



在每一个地方,令脚踏实地的人感到烦恼的,是不断在他面前涌现的、他无法控制的大量的事情和事件。为此,所需要做的工作是对此从总体上予以把握。
T·麦茨(Theodore Merz)
桥牌中有一个非常好的战术:当手中的牌力不够强时,就从最弱的一门花色开始出牌。我们在这里所要讨论的是,对于科学之“手”,这一战术也能发挥很好的作用。当社会科学家们认识到他们手中没有把握什么王牌时,他们意识到,如果利用这一战术,也能取得惊人的成就。
数学家、物理学家们取得成功的方法,可以简要地描述成是先验的(a priori)和演绎的。通过对一种现象各种可能有用的知识进行仔细的思考,他们得到了作为公理的、具有广泛用途的基本原理。然后,用演绎推理导出新的结论、获得新的知识。在这种“安乐椅”式的方法中,观察和实验可能有助于得到最初的原理,或者检验通过演绎得出的结论是否正确,但是真正起作用的因素却是思想而不是感觉。
总的来说,先验的和演绎的方法,由于某些非常重要的原因,对社会科学家是无用的。也许主要的原因是因为他们所研究的现象非常复杂。甚至在相当小的问题中牵涉到的因素也很多,以至于不可能挑出最主要的因素。例如,对于一个时期国家的繁荣程度,我们将如何考察呢?这样的问题,取决于自然资源、劳动力供给、可利用的资本、外贸、战争与和平、心理情绪和其他因素。因此,没有一个因素处于这个问题的核心位置。这种状况丝毫也不令人惊奇。如果一位经济学家试图通过假设某些相关的因素来简化这个问题,那么,他很可能会使得这个问题变得不真实,并且不久就与实际情形相去十万八千里了。
在许多情形中,先验的和演绎的方法是不可能的,因为实际上就没有对此行得通的知识。有些治疗疾病的处方不能够事先开出来,因为我们对这些疾病的起因一无所知,而且传播疾病的许多因素我们也了解得甚少。对于生物学家来说,整个人体的化学构造和脑的功能还是一个很大的谜。对此,按自然法则遗传的机械论几乎是一本未开封的书。在这些领域里,分析的方法几乎还没有开始,也无从开始。
在有些问题中,利用从公理出发的经典演绎方法也得不到基本定律,这则是由于所能得到的知识太多了,这似乎自相矛盾。气体由分子构成,按照大家熟知的万有引力,这些分子彼此相互吸引。除此之外,分子必须服从牛顿运动定律。如果在一给定体积内的气体只有两三个分子,那么就可以像科学家预测行星的行为一样,能够预测出气体的行为。但是,在标准状况下,一立方厘米的气体含有6×1023(即6后面接23个0)个分子。按照引力定律,每个分子都对所有其他分子产生影响。显然,我们不能把所有这些分子对其他分子的作用力之和加起来,从而来研究这一体积内气体的状况。因此,就需要有某些方法,允许将数量巨大的分子看作一个整体。
利用先验的和演绎的方法讨论社会问题之所以令人不满意,还有另一个原因,这是由19世纪的特点决定的。工业革命带来了大规模的工厂生产,从而使得都市人口激增。这些发展带来了一大批与人口增长相关的社会问题,在大规模的企业中,面临着失业、商品的大量生产、消费和保险等问题。在拥挤的地区,由于不卫生的居住条件,使得疾病频发。这些问题纷至沓来,全都压在科学工作者的肩上。问题来得非常快,即使他们能够利用先验的和演绎的方法解决这些问题,但是解决这些问题所需要的时间也许比所能节省的时间还要多。这种方法,即使哥白尼、开普勒、伽利略和牛顿这些天才都曾广泛地利用过,但是他们也花了百余年的时间才创立了运动定律和引力定律。因此希望在社会、医学等领域更快地取得成果是几乎不可能的。
由于这些原因,所以社会科学家利用先验的、演绎的方法是不适合的。看来,解决这些问题似乎必须要有新的方法。如果每个人都停止工作,来思考得到科学定律所需要的新方法,那么也永远不可能找到它。这种新方法必须能迅速产生结果,综合许多起作用的因素,并能够在那些完全缺乏研究的地方仍然有效,还要能处理影响一种现象的数百万个因素的效应,以及测量出那些本身不可测量的因素的作用。尽管有这些非同寻常的要求,但是为解决科学问题而创立的新方法,却仍然能满足所有这些要求。
