



文本分类特征提取框架研究[1]
李 纲 戴强斌 夏晨曦
(武汉大学信息管理学院)
【摘 要】 互联网的飞速发展,使得网络上的信息类型和信息量快速膨胀,但作为互联网海量信息中最基本的类型——文本信息的表示和利用方式比较简单,文本信息的组织和检索效率仍难以令人满意。由于计算机不可能像人类一样理解和使用文本信息,所以必须把文本表示为某种计算机能够处理的方式,以便更好地挖掘和使用这些信息。
本文以文本分类问题为切入点,构建了一个用于文本特征集提取和应用的统一框架,包括数据准备、特征提取、性能实验和比较、应用接口等。数据准备用来获取待处理的文本,特征提取通过对文本的分词、词条过滤,并使用语义映射处理同义词和多义词,将词条映射为特征,再通过某种算法计算特征值,根据某种标准进行特征选择,构建一个文本的特征向量空间、性能实验和比较,将特征提取的结果应用于文本分类、文本聚类、信息检索、信息提取等各种不同的系统中,并评价特征提取的准确率和查全率,应用接口为各种不同的应用提供统一的调用接口。在这个框架的基础上,对文本分类中的特征提取算法进行了比较研究,并改进了应用于局部特征选取的优势率算法。实验证明,利用该框架,可以大大提高网络信息组织和利用的效率。
【关键词】 文本特征 语义映射 特征提取 统一框架 文本分类
Text Categorization Oriented Features Extraction Framework Study
Li Gang Dai Qiangbin Xia Chenxi
(School of Information Management,Wuhan University)
【Abstract】 Text Features Extraction is a basic problem in many domains such as text categorization,text clustering and information retrieve.And as the most important type of information on the web,text is not organized and used efficiently.For the information in text being used more efficiently,it is necessary to reorganize text using features extraction.
This study establishes a framework which includes Data Preparation,Features Extraction,performance evaluation and application interface.Date Preparation is responsible to acquire text from web pages which becomes a words-set called features during a process of text segmentation,words filtering,semantic combination and features selection subsequently in Features Extraction.And then the features will be evaluated in different systems or is invoked through the integrative application interface.Based on this framework which will be helpful to organization and usage of text information in web,the study compares different features extraction algorithm used in text categorization.
