



第一节 无形资产统计资料的整理和描述
一、统计数据的汇总
统计资料的汇总就是将调查单位归入相应的组内,然后将调查单位的有关标志值汇总,最后得到有关统计指标的工作过程。汇总的方法主要有手工汇总和电子计算机汇总。手工汇总包括划记法、过录法和折叠法。电子计算机的汇总需要编程序、编码、数据录入、逻辑检查和制表打印。
二、统计分组
统计分组就是将得到的统计资料按一定标志分类,划分为互斥的几个部分的过程。为什么要分组呢?因为我们搜集到的资料有的凌乱不堪,根本无法找出总体的特征;也有的即使有分组,可能与我们的研究目的不同,无法使用。
统计分组最重要的问题是选择标志。标志是总体单位的属性或性质,比如企业的所有制和无形资产数量,前者为品质标志,后者为数量标志。选择标志主要看你的研究目的,研究目的不同标志也不相同。比如你要研究国有企业与三资企业无形资产的比较,你要选择所有制标志;你若研究无形资产数量与企业规模的关系,就要选择数量标志。特别地,你要研究无形资产的多少与企业资产质量关系的时候,数量标志的选择是必须慎重的。就像60分及格线一样,它表明经营的好坏。
统计分组的原则是互斥和包容,互斥就是将统计资料只能归入某一组,而不能在两个组中出现同一个资料;包容是指统计资料必须归入某一组,而不能有剩下的资料不知归入哪一组。解决包容问题就是在分组时加上其他、某某以下或以上。
统计分组要解决的问题有:将统计总体分为不同的类别;研究内部各部分之间的关系;研究总体的分布和变量之间的关系。
统计分组按标志可以分为品质标志分组和数量标志分组;而数量标志分组又包括单项式分组和组距式分组。
统计总体特征描述主要包括次数分布与位置特征和离散特征两项内容。
(1)次数分布。次数也叫频数,次数是落在各组内的数据个数。由于每个数据是每个总体单位的表现,也可以称次数是落在各组内的总体单位个数。按照互斥和包容原则分组的总体单位,必定落在某一个组内。将各组的名称和次数排列起来,就是次数分布。
利用次数分布,可以看出总体单位集中在哪个组或哪些组,我们就能知道总体单位的状况、位置等。进一步,还可以利用次数分布计算频率(比重),这样就能将次数分布标准化,更加准确地给出总体单位的信息。频率的计算是个组的频数除以总频数,如表6.1和表6.2所示。
表6.1 某市2004年拥有无形资产的大企业分布
表6.2 某市2004年拥有无形资产的大企业分布
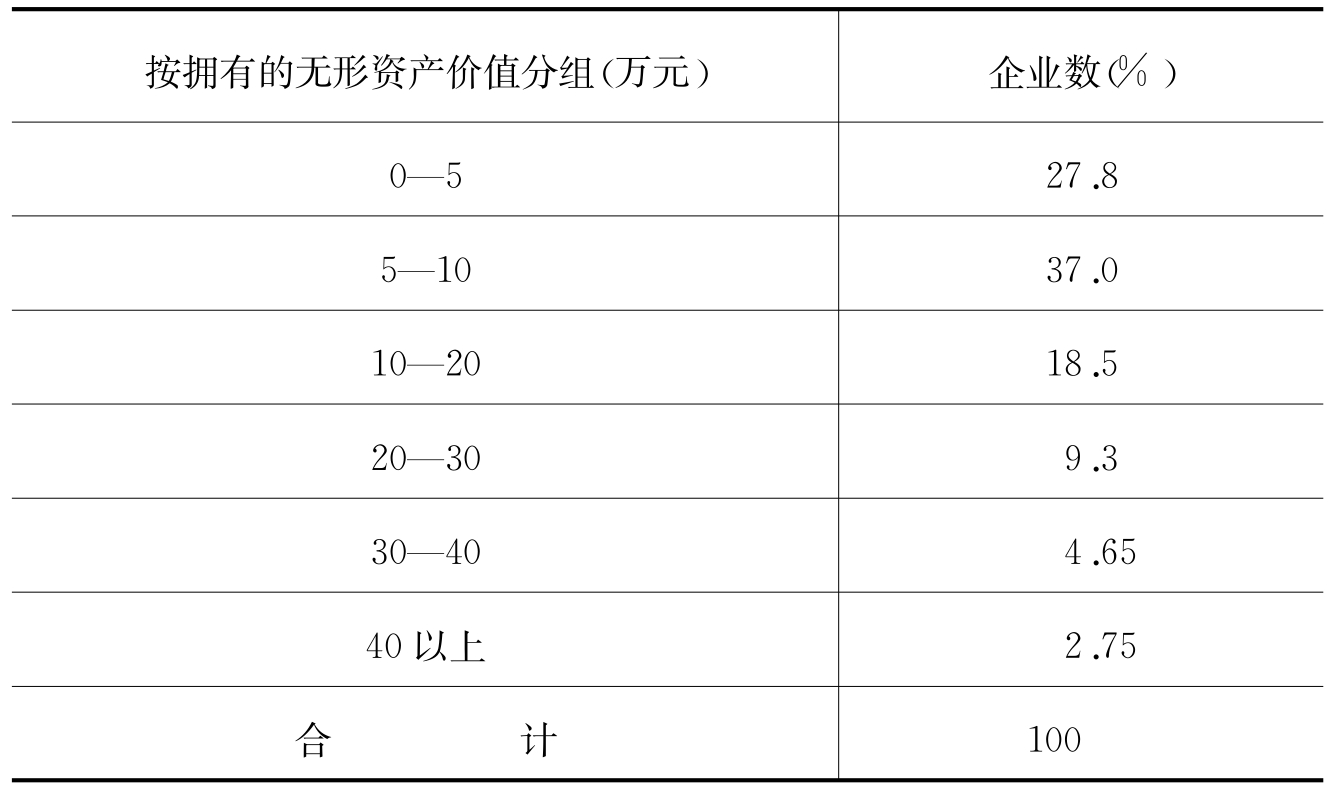
