



包名全小写,类名首字母全大写,常量全部大写并用下划线分隔,变量采用驼峰命名法(Camel Case)命名等,这些都是最基本的Java编码规范,是每个javaer都应熟知的规则,但是在变量的声明中要注意不要引入容易混淆的字母。尝试阅读如下代码,思考打印结果的i是多少:
肯定会有人说:这么简单的例子还能出错?运行结果肯定是22!实践是检验真理的唯一标准,将其Run一下看看,或许你会很奇怪,结果是2,而不是22.难道是编译器出问题了,少了个"2"?
因为赋给变量i的值就是数字"1",只是后面加了长整型变量的标示字母"l"而已。别说是我挖坑让你跳,如果有类似程序出现在项目中,当你试图通过阅读代码来理解作者的思想时,此情景就可能会出现。所以为了让你的程序更容易理解,字母"l"(包括大写字母"O")尽量不要和数字混用,以免使读者的理解和程序意图产生偏差。如果字母和数字混合使用,字母"l"务必大写,字母"O"则增加注释。
注意:字母"l"作为长整型标志时务必大写。
常量蜕变成变量?你胡扯吧,加了final和static的常量怎么可能会变呢?不可能为此赋值的呀。真的不可能吗?看看如下代码:
RAND_CONST是常量吗?它的值会变吗?绝对会变!这种常量的定义方式是绝对不可取的,常量就是常量,在编译期就必须确定其值,不应该在运行期更改,否则程序的可读性会非常差,甚至连作者自己都不能确定在运行期发生了何种神奇的事情。
甭想着使用常量会变的这个功能来实现序列号算法、随机种子生成,除非这真的是项目中的唯一方案,否则就放弃吧,常量还是当常量使用。
注意:务必让常量的值在运行期保持不变。
三元操作符是if-else的简化写法,在项目中使用它的地方很多,也非常好用,但是好用又简单的东西并不表示就可以随意使用,看看如下代码:
分析一下这段程序,i是80,小于100,两者的返回值肯定都是90,再转成String类型,其值也绝对相等,毋庸置疑的。嗯,分析的有点道理,但是变量str中的三元操作符的第二个操作数是100,而str1中的第二个操作数是100.0,难道木有影响吗?不可能有影响吧,三元操作符的条件都为真了,只返回第一个值嘛,于第二个值有毛线关系,貌似有道理。
运行之后,结果却是:"两者是否相等:false",不相等,why?
问题就出在了100和100.0这两个数字上,在变量str中,三元操作符的第一个操作数90和第二个操作数100都是int类型,类型相同,返回的结果也是int类型的90,而变量str1中的第一个操作数(90)是int类型,第二个操作数100.0是浮点数,也就是两个操作数的类型不一致,可三元操作符必须要返回一个数据,而且类型要确定,不可能条件为真时返回int类型,条件为假时返回float类型,编译器是不允许如此的,所以它会进行类型转换int类型转换为浮点数90.0,也就是三元操作符的返回值是浮点数90.0,那么当然和整型的90不相等了。这里为什么是整型转成浮点型,而不是浮点型转成整型呢?这就涉及三元操作符类型的转换规则:
若两个操作数不可转换,则不作转换,返回值是Object类型;
若两个操作数是明确类型的表达式(比如变量),则按照正常的二进制数字转换,int转为long,long转为float等;
若两个操作数中有一个是数字S,另外一个是表达式,且其类型标志位T,那么,若数字S在T的范围内,则转换为T类型;若S超出了T的范围,则T转换为S;
若两个操作数都是直接量数字,则返回值类型范围较大者。
知道什么原因了,相应的解决办法也就有了:保证三元操作符中的两个操作数类型一致,避免此错误的发生。
在项目和系统开发中,为了提高方法的灵活度和可复用性,我们经常要传递不确定数量的参数到方法中,在JAVA5之前常用的设计技巧就是把形参定义成Collection类型或其子类类型,或者数组类型,这种方法的缺点就是需要对空参数进行判断和筛选,比如实参为null值和长度为0的Collection或数组。而Java5引入了变长参数(varags)就是为了更好地挺好方法的复用性,让方法的调用者可以"随心所欲"地传递实参数量,当然变长参数也是要遵循一定规则的,比如变长参数必须是方法中的最后一个参数;一个方法不能定义多个变长参数等,这些基本规则需要牢记,但是即使记住了这些规则,仍然有可能出现错误,看如下代码:
这是一个计算商品折扣的模拟类,带有两个参数的calPrice方法(该方法的业务逻辑是:提供商品的原价和折扣率,即可获得商品的折扣价)是一个简单的折扣计算方法,该方法在实际项目中经常会用到,这是单一的打折方法。而带有变长参数的calPrice方法是叫较复杂的折扣计算方式,多种折扣的叠加运算(模拟类是比较简单的实现)在实际中也经常见到,比如在大甩卖期间对VIP会员再度进行打折;或者当天是你的生日,再给你打个9折,也就是俗话中的折上折。
业务逻辑清楚了,我们来仔细看看这两个方法,它们是重载吗?当然是了,重载的定义是:"方法名相同,参数类型或数量不同",很明显这两个方法是重载。但是这个重载有点特殊,calPrice(int price ,int... discounts)的参数范畴覆盖了calPrice(int price,int discount)的参数范畴。那问题就出来了:对于calPrice(499,75)这样的计算,到底该调用哪个方法来处理呢?
我们知道java编译器是很聪明的,它在编译时会根据方法签名来确定调用那个方法,比如:calPrice(499,75,95)这个调用,很明显75和95会被转成一个包含两个元素的数组,并传递到calPrice(int price,int...discounts)中,因为只有这一个方法符合这个实参类型,这很容易理解。但是我们现在面对的是calPrice(499,75)调用,这个75既可以被编译成int类型的75,也可以被编译成int数组{75},即只包含一个元素的数组。那到底该调用哪一个方法呢?运行结果是:"简单折扣后的价格是:374.25"。看来调用了第一个方法,为什么会调用第一个方法,而不是第二个变长方法呢?因为java在编译时,首先会根据实参的数量和类型(这里2个实参,都为int类型,注意没有转成int数组)来进行处理,也就是找到calPrice(int price,int discount)方法,而且确认他是否符合方法签名条件。现在的问题是编译器为什么会首先根据两个int类型的实参而不是一个int类型,一个int数组类型的实参来查找方法呢?
因为int是一个原生数据类型,而数组本身是一个对象,编译器想要"偷懒",于是它会从最简单的开始"猜想",只要符合编译条件的即可通过,于是就出现了此问题。
问题阐述清楚了,为了让我们的程序能被"人类"看懂,还是慎重考虑变长参数的方法重载吧,否则让人伤脑筋不说,说不定哪天就陷入这类小陷阱里了。
上一建议讲解了变长参数的重载问题,本建议会继续讨论变长参数的重载问题,上一建议的例子是变长参数的范围覆盖了非变长参数的范围,这次讨论两个都是变长参数的方法说起,代码如下:
两个methodA都进行了重载,现在的问题是:上面的client5.methodA("china");client5.methodA("china", null);编译不通过,提示相同:方法模糊不清,编译器不知道调用哪一个方法,但这两处代码反应的味道是不同的。
对于methodA("china")方法,根据实参"china"(String类型),两个方法都符合形参格式,编译器不知道调用那个方法,于是报错。我们思考一下此问题:Client5这个类是一个复杂的商业逻辑,提供了两个重载方法,从其它模块调用(系统内本地调用系统或系统外远程系统调用)时,调用者根据变长参数的规范调用,传入变长参数的参数数量可以是N个(N>=0),那当然可以写成client5.methodA("china")方法啊!完全符合规范,但是这个却让编译器和调用者郁闷,程序符合规则却不能运行,如此问题,谁之责任呢?是Client5类的设计者,他违反了KISS原则(Keep it Smile,Stupid,即懒人原则),按照此设计的方法应该很容一调用,可是现在遵循规范却编译不通过,这对设计者和开发者而言都是应该禁止出现的。
对于Client5.methodA("China",null),直接量null是没哟类型的,虽然两个methodA方法都符合调用要求,但不知道调用哪一个,于是报错了。仔细分析一下,除了不符合上面的懒人原则之外,还有一个非常不好的编码习惯,即调用者隐藏了实参类型,这是非常危险的,不仅仅调用者需要"猜测调用那个方法",而且被调用者也可能产生内部逻辑混乱的情况。对于本例来说应该如此修改:
在JAVA中,子类覆写父类的中的方法很常见,这样做既可以修正bug,也可以提供扩展的业务功能支持,同时还符合开闭原则(Open-Closed Principle)。
符合开闭原则(Open-Closed Principle)的主要特征:
1.对于扩展是开放的(Open for extension)。这意味着模块的行为是可以扩展的。当应用的需求改变时,我们可以对模块进行扩展,使其具有满足那些改变的新行为。也就是说,我们可以改变模块的功能。
2.对于修改是关闭的(Closed for modification)。对模块行为进行扩展时,不必改动模块的源代码或者二进制代码。模块的二进制可执行版本,无论是可链接的库、DLL或者.EXE文件,都无需改动。
下面我们看一下覆写必须满足的条件:
覆写方法不能缩小访问权限;
参数列表必须与被覆写方法相同;
返回类型必须与被重写方法的相同;
重写方法不能抛出新的异常,或者超出父类范围的异常,但是可以抛出更少,更有限的异常,或者不抛出异常。
看下面这段代码:
该程序中sub.fun(100, 50)报错,提示找不到fun(int,int)方法。这太奇怪了:子类继承了父类的所有属性和方法,甭管是私有的还是公开的访问权限,同样的参数,同样的方法名,通过父类调用没有任何问题,通过子类调用,却编译不过,为啥?难到是没继承下来?或者子类缩小了父类方法的前置条件?如果是这样,就不应该覆写,@Override就应该报错呀。
事实上,base对象是把子类对象做了向上转型,形参列表由父类决定,由于是变长参数,在编译时,base.fun(100, 50);中的50这个实参会被编译器"猜测"而编译成"{50}"数组,再由子类Sub执行。我们再来看看直接调用子类的情况,这时编译器并不会把"50"座类型转换因为数组本身也是一个对象,编译器还没有聪明到要在两个没有继承关系的类之间转换,要知道JAVA是要求严格的类型匹配的,类型不匹配编译器自然就会拒绝执行,并给予错误提示。
这是个特例,覆写的方法参数列表竟然与父类不相同,这违背了覆写的定义,并且会引发莫名其妙的错误。所以读者在对变长参数进行覆写时,如果要使用次类似的方法,请仔细想想是不是要一定如此。
注意:覆写的方法参数与父类相同,不仅仅是类型、数量,还包括显示形式.
记得大学刚开始学C语言时,老师就说:自增有两种形式,分别是i++和++i,i++表示的先赋值后加1,++i是先加1后赋值,这样理解了很多年也木有问题,直到遇到如下代码,我才怀疑我的理解是不是错了:
这个程序输出的count等于几?是count自加10次吗?答案等于10?可以肯定的说,这个运行结果是count=0。为什么呢?
count++是一个表达式,是由返回值的,它的返回值就是count自加前的值,Java对自加是这样处理的:首先把count的值(注意是值,不是引用)拷贝到一个临时变量区,然后对count变量+1,最后返回临时变量区的值。程序第一次循环处理步骤如下:
JVM把count的值(其值是0)拷贝到临时变量区;
count的值+1,这时候count的值是1;
返回临时变量区的值,注意这个值是0,没修改过;
返回值赋给count,此时count的值被重置为0.
"count=count++"这条语句可以按照如下代码理解:
于是第一次循环后count的值为0,其它9次循环也是一样的,最终你会发现count的值始终没有改变,仍然保持着最初的状态.
此例中代码作者的本意是希望count自增,所以想当然的赋值给自身就可以了,不曾想到调到Java自增的陷阱中了,解决办法很简单,把"count=count++"改为"count++"即可。该问题在不同的语言环境中有着不同的实现:C++中"count=count++"与"count++"是等效的,而在PHP中保持着与JAVA相同的处理方式。每种语言对自增的实现方式各不相同。
这段代码分析一下,输出结果,以及语法含义:
首先这段代码中有标号(:)操作符,C语言的同学一看便知,类似JAVA中的保留关键字 go to 语句,但Java中抛弃了goto语法,只是不进行语义处理,与此类似的还有const关键字。
Java中虽然没有了goto语法,但扩展了break和continue关键字,他们的后面都可以加上标号做跳转,完全实现了goto功能,同时也把goto的诟病带进来了。
运行之后代码输入为"save....",运行时没错,但这样的代码,给大家阅读上造成了很大的问题,所以就语法就让他随风远去吧!
从Java5开始引入了静态导入语法(import static),其目的是为了减少字符的输入量,提高代码的可阅读性,以便更好地理解程序。我们先俩看一个不用静态导入的例子,也就是一般导入:
这是很简单的两个方法,我们再这两个计算面积的方法中都引入了java.lang.Math类(该类是默认导入的)中的PI(圆周率)常量,而Math这个类写在这里有点多余,特别是如果Client9类中的方法比较多时。如果每次输入都需要敲入Math这个类,繁琐且多余,静态导入可以解决此问题,使用静态导入后的程序如下:
静态导入的作用是把Math类中的Pi常量引入到本类中,这会是程序更简单,更容易阅读,只要看到PI就知道这是圆周率,不用每次都把类名写全了。但是,滥用静态导入会使程序更难阅读,更难维护,静态导入后,代码中就不需要再写类名了,但我们知道类是"一类事物的描述",缺少了类名的修饰,静态属性和静态方法的表象意义可以被无限放大,这会让阅读者很难弄清楚其属性或者方法代表何意,绳子哪一类的属性(方法)都要思考一番(当然IDE的友好提示功能另说),把一个类的静态导入元素都引入进来了,那简直就是噩梦。我们来看下面的例子:
就这么一段程序,看着就让人恼火,常量PI,这知道是圆周率;parseDouble方法可能是Double类的一个转换方法,这看名称可以猜的到。那紧接着getInstance()方法是哪个类的?是Client9本地类?不对呀,本地没有这个方法,哦,原来是NumberFormat类的方法,这个和formatMessage本地方法没有任何区别了---这代码太难阅读了,肯定有人骂娘。
所以,对于静态导入,一定要追寻两个原则:
不使用*(星号)通配符,除非是导入静态常量类(只包含常量的类或接口);
方法名是具有明确、清晰表象意义的工具类。
何为具有明确、清晰表象意义的工具类,我们看看Junit中使用静态导入的例子:
我们从程序中很容易判断出assertEquals方法是用来断言两个值是否相等的,assertFalse方法则是断言表达式为假,如此确实减少了代码量,而且代码的可读性也提高了,这也是静态导入用到正确的地方带来的好处。
如果在一个类中的方法及属性与静态导入的方法及属性相同会出现什么问题呢?看下面的代码
以上代码中定义了一个String类型的常量PI,又定义了一个abs方法,与静态导入的相同。首先说好消息,代码没有报错,接下来是坏消息:我们不知道那个属性和方法别调用了,因为常量名和方法名相同,到底调用了那一个方法呢?运行之后结果为:
PI = "祖冲之",abs(-100) = 0;
很明显是本地的方法被调用了,为何不调用Math类中的属性和方法呢?那是因为编译器有一个"最短路径"原则:如果能够在本类中查找到相关的变量、常量、方法、就不会去其它包或父类、接口中查找,以确保本类中的属性、方法优先。
因此,如果要变更一个被静态导入的方法,最好的办法是在原始类中重构,而不是在本类中覆盖.
我们编写一个实现了Serializable接口(序列化标志接口)的类,Eclipse马上就会给一个黄色警告:需要添加一个Serial Version ID。为什么要增加?他是怎么计算出来的?有什么用?下面就来解释该问题。
类实现Serializable接口的目的是为了可持久化,比如网络传输或本地存储,为系统的分布和异构部署提供先决条件支持。若没有序列化,现在我们熟悉的远程调用、对象数据库都不可能存在,我们来看一个简单的序列化类:
这是一个简单的JavaBean,实现了Serializable接口,可以在网络上传输,也可以在本地存储然后读取。这里我们以java消息服务(Java Message Service)方式传递对象(即通过网络传递一个对象),定义在消息队列中的数据类型为ObjectMessage,首先定义一个消息的生产者(Producer),代码如下:
这里引入了一个工具类SerializationUtils,其作用是对一个类进行序列化和反序列化,并存储到硬盘上(模拟网络传输),其代码如下:
通过对象序列化过程,把一个内存块转化为可传输的数据流,然后通过网络发送到消息消费者(Customer)哪里,进行反序列化,生成实验对象,代码如下:
这是一个反序列化的过程,也就是对象数据流转换为一个实例的过程,其运行后的输出结果为“混世魔王”。这太easy了,是的,这就是序列化和反序列化的典型Demo。但此处藏着一个问题:如果消息的生产者和消息的消费者(Person类)有差异,会出现何种神奇事件呢?比如:消息生产者中的Person类添加一个年龄属性,而消费者没有增加该属性。为啥没有增加?因为这个是分布式部署的应用,你甚至不知道这个应用部署在何处,特别是通过广播方式发消息的情况,漏掉一两个订阅者也是很正常的。
这中序列化和反序列化的类在不一致的情况下,反序列化时会报一个InalidClassException异常,原因是序列化和反序列化所对应的类版本发生了变化,JVM不能把数据流转换为实例对象。刨根问底:JVM是根据什么来判断一个类的版本呢?
好问题,通过SerializableUID,也叫做流标识符(Stream Unique Identifier),即类的版本定义的,它可以显示声明也可以隐式声明。显示声明格式如下:
private static final long serialVersionUID = 1867341609628930239L;
而隐式声明则是我不声明,你编译器在编译的时候帮我生成。生成的依据是通过包名、类名、继承关系、非私有的方法和属性,以及参数、返回值等诸多因子算出来的,极度复杂,基本上计算出来的这个值是唯一的。
serialVersionUID如何生成已经说明了,我们再来看看serialVersionUID的作用。JVM在反序列化时,会比较数据流中的serialVersionUID与类的serialVersionUID是否相同,如果相同,则认为类没有改变,可以把数据load为实例相同;如果不相同,对不起,我JVM不干了,抛个异常InviladClassException给你瞧瞧。这是一个非常好的校验机制,可以保证一个对象即使在网络或磁盘中“滚过”一次,仍能做到“出淤泥而不染”,完美的实现了类的一致性。
但是,有时候我们需要一点特例场景,例如我的类改变不大,JVM是否可以把我以前的对象反序列化回来?就是依据显示声明的serialVersionUID,向JVM撒谎说"我的类版本没有变化",如此我买你编写的类就实现了向上兼容,我们修改Person类,里面添加private static final long serialVersionUID = 1867341609628930239L;
刚开始生产者和消费者持有的Person类一致,都是V1.0,某天生产者的Person类变更了,增加了一个“年龄”属性,升级为V2.0,由于种种原因(比如程序员疏忽,升级时间窗口不同等)消费端的Person类还是V1.0版本,添加的代码为 priavte int age;以及对应的setter和getter方法。
此时虽然生产这和消费者对应的类版本不同,但是显示声明的serialVersionUID相同,序列化也是可以运行的,所带来的业务问题就是消费端不能读取到新增的业务属性(age属性而已)。通过此例,我们反序列化也实现了版本向上兼容的功能,使用V1.0版本的应用访问了一个V2.0的对象,这无疑提高了代码的健壮性。我们在编写序列化类代码时随手添加一个serialVersionUID字段,也不会带来太多的工作量,但它却可以在关键时候发挥异乎寻常的作用。
显示声明serialVersionUID可以避免对象的不一致,但尽量不要以这种方式向JVM撒谎。
我们知道带有final标识的属性是不变量,也就是只能赋值一次,不能重复赋值,但是在序列化类中就有点复杂了,比如这个类:
这个Peson类(此时V1.0版本)被序列化,然后存储在磁盘上,在反序列化时perName属性会重新计算其值(这与static变量不同,static变量压根就没有保存到数据流中)比如perName属性修改成了"秦叔宝"(版本升级为V2.0),那么反序列化的perName值就是"秦叔宝"。保持新旧对象的final变量相同,有利于代码业务逻辑统一,这是序列化的基本原则之一,也就是说,如果final属性是一个直接量,在反序列化时就会重新计算。对于基本原则不多说,现在说一下final变量的另一种赋值方式:通过构造函数赋值。代码如下:
这也是我们常用的一种赋值方式,可以把Person类定义为版本V1.0,然后进行序列化,看看序列化后有什么问题,序列化代码如下:
Person的实习对象保存到了磁盘上,它时一个贫血对象(承载业务属性定义,但不包含其行为定义),我们做一个简单的模拟,修改一下PerName值代表变更,要注意的是serialVersionUID不变,修改后的代码如下:
此时Person类的版本时V2.0但serialVersionUID没有改变,仍然可以反序列化,代码如下:
现在问题出来了,打印出来的结果是"程咬金" 还是"秦叔宝"?答案是:"程咬金"。final类型的变量不是会重新计算嘛,打印出来的应该是秦叔宝才对呀。为什么会是程咬金?这是因为这里触及到了反序列化的两一个原则:反序列化时构造函数不会执行.
