



2 方法与数据
2.1 方法
2.1.1 中国茶叶需求规模影响因素的理论假设
中国茶叶需求包括出口与内销两个部分。近50年中,出口是影响我国茶产业发展的一个重要变量,但其重要性在不同历史时期有所差异。20世纪50—80年代我国茶叶出口持续增长,但进入90年代,出口量有所回落,90年代中后期出口量逐渐回升。从总体上来看,中国茶叶出口增长有趋缓的趋势。今后我国茶叶出口规模将受到进口国的社会经济条件、消费者偏好变化、替代品的供应状况以及技术壁垒等诸多因素的影响,其中可支配收入和消费人口等社会经济条件是潜在需求规模的决定因素,而替代品和技术壁垒则是竞争性因素。
在内销方面,20世纪90年代以前,茶叶国内消费受政策的抑制,其潜在需求量并没有得到充分释放。90年代初期,我国茶叶出口遇到一些困难,国内茶叶流通管制逐步放开,茶叶内销市场随之有了较快的发展。目前,我国内销市场的茶叶消费主要来自传统饮茶方式的消费以及深加工的原料需求。前者指茶叶直接用来饮用,这是茶叶总需求中的最主要部分;后者指用于加工液态茶、速溶茶粉以及其他深加工用途的原料消耗。由于饮食习惯原因,茶叶是我国边疆一些少数民族的生活必需品,但对绝大多数消费者来说,茶叶仅是一种嗜好品。针对这些消费群体,当消费者收入较低时,茶叶需求对价格和收入的变化会表现出富有弹性的市场特性。另外,近几年,我国国内市场用于加工饮料及其他深加工用途的茶叶原料消耗量已具相当规模,并呈逐年增加态势。这部分需求量亦与收入有关。因此,可支配收入变化以及人口自然增长所导致饮茶群体人数增加是影响国内茶叶消费量的两个直接因素,并呈正相关关系。上述影响我国茶叶需求总规模的因素与关系可用图1来表示,可用下列数学函数来表示Z=f(X,Y)(2-1)其中Z为总需求规模,X为出口量,X=∑n i=1Xi(Xi为不同国家对中国茶叶的进口量)。Y为内销需求量,它受可支配收入和消费人口的影响,其函数式Y=f(x1,x2,x3,ε)(2-2)其中x1为人均可支配收入,x2茶叶消费人口,x3为用于深加工原料需求变量,其中x3亦可以由x1和x2来解释,ε为扰动项。
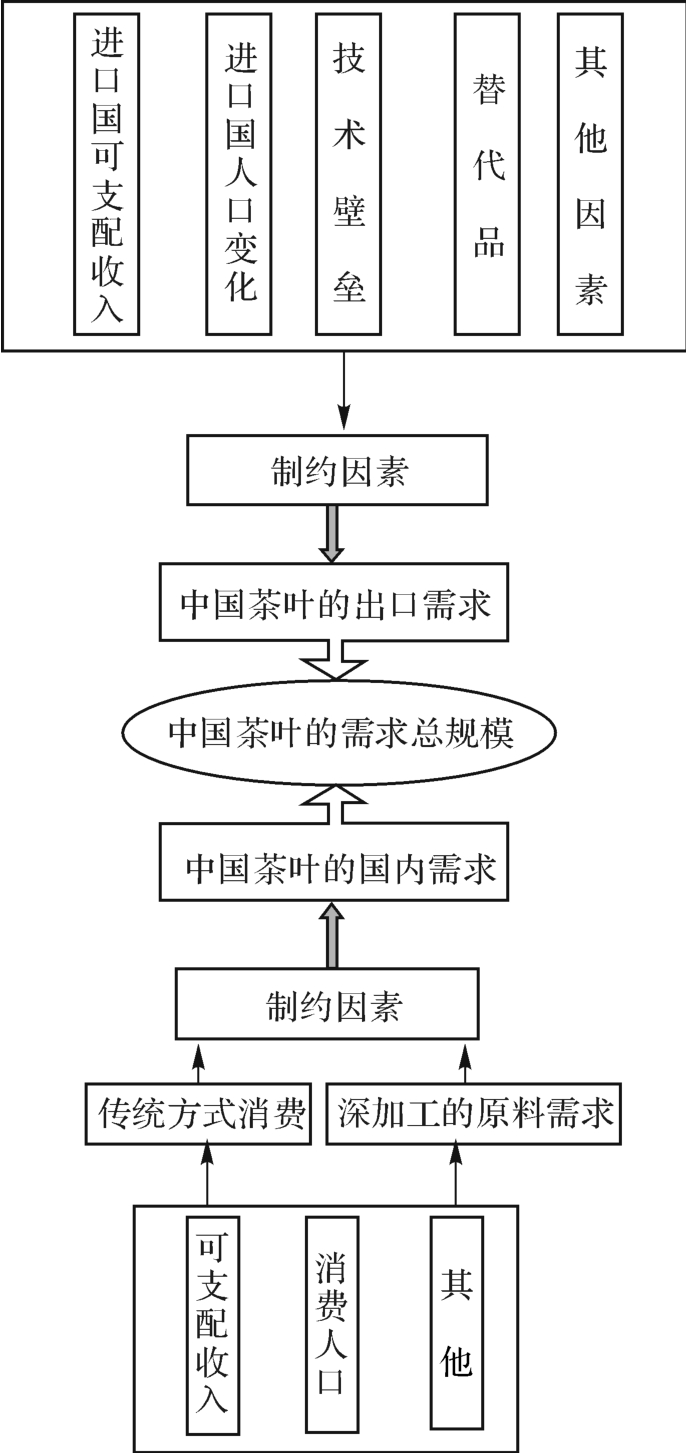
图1 中国茶叶需求规模的影响因素
2.1.2 对中国茶叶需求规模的影响程度
现有文献中,常采用不同年份茶叶出口量占总产量的比例来分析茶叶出口的地位。这种时点静态方法不容易克服一些个别年份因偶发性因素所导致出口量波动的非系统性影响。本文利用五年平滑移动均值来分析出口因素对中国茶叶需求规模的影响趋势。
2.1.3 国内市场茶叶需求影响因素的分析模型
利用表达式(2-2)的线形模型分析国内市场茶叶需求规模的影响因素,其中国内茶叶年消费量是用茶叶年产量和出口量的差值来代替,这是以国内茶叶年度库存量在动态上的相对稳定为假设前提。近年,普洱茶的收藏性消费已成一种时尚,它应是影响我国茶叶需求规模的自变量之一,但由于其年增加的收藏量无法估计,因此,只能作为残差的一部分进行估计。另外,模型(2-2)中人口和可支配收入的变化亦会同时影响茶饮料的消费。因此,模型中可能存在共线形的问题,多重共线形的存在会造成方差和标准误的增大以及t估计量的减少。在应用该线形模型时,必须先预诊断,并根据实际诊断结果对模型进行修正。
2.1.4 中国茶叶需求规模的预测