新方法开始于对事件状态的分析。这里有一些社会科学家争论的问题,其中包括没有了解这些问题的内在本质,或者说即使了解了其内在本质,如在气体分子运动的情况下,但了解得很不充分,真正的目的却被略去了。因此,我们没有能被用于作好演绎方法基础的明确的基本原理。另一方面,当时的困难是,面临着大量的未经处理的、基本的事实,这些事实压得人们喘不过气来,使得人们愈发无知。
正是在这一点上,社会科学家们想起了桥牌中的战术。由于他们手中没有作为王牌的基本原理,所以他们决定从薄弱之处着手。他们宣称,如果我们无法知道落下的雨是如何对蔬菜产生作用的,那么我们就应该测量这一作用的结果;如果我们不知道接种疫苗为什么会防止死亡,那我们就应该将实际的结果列成表;如果我们不能彻底地了解复杂的国家繁荣状态,那么我们就应该列出一个适当的图表来描述其兴衰;如果我们不能理解植物、动物和人类的遗传机制,那么我们就应该重新培育这个种类,记录下它的子代再现的情况。让世界成为我们的实验室,让我们在这个实验室里收集、统计所发生的情况。
仅仅进行收集、统计并不是一种新思想,在《圣经》和较早的公文文件中也可找到统计的方法,它的新颖之处就在于,统计方法能够作为一个重要的方法来处理社会科学问题。这种方法第一次取得成功,得力于17世纪一位富有的英格兰服饰杂货商人J·格兰特(John Graunt)。作为消遣,格兰特研究过英国城市的死亡记录。他注意到,事故、自杀、各种疾病的死亡百分比固定不变。从表面上来看,这一情况似乎只是一种偶然的娱乐,但它却揭示了其中具有的惊人的规律性。格兰特也发现,男婴出生的比例超过女婴。在这个统计的基础之上,他得出了这样的结论:由于男人受到职业的危害和参加战争,因此适婚男人的数量大约等于女人的数量,所以一夫一妻制必定是婚姻的自然形式。
格兰特的工作得到了他的朋友W·佩蒂爵士(Sir William Petty)的支持和拥护,佩蒂是一位解剖学、音乐教授,后来成了军医。尽管佩蒂没有做过像格兰特那样引人注目的观察,但他还是值得引起特别注意,因为他的观点是深刻的。他坚持认为,社会科学必须像物理科学一样定量化。谈到他在医学、数学、政治学和经济学诸学科的著作时,他说:“我利用的方法是很不一般的;因为,我不是仅仅利用漂亮的辞藻、华而不实的结论,我采取的方法……是用数字、重量、测量来表示;仅仅利用感觉的论据,只考虑一些自然界可见的基本原因。”他给统计学这门刚起步的科学,命名为“政治算术”(Political Arithmetic),而且定义为“利用数字处理与政府相关问题的推理艺术”。事实上,他认为所有的政治经济学的全部内容如同是统计学的一个分支。
当这些头脑清醒、目光远大的英国人谈论统计学的潜力时,当一位17世纪的牧师利用统计的方法与迷信作斗争,得出月相(月亮的变化)影响健康的结论时,科学的新基础已经形成了。它的孕育期持续了大约100年。在这一时期内,得出的一般结论是,一个国家的定量材料应该受到重视;也就是说,政府官员应该思考数据。直到19世纪早期,继格兰特和佩蒂的工作之后,陆续有了一些成果,即在数据的基础上得出了一些定律。这个时期,一群有影响的人意识到,先验的和演绎的方法对社会科学是不可能有什么作用的,同时他们也意识到了统计学的潜力,并开始用它来解决一些重要的问题。
格兰特和佩蒂是这一思想的开创者。但是,为了得到纯金子,仅仅挖采矿石还远远不够,尽管这也是必需的。矿石必须经过筛选、过滤、提炼才能得到金子。同样的,统计学仅仅本身取得一点成就还不够,因为在一些非常简单的问题中,结论的确很容易从数据中得到。从大量的数据中得到精确的知识,这要靠数学才能完成。
