析研究,可以了解一组数据的全貌。标准差的定义公式为:
![]()
式中:X-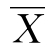 表示离差,即每个数据与平均数的差数;∑(X-
表示离差,即每个数据与平均数的差数;∑(X- )2表示离差平方和;N表示数据的总个数。
)2表示离差平方和;N表示数据的总个数。
方差是标准差的平方。样本的方差常用符号S2表示。方差的定义公式为:
![]()
3)百分数
百分数又叫做“百分率”或“百分比”,是反映数据中每一部分在总体中所占比率或某一事件发生的可能性大小的量,用字母P表示。百分数是“表示一个数是另一个数百分之几的数”。百分数只表示关系,不表示数量,即是说,百分数只能表示两数之间的倍数关系,不能表示某一具体数量。如:可以说“1米是5米的20%”,不可以说“一段绳子长为20%米”。百分数后面不能带单位名称。
3.基础分析的适用性
基础分析在实际的运用中对于绝大多数研究者来讲缺乏可操作性,主要有以下几个原因。
第一,在实际运用中,要求操作者具备极高的专业理论知识。目前国内很多著名的教育研究者都不敢号称完全掌握基础分析,更何况普通的研究者了。
第二,基础分析要求拥有完备的即时资料,并同时建立完善的数据库。影响教育波动的任何信息,包括政策消息、公众心理等,都要在第一时间搜集齐全,并在第一时间分析出会对教育产生哪些影响,这对于任何一个教育研究者来说都是不可能办到的事情,对于普通研究者而言就更是难上加难了。
第三,最重要的一点是基础分析不能量化,例如美国教育部公布的教育统计数据对教育改革产生多大的影响、会造成怎样的教育波动等是不可能用具体数字反映出来的。我们研究基础分析的目的主要是站在市场的角度全面地看待问题,把握住大方向,真正改革还要看技术分析。
(二)相关分析
两个变量之间不精确、不稳定的变化关系称为“相关关系”。(12)相关分析是研究现象之间是否存在某种依存关系,并对具有依存关系的现象加以探讨,从而发现其相关方向及相关程度。相关分析是研究随机变量之间的相关关系的一种统计方法。在教育科研中,常常需要考虑变量之间的关系,例如:学校班级的规模是否与学习成绩有关系;教师的缺勤率与工作积极性有何关系等。要回答这些问题,就需要进行相关分析。
1.相关系数
相关分析所关心的是一个随机变量(如果以Y代表)对另一个(或一组)随机变量(如果以X代表)的依赖关系的函数形式。相关分析侧重探讨随机变量之间的种种相关特征。例如,以X、Y分别记小学生的数学与语文成绩,感兴趣的是二者的关系如何,而不在于由X去预测Y。相关系数是用来描述两个变量相互之间变化方向及密切程度的数字特征量,(13)不过,它并不能够揭示二者之间的内在本质联系。
一个随机变量与另一个(或一组)随机变量的相关按性质可分为三种情况:正相关、零相关和负相关。当一个变量变大(或变小)时,另一个变量也变大(或变小),则这两个变量之间是正相关,相关系数为正值。当一变量变动时,另一变量无变化,或忽大忽小呈无规律变化,表示两变量间无一定的联系,即零相关,相关系数为零。当一变量变大(或变小)时,另一变量却变小(或变大),这两个变量之间是负相关,相关系数为负值。
在教育科学研究领域中,人们通常用字母r表示相关系数。相关系数的取值范围在-1到+1之间,即-1≤r≤1。相关系数的正负只表示相关的方向,它的绝对值表示相关的程度,绝对值越大,表明相关程度越高。相关系数为0表示零相关。
相关系数的值是一个比值,它既不是由相等单位度量而来(即不等距),又不是百分比,因而不能直接作加、减、乘、除运算。
2.复相关
