



4.2.1 主导指标法
主导指标法就是根据区划的要求,从各项定量指标中,选出最能反映区域特征的主要指标来进行区域划分的方法。针对不同的区划种类、等级,主导指标的选择有所区别,如农业气候区划一般以热量和水分为主导指标,畜牧业区划以畜禽结构为主导指标等。区域划分的等级表明对区域差异的概括程度。同一种农业区划,等级不同,所采用的主导指标有所不同。以中国农业机械化区划为例,一级区划反映机械化条件在全国范围内的地域差异,以影响农业机械类型最大的农业生产部门和地貌作为主导指标;二级区划以地貌、农业部门和草原(水域)类型为主导指标。不同行政级的农业区划,主导指标也有所不同,如全国性林业区划以气候带、地貌和林业发展方向为主导指标,县级林业区划则以地貌或代表性树种为主导指标。由于资料收集的原因,本书所研究的风险区划限于全国性范围(一级风险区划),因此所选主导指标包括各地区受灾损失概率、各种农作物单位面积产量水平和波动情况以及各地各种农作物种植面积情况等指标。至于保险区划的细分,可以根据全国性风险区划再作详细分解,但分区思路和方法可以参照一级区划标准。
农作物保险的一个重要原则是在保险经营的过程中按照大数法则的要求,确定风险的同质性,并在风险同质性的基础上确定公平合理的保费,从而减少投保人进行逆选择的可能性,保证保险人经营的稳定性。农作物生产是经济再生产和自然再生产相互交织的过程,它以土地为基本生产资料,以有生命的农作物为主要生产对象。农作物的生长过程离不开特定的时空条件、自然环境条件、社会经济条件和相应的生产技术条件,因而这些条件都成为农作物生产中的风险因子。
主导指标必须具有空间差异,以便选出最能反映地区差异的指标;同时要注意选择典型性较高的代表单元(聚类单元),样本分布尽可能均匀,观测数据应比较完整,避免样本过于集中或数据残缺不全而影响分析的准确性。主导指标选取后,要力求计算准确。这些风险因子在不同区域的表现存在差异,这种差异导致农作物生产风险的区域差异。农作物生产风险的地区差异必然使得各个区域的农作物受到灾害的损失程度和范围以及单位面积产量波动和减少的情况不尽相同。因此,在以农作物区域产量为标的,以区域平均产量低于正常为农作物产量损失的农作物保险中,要坚持风险的一致性原则,首先必须根据上述风险因子的差异对农作物生产进行风险区划,也就是根据上述风险因子的种类、发生频度和强度以及这些风险因子的时空特性及其对农作物产量的影响程度,按照一定的原则把不同农作物生产的风险区域划分开来,在此基础上,根据上述各种风险因子的分异特性对不同农作物生产区域进行风险等级的划分,从而为确定农作物区域产量保险的费率等级提供科学依据和技术支持。
