



抽样推断的目的在于根据抽样指标数值估计全及指标数值,然而抽样总体终究不是全及总体,样本指标与总体指标之间往往存在着误差,而且不可避免。因此,在研究参数估计之前有必要先对抽样误差进行分析。
抽样误差是指抽样指标数值与被估计全及指标数值之差,即抽样平均数与总体平均数之差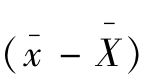 ,抽样成数与总体成数之差(p-P),等等。抽样误差的来源有两种:一种是登记性误差,即在调查过程中由于主客观原因而引起登记上的差错所造成的误差,如测量的工具或器具不够精确、观察的方法不够规范、人为的抄录笔误等造成的差错;另一种是代表性误差,即样本各单位的结构情况不足以代表总体的内部结构。代表性误差的发生有以下两种情况:一种是由于违反抽样调查的随机原则,如有意地多选较好的单位或较差的单位进行调查而使得样本缺乏充分代表性。这样,所据以计算的抽样指标必然会出现偏高或偏低现象,造成系统性误差。系统性误差和登记性误差都是抽样工作中的组织问题,应该采取措施避免发生或使其减少到最小限度。另一种情况,即使遵循随机原则,由于面对的样本有多个,只要被抽中的样本其内部构成比例和总体有出入,就会出现或大或小的偶然性的代表性误差。这种偶然性的代表性误差是无法消除的。
,抽样成数与总体成数之差(p-P),等等。抽样误差的来源有两种:一种是登记性误差,即在调查过程中由于主客观原因而引起登记上的差错所造成的误差,如测量的工具或器具不够精确、观察的方法不够规范、人为的抄录笔误等造成的差错;另一种是代表性误差,即样本各单位的结构情况不足以代表总体的内部结构。代表性误差的发生有以下两种情况:一种是由于违反抽样调查的随机原则,如有意地多选较好的单位或较差的单位进行调查而使得样本缺乏充分代表性。这样,所据以计算的抽样指标必然会出现偏高或偏低现象,造成系统性误差。系统性误差和登记性误差都是抽样工作中的组织问题,应该采取措施避免发生或使其减少到最小限度。另一种情况,即使遵循随机原则,由于面对的样本有多个,只要被抽中的样本其内部构成比例和总体有出入,就会出现或大或小的偶然性的代表性误差。这种偶然性的代表性误差是无法消除的。
(一)抽样实际误差的概念
抽样实际误差是指在某次抽样推断中,确定的抽样指标数值与被估计总体指标数值之间的误差。即按照随机原则抽样时,在没有登记误差和系统性误差的条件下,单纯由于不同的随机样本得出不同的抽样指标实际值而产生的误差,属于偶然性的代表性误差。
比如某年级100名同学的平均体重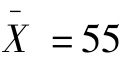 ,现随机地抽取10名同学为样本,其平均体重
,现随机地抽取10名同学为样本,其平均体重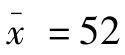 千克。若用52千克估计55千克,则抽样实际误差为52-55=-3(千克);如果重新抽10名同学,若测得
千克。若用52千克估计55千克,则抽样实际误差为52-55=-3(千克);如果重新抽10名同学,若测得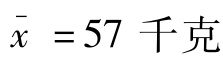 千克,则抽样实际误差为2千克。
千克,则抽样实际误差为2千克。
由本例不难看出,抽样实际误差既是一种随机性误差,也是一种代表性误差。说其是代表性误差,是因为利用总体的部分资料推算总体时,不论样本选取有多么公正,设计多么完善,总还是一部分单位而不是所有单位,产生误差是无法避免的。说其是随机性误差,是指按随机性原则抽样时,由于抽样的不同,会得到不同的抽样指标数值,由此产生的误差值各不相同。抽样实际误差中的代表性误差是抽样调查本身所固有的、无法避免的误差,但随机性误差则可利用大数定律精确地计算并能够通过恰当的抽样设计加以控制。
(二)影响抽样实际误差的因素
1. 样本容量的多少
由于总体内各单位之间总存在着差异,在其他条件不变的情况下,大量观察总比小量观察易于发现总体规律或特征,因此,样本容量越大,样本越能代表总体,抽样实际误差就越小;反之,样本容量越小,抽样实际误差就越大。当样本容量扩大到非常接近总体单位数时,抽样调查也就近于全面调查,抽样误差会缩小到几乎为零的程度。
2. 总体各单位标志值的差异程度
在其他条件不变的情况下,总体内各单位标志的差异程度越小即总体的标准差越小,则抽样误差就越小;反之,抽样误差就越大。抽样误差和总体单位之间的变异程度成正比。
3. 抽样方法
抽样方法不同,抽样误差也不同。一般来说,重复抽样的误差比不重复抽样的误差要大。