反序列化的执行过程是这样的:JVM从数据流中获取一个Object对象,然后根据数据流中的类文件描述信息(在序列化时,保存到磁盘的对象文件中包含了类描述信息,注意是描述信息,不是类)查看,发现是final变量,需要重新计算,于是引用Person类中的perName值,而此时JVM又发现perName竟没有赋值,不能引用,于是它很聪明的不再初始化,保持原值状态,所以结果就是"程咬金"了。
注意:在序列化类中不使用构造函数为final变量赋值.
为final变量赋值还有另外一种方式:通过方法赋值,及直接在声明时通过方法的返回值赋值,还是以Person类为例来说明,代码如下:
pName属性是通过initName方法的返回值赋值的,这在复杂的类中经常用到,这比使用构造函数赋值更简洁,易修改,那么如此用法在序列化时会不会有问题呢?我们一起看看。Person类写好了(定义为V1.0版本),先把它序列化,存储到本地文件,其代码与之前相同,不在赘述。现在Person类的代码需要修改,initName的返回值改为"秦叔宝".那么我们之前存储在磁盘上的的实例加载上来,pName的会是什么呢?
现在,Person类的代码需要修改,initName的返回值也改变了,代码如下:
上段代码仅仅修改了initName的返回值(Person类为V2.0版本)也就是通过new生成的对象的final变量的值都是"秦叔宝",那么我们把之前存储在磁盘上的实例加载上来,pName的值会是什么呢?
结果是"程咬金",很诧异,上一建议说过final变量会被重新赋值,但是这个例子又没有重新赋值,为什么?
上个建议说的重新赋值,其中的"值"指的是简单对象。简单对象包括:8个基本类型,以及数组、字符串(字符串情况复杂,不通过new关键字生成的String对象的情况下,final变量的赋值与基本类型相同),但是不能方法赋值。
其中的原理是这样的,保存到磁盘上(或网络传输)的对象文件包括两部分:
(1).类描述信息:包括类路径、继承关系、访问权限、变量描述、变量访问权限、方法签名、返回值、以及变量的关联类信息。要注意一点是,它并不是class文件的翻版,它不记录方法、构造函数、static变量等的具体实现。之所以类描述会被保存,很简单,是因为能去也能回嘛,这保证反序列化的健壮运行。
(2).非瞬态(transient关键字)和非静态(static关键字)的实体变量值
注意,这里的值如果是一个基本类型,好说,就是一个简单值保存下来;如果是复杂对象,也简单,连该对象和关联类信息一起保存,并且持续递归下去(关联类也必须实现Serializable接口,否则会出现序列化异常),也就是递归到最后,还是基本数据类型的保存。
正是因为这两个原因,一个持久化的对象文件会比一个class类文件大很多,有兴趣的读者可以自己测试一下,体积确实膨胀了不少。
总结一下:反序列化时final变量在以下情况下不会被重新赋值:
通过构造函数为final变量赋值
通过方法返回值为final变量赋值
final修饰的属性不是基本类型
部分属性持久化问题看似很简单,只要把不需要持久化的属性加上瞬态关键字(transient关键字)即可。这是一种解决方案,但有时候行不通。例如一个计税系统和一个HR系统,通过RMI(Remote Method Invocation,远程方法调用)对接,计税系统需要从HR系统获得人员的姓名和基本工资,以作为纳税的依据,而HR系统的工资分为两部分:基本工资和绩效工资,基本工资没什么秘密,绩效工资是保密的,不能泄露到外系统,这明显是连个相互关联的类,先看看薪水类Salary的代码:
Person类和Salary类是关联关系,代码如下:
这是两个简单的JavaBean,都实现了Serializable接口,具备了序列化的条件。首先计税系统请求HR系统对一个Person对象进行序列化,把人员信息和工资信息传递到计税系统中,代码如下:
在通过网络传输到计税系统后,进行反序列化,代码如下:
打印出的结果为:姓名: 张三 基本工资: 1000 绩效工资: 2500
但是这不符合需求,因为计税系统只能从HR系统中获取人员姓名和基本工资,而绩效工资是不能获得的,这是个保密数据,不允许发生泄漏。怎么解决这个问题呢?你可能会想到以下四种方案:
在bonus前加上关键字transient:这是一个方法,但不是一个好方法,加上transient关键字就标志着Salary失去了分布式部署的功能,它可能是HR系统核心的类了,一旦遭遇性能瓶颈,再想实现分布式部署就可能了,此方案否定;
新增业务对象:增加一个Person4Tax类,完全为计税系统服务,就是说它只有两个属性:姓名和基本工资。符合开闭原则,而且对原系统也没有侵入性,只是增加了工作量而已。但是这个方法不是最优方法;
请求端过滤:在计税系统获得Person对象后,过滤掉Salary的bonus属性,方案可行但不符合规矩,因为HR系统中的Salary类安全性竟然然外系统(计税系统来承担),设计严重失职;
变更传输契约:例如改用XML传输,或者重建一个WebSerive服务,可以做但成本很高。
下面展示一个优秀的方案,其中实现了Serializable接口的类可以实现两个私有方法:writeObject和readObject,以影响和控制序列化和反序列化的过程。我们把Person类稍作修改,看看如何控制序列化和反序列化,代码如下:
其它代码不做任何改动,运行之后结果为:姓名: 张三 基本工资: 1000 绩效工资: 0
在Person类中增加了writeObject和readObject两个方法,并且访问权限都是私有级别,为什么会改变程序的运行结果呢?其实这里用了序列化的独有机制:序列化回调。Java调用ObjectOutputStream类把一个对象转换成数据流时,会通过反射(Refection)检查被序列化的类是否有writeObject方法,并且检查其是否符合私有,无返回值的特性,若有,则会委托该方法进行对象序列化,若没有,则由ObjectOutputStream按照默认规则继续序列化。同样,在从流数据恢复成实例对象时,也会检查是否有一个私有的readObject方法,如果有,则会通过该方法读取属性值,此处有几个关键点需要说明:
oos.defaultWriteObject():告知JVM按照默认的规则写入对象,惯例的写法是写在第一行。
input.defaultReadObject():告知JVM按照默认规则读入对象,惯例的写法是写在第一行。
oos.writeXX和input.readXX
分别是写入和读出相应的值,类似一个队列,先进先出,如果此处有复杂的数据逻辑,建议按封装Collection对象处理。大家可能注意到上面的方式也是Person失去了分布式部署的能了,确实是,但是HR系统的难点和重点是薪水的计算,特别是绩效工资,它所依赖的参数很复杂(仅从数量上说就有上百甚至上千种),计算公式也不简单(一般是引入脚本语言,个性化公式定制)而相对来说Person类基本上都是静态属性,计算的可能性不大,所以即使为性能考虑,Person类为分布式部署的意义也不大。
我们经常会写一些转换类,比如货币转换,日期转换,编码转换等,在金融领域里用到的最多的要数中文数字转换了,比如把"1"转换为"壹" ,不过开源工具是不会提供此工具类的,因为它太贴近中国文化了,需要自己编写:
这是一个简单的代码,但运行结果却是"玖",这个很简单,可能大家在刚接触语法时都学过,但虽简单,如果程序员漏写了,简单的问题会造成很大的后果,甚至经济上的损失。所以在用switch语句上记得加上break,养成良好的习惯。对于此类问题,除了平常小心之外,可以使用单元测试来避免,但大家都晓得,项目紧的时候,可能但单元测试都覆盖不了。所以对于此类问题,一个最简单的办法就是:修改IDE的警告级别,例如在Eclipse中,可以依次点击PerFormaces-->Java-->Compiler-->Errors/Warings-->Potential Programming problems,然后修改'switch' case fall-through为Errors级别,如果你胆敢不在case语句中加入break,那Eclipse直接就报个红叉给你看,这样可以避免该问题的发生了。但还是啰嗦一句,养成良好习惯更重要!
Java世界一直在遭受着异种语言的入侵,比如PHP,Ruby,Groovy、Javascript等,这些入侵者都有一个共同特征:全是同一类语言-----脚本语言,它们都是在运行期解释执行的。为什么Java这种强编译型语言会需要这些脚本语言呢?那是因为脚本语言的三大特征,如下所示:
灵活:脚本语言一般都是动态类型,可以不用声明变量类型而直接使用,可以再运行期改变类型。
便捷:脚本语言是一种解释性语言,不需要编译成二进制代码,也不需要像Java一样生成字节码。它的执行时依靠解释器解释的,因此在运行期间变更代码很容易,而且不用停止应用;
简单:只能说部分脚本语言简单,比如Groovy,对于程序员来说,没有多大的门槛。
脚本语言的这些特性是Java缺少的,引入脚本语言可以使Java更强大,于是Java6开始正式支持脚本语言。但是因为脚本语言比较多,Java的开发者也很难确定该支持哪种语言,于是JSCP(Java Community ProCess)很聪明的提出了JSR233规范,只要符合该规范的语言都可以在Java平台上运行(它对JavaScript是默认支持的)。
简单看看下面这个小例子:
这就是一个简单的脚本语言函数,可能你会很疑惑:factor(因子)这个变量是从那儿来的?它是从上下文来的,类似于一个运行的环境变量。该js保存在C:/model.js中,下一步需要调用JavaScript公式,代码如下:
上段代码使用Scanner类接受键盘输入的两个数字,然后调用JavaScript脚本的formula函数计算其结果,注意,除非输入了一个非int数字,否则当前JVM会一直运行,这也是模拟生成系统的在线变更情况。运行结果如下:
输入参数是;1,2 运算结果是:3
此时,保持JVM的运行状态,我们修改一下formula函数,代码如下:
其中,乘号变成了减号,计算公式发生了重大改变。回到JVM中继续输入,运行结果如下:
输入参数:1,2 运行结果是:2
修改Js代码,JVM没有重启,输入参数也没有任何改变,仅仅改变脚本函数即可产生不同的效果。这就是脚本语言对系统设计最有利的地方:可以随时发布而不用部署;这也是我们javaer最喜爱它的地方----即使进行变更,也能提供不间断的业务服务。
Java6不仅仅提供了代码级的脚本内置,还提供了jrunscript命令工具,它可以再批处理中发挥最大效能,而且不需要通过JVM解释脚本语言,可以直接通过该工具运行脚本。想想看。这是多么大的诱惑力呀!而且这个工具是可以跨操作系统的,脚本移植就更容易了。
动态编译一直是java的梦想,从Java6开始支持动态编译了,可以再运行期直接编译.java文件,执行.class,并且获得相关的输入输出,甚至还能监听相关的事件。不过,我们最期望的还是定一段代码,直接编译,然后运行,也就是空中编译执行(on-the-fly),看如下代码:
上面代码较多,可以作为一个动态编译的模板程序。只要是在本地静态编译能够实现的任务,比如编译参数,输入输出,错误监控等,动态编译都能实现。
Java的动态编译对源提供了多个渠道。比如,可以是字符串,文本文件,字节码文件,还有存放在数据库中的明文代码或者字节码。汇总一句话,只要符合Java规范的就可以在运行期动态加载,其实现方式就是实现JavaFileObject接口,重写getCharContent、openInputStream、openOutputStream,或者实现JDK已经提供的两个SimpleJavaFileObject、ForwardingJavaFileObject,具体代码可以参考上个例子。
动态编译虽然是很好的工具,让我们可以更加自如的控制编译过程,但是在我们目前所接触的项目中还是使用较少。原因很简单,静态编译已经能够帮我们处理大部分的工作,甚至是全部的工作,即使真的需要动态编译,也有很好的替代方案,比如Jruby、Groovy等无缝的脚本语言。另外,我们在使用动态编译时,需要注意以下几点:
在框架中谨慎使用:比如要在struts中使用动态编译,动态实现一个类,它若继承自ActionSupport就希望它成为一个Action。能做到,但是debug很困难;再比如在Spring中,写一个动态类,要让它注入到Spring容器中,这是需要花费老大功夫的。
不要在要求性能高的项目中使用:如果你在web界面上提供了一个功能,允许上传一个java文件然后运行,那就等于说:"我的机器没有密码,大家都可以看看",这是非常典型的注入漏洞,只要上传一个恶意Java程序就可以让你所有的安全工作毁于一旦。
记录动态编译过程:建议记录源文件,目标文件,编译过程,执行过程等日志,不仅仅是为了诊断,还是为了安全和审计,对Java项目来说,空中编译和运行时很不让人放心的,留下这些依据可以很好地优化程序。
instanceof是一个简单的二元操作符,它是用来判断一个对象是否是一个类的实现,其操作类似于>=、==,非常简单,我们看段程序,代码如下:
就这么一段程序,instanceof的应用场景基本都出现了,同时问题也产生了:这段程序中哪些语句编译不通过,我们一个一个的解释说:
null instanceof String:返回值为false,这是instanceof特有的规则,若做操作数为null,结果就直接返回false,不再运算右操作数是什么类。这对我们的程序非常有利,在使用instanceof操作符时,不用关心被判断的类(也就是左操作数)是否为null,这与我们经常用到的equals、toString方法不同。
在防御式编程中经常会用断言(Assertion)对参数和环境做出判断,避免程序因不当的判断或输入错误而产生逻辑异常,断言在很多语言中都存在,C、C++、Python都有不同的断言表现形式.在Java中断言使用的是assert关键字,其基本用法如下:
assert<布尔表达式>
assert<布尔表达式> : <错误信息>
在布尔表达式为假时,跑出AssertionError错误,并附带了错误信息。assert的语法比较简单,有以下两个特性:
(1)、assert默认是不启用的
我们知道断言是为调试程序服务的,目的是为了能够迅速、方便地检查到程序异常,但Java在默认条件下是不启用的,要启用就要在编译、运行时加上相关的关键字,这就不多说,有需要的话可以参考一下Java规范。
(2)、assert跑出的异常AssertionError是继承自Error的
断言失败后,JVM会抛出一个AssertionError的错误,它继承自Error,注意,这是一个错误,不可恢复,也就是表明这是一个严重问题,开发者必须予以关注并解决之。
assert虽然是做断言的,但不能将其等价于if...else...这样的条件判断,它在以下两种情况下不可使用:
(1)、在对外的公开方法中
我们知道防御式编程最核心的一点就是:所有的外部因素(输入参数、环境变量、上下文)都是"邪恶"的,都存在着企图摧毁程序的罪恶本源,为了抵制它,我们要在程序处处检验。满地设卡,不满足条件,就不执行后续程序,以保护后续程序的正确性,处处设卡没问题,但就是不能用断言做输入校验,特别是公开方法。我们开看一个例子:
encode方法对输入参数做了不为空的假设,如果为空,则抛出AssertionError错误,但这段程序存在一个严重的问题,encode是一个public方法,这标志着它时对外公开的,任何一个类只要能传递一个String类型的参数(遵守契约)就可以调用,但是Client19类按照规定和契约调用encode方法,却获得了一个AssertionError错误信息,是谁破坏了契约协议?---是encode方法自己。
(2)、在执行逻辑代码的情况下
assert的支持是可选的,在开发时可以让他运行,但在生产环境中系统则不需要其运行了(以便提高性能),因此在assert的布尔表达式中不能执行逻辑代码,否则会因为环境的不同而产生不同的逻辑,例如:
这段代码在assert启用的环境下没有任何问题,但是一但投入到生成环境,就不会启用断言了,而这个方法就彻底完蛋了,list的删除动作永远不会执行,所以就永远不会报错或异常了,因为根本就没有执行嘛!
以上两种情况下不能使用断言assert,那在什么情况下能够使用assert呢?一句话:按照正常的执行逻辑不可能到达的代码区域可以防止assert。具体分为三种情况:
在私有方法中放置assert作为输入参数的校验:在私有方法中可以放置assert校验输入参数,因为私有方法的使用者是作者自己,私有的方法的调用者和被调用者是一种契约关系,或者说没有契约关系,期间的约束是靠作者自己控制的,因此加上assert可以更好地预防自己犯错,或者无意的程序犯错。
流程控制中不可能到达的区域:这类似于Junit的fail方法,其标志性的意义就是,程序执行到这里就是错误的,例如:
3.建立程序探针:我们可能会在一段程序中定义两个变量,分别代两个不同的业务含义,但是两者有固定的关系,例如:var1=var2 * 2,那我们就可以在程序中到处设"桩"了,断言这两者的关系,如果不满足即表明程序已经出现了异常,业务也就没有必要运行下去了。
我们经常在系统中定义一个常量接口(或常量类),以囊括系统中所涉及的常量,从而简化代码,方便开发,在很多的开源项目中已经采用了类似的方法,比如在struts2中,org.apache.struts2.StrutsConstants就是一个常量类,它定义Struts框架中与配置有关的常量,而org.apache.struts2.StrutsConstants则是一个常量接口,其中定义了OGNL访问的关键字。
关于常量接口(类)我们开看一个例子,首先定义一个常量类:
这是一个非常简单的常量类,定义了人类的最大年龄,我们引用这个常量,代码如下:
运行结果easy,故省略。目前的代码是写在"智能型"IDE工具中完成的,下面暂时回溯到原始时代,也就是回归到用记事本编写代码的年代,然后看看会发生什么事情(为什么要如此,下面会给出答案)
修改常量Constant类,人类的寿命极限增加了,最大活到180,代码如下:
然后重新编译,javac Constant,编译完成后执行:java Client,大家猜猜输出的年龄是多少?
输出的结果是:"人类的寿命极限是150",竟然没有改成180,太奇怪了,这是为何?