【Keywords】 text features semantic mapping features extraction framework text categorization
1 引言
Internet上包含海量的文本信息,但这些信息组织混乱,查询和利用方法简单,信息没有得到充分的发掘和利用,用户迫切需要更好的方法来组织、检索和利用这些信息。
信息检索(Information Retrieval)里的许多任务都可以归结为文本分类问题,包括搜索引擎对网页的相关性排序、邮件的过滤、文档的组织。一些自然语言处理任务,像词义消歧、词性标注等,也可以转换为文本分类的问题。Google公司和微软公司在网页检索方面已不再满足简单的单词匹配来给出与用户查询相关的网页,越来越多地将信息检索和文本分类的技术引入以更好地理解用户的搜索需求,提供给用户更优的信息处理服务。毫无疑问,文本分类技术作为上述应用的基础理论,必然会推动这些应用领域的发展。
然而,由于计算机不能像人类一样理解文本信息,所以对文本进行预处理,把文本表示为某种计算机能够处理的形式,是对文本信息进行进一步处理的基础。文本集的特征提取,是目前应用最广泛的一种自然文本预处理方法。目前,国内外关于文本集特征提取的研究主要集中在文本分类、文本聚类和信息提取三个领域。作为文本分类、文本聚类和信息提取中对文本进行预处理的关键环节,这三个研究领域中的文本集特征提取算法有共通之处,但由于研究领域的不同,研究的侧重点也各有不同。在文本分类问题中,即使对于较小的文本集,其中包含的词也多达成千上万,如果把所有的词都作为文本集的特征,对分类算法来说显然是不可接受的。所以,在文本分类领域中,文本集特征提取的研究重点在于尽量减少特征数量,而又不牺牲分类的精确性。目前,通用的方法是利用文本中词的词频、篇章覆盖率等信息计算词的一个权值,并根据设定的阈值选择权值较大的前若干词作为文本集的特征。如Lweis和Ginguette[1]在1994年提出了信息增益(Information Gain)的算法,Wiener[2]等在1995年提出了互信息(Mutual Information)算法和χ2统计算法,Yang和Wilbur[3]在1996年提出了词组强度(Term Strength)算法等。国内也有学者在2005年提出了基于词频和词在现代汉语中使用频率的相对词频算法。文本聚类与文本分类面临着类似的问题,都必须尽量减少特征数量,以适应聚类算法的需要,而又不牺牲聚类的精确性。但与文本分类不同的是,在文本聚类时,不存在预先定义的文本类别,所以在计算词的权值时,使用的算法不同于文本分类中所用算法。Hotho和Stumme[4]在2002年提出使用WordNet处理文本中的同义词和多义词,并使用tfidf公式来计算文本特征的权值。陈涛等[5]在2004年提出使用改进的信息增益方法来完成文本的特征选择。在信息提取中,由于用户查询中出现的词是随机出现的,所以不能减少文本集的特征数量。在这一领域中,一个研究的侧重点是设计提取算法,以求更好地计算文本与查询的匹配程度,提高查询的准确率。HuiFang[6]等在2004年完成一项非常有建设性的研究,他们提出通过形式化的定义提取算法应满足的限制条件来指导对现有算法的改进和新算法的设计,并初步提出了6种限定条件。