4. 抽样的组织形式
从同一总体中抽取相同样本容量的样本,采用简单随机抽样、等距抽样、类型抽样、整群抽样或者多阶段抽样等不同的抽样组织形式,所抽取的样本对于总体的代表性不同,其抽样实际误差也是不同的。
从一个总体可以抽取很多个样本,各个抽样指标(抽样平均数、抽样成数等)数值往往不同,它们与总体指标(总体平均数、总体成数等)数值的离差(即抽样实际误差)也就不同。抽样平均误差就是反映抽样实际误差一般水平的指标,通常用抽样平均数(或抽样成数)的标准差来表示。
(一)抽样平均数的抽样平均误差
以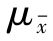 表示抽样平均数的抽样平均误差,
表示抽样平均数的抽样平均误差,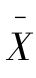 表示总体平均数,σ表示总体的标准差,k表示样本个数,
表示总体平均数,σ表示总体的标准差,k表示样本个数,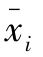 表示各抽样平均数。根据定义有:
表示各抽样平均数。根据定义有:
此式只是定义公式,实际推断中并不能用来计算抽样平均误差,因为我们往往只抽取一个或极少数样本,并且总体平均数本身就是待估计对象。
(1)当抽样方式为重复抽样时,样本标志值x1,x2,…,xn是相互独立的,样本变量x与总体变量X同分布,根据辛钦中心极限定理可得:
它说明在重复抽样的条件下,抽样平均误差与总体标准差成正比,与样本容量的平方根成反比。
例7-5 有5个工人的日产量分别为(单位:件)6,8,10,12,14,用重复抽样的方法,从中随机抽取两个工人的日产量,依据其一般水平来估计这5个工人的一般水平,则抽样平均误差为多少?
(2)当抽样方式为不重复抽样时,样本标志值x1,x2,…,xn不是相互独立的,根据数理统计知识可知:
当总体单位数N很大时,这个公式可近似表示为:
在计算抽样平均误差时,如果未知总体标准差数值,一般可以用样本标准差来代替近似计算。
(二)抽样成数的抽样平均误差
根据抽样平均数的抽样平均误差和总体标准差之间的关系,可以得到抽样成数的抽样平均误差的计算公式。
(1)在重复抽样下:
式中,μp——抽样成数的抽样平均误差;
P——总体成数;
p——抽样成数。
(2)在不重复抽样下:
例7-6 要估计某高校10 000名在校生的近视率,现随机从中抽取400名,检查有近视眼的学生320名,试计算样本近视率的抽样平均误差。
根据已知条件可知:
(1)在重复抽样条件下,样本近视率的抽样平均误差:
(2)在不重复抽样条件下,样本近视率的抽样平均误差:
计算结果表明,用样本的近视率来估计总体的近视率,其抽样平均误差为2%左右(即用样本的近视率来估计总体的近视率,其误差的绝对值平均来说在2%左右)。
设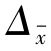 、Δp分别表示抽样平均数的抽样极限误差和抽样成数的抽样极限误差,则有:
、Δp分别表示抽样平均数的抽样极限误差和抽样成数的抽样极限误差,则有:
p——有效样本的抽样成数;
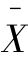 ——待估计总体平均数;
——待估计总体平均数;
P——待估计总体成数。
上面的不等式可变换为:
例7-7 要估计某乡粮食亩产量和总产量水平,从该乡8 000亩粮食作物中用不重复抽样方法抽取400亩,求得其平均亩产量为450千克。如果规定抽样极限误差为5千克,试估计该乡粮食亩产量和总产量所在的置信区间。
解:根据已知条件:
则该乡粮食亩产量为450千克±5千克,即445~455千克;粮食总产量在8 000×(450±5)千克的范围内,即356万~364万千克。
例7-8 要估计某农作物苗的成活率,现从播种这一品种的秧苗地块随机重复抽取秧苗1 000棵,其中死苗80棵,如果规定抽样极限误差为2%,试估计该农作物苗的成活率所在的置信区间。
解:根据已知条件:
p=92%,Δp=2%。
则该农作物苗的成活率为92%±2%,即90%~94%。
承例7-7,若已知某乡粮食亩产的标准差为σ=82千克,则平均亩产量的抽样平均误差为:
承例7-8,根据求得的秧苗成活率92%,可以求得农作物苗成活率的抽样平均误差为:
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