茶叶出口和国内需求的预测是本文重点探讨的内容。在计量经济学中,预测是对被解释变量样本外观测值的期望值的估计。大多数的预测是对未来时期的值进行推测,其依据的变量值大多是时间序列数据,较少采用横断面样本。在利用序列数据进行模型估计时,必须处理好序列相关和非平稳性两个问题。
(1)趋势外推预测模型。该模型是以时间t为自变量,时间序列y为因变量,并以适当的函数曲线来反映变化趋势,可表达为~Yt=f(t)(2-3)当认为这种趋势可以延伸至未来时,给定时间t的未来值,将其代入模型可以得到相应时刻的时间序列变量的预测值。实际应用时,有采用不同曲线进行拟合。
(2)自回归模型。序列相关又叫自相关,是指模型残差间存在自相关现象。在利用年度茶叶产量和出口量的差值代替国内需求规模变量值时,这个问题似乎尤为突出。由于我国茶叶每年有一定的库存,库存是导致残差自相关的一个潜在变量。在序列相关情况下,OLS对标准误的估计程序产生了有偏的SE()估计,从而导致有偏的t统计值和不可靠的假设检验。对是否存在一阶序列相关,可用Durbin-W atson d statistic进行检验。如果d为0或4,则存在极端的正序列相关或负序列相关,其值越接近2,序列相关越弱。当存在一阶序列相关时,可采用广义最小二乘法来消除标准误的有偏估计,可利用Exact maximumlikelihood、Cochrane-O rcutt或Praise-W insten估计参数。其过程相当于在普通回归方程的右侧添加1阶自回归算子,模型的表达式为Yt=Ф1Yt-1+Xtβ+εt(2-4)其中,Ф1为自回归系数,Xt为解释变量序列或自变量序列,β为回归系数向量,εt为白噪声序列。
(3)AR IM A模型。使用时间序列数据进行统计所面临的第二个问题,是数据值的非平稳性。非平稳时间序列是指变量的基本性质(如它的均值和方差等)随时间而变化。如果应变量和至少一个解释变量是非平稳的,简单的最小二乘法回归会放大R2和非平稳变量的t值。对非平稳性数据,需要对方程中变量取一阶差分或以上,直至非平稳序列转换为平稳序列,其一阶差分即为Y*=ΔYt=Yt-Yt-1
(2-5)
针对残差相关和非平稳性变量数据预测模型的构建,ARIM A(p,d,q)是目前广泛采用的方法。这种方法完全忽略解释变量,而是利用当期值和过去值对变量进行精确的短期预测。其理论数学表达式为
AR
Yt=β0+θ1Yt-1+θ2Yt-2+…+θpYt-p+Ф1εt-1+Ф2εt-2+…+Фqεt-q+εt
M A(2-6)其中θ和Ф分别是自回归过程和移动平均过程的系数,p和q分别是所使用的Y和ε的过去值的个数。使用ARIM A的第一步是通过d次的一阶差分直至被解释变量序列的均值和方差为常数,从而将变量序列转化为平稳序列。具体应用该模型拟合时,一般包括模型的识别阶段、参数估计和检验阶段以及预测应用阶段三个步骤。其中,前两个阶段需要反复进行。
2.2 数据
中国茶叶需求规模预测模型的分析样本为国家统计年鉴中总产量数据(1976—2007年)以及中国海关行业统计年鉴茶叶出口数据(1976—2007年)。中国国内市场茶叶需求规模影响因素的模型构建中,人口和可支配收入数据来自中华人民共和国统计年鉴(1978—2007年),其中可支配收入采用实际工资指数来代替;深加工对茶叶原料消耗的变量,利用中国饮料工业协会统计资料中的“其他饮料”栏中的数据值(1997—2007年)来代替。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