在这些研究领域中,文本集特征提取的方法既有共通之处,而又各有侧重。我们需要从文本自身固有的特性出发,建立一种统一的文本集特征提取方法,而在进行文本分类、文本聚类、信息检索时,在这个统一的方法中,可以根据不同的应用环境,根据文本的固有特点和各种应用领域的要求,建立数学模型形式化的定义在各个应用领域中,特征选取和特征值的算法应该满足限制条件,选择适宜的、更有效的特征选择和特征值算法来提高查全率和查准率,并以之指导对现有算法的改进和新算法的设计。
本文在文本分类、文本聚类、信息提取等领域的现有研究基础之上,总结各领域中文本集特征提取方法的共性,结合对文本自身固有特点的分析,以文本分类问题为切入点,建立了一个文本分类特征提取框架。利用该框架,针对不同研究领域的特性,研究者可以选择适宜的、更有效的特征选择和特征值算法来提高文本分类、文本聚类、信息提取的性能和查全率、查准率。同时,我们对以下几个方面进行了细致的研究:
(1)词条过滤技术研究。运用各种词条过滤技术,如停用词表过滤、词性过滤、词频过滤等,过滤文本中信息含量较低的词,并研究了各种阈值的合理取值范围及其对文本分类、文本聚类性能的影响。
(2)语义学方法在特征提取的作用研究。在特征集提取的过程中,会遇到很多相似、相近和相关的词语。如同义词、近义词和相关词等。需要对这些词语加以处理,获取其中最本质的、能够代表词语在特定领域下的具体含义的信息,并将其表示为特征。语义学方法的引入,能够有效地解决同义词、近义词和相关词的问题,同时也可以在一定程度上解决多义词的问题。本文在HowNet语义词典的基础上,对词语的语义计算问题,进行了深入的研究。
(3)特征选择研究。特征选择是特征降维的一个重要内容。表示文本的向量空间是一个高维度的特征集合,处理高维的特征空间,需要大量的计算资源,有时甚至是不可行的。因此,需要在表示文本的特征中选取最重要的、能够代表文本信息的那些特征,重新构建低维特征空间。这个过程叫做特征降维。本文研究了特征选取时的权值计算方法和阈值的最优选择范围,并建立数学模型形式化的定义算法应满足的限制条件。
(4)文本特征属性的计算方法研究。特征提取另外一个重要的内容是特征值计算。这表示特征为文本提供的信息大小的程度。根据不同的应用,特征值的处理原则和计算方法是不同的。本文对文本特征值的算法进行了研究,并建立数学模型,形式化地定义了算法应满足的限制条件。
(5)性能实验和比较研究。不同的应用往往需要提取不同的特征信息。在文本分类、文本聚类、信息提取等领域的现有研究基础之上,总结各领域中文本集特征提取方法的共性,结合对文本自身固有特点的分析,建立一种统一的文本集特征提取方法,同时分析各研究领域的特性,对不同的特征选择算法和特征值算法在不同的应用领域中的性能进行了实验和比较。对于如何选择适宜的、更有效的特征选择和特征值算法,以提高文本分类、文本聚类、信息提取的性能和查全率、查准率,有一定的指导意义。
(6)改进了优势率算法。通过实验,我们发现优势率算法在应用于局部文本特征提取时,性能与其他常用的算法比较相差很远,我们提出了另一种由优势率算法改进而来的、相对更简洁的算法,可以取得更好的性能。
2 文本分类概述
文本分类问题研究如何为自然语言文本分配预定义分类集中所属的类别。一个完整的文本分类实验包括实验文本集准备、文本索引、特征降维、分类,以及性能评估等多个步骤。
2.1 文本分类定义及方法
