



4.3 基于可拓学与模糊理论的综合集成评价方法
极端降雨诱发山地公路地质灾害的危险性评价是一项复杂的系统工程。对于山地公路沿线地质灾害而言,其影响因素繁多,诸因素对其危险性的影响具有模糊性、层次性和影响程度的差异性[107—110],且作为诱发因子的极端降雨等条件又具有一定的动态性,因此,理想的危险性评价方法必须反映这些特点。由于模糊数学是研究和处理模糊性现象的一种数学理论和方法[111],因此,基于模糊综合评判的非确定性分析方法用于地质灾害的危险性评价在理论上是可行的。
模糊综合评判是地质灾害危险性评价的一种基本方法,鉴于该方法运用过程中权重的确定主观性太强,致使评价结果的可信度下降,本书通过运用可拓学中基本关联度函数对传统权重系统的求解过程做了改进,使得评价指标体系中各单因素权重分配更符合实际情况,最终提出了基于模糊理论与可拓学理论的综合集成评价方法。该方法在深入分析各种影响因素的基础上,通过建立模糊综合评判指标体系、划分危险性等级、运用多级模糊综合评判模型进行危险性评价。
4.3.1 模糊综合评判的数学模型
对于山地公路地质灾害危险性评价的复杂系统,其评价指标体系由富有层次性的众多指标构成,上层指标的取值由下层更多的指标决定。因此,采用模糊数学的理论解决该问题时必须进行多级模糊综合评判。下面给出解决该问题的三级模糊综合评判数学模型的构建步骤,其他多级模型构建方法类同。
第一步:因素集的层次划分
设因素集U ={u1,u2,…,un},其中,ui(i =1,2,…,n)代表评价系统第一层指标;对其子因素ui做进一步划分,使Ui={ui1,ui2,…,uim},其中,uij(i =1,2,…,n;j=1,2,…,m)代表评价系统第二层指标;再对uij做进一步划分得第三层指标Uij={uij1,uij2,…,uijk}。
第二步:建立评价结果集
综合前人的研究成果,并结合工程实际,把降雨诱发公路地质灾害危险性评价等级划分为5个等级,则评价结果集可表述为:
V={v1,v2,…,v5}
v1~v5依次代表危险性等级为极高度危险、高度危险、中度危险、轻度危险和极轻度危险。
第三步:建立权重集
为描述各子指标之间对各层指标的重要程度,及评价过程中所起贡献的大小,需引入“权重”概念。设各层指标权重分别表示为A、Ai、Aij,令A=(a1,a2,…,an)为归一化的权向量,其他两层指标类似处理。
第四步:三级模糊综合评判
对第i个指标的单因素模糊评判为评价集V上的模糊子集:
Ri= (ri1,ri2,…,ri5)
于是得到单因素评价矩阵
R = [rij]i = 1,2,…,n;j = 1,2,…,5
则对相应评判对象的模糊综合评判B是V上的模糊子集:
B = A° R
“ ° ”作为模糊关系合成运算,一般可选用5种模型,分别为:M(∧,∨)、M(· ,∨)、M(∧,⊕)、M(· ,⊕)、M(· ,+)。这5种模型运算的定义不同,所以对同一评价对象求出的评价结果也会不一样。其中模型Ⅰ~Ⅳ都是在具有某种限制和取极限值的情况下寻求各自的评价结果的。因此,会不同程度丢失某些有用信息。这种模型适用于仅关心评价对象极限值和突出其主要因素的场合。模型Ⅴ考虑了所有因素的影响,而且保留了单因素评价的全部信息,除必须对权值进行归一化处理外,运算中对权值和隶属度无上限限制,故本书选用该模型。

