



3.3.1 预测基本模型
应用于电力负荷预测的方法很多,大体可分为两大类,一类是利用历史的负荷数据,寻找变化规律,以预测后期负荷;另一类是找到影响负荷变化的主要因素,根据这些因素后期的变化趋势进行相关分析,从而预测电力负荷。
常用计算模型计算原理介绍如下:
1.时间序列模型
时间序列模型是利用已知的历史数据拟合一条曲线,使得这条曲线能反映电量或负荷本身的增长趋势。然后,按照这个增长趋势曲线,对于要求的未来某预测年份,从曲线上估计出那时的预测值。
拟合曲线有很多种回归方法,可以选择不同的曲线方程,常用的曲线形式如下:
二次曲线:y=a+bx+cx2
三次曲线:y=a+bx+cx2+ex3
指数曲线:y=abx
S型曲线:y=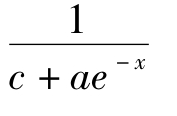
2.弹性系数模型
由规划区以往的用电量和国民生产总值分别求出它们的平均增长率Ky、Kx,从而求得电力弹性系数E=Ky/Kx,再用某种方法预测未来m年的弹性系数E'及国民生产总值的增长率K'x,则可得电力需求增长率K'y,从而可按比例系数增长预测法得出第m年的用电量。在经济发展和用电量比较稳定的情况下使用效果较好。
3.灰色系统模型
灰色系统预测,是指采用GM模型对系统行为特征值的发展进行的预测。若系统存在多个因子的动态关联,就要进行GM(1,1)和GM(1,N)的配合研究。
采用灰色系统模型,其关键是历史数据的预处理以及在预处理数据结果基础上得到的预测结果的还原,即所谓数据累加生成和数据累减还原的过程。GM模型即灰色预测,在负荷预测中主要用来进行中期和长期负荷预测。
4.移动平均模型
在数理统计中,如果要处理一组数据,一般取其算术平均值代表这一总体取值水平,算术平均值只能说明一般情况,看不出数据中的高点和低点,也不能反映发展过程和趋势。如果对一组数据分段平均,并且分段平均法不是固定在某一段上,而是在每段间距保持不变的情况下,逐次后移一位求其平均值,则效果显著好转。移动平均法的关键是,仅取最近几个数据点的平均值,并令参与计算移动平均值的各点权数相等,即均等于1/N,再令以前的数据点的权数为零。
5.相关分析模型
相关分析模型法是把电量或负荷预测与各种社会和经济因素联系起来,借助于这些因素的变化来预测电量或负荷的发展趋势。相关分析模型包括单元回归模型和多元回归模型,预测时除了需要待求量和相关量的历史数据,还需要未来年各相关量的预测值。
模型方程Y=a+bX+ε,X为相关量,Y为预测量,a和b为回归系数,ε为随机误差。单元线性回归用于预测的基本思想是:根据相关量和预测量的观测数据,把相关量、预测量当作已知数,寻求合理的回归系数a和b的值,从而确定回归方程。利用求出的回归方程,把a和b当作已知数,根据相关量的未来变化计算预测量的值。多元回归与单元回归不同的是这里的a、b、x、y都是矩阵,也就是说有多个相关量。多元线性回归用于预测的基本思想是:根据相关量和预测量的观测数据,把相关量、预测量当作已知数,寻求合理的回归矩阵a和b的值,从而确定回归方程。利用求出的回归方程,把a和b当作已知数根据相关量的未来变化计算预测量的值。
6.负荷密度指标法
负荷密度指标法即空间负荷预测是在将规划区分区、负荷分类的基础上进行的,分区负荷预测是为了反映负荷分布的空间特征,将供电区域细分成若干个单元小区,空间负荷预测归结为单元小区负荷的预测。分类负荷密度预测是为了便于对众多的小区负荷进行分析,将小区聚合成类,认为同类小区具有相同或近似的负荷特性。
在综合预测方法中,各类小区负荷密度指标是在远景年在负荷发展饱和情况下,考虑环保、社会、经济等因素而确定的指标,负荷密度指标是负荷密度指标法预测的关键因素,是负荷分布预测的基础,直接决定负荷空间分布的可信性。指标确定的高低直接影响预测结果的准确度,关系到规划网架的构成及布置。
负荷密度指标的获得主要通过四种途径:
(1)按分类平均负荷密度设置。