复相关是指因变量和两个以上自变量之间的相关关系,它表示一个变量Y与另一组变量(X1,X2,…,Xk)之间的相关程度。例如,教师职业声望同时受到一系列因素(如收入、文化、社会地位等)的影响,那么这一系列因素的总和与教师职业声望之间的关系,就是复相关。
复相关系数是反映一个因变量与一组自变量(两个或两个以上自变量)之间相关程度的指标。它是包含所有变量在内的相关系数。复相关系数越大,表明要素或变量之间的线性相关程度越密切。
复相关系数不能直接测算,只能采取一定的方法进行间接测算。比如,为了测定一个变量y与其他多个变量X1,X2,…,Xk之间的相关系数,可以考虑构造一个关于X1,X2,…,Xk的线性组合,通过计算该线性组合与y之间的简单相关系数作为变量y与X1,X2,…,Xk之间的复相关系数。具体计算过程如下。
第一步,用y对X1,X2,…,Xk作回归,得:
![]()
第二步,计y和 的简单相关系数,此简单相关系数即为y与X1,X2,…,Xk之间的复相关系数。复相关系数的计算公式为:
的简单相关系数,此简单相关系数即为y与X1,X2,…,Xk之间的复相关系数。复相关系数的计算公式为:
![]()
之所以用R表示复相关系数,是因为R的平方恰好就是线性回归方程的决定系数。
复相关系数与简单相关系数的区别在于,简单相关系数的取值范围是[-1,1],而复相关系数的取值范围是[0,1]。这是因为,在两个变量的情况下,回归系数有正、负之分,所以在研究相关时,也有正相关和负相关之分;但在多个变量时,偏回归系数有两个或两个以上,其符号有正有负,不能按正负来区别,所以复相关系数也就只取正值。
3.偏相关
偏相关是研究在多变量的情况下,在控制其他变量的影响后,两个变量间的直线相关程度。偏相关又称“净相关”或“部分相关”。偏相关分析是指当两个变量同时与第三个变量相关时,将第三个变量的影响剔除,只分析另外两个变量之间相关程度的过程。
偏相关分析也称“净相关分析”,它在控制其他变量的线性影响的条件下分析两变量间的线性相关性,所采用的工具是偏相关系数(净相关系数)。控制变量个数为一时,偏相关系数称为“一阶偏相关系数”;控制变量个数为二时,偏相关系数称为“二阶相关系数”;控制变量个数为为零时,偏相关系数称为“零阶偏相关系数”,也就是相关系数。
偏相关系数较简单直线相关系数更能真实反映两变量间的联系。
偏相关系数、复相关系数、简单直线相关系数之间存在着一定的关系。以三个变量x1,x2,x3为例,它们有如下的关系:
 或者
或者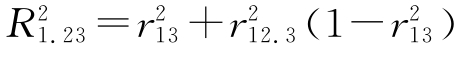
上式中,偏相关系数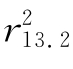 表示控制变量x2的影响之后,变量x1和变量x3之间的直线相关;偏相关系数
表示控制变量x2的影响之后,变量x1和变量x3之间的直线相关;偏相关系数 表示控制变量x3的影响之后,变量x1和变量x2之间的直线相关
表示控制变量x3的影响之后,变量x1和变量x2之间的直线相关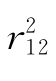 表示变量x1和变量x2之间的相关关系
表示变量x1和变量x2之间的相关关系 表示变量x1和变量x3之间的相关关系。
表示变量x1和变量x3之间的相关关系。
(三)推断统计分析
推断应用的背景是通过较大群体的子群体数据或通过总体的样本数据来推论该较大群体的情况。(14)推断统计,又叫“抽样统计”,是指根据抽样调查获得的样本信息,对总体的数量特征作出具有一定可靠程度的估计和推断的方法。推断统计是用概率形式来决断数据之间是否存在某种关系,以及用样本统计值来推测总体特征的一种重要的统计方法。推断统计包括总体参数估计、假设检验和回归分析,最常用的方法有z检验、t检验、卡方检验等。
