



设总体X服从某已知分布,如正态分布、泊松分布和指数分布等,但是其中的一个或多个参数为未知,如何根据抽取的样本估计出未知参数的值,就是参数的点估计问题.
在实际问题中我们可以根据参数的性质确定出参数的取值范围,并把参数的取值范围称为参数空间,记为Θ.例如:设某总体X~P(λ),试由样本(X1,X2,…,Xn)来估计参数λ.这个例子中参数空间为Θ={λ|λ>0}.
例如,人的身高X~N(μ,σ2),一个样本为X1,X2,…,Xn,则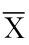 =1n(X1+…+Xn)为n个人的平均身高,近似认为总体均值μ为
=1n(X1+…+Xn)为n个人的平均身高,近似认为总体均值μ为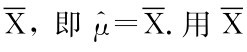 来估计μ,这里
来估计μ,这里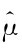 不是真值,而是估计值.
不是真值,而是估计值.
若总体的分布中含有m(m>1)个未知参数,则需构造m个统计量作为相应m个未知参数的点估计量.点估计量的求解方法很多,如矩估计法、极大似然估计法、Bayes方法和最小二乘法等.本书只介绍前两种最常用的方法:矩估计法和极大似然估计法.
1.矩估计法
矩估计法是由著名的统计学家卡尔·皮尔逊(K.Pearson)首先提出的.它的理论依据是:当n充分大时,样本的k阶原点矩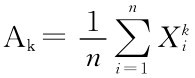 依概率收敛到总体X的k阶原点矩.矩估计法就是用样本的各阶矩来估计总体的相应矩.
依概率收敛到总体X的k阶原点矩.矩估计法就是用样本的各阶矩来估计总体的相应矩.
设总体X的分布函数为F(x;θ1,θ2,…,θk),有k个未知参数θ1,θ2,…,θk.X1,X2,…,Xn为来自总体X的一个样本,x1,x2,…,xn为相应的样本观测值,并设总体X的前k阶矩E(X),E(X2),…,E(Xk)都存在,则θ1,θ2,…,θk的矩估计的计算步骤如下:
(1)计算出总体X的前k阶矩
则μi=E(Xi)是θ1,θ2,…,θk的函数,记作μi=μi(θ1,θ2,…,θk).
(2)用样本矩代替总体矩,列出方程组
(3)解(2)中的方程组得到参数θ1,θ2,…,θk的矩估计量为:
将样本值x1,x2,…,xn替换X1,X2,…,Xn,即得到相应的矩估计值.
例7.1.1 设设总体X的均值μ及方差σ2都存在但均未知,且有σ2>0,又设(X1, X2,…,Xn)是来自总体X的一个样本,试求μ,σ2的矩估计量.
解 因为
解得μ和σ2的矩估计量为:
例7.1.2 设X1,X2,…,Xn为来自总体X服从参数为λ的泊松分布P(λ)的一个样本,求参数λ矩估计量.
解 由于λ=E(X),于是令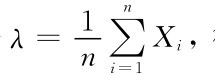 得到参数λ的矩估计量为
得到参数λ的矩估计量为
由于参数θ可以由其总体的各阶原点矩表示出来,即
θ=g(E(X),E(X2),…,E(Xk)).
此时,用样本原点矩来估计总体原点矩代入上面的函数中就可以得到参数θ的估计,即
因此,求θ的矩估计的关键就在于找出关系θ=g(E(X),E(X2),…,E(Xk)).
例7.1.3 设X1,X2,…,Xn为来自总体X服从区间(a,b)上的均匀分布U(a,b)的一个样本,求参数a,b的矩估计量.
解 因为
矩估计法的优点是计算较为简便,且当样本容量n很大时矩估计接近被估计参数真值的可能性很大.但其估计量有时不唯一.例如对于泊松分布P(λ),已知E(X)=λ=D(X),于是可以得到λ的两个矩估计量: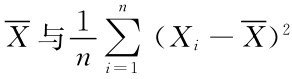 .一般来讲,在求矩估计量时,如没有其他要求,往往用一个较简单的结果就行了.
.一般来讲,在求矩估计量时,如没有其他要求,往往用一个较简单的结果就行了.
2.最大似然估计法
极大似然估计法最早由高斯(1821)提出,后经英国统计学家费希尔(R.A.Fisher, 1922)发展起来的一种应用广泛的参数估计方法.它是建立在极大似然原理基础上的一种统计方法.假如一个随机试验可能发生的结果有A,B,C三种.若在一次试验中结果A发生了,通常便认为事件A发生的概率最大.换句话说,对于概率不同的三个事件,在一次试验之前,如果我们断言将发生的事件是概率大的事件而不是概率小的事件,应该说是合理的.所谓的极大似然估计法就是依据此想法来估计未知参数的.为进一步说明极大似然估计法的基本思想,我们下面通过一个例子的分析进行介绍.
例7.1.4 设X1,X2,…,Xn为来自总体X服从0-1分布的一个样本,x1,x2,…, xn为相应的样本观测值,则X1,X2,…,Xn的联合概率密度函数为:
f(x1,x2,…,xn;p)=P{X1=x1,X2=x2,…,Xn=xn}
易知随p的取值不同,概率值P{X1=x1,X2=x2,…,Xn=xn}将发生变化,而此处p的实际取值是未知的,那么如何估计p的实际取值呢?