多级模糊综合评判是对多层次指标体系自下而上进行单因素综合评判的组合过程,即:按照最大隶属度原则,若rk=maxB=max[r1,r2,…,rm],则评价等级为k。
4.3.2 指标权重确定的可拓学方法
在多指标危险性等级系统评价中如何合理分配各因素的权重一直是广大研究人员努力探讨的问题。公路地质灾害危险性评价是涉及多因素多指标的综合性评价问题,并且评价结果的好坏直接关系到公路的安全程度与整个社会的经济效益及社会效益,所以,如何正确、合理地对因素的权重值进行分配显得异常重要。
目前,有不少文献[112—128]对如何确定权重进行了研究,也发展了多种常用的确定权重的方法,如:专家打分法、德尔菲法等,上述几种方法对权重涵义的理解不够透彻,这些方法只考虑评价指标物理意义的不同,而没有考虑到指标具体数值的变化对指标权重的影响,这样势必会导致权重确定的不当,更为重要的是将会对工程评价及相关决策产生不良后果。在此,本节试图对上述问题进行一些分析探讨,目的在于通过判断矩阵构造过程的改进来避免过多人为因素的干扰,为更加合理地分配权重提供依据。
1)权重涵义的进一步探讨
按照常规思路对多因素复杂系统进行评价时,评价指标体系确定之后首先要做的工作就是对各因素指标进行权重分配,以便确定各因素对评价指标系统的重要程度,界定各指标对系统功能的影响。在定量化评价的过程中,权重实为对评价系统不同侧面重要程度的定量分配。
根据上述权重的基本涵义,我们可以进一步用数学语言表达权重。对于一个评价系统,设有n个评价因素,wi为某一因素的权重值,那么wi具有如下特点:
①wi是各因素相对重要程度的定量化表达;
②0<wi<1,i= 1,2,…,n;
③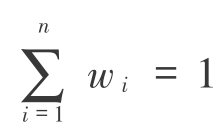 。
。
显然,权重具有一定的随机性、模糊性和相对性等特点,不同的指标对系统的影响程度不同,同一指标取值发生变化时他对系统的影响同样发生了变化,因此必须对各指标分配不同的权重。例如:边坡稳定性评价是一个多因素多指标的复杂系统的评判问题,假设我们用岩体质量、黏聚力、内摩擦角、坡高、岩体结构、降雨这6个评价指标对其进行评价,上述6个指标并非完全独立、互不相关,而是在一定程度上相互影响。进一步思考后我们可以发现,如果某边坡岩体的水饱和状态发生了变化,那么岩土体的强度以及结构面的抗剪强度必定显著降低,由此边坡岩土体发生破坏的可能性增大。由此可见降雨量指标取值的变化使其对边坡稳定性的贡献发生了变化,且引起了其他指标重要程度发生变化。
基于上述讨论,本书认为权重的确定至少取决于两个方面的因素:一是指标的基本特征,即指标不同则权重各异;二是指标取值的大小,即同一指标取值变化则权重亦要变化。
2)基于关联度确定指标相对重要程度
指标权重的分配问题一般采用层次分析法解决,过程中最重要的一步是判断矩阵的构造。这一步骤往往是通过德尔菲法进行操作,专家的经验决定了判断矩阵构造的优劣;同时,这种方法在指标重要程度比较方面只侧重于各指标的基本特征,当指标取值发生变化时其相对重要程度不变。显然,德尔菲法确定权重只满足权重涵义讨论结果中的“指标不同则权重各异”,未能满足“同一指标取值变化则权重亦要变化”这一事实,由此所构造的判断矩阵必然不能反映实际情况,最终导出的权重分配结果也就失去了意义。
针对山地公路地质灾害危险性评价的具体问题,我们同时考虑两个方面的因素来确定指标权重系统,以便更加准确地反映实际问题。本书中笔者把山地公路地质灾害的危险性等级划分为极高度危险、高度危险、中度危险、低度危险、极低度危险5个等级,根据本章第二节中的分类标准可知每个指标对于其中任何一个等级都有相应的区间范围,若某一指标关联的危险性等级越大,则说明该指标对公路地质灾害危险性的影响越不利,即对危险性的影响程度越大。
可拓学理论中的初等关联函数[129—132]可以用于评价某个数值相对于某个区间的关联程度,通过对关联度大小的判断可以很清晰地给出某指标对相应评价等级的关联情况,从而给出评价指标间的相对重要程度排序。
3)可拓学理论的关联函数
可拓学是基于解决现实中的矛盾问题而发展起来的一门学科,可拓学早期称为物元分析,随着研究的深入,逐步发展为可拓学,包括可拓论、可拓方法和可拓工程[131]。从可拓学创立到现在短短二十多年间,可拓理论已经广泛应用于各种实践工程项目中,其中的关联函数概念为地质灾害危险性评价问题提供了基础条件。
可拓理论中的关联函数类似于经典数学中的特征函数和模糊数学中的隶属函数,前者用于刻划可拓集合,后两者分别用于确定经典集合和模糊集合。关联函数的取值范围是整个实数轴,其中,K(u)≥0表示u属于可拓集合A的程度,K(u)≤0表示u不属于可拓集合A的程度,K(u) = 0表示u既属于可拓集合A又不属于可拓集合A。下面分别给出可拓集合正域为有限区间和无限区间的关联函数:
正域为有限区间<a,b>
设区间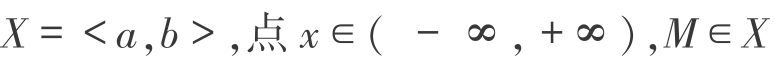 若
若 ,则此时关联函数定为:
,则此时关联函数定为:

正域为无限区间<a,+∞>
设区间X=<a,+∞>,点x∈( -∞,+∞),M∈X,若 1,则此时关联函数定为:
1,则此时关联函数定为:

若K(x)在X=<a,+∞>没有最大值,取:
K(x) =x -a
为说明解决问题的具体方法,下文给出基于简单关联度的指标重要程度判断的具体步骤:
①获取待评价对象各指标的取值,按照各评价等级可拓集合区间的类别(有限区间或无限区间),选取不同的关联度计算公式计算关联度;
②根据各指标对不同等级的关联度进行排序,关联度越大则关联性越强;
③进一步按照关联度大小构造判断矩阵,确定权重。
通过引入可拓理论中的关联度可判断由于指标不同及指标取值大小而带来的对评价系统贡献程度的差异性,从而给出各指标的相对重要性排序,很大程度上避免了全凭专家经验来确定指标重要程度的不足,有助于更加准确的确定评价指标体系的权重系统。
4)改进AHP法确定指标权重
(1)层次分析法基本思路及原理
层次分析法(analytic hirerarchy process,简称AHP)是美国运筹学家撒汀(T.L.Saaty)等人于20世纪70年代提出的对复杂问题作出决策的一种简明有效的新方法。随着科学技术的发展,对以前在社会、经济、生物、心理、工程、组织管理等领域只能定性描述的因素、事物和概念等,现在迫切需要作定量化的研究,层次分析法把定性分析与定量分析相结合,在一定程度上满足了这种需要[133,134,135]。
根据问题的总目标和决策方案,传统的层次分析法把问题划分为三个层次:目标层G、准则层C和方案层P(图4.2)。然后应用两两比较的方法确定决策方案的重要性,即得到决策方案P1,P2,…,Pn相对于目标层G重要性,从而获得比较满意的决策[136]。上述决策是一种自上而下的组合过程,而权重的分配问题不同于该过程,所以需要改进后使用该方法。

图4.2 传统层次分析法层次结构图
(2)改进的层次分析法步骤解析
改进后用于确定权重系统的层次分析法可分4个步骤。
第一步:明确问题,建立复杂系统评价的指标体系。
首先要对问题有明确的认识,弄清问题范围、所包含的因素及其相互关系、解决问题的目的等,然后分析系统中各因素之间的关系,分层次建立评价指标体系。
第二步:构造判断矩阵。
设同一层次待比较元素构成行向量U={u1,u2,…,un},对任意ui、uj重要程度进行比较,用rij表示ui对uj“重要程度”的判断值,则构成判断矩阵M=(rij)n×n。显然,矩阵M是正互反矩阵。判断值的确定方法如表4.5所示。
表4.5 指标重要程度判断取值表[137]

第三步:层次单排序及一致性检验。
判断矩阵M构造完成之后,可求其最大(绝对值)特征值λmax,即满足式(4.1)的最大λ值。

将求取的最大特征根λmax带入齐次方程组式(4.2)解出x1,x2,…,xn,于是得到最大特征根λmax对应的特征向量w={x1,x2,…,xn}。

对w ={x1,x2,…,xn}归一化处理后即为同一层次的各因素相对于上一层级某因素的权重。这一过程称为层次单排序。
在构造判断矩阵进行两两对比判断时,由于客观事物的复杂性,所以即便是经验丰富的专家也难免会带有主观性和片面性。因此,在构造判断矩阵M之后,还必须进行一致性检验。因判断矩阵M=(rij)n×n具有正互反性,所以可用一致性指标C衡量其不一致程度:
![]()
当C = 0时,判断矩阵式是完全一致的,C的值越大,判断矩阵不一致程度越高。根据专家经验构造的判断矩阵往往具有一定程度的不一致性,为保证层次分析法仍然可以使用,我们引入随机一致性指标:
![]()
其中: 为多个n阶随机互反矩阵最大特征值的平均值,当随机一致性比例
为多个n阶随机互反矩阵最大特征值的平均值,当随机一致性比例
 时,R的不一致性仍可接受,否则必须调整判断矩阵。随机一致性指标R的取值采用表4.6所示的撒丁统计结果[137]。
时,R的不一致性仍可接受,否则必须调整判断矩阵。随机一致性指标R的取值采用表4.6所示的撒丁统计结果[137]。
表4.6 随机一致性指标的取值表