在处理调查或实验的数据时,研究者经常要讨论统计值之间差异的问题。如两个平均数、两个比率的差异,利用两个样本(所选取研究对象)之间的差异是否显著来推断其对应总体(研究对象所属的群体)之间是否有差异。其中差异显著性检验是最常见的内容。
差异显著性检验的一般步骤如下。
首先建立无差假设,即两个样本特征量所代表的总体参数之间没有显著差异,假定现有的差异只是由选择研究对象进行抽样时的误差造成的。其次,计算统计量,选择进行检验的相应统计量和公式,计算出统计量的数值。最后,进行统计决断,将计算所得的统计量与判断为小概率事件的临界值进行比较。如果统计量超过临界值,判定研究中提出的无差假设属小概率事件,则两样本的统计量乃至其对应总体之间差异显著,反之则差异不显著。一般来说,需要检验的统计量包括平均数差异、计数数据、平均数、方差、相关系数等。常用的推断统计分析主要有以下几种。
1.两个独立大样本的平均数差异显著性检验——z检验
随机抽取的非相关样本称为“独立样本”,大样本即所选取的研究对象多于30人。大样本的方差基本等同于总体方差,故独立大样本的显著性检验可采用z检验。如果计算出z<1.96(p=0.05时,z=1.96),则p>0.05,两样本的平均数差异不显著;如果计算出z>1.96,则p<0.05,两独立大样本的平均数差异显著。
2.两个独立小样本的平均数差异显著性检验——t检验
由于小样本(即所选取的研究对象数量少于30)的方差不能代表总体方差,故要用t检验。如果两样本所属总体的方差相等,则可将计算得出的t值与d=n1+n2-2(n1、n2分别为两样本的样本数)时t0.05相比较,若t>t0.05,则p<0.05,两样本平均数差异显著。
3.相关样本的平均数差异显著性检验——t检验
所谓相关样本,是指两个样本的数据之间存在一一对应的关系。如研究者对学生的数学和物理成绩进行比较要用t检验。
4.计数数据差异的显著性检验——χ2检验
在教育科学的实际研究和调查中,经常得到很多多项分类的实计数,如选项间并列关系的科研资料与排列式选项的科研资料整理分析所得的数据。对于这些数据的统计分析,一般用χ2检验的方法。
卡方检验(χ2检验)主要是对计数数据进行差异的显著性检验,它是检验实得数与理论数(期望次数)的偏差是否存在显著性差异的一种检验。例如,抛掷一枚均匀的硬币100次,结果出现正面58次,反面42次,请问正、反面之间的差异有无显著性意义?
通过计算χ2来检验实得数与理论次数差异的显著性,就叫做卡方检验(χ2检验)。卡方检验的步骤与z检验和t检验的步骤基本类似。
χ2检验统计量的基本形式为:
![]()
式中:f0表示实际频数;ft表示理论频数;∑表示总和。
除了以上几种分析以外,研究者还可运用方差分析来研究实验数据中各变量对实验结果影响的大小。如运用因素分析从众多变量的相互关联中找出起决定作用的基本因素,运用回归分析确定研究变量的数学模型,从而预测或估计量的变化。
(四)方差分析
方差分析(analysis of variance,简称ANOVA),又称“变异数分析”或“F检验”,是英国统计学家费舍尔(R.A.Fisher,1890—1962)发明的,用于两个及两个以上样本均数差别的显著性检验。由于各种因素的影响,研究所得的数据呈现波动状。造成波动的原因可分成两类:一类是不可控的随机因素;另一类是研究中施加的对结果形成影响的可控因素。
1.方差分析的假定条件
进行方差分析必须满足以下条件:
一是各处理条件下的样本是随机的;
二是各处理条件下的样本是相互的,否则可能出现无法解析的输出结果;