原因是:对于final修饰的基本类型和String类型,编译器会认为它是稳定态的(Immutable Status)所以在编译时就直接把值编译到字节码中了,避免了在运行期引用(Run-time Reference),以提高代码的执行效率。对于我们的例子来说,Client类在编译时字节码中就写上了"150",这个常量,而不是一个地址引用,因此无论你后续怎么修改常量类,只要不重新编译Client类,输出还是照旧。
对于final修饰的类(即非基本类型),编译器会认为它不是稳定态的(Mutable Status),编译时建立的则是引用关系(该类型也叫作Soft Final)。如果Client类引入的常量是一个类或实例,及时不重新编译也会输出最新值。
千万不可小看了这点知识,细坑也能绊倒大象,比如在一个web项目中,开发人员修改了一个final类型的值(基本类型)考虑到重新发布的风险较大,或者是审批流程过于繁琐,反正是为了偷懒,于是直接采用替换class类文件的方式发布,替换完毕后应用服务器自动重启,然后简单测试一下,一切Ok,可运行几天后发现业务数据对不上,有的类(引用关系的类)使用了旧值,有的类(继承关系的类)使用的是新值,而且毫无头绪,让人一筹莫展,其实问题的根源就在于此。
还有个小问题没有说明,我们的例子为什么不在IDE工具(比如Eclipse)中运行呢?那是因为在IDE中设置了自动编译不能重现此问题,若修改了Constant类,IDE工具会自动编译所有的引用类,"智能"化屏蔽了该问题,但潜在的风险其实仍然存在,我记得Eclipse应该有个设置自动编译的入口,有兴趣大家可以自己尝试一下。
注意:发布应用系统时禁止使用类文件替换方式,整体WAR包发布才是万全之策。但我觉得应特殊情况特殊对待,并不可以偏概全,大家以为呢?
判断一个数是奇数还是偶数是小学里的基本知识,能够被2整除的整数是偶数,不能被2整除的数是奇数,这规则简单明了,还有什么可考虑的?好,我们来看一个例子,代码如下:
输入多个数字,然后判断每个数字的奇偶性,不能被2整除的就是奇数,其它的都是偶数,完全是根据奇偶数的定义编写的程序,我们开看看打印的结果:
输入多个数字判断奇偶:1 2 0 -1 -2 1-->奇数 2-->偶数 0-->偶数 -1-->偶数 -2-->偶数
前三个还很靠谱,第四个参数-1怎么可能是偶数呢,这Java也太差劲了吧。如此简单的计算也会出错!别忙着下结论,我们先来了解一下Java中的取余(%标识符)算法,模拟代码如下:
看到这段程序,大家都会心的笑了,原来Java这么处理取余计算的呀,根据上面的模拟取余可知,当输入-1的时候,运算结果为-1,当然不等于1了,所以它就被判定为偶数了,也就是我们的判断失误了。问题明白了,修正也很简单,改为判断是否是偶数即可。代码如下: i % 2 == 0 ? "偶数" : "奇数";
注意:对于基础知识,我们应该"知其然,并知其所以然"。
在日常生活中,最容易接触到的小数就是货币,比如,你付给售货员10元钱购买一个9.6元的零食,售货员应该找你0.4元,也就是4毛钱才对,我们来看下面的程序:
我们的期望结果是0.4,也应该是这个数字,但是打印出来的却是:0.40000000000000036,这是为什么呢?
这是因为在计算机中浮点数有可能(注意是有可能)是不准确的,它只能无限接近准确值,而不能完全精确。为什么会如此呢?这是由浮点数的存储规则所决定的,我们先来看看0.4这个十进制小数如何转换成二进制小数,使用"乘2取整,顺序排列"法(不懂,这就没招了,这太基础了),我们发现0.4不能使用二进制准确的表示,在二进制数世界里它是一个无限循环的小数,也就是说,"展示" 都不能 "展示",更别说在内存中存储了(浮点数的存储包括三部分:符号位、指数位、尾数,具体不再介绍),可以这样理解,在十进制的世界里没有办法唯一准确表示1/3,那么在二进制的世界里当然也无法准确表示1/5(如果二进制也有分数的话倒是可以表示),在二进制的世界里1/5是一个无限循环的小数。
大家可能要说了,那我对结果取整不就对了吗?代码如下
打印出的结果是0.4,看似解决了。但是隐藏了一个很深的问题。我们来思考一下金融行业的计算方法,会计系统一般记录小数点后的4为小数,但是在汇总、展现、报表中、则只记录小数点后的2位小数,如果使用浮点数来计算货币,想想看,在大批量加减乘除后结果会有很大的差距(其中还涉及到四舍五入的问题)!会计系统要求的就是准确,但是因为计算机的缘故不准确了,那真是罪过,要解决此问题有两种方法:
(1)、使用BigDecimal
BigDecimal是专门为弥补浮点数无法精确计算的缺憾而设计的类,并且它本身也提供了加减乘除的常用数学算法。特别是与数据库Decimal类型的字段映射时,BigDecimal是最优的解决方案。
(2)、使用整型
把参与运算的值扩大100倍,并转为整型,然后在展现时再缩小100倍,这样处理的好处是计算简单,准确,一般在非金融行业(如零售行业)应用较多。此方法还会用于某些零售POS机,他们输入和输出的全部是整数,那运算就更简单了.
我们做一个小学生的题目,光速每秒30万公里,根据光线的旅行时间,计算月球和地球,太阳和地球之间的距离。代码如下:
估计有人鄙视了,这种小学生的乘法有神么可做的,不错,就是一个乘法运算,我们运行之后的结果如下:
题目1:月球照射到地球需要一秒,计算月亮和地球的距离。
月球与地球的距离是:300000000 米
-------------------------------
题目2:太阳光照射到地球需要8分钟,计算太阳到地球的距离.
太阳与地球之间的距离是:-2028888064 米
太阳和地球的距离竟然是负的,诡异。dis2不是已经考虑到int类型可能越界的问题,并使用了long型吗,怎么还会出现负值呢?
那是因为Java是先运算然后进行类型转换的,具体的说就是因为dis2的三个运算参数都是int型,三者相乘的结果虽然也是int型,但是已经超过了int的最大值,所以其值就是负值了(为什么是负值,因为过界了就会重头开始),再转换为long型,结果还是负值。
问题知道了,解决起来也很简单,只要加个小小的L即可,代码如下:
long dis2 = LIGHT_SPEED * 60L * 8;
60L是一个长整型,乘出来的结果也是一个长整型的(此乃Java的基本转换规则,向数据范围大的方向转换,也就是加宽类型),在还没有超过int类型的范围时就已经转换为long型了,彻底解决了越界问题。在实际开发中,更通用的做法是主动声明类型转化(注意,不是强制类型转换)代码如下:
long dis2 = 1L * LIGHT_SPEED * 60L * 8
既然期望的结果是long型,那就让第一个参与的参数也是Long(1L)吧,也就说明"嗨"我已经是长整型了,你们都跟着我一块转为长整型吧。
注意:基本类型转换时,使用主动声明方式减少不必要的Bug.
某商家生产的电子产品非常畅销,需要提前30天预订才能抢到手,同时还规定了一个会员可拥有的最多产品数量,目的是为了防止囤积压货肆意加价。会员的预订过程是这样的:先登录官方网站,选择产品型号,然后设置需要预订的数量,提交,符合规则即提示下单成功,不符合规则提示下单失败,后台的处理模拟如下:
这是一个简单的订单处理程序,其中cur代表的是会员当前拥有的产品数量,LIMIT是一个会员最多拥有的产品数量(现实中,这两个参数当然是从数据库中获得的,不过这里是一个模拟程序),如果当前预订数量与拥有数量之和超过了最大数量,则预订失败,否则下单成功。业务逻辑很简单,同时在web界面上对订单数量做了严格的校验,比如不能是负值、不能超过最大数量等,但是人算不如天算,运行不到两小时数据库中就出现了异常数据:某会员拥有的产品数量与预定数量之和远远大于限额。怎么会这样呢?程序逻辑上不可能有问题呀,这如何产生的呢?我们来模拟一下,第一次输入:
请输入需要预定的数量:800 你已经成功预定800个产品
这完全满足条件,没有任何问题,继续输入:
请输入需要预定的数量:2147483647 你已经成功预定2147483647个产品
看到没有,这个数字已经远远超过了2000的限额,但是竟然预定成功了,真实神奇!
看着2147483647这个数字很眼熟?那就对了,这个数字就是int类型的最大值,没错,有人输入了一个最大值,使校验条件失败了,Why?我们来看程序,order的值是2147483647那再加上1000就超出int的范围了,其结果是-2147482649,那当然是小于正数2000了!一句归其原因:数字越界使校验条件失效。
在单元测试中,有一项测试叫做边界测试(也叫临界测试),如果一个方法接收的是int类型的参数,那么以下三个值是必须测试的:0、正最大、负最小,其中正最大、负最小是边界值,如果这三个值都没有问题,方法才是比较安全可靠的。我们的例子就是因为缺少边界测试,致使生产系统产生了严重的偏差。
也许你要疑惑了,Web界面已经做了严格的校验,为什么还能输入2147483647 这么大的数字呢?是否说明Web校验不严格?错了,不是这样的,Web校验都是在页面上通过JavaScript实现的,只能限制普通用户(这里的普通用户是指不懂html,不懂HTTP,不懂Java的简单使用者),而对于高手,这些校验基本上就是摆设,HTTP是明文传输的,将其拦截几次,分析一下数据结构,然后写一个模拟器,一切前端校验就成了浮云!想往后台提交个什么数据还不是信手拈来!
本建议还是来重温一个小学数学问题:四舍五入。四舍五入是一种近似精确的计算方法,在Java5之前,我们一般是通过Math.round来获得指定精度的整数或小数的,这种方法使用非常广泛,代码如下:
输出结果为:10.5近似值: 11 -10.5近似值: -10
这是四舍五入的经典案例,也是初级面试官很乐意选择的考题,绝对值相同的两个数字,近似值为什么就不同了呢?这是由Math.round采用的舍入规则决定的(采用的是正无穷方向舍入规则),我们知道四舍五入是有误差的:其误差值是舍入的一半。我们以舍入运用最频繁的银行利息计算为例来阐述此问题。
我们知道银行的盈利渠道主要是利息差,从储户手里收拢资金,然后房贷出去,期间的利息差额便是所获得利润,对一个银行来说,对付给储户的利息计算非常频繁,人民银行规定每个季度末月的20日为银行结息日,一年有4次的结息日。
场景介绍完毕,我们回头来看看四舍五入,小于5的数字被舍去,大于5的数字进位后舍去,由于单位上的数字都是自然计算出来的,按照利率计算可知,被舍去的数字都分布在0~9之间,下面以10笔存款利息计算作为模型,以银行家的身份来思考这个算法:
四舍:舍弃的数值是:0.000、0.001、0.002、0.003、0.004因为是舍弃的,对于银行家来说就不需要付款给储户了,那每舍一个数字就会赚取相应的金额:0.000、0.001、0.002、0.003、0.004.
五入:进位的数值是:0.005、0.006、0.007、0.008、0.009,因为是进位,对银行家来说,每进一位就会多付款给储户,也就是亏损了,那亏损部分就是其对应的10进制补数:0.005、.0004、0.003、0.002、0.001.
因为舍弃和进位的数字是均匀分布在0~9之间,对于银行家来说,没10笔存款的利息因采用四舍五入而获得的盈利是:
0.000 + 0.001 + 0.002 + 0.003 + 0.004 - 0.005 - 0.004 - 0.003 - 0.002 - 0.001 = - 0.005;
也就是说,每10笔利息计算中就损失0.005元,即每笔利息计算就损失0.0005元,这对一家有5千万储户的银行家来说(对国内银行来说,5千万是个小数字),每年仅仅因为四舍五入的误差而损失的金额是:
银行账户数量(5千万)*4(一年计算四次利息)*0.0005(每笔利息损失的金额)
5000*10000*0.0005*4=100000.0;即,每年因为一个算法误差就损失了10万元,事实上以上的假设条件都是非常保守的,实际情况可能损失的更多。那各位可能要说了,银行还要放贷呀,放出去这笔计算误差不就抵消了吗?不会抵消,银行的贷款数量是非常有限的其数量级根本无法和存款相比。
这个算法误差是由美国银行家发现的(那可是私人银行,钱是自己的,白白损失了可不行),并且对此提出了一个修正算法,叫做银行家舍入(Banker's Round)的近似算法,其规则如下:
舍去位的数值小于5时,直接舍去;
舍去位的数值大于等于6时,进位后舍去;
当舍去位的数值等于5时,分两种情况:5后面还有其它数字(非0),则进位后舍去;若5后面是0(即5是最后一个数字),则根据5前一位数的奇偶性来判断是否需要进位,奇数进位,偶数舍去。
以上规则汇总成一句话:四舍六入五考虑,五后非零就进一,五后为零看奇偶,五前为偶应舍去,五前为奇要进一。我们举例说明,取2位精度;
round(10.5551) = 10.56 round(10.555) = 10.56 round(10.545) = 10.54
要在Java5以上的版本中使用银行家的舍入法则非常简单,直接使用RoundingMode类提供的Round模式即可,示例代码如下:
在上面的例子中,我们使用了BigDecimal类,并且采用了setScale方法设置了精度,同时传递了一个RoundingMode.HALF_EVEN参数表示使用银行家法则进行近似计算,BigDecimal和RoundingMode是一个绝配,想要采用什么方式使用RoundingMode设置即可。目前Java支持以下七种舍入方式:
ROUND_UP:原理零方向舍入。向远离0的方向舍入,也就是说,向绝对值最大的方向舍入,只要舍弃位非0即进位。
ROUND_DOWN:趋向0方向舍入。向0方向靠拢,也就是说,向绝对值最小的方向输入,注意:所有的位都舍弃,不存在进位情况。
ROUND_CEILING:向正无穷方向舍入。向正最大方向靠拢,如果是正数,舍入行为类似于ROUND_UP;如果为负数,则舍入行为类似于ROUND_DOWN.注意:Math.round方法使用的即为此模式。
ROUND_FLOOR:向负无穷方向舍入。向负无穷方向靠拢,如果是正数,则舍入行为类似ROUND_DOWN,如果是负数,舍入行为类似以ROUND_UP。
HALF_UP:最近数字舍入(5舍),这就是我们经典的四舍五入。
HALF_DOWN:最近数字舍入(5舍)。在四舍五入中,5是进位的,在HALF_DOWN中却是舍弃不进位。
HALF_EVEN:银行家算法
在普通的项目中舍入模式不会有太多影响,可以直接使用Math.round方法,但在大量与货币数字交互的项目中,一定要选择好近似的计算模式,尽量减少因算法不同而造成的损失。
注意:根据不同的场景,慎重选择不同的舍入模式,以提高项目的精准度,减少算法损失。
我们知道Java引入包装类型(Wrapper Types)是为了解决基本类型的实例化问题,以便让一个基本类型也能参与到面向对象的编程世界中。而在Java5中泛型更是对基本类型说了"不",如果把一个整型放入List中,就必须使用Integer包装类型。我们看一段代码:
上面以Integer和int为例说明了拆箱问题,其它7个包装对象的拆箱过程也存在着同样的问题。包装对象和拆箱对象可以自由转换,这不假,但是要剔除null值,null值并不能转换为基本类型。对于此问题,我们谨记一点:包装类型参与运算时,要做null值校验。
基本类型是可以比较大小的,其所对应的包装类型都实现了Comparable接口,也说明了此问题,那我们来比较一下两个包装类型的大小,代码如下:
代码很简单,产生了两个Integer对象,然后比较两个的大小关系,既然包装类型和基本类型是可以自由转换的,那上面的代码是不是就可以打印出两个相等的值呢?让事实说话,运行结果如下:
false false false
竟然是3个false,也就是说两个值之间不相等,也没大小关系,这个也太奇怪了吧。不奇怪,我们来一 一解释:
i==j:在java中"=="是用来判断两个操作数是否有相等关系的,如果是基本类型则判断值是否相等,如果是对象则判断是否是一个对象的两个引用,也就是地址是否相等,这里很明显是两个对象,两个地址不可能相等。
i>j 和 i<j:在Java中,">" 和 "<" 用来判断两个数字类型的大小关系,注意只能是数字类型的判断,对于Integer包装类型,是根据其intValue()方法的返回值(也就是其相应的基本类型)进行比较的(其它包装类型是根据相应的value值比较的,如doubleValue,floatValue等),那很显然,两者不肯能有大小关系的。
问题清楚了,修改总是比较容易的,直接使用Integer的实例compareTo方法即可,但是这类问题的产生更应该说是习惯问题,只要是两个对象之间的比较就应该采用相应的方法,而不是通过Java的默认机制来处理,除非你确定对此非常了解。
上一个建议我们解释了包装对象的比较问题,本建议将继续深入讨论相关问题,首先看看如下代码:
输入多个数字,然后按照3中不同的方式产生Integer对象,判断其是否相等,注意这里使用了"==",这说明判断的不是同一个对象。我们输入三个数字127、128、555,结果如下:
127
=====127 的相等判断=====
new 产生的对象:false
基本类型转换的对象:true
valueOf产生的对象:true
128
=====128 的相等判断=====
new 产生的对象:false
基本类型转换的对象:false
valueOf产生的对象:false
555
=====555 的相等判断=====
new 产生的对象:false
基本类型转换的对象:false
valueOf产生的对象:false
很不可思议呀,数字127的比较结果竟然和其它两个数字不同,它的装箱动作所产生的对象竟然是同一个对象,valueOf产生的也是同一个对象,但是大于127的数字和128和555的比较过程中产生的却不是同一个对象,这是为什么?我们来一个一个解释。
(1)、new产生的Integer对象
new声明的就是要生成一个新的对象,没二话,这是两个对象,地址肯定不等,比较结果为false。
(2)、装箱生成的对象
对于这一点,首先要说明的是装箱动作是通过valueOf方法实现的,也就是说后两个算法相同的,那结果肯定也是一样的,现在问题是:valueOf是如何生成对象的呢?我们来阅读以下Integer.valueOf的源码:
这段代码的意思已经很明了了,如果是-128到127之间的int类型转换为Integer对象,则直接从cache数组中获得,那cache数组里是什么东西,JDK7的源代码如下:
cache是IntegerCache内部类的一个静态数组,容纳的是-128到127之间的Integer对象。通过valueOf产生包装对象时,如果int参数在-128到127之间,则直接从整型池中获得对象,不在该范围内的int类型则通过new生成包装对象。
明白了这一点,要理解上面的输出结果就迎刃而解了,127的包装对象是直接从整型池中获得的,不管你输入多少次127这个数字,获得的对象都是同一个,那地址自然是相等的。而128、555超出了整型池范围,是通过new产生一个新的对象,地址不同,当然也就不相等了。
以上的理解也是整型池的原理,整型池的存在不仅仅提高了系统性能,同时也节约了内存空间,这也是我们使用整型池的原因,也就是在声明包装对象的时候使用valueOf生成,而不是通过构造函数来生成的原因。顺便提醒大家,在判断对象是否相等的时候,最好使用equals方法,避免使用"=="产生非预期效果。
注意:通过包装类型的valueOf生成的包装实例可以显著提高空间和时间性能。
包装类型是一个类,它提供了诸如构造方法,类型转换,比较等非常实用的功能,而且在Java5之后又实现了与基本类型的转换,这使包装类型如虎添翼,更是应用广泛了,在开发中包装类型已经随处可见,但无论是从安全性、性能方面来说,还是从稳定性方面来说,基本类型都是首选方案。我们看一段代码:
在上面的程序中首先声明了一个int变量i,然后加宽转变成long型,再调用testMethod()方法,分别传递int和long的基本类型和包装类型,诸位想想该程序是否能够编译?如果能编译,输出结果又是什么呢?