从数据中得到整理过的知识,最简单的莫过于数学方法中的平均法。假设一些小的商业组织的雇员每周得到的薪金如下(以美元计):
20,30,40,50,50,50,60,70,80,90,100,1000,2000
每周每人的平均薪金是多少呢?通常,我们将所有这些薪金相加求出和,然后再除以领取薪水的人数。在这个例子中,和是3640,而领取薪水的人数为13。因此平均数是280。这种平均值称为算术平均值(arithmetic mean)。
很清楚,这种平均并没有太多的内容。没有一个人实际上挣得过这一数目的薪金。而且,13个中仅仅有两人挣得较多,其他人挣得的都较少。换句话说,如果一组数据中有些数与其他数相比大得多,那么算术平均就不是一个具有代表性的数字。在这种情况下,其他平均可能具有更多的内容。另一种经常利用的平均法,称为中位数(median)法,就是选取一组按顺序排列的数据中中间的那个数。在上面的例子中,有13个数据。因此中位数所代表的薪水是60,因为有6人挣得的薪水比该值少,6人挣得的则比该值大。
在这个例子中,中位数的确是一个更具有代表性的数字。但是,它也不能告诉我们全部的情况。如果在中位数以下6人的薪水比上述这个数字少得多,在中位数以上的6人的薪水又比这个数字大很多,而中位数仍将是不变的。这样12个人挣得的薪水却都不能在“60”这个中位数中反映出来。因此,中位数通常也不是一个具有代表性的数字。
众数(mode)是另一个经常利用的平均。在数据中出现次数最多的数字,就是该数据中的众数。在这个例子中,薪水的众数是50,因为挣得这个数字薪水的人最多。尽管这个平均值像其他平均数一样,给出了薪水分布的某些特征,但它依然不够完全。在众数上下分布的薪水,也没有在这个平均值中反映出来。
每一个平均值法都不能告诉我们在这个平均值上下数据的分布情况。平均法的确依赖所有的数据,但是却不能从中推断出其分布的性质。例如,如果最高的两份薪水,从1000和2000变化到100和2900,则相应的平均值依然相同,但是分布的性质却变化了。真正所需要的是测量在平均值附近的某种差量,即离差(dispersion)。为了这个目的,统计学家们使用了一种称为标准差(standard deviation)的量,用σ来表示。这个量的计算如下:首先,算出任何一个已知量与算术平均值两者之差,也就是已知量与平均值的差。为了避免负数,则取这个差的平方。然后,把所有这些差的平方加起来,再除以数据的个数,即取差的平方的平均值。对这个平均数开方,这样就与早先所实施的平方运算抵消了。简单地说,一组数据的标准差,就是每一单个数据与算术平均值之差的平方和的平均值的平方根。
我们可以利用上述一组薪水来说明标准差的计算。不过,为了避免复杂的算术计算,我们还是来利用一组简单的数字。计算数组
1,3,4,7,10,13,18
的标准差,这个数组的平均值(算术)是8。因此,平均差就是
7,5,4,1,2,5,10,
这些差的平方是
49,25,16,1,4,25,100,
这些平方的和是220。因此,这些平方和的平均值就是220除以7,即近似地为31.4。这一平均的平方根约为5.6。由于上述这一数组往后的数与平均值8相差较大,因此数组的离差(标准差)也较大。如果对薪水的那组数据作同样的运算,将得到标准差556。我们记得其平均值为280。我们再一次验证了这样的推论,即薪水的离差相对于平均值而言必定会大些。
当然,即使像平均值与标准差这样两个有代表性的数字,也没有数据本身说明问题。但是,由于我们的思维不能思考所有的数据,不能把握所有的数据,因此这些数字还是十分有帮助的。