农业自然灾害的最终结果是造成农作物减产乃至绝收(主要指种植业),因而农作物最终减产数量可以综合地反映农业灾情。在一定的单产水平下,一个地区内农作物减产的数量取决于因灾减产的幅度及遭灾面积的大小。各地区遭受不同幅度减产的耕地面积的大小,可以作为刻画农业灾情的综合指标。我国民政系统规定,作物收成因灾减产为受灾,减产幅度在30%以上为成灾(其中,减产30%~50%为轻灾,50%~80%为重灾),减产幅度超过80%为绝收。如果仅用受灾或成灾面积来衡量各地农业灾情轻重的空间分布状况,可能存在一定缺陷:由于各省市自治区农业生产水平不同,同一数量级的耕地受灾,实际经济损失并不相同。为此,应当在农业风险区划中加入各地单产水平变异系数和各地各种农作物播种面积指数。
农业保险通常假定生产技术、自然状态以及由此引发的各个因素都是随机的,因此保险条约是依据过去对于自然状态的观测而制订的(Nelson,Loehman)。但是,正如Hirshleifer和Riley所注意到的,对于自然状态的监测通常并不准确,特别是在农业生产中,自然状态通常是很多潜在风险因素的组合,所以农业保险条款实际是通过观测“结果状态”(例如“产量”)的变化而制订的。在进行中国种植业生产风险区域划分时,本研究根据这一原则和聚类分析的要求,设计了四个风险分区的具体指标(具体见表4-1)。
表4-1 风险分区指标及其解释

续表

X1为各地区各种农作物单产变异系数,是一个衡量各种农作物单位面积产量年际变动幅度的综合性指标。它剔除了生产力水平的差异,在一定程度上反映了生产波动的情况,指标值越小表明生产越稳定,生产风险越小。计算模型如下:
将各省市历年某种农作物单产对时间趋势t做回归,并记录残差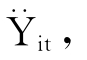 则
则
![]()
Yi表示i地区某作物的单产水平;t=1,2,3,…,T;
f(t)为作物单产与时间趋势的二项式函数关系式。
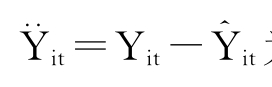 为剔除了时间趋势的产量(Detrending),我们可以利用其计算各种作物单产的波动水平,即变异系数(CV,Coefficient of Variation)。