三是各处理条件下的样本分别来自正态分布总体,否则使用非参数分析;
四是各处理条件下的样本方差相同,即具有齐效性。
如果以上条件得不到满足,则不适使用方差分析,或者说进行方差分析的效果不理想。
2.方差分析的假设检验
假设有K个样本,如果原假设H0样本均数都相同,K个样本有共同的方差σ,则K个样本来自具有共同方差σ和相同均值的总体。如果经过计算,组间均方远远大于组内均方,则推翻原假设,说明样本来自不同的正态总体,说明处理造成均值的差异有统计意义。否则承认原假设,样本来自相同总体,处理间无差异。
3.方差分析的基本思想
一个复杂的教育现象,其中往往有许多因素互相制约又互相依存。方差分析的目的是通过数据分析找出对该现象有显著影响的因素,各因素之间的交互作用,以及显著影响因素的最佳水平等。方差分析是在可比较的数组中,把数据间的总的变差按各指定的变差来源进行分解的一种技术。对变差的度量,采用离差平方和。方差分析方法就是从总离差平方和分解出可追溯到指定来源的部分离差平方和,这是一个很重要的思想。
经过方差分析若拒绝了检验假设,只能说明多个样本总体均值不相等或不全相等。若要得到各组均值间更详细的信息,应在方差分析的基础上进行多个样本均值的两两比较。
在方差分析的具体运用中,通过分析研究不同来源的变异对总变异的贡献大小,从而确定可控因素对研究结果影响力的大小。
(五)因素分析
因素分析法(factor analysis approach),又称指数因素分析法,是利用统计指数体系分析现象总变动中各个因素影响程度的一种统计分析方法。因素分析法是目前研究结构效度最常用的一种实证方法。因素分析是“研究者控制一个或者更多的影响被试行为的因素……而操纵一个因素的目的是为了考察它和另一个因素的因果关系”(15)。依使用目的而言,因素分析可分为探索性因素分析(exploratory factor analysis,简称EFA)与验证性因素分析(confirmatory factor analysis,简称CFA)。简单地说,探索性因素分析所要达到的目的是建立量表或问卷的结构效度,而验证性因素分析则是要检验此结构效度的适切性与真实性。
因素分析法是现代统计学中一种重要而实用的方法,它是多元统计分析的一个分支。使用这种方法能够使研究者把一组反映事物性质、状态、特点等的变量简化为少数几个能够反映出事物内在联系的、固有的、决定事物本质特征的因素。因素分析法的最大功用,就是运用数学方法对可观测的事物在发展中所表现出的外部特征和联系进行由表及里、由此及彼、去粗取精、去伪存真的处理,从而得出客观事物普遍本质的概括。此外,使用因素分析法可以使复杂的研究课题大为简化,并保持其基本的信息量。因素分析法包括连环替代法、差额分析法、指标分解法、定基替代法。在教育科学研究中,人们可以用到的主要是连环替代法、指标分解法和差额分析法。
1.连环替代法
连环替代法是将分析指标分解为各个可以计量的因素,并根据各个因素之间的依存关系,顺次用各因素的比较值(通常指实际值)替代基准值(通常为标准值或计划值),据此测定各因素对分析指标的影响。
例如,设某一分析指标M是由相互联系的X、Y、Z三个因素相乘得到,报告期(实际)指标和基期(计划)指标为:报告期(实际)指标为M1=X1×Y1×Z1;基期(计划)指标为M0=X0×Y0×Z0。
在测定各因素变动指标对指标R影响程度时可按顺序进行:
基期(计划)指标M0=A0×B0×C0(式1);
第一次替代X1×Y0×Z0(式2);
第二次替代X1×Y1×Z0(式3);
第三次替代X1×Y1×Z1(式4)。
分析如下:
式2减式1所得,即X变动对M的影响;