既然x1,x2,…,xn在一次试验中已经出现,按极大似然原理,事件{X1=x1,X2=x2,…,Xn=xn}发生的概率是最大的,因此p的实际取值应使(*)式中的概率值比p取其他所得的概率值要大.这样,我们自然选取使(*)中的概率值达到最大的p值作为p的估计值,这就是极大似然估计法选择未知参数的估计值的基本思想.
定义7.1.1 (极大似然估计量)设总体X的概率密度函数为p(x;θ)(当X为离散型总体时p(x;θ)=P{X=x},而当X为连续型总体时p(x;θ)=f(x;θ)),其中θ为未知参数或未知参数向量,并设X1,X2,…,Xn为来自总体X的一个样本,x1,x2,…,xn为相应的样本观测值,将样本的联合概率密度函数看成θ的函数,用L(x1,x2,…,xn;θ)表示,简记为L(θ),即
这里L(θ)称为参数θ的似然函数.若某统计量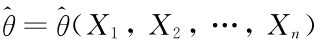 的观测值使得函数L(θ)取到最大值,则称
的观测值使得函数L(θ)取到最大值,则称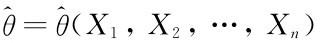 为参数θ的极大似然估计量,并称这种求估计量的方法为极大似然估计法.相应的
为参数θ的极大似然估计量,并称这种求估计量的方法为极大似然估计法.相应的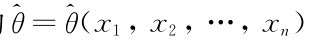 称为参数θ的极大似然估计值.
称为参数θ的极大似然估计值.
求极大似然估计量的具体做法:
在很多情况下,p(x;θ)关于θ可微,因此据似然函数的特点,常把它变为如下形式: 该式称为对数似然函数.由高等数学知:L(θ)与ln L(θ)的最大值点相同,为计算方便,人们更习惯于从ln L(θ)出发寻找参数θ的极大似然估计.下面给出极大似然估计的计算步骤:
该式称为对数似然函数.由高等数学知:L(θ)与ln L(θ)的最大值点相同,为计算方便,人们更习惯于从ln L(θ)出发寻找参数θ的极大似然估计.下面给出极大似然估计的计算步骤:
(1)计算极大似然函数:
(2)取对数
(3)写出对数似然方程组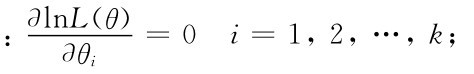
(4)解得θi的极大似然估计值 相应的极大似然估计量为
相应的极大似然估计量为 =
=
注7.1.1 若p(x;θ)关于θ不可微时,需另寻他法.
例7.1.5 设X1,X2,…,Xn为总体X服从B(1,p)的一个样本,(x1,x2,…,xn)为相应的样本观测值,求参数p的极大似然估计.
解 因为总体X的分布律为:
P{X=x}=px(1-p)1-x,x=0,1
故似然函数为
取对数,有
令
解得p的最大似然估计值为 所以p的最大似然估计量为:
所以p的最大似然估计量为: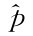 =
=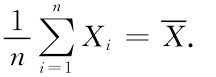
例7.1.6 设X1,X2,…,Xn为总体X服从参数为θ的指数分布的一个样本,其观测值为x1,x2,…,xn,求θ的最大似然估计.
解 由于X的概率密度函数为
故似然函数为
取对数,得
令
解得参数θ的最大似然估计值为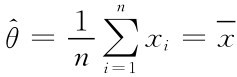 ;最大似然估计量为
;最大似然估计量为
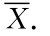
例7.1.7 设X1,X2,…,Xn为来自总体X~N(μ,σ2)的一个样本,参数μ和σ2均未知,x1,x2,…,xn为相应的样本观测值,求μ和σ2的极大似然估计值及相应的估计量.
解 由于X的概率密度函数为
故似然函数为
取对数,得
分别对μ和σ2求偏导数并令其为0,得
解得μ和σ2的极大似然估计值分别为
相应的μ和σ2的极大似然估计量分别为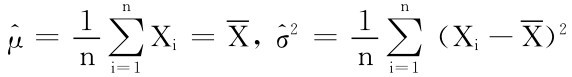 = =
= =
例7.1.8 设X~U[a,b]a,b未知,(x1,x2,…,xn)是一个样本值,求a,b的极大似然估计.
解 由于 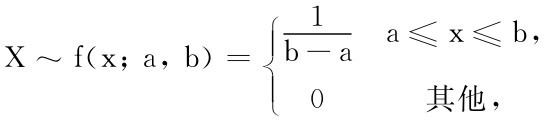
故似然函数为
通过分析可知,用解似然方程极大值的方法求极大似然估计很难求解(因为无极值点),所以可用直接观察法:
记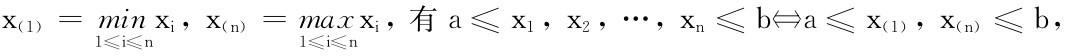 1≤i≤n1≤i≤n
1≤i≤n1≤i≤n
则对于满足条件:a≤x(1),x(n)≤b的任意a,b有
即L(a,b)在a=x(1),b=x(n)时取得最大值Lmax(a,b)=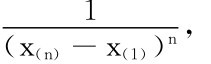
故参数a,b的极大似然估计值为
相应的参数a,b的极大似然估计量为
例如,在例7.1.7中得到σ2的极大似然估计量为 则据上述性质有:标准差σ的极大似然估计为
则据上述性质有:标准差σ的极大似然估计为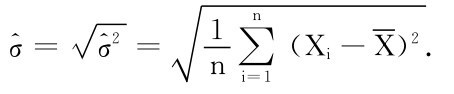
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