文本分类可以形式化地定义为一个函数F:D×C→{true,false},即对文本集D和分类集C中的每一对<d,c>∈D×C,分配一个布尔值,对<d,c>赋值为true,意味着d属于C,而赋值为false意味着d不属于C。对于机器学习方法,更正式的定义为:将预分类的文本集D划分为不相交的两个子集,培训文本集Dtraining和测试Dtest,通过从函数F:Dtraining×C中学习到的函数F':Dtest×C,来逼近函数F:Dtest×C,使得F:Dtest×C和F':Dtest×C尽可能接近。F':Dtest×C将用来对新的文本进行分类。
2.2 文本索引
分类器或分类器学习算法不能直接理解自然语言文本,所以必须通过一个文本索引过程把培训文本集Dtraining和测试文本集Dtest中每个文本的内容表示为一种更为紧凑的、机器学习算法能够处理的形式。最常用的文本表示方法是向量空间模型(VSM)。在向量空间模型中,训练样本被表示成由特征项构成的向量空间。一篇文本文档d通常表示为一个权重向量<d>=<w1,…,w|F|>,称为文本特征向量,其中F={f1,…,f|F|}是一个特征集合,每个特征在文本集D中至少出现过一次,而权重wi简单地说,代表特征fi对文本d语意的贡献。我们可以注意到这种表示方式仅考虑了特征是否在文本中出现,而忽略了特征在文本中出现的顺序和在语法中的作用。D中所有文本的特征向量构成了一个文本特征矩阵M。
各种文本索引方法可以从两个方面加以区分:什么是文本特征以及怎样计算特征权重。典型的选择是使用文本中包含的词(需要去掉介词、连词、代词等虚词),来作为文本特征。也有一些研究使用词组作为文本特征。在计算特征权重上,一些学者使用二值权重(1代表特征fi出现在文本d中,反之为0),另一种标准的权重算法是tfidf公式:
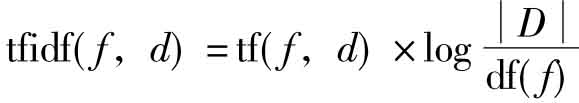
其中tf(f,d)代表特征f在文本d中出现的次数,df(f)代表文本集D中包含特征f的文本数。这一算法意味着特征f在文本d中出现的次数越多,越能代表文本d的内容,而特征f出现在越多的文本中,能起到的区分文本所属类别的作用就越小。
2.3 特征降维
在文本分类问题中,文本特征空间的维数一般很大,通常需要在推导分类器前,将特征集F转换为F',使得|F'|<<|F|。同时,特征降维也有利于降低过拟合现象的发生。过拟合是指生成的分类器和培训文本集的特性过于接近,以至于在重新分类培训文本集时表现出良好的性能,但在分类测试文本时性能就差得多。
目前使用较多的是局部的(为分类集中的每个文本类别)特征降维和全局特征降维方法。前者的工作原理是对每个文本类别c,选择|F'|<<|F|个特征以支持类别c的文本分类,这意味着在分类文本d时,对不同的类别c,使用不同的特征向量<d>。后者则是对整个文本类别集合C,选择|F'|<<|F|个特征用于文本分类,这意味着在分类文本d时,对所有类别使用相同的特征向量<d>。
如果根据最后所得特征的性质,可以从另一个角度把特征降维方法分为两种:特征选取和特征提取方法。区分标准是判断F'是否是F的子集/通常F'中的特征和F中的特征完全不同(例如,F中的特征是词,而F'中的特征不是词,而是F中特征的组合或变形)。这两种不同的特征降维方法使用了完全不同的技术。特征选择方法使用预先定义的算法来评估特征对文本分类的“重要性”,并选择|F'|<<|F|个评分最高的特征,来构成子集F'。这些算法包括文档频率、信息增益、互信息、chi-square,优势率等。而特征提取方法使用原特征集F合成另一个集合F',使得|F'|<<|F|,试图通过创建新的特征来克服同义词和多义词的问题。使用得比较多的特征提取方法包括特征聚类和潜在语意索引等。
2.4 分类算法