记住所有收集到的数据,或者仅仅依靠刚才这样两个具有代表性的数字,都可以利用图形来代替。几乎每个人读报纸新闻,都会看到数据的图形表示,这种图形可以使那些不用此方法将令人难以把握的事实变得一目了然。生活费用和股票价格的升降图形,就是常见的例子。不过,展示数据的图形的方法,比这种单纯的升降示意法要产生出更深、更有意义的结论。
假定在某一个地区测量所有男人的身高。对应于每个高度,将有一个相应出现的频率(即具有同一高度的人的数目)。如果把所有男人的身高画成横坐标,而对应的频率作为纵坐标,那么将得到这些频率的分布图。实际数据的图形如图70所示,在这里,通过数据画出了一条光滑的曲线。这个图形所给出的曲线无疑地很容易记住,而且立刻显示出了包含在原始数据中的大量信息。

图70 某一地区男人的身高
关于身高分布,以及许多其他我们不久将要讨论的特征,其最突出的意义是,这条曲线接近数学家作为理想分布的正态频率曲线(图71)。事实上,一组身高包括的数目越大,则曲线就越接近理想形状,就如同正多边形的边数越多,就越接近圆一样。
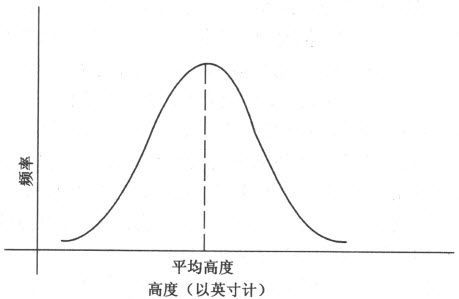
图71 正态频率曲线
正态频率曲线,或者说正态分布曲线,非常普通也极其重要,因此我们必须讨论一下它的主要特征。该曲线关于一条表示在所有数据中频率最大的垂线对称。当这条垂线沿曲线向左、向右时,曲线开始缓慢下落,随后变化得很快,最后,当它延伸直到最右边和最左边时,它就会趋近水平轴,但是不会相交于水平轴。这个曲线可以比喻成一口钟的形状,事实上,这条曲线也就被称为钟形曲线。
在任何正态分布中,对应于最大的纵坐标即最大频率的横坐标,必定是分布的众数,因为它是测量中出现次数最多的量。这个众数也是中位数,因为图形的对称性告诉我们,这个横坐标左、右两边出现的情形相同。非常明显,这个众数也是平均值,因为在众数两边的横坐标相等,远离众数的两边也有相同的频率,而且在平均值的计算中,所有与横坐标等距离的点对应的平均值将位于中间。因此,在正态分布中,众数、中位数、平均值恰好相同。
大约从1800年以来,天文学家、科学家对正态频率曲线已经很熟悉了,因为它经常出现在有关的测量中。假设一位科学家对导线的精确长度感兴趣。部分地因为手和眼睛不是非常地准确,部分地因为受周围条件例如温度的影响,因此他测量一个长度不是只测量一次而是要测量50次。这50次测量彼此都不同,这种差异有时感觉得到,有时感觉不到。各种测量值对50次中每一种测量值出现的次数的图形趋近正态频率曲线。事实上,测量得越多,则它们的频率分布就越接近这条正态频率曲线。
有充分的理由期望,仔细进行一组测量,将会出现一条正态曲线。测量中的误差应该归结为眼和手造成的随机误差以及所使用仪器的随机变化。这些误差本身应该分布在准确值的两边,而且紧紧地围绕着这个值,就如同一个步兵对准目标射击,如果他是神枪手,那么他所射出的子弹落在目标上的枪眼就应聚在一起,而且与中心的距离越来越小。
事实上,测量的正态曲线对科学家是非常有帮助的。在正态分布中,数据围绕着平均值,如刚才所谈到的那样,也就是趋近准确值。因此,大量测量的平均值,如果它们看来遵循正态曲线,那么就是实际测量的准确值的最佳逼近。而且,如果大规模的测量呈现非正态分布,那么就表明有一些附加的影响已经渗透到测量中去了,因此应该予以清除。例如,如果在一间温度不断增高的房子里,测量金属的长度,那么测量的结果无疑地将会持续不断的增加,而不会呈现正态分布。这些测量的平均值也将会出现许多误差,获得的图形将立刻会反映出这种附加的因素。
正态曲线曾被上千次运用于确定天文距离;用于测量质量、力和速度;用于确定物质的熔点、沸点、结冰点的温度以及其他上百种化学性质。由于它在清除测量中的错误时的作用,正态曲线也因此被人称为“误差曲线”。正是误差曲线的存在表明了一个看似悖论,然而却是真实的结论:测量中的误差(随机误差)并不是随意出现的,而总是表现为上述曲线。人类甚至也不是随意地犯错误!