首先,这段程序绝对是能够编译的。不过,说不能编译的同学还是动了一番脑筋的,你可能猜测以下这些地方不能编译:
(1)、testMethod方法重载问题。定义的两个testMethod()方法实现了重载,一个形参是基本类型,一个形参是包装类型,这类重载很正常。虽然基本类型和包装类型有自动装箱、自动拆箱功能,但并不影响它们的重载,自动拆箱(装箱)只有在赋值时才会发生,和编译重载没有关系。
(2)、c.testMethod(i) 报错。i 是int类型,传递到testMethod(long a)是没有任何问题的,编译器会自动把 i 的类型加宽,并将其转变为long型,这是基本类型的转换法则,也没有任何问题。
(3)、c.testMethod(new Integer(i))报错。代码中没有testMethod(Integer i)方法,不可能接收一个Integer类型的参数,而且Integer和Long两个包装类型是兄弟关系,不是继承关系,那就是说肯定编译失败了?不,编译时成功的,稍后再解释为什么这里编译成功。
既然编译通过了,我们看一下输出:
基本类型的方法被调用
基本类型的方法被调用
c.testMethod(i)的输出是正常的,我们已经解释过了,那第二个输出就让人困惑了,为什么会调用testMethod(long a)方法呢?这是因为自动装箱有一个重要原则:基本类型可以先加宽,再转变成宽类型的包装类型,但不能直接转变成宽类型的包装类型。这句话比较拗口,简单的说就是,int可以加宽转变成long,然后再转变成Long对象,但不能直接转变成包装类型,注意这里指的都是自动转换,不是通过构造函数生成,为了解释这个原则,我们再来看一个例子:
这段程序的编译是不通过的,因为i是一个int类型,不能自动转变为Long型,但是修改成以下代码就可以通过了:
int i = 140; long a =(long)i; c.testMethod(a);
这就是int先加宽转变成为long型,然后自动转换成Long型,规则说明了,我们继续来看testMethod(Integer.valueOf(i))是如何调用的,Integer.valueOf(i)返回的是一个Integer对象,这没错,但是Integer和int是可以互相转换的。没有testMethod(Integer i)方法?没关系,编译器会尝试转换成int类型的实参调用,Ok,这次成功了,与testMethod(i)相同了,于是乎被加宽转变成long型---结果也很明显了。整个testMethod(Integer.valueOf(i))的执行过程是这样的:
(1)、i 通过valueOf方法包装成一个Integer对象
(2)、由于没有testMethod(Integer i)方法,编译器会"聪明"的把Integer对象转换成int。
(3)、int自动拓宽为long,编译结束
使用包装类型确实有方便的方法,但是也引起一些不必要的困惑,比如我们这个例子,如果testMethod()的两个重载方法使用的是基本类型,而且实参也是基本类型,就不会产生以上问题,而且程序的可读性更强。自动装箱(拆箱)虽然很方便,但引起的问题也非常严重,我们甚至都不知道执行的是哪个方法。
注意:重申,基本类型优先考虑。
看到这样的标题,大家是否感到郁闷呢?接口中有实现代码吗?这怎么可能呢?确实,接口中可以声明常量,声明抽象方法,可以继承父接口,但就是不能有具体实现,因为接口是一种契约(Contract),是一种框架性协议,这表明它的实现类都是同一种类型,或者具备相似特征的一个集合体。对于一般程序,接口确实没有任何实现,但是在那些特殊的程序中就例外了,阅读如下代码:
仔细看main方法,注意那个B接口。它调用了接口常量,在没有实现任何显示实现类的情况下,它竟然打印出了结果,那B接口中的s常量(接口是S)是在什么地方被实现的呢?答案在B接口中。
在B接口中声明了一个静态常量s,其值是一个匿名内部类(Anonymous Inner Class)的实例对象,就是该匿名内部类(当然,也可以不用匿名,直接在接口中是实现内部类也是允许的)实现了S接口。你看,在接口中也存在着实现代码吧!
这确实很好,很强大,但是在一般的项目中,此类代码是严禁出现的,原因很简单:这是一种非常不好的编码习惯,接口是用来干什么的?接口是一个契约,不仅仅约束着实现,同时也是一个保证,保证提供的服务(常量和方法)是稳定的、可靠的,如果把实现代码写到接口中,那接口就绑定了可能变化的因素,这会导致实现不再稳定和可靠,是随时都可能被抛弃、被更改、被重构的。所以,接口中虽然可以有实现,但应避免使用。
注意:接口中不能出现实现代码。
这个标题是否像上一个建议的标题一样让人郁闷呢?什么叫做变量一定要先声明后赋值?Java中的变量不都是先声明后使用的吗?难道还能先使用后声明?能不能暂且不说,我们看一个例子,代码如下:
这段程序很简单,输出100嘛,对,确实是100,我们稍稍修改一下,代码如下:
注意变量 i 的声明和赋值调换了位置,现在的问题是:这段程序能否编译?如过可以编译,输出是多少?还要注意,这个变量i可是先使用(也就是赋值)后声明的。
答案是:可以编译,没有任何问题,输出结果为1。对,输出是 1 不是100.仅仅调换了位置,输出就变了,而且变量 i 还是先使用后声明的,难道颠倒了?
这要从静态变量的诞生说起,静态变量是类加载时被分配到数据区(Data Area)的,它在内存中只有一个拷贝,不会被分配多次,其后的所有赋值操作都是值改变,地址则保持不变。我们知道JVM初始化变量是先声明空间,然后再赋值,也就是说:在JVM中是分开执行的,等价于:
int i ; //分配空间
i = 100; //赋值
静态变量是在类初始化的时候首先被加载的,JVM会去查找类中所有的静态声明,然后分配空间,注意这时候只是完成了地址空间的分配,还没有赋值,之后JVM会根据类中静态赋值(包括静态类赋值和静态块赋值)的先后顺序来执行。对于程序来说,就是先声明了int类型的地址空间,并把地址传递给了i,然后按照类的先后顺序执行赋值操作,首先执行静态块中i = 100,接着执行 i = 1,那最后的结果就是 i =1了。
哦,如此而已,如果有多个静态块对 i 继续赋值呢?i 当然还是等于1了,谁的位置最靠后谁有最终的决定权。
有些程序员喜欢把变量定义放到类最底部,如果这是实例变量还好说,没有任何问题,但如果是静态变量,而且还在静态块中赋值了,那这结果就和期望的不一样了,所以遵循Java通用的开发规范"变量先声明后赋值使用",是一个良好的编码风格。
注意:再次重申变量要先声明后使用,这不是一句废话。
我们知到在Java中可以通过覆写(Override)来增强或减弱父类的方法和行为,但覆写是针对非静态方法(也叫做实例方法,只有生成实例才能调用的方法)的,不能针对静态方法(static修饰的方法,也叫做类方法),为什么呢?我们看一个例子,代码如下:
注意看程序,子类的doAnything方法覆写了父类方法,真没有问题,那么doSomething方法呢?它与父类的方法名相同,输入、输出也相同,按道理来说应该是覆写,不过到底是不是覆写呢?我们看看输出结果: 我是子类非静态方法 我是父类静态方法
这个结果很让人困惑,同样是调用子类方法,一个执行了父类方法,两者的差别仅仅是有无static修饰,却得到不同的结果,原因何在呢?
我们知道一个实例对象有两个类型:表面类型(Apparent Type)和实际类型(Actual Type),表面类型是声明的类型,实际类型是对象产生时的类型,比如我们例子,变量base的表面类型是Base,实际类型是Sub。对于非静态方法,它是根据对象的实际类型来执行的,也就是执行了Sub类中的doAnything方法。而对于静态方法来说就比较特殊了,首先静态方法不依赖实例对象,它是通过类名来访问的;其次,可以通过对象访问静态方法,如果是通过对象访问静态方法,JVM则会通过对象的表面类型查找静态方法的入口,继而执行之。因此上面的程序打印出"我是父类非静态方法",也就不足为奇了。
在子类中构建与父类方法相同的方法名、输入参数、输出参数、访问权限(权限可以扩大),并且父类,子类都是静态方法,此种行为叫做隐藏(Hide),它与覆写有两点不同:
(1)、表现形式不同:隐藏用于静态方法,覆写用于非静态方法,在代码上的表现是@Override注解可用于覆写,不可用于隐藏。
(2)、职责不同:隐藏的目的是为了抛弃父类的静态方法,重现子类方法,例如我们的例子,Sub.doSomething的出现是为了遮盖父类的Base.doSomething方法,也就是i期望父类的静态方法不要做破坏子类的业务行为,而覆写是将父类的的行为增强或减弱,延续父类的职责。
解释了这么多,我们回头看看本建议的标题,静态方法不能覆写,可以再续上一句话,虽然不能覆写,但可以隐藏。顺便说一下,通过实例对象访问静态方法或静态属性不是好习惯,它给代码带来了"坏味道",建议大家阅之戒之。
我们知道通过new关键字生成的对象必然会调用构造函数,构造函数的简繁情况会直接影响实例对象的创建是否繁琐,在项目开发中,我们一般都会制定构造函数尽量简单,尽可能不抛异常,尽量不做复杂运算等规范,那如果一个构造函数确实复杂了会怎么样?我们开看一段代码:
该代码是一个服务类的简单模拟程序,Server类实现了服务器的创建逻辑,子类要在生成实例对象时传递一个端口号即可创建一个监听端口的服务,该代码的意图如下:
通过SimpleServer的构造函数接收端口参数;
子类的构造函数默认调用父类的构造函数;
父类构造函数调用子类的getPort方法获得端口号;
父类的构造函数建立端口监听机制;
对象创建完毕,服务监听启动,正常运行。
貌似很合理,再仔细看看代码,确实与我们的意图相吻合,那我们尝试多次运行看看,输出结果要么是"端口号:40000",要么是"端口号:0",永远不会出现"端口号:100"或是"端口号:1000",这就奇怪了,40000还好说,那个0是怎么冒出来的呢?怠慢什么地方出现了问题呢?
要解释这个问题,我们首先要说说子类是如何实例化的。子类实例化时,会首先初始化父类(注意这里是初始化,不是生成父类对象),也就是初始化父类的变量,调用父类的构造函数,然后才会初始化子类的变量,调用子类的构造函数,最后生成一个实例对象。了解了相关知识,我们再来看看上面的程序,其执行过程如下:
子类SimpleServer的构造函数接收int类型的参数1000;
父类初始化常量,也就是DEFAULT_PORT初始化,并设置值为40000;
执行父类无参构造函数,也就是子类有参构造函数默认包含了super()方法;
父类无参构造函数执行到“int port = getPort() ”方法,调用子类的getPort方法实现;
子类的getPort方法返回port值(注意,此时port变量还没有赋值,是0)或DEFAULT_PORT(此时已经是40000)了;
父类初始化完毕,开始初始化子类的实例变量,port值赋值100;
执行子类构造函数,port值被重新赋值为1000;
子类SimpleServer实例化结束,对象创建完毕。
终于清楚了,在类初始化时getPort方法返回值还没有赋值,port只是获得了默认初始值(int类型的实例变量默认初始值是0),因此Server永远监听的是40000端口(0端口是没有意义的)。这个问题的产生从浅处说是类元素初始顺序导致的,从深处说是因为构造函数太复杂引起的。构造函数用作初始化变量,声明实例的上下文,这都是简单实现的,没有任何问题,但我们的例子却实现了一个复杂的逻辑,而这放在构造函数里就不合适了。
问题知道了,修改也很简单,把父类的无参构造函数中的所有实现都移动到一个叫做start的方法中,将SimpleServer类初始化完毕,再调用其start方法即可实现服务器的启动工作,简洁而又直观,这也是大部分JEE服务器的实现方式。
注意:构造函数简化,再简化,应该达到"一眼洞穿"的境界。
构造函数是一个类初始化必须执行的代码,它决定着类初始化的效率,如果构造函数比较复杂,而且还关联了其它类,则可能产生想不到的问题,我们来看如下代码:
这段代码并不复杂,只是在构造函数中初始化了其它类,想想看这段代码的运行结果是什么?会打印出"Hi ,show me Something!"吗?
答案是这段代码不能运行,报StatckOverflowError异常,栈(Stack)内存溢出,这是因为声明变量son时,调用了Son的无参构造函数,JVM又默认调用了父类的构造函数,接着Father又初始化了Other类,而Other类又调用了Son类,于是一个死循环就诞生了,知道内存被消耗完停止。
大家可能觉得这样的场景不会出现在开发中,我们来思考这样的场景,Father是由框架提供的,Son类是我们自己编写的扩展代码,而Other类则是框架要求的拦截类(Interceptor类或者Handle类或者Hook方法),再来看看问题,这种场景不可能出现吗?
可能大家会觉得这样的场景不会出现,这种问题只要系统一运行就会发现,不可能对项目产生影响。
那是因为我们这里展示的代码比较简单,很容易一眼洞穿,一个项目中的构造函数可不止一两个,类之间的关系也不会这么简单,要想瞥一眼就能明白是否有缺陷这对所有人员来说都是不可能完成的任务,解决此类问题最好的办法就是:不要在构造函数中声明初始化其他类,养成良好习惯。
什么叫做代码块(Code Block)?用大括号把多行代码封装在一起,形成一个独立的数据体,实现特定算法的代码集合即为代码块,一般来说代码快不能单独运行的,必须要有运行主体。在Java中一共有四种类型的代码块:
普通代码块:就是在方法后面使用"{}"括起来的代码片段,它不能单独运行,必须通过方法名调用执行;
静态代码块:在类中使用static修饰,并用"{}"括起来的代码片段,用于静态变量初始化或对象创建前的环境初始化。
同步代码块:使用synchronized关键字修饰,并使用"{}"括起来的代码片段,它表示同一时间只能有一个线程进入到该方法块中,是一种多线程保护机制。
构造代码块:在类中没有任何前缀和后缀,并使用"{}"括起来的代码片段;
我么知道一个类中至少有一个构造函数(如果没有,编译器会无私的为其创建一个无参构造函数),构造函数是在对象生成时调用的,那现在为你来了:构造函数和代码块是什么关系,构造代码块是在什么时候执行的?在回答这个问题之前,我们先看看编译器是如何处理构造代码块的,看如下代码:
这是一段非常简单的代码,它包含了构造代码块、无参构造、有参构造,我们知道代码块不具有独立执行能力,那么编译器是如何处理构造代码块的呢?很简单,编译器会把构造代码块插入到每个构造函数的最前端,上面的代码等价于:
每个构造函数的最前端都被插入了构造代码块,很显然,在通过new关键字生成一个实例时会先执行构造代码块,然后再执行其他代码,也就是说:构造代码块会在每个构造函数内首先执行(需要注意的是:构造代码块不是在构造函数之前运行的,它依托于构造函数的执行),明白了这一点,我们就可以把构造代码块应用到如下场景中:
初始化实例变量(Instance Variable):如果每个构造函数都要初始化变量,可以通过构造代码块来实现。当然也可以通过定义一个方法,然后在每个构造函数中调用该方法来实现,没错,可以解决,但是要在每个构造函数中都调用该方法,而这就是其缺点,若采用构造代码块的方式则不用定义和调用,会直接由编译器写入到每个构造函数中,这才是解决此问题的绝佳方式。
初始化实例环境:一个对象必须在适当的场景下才能存在,如果没有适当的场景,则就需要在创建该对象的时候创建次场景,例如在JEE开发中,要产生HTTP Request必须首先建立HTTP Session,在创建HTTP Request时就可以通过构造代码块来检查HTTP Session是否已经存在,不存在则创建之。
以上两个场景利用了构造代码块的两个特性:在每个构造函数中都运行和在构造函数中它会首先运行。很好的利用构造代码块的这连个特性不仅可以减少代码量,还可以让程序更容易阅读,特别是当所有的构造函数都要实现逻辑,而且这部分逻辑有很复杂时,这时就可以通过编写多个构造代码块来实现。每个代码块完成不同的业务逻辑(当然了构造函数尽量简单,这是基本原则),按照业务顺序一次存放,这样在创建实例对象时JVM就会按照顺序依次执行,实现复杂对象的模块化创建。
上一建议中我们提议使用构造代码块来简化代码,并且也了解到编译器会自动把构造代码块插入到各个构造函数中,那我们接下来看看,编译器是不是足够聪明,能为我们解决真实的开发问题,有这样一个案例,统计一个类的实例变量数。你可要说了,这很简单,在每个构造函数中加入一个对象计数器补救解决了嘛?或者我们使用上一建议介绍的,使用构造代码块也可以,确实如此,我们来看如下代码是否可行:
这段代码可行吗?能计算出实例对象的数量吗?如果编译器把构造代码块插入到各个构造函数中,那带有String形参的构造函数就可能有问题,它会调用无参构造,那通过它生成的Student对象就会执行两次构造代码块:一次是无参构造函数调用构造代码块,一次是执行自身的构造代码块,这样的话计算就不准确了,main函数实际在内存中产生了3个对象,但结果确是4。不过真的是这样吗?我们运行之后,结果是:
实例对象数量:3;
实例对象的数量还是3,程序没有问题,奇怪吗?不奇怪,上一建议是说编译器会把构造代码块插入到每一个构造函数中,但是有一个例外的情况没有说明:如果遇到this关键字(也就是构造函数调用自身的其它构造函数时),则不插入构造代码块,对于我们的例子来说,编译器在编译时发现String形参的构造函数调用了无参构造,于是放弃插入构造代码块,所以只执行了一次构造代码块。
那Java编译器为何如此聪明?这还要从构造代码块的诞生说起,构造代码块是为了提取构造函数的共同量,减少各个构造函数的代码产生的,因此,Java就很聪明的认为把代码插入到this方法的构造函数中即可,而调用其它的构造函数则不插入,确保每个构造函数只执行一次构造代码块。
还有一点需要说明,大家千万不要以为this是特殊情况,那super也会类似处理了,其实不会,在构造块的处理上,super方法没有任何特殊的地方,编译器只把构造代码块插入到super方法之后执行而已。仅此不同。
注意:放心的使用构造代码块吧,Java已经想你所想了。
Java中的嵌套类(Nested Class)分为两种:静态内部类(也叫静态嵌套类,Static Nested Class)和内部类(Inner Class)。本次主要看看静态内部类。什么是静态内部类呢?是内部类,并且是静态(static修饰)的即为静态内部类,只有在是静态内部类的情况下才能把static修饰符放在类前,其它任何时候static都是不能修饰类的。
静态内部类的形式很好理解,但是为什么需要静态内部类呢?那是因为静态内部类有两个优点:加强了类的封装和提高了代码的可读性,我们通过下面代码来解释这两个优点。
其中,Person类中定义了一个静态内部类Home,它表示的意思是"人的家庭信息",由于Home类封装了家庭信息,不用再Person中再定义homeAddr,homeTel等属性,这就使封装性提高了。同时我们仅仅通过代码就可以分析出Person和Home之间的强关联关系,也就是说语义增强了,可读性提高了。所以在使用时就会非常清楚它表达的含义。
定义张三这个人,然后通过Person.Home类设置张三的家庭信息,这是不是就和我们真是世界的情形相同了?先登记人的主要信息,然后登记人员的分类信息。可能你由要问了,这和我们一般定义的类有神么区别呢?又有什么吸引人的地方呢?如下所示:
提高封装性:从代码的位置上来讲,静态内部类放置在外部类内,其代码层意义就是,静态内部类是外部类的子行为或子属性,两者之间保持着一定的关系,比如在我们的例子中,看到Home类就知道它是Person的home信息。
提高代码的可读性:相关联的代码放在一起,可读性肯定提高了。
形似内部,神似外部:静态内部类虽然存在于外部类内,而且编译后的类文件也包含外部类(格式是:外部类+$+内部类),但是它可以脱离外部类存在,也就说我们仍然可以通过new Home()声明一个home对象,只是需要导入"Person.Home"而已。
解释了这么多,大家可能会觉得外部类和静态内部类之间是组合关系(Composition)了,这是错误的,外部类和静态内部类之间有强关联关系,这仅仅表现在"字面上",而深层次的抽象意义则依类的设计.