在完成分类负荷预测后,由于各类负荷的总面积可以在用地规划图中统计得到,分类平均负荷密度较容易获得。在实际系统中,尽管由于同类负荷小区的负荷发展水平不同,从而导致一些同类小区的负荷密度存在着一定的差异,但相当一部分同类小区的负荷密度还是与平均负荷密度十分接近。按照这种方法确定小区负荷密度简便、有效。对于那些与平均负荷密度相差较大的小区,可以采用其他方法进行修正。
(2)参考经验数据。
该方法属于一种经验类方法。通过对国内外各类相似小区负荷密度及其相关资料的调查,将负荷密度值按相关因素加以归类整理,可以形成小区负荷密度的经验数据库,以供规划时参考。实际上,这一方法就是要借鉴发达国家或发达地区已建成区的经验,通过类比的方式来确定规划各小区的负荷密度。有时,也可借鉴规划区内已建成区的负荷密度指标,通过适当的调整,用于其他待开发的相似小区。在决定已经掌握的小区负荷密度值能否应用于某规划小区时,需要对小区的特征进行相似性分析后加以判断,这些特征可以分为城市地域及发展特征(简称城市因素)、小区地域及发展特征(简称小区因素)两类,具体见表3-1。
表3-1 小区特征相关因素

(3)通过密度外推法获得。
首先,需要根据各小区的历史负荷数据估算小区历史年的负荷密度,然后以历史年负荷密度值为基本数据,采用外推法计算规划年的小区负荷密度指标。
这里用负荷密度外推,而不是小区负荷外推,主要是因为在综合预测方法中,小区面积大小不同。
在整个规划区内,可以选择一批典型的历史数据比较齐全的各类小区进行负荷密度趋势预测,其预测结果可以作为各类小区的负荷密度样板,用于其他同类型相似小区。为了反映同类小区中存在的负荷发展水平不一致性,同一类负荷小区中,可以选择不同发展水平的小区做样板进行负荷密度趋势预测。为了增强典型负荷密度预测结果的可信性,应尽可能多的选择历史数据比较齐全的小区进行预测,最后的典型负荷密度预测结果可以取为同类型同一负荷发展水平各小区负荷密度预测结果的平均值。
值得强调的是,和负荷预测趋势法不同,这里需要的是小区负荷密度历史数据,在小区面积已知的情况下,可将小区负荷历史数据转换为小区负荷密度历史数据。在对负荷密度进行趋势预测时,也应当考虑各类小区负荷密度的饱和值。
(4)终端设备负荷曲线叠加法。
这种方法来源于用地仿真空间负荷预测方法。考虑到很难获得各种型号设备的典型负荷曲线以及统计不同型号设备比例的难度,可以直接从反映终端功能类负荷特征的负荷曲线开始叠加,也就是通过统计等方法,直接获取终端功能类负荷曲线。
值得强调的是,在综合预测方法的实际预测过程中,预测者并不一定仅限于采用上述四种方法中的一种。根据各小区的历史数据情况,对某些小区可以选用一种方法,对其他小区也可以选用另外的方法。选用什么样的方法对一个小区的负荷密度指标进行预测,需要预测人员根据对数据的掌握情况以及小区的特征综合进行判断。
此外,在负荷密度指标的预测计算过程中,有时按照单位建筑面积给出负荷密度指标更为方便,尤其对于居民生活用电或商业用电等。相应地,这时需要将小区用地面积也折算为建筑面积。在城市规划部门给出的规划结果中,用地面积与建筑面积通过建筑区域的容积率来联系:建筑面积=用地面积×建筑容积率。
在已知小区面积以及小区预测年份负荷密度指标的情况下,计算小区的负荷预测值很简单,小区负荷值也就等于二者的乘积。不过,在空间负荷综合预测方法中,按照前述四种方法获得的小区负荷密度指标只能看作是负荷密度的初步预测结果,还需要执行校核、修正、再计算的循环过程,目的是使得小区的负荷预测结果与分类负荷的总量预测结果相吻合,实现总量控制。小区负荷的预测、修正、再预测、再修正是个复杂而繁琐的过程,若想得到比较具体可信的结果,需要大量深入细致的工作,还必须有相应的计算机软件作为支持。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