为剔除了时间趋势的产量(Detrending),我们可以利用其计算各种作物单产的波动水平,即变异系数(CV,Coefficient of Variation)。
![]()
Yit为实际单产;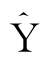 为趋势单产;
为趋势单产;
Y为平均单产,T为年数。
X2为各地农作物受灾率超过30%的发生概率。影响各地区受灾率(受灾面积占当年播种面积的比例)大小的因素有很多,包括各地区地形地貌、土壤条件、气候综合状况等。由于人们对造成农作物损失的致灾事件的物理过程并不十分清楚,各地区自然状况对农作物造成的损失很难确定,因此我们选择各地农业受灾程度作为一个综合度量各地区自然条件优劣的指标。根据时间序列数据分析,各地受灾率大于30%的发生概率差异较大,因此选择受灾率超过30%的发生概率为量化指标来度量不同省市自然条件的优劣。
目前对于风险损失分布还没有一个较为系统的方法,通常的做法是根据灾害事件的历史数据做出粗略估计。常用的有两种方法:一种是参数估计,首先假定这种损失随机变量服从某一具体分布,然后根据样本数据进行参数估计;另一种是非参数方法,根据样本数据对所寻找的分布通过直方图来进行描述,或者根据样本数据利用某种非参数方法,如非参数核密度估计方法或最临近估计方法,对所求的分布进行密度估计。对于参数估计来说,由于灾害系统非常复杂,要给出合乎情理的概率分布并非易事,很难准确判断由于灾害造成的损失究竟服从什么分布,无法明确知道分布的具体形式是正态分布、指数分布或是其他形式的分布。对于非参数方法来说,直方图法过于粗糙且极不稳定;而非参数密度估计,则由于数据收集方面的原因,对有记录的灾害统计,即灾害损失的样本量相对较小,在小样本条件下进行非参数密度估计缺乏稳健性,因此,通常的非参数估计方法在农作物生产风险评估中不太适用。
根据上面的分析,我们借用非参数密度估计的信息扩散方法(E.Parzen,1962),即非参数信息扩散模型来考察和研究上述问题。非参数信息扩散模型是一种非参数统计方法与模糊数学方法相结合的产物。该方法认为,某个样本数据所带的信息并不仅仅反映某个样本点的信息,而是带有整个样本空间的所有样本点的信息。因此,我们在得到一个具体的样本数据以后,将这种样本数据看成是样本空间的一个模糊子集,在具体计算的过程中将该样本点所带的信息扩散到整个样本空间,或者说分配到整个样本空间中的每个样本点;当所有样本数据的信息分配完成以后,样本空间中的每个样本点都带有全部样本数据的信息,从而形成样本信息在样本空间中的一个分布,这种分布就是我们所寻求的农作物生产风险的损失分布。[3]