那静态类内部类和普通内部类有什么区别呢?下面就来说明一下:
静态内部类不持有外部类的引用:在普通内部类中,我们可以直接访问外部类的属性、方法,即使是private类型也可以访问,这是因为内部类持有一个外部类的引用,可以自由访问。而静态内部类,则只可以访问外部类的静态方法和静态属性(如果是private权限也能访问,这是由其代码位置决定的),其它的则不能访问。
静态内部类不依赖外部类:普通内部类与外部类之间是相互依赖关系,内部类实例不能脱离外部类实例,也就是说它们会同生共死,一起声明,一起被垃圾回收,而静态内部类是可以独立存在的,即使外部类消亡了,静态内部类也是可以存在的。
普通内部类不能声明static的方法和变量:普通内部类不能声明static的方法和变量,注意这里说的是变量,常量(也就是final static 修饰的属性)还是可以的,而静态内部类形似外部类,没有任何限制。
阅读如下代码,看上是否可以编译:
注意ArrayList后面的不通点:list1变量后面什么都没有,list2后面有一对{},list3后面有两个嵌套的{},这段程序能否编译呢?若能编译,那输结果是什么呢?
答案是能编译,输出的是3个false。list1很容易理解,就是生命了ArrayList的实例对象,那list2和list3代表的是什么呢?
(1)、list2 = new ArrayList(){}:list2代表的是一个匿名类的声明和赋值,它定义了一个继承于ArrayList的匿名类,只是没有任何覆写的方法而已,其代码类似于:
(2)、list3 = new ArrayList(){{}}:这个语句就有点奇怪了,带了两对{},我们分开解释就明白了,这也是一个匿名类的定义,它的代码类似于:
看到了吧,就是多了一个初始化块而已,起到构造函数的功能,我们知道一个类肯定有一个构造函数,而且构造函数的名称和类名相同,那问题来了:匿名类的构造函数是什么呢?它没有名字呀!很显然,初始化块就是它的构造函数。当然,一个类中的构造函数块可以是多个,也就是说会出现如下代码:
上面的代码是正确无误,没有任何问题的,现在清楚了,匿名类虽然没有名字,但也是可以有构造函数的,它用构造函数块来代替构造函数,那上面的3个输出就很明显了:虽然父类相同,但是类还是不同的。
在上一建议中我们讲到匿名类虽然没有名字,但可以有一个初始化块来充当构造函数,那这个构造函数是否就和普通的构造函数完全不一样呢?我们来看一个例子,设计一个计算器,进行加减运算,代码如下:
代码的意图是,通过构造函数传递两个int类型的数字,然后根据设置的操作符(加法还是减法)进行运算,编写一个客户端调用:
这段匿名类的代码非常清晰:接收两个参数1和2,然后设置一个操作符号,计算其值,结果是3,这毫无疑问,但是这中间隐藏着一个问题:带有参数的匿名类声明时到底调用的是哪一个构造函数呢?我们把这段程序模拟一下:
匿名类和这个Add类等价吗?可能有人会说:上面只是把匿名类增加了一个名字,其它的都没有改动,那肯定是等价了,毫无疑问 ,那好,编写一个客户端调用Add类的方法看看。代码就略了,因为很简单new Add,然后调用父类的getResult方法就可以了,经过测试,输出结果为0(为什么而是0?这很容易,有参构造没有赋值)。这说明两者不等价,不过,原因何在呢?
因为匿名类的构造函数特殊处理机制,一般类(也就是没有显示名字的类)的所有构造函数默认都是调用父类的无参构造函数的,而匿名类因为没有名字,只能由构造代码块代替,也就无所谓有参和无参的构造函数了,它在初始化时直接调用了父类的同参数构造函数,然后再调用了自己的构造代码块,也就是说上面的匿名类和下面的代码是等价的:
它会首先调用父类有两个参数的构造函数,而不是无参构造,这是匿名类的构造函数与普通类的差别,但是这一点也确实鲜有人仔细琢磨,因为它的处理机制符合习惯呀,我传递两个参数,就是希望先调用父类有两个参数的构造,然后再执行我自己的构造函数,而Java的处理机制也正是如此处理的。
在Java中一个类可以多重实现,但不能多重继承,也就是说一个类能够同时实现多个接口,但不 能同时继承多个类。但有时候我们确实需要继承多个类,比如希望拥有多个类的行为功能,就很难使用单继承来解决问题了(当然,使用多继承是可以解决的)。幸 运的是Java中提供的内部类可以曲折的解决此问题,我们来看一个案例,定义一个父亲、母亲接口,描述父亲强壮、母亲温柔的理想情形,代码如下:
其中strong和kind的返回值表示强壮和温柔的指数,指数越高强壮和温柔也就越高,这与游戏中设置人物的属性是一样的,我们继续开看父亲、母亲这两个实现:
父亲的强壮指数为8,母亲的温柔指数也为8,门当户对,那他们生的儿子和女儿一定更优秀了,我们看看儿子类,代码如下:
儿子继承自父亲,变得比父亲更强壮了(覆写父类strong方法),同时儿子也具有母亲的优点,只是 温柔指数降低了。注意看,这里构造了MotherSpecial类继承母亲类,也就是获得了母亲类的行为和方法,这也是内部类的一个重要特性:内部类可以 继承一个与外部类无关的类,保证了内部类的独立性,正是基于这一点,多重继承才会成为可能。MotherSpecial的这种内部类叫做成员内部类(也叫 作实例内部类,Instance Inner Class),我们再来看看女儿类,代码如下:
女儿继承了目前的温柔指数,同时又覆写了父亲的强壮指数,不多解释。注意看覆写的strong方法,这里是创建了一个匿名内部类(Anonymous Inner Class)来覆写父类的方法,以完成继承父亲行为的功能。
多重继承指的是一个类可以同时从多与一个的父亲那里继承行为与特征,按照这个定义,我们的儿子类、女儿类都实现了从父亲和母亲那里继承所有的功能,应该属于多重继承,这完全归功于内部类,大家在需要用到多重继承的时候,可以思考一下内部类。
在现实生活中,也确实存在多重继承的问题,上面的例子说后人继承了父亲也继承了母亲的行为和特征,再比如我国的特产动物"四不像"(学名麋鹿),其外 形" 似鹿非鹿,似马非马,似牛非牛,似驴非驴 ",这你想要用单继承实现就比较麻烦了,如果用多继承则可以很好地解决此问题:定义鹿、马、牛、驴 四个类,然后建立麋鹿类的多个内部类,继承他们即可。
Java项目中使用的工具类非常多,比如JDK自己的工具类 java.lang.Math、java.util.Collections等都是我们经常用到的。工具类的方法和属性都是静态的,不需要生成实例即可访 问,而且JDK也做了很好的处理,由于不希望被初始化,于是就设置了构造函数private的访问权限,表示出了类本身之外,谁都不能产生一个实例,我们 来看一下java.lang.Math代码:
之所以要将"Don't let anyone instantiate this class." 留下来,是因为Math的构造函数设置为了private:我就是一个工具类,我只想要其它类通过类名来访问,我不想你通过实例对象来访问。这在平台型或 框架项目中已经足够了。但是如果已经告诉你不要这么做了,你还要生成一个Math对象实例来访问静态方法和属性(Java的反射是如此的发达,修改个构造 函数的访问权限易如反掌),那我就不保证正确性了,隐藏问题随时都有可能爆发!那我们在项目中有没有更好地限制办法呢?有,即不仅仅设置成private 权限,还抛出异常,代码如下:
如此,才能保证一个工具类不会实例化,并且保证了所有的访问都是通过类名来进行的。需要注意的一点是,此工具类最好不要做集成的打算,因为如果子类可以实例化的话,就要调用父类的构造函数,可是父类没有可以被访问的构造函数,于是问题就会出现。
注意:如果一个类不允许实例化,就要保证"平常" 渠道都不能实例它。
我们知道一个类实现了Cloneable接口就表示它具备了被拷贝的能力。如果在覆写clone()方法就会完全具备拷贝能力。拷贝是在内存中运行的, 所以在性能方面比直接通过new生成的对象要快很多,特别是在大对象的生成上,这会使得性能的提升非常显著。但是对象拷贝也有一个比较容易忽略的问题:浅 拷贝(Shadow Clone,也叫作影子拷贝)存在对象属性拷贝不彻底的问题。我们来看这样一段代码:
程序中我们描述了这样一个场景:一个父亲,有两个儿子,大小儿子同根同种,所以小儿子的对象就通过拷贝大儿子的对象来生成,运行输出结果如下:
大儿子 的父亲是 父亲
小儿子 的父亲是 父亲
这很正确,没有问题。突然有一天,父亲心血来潮想让大儿子去认个干爹,也就是大儿子的父亲名称需要重新设置一下,代码如下:
大儿子重新设置了父亲名称,我们期望的输出结果是:将大儿子的父亲名称修改为干爹,小儿子的父亲名称保持不变。运行一下结果如下:
大儿子 的父亲是 干爹
小儿子 的父亲是 干爹
怎 么回事,小儿子的父亲也成了"干爹"?两个儿子都木有了,这老子估计被要被气死了!出现这个问题的原因就在于clone方法,我们知道所有类都继承自 Object,Object提供了一个对象拷贝的默认方法,即页面代码中 的super.clone()方法,但是该方法是有缺陷的,他提供的是一种浅拷贝,也就是说它并不会把对象的所有属性全部拷贝一份,而是有选择的拷贝,它 的拷贝规则如下:
基本类型:如果变量是基本类型,则拷贝其值。比如int、float等
对 象:如果变量是一个实例对象,则拷贝其地址引用,也就是说此时拷贝出的对象与原有对象共享该实例变量,不受访问权限的控制,这在Java中是很疯狂的,因 为它突破了访问权限的定义:一个private修饰的变量,竟然可以被两个不同的实例对象访问,这让java的访问权限体系情何以堪。
String字符串:这个比较特殊,拷贝的也是一个地址,是个引用,但是在修改时,它会从字符串池(String pool)中重新生成新的字符串,原有的字符串对象保持不变,在此处我们可以认为String是一个基本类型。
明白了这三个原则,上面的例子就很清晰了。小儿子的对象是通过大儿子拷贝而来的,其父亲是同一个人,也就是同一个对象,大儿子修改了父亲的名称后,小儿子也很跟着修改了——于是,父亲的两个儿子都没了。其实要更正也很简单,clone方法的代码如下:
然后再运行,小儿子的父亲就不会是干爹了,如此就实现了对象的深拷贝(Deep Clone),保证拷贝出来的对象自成一体,不受"母体"影响,和new生成的对象没有什么区别。
注意:浅拷贝只是Java提供的一种简单拷贝机制,不便于直接使用。
上一建议说了对象的浅拷贝问题,试下Cloneable接口就具备了拷贝能力,那我们开思考这样一个问题:如果一个项目中有大量的对象是通过拷贝生成 的,那我们该如何处理呢?每个类都系而一个clone方法,并且还有深拷贝?想想这是何等巨大的工作量呀!是否有更好的方法呢?
其实,可以通过序列化方式来处理,在内存中通过字节流的拷贝来实现,也就是把母对象写到一个字节流中,再从字节流中将其读出来,这样就可以重建一个对象了,该新对象与母对象之间不存在引用共享的问题,也就相当于深拷贝了一个对象,代码如下:
此工具类要求被拷贝的对象实现了Serializable 接口,否则是没办法拷贝的(当然,使用反射是另一种技巧),上一建议中的例子只是稍微修改一下即可实现深拷贝,代码如下
被拷贝的类只要实现Serializable这个标志性接口即可,不需要任何实现,当然serialVersionUID常量还是要加上去的,然后我们就可以通过CloneUtils工具进行对象的深拷贝了,用词方法进行对象拷贝时需要注意两点:
对象的内部属性都是可序列化的:如果有内部属性不可序列化,则会抛出序列化异常,这会让调试者很纳闷,生成一个对象怎么回出现序列化异常呢?从这一点考虑,也需要把CloneUtils工具的异常进行细化处理。
注 意方法和属性的特殊修饰符:比如final,static变量的序列化问题会被引入对象的拷贝中,这点需要特别注意,同时 transient变量(瞬态变量,不进行序列化的变量)也会影响到拷贝的效果。当然,采用序列化拷贝时还有一个更简单的方法,即使用Apache下的 commons工具包中SerializationUtils类,直接使用更加简洁.
我们在写一个JavaBean时,经常会覆写equals方 法,其目的是根据业务规则判断两个对象是否相等,比如我们写一个Person类,然后根据姓名判断两个实例对象是否相同时,这在DAO(Data Access Objects)层是经常用到的。具体操作时先从数据库中获得两个DTO(Data Transfer Object,数据传输对象),然后判断他们是否相等的,代码如下:
覆写的equals方法做了多个校验,考虑到Web上传递过来的对象有可能输入了前后空格,所以用trim方法剪切了一下,看看代码有没有问题,我们写一个main:
上面的代码产生了两个Person对象(注意p2变量中的那个张三后面有一个空格),然后放到list中,最后判断list是否包含了这两个对象。看上去没有问题,应该打印出两个true才对,但是结果却是:
列表中是否包含张三:true
列表中是否包含张三:false
刚刚放到list中的对象竟然说没有,这太让人失望了,原因何在呢?list类检查是否包含元素时时通过调用对象的equals方法来判断的,也就是说 contains(p2)传递进去,会依次执行p2.equals(p1),p2.equals(p2),只有一个返回true,结果都是true,可惜 的是比较结果都是false,那问题出来了:难道
p2.equals(p2)因为false不成?
还真说对了,p2.equals(p2)确实是false,看看我们的equals方法,它把第二个参数进行了剪切!也就是说比较的如下等式:
注意前面的那个张三,是有空格的,那结果肯定是false了,错误也就此产生了,这是一个想做好事却办成了 "坏事" 的典型案例,它违背了equlas方法的自反性原则:对于任何非空引用x,x.equals(x)应该返回true,问题直到了,解决非常简单,只要把trim()去掉即可。注意解决的只是当前问题,该equals方法还存在其它问题。
继续45建议的问题,我们解决了覆写equals的自反性问题,是不是就完美了呢?在把main方法重构一下:
很小的改动,大家肯定晓得了运行结果是包"空指针"异常。原因也很简单:null.equalsIgnoreCase方法自然报错,此处就是为了说明覆写equals方法遵循的一个原则---
对称性原则:对于任何引用x和y的情形,如果x.equals(y),把么y.equals(x)也应该返回true。
看到这样的标题,大家是否感到郁闷呢?接口中有实现代码吗?这怎么可能呢?确实,接口中可以声明常量,声明抽象方法,可以继承父接口,但就是不能有具体实现,因为接口是一种契约(Contract),是一种框架性协议,这表明它的实现类都是同一种类型,或者具备相似特征的一个集合体。对于一般程序,接口确实没有任何实现,但是在那些特殊的程序中就例外了,阅读如下代码:
仔细看main方法,注意那个B接口。它调用了接口常量,在没有实现任何显示实现类的情况下,它竟然打印出了结果,那B接口中的s常量(接口是S)是在什么地方被实现的呢?答案在B接口中。
在B接口中声明了一个静态常量s,其值是一个匿名内部类(Anonymous Inner Class)的实例对象,就是该匿名内部类(当然,也可以不用匿名,直接在接口中是实现内部类也是允许的)实现了S接口。你看,在接口中也存在着实现代码吧!
这确实很好,很强大,但是在一般的项目中,此类代码是严禁出现的,原因很简单:这是一种非常不好的编码习惯,接口是用来干什么的?接口是一个契约,不仅仅约束着实现,同时也是一个保证,保证提供的服务(常量和方法)是稳定的、可靠的,如果把实现代码写到接口中,那接口就绑定了可能变化的因素,这会导致实现不再稳定和可靠,是随时都可能被抛弃、被更改、被重构的。所以,接口中虽然可以有实现,但应避免使用。
注意:接口中不能出现实现代码。
这个标题是否像上一个建议的标题一样让人郁闷呢?什么叫做变量一定要先声明后赋值?Java中的变量不都是先声明后使用的吗?难道还能先使用后声明?能不能暂且不说,我们看一个例子,代码如下:
这段程序很简单,输出100嘛,对,确实是100,我们稍稍修改一下,代码如下:
注意变量 i 的声明和赋值调换了位置,现在的问题是:这段程序能否编译?如过可以编译,输出是多少?还要注意,这个变量i可是先使用(也就是赋值)后声明的。
答案是:可以编译,没有任何问题,输出结果为1。对,输出是 1 不是100.仅仅调换了位置,输出就变了,而且变量 i 还是先使用后声明的,难道颠倒了?
这要从静态变量的诞生说起,静态变量是类加载时被分配到数据区(Data Area)的,它在内存中只有一个拷贝,不会被分配多次,其后的所有赋值操作都是值改变,地址则保持不变。我们知道JVM初始化变量是先声明空间,然后再赋值,也就是说:在JVM中是分开执行的,等价于:
int i ; //分配空间
i = 100; //赋值
静态变量是在类初始化的时候首先被加载的,JVM会去查找类中所有的静态声明,然后分配空间,注意这时候只是完成了地址空间的分配,还没有赋值,之后JVM会根据类中静态赋值(包括静态类赋值和静态块赋值)的先后顺序来执行。对于程序来说,就是先声明了int类型的地址空间,并把地址传递给了i,然后按照类的先后顺序执行赋值操作,首先执行静态块中i = 100,接着执行 i = 1,那最后的结果就是 i =1了。
哦,如此而已,如果有多个静态块对 i 继续赋值呢?i 当然还是等于1了,谁的位置最靠后谁有最终的决定权。
有些程序员喜欢把变量定义放到类最底部,如果这是实例变量还好说,没有任何问题,但如果是静态变量,而且还在静态块中赋值了,那这结果就和期望的不一样了,所以遵循Java通用的开发规范"变量先声明后赋值使用",是一个良好的编码风格。
注意:再次重申变量要先声明后使用,这不是一句废话。
我们知到在Java中可以通过覆写(Override)来增强或减弱父类的方法和行为,但覆写是针对非静态方法(也叫做实例方法,只有生成实例才能调用的方法)的,不能针对静态方法(static修饰的方法,也叫做类方法),为什么呢?我们看一个例子,代码如下:
注意看程序,子类的doAnything方法覆写了父类方法,真没有问题,那么doSomething方法呢?它与父类的方法名相同,输入、输出也相同,按道理来说应该是覆写,不过到底是不是覆写呢?我们看看输出结果: 我是子类非静态方法 我是父类静态方法
这个结果很让人困惑,同样是调用子类方法,一个执行了父类方法,两者的差别仅仅是有无static修饰,却得到不同的结果,原因何在呢?