文本分类主要分为两种方法:基于统计的方法和基于规则的方法。基于规则的方法通过手工定义一些规则来对文本进行分类,用户直接为每个类目确定分类规则形成类别模板,规则分类器依据类别模板统计测试样本中满足的规则条数及规则出现的次数信息,同时利用规则在测试文本结构中的位置信息,来衡量测试样本所属的类别。这种方法费时费力,且必须对某一领域有足够的了解,才能写出合适的规则。二是统计的方法。基于统计的方法通过在预先分类好的文本集上训练,建立一个判别规则或分类器,从而对未知类别的新样本进行自动归类。大量的结果表明它的分类精度比得上专家手工分类的结果,并且它的学习不需要专家干预,能适用于任何领域的学习,使得它成为目前文本分类的主流方法。
2.4.1 基于统计的方法
(1)k近邻分类模型
k近邻分类模型是最著名的模式识别统计学方法之一,它在很早就被用于文本分类研究,而且是取得最好结果的文本分类算法之一。KNN分类模型的原理如下:给定一个待分类的测试文档,考察和待分类文本最相似的k篇文本,根据k篇文本的类别来判断待分类文本的类别值。k近邻法没有离线训练阶段,所有的计算都是在线进行的。因此这种方法的实时性不好,计算的时间复杂性是O(L×N),其中L是待分类文本向量中非0的分量个数,而N是训练集的文本数量。
(2)朴素贝叶斯模型
朴素贝叶斯分类算法是一种最常用的有指导意义的方法,它以贝叶斯理论为基础,是一种在已知先验概率与条件概率的情况下的模式识别方法。朴素贝叶斯分类算法基于独立性假设,即一个属性对给定类的影响独立于其他属性。“贝叶斯假设”具有双重意义:它一方面大大简化了贝叶斯分类器的计算量;另一方面它导致了贝叶斯分类器的分类质量常常不太理想。
目前存在两种通用的模型:多变量贝努利模型与多项式模型。在这里我们采用多变量贝努利模型来介绍。在这种模型中,文本向量是布尔权重,也就是说,如果特征词在文本中出现,则权重为1,否则权重为0。不考虑特征词的出现顺序,忽略特征在文本中的出现次数。
(3)支持向量机
支持向量机(Support Vector Machine,SVM)是近些年来在统计学习理论的基础上发展起来的模式识别方法。目前已在文本分类领域取得了很好的分类质量。它基于结构风险最小化原理,将原是数据压缩到支持向量集合(通常为前者的3%~5%),学习得到分类决策函数。其基本思想是够做一个超平面最为决策平面,使正负模式之间的空白最大。支持向量机在解决小样本、非线性及高维模式识别问题时表现出了许多特有的优势,并能够推广到其他机器学习问题中。SVM已初步表现出了很多优于已有方法的性能,并在很多领域诸如人脸识别、手写体识别、文本分类等得到了成功的应用。在文本分类方面SVM的表现尤为突出,其分类的查准率和查全率都很高。因为支持向量机的训练是一个二次规划问题,所以它的训练集规模受到严格的限制,对于大规模语料集的训练还存在较大的困难。
(4)神经网络
神经网络系统是由大量简单的处理单元(即神经元)广泛连接而成的复杂网络系统。它反映了人脑功能的许多基本特性,但它并不完全是人脑神经网络系统的真实写照,而只是对其作某种简化、抽象和模拟。目前在文本分类领域得到广泛应用的是前馈式神经网络,又称多层感知机。多层感知机包括输入层、隐含层和输出层(见图1)。隐含层可以是一层或多层。
图1 多层感知机示意图
文本特征降维与分类规则抽取方法研究与应用多层感知机的输入输出关系,可以看成是一种映射关系,即每一组输入对应着一组输出。由于网络中神经元的活化函数的非线性,使网络实现的是复杂的非线性映射。
多层感知机的分类精度相当高,仅次于支持向量机。但是,神经网络目前还缺少快速而又高效的学习算法。因此,对于大规模文本的训练还是一个亟待解决的问题。
(5)最小二乘拟合