设农作物生产损失为l,显然l∈[0,1],某地区第t年的生产损失率的样本观测数据为xt,t=1,2,3,…,T。设xt的信息按正态分布规律扩散给样本空间[0,1]中的每个样本点l,其信息扩散模型为:
![]()
其中,h为信息扩散系数,exp(.)表示自然底的指数函数。
在实际操作中,扩散系数h可根据样本数据中样本的个数m和样本的最大值b与最小值a通过如下的经验公式来确定:
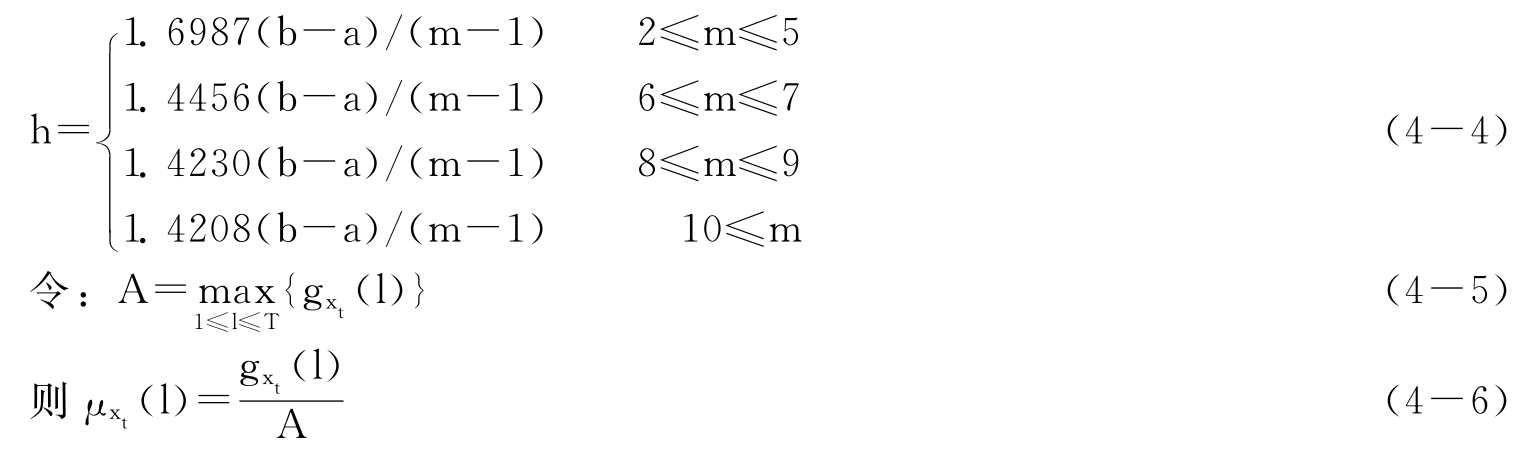
![]()
通过以上几步,就将样本损失率xt变成了一个以μxt(l)为隶属函数的模糊样本,而且这种模糊样本是一种最大隶属度为1的正规化模糊样本子集。
在进行风险评估时,我们并不知道哪一个样本对最后分布的贡献更大,因此,必须对上述模糊样本子集进行归一化处理,从而使得每个模糊样本在评估中所处的地位相同。为此令:则相应的模糊样本子集的隶属函数为:
![]()
它是原生产风险损失率样本xt的归一化的信息分布。对这种归一化的信息分布μxt(l)进行如下的处理,便得到一种效果较好的关于农作物区域产量风险损失率的评价结果。
![]()
其统计意义在于,原灾害损失样本经过信息扩散后取值为l的样本个数。
![]()
则M为[0,1]区间上所有样本点的总和,显然在理论上应该有M=T。事实上:
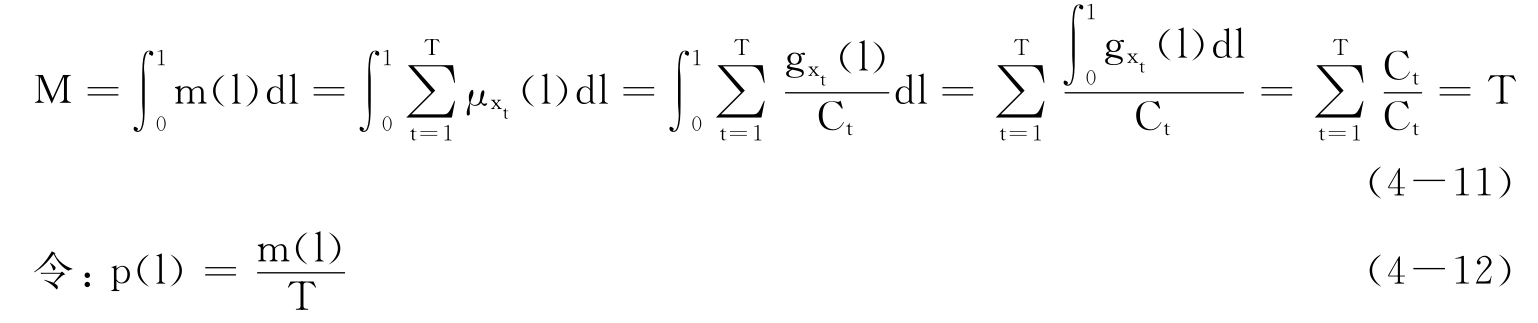
可知,其实际上是所有生产风险损失率的样本点落在l处的频率,可以作为损失率为l的概率的估计值。
![]()
则p(l)为损失样本经过信息扩散后得到的损失率超过l的概率估计值,即我们寻求的风险估计值。
在实际应用中,为了计算的方便起见,我们将上述连续的信息扩散模型通过如下的方式进行离散化。将生产损失的样本空间[0,1]分成若干等份:0=l1<l2<l3<…<ln=1,
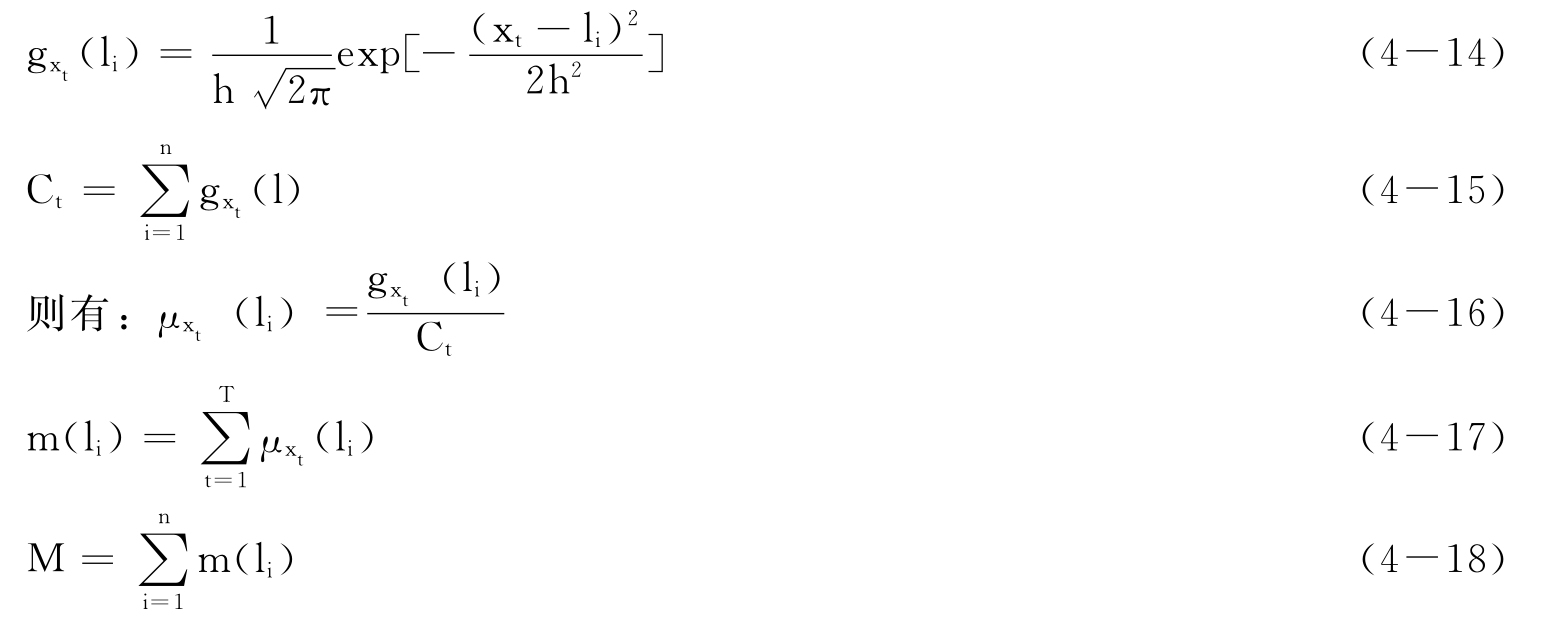
显然,在理论上应当有:M=T,但是由于计算中的舍入误差,最后计算的结果有可能M与T并不相等,为此,我们仍然采用理论值T。所以有:

据此便可以进行相应的生产风险损失率的概率估计。
X3为各地区各种农作物的专业化指数。一般来说,农作物播种面积的大小,即生产规模也在一定程度上反映了同一地区易受灾损的程度。因为不同省市某种农作物播种面积大小不同,因此选择这一指标作为生产规模的代表指标。