我们知道一个实例对象有两个类型:表面类型(Apparent Type)和实际类型(Actual Type),表面类型是声明的类型,实际类型是对象产生时的类型,比如我们例子,变量base的表面类型是Base,实际类型是Sub。对于非静态方法,它是根据对象的实际类型来执行的,也就是执行了Sub类中的doAnything方法。而对于静态方法来说就比较特殊了,首先静态方法不依赖实例对象,它是通过类名来访问的;其次,可以通过对象访问静态方法,如果是通过对象访问静态方法,JVM则会通过对象的表面类型查找静态方法的入口,继而执行之。因此上面的程序打印出"我是父类非静态方法",也就不足为奇了。
在子类中构建与父类方法相同的方法名、输入参数、输出参数、访问权限(权限可以扩大),并且父类,子类都是静态方法,此种行为叫做隐藏(Hide),它与覆写有两点不同:
(1)、表现形式不同:隐藏用于静态方法,覆写用于非静态方法,在代码上的表现是@Override注解可用于覆写,不可用于隐藏。
(2)、职责不同:隐藏的目的是为了抛弃父类的静态方法,重现子类方法,例如我们的例子,Sub.doSomething的出现是为了遮盖父类的Base.doSomething方法,也就是i期望父类的静态方法不要做破坏子类的业务行为,而覆写是将父类的的行为增强或减弱,延续父类的职责。
解释了这么多,我们回头看看本建议的标题,静态方法不能覆写,可以再续上一句话,虽然不能覆写,但可以隐藏。顺便说一下,通过实例对象访问静态方法或静态属性不是好习惯,它给代码带来了"坏味道",建议大家阅之戒之。
我们知道通过new关键字生成的对象必然会调用构造函数,构造函数的简繁情况会直接影响实例对象的创建是否繁琐,在项目开发中,我们一般都会制定构造函数尽量简单,尽可能不抛异常,尽量不做复杂运算等规范,那如果一个构造函数确实复杂了会怎么样?我们开看一段代码:
该代码是一个服务类的简单模拟程序,Server类实现了服务器的创建逻辑,子类要在生成实例对象时传递一个端口号即可创建一个监听端口的服务,该代码的意图如下:
通过SimpleServer的构造函数接收端口参数;
子类的构造函数默认调用父类的构造函数;
父类构造函数调用子类的getPort方法获得端口号;
父类的构造函数建立端口监听机制;
对象创建完毕,服务监听启动,正常运行。
貌似很合理,再仔细看看代码,确实与我们的意图相吻合,那我们尝试多次运行看看,输出结果要么是"端口号:40000",要么是"端口号:0",永远不会出现"端口号:100"或是"端口号:1000",这就奇怪了,40000还好说,那个0是怎么冒出来的呢?怠慢什么地方出现了问题呢?
要解释这个问题,我们首先要说说子类是如何实例化的。子类实例化时,会首先初始化父类(注意这里是初始化,不是生成父类对象),也就是初始化父类的变量,调用父类的构造函数,然后才会初始化子类的变量,调用子类的构造函数,最后生成一个实例对象。了解了相关知识,我们再来看看上面的程序,其执行过程如下:
子类SimpleServer的构造函数接收int类型的参数1000;
父类初始化常量,也就是DEFAULT_PORT初始化,并设置值为40000;
执行父类无参构造函数,也就是子类有参构造函数默认包含了super()方法;
父类无参构造函数执行到“int port = getPort() ”方法,调用子类的getPort方法实现;
子类的getPort方法返回port值(注意,此时port变量还没有赋值,是0)或DEFAULT_PORT(此时已经是40000)了;
父类初始化完毕,开始初始化子类的实例变量,port值赋值100;
执行子类构造函数,port值被重新赋值为1000;
子类SimpleServer实例化结束,对象创建完毕。
终于清楚了,在类初始化时getPort方法返回值还没有赋值,port只是获得了默认初始值(int类型的实例变量默认初始值是0),因此Server永远监听的是40000端口(0端口是没有意义的)。这个问题的产生从浅处说是类元素初始顺序导致的,从深处说是因为构造函数太复杂引起的。构造函数用作初始化变量,声明实例的上下文,这都是简单实现的,没有任何问题,但我们的例子却实现了一个复杂的逻辑,而这放在构造函数里就不合适了。
问题知道了,修改也很简单,把父类的无参构造函数中的所有实现都移动到一个叫做start的方法中,将SimpleServer类初始化完毕,再调用其start方法即可实现服务器的启动工作,简洁而又直观,这也是大部分JEE服务器的实现方式。
注意:构造函数简化,再简化,应该达到"一眼洞穿"的境界。
构造函数是一个类初始化必须执行的代码,它决定着类初始化的效率,如果构造函数比较复杂,而且还关联了其它类,则可能产生想不到的问题,我们来看如下代码:
这段代码并不复杂,只是在构造函数中初始化了其它类,想想看这段代码的运行结果是什么?会打印出"Hi ,show me Something!"吗?
答案是这段代码不能运行,报StatckOverflowError异常,栈(Stack)内存溢出,这是因为声明变量son时,调用了Son的无参构造函数,JVM又默认调用了父类的构造函数,接着Father又初始化了Other类,而Other类又调用了Son类,于是一个死循环就诞生了,知道内存被消耗完停止。
大家可能觉得这样的场景不会出现在开发中,我们来思考这样的场景,Father是由框架提供的,Son类是我们自己编写的扩展代码,而Other类则是框架要求的拦截类(Interceptor类或者Handle类或者Hook方法),再来看看问题,这种场景不可能出现吗?
可能大家会觉得这样的场景不会出现,这种问题只要系统一运行就会发现,不可能对项目产生影响。
那是因为我们这里展示的代码比较简单,很容易一眼洞穿,一个项目中的构造函数可不止一两个,类之间的关系也不会这么简单,要想瞥一眼就能明白是否有缺陷这对所有人员来说都是不可能完成的任务,解决此类问题最好的办法就是:不要在构造函数中声明初始化其他类,养成良好习惯。
什么叫做代码块(Code Block)?用大括号把多行代码封装在一起,形成一个独立的数据体,实现特定算法的代码集合即为代码块,一般来说代码快不能单独运行的,必须要有运行主体。在Java中一共有四种类型的代码块:
普通代码块:就是在方法后面使用"{}"括起来的代码片段,它不能单独运行,必须通过方法名调用执行;
静态代码块:在类中使用static修饰,并用"{}"括起来的代码片段,用于静态变量初始化或对象创建前的环境初始化。
同步代码块:使用synchronized关键字修饰,并使用"{}"括起来的代码片段,它表示同一时间只能有一个线程进入到该方法块中,是一种多线程保护机制。
构造代码块:在类中没有任何前缀和后缀,并使用"{}"括起来的代码片段;
我么知道一个类中至少有一个构造函数(如果没有,编译器会无私的为其创建一个无参构造函数),构造函数是在对象生成时调用的,那现在为你来了:构造函数和代码块是什么关系,构造代码块是在什么时候执行的?在回答这个问题之前,我们先看看编译器是如何处理构造代码块的,看如下代码:
这是一段非常简单的代码,它包含了构造代码块、无参构造、有参构造,我们知道代码块不具有独立执行能力,那么编译器是如何处理构造代码块的呢?很简单,编译器会把构造代码块插入到每个构造函数的最前端,上面的代码等价于:
每个构造函数的最前端都被插入了构造代码块,很显然,在通过new关键字生成一个实例时会先执行构造代码块,然后再执行其他代码,也就是说:构造代码块会在每个构造函数内首先执行(需要注意的是:构造代码块不是在构造函数之前运行的,它依托于构造函数的执行),明白了这一点,我们就可以把构造代码块应用到如下场景中:
初始化实例变量(Instance Variable):如果每个构造函数都要初始化变量,可以通过构造代码块来实现。当然也可以通过定义一个方法,然后在每个构造函数中调用该方法来实现,没错,可以解决,但是要在每个构造函数中都调用该方法,而这就是其缺点,若采用构造代码块的方式则不用定义和调用,会直接由编译器写入到每个构造函数中,这才是解决此问题的绝佳方式。
初始化实例环境:一个对象必须在适当的场景下才能存在,如果没有适当的场景,则就需要在创建该对象的时候创建次场景,例如在JEE开发中,要产生HTTP Request必须首先建立HTTP Session,在创建HTTP Request时就可以通过构造代码块来检查HTTP Session是否已经存在,不存在则创建之。
以上两个场景利用了构造代码块的两个特性:在每个构造函数中都运行和在构造函数中它会首先运行。很好的利用构造代码块的这连个特性不仅可以减少代码量,还可以让程序更容易阅读,特别是当所有的构造函数都要实现逻辑,而且这部分逻辑有很复杂时,这时就可以通过编写多个构造代码块来实现。每个代码块完成不同的业务逻辑(当然了构造函数尽量简单,这是基本原则),按照业务顺序一次存放,这样在创建实例对象时JVM就会按照顺序依次执行,实现复杂对象的模块化创建。
上一建议中我们提议使用构造代码块来简化代码,并且也了解到编译器会自动把构造代码块插入到各个构造函数中,那我们接下来看看,编译器是不是足够聪明,能为我们解决真实的开发问题,有这样一个案例,统计一个类的实例变量数。你可要说了,这很简单,在每个构造函数中加入一个对象计数器补救解决了嘛?或者我们使用上一建议介绍的,使用构造代码块也可以,确实如此,我们来看如下代码是否可行:
这段代码可行吗?能计算出实例对象的数量吗?如果编译器把构造代码块插入到各个构造函数中,那带有String形参的构造函数就可能有问题,它会调用无参构造,那通过它生成的Student对象就会执行两次构造代码块:一次是无参构造函数调用构造代码块,一次是执行自身的构造代码块,这样的话计算就不准确了,main函数实际在内存中产生了3个对象,但结果确是4。不过真的是这样吗?我们运行之后,结果是:
实例对象数量:3;
实例对象的数量还是3,程序没有问题,奇怪吗?不奇怪,上一建议是说编译器会把构造代码块插入到每一个构造函数中,但是有一个例外的情况没有说明:如果遇到this关键字(也就是构造函数调用自身的其它构造函数时),则不插入构造代码块,对于我们的例子来说,编译器在编译时发现String形参的构造函数调用了无参构造,于是放弃插入构造代码块,所以只执行了一次构造代码块。
那Java编译器为何如此聪明?这还要从构造代码块的诞生说起,构造代码块是为了提取构造函数的共同量,减少各个构造函数的代码产生的,因此,Java就很聪明的认为把代码插入到this方法的构造函数中即可,而调用其它的构造函数则不插入,确保每个构造函数只执行一次构造代码块。
还有一点需要说明,大家千万不要以为this是特殊情况,那super也会类似处理了,其实不会,在构造块的处理上,super方法没有任何特殊的地方,编译器只把构造代码块插入到super方法之后执行而已。仅此不同。
注意:放心的使用构造代码块吧,Java已经想你所想了。
Java中的嵌套类(Nested Class)分为两种:静态内部类(也叫静态嵌套类,Static Nested Class)和内部类(Inner Class)。本次主要看看静态内部类。什么是静态内部类呢?是内部类,并且是静态(static修饰)的即为静态内部类,只有在是静态内部类的情况下才能把static修饰符放在类前,其它任何时候static都是不能修饰类的。
静态内部类的形式很好理解,但是为什么需要静态内部类呢?那是因为静态内部类有两个优点:加强了类的封装和提高了代码的可读性,我们通过下面代码来解释这两个优点。
其中,Person类中定义了一个静态内部类Home,它表示的意思是"人的家庭信息",由于Home类封装了家庭信息,不用再Person中再定义homeAddr,homeTel等属性,这就使封装性提高了。同时我们仅仅通过代码就可以分析出Person和Home之间的强关联关系,也就是说语义增强了,可读性提高了。所以在使用时就会非常清楚它表达的含义。
定义张三这个人,然后通过Person.Home类设置张三的家庭信息,这是不是就和我们真是世界的情形相同了?先登记人的主要信息,然后登记人员的分类信息。可能你由要问了,这和我们一般定义的类有神么区别呢?又有什么吸引人的地方呢?如下所示:
提高封装性:从代码的位置上来讲,静态内部类放置在外部类内,其代码层意义就是,静态内部类是外部类的子行为或子属性,两者之间保持着一定的关系,比如在我们的例子中,看到Home类就知道它是Person的home信息。
提高代码的可读性:相关联的代码放在一起,可读性肯定提高了。
形似内部,神似外部:静态内部类虽然存在于外部类内,而且编译后的类文件也包含外部类(格式是:外部类+$+内部类),但是它可以脱离外部类存在,也就说我们仍然可以通过new Home()声明一个home对象,只是需要导入"Person.Home"而已。
解释了这么多,大家可能会觉得外部类和静态内部类之间是组合关系(Composition)了,这是错误的,外部类和静态内部类之间有强关联关系,这仅仅表现在"字面上",而深层次的抽象意义则依类的设计.
那静态类内部类和普通内部类有什么区别呢?下面就来说明一下:
静态内部类不持有外部类的引用:在普通内部类中,我们可以直接访问外部类的属性、方法,即使是private类型也可以访问,这是因为内部类持有一个外部类的引用,可以自由访问。而静态内部类,则只可以访问外部类的静态方法和静态属性(如果是private权限也能访问,这是由其代码位置决定的),其它的则不能访问。
静态内部类不依赖外部类:普通内部类与外部类之间是相互依赖关系,内部类实例不能脱离外部类实例,也就是说它们会同生共死,一起声明,一起被垃圾回收,而静态内部类是可以独立存在的,即使外部类消亡了,静态内部类也是可以存在的。
普通内部类不能声明static的方法和变量:普通内部类不能声明static的方法和变量,注意这里说的是变量,常量(也就是final static 修饰的属性)还是可以的,而静态内部类形似外部类,没有任何限制。
阅读如下代码,看上是否可以编译:
注意ArrayList后面的不通点:list1变量后面什么都没有,list2后面有一对{},list3后面有两个嵌套的{},这段程序能否编译呢?若能编译,那输结果是什么呢?
答案是能编译,输出的是3个false。list1很容易理解,就是生命了ArrayList的实例对象,那list2和list3代表的是什么呢?
(1)、list2 = new ArrayList(){}:list2代表的是一个匿名类的声明和赋值,它定义了一个继承于ArrayList的匿名类,只是没有任何覆写的方法而已,其代码类似于:
(2)、list3 = new ArrayList(){{}}:这个语句就有点奇怪了,带了两对{},我们分开解释就明白了,这也是一个匿名类的定义,它的代码类似于:
看到了吧,就是多了一个初始化块而已,起到构造函数的功能,我们知道一个类肯定有一个构造函数,而且构造函数的名称和类名相同,那问题来了:匿名类的构造函数是什么呢?它没有名字呀!很显然,初始化块就是它的构造函数。当然,一个类中的构造函数块可以是多个,也就是说会出现如下代码:
上面的代码是正确无误,没有任何问题的,现在清楚了,匿名类虽然没有名字,但也是可以有构造函数的,它用构造函数块来代替构造函数,那上面的3个输出就很明显了:虽然父类相同,但是类还是不同的。
在上一建议中我们讲到匿名类虽然没有名字,但可以有一个初始化块来充当构造函数,那这个构造函数是否就和普通的构造函数完全不一样呢?我们来看一个例子,设计一个计算器,进行加减运算,代码如下:
代码的意图是,通过构造函数传递两个int类型的数字,然后根据设置的操作符(加法还是减法)进行运算,编写一个客户端调用:
这段匿名类的代码非常清晰:接收两个参数1和2,然后设置一个操作符号,计算其值,结果是3,这毫无疑问,但是这中间隐藏着一个问题:带有参数的匿名类声明时到底调用的是哪一个构造函数呢?我们把这段程序模拟一下:
匿名类和这个Add类等价吗?可能有人会说:上面只是把匿名类增加了一个名字,其它的都没有改动,那肯定是等价了,毫无疑问 ,那好,编写一个客户端调用Add类的方法看看。代码就略了,因为很简单new Add,然后调用父类的getResult方法就可以了,经过测试,输出结果为0(为什么而是0?这很容易,有参构造没有赋值)。这说明两者不等价,不过,原因何在呢?