式3减式2所得,即Y变动对M的影响;
式4减式3所得,即Z变动对M的影响。
把各因素变动综合起来,总影响:ΔM=M1-M0=式4-式3+式3-式2+式2-式4。
2.指标分析法
指标分析法是利用指标体系,对教育现象的综合变动从数量上分析其受各因素影响的方向、程度及绝对数量。指标分析法实际上是依据一定的统计方法,运用一些复杂的数学计算公式或数量模型,通过计算机系统生成的某种指标值或图形曲线进行分析。这种分析方法对于判断教育未来走势具有重要实践意义。
指标分析法的特点体现在其指标体系的要求上。在对教育现象或教育问题进行指标分析时,指标体系的建立应当具备三个基本素质:一是指标要素齐全适当;二是主辅指标功能匹配;三是满足多方信息需要。
指标分析法是通过对指标的分析得出一些数据,而数据本身是教育科研的基础信息,可以直接作为教育决策依据的信息往往隐藏在这些数据之中。要将这些数据变成直观的决策依据,需要我们采取信息整合活动,对各种信息进行搜集、筛选、分析、判断、推理等,以整合成有效信息。(16)信息整合是指标分析的基本手段,主要有以下步骤。
一是选定影响教育发展状况的各项指标。通常可选择的指标有:师资水平达标率、教学条件合格率、生均占地面积达标率等。因不同教育机构的具体情况不同,在选择评价指标时也应有所区别。
二是根据重要性程度,对各种比率标注重要性系数,并使各系数之和等于1。
三是确定各项指标的标准值。如果一个教育机构各项指标的比率实际数达到了标准值,便意味着教育硬件状况最优。
四是计算确定教育分析期各项指标比率的实际数值。
五是计算求出实际比率和标准比率的百分比,即相对比率。
六是用相对比率乘以重要性系数,求出各比率的评分,即综合指数,并求出各比率综合指数的合计数,即总评分,以此作为对学校教育状况的评价依据。如果综合指数合计为1或在1左右变动,则表明教育常规运行状况达到标准要求;如果大于或小于1,则表明实际教育状况偏离了标准要求,详细原因应进一步分析查找。
3.差额分析法
差额分析法实际上是连环替代法的一种简化形式,是利用各个因素的比较值与基准值之间的差额来计算各因素对分析指标的影响。
例如,某所学校财务指标及有关因素的关系:
实际指标为Po=Ao×Bo×Co;
标准指标为Ps=As×Bs×Cs;
实际指标与标准指标的总差异为Po-Ps。
Po-Ps这一总差异同时受到A、B、C三个因素的影响,它们各自的影响程度分别由以下公式计算求得:
A因素变动的影响为(Ao-As)×Bs×Cs;
B因素变动的影响为Ao×(Bo-Bs)×Cs;
C因素变动的影响为Ao×Bo×(Co-Cs)。
最后,可以将以上三大因素各自的影响数相加就应该等于实际指标与标准指标的总差异Po-Ps。
(六)回归分析
回归分析(regression analysis)是研究一个随机变量Y对另一个变量(X)或一组变量(X1,X2,…,Xk)的相依关系的统计分析方法。在教育科学研究中,回归分析的运用十分广泛。回归分析按照涉及的自变量的多少,可分为一元回归分析和多元回归分析;按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。如果在回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为“一元线性回归分析”;如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为“多元线性回归分析”。
1.回归分析的主要内容
(1)从一组数据出发确定某些变量之间的定量关系式,即建立数学模型并估计其中的未知参数。估计参数的常用方法是最小二乘法。
(2)对这些关系式的可信程度进行检验。