在利用正态分布时,了解在任意给定的一个数量测量的范围内有多少种情况,这是十分重要的。例如,考虑100000个美国男人的不同身高。在一条正态曲线上,已经画出了各种身高的分布频率。假设这一分布中的平均值和标准差相应的是67英寸和2英寸。这样(图72)位于一个标准差即平均2英寸之内的理想身高的人占68.29%;也就是说,68.29%的男人身高在65~69英寸之间。除此之外,位于2个标准差即平均4英寸之内的身高的人占95.4%;位于3个标准差即平均为6英寸之内的身高的人占99.8%。位于任意给定的标准差与平均值范围内分布的百分比也能计算出和在表中找出。这样,如果研究正态分布的人计算出了平均值和标准差,那么从这两个量出发,就能得到所需要的关于分布的所有情况。
图72 正态频率分布中落在不同区域的百分比情况
大约在1833年,比利时天文学家、气象学家、统计学家L·A·J·凯特勒(Quételet),打算借助正态曲线来研究人的特征及能力的分布。附带说一下,他的大多数数据,取自文艺复兴时代的艺术家阿尔贝蒂、达·芬奇、吉贝尔蒂(Ghiberti)、丢勒、米开朗基罗以及其他人对人体各部位所作的上千次测量。凯特勒确立了自己的研究目标后,得到了数百名后继者的响应。人类几乎所有的精神和物理特征都呈现正态频率分布。任何肢体的尺寸、身高、头颅的大小、脑的重量、智力(通过智力测验测试)、眼睛对电磁光谱中可见光部分的每段频率的反应灵敏度——所有这些特征在一个“种族”或“民族”之内,人们发现总是呈正态分布。动物、蔬菜、矿物也同样如此。任何一种葡萄的大小和重量,任何一种硬币中麦穗的长度,等等,都呈正态分布。
与测量中的误差分布一样,人的特征和才能也呈正态分布,这个事实对凯特勒来说具有非常重大的意义。他坚持认为,所有的人,就像面包一样,是从同一个模型中制造出来的,不同之处仅仅在于,在创造过程中,发生了某些意外的变化。由于这个原因,因此误差规律也适用于人类。自然界想创造完美的人,但是失败了,因此在每一方面都产生了一些误差。另一方面,如果没有任何一类人符合我们测量出的特征——例如身高——那么,在有关数据的任何有限数量关系或图形中,我们就将找不出任何特殊的意义。
凯特勒越是进行测量,他注意到,个体的变化就越不突出。因此人类的主要特征的趋向也就是十分明显的了。每个这个特征的中间值,就等同于理想的或“平均的人”。而且,平均的人就是一个引力中心,整个社会都围绕他旋转。凯特勒然后断定,中心特征起源于最一般的原因,社会也就由此而存在并且受到了保护。进一步说,如同在物理现象中一样,在社会现象中也出现了清晰的设计和决定论的特征。
我们将把凯特勒哲学所引出的推论留到下一章进行讨论。现在,让我们还是只考察如何将正态曲线应用于社会和生理学的问题,从而导出一些知识和相关定律。的确,今天人们深信,任何物理的或精神方面的能力分布,都一定呈现正态分布状况。这种信念根深蒂固,以至于在对大量的人所进行的任何测试中,如果得不到这个结果,就会遭到怀疑。例如,如果对一组人进行一场新的考试,若没有得出呈正态分布的成绩,在这种情况下,关于智力分布的结论并不会受到人们的怀疑,而是人们会宣布这次考试失败了。
关于分布图形的研究,引出了一些十分有趣的结论和问题。我们看到,精神的和物质的特征呈现正态分布。但是,如果我们描绘收入的分布图形——也就是,各种各样的收入与具有这种收入的人的数目——这样的图形则看起来很可能如图73所示。这条曲线表明,大多数人都处于低收入的水平。事实上,研究表明,最普遍的收入即大众的收入,处于“狼点”(wolf-point)即处于仅仅维持生计的水平。曲线也表明,许多人所挣的只不过刚够维持生计,只有少数人挣得多。

图73 收入频率分布
收入频率分布图形立刻显示出,在收入水平上人类有极大的不同。这就使人们注意到,一方面是收入,另一方面是物质和精神方面的能力,人类在这两方面存在着惊人的差异。面对这种差异,社会上自然地就要求能给出一种解释,为什么收入的分布,与挣得这些收入的人的能力的分布,两者之间会有如此巨大的不同呢?