因为匿名类的构造函数特殊处理机制,一般类(也就是没有显示名字的类)的所有构造函数默认都是调用父类的无参构造函数的,而匿名类因为没有名字,只能由构造代码块代替,也就无所谓有参和无参的构造函数了,它在初始化时直接调用了父类的同参数构造函数,然后再调用了自己的构造代码块,也就是说上面的匿名类和下面的代码是等价的:
它会首先调用父类有两个参数的构造函数,而不是无参构造,这是匿名类的构造函数与普通类的差别,但是这一点也确实鲜有人仔细琢磨,因为它的处理机制符合习惯呀,我传递两个参数,就是希望先调用父类有两个参数的构造,然后再执行我自己的构造函数,而Java的处理机制也正是如此处理的。
在Java中一个类可以多重实现,但不能多重继承,也就是说一个类能够同时实现多个接口,但不 能同时继承多个类。但有时候我们确实需要继承多个类,比如希望拥有多个类的行为功能,就很难使用单继承来解决问题了(当然,使用多继承是可以解决的)。幸 运的是Java中提供的内部类可以曲折的解决此问题,我们来看一个案例,定义一个父亲、母亲接口,描述父亲强壮、母亲温柔的理想情形,代码如下:
其中strong和kind的返回值表示强壮和温柔的指数,指数越高强壮和温柔也就越高,这与游戏中设置人物的属性是一样的,我们继续开看父亲、母亲这两个实现:
父亲的强壮指数为8,母亲的温柔指数也为8,门当户对,那他们生的儿子和女儿一定更优秀了,我们看看儿子类,代码如下:
儿子继承自父亲,变得比父亲更强壮了(覆写父类strong方法),同时儿子也具有母亲的优点,只是 温柔指数降低了。注意看,这里构造了MotherSpecial类继承母亲类,也就是获得了母亲类的行为和方法,这也是内部类的一个重要特性:内部类可以 继承一个与外部类无关的类,保证了内部类的独立性,正是基于这一点,多重继承才会成为可能。MotherSpecial的这种内部类叫做成员内部类(也叫 作实例内部类,Instance Inner Class),我们再来看看女儿类,代码如下:
女儿继承了目前的温柔指数,同时又覆写了父亲的强壮指数,不多解释。注意看覆写的strong方法,这里是创建了一个匿名内部类(Anonymous Inner Class)来覆写父类的方法,以完成继承父亲行为的功能。
多重继承指的是一个类可以同时从多与一个的父亲那里继承行为与特征,按照这个定义,我们的儿子类、女儿类都实现了从父亲和母亲那里继承所有的功能,应该属于多重继承,这完全归功于内部类,大家在需要用到多重继承的时候,可以思考一下内部类。
在现实生活中,也确实存在多重继承的问题,上面的例子说后人继承了父亲也继承了母亲的行为和特征,再比如我国的特产动物"四不像"(学名麋鹿),其外 形" 似鹿非鹿,似马非马,似牛非牛,似驴非驴 ",这你想要用单继承实现就比较麻烦了,如果用多继承则可以很好地解决此问题:定义鹿、马、牛、驴 四个类,然后建立麋鹿类的多个内部类,继承他们即可。
Java项目中使用的工具类非常多,比如JDK自己的工具类 java.lang.Math、java.util.Collections等都是我们经常用到的。工具类的方法和属性都是静态的,不需要生成实例即可访 问,而且JDK也做了很好的处理,由于不希望被初始化,于是就设置了构造函数private的访问权限,表示出了类本身之外,谁都不能产生一个实例,我们 来看一下java.lang.Math代码:
之所以要将"Don't let anyone instantiate this class." 留下来,是因为Math的构造函数设置为了private:我就是一个工具类,我只想要其它类通过类名来访问,我不想你通过实例对象来访问。这在平台型或 框架项目中已经足够了。但是如果已经告诉你不要这么做了,你还要生成一个Math对象实例来访问静态方法和属性(Java的反射是如此的发达,修改个构造 函数的访问权限易如反掌),那我就不保证正确性了,隐藏问题随时都有可能爆发!那我们在项目中有没有更好地限制办法呢?有,即不仅仅设置成private 权限,还抛出异常,代码如下:
如此,才能保证一个工具类不会实例化,并且保证了所有的访问都是通过类名来进行的。需要注意的一点是,此工具类最好不要做集成的打算,因为如果子类可以实例化的话,就要调用父类的构造函数,可是父类没有可以被访问的构造函数,于是问题就会出现。
注意:如果一个类不允许实例化,就要保证"平常" 渠道都不能实例它。
我们知道一个类实现了Cloneable接口就表示它具备了被拷贝的能力。如果在覆写clone()方法就会完全具备拷贝能力。拷贝是在内存中运行的, 所以在性能方面比直接通过new生成的对象要快很多,特别是在大对象的生成上,这会使得性能的提升非常显著。但是对象拷贝也有一个比较容易忽略的问题:浅 拷贝(Shadow Clone,也叫作影子拷贝)存在对象属性拷贝不彻底的问题。我们来看这样一段代码:
程序中我们描述了这样一个场景:一个父亲,有两个儿子,大小儿子同根同种,所以小儿子的对象就通过拷贝大儿子的对象来生成,运行输出结果如下:
大儿子 的父亲是 父亲
小儿子 的父亲是 父亲
这很正确,没有问题。突然有一天,父亲心血来潮想让大儿子去认个干爹,也就是大儿子的父亲名称需要重新设置一下,代码如下:
大儿子重新设置了父亲名称,我们期望的输出结果是:将大儿子的父亲名称修改为干爹,小儿子的父亲名称保持不变。运行一下结果如下:
大儿子 的父亲是 干爹
小儿子 的父亲是 干爹
怎 么回事,小儿子的父亲也成了"干爹"?两个儿子都木有了,这老子估计被要被气死了!出现这个问题的原因就在于clone方法,我们知道所有类都继承自 Object,Object提供了一个对象拷贝的默认方法,即页面代码中 的super.clone()方法,但是该方法是有缺陷的,他提供的是一种浅拷贝,也就是说它并不会把对象的所有属性全部拷贝一份,而是有选择的拷贝,它 的拷贝规则如下:
基本类型:如果变量是基本类型,则拷贝其值。比如int、float等
对 象:如果变量是一个实例对象,则拷贝其地址引用,也就是说此时拷贝出的对象与原有对象共享该实例变量,不受访问权限的控制,这在Java中是很疯狂的,因 为它突破了访问权限的定义:一个private修饰的变量,竟然可以被两个不同的实例对象访问,这让java的访问权限体系情何以堪。
String字符串:这个比较特殊,拷贝的也是一个地址,是个引用,但是在修改时,它会从字符串池(String pool)中重新生成新的字符串,原有的字符串对象保持不变,在此处我们可以认为String是一个基本类型。
明白了这三个原则,上面的例子就很清晰了。小儿子的对象是通过大儿子拷贝而来的,其父亲是同一个人,也就是同一个对象,大儿子修改了父亲的名称后,小儿子也很跟着修改了——于是,父亲的两个儿子都没了。其实要更正也很简单,clone方法的代码如下:
然后再运行,小儿子的父亲就不会是干爹了,如此就实现了对象的深拷贝(Deep Clone),保证拷贝出来的对象自成一体,不受"母体"影响,和new生成的对象没有什么区别。
注意:浅拷贝只是Java提供的一种简单拷贝机制,不便于直接使用。
上一建议说了对象的浅拷贝问题,试下Cloneable接口就具备了拷贝能力,那我们开思考这样一个问题:如果一个项目中有大量的对象是通过拷贝生成 的,那我们该如何处理呢?每个类都系而一个clone方法,并且还有深拷贝?想想这是何等巨大的工作量呀!是否有更好的方法呢?
其实,可以通过序列化方式来处理,在内存中通过字节流的拷贝来实现,也就是把母对象写到一个字节流中,再从字节流中将其读出来,这样就可以重建一个对象了,该新对象与母对象之间不存在引用共享的问题,也就相当于深拷贝了一个对象,代码如下:
此工具类要求被拷贝的对象实现了Serializable 接口,否则是没办法拷贝的(当然,使用反射是另一种技巧),上一建议中的例子只是稍微修改一下即可实现深拷贝,代码如下
被拷贝的类只要实现Serializable这个标志性接口即可,不需要任何实现,当然serialVersionUID常量还是要加上去的,然后我们就可以通过CloneUtils工具进行对象的深拷贝了,用词方法进行对象拷贝时需要注意两点:
对象的内部属性都是可序列化的:如果有内部属性不可序列化,则会抛出序列化异常,这会让调试者很纳闷,生成一个对象怎么回出现序列化异常呢?从这一点考虑,也需要把CloneUtils工具的异常进行细化处理。
注 意方法和属性的特殊修饰符:比如final,static变量的序列化问题会被引入对象的拷贝中,这点需要特别注意,同时 transient变量(瞬态变量,不进行序列化的变量)也会影响到拷贝的效果。当然,采用序列化拷贝时还有一个更简单的方法,即使用Apache下的 commons工具包中SerializationUtils类,直接使用更加简洁.
我们在写一个JavaBean时,经常会覆写equals方 法,其目的是根据业务规则判断两个对象是否相等,比如我们写一个Person类,然后根据姓名判断两个实例对象是否相同时,这在DAO(Data Access Objects)层是经常用到的。具体操作时先从数据库中获得两个DTO(Data Transfer Object,数据传输对象),然后判断他们是否相等的,代码如下:
覆写的equals方法做了多个校验,考虑到Web上传递过来的对象有可能输入了前后空格,所以用trim方法剪切了一下,看看代码有没有问题,我们写一个main:
上面的代码产生了两个Person对象(注意p2变量中的那个张三后面有一个空格),然后放到list中,最后判断list是否包含了这两个对象。看上去没有问题,应该打印出两个true才对,但是结果却是:
列表中是否包含张三:true
列表中是否包含张三:false
刚刚放到list中的对象竟然说没有,这太让人失望了,原因何在呢?list类检查是否包含元素时时通过调用对象的equals方法来判断的,也就是说 contains(p2)传递进去,会依次执行p2.equals(p1),p2.equals(p2),只有一个返回true,结果都是true,可惜 的是比较结果都是false,那问题出来了:难道
p2.equals(p2)因为false不成?
还真说对了,p2.equals(p2)确实是false,看看我们的equals方法,它把第二个参数进行了剪切!也就是说比较的如下等式:
注意前面的那个张三,是有空格的,那结果肯定是false了,错误也就此产生了,这是一个想做好事却办成了 "坏事" 的典型案例,它违背了equlas方法的自反性原则:对于任何非空引用x,x.equals(x)应该返回true,问题直到了,解决非常简单,只要把trim()去掉即可。注意解决的只是当前问题,该equals方法还存在其它问题。
继续45建议的问题,我们解决了覆写equals的自反性问题,是不是就完美了呢?在把main方法重构一下:
很小的改动,大家肯定晓得了运行结果是包"空指针"异常。原因也很简单:null.equalsIgnoreCase方法自然报错,此处就是为了说明覆写equals方法遵循的一个原则---
对称性原则:对于任何引用x和y的情形,如果x.equals(y),把么y.equals(x)也应该返回true。
本节我们继续讨论覆写equals的问题,这次我们编写一个员工Employee类继承Person类,这很正常,员工也是人嘛,而且在JavaBean中继承也很多见,代码如下:
员工类增加了工号ID属性,同时也覆写了equals方法,只有在姓名和ID都相同的情况下才表示同一个员工,这是为了避免一个公司中出现同名同姓员工的情况。看看上面的代码,这里的条件已经相当完善了,应该不会出错了,那我们测试一下,代码如下:
上面定义了两个员工和一个社会闲杂人员,虽然他们同名同姓,但肯定不是同一个,输出都应该是false,但运行之后结果为: true true false
很不给力呀,p1竟然等于e1,也等于e2,为什么不是同一个类的两个实例竟然也会相等呢?这很简单,因为p1.equals(e1)是调用父类Person的equals方法进行判断的,它使用的是instanceof关键字检查e1是否是Person的实例,由于两者村子继承关系,那结果当然是true了,相等也就没有任何问题了,但是反过来就不成立了,e1和e2是不可能等于p1,这也是违反对称性原则的一个典型案例。
更玄的是p1与e1、e2相等,但e1和e2却不相等,似乎一个简单的符号传递都不能实现,这才是我们分析的重点:e1.equals(e2)调用的是子类Employee的equals方法,不仅仅要判断姓名相同,还要判断Id相同,两者工号是不同的,不相等也是自然的了。等式不传递是因为违反了equals的传递性原则,传递性原则指的是对于实例对象x、y、z来说,如果x.equals(y)返回true,y.equals(z)返回true,那么x.equals(z)也应该返回true。
这种情况发生的关键是父类引用了instanceof关键字,它是用来判断一个类的实例对象的,这很容易让子类钻空子。想要解决也很简单,使用getClass来代替instanceof进行类型判断,Person的equals方法修改后如下所示:
当然,考虑到Employee也有可能被继承,也需要把它的instanceof修改为getClass。总之,在覆写equals时建议使用getClass进行类型判断,而不要使用instanceof。
覆写equals方法必须覆写hasCode方法,这条规则基本上每个Javaer都知道,这也是JDK的API上反复说明的,不过为什么要则这么做呢?这两个方法之间什么关系呢?本建议就来解释该问题,我们先看看代码:
代码中的Person类与上一建议的Person相同,equals方法完美无缺。在这段代码中,我们在声明时直接调用方法赋值,这其实也是一个内部匿名类,现在的问题是b1和b2值是否都为true?
我们先来看b1,Person类的equals覆写了,不再判断两个地址相等,而是根据人员的姓名来判断两个对象是否相等,所以不管我们的new Person("张三")产生了多少个对象,它们都是相等的。把张三放入List中,再检查List中是否包含,那结果肯定是true了。
接下来看b2,我们把张三这个对象作为了Map的键(Key),放进去的是张三,检查的对象还是张三,那应该和List的结果相同了,但是很遗憾,结果为false。原因何在呢?
原因就是HashMap的底层处理机制是以数组的方式保存Map条目的(Map Entry)的,这其中的关键是这个数组的下标处理机制:依据传入元素hashCode方法的返回值决定其数组的下标,如果该数组位置上已经有Map条目,并且与传入的值相等则不处理,若不相等则覆盖;如果数组位置没有条目,则插入,并加入到Map条目的链表中。同理,检查键是否存在也是根据哈希码确定位置,然后遍历查找键值的。
接着深入探讨,那对象元素的hashCode方法返回的是什么值呢?它是一个对象的哈希码,是由Object类的本地方法生成的,确保每个对象有一个哈希码(也是哈希算法的基本要求:任意输入k,通过一定算法f(k),将其转换为非可逆的输出,对于两个输入k1和k2,要求若k1=k2,则必须f(k1)=f(k2),但也允许k1 != k2 , f(k1)=f(k2)的情况存在)。
那回到我们的例子上,由于我们没有覆写hashCode方法,两个张三对象的hashCode方法返回值(也就是哈希码)肯定是不相同的了,在HashMap的数组中也找不到对应的Map条目了,于是就返回了false。
问题清楚了,修改也很简单,在Person类中重写一下hashCode方法即可,代码如下:
其中HashCodeBuilder是org.apache.commons.lang.builder包下的一个哈希码生成工具,使用起来非常方便,大家可以直接项目中集成(为何不直接写hashCode方法?因为哈希码的生成有很多种算法,自己写麻烦,事儿又多,所以必要的时候才取"拿来主义",不重复造轮子是最好的办法。)
为什么要覆写toString方法,这个问题很简单,因为Java提供的默认toString方法不友好,打印出来看不懂,不覆写不行,看这样一段代码:
输出结果是:Perso@188edd79.如果机器不同,@后面的内容也会不同,但格式都是相同的:类名+@+hashCode,这玩意是给机器看的,人哪能看懂呀!这就是因为我们没有覆写Object类的toString方法的缘故,修改一下,代码如下:
如此即就可以在需要的时候输出调试信息了,而且非常友好,特别是在bean流行的项目中(一般的Web项目就是这样),有了这样的输出才能更好地debug,否则查找错误就有点麻烦!当然,当bean的属性较多时,自己实现就不可取了,不过可以直接使用apache的commons工具包中的ToStringBuilder类,简洁,实用又方便。可能有人会说,为什么通过println方法打印一个对象会调用toString方法?那是源于println的打印机制:如果是一个原始类型就直接打印,如果是一个类类型,则打印出其toString方法的返回值,如此而已。同时现在IDE也很先进,大家debug时也可查看对象的变量,但还是建议大家覆写toString方法,这样调试会更方便哦。
Java中有一个特殊的类:package-info类,它是专门为本包服务的,为什么说它特殊,主要体现在三个方面:
它不能随便创建:在一般的IDE中,Eclipse、package-info等文件是不能随便被创建的,会报"Type name is notvalid"错误,类名无效。在Java中变量定义规范中规定如下字符是允许的:字母、数字、下划线,以及那个不怎么写的$符号,不过中划线可不在之列,那么怎么创建这个文件呢?很简单,用记事本创建一个,然后拷贝进去再改一下就成了,更直接的办法就是从别的项目中拷贝过来。
它服务的对象很特殊:一个类是一类或一组事物的描述,比如Dog这个类,就是描述"阿黄"的,那package-info这个类描述的是什么呢?它总是要有一个被描述或陈述的对象吧,它是描述和记录本包信息的。
package-info类不能有实现代码:package-info类再怎么特殊也是 一个类,也会被编译成 package-info.class,但是在package-info.java文件不能声明package-info类。
package-info类还有几个特殊的地方,比如不可以继承,没有接口,没有类间关系(关联、组合、聚合等)等,Java中既然有这么特殊的一个类,那肯定有其特殊的作用了,我们来看看它的特殊作用,主要表现在以下三个方面:
声明友好类和包内访问常量:这个比较简单,而且很实用,比如一个包中有很多内部访问的类或常量,就可以统一放到package-info类中,这样很方便,便于集中管理,可以减少友好类到处游走的情况,代码如下:
注意以上代码是放在package-info.java中的,虽然它没有编写package-info的实现,但是package-info.class类文件还是会生成。通过这样的定义,我们把一个包需要的常量和类都放置在本包下,在语义上和习惯上都能让程序员更适应。
为在包上提供注解提供便利:比如我们要写一个注解(Annotation),查看一下包下的对象,只要把注解标注到package-info文件中即可,而且在很多开源项目中也采用了此方法,比如struts2的@namespace、hibernate的@FilterDef等.
提供包的整体注释说明:如果是分包开发,也就是说一个包实现了一个业务逻辑或功能点或模块或组件,则该包需要一个很好的说明文档,说明这个包是做什么用的,版本变迁历史,与其他包的逻辑关系等,package-info文件的作用在此就发挥出来了,这些都可以直接定义到此文件中,通过javadoc生成文档时,会吧这些说明作为包文档的首页,让读者更容易对该包有一个整体的认识。当然在这点上它与package.html的作用是相同的,不过package-info可以在代码中维护文档的完整性,并且可以实现代码与文档的同步更新。
创建package-info,也可以利用IDE工具如下图:
解释了这么多,总结成一句话:在需要用到包的地方,就可以考虑一下package-info这个特殊类,也许能起到事半功倍的作用。
很久很久以前,在java1.1的年代里,我们经常会看到System.gc这样的调用---主动对垃圾进行回收,不过,在Java知识深入人心后,这样的代码就逐渐销声匿迹了---这是好现象,因为主动进行垃圾回收是一个非常危险的动作。
之所以危险,是因为System.gc要停止所有的响应,才能检查内存中是否存在可以回收的对象,这对一个应用系统来说风险极大,如果是一个Web应用,所有的请求都会暂停,等待垃圾回收器执行完毕,若此时堆内存(heap)中的对象少的话还可以接受,一但对象较多(现在的web项目是越做越大,框架、工具也越来越多,加载到内存中的对象当然也就更多了),这个过程非常耗时,可能是0.01秒,也可能是1秒,甚至20秒,这就严重影响到业务的运行了。
例如:我们写这样一段代码:new String("abc"),该对象没有任何引用,对JVM来说就是个垃圾对象。JVM的垃圾回收器线程第一次扫描(扫描时间不确定,在系统不繁忙的时候执行)时给它贴上一个标签,说"你是可以回收的",第二次扫描时才真正的回收该对象,并释放内存空间,如果我们直接调用System.gc,则是说“嗨,你,那个垃圾回收器过来检查一下有没有垃圾对象,回收一下”。瞧瞧看,程序主动找来垃圾回收器,这意味着正在运行的系统要让出资源,以供垃圾回收器执行,想想看吧,它会把所有的对象都检查一遍,然后处理掉那些垃圾对象。注意哦,是检查每个对象。
不要调用System.gc,即使经常出现内存溢出也不要调用,内存溢出是可分析的,是可以查找原因的,GC可不是一个好招数。
一般对象都是通过new关键字生成的,但是String还有第二种生成方式,也就是我们经常使用的直接声明方式,这种方式是极力推荐的,但不建议使用new String("A")的方式赋值。为什么呢?我们看如下代码:
注意看上面的程序,我们使用"=="判断的是两个对象的引用地址是否相同,也就是判断是否为同一个对象,打印的结果是true,false,true。即有两个直接量是同一个对象(进过intern处理后的String与直接量是同一个对象),但直接通过new生成的对象却与之不等,原因何在?
原因是Java为了避免在一个系统中大量产生String对象(为什么会大量产生,因为String字符串是程序中最经常使用的类型),于是就设计了一个字符串池(也叫作字符串常量池,String pool或String Constant Pool或String Literal Pool),在字符串池中容纳的都是String字符串对象,它的创建机制是这样的:创建一个字符串时,首先检查池中是否有字面值相等的字符串,如果有,则不再创建,直接返回池中该对象的引用,若没有则创建之,然后放到池中,并返回新建对象的引用,这个池和我们平常说的池非常接近。对于此例子来说,就是创建第一个"詹姆斯"字符串时,先检查字符串池中有没有该对象,发现没有,于是就创建了"詹姆斯"这个字符串并放到池中,待创建str2字符串时,由于池中已经有了该字符串,于是就直接返回了该对象的引用,此时,str1和str2指向的是同一个地址,所以使用"=="来判断那当然是相等的了。
那为什么使用new String("詹姆斯")就不相等了呢?因为直接声明一个String对象是不检查字符串池的,也不会把对象放到字符串池中,那当然"=="为false了。
那为什么intern方法处理后即又相等了呢?因为intern会检查当前对象在对象池中是否存在字面值相同的引用对象,如果有则返回池中的对象,如果没有则放置到对象池中,并返回当前对象。
可能有人要问了,放到池中,是不是要考虑垃圾回收问题呀?不用考虑了,虽然Java的每个对象都保存在堆内存中但是字符串非常特殊,它在编译期已经决定了其存在JVM的常量池(Constant Pool),垃圾回收不会对它进行回收的。
通过上面的介绍,我们发现Java在字符串的创建方面确实提供了非常好的机制,利用对象池不仅可以提高效率,同时减少了内存空间的占用,建议大家在开发中使用直接量赋值方式,除非必要才建立一个String对象。
有这样的一个简单需求,写一个方法,实现从原始字符串中删除与之匹配的所有字符串,比如在"好是好"中,删除"好",代码如下:
StringUtils工具类很简单,它采用了String的replaceAll方法,该方法是做字符串替换的,我们编写一个测试用例,检查remove方法是否正确,如下所示:
单独运行第一个是绿条,单独运行第二个是红条,为什么第二个(assertTrue(StringUtils.remove(" ","$").equals("是")))不通过呢?