从统计学习的角度来看,所谓回归(Regression)即是寻找训练样本的拟合函数。Yang和Chute在1994年提出了线性最小二乘拟合(Linear least squares fit,简写为LLSF)模型。Yang和Chute选择其中的最小模最小二乘解作为最优分类矩阵F*。F*定义了一个从文本向量到加权的类向量之间的映射。在多标签分类时,首先通过对这个类向量进行排序,再根据已确定的阈值就可以确定一篇文本的类别;在通常的单标签分类时,我们可以直接选择类向量中的最大分量所对应的类别作为待分类文本的类别。该算法从理论上来说非常完美,但是对大规模文本矩阵求最小二乘将是一件非常可怕的事情,因为这将耗费大量的计算时间。
(6)潜在语义分类模型
潜在语义索引方法,已经被证明是对传统的向量空间技术的一种改良,可以达到消除词之间的相关性,化简文档向量的目的[7][8]。然而,LSI在降低维数的同时也会丢失一些关键信息。LSI基于文档的词信息来构建语义空间,得到的特征空间会保留原始文档矩阵中最主要的全局信息。但在某些情况下,一些对特定类别的正确分类非常重要的特征,因为放在全局下考虑显得不重要,而在维数约减的过程中被过滤掉,该情况对稀有类别尤为明显。事实上也是如此,稀有类中出现的词很可能是整个文档集中的稀有词,那么被滤掉的可能性就很大了。而如果这样,稀有类的分类性能就肯定会受到影响。
针对上述问题,在扩展LSI模型的基础上,文献[9]提出了一种新的文本分类模型:潜在语义分类模型(Latent Semantic Classification:LSC)[9][10]。与LSI模型类似,文献[9]希望从原始文档空间中得到一个语义空间;然而不同的是,通过第二类潜在变量的加入,把训练集文档的类别信息引入到了语义空间中,也就是在尽量保留训练集文档的词信息的同时,通过对词信息和类别信息联合建模,把词和类别之间的关联考虑进来。这样,就可以得到比LSI模型的语义空间更适合文本分类的语义空间。
2.4.2 基于规则的方法
(1)决策树
决策树又称判定树,是一种类似二叉树或多叉树的树结构。决策树学习是以实例为基础的归纳学习算法。它着眼于从一组无次序、无规则的事例中推理出决策树表示形式的分类规则。
决策树中的每个非叶节点(包括根节点)对应于训练样本集中一个非类别属性的测试,非叶节点的每一个分支对应属性的一个测试结果,每个叶子节点则代表一个类或类分布。从根节点到叶子节点的一条路径形成一条分类规则。决策树可以很方便地转化为分类规则,是一种非常直观的分类模式表示形式。
决策树的构建是一种典型贪婪算法,它是一种自上而下、分而治之的归纳过程。从根节点开始,对每个非叶节点,找出其对应样本集中的一个属性(本文中称为测试属性)对样本集进行测试,根据不同的测试结果将训练样本集划分成若干个子样本集,每个子样本集构成一个新叶节点,对新叶节点再重复上述划分过程,这样不断循环,直至达到特定的终止条件。其中,测试属性的选择和如何划分样本集是构建决策树的关键环节。不同的决策树算法在此使用的技术不尽相同。文本分类的主要特点是属性很多,这就会导致决策树的结构非常复杂,规模极其巨大,这就限制了决策树应用于大规模文本的分类问题。
(2)基于模糊-粗糙集的文本分类模型
文本分类过程中由于同义词、多义词、近义词的存在导致许多类并不能完全划分开来,造成类之间的边界模糊。此外交叉学科的发展使得类之间出现重叠,于是造成许多文本信息并非绝对属于某个类。这两种情况均会导致分类有偏差。针对上述情形,文献[11]提出利用粗糙-模糊集理论结合KNN方法来处理在文本分类问题中出现的这些偏差。模糊-粗糙集理论有机地结合了模糊集理论与粗糙集理论在处理不确定信息方面的能力。粗糙集理论体现了由于属性不足引起集合中对象间的不可区分性,即由于知识的粒度而导致的粗糙性;而模糊集理论则对集合中子类边界的不清晰定义进行了模型化,反映了由于类别之间的重叠体现出的隶属边界的模糊性,它们处理的是两种不同类别的模糊和不确定性。将两者结合起来的模糊-粗糙集理论能更好地处理不完全知识。