真正有价值的结论,不仅在个别问题上有用,而且在理论方面也有重要的意义,这样的结论明显地也能从数据或以数据为基础的图形中得到。但是,按现代标准来判断,任何科学研究的要旨都是数学公式。公式中的结论具有双重价值。不但公式本身是一个简单的、有价值的结果,而且它还允许利用所有代数、微积分和其他的数学方法来推导出新结论。这一点,通过参考前面的例子应该可以明白。万有引力的概念,本身就含有高度概括性的内容。但是,作为一个公式,它的作用也能够充分地显示出来,我们也可以将它与运动定律联系起来,从而推导出围绕太阳旋转的行星的轨迹。
将数据概括成言简意赅的公式——有时这是可能的——在这种情形中,过程与意义紧密相连。现在,我们来阐明用一个公式处理数据的过程。为了这样做,我们将考虑一个稍微特殊一些并经过简化了的问题。
假设要研究几年内食品价格的变化。我们知道,食品价格的高低,与其他商品的价格一样,是通过“指数”(index number)来计量的,“指数”大致是一个平均价格,其计算方法与我们这里的讨论无关。下面这个表列出了美国许多年内零售食品价格的指数(用y表示)。在表中,x代表自1900年以后的年份;也就是说x=1对应于1901年,等等。

仅仅观察还不能得出与x和y相关的公式。下一步是画出这些x和y值的对应点,用横坐标代表x值,纵坐标代表y值(图74)。画出的点似乎位于同一条直线上。事实上,线段通过点(3,75)和点(9,89),这两点的连线及其延长线非常靠近其他的点,不过其他的点也并不完全精确地位于这条直线上,所以,在确定考虑指数时,不可避免地会出现误差。至此,我们已经确定了,该函数的图形是一条直线。

图74 关于食品价格的数据图形
在坐标几何(即解析几何)中,求出这条直线的方程是一个简单的问题。得到的结果是公式

此处y是对应于任意给定年份x的指数。这个公式适合于那些在图74中靠近该直线的点所对应的数据。
获得这个公式是一个十分巨大的成就。没有任何关于食品价格上升和下落因素的知识,就得到了一条描述其过程的定律。这条定律无疑地适用于从1900年至1915年这段时期。而且,像其他科学定律一样,该公式能用于预测——在这种情况下,就是预测1915年以后某些时期内食品价格的变化。
还有更进一步的问题。这个公式给出的食品价格的变化规律,在所有时期都真实吗?当然不会!事实上,存在着一个基本的问题:是否食品价格会遵循任何不变的模式。无论如何,食品价格不会持续上升,因此充其量,上述公式不过是在一个短时期内,仅仅近似地能表示出真实的规律。这个公式之所以不能更具有代表性、规律性,部分地是因为它得以建立公式的数据太少,部分地也许是因为食品价格的指数不可靠。
食品价格高低这个特殊的问题,可能不会导出任何具有普遍意义的或基本的定律,但是,利用上面所描述的方法,却能够导出这样的规律,这些规律是存在的,也就是说,数据的确遵循着一种固定的模式。其方法是,对数据画出图形,然后再确定适合于图形的公式。可以预料,这些图形不一定碰巧会是直线,这样该过程可能要涉及某些复杂的数学知识。
从数据中得到一个更加具有意义的公式的例子——这个公式可以被称为真正的经济学定律——是由著名的政治经济学学者帕累托提出来的。帕累托通过对某个社会收入分布状况的研究,提出了一个公式:N=Axm,此处N代表收入等于和高于任意给定量x的人的数目,A,m是两个常数,它们由一个国家或地区的数据确定。帕累托也发现,m的值大致相同,在每一个地区测量得到的结果都近似地为-1.5。从一个国家到另一个国家,这个数字都相同,而且反复出现了帕累托所提出的情况。因此,其他许多经济学家都认为该公式具有深远意义。
帕累托本人认为,对经济结构不同但人口的自然分布相同的许多国家来说,存在着相同的收入分布定律。他利用自己提出的定律来反驳卡尔·马克思(Karl Marx)的观点。马克思认为,资本主义社会的趋势是越来越多的人的收入减少。帕累托还利用这条定律断言,国家不应该试图通过法律的形式来改变收入中的不合理状况。