(3)在许多自变量共同影响着一个因变量的关系中,判断哪个(或哪些)自变量的影响是显著的,哪些自变量的影响是不显著的,将影响显著的自变量选入模型中,剔除影响不显著的变量,通常用逐步回归、向前回归和向后回归等方法。
(4)利用所求的关系式对某一教育过程进行预测或控制。
2.回归分析研究的主要问题
在回归分析中,把变量分为两类:一类是因变量,它们通常是实际问题中所关心的一类指标,通常用Y表示;而影响因变量取值的另一变量称为自变量,用X来表示。回归分析研究的主要问题包括:
一是确定Y与X间的定量关系表达式,这种表达式称为“回归方程”;
二是对求得的回归方程的可信度进行检验;
三是判断自变量X对Y有无影响;
四是利用所求得的回归方程进行预测和控制。
3.回归分析法应用举例
为了更好地说明回归分析在教育科研中的具体应用,我们在此以赵庆刚、彭瑞霞的《以回归分析法构建教师信息素养评价体系》(17)一文为例加以分析。
1)在构建教师信息素养量化评价指标体系中引进回归分析方法
假设教师信息素养量化评价指标系统是线性或者趋近于线性的,那么建立一个量化评价指标体系主要就是要确定各项评价指标的具体内容,以及它们各自所对应的权重。假设该评价体系有n个评价指标,各项评价指标所对应的权重为x1,x2,x3,…,xn。现在通过调查表的方法获取了m个评价样本,以及他们各自对应的信息素养总的得分为b1,b2,b3,…,bm,那么如果所给出的权重x1,x2,x3,…,xn是一组合理的权重的话,它应该尽可能满足下面的等式:
Ax=b
其中,A=(a1,a2,a3,…,am)-1为随机抽样获取的m个样本中评价指标的分值a1=(a11,a12,a13,…,a1n),a2=(a21,a22,a23,…,a2n),a3=(a31,a32,a33,…,a3n),…,am=(am1,am2,am3,…,amn)组成的矩阵;b=(b1,b2,b3,…,bm)-1为各个样本中教师信息素养得分b1,b2,b3,…,bm组成的列向量;x=(x1,x2,x3,…,xn)-1为各评价指标对应的权重x1,x2,x3,…,xn组成的列向量。
实际上,通常我们通过问卷或者调查获取的教师信息素养的样本数m会远大于未知数(各项权重)的数量n(即m》n)。这时,由于统计误差的原因,一般并不存在一个x严格地满足上面的等式Ax=b,因此,我们的任务就是求得使|Ax-b|最小化的x。|Ax-b|在这里指的是Ax-b的方差。当样本数m大于未知数n越多,样本的统计误差就越小,这样我们通过|Ax-b|求解所得的x值(即权重分布)就会更准确,因而最后得出的教师信息素养量化评价指标体系的权重分布也就更科学合理。
2)引进回归分析法的附加说明
首先,关于评价指标体系中的指标的获取建议各学校或各地区建立自己的教师信息素养量化评价指标库,指标库的内容可以参考各学者的研究和其他学校或地区的评价指标,且指标库的内容可以根据学校信息化的发展需要定期(如半年一次)进行更新。其次,样本的获取要尽可能真实,最好能反映被调查教师自身或其身边教师的信息素养真实状况。最后,关于满足|Ax-b|最小化的x的求解,也即是样本偏差最小化的线性回归方程的求解,这是一个常见的数学问题,可以使用一个通用的数学程序来完成。
3)回归分析法应用举例
我们试举一例来说明回归分析法的应用。我们通过研究和调查确定了某中学的教师信息素养量化评价指标库。其中一级指标有四个:信息意识、信息知识、信息能力和信息伦理。在一级指标下面又各有其易于测量和实际操作的二级指标。为了简化论述,我们将其分解,下面仅挑选其中的一部分来应用线性回归方法确定其权重分布,其他部分依次类推即可得出结论。
