



9.3 分类规则提取
对规则分类部分,本系统采用了粗糙集方法。很多研究都提出了基于粗糙集的属性约简和规则提取算法。在此规则辅助分类过程中,考虑到整体分类的时间复杂度及规则分类的辅助性地位,本书采取了以下方案:
对规则分类算法,本书采用已有研究成果的成熟算法[7],在前期统计训练的同时,生成各类别的规则集。在进行统计分类的同时,进行规则分类,获取统计分类结果的前三条最佳分类类别,与规则分类结果进行交集运算,其结果作为最终分类结果。若无规则匹配,则仍以统计分类首选结果为准。
常规的粗糙集规则分类都是基于全文的,其运算量都比较大。作为统计分类的补充,如果也基于全文进行,在整体效率上可能难以接受。我们知道,基于统计的自然语言处理中,经常会用到词共现模型[8]。它基于如下假设:若两个词经常共同出现(即共现)在文档的同一窗口单元中,则认为这两个词在意义上是相互关联的;并且,共现的概率越高,其相互关联的程度越高,可以用此方法来进行概念的反映。而这恰恰是传统VSM模型的不足之处。如果我们将每篇文献的标题作为窗口单元,对其词共现进行规则提取,则在一定程度上可以修正传统VSM的缺陷。基于这一原理,本系统进行了相关的算法设计。
其中规则提取分类的基本过程如下:
(1)在前期抽词及统计时,加入标题关键词的共现处理,即单独提取出在标题中共现的关键词集作为标题特征项,并将此特征项的权值进行离散化处理。
(2)构造决策表,以关键词向量集作为决策表的条件属性集,文本所属的类别集作为决策属性集,如表9-4所示。
表9-4 决策信息表
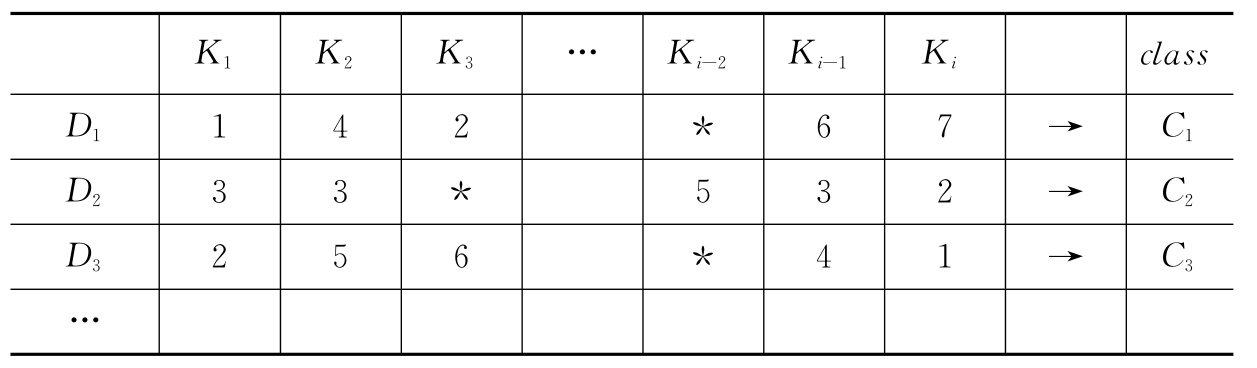
Ki表示特征项,表中的数字是特征项离散化后的表示符,*表示空集,Ci表示文档D j的类别标识。
(3)利用决策表约简步骤化简决策表,得到的化简结果实际就是一个规则集合。
(4)对上面得到的规则集合进一步简化,并输出规则。
属性约简及规则提取算法见文献[7]文中表6.2.2.1算法。
最终提取出的规则示例如下:
查封∧出台∧强制执行∧权力∧人民法院∧司法解释→0101
权益保护法∧实施办法→0101
人民法院∧司法∧体制改革→0101
草案∧审议∧宪法∧修正案→0101
…
跨国公司∧联合国∧投资战略→0109
登记注册∧美元∧投资总额∧外商投资企业→0109
经济开发区∧企业∧投资→0109
…
(5)采用完全与部分匹配方法结合进行匹配分类,匹配算法见文献[7]文中第85~86页,改进的BasicStrength算法。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