现在,我们可以针对帕累托的收入研究,提出前面对食品价格情形相同的问题。存在一个普遍的收入分布定律吗?如果存在,帕累托的公式就代表着这一定律吗?有比在食品价格情形中更充分的理由相信,在收入情形中存在着这样的定律。我们可以坚信,在所有社会、所有时代,影响收入的主要因素将以大致相同的方式产生作用。至少,这种情况的可能性,与行星年复一年地遵循不变的轨道的可能性,在先验的基础上来说,一样有利,一样好。
实际上,帕累托的定律是否正确,经济学家们一直有争论。第一次提出这个定律是在1895年,从那以后,从许多国家选取数据进行过测试。在许多测试地区,如19世纪至20世纪早期在英国进行测试,数据与公式十分吻合。但是另一方面,在证明该公式的必要性方面却不怎么成功,因为数据的可靠性总是存在一些问题。
实际上,我们不能肯定从数据适合的公式中得到的定律都是正确的。制作了指数与时间的关系表后,我们选择了一条尽可能过更多的点、与其他点非常接近的直线(见图74)。如果我们改变这条直线,使得该直线的公式也可以从给定的数据中推导出来,那么将存在着不止一条直线,能够过那些点而趋近于其他的点。当然,在实际运用中,两条直线的差别可以忽略不计,但是,这对预先探明真相并非总是十分有利。
公式可能比上面讨论的精确度更小。在关于物价(指食品)指数的图中,图形中的点几乎全都位于一条直线上;然后,再假定图形是一真正的直线,如不符合就认为是收集数据中出现了误差。然而,真实的情况可能是,数据是准确的,这些点却并不位于一条直线上,而位于过所有这些点的一条曲线上。如果是这样,则我们所找出的公式肯定是不正确的,尽管也许这个公式与实际情形充分接近,或对实际情形有用处。
我们能够断定,在确定适合数据公式的过程中,慢慢地不会产生某些误差吗?我们真正所能做的全部工作,就是利用昨天和今天去指导明天。利用得到的公式进行预测,然后检查所作的预测与实际发生的情况。如果预测不正确,我们可以利用新数据与适合于一个公式的旧数据,从而使可利用的数据增多。尽管从这些数据中所作的预测,和建立在这类公式基础上所作的预测,还不具有确定性。但是,这个公式总结和代表了在大多数可描述的形式中的已知数据,这一点是确实无疑的。而且,适合于数据的某些公式已经被证明是可以经常应用的,它们似乎表示了自然界永恒的行为,如牛顿运动定律和万有引力定律一样,它们也发挥了极其重大的作用。这一事实的重要意义将在下一章进行讨论。
在某些统计研究中,不能再套用公式的概念,但是我们还是希望能从数据中获得某些知识。让我们来考察F·高尔顿爵士(Sir Francis Galton)研究过的一个问题。高尔顿是达尔文(Darwin)的表弟、优生学的奠基人。他研究的一个问题是:异常的身高是否有遗传性。他采用的方法其实质是这样的:选取1000名父亲,记录下他们的身高,然后记录下他们儿子的身高。一般来说,第一个变量的每一个值,将刚好产生第二个变量的一个值。例如,公式y=3x中,对每一个x的值,将出现一个y值。然而在这里,任意一位父亲的高度,相应的却有几个儿子的高度。因此,用公式来表示是毫无可能的。高尔顿所做的创造性工作之一,是在这一研究中引入“相关”(correlation)的思想。两个变量相关,是它们之间相互关系的一种度量。这个度量或数字,是通过把变量中的单个的值代入到一个特别的结构表达式中得到的。众所周知,相关系数取从-1到+1间的值。
相关数为1,表示一种正比关系;当一个变量上升或减少时,另一个变量也上升或减少;当一个变量较大时,另一个变量也较大。相关数为-1,则意味着一个变量与另一个变量存在着反比关系;当第一个值高时,第二个值在其范围内就低,反之亦然。相关数为0,则意味着一个变量的行为与另一个变量的行为无关;它们的变化彼此独立。相关数为 ,就是指一个变量的行为与另一个变量的行为类似,尽管它们不完全相同。
,就是指一个变量的行为与另一个变量的行为类似,尽管它们不完全相同。