专业化指数反映一个地区某一农作物生产的规模和专业化程度,它是市场需求、资源禀赋、种植制度等因素相互作用的结果。一般来说,在一定长的时期内,只要有相当的规模,就意味着有市场需求,而有市场需求就意味着有经济效益。但规模较大的农作物相对来说风险也较大,因此,专业化指数在一定程度上可以反映农作物生产的风险状况。规模优势指数的计算公式如下:
![]()
其中:
SAIij为专业化指数;
GSij为i区j种农作物的播种面积;
GSi为i区所有农作物的播种总面积;
GSj为全国j种农作物的播种面积;
GS为全国所有农作物的播种总面积。
SAIij>1,表明与区域平均水平相比,i区j作物生产规模较大;SAIij<1,表明i区j作物相对于区域平均水平来说规模较小。
X4为各地区各种农作物的效率指数。一般来说,农作物的高产量通常伴随着高风险。国内外相关研究结果表明,农作物产量的标准差与产量正相关,但随着农作物单产的增加,农作物产量的变异系数却是下降的(Skees,Reed,1986;刘长标,2000)。这表明农业生产风险一方面随着农作物产量的增加而增加,另一方面农作物产量与变异系数又呈负相关。因此,单产变异系数并不能完全说明农作物生产区域生产风险的高低水平,选用不同地区不同农作物单产的相对水平也是衡量生产风险的指标之一。
农作物效率指数主要是从资源内涵生产力的角度来反映作物的生产风险程度,计算公式如下:
![]()
式中:
EAIij为i区j种农作物的效率指数;
APij为i区j种作物单产;
APj为全国j种作物平均单产。
EAIij>1,表明与全国平均水平相比,i区j作物生产具有效率优势;EAIij<1,表明i区j作物生产与全国平均水平相比生产效率处于劣势。EAIij值越大,生产效率优势越明显。在一般情况下,单产水平越高,效率指数也就越高,同时生产风险也越大。
从以上各风险区划指标的解释及其与生产风险程度的关系可以看出,在运用它们对农作物生产区域进行风险划分的过程中其实隐含着如下假设,即如果各地区自然条件恶劣(受灾率超过30%的发生概率高)、各种农作物单产波动幅度大(变异系数大)、单产水平相对较高(效率指数大)、生产规模相对较大(专业化指数大),其所面临的生产风险水平也较高。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