2.5 性能评估
在度量分类结果性能时,我们使用了常用的查准率和查全率。查准率定义为条件概率P(F(d,c)=true|F'(d,c)=true),即将文档分配d为类别c的时候,这一决策的正确概率。类似地,查全率定义为P(F'(d,c)=true|F(d,c)=true),即文档d应该分配为类别c的时候,正确采取这一决策的概率。近似地,查准率 ,查全率
,查全率 。同时,我们使用
。同时,我们使用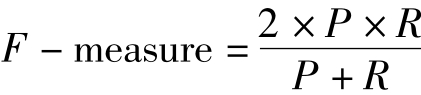 来消除查准率和查全率的相互影响,以获得一个单一的数字来度量各种算法的有效性。
来消除查准率和查全率的相互影响,以获得一个单一的数字来度量各种算法的有效性。
3 特征降维技术
在文本分类问题中,文本特征空间的维数一般很大,通常需要在推导分类器前,将特征集F转换为F',使得|F'|<<|F|。同时,特征降维也有利于降低过拟合现象的发生。
目前使用较多的是局部的(为分类集中的每个文本类别)特征降维和全局特征降维方法。前者的工作原理是对每个文本类别c,选择|F'|<<|F|个特征以支持类别c的文本分类,这意味着在分类文本d时,对不同的类别c使用不同的特征向量<d>。后者则是对整个文本类别集合C,选择|F'|<<|F|个特征用于文本分类,这意味着在分类文本d时,对所有类别使用相同的特征向量<d>。
如果根据最后所得特征的性质,可以从另一个角度把特征降维方法分为两种:特征选取和特征提取方法。区分标准是判断F'是否是F的子集/通常F'中的特征和F中的特征完全不同(例如,F中的特征是词,而F'中的特征不是词,而是F中特征的组合或变形)。这两种不同的特征降维方法使用了完全不同的技术。特征选择方法使用预先定义的算法来评估特征对文本分类的“重要性”,并选择|F'|<<|F|个评分最高的特征来构成子集F'。这些算法包括文档频率、信息增益、互信息、chi-square优势率等。而特征提取方法使用原特征集F合成另一个集合F',使得|F'|<<|F|,试图通过创建新的特征来克服同义词和多义词的问题。使用得比较多的特征提取方法包括潜在语义索引和主成分分析等。
这些算法包括文档频率、信息增益、互信息、chi-square,优势率等。而特征提取方法使用原特征集F合成另一个集合F',使得|F|'<<|F|,试图通过创建新的特征来克服同义词和多义词的问题。使用得比较多的特征提取方法包括潜在语义索引和特征聚类等。
3.1 特征选择
(1)文档频率
词条的文档频率(DF)就是指在训练样本集中出现该词条的文档数。在进行特征抽取时,将DF高于某个特定阈值的词条提取出来,低于这个阈值的词条给予滤除。DF评估函数的理论假设是稀有词条不含有用信息,或含有的信息太少不足以对分类产生影响,而应当被去除。然而,这种假设与一般的信息抽取观念有点冲突,因为在信息抽取中,有些稀有词条(如类别特征词)却恰恰比那些中频词更能反映类别的特征而不应该被滤除,因此,该方法不够准确。
(2)信息增益
IG是一种在机器学习领域应用较为广泛的特征选择方法。它从信息论角度出发,以各特征取值情况来划分学习样本空间,根据所获信息增益的多少来筛选有效的特征。IG可以用下式表示:
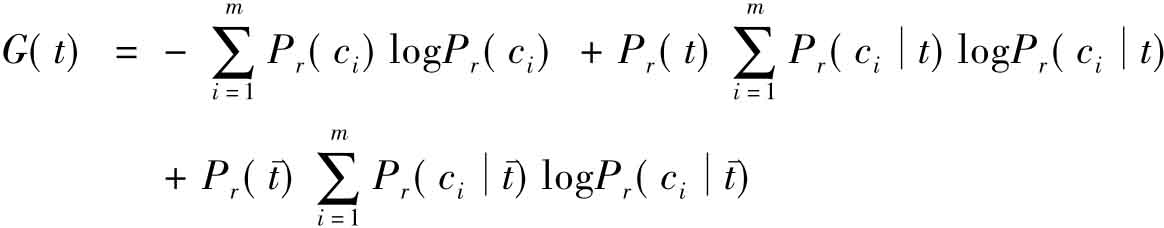
(3)互信息(Mutual Information)算法
互信息理论进行特征抽取是基于如下假设:在某个特定类别出现频率高,但在其他类别出现频率比较低的词条与该类的互信息比较大。