高尔顿发现,父亲的身高和儿子的身高两者之间有一种确定的正相关。一般来说,高个父亲有高个儿子。高尔顿也发现,儿子与中等水平的偏差比父亲与中等水平的偏差要小——也就是说,父亲是高个儿,儿子一般也是高个儿,但儿子却不像父亲那样在同龄人中显得那样高,他们的身高将向中等身高退化。高尔顿在智力遗传的研究中,也得到了类似的结果:一般说来,天才是遗传的,但是,天才的孩子们却较他们的父母平庸,而一般智力水平的父亲,其孩子却极有可能是超群的天才(那些因为自己在智力上不特别突出而为孩子感到痛苦的父母,应该看看这个研究结果)。
像凯特勒一样,高尔顿为自己的研究所揭示的内容而激动不已。在发现他得到的关于身高和智力方面的结果能应用到人的许多其他特征方面之后,他得出结论:人的生理结构是稳定的,所有有机组织都趋于标准状态。
在高尔顿的研究中,最有价值的东西是相关的思想。这个思想能够立刻被证明是有用的。为了研究一个国家工业生产的水平,需要收集详细完整的数据。但是,如果工业生产与证券交易所的股票生意高度相关,后者的数据很容易弄到,因而能被用来反映工业生产的水平。如果一般智力与数学方面的能力高度相关,那么具有较高智力的人可以希望在数学上有所作为。若中学的成绩与大学成绩两者之间,或大学成绩与后来在生活中商业上的成就两者之间密切相关,则在预测许多人的未来发展方面,将能够发挥巨大作用。
在统计方法的应用中,存在着不少困难。它们并不是数学上的问题,而是需要人们作出谨慎的判断。其中一个困难是由术语的含义造成的。假设我们打算研究美国的失业。哪些人失业了呢?这个术语包括那些不必工作但是想工作的人吗?或者包括那些每周两天被雇用,但又希望所有的时间都工作的人吗?或者包括那些找不到比开计程车更好的工作的优秀工程师吗?或者包括那些不适于雇用的人吗?
统计结论的解释也充满了困难。统计表明死于癌症的人在逐年增加。这是否意味着现代生活更易于使人患癌症呢?不能这么说。50年前许多死于癌症的人,但由于医疗技术不够发达,因而没有能够查明死因。今天,人们的寿命比50年以前要长,而由于癌症主要是老年人的疾病,所以发生得就更频繁。许多年前死于肺结核的人,如果他们活得更长久一些的话,就可能患癌症。最后,今天的记录很完整。换句话说,癌症现在可能“杀死”的人比以前多,但我们不能推断说,现代生活更易造成癌症,或者说生活在今天的人们更易生病。
遗憾的是,统计方法应用中的这些困难,经常在辩论中被人忽略了,或者被那些广告商、宣传家为了“宣布”他们的结论而掩盖起来了。统计学的滥用,已经导致了不恰当的怀疑,败坏了统计学的名声。统计学家被描绘成试图在从模糊的假设到预料中必然的结论中划出一条精确界限的人。无疑地还有一种类似的讽刺:谎言、弥天大谎以及统计学。
统计学中的种种弊端,不应该使我们看不到它所发挥的作用。统计学在人口变化、股票市场运行、失业、工资、生活消费、出生与死亡率、酗酒与犯罪的关系、物理特征与智力分布,以及疾病发病率的研究中发挥着作用。统计学是人寿保险、社会安全系统、医疗保健、国家政治和许多繁杂事情的基础。即使是头脑精明的商人,也利用统计学方法来确定最好的商场,控制生产过程,检验广告效果,判断人们对新产品的兴趣程度。统计方法摒弃了随意性的猜测、吹毛求疵的个人判断,而用十分有用的结论取代了它们。
的确,说统计方法只是已经在许多问题上取得了成功,那是一种保守的说法。它们在使科学脱离臆测方面,在科学的落后领域中,起着决定性的作用。事实上,统计学已经在所有领域中成了一种处理问题和思考问题的方法。测试的思想,当今在西方文化的所有活动中流行开了。不久前,著名的W·奥斯勒(Dr. William Osler)宣称,当医生都学会了计算时,医学就成了一门科学。统计研究的重要性使得A·法朗士(Anatole France)说,实际上,不能计算的人才不愿计算。从“为政治家提供的数据”中得出数学结论,的确正在成为一种国际潮流。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