通过抽样调查,我们获取了10个样本,其中关于教师信息意识(一级指标)这部分有6个下一级评价指标及其对应的得分(各项分值满分为1),如表14-2所示。
表14-2 教师信息意识的细分指标及其对应得分

续表

于是我们可以得到|Ax-b|中
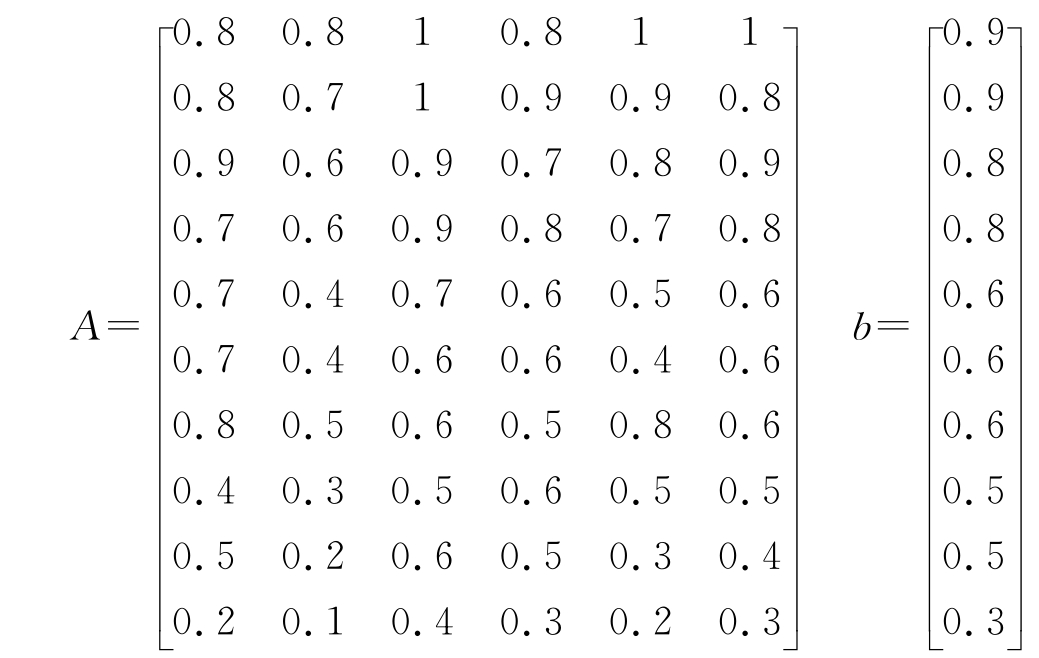
采用最小二乘法进行回归分析得到:
x=(0.1258 0.1126 0.3238 0.3394 0.0422 0.0666)-1;
Ax=(0.895 0.900 0.803 0.801 0.624 0.588 0.595 0.504 0.489 0.296)-1;
Ax-b的均方差为0.00312。
于是我们可以得到教师信息素养量化评价指标体系中信息意识这部分的评价指标及其权重分布,如表14-3所示。(权重四舍五入保留到小数点后两位)
表14-3 教师信息意识的细分指标及其权重分布

类似以上求解过程,我们可以依次算出教师信息素养中信息知识、信息能力和信息伦理这几部分的各项评价指标的权重分布,最后再算出信息意识、信息知识、信息能力和信息伦理四个一级指标的权重分布,至此,一个完整的教师信息素养量化评价指标体系便会呈现在我们眼前。限于篇幅,同样的过程不再赘述。
思考题
1.教育科研资料的类型有哪些?
2.如何处理教育科研资料?
3.如何分析教育科研资料?
【注释】
(1)王德润、蒋海风《试论数学教师科研资料的搜集、整理和研究工作》,载《数学教学研究》,2009年第2期。
(2)宋艳《中小学教师怎样进行课题研究(九)——教育科研资料的处理与分析》,载《教育理论与实践》,2008年第9期。
(3)张景焕、陈月茹、郭玉峰《教育科学方法论》,山东人民出版社2010年版,第100页。
(4)候怀银《教育研究方法》,高等教育出版社2009年版,第276页。
(5)宋艳《中小学教师怎样进行课题研究(九)——教育科研资料的处理与分析》,载《教育理论与实践》2008年第9期。
(6)(美)威廉·维尔斯马、斯蒂芬·G.于尔斯《教育研究方法导论》,袁振国主译,教育科学出版社2010年版,第7-11页。
(7)(美)威廉·维尔斯马、斯蒂芬·G.于尔斯《教育研究方法导论》,袁振国主译,教育科学出版社2010年版,第11页。
(8)袁振国《教育研究方法》,高等教育出版社2000年版,第186页。
(9)廖茂忠《教育科研资料的处理——教育科研系列讲座之五》,载《中小学教材教学》2003年第3期。
(10)(美)威廉·维尔斯马、斯蒂芬·G.于尔斯《教育研究方法导论》,袁振国主译,教育科学出版社2010年版,第386页。
(11)(美)威廉·维尔斯马、斯蒂芬·G.于尔斯《教育研究方法导论》,袁振国主译,教育科学出版社2010年版,第390页。
(12)王孝玲《教育统计学》,华东师范大学出版社2001年版,第228页。
(13)王孝玲《教育统计学》,华东师范大学出版社2001年版,第229页。
(14)(美)威廉·维尔斯马、斯蒂芬·G.于尔斯《教育研究方法导论》,袁振国主译,教育科学出版社2010年版,第409页。
(15)(美)威廉·维尔斯马、斯蒂芬·G.于尔斯《教育研究方法导论》,袁振国主译,教育科学出版社2010年版,第15页。
(16)胡兴华《小议指标分析法在事业单位的应用》,载《中国集体经济》2008年第10期。
(17)彭瑞霞、赵庆刚《以回归分析法构建教师信息素养评价体系》,载《清华大学教育研究》2006年第3期。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