从以上次数分布看出,某市2004年拥有无形资产的大企业数以5万—10万元为最多,0—5万元次之,说明该市大企业拥有无形资产的价值不高。在频率分布表中,这种情况看得更清楚,在该市108个大企业中,拥有5万—10万元无形资产的占37%,0—5万元的大企业占27.8%,两者相加我们可以得出这样的结论,64.8%的大企业拥有的无形资产在0—10万元之间。企业不注重无形资产培育的情况十分清楚地展现在面前。
除了用表格反映统计总体的特征外,我们还可以用图来更加直观地反映这些特征。统计图就是将表格中的数字用各种图的形式反映统计总体的特征。统计图有条形图、柱形图、直方图、饼形图、环形图等。
(2)位置特征和离散特征。仅仅计算统计总体的次数或频率,只是对统计总体的简单和粗糙的描述,对统计总体的精确描述要计算众数、中位数、平均数、方差等。前三个被称为位置特征数,因为它们描述了数据的位置或总体水平;方差描述的是数据的离中趋势,所以被称为离散特征数。
众数是专门针对定类数据比如男女分类的变量开发的,它指的是各组中频数最多的那一组的变量值。中位数是针对定序数据如一级、二级、等外品这样的变量开发的,它是指将数据按从小到大排列处于中间位置的变量值。平均数是对可以用数量表示的变量进行平均。平均数的平均有算术平均、加权平均和几何平均。算术平均是针对为分组的资料,将各个总体单位的数值加起来,然后除以数据的个数;加权平均是针对分组资料,将各个组的代表值乘以所对应的频数然后相加,将加总值除以总频数。
如果我们计算出了位置特征数,我们就可以知道总体的水平,可以与其他总体进行比较。比如,如果我们知道了我国2004年每个国有企业注册的商标为10件,而三资企业为15件,我们就可以判断三资企业比国有企业更注重无形资产的培养。根据2005年美国《商业周刊》评出的世界著名100名品牌中中国无一上榜,而“可口可乐”继续以675.25亿美元的品牌价值继续蝉联冠军,而同时最后一名的品牌价值也比2001年第一届的门槛提高了10多亿美元。此次上榜的企业中,“可口可乐”、“微软”、“IBM”、“GE”和“英特尔”名列前5位,而这5个品牌的总价值超过了2660亿美元。此外,2005年全球品牌100强中共有52个美国品牌,比2004年减少了6个,上榜的德国品牌有9个,法国为7个,日本为6个,而韩国的“三星”和“LG”两大品牌也榜上有名。这可以说明我国企业的差距是很大的。
方差是各个观察值与均值的离差平方加总后的平均值。计算方差的目的是看一下各个观察值离均值的位置远近有多少。如值大说明离开均值的距离远,其代表性差。方差的主要用处还是比较不同总体的情况。比如,如果中国和印度的每个企业商标平均价值都是30万美元,则必须比较方差才能看出两国的差距。如中国的方差为5万美元,印度为6万美元,则中国的企业商标水平好于印度。
三、因素分析