注:任意一阶、二阶正互反矩阵式完全一致的。
第四步:层次总排序及其组合一致性检验。
计算最底层各指标对于顶层指标的权重,称为层次总排序。传统层次分析法由最高层到最底层逐层测算方案层的重要程度。为实现权重分配的目的,我们需计算最底层元素对最高层目标的权重,因此,该权重系统的确定要改为自下而上进行。设某一层A包含m个因素A1,A2,…,Am,它们关于上一层中某一因素G的权重为a1,a2,…,am,其下一层B包含n个因素Bi1,Bi2,…,Bin,它们关于Ai的权重为bi1,bi2,…,bim,那么B1,B2,…,Bn关于G的权重为可记为W= wi1×n,其中:
![]()
因层次单排序后的判断矩阵具有一致性,因此,改进后的层次总排序无需进行一致性检验。
(3)进一步改进判断矩阵的构造方法
构造具有满意一致性的判断矩阵是进行多因素层次分析的前提,传统的层次分析法以1~9标度法确定判断矩阵,该标度法有缺点:不满足一致性或精度不够,本书对其进行了改进,用e0/5~e8/5指数标度法替换,有效地解决了该缺点。假设某上层指标A由底层{B1,B2,B3,B4} 4个指标控制,下面以底层指标权重的确定为例进行改进前后的对比。
经课题组专家讨论后认为:B2比B1稍小重要;B3比B2稍微重要、比B1比较重要;B4比B1十分重要、比B3稍小重要。按照上述模糊语言分别用两种标度法建立判断矩阵进行比较,结果列于表4.7。
表4.7 两种标度计算结果对比
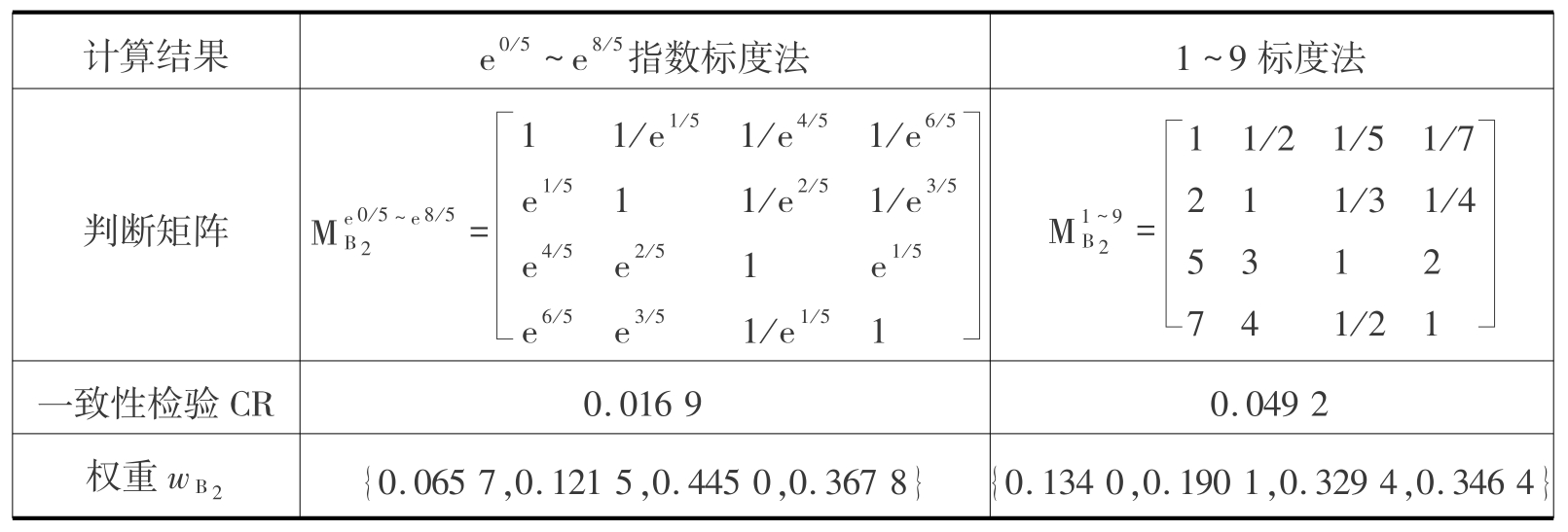
由表4.7可知:同种模糊语言的情况下,e0/ 5~e8/5指数标度法和1~9标度法相比,前者所构造的判断矩阵在一致性程度上远高于后者,由此计算的权重存在很大区别。根据数理统计的知识可以确定,e0/5~e8/5指数标度法用于判断矩阵的构造更加合理。
4.3.3 指标隶属度的测算
指标隶属度的测算是模糊综合评判中单因素评判的关键环节之一。在本书构建的评价指标体系中,各指标按数学分类划分,可分为离散型(定性)指标和连续型(定量)指标。离散型指标地层岩性、斜坡体结构等,其余为连续型指标。对于离散型指标一般采用经验赋值的方法确定隶属度;对于连续型指标则可根据指标特性通过构造隶属函数的方法测算隶属度。本书参考国内外研究成果[13-16],结合降雨诱发公路滑坡灾害的特点,给出“梯形”隶属函数,第i个指标对危险性等级Ⅰ~Ⅴ的隶属度计算公式如下:

式中,a0,a1,a2,a3,a4,a5表示等级标准中区间划分界限,某一等级标准值域的界限值。隶属函数曲线图如图4.3所示。

图4.3 隶属函数曲线图
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