问题就出在replaceAll方法上,该方法确实需要传递两个String类型的参数,也确实进行了字符串替换,但是它要求第一个参数是正则表达式,符合正则表达式的字符串才会被替换。对上面的例子来说,第一个测试案例传递进来的是一个字符串"好",这是一个全匹配查找替换,处理的非常正确,第二个测试案例传递进来的是一个" "符号在正则表达式中表示的是字符串的结束位置,也就是执行完replaceAll后在字符串结尾的地方加上了空字符串,其结果还是" ",所以测试失败也就再所难免了。问题清楚了,解决方案也就出来了:使用replace方法替换即可,它是replaceAll的方法的简化版,可传递两个String参数,与我们的编码意图是吻合的。
大家如果注意看JDK文档,会发现replace(CharSequence target,CharSequence replacement)方法是1.5版本以后才开始提供的, 在此之前如果要对一个字符串进行全体换,只能使用replaceAll方法,不过由于replaceAll方法的第二个参数使用了正则表达式,而且参数类型只要是CharSequence就可以(String的父类),所以很容易使使用者误解,稍有不慎就会导致严重的替换错误。
注意:replaceAll传递的第一个参数是正则表达式
CharSequence接口有三个实现类与字符串有关,String、StringBuffer、StringBuilder,虽然它们都与字符串有关,但其处理机制是不同的。
String类是不可变的量,也就是创建后就不能再修改了,比如创建了一个"abc"这样的字符串对象,那么它在内存中永远都会是"abc"这样具有固定表面值的一个对象,不能被修改,即使想通过String提供的方法来尝试修改,也是要么创建一个新的字符串对象,要么返回自己,比如:
其中str是一个字符串对象,其值是"abc",通过substring方法又重新生成了一个字符串str1,它的值是"bc",也就是说str引用的对象一但产生就永远不会变。为什么上面还说有可能不创建对象而返回自己呢?那是因为采用substring(0)就不会创建对象。JVM从字符串池中返回str的引用,也就是自身的引用。
StringBuffer是一个可变字符串,它与String一样,在内存中保存的都是一个有序的字符序列(char 类型的数组),不同点是StringBuffer对象的值是可改变的,例如:
从上面的代码可以看出sb的值在改变,初始化的时候是"a" ,经过append方法后,其值变成了"ab"。可能有人会问了,这与String类通过 "+" 连接有什么区别呢?例如
有区别,字符串变量s初始化时是 "a" 对象的引用,经过加号计算后,s变量就修改为了 “ab” 的引用,但是初始化的 “a” 对象还没有改变,只是变量s指向了新的引用地址,再看看StringBuffer的对象,它的引用地址虽不变,但值在改变。
StringBuffer和StringBuilder基本相同,都是可变字符序列,不同点是:StringBuffer是线程安全的,StringBuilder是线程不安全的,翻翻两者的源代码,就会发现在StringBuffer的方法前都有关键字syschronized,这也是StringBuffer在性能上远远低于StringBuffer的原因。
在性能方面,由于String类的操作都是产生String的对象,而StringBuilder和StringBuffer只是一个字符数组的再扩容而已,所以String类的操作要远慢于StringBuffer 和 StringBuilder。
弄清楚了三者之间的原理,我们就可以在不同的场景下使用不同的字符序列了:
使用String类的场景:在字符串不经常变化的场景中可以使用String类,例如常量的声明、少量的变量运算等;
使用StringBuffer的场景:在频繁进行字符串的运算(如拼接、替换、删除等),并且运行在多线程的环境中,则可以考虑使用StringBuffer,例如XML解析、HTTP参数解析和封装等;
使用StringBuilder的场景:在频繁进行字符串的运算(如拼接、替换、删除等),并且运行在单线程的环境中,则可以考虑使用StringBuilder,如SQL语句的拼接,JSON封装等。
注意:在适当的场景选用字符串类型
看下面一段程序:
想想两个字符串输出的结果的苹果数量是否一致,如果一致,会是几呢?
答案是不一致,str1的值是"3apples" ,str2的值是“apples12”,这中间悬殊很大,只是把“apples” 调换了一下位置,为何会发生如此大的变化呢?
这都源于java对于加号的处理机制:在使用加号进行计算的表达式中,只要遇到String字符串,则所有的数据都会转换为String类型进行拼接,如果是原始数据,则直接拼接,如是是对象,则调用toString方法的返回值然后拼接,如:
str = str + new ArrayList();
上面就是调用ArrayList对象的toString方法返回值进行拼接的。再回到前面的问题上,对与str1 字符串,Java的执行顺序是从左到右,先执行1+2,也就是算术加法运算,结果等于3,然后再与字符串进行拼接,结果就是 "3 apples",其它形式类似于如下计算:
String str1 = (1 + 2 ) + "apples" ;
而对于str2字符串,由于第一个参与运算的是String类型,加1后的结果是“apples 1” ,这仍然是一个字符串,然后再与2相加,结果还是一个字符串,也就是“apples12”。这说明如果第一个参数是String,则后续的所有计算都会转变为String类型,谁让字符串是老大呢!
注意: 在“+” 表达式中,String字符串具有最高优先级。
对一个字符串拼接有三种方法:加号、concat方法及StringBuilder(或StringBuffer ,由于StringBuffer的方法与StringBuilder相同,不在赘述)的append方法,其中加号是最常用的,其它两种方式偶尔会出现在一些开源项目中,那这三者之间有什么区别吗?我们看看下面的例子:
上面是4种不同方式的字符串拼接方式,循环10万次后检查其执行时间,执行结果如下:
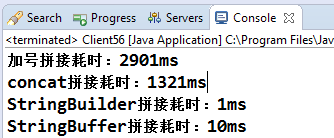
从上面的执行结果来看,在字符串拼接方式中,StringBuilder的append方法最快,StringBuffer的append方法次之(因为StringBuffer的append方法是线程安全的,同步方法自然慢一点),其次是concat方法,加号最慢,这是为何呢?
(1)、"+" 方法拼接字符串:虽然编辑器对字符串的加号做了优化,它会使用StringBuilder的append方法进行追加,按道理来说,其执行时间也应该是1ms,不过最终是通过toString方法转换为String字符串的,例子中的"+" 拼接的代码如下代码相同
注意看,它与纯粹使用StringBuilder的append方法是不同的:一是每次循环都会创建一个StringBuilder对象,二是每次执行完毕都要调用toString方法将其转换为字符串——它的执行时间就耗费在这里了!
(2)、concat方法拼接字符串:我们从源码上看一下concat方法的实现,代码如下:
其整体看上去就是一个数组拷贝,虽然在内存中处理都是原子性操作,速度非常快,不过,注意看最后的return语句,每次concat操作都会创建一个String对象,这就是concat速度慢下来的真正原因,它创建了10万个String对象呀。
(3)、append方法拼接字符串:StringBuilder的append方法直接由父类AbstractStringBuilder实现,其代码如下:
看到没,整个append方法都在做字符数组处理,加长,然后拷贝数组,这些都是基本的数据处理,没有创建任何对象,所以速度也就最快了!注意:例子中是在随后通过StringBuilder的toString方法返回了一个字符串,也就是说在10万次循环结束后才生成了一个String对象。StringBuffer的处理和此类似,只是方法是同步的而已。
四者的实现方法不同,性能也就不同,但并不表示我们一定要使用StringBuilder,这是因为"+"非常符合我们的编码习惯,适合阅读,两个字符串拼接,就用加号连一下,这很正常,也很友好,在大多数情况下我们都可以使用加号操作,只有在系统性能临界(如在性能 " 增长一分则太长" 的情况下)的时候才可以考虑使用concat或append方法。而且,很多时候系统80% 的性能是消耗在20%的代码上的,我们的精力应该更多的投入到算法和结构上。
注意:适当的场景使用适当的字符串拼接方式。
字符串的操作,诸如追加、合并、替换、倒叙、分割等,都是在编码过程中经常用到的,而且Java也提供了append、replace、reverse、spit等方法来完成这些操作,它们使用起来确实方便,但是更多时候,需要使用正则表达式来完成复杂的处理,我们来看一个例子:统计一篇文章中英文单词的数量,很简单吧,代码如下:
使用spit方法根据空格来分割单词,然后计算分割后的数组长度,这种方法可靠吗?我们看看输出结果:
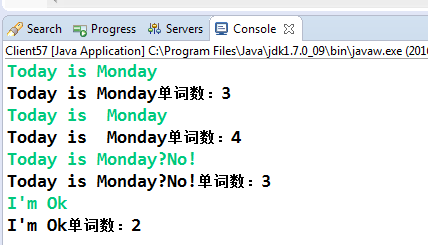
注意看输出,除了第一个输入"Today is Monday"正确外,其它的都是错误的!第二条输入中的单词"Monday"前有2个连续的空格,第三条输入中"No"单词前后都没有空格,最后一个输入则没有把连写符号" ' "考虑进去,这样统计出来的单词数量肯定是错误一堆,那怎么做才合理呢?
如果考虑使用一个循环来处理这样的"异常"情况,会使程序的稳定性变差,而且要考虑太多太多的因素,这让程序的复杂性也大大提高了。那如何处理呢?可以考虑使用正则表达式,代码如下:
准不准确,我们看看相同的输入,输出结果如下:
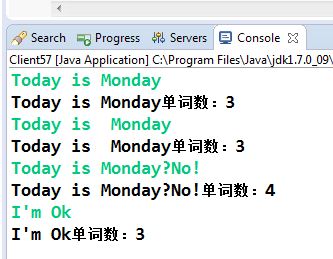
每项的输出都是准确的,而且程序也不复杂,先生成一个正则表达式对象,然后使用匹配器进行匹配,之后通过一个while循环统计匹配的数量。需要说明的是,在Java的正则表达式中"\b" 表示的是一个单词的边界,它是一个位置界定符,一边为字符或数字,另外一边为非字符或数字,例如"A"这样一个输入就有两个边界,即单词"A"的左右位置,这也就说明了为什么要加上"\w"(它表示的是字符或数字)。
正则表达式在字符串的查找,替换,剪切,复制,删除等方面有着非凡的作用,特别是面对大量的文本字符需要处理(如需要读取大量的LOG日志)时,使用正则表达式可以大幅地提高开发效率和系统性能,但是正则表达式是一个恶魔,它会使程序难以读懂,想想看,写一个包含^、$、\A、\s、\Q、+、?、()、{}、[]等符号的正则表达式,然后再告诉你这是一个" 这样,这样......"字符串查找,你是不是要崩溃了?这个代码确实不好阅读,你就要在正则上多下点功夫了。
注意:正则表达式是恶魔,威力巨大,但难以控制。
Java的乱码问题由来已久,有经验的开发人员肯定遇到过乱码,有时从Web接收的乱码,有时从数据库中读取的乱码,有时是在外部接口中接收的乱码文件,这些都让我们困惑不已,甚至是痛苦不堪,看如下代码:
Java文件是通过IDE工具默认创建的,编码格式是GBK,大家想想看上面的输出结果会是什么?可能是乱码吧?两个编码格式不同。我们暂时不说结果,先解释一下Java中的编码规则。Java程序涉及的编码包括两部分:
(1)、Java文件编码:如果我们使用记事本创建一个.java后缀的文件,则文件的编码格式就是操作系统默认的格式。如果是使用IDE工具创建的,如Eclipse,则依赖于IDE的设置,Eclipse默认是操作系统编码(Windows一般为GBK);
(2)、Class文件编码:通过javac命令生成的后缀名为.class的文件是UTF-8编码的UNICODE文件,这在任何操作系统上都是一样的,只要是.class文件就会使UNICODE格式。需要说明的是,UTF是UNICODE的存储和传输格式,它是为了解决UNICODE的高位占用冗余空间而产生的,使用UTF编码就意味着字符集使用的是UNICODE.
再回到我们的例子上,getBytes方法会根据指定的字符集取出字节数组(这里按照UNICODE格式来提取),然后程序又通过new String(byte [] bytes)重新生成一个字符串,来看看String的这个构造函数:通过操作系统默认的字符集解码指定的byte数组,构造一个新的String,结果已经很清楚了,如果操作系统是UTF-8的话,输出就是正确的,如果不是,则会是乱码。由于这里使用的是默认编码GBK,那么输出的结果也就是乱码了。我们再详细分解一下运行步骤:
步骤1:创建Client58.java文件:该文件的默认编码格式GBK(如果是Eclipse,则可以在属性中查看到)。
步骤2:编写代码(如上);
步骤3:保存,使用javac编译,注意我们没有使用"javac -encoding GBK Client58.java" 显示声明Java的编码方式,javac会自动按照操作系统的编码(GBK)读取Client58.java文件,然后将其编译成.class文件。
步骤4:生成.class文件。编译结束,生成.class文件,并保存到硬盘上,此时 .class文件使用的UTF-8格式编码的UNICODE字符集,可以通过javap 命令阅读class文件,其中" 汉字"变量也已经由GBK转变成UNICODE格式了。
步骤5:运行main方法,提取"汉字"的字节数组。"汉字" 原本是按照UTF-8格式保存的,要再提取出来当然没有任何问题了。
步骤6:重组字符串,读取操作系统默认的编码GBK,然后重新编码变量b的所有字节。问题就在这里产生了:因为UNICODE的存储格式是两个字节表示一个字符(注意:这里是指UCS-2标准),虽然GBK也是两个字节表示一个字符,但两者之间没有映射关系,只要做转换只能读取映射表,不能实现自动转换----于是JVM就按照默认的编码方式(GBK)读取了UNICODE的两个字节。
步骤7:输出乱码,程序运行结束,问题清楚了,解决方案也随之产生,方案有两个。
步骤8:修改代码,明确指定编码即可,代码如下:
System.out.println(new String(b,"UTF-8"));
步骤9:修改操作系统的编码方式,各个操作系统的修改方式不同,不再赘述。
我们可以把字符串读取字节的过程看做是数据传输的需要(比如网络、存储),而重组字符串则是业务逻辑的需求,这样就可以是乱码重现:通过JDBC读取的字节数组是GBK的,而业务逻辑编码时采用的是UTF-8,于是乱码就产生了。对于此类问题,最好的解决办法就是使用统一的编码格式,要么都用GBK,要么都用UTF-8,各个组件、接口、逻辑层、都用UTF-8,拒绝独树一帜的情况。
问题清楚了,我么看看以下代码:
仅仅修改了读取字节的编码方式(修改成了GB2312),结果会怎样呢?又或者将其修改成GB18030,结果又是怎样的呢?结果都是"汉字",不是乱码。这是因为GB2312是中文字符集的V1.0版本,GBK是V2.0版本,GB18030是V3.0版本,版本是向下兼容的,只是它们包含的汉字数量不同而已,注意UNICODE可不在这个序列之内。
注意:一个系统使用统一的编码。
在Java 中一涉及中文处理就会冒出很多问题来,其中排序也是一个让人头疼的课题,我们看如下代码:
上面的代码定义了一个数组,然后进行升序排序,我们期望的结果是按照拼音升序排列,即为李四、王五、张三,但是结果却不是这样的:
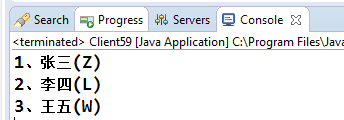
这是按照什么排的序呀,非常混乱!我们知道Arrays工具类的默认排序是通过数组元素的compareTo方法进行比较的,那我们来看String类的compareTo的主要实现:
上面的代码先取得字符串的字符数组,然后一个一个地比较大小,注意这里是字符比较(减号操作符),也就是UNICODE码值比较,查一下UNICODE代码表,"张" 的码值是5F20,"李"是674E,这样一看,"张" 排在 "李" 前面也就很正确了---但这明显与我们的意图冲突了。这一点在JDK的文档中也有说明:对于非英文的String排序可能会出现不准确的情况,那该如何解决这个问题呢?Java推荐使用collator类进行排序,那好,我们把代码修改一下:
输出结果:
1、李四(L)
2、王五(W)
3、张三(Z)
这确实是我们期望的结果,应该不会错了吧!但是且慢,中国的汉字博大精深,Java是否都能精确的排序呢?最主要的一点是汉字中有象形文字,音形分离,是不是每个汉字都能按照拼音的顺序排好呢?我们写一个复杂的汉字来看看:
输出结果如下:
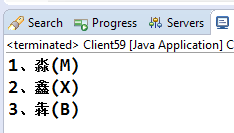
输出结果又乱了,不要责怪Java,它们已尽量为我们考虑了,只是因为我们的汉字文化太博大精深了,要做好这个排序确实有点为难它,更深层次的原因是Java使用的是UNICODE编码,而中文UNICODE字符集来源于GB18030的,GB18030又是从GB2312发展起来,GB2312是一个包含了7000多个字符的字符集,它是按照拼音排序,并且是连续的,之后的GBK、GB18030都是在其基础上扩充而来的,所以要让它们完整的排序也就难上加难了。
如果排序对象是经常使用的汉字,使用Collator类排序完全可以满足我们的要求,毕竟GB2312已经包含了大部分的汉字,如果需要严格排序,则要使用一些开源项目来自己实现了,比如pinyin4j可以把汉字转换为拼音,然后我们自己来实现排序算法,不过此时你会发现要考虑的诸如算法、同音字、多音字等众多问题。
注意:如果排序不是一个关键算法,使用Collator类即可。
数组在实际的系统开发中用的越来越少了,我们通常只有在阅读一些开源项目时才会看到它们的身影,在Java中它确实没有List、Set、Map这些集合类用起来方便,但是在基本类型处理方面,数组还是占优势的,而且集合类的底层也都是通过数组实现的,比如对一数据集求和这样的计算:
对一个int类型 的数组求和,取出所有数组元素并相加,此算法中如果是基本类型则使用数组效率是最高的,使用集合则效率次之。再看使用List求和:
注意看sum += datas.get(i);这行代码,这里其实已经做了一个拆箱动作,Integer对象通过intValue方法自动转换成了一个int基本类型,对于性能濒于临界的系统来说该方案是比较危险的,特别是大数量的时候,首先,在初始化List数组时要进行装箱操作,把一个int类型包装成一个Integer对象,虽然有整型池在,但不在整型池范围内的都会产生一个新的Integer对象,而且众所周知,基本类型是在栈内存中操作的,而对象是堆内存中操作的,栈内存的特点是:速度快,容量小;堆内存的特点是:速度慢,容量大(从性能上讲,基本类型的处理占优势)。其次,在进行求和运算时(或者其它遍历计算)时要做拆箱动作,因此无谓的性能消耗也就产生了。在实际测试中发现:对基本类型进行求和运算时,数组的效率是集合的10倍。
注意:性能要求较高的场景中使用数组代替集合。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