因素分析就是先找出影响某个变量的各个因素,然后利用连环替代法找出其影响的数值。因素分析要求影响某个变量的各个因素之间的关系是相乘关系,各个因素的排列是有一定规则的,一般是数量因素在前,质量因素在后。因为在统计中是先有数量指标,质量指标是根据数量指标计算的。连环替代是假定这些因素中的其他因素不变,一个因素的变动对某变量的影响。这类似于物理实验中方法。经济学中,在分析某个因素对某变量的影响时都是假定其他因素不变。这样才能将一个因素的影响从其他因素中分离出来。
比如,一个企业的无形资产大小受到数量和价格的影响。如果我们知道无形资产的数量去年为10件,每件价格为3万元,今年为15件,每件价格为5万元,去年的无形资产价值为30万元,今年达到75万元。那么,今年无形资产的价值比去年多了45万元。在这45万元的增加值中到底是价格和数量谁的影响大呢?
四、回归分析
回归分析就是根据经济理论设立模型,然后利用最小平方法、极大似然法等估计出模型的参数。这样就得到了一个回归方程,在对方程进行各种检验后,如果各项检验获得通过,就可以利用得到的回归方程进行预测和分析。
一般设定方程的形式是线性的,形如Y=a0+a1X1+u,这里的Y称作被解释变量,X1称作解释变量,a0为常数项,a1为系数。a0、a1都是参数,也就是我们要用最小平方法等估计;u成为随机扰动项,它代表所有其他未被标示的变量的影响。方程可以是非线性的,也可以有一个、多个解释变量。
方程的参数被估计出来后,我们要对它进行显著性检验,即在给定的显著水平下参数在统计上是否显著,显著的意思就是接受对这个参数的等于零的假设,或样本和总体参数值不是真正的差异。一般显著性检验就是标准误差检验或采用t检验,一般t检验的值大于2就视为通过检验。
另外几个检验包括拟合优度检验、F检验和自相关检验。拟合优度检验就是要看被解释变量在多大程度上为解释变量所解释。拟合优度的值一般介于0和1之间,若大于0.5即可。而F检验是要检验方程本身是否显著。给定显著水平,查表后的临界值与得到的F值比较,若F值小于临界值,则认为方程是显著的;否则认为方程不显著,也就是方程不能用作分析。自相关检验又称杜宾—沃特森检验,简称DW检验。一般DW值约等于2即认为没有自相关,可以用作分析。
注意,只有上述检验都通过方程才可用于分析。否则,必须对模型进行调整和重新计算,直到所有检验通过为止。方程参数的估计和各种检验都可以利用统计软件计算,常用的统计软件有EXCEL、SPSS、EVIEWS和SAS等。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