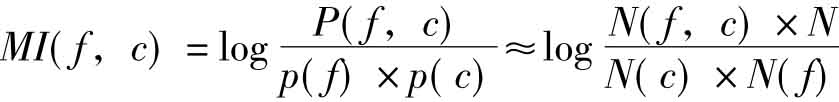
其中,P(f,c)为文本属于类别c并同时具有特征f的概率,p(f)为文本具有特征f的概率,p(c)为文本属于类别c的概率。
(4)χ2统计算法(CHI)
χ2统计法用于度量词条与文档类别之间的相关程度。词条对于某个类别的χ2统计量越高,表明它与该类之间的相关性越大,所携带的类别信息也就越多。利用χ2统计方法来进行特征抽取是基于如下假设:在指定类别文本中出现频率高的词条与在其他类别文本中出现频率比较高的词条,对判定文档是否属于该类别都是很有帮助的。词条的χ2统计值反映了词条对一个类别的贡献和其他类别的贡献,以及词条和其他词条对分类的影响。
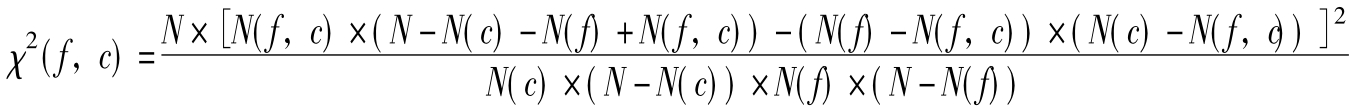
(5)优势率(Odds Ratio)算法
优势率原本用于二元分类器,优势率算法不会将所有类别同等对待,该算法只关心目标类值,因此,这种算法特别适用于二元分类。在二元分类问题中,希望能识别出尽可能多的正确类别,而不用关注其他的类别信息。这时,优势率算法具有独特的优势。其定义如下:
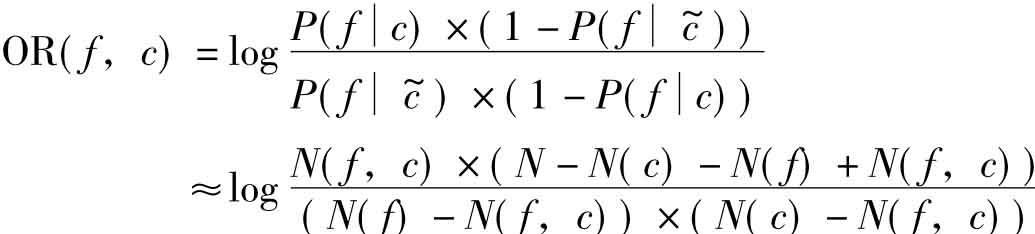
其中,P(f|c)当文本属于类别c时具有特征f的概率, 为当文本不属于类别c时具有特征f的概率。
为当文本不属于类别c时具有特征f的概率。
(6)优势率算法的改进算法
通过实验,我们还发现,优势率算法在应用于局部文本特征提取时,性能与其他常用的算法比较相差很远,而另一种由优势率算法改进而来的,相对更简洁的公式,可以取得更好的性能:
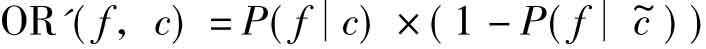
3.2 特征抽取
(1)潜在语义索引(Latent Semantic Indexing)
潜在语义标引是将矩阵的奇异值分解用到文档的语义特征抽取中,将文档的关键词向量空间转化为语义概念空间,在降维的语义概念空间中,计算查询向量与文档向量的相似度,根据相似度的大小,返回给用户按相关性排序后的文档。
潜语义标引的思想是根据数学方法,将m×n的关键词——文档矩阵A进行奇异值分解(Singular Value Decomposition,SVD):
A=UΣVT
这里U是m×m的正交矩阵(即UUT=UTU=Im,Im是m×m单位矩阵),称为A的左奇异值向量(即U是ATA的正交特征向量);V是n×n的正交矩阵,称作A的右奇异值向量(即V是AAT的正交特征向量);Σ是m×n的对角矩阵,对角元为a1,a2,…,amin(m,n),a1,a2,…,amin(m,n)是A的奇异值(即是ATA的非负平方根)。设秩(A)=r,则存在k,k≤r且k<<min(m,n),A的秩——k近似矩阵AK为:
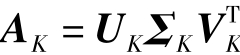
其中UK是m×k的矩阵(由U的前k列组成);Σk是k×k矩阵,是由Σ的前k行、前k列组成;VK是k×n矩阵,由V的前k行构成。k的取值一般在100~300,可以根据实际文档数据库的大小,选择合适的k值。
这样定义的AK是矩阵A的秩——k近似矩阵,可以证明:AK近似到A,由A的秩——k近似矩阵AK,就可将文档的关键词向量空间转化为语义概念空间,且语义概念空间的维数k满足:k<<n(n是文档关键词向量空间的维数)。
(2)主成分分析
在降维技术中有一种重要的常用方法是主成分分析法(Principal Component Analysis,PCA)。它应用线性代数中的KL变换将原始特征空间映射到一个低维的正交空间。通过搜索最能代表原数据的正交向量,创立一个替换的、较小的变量集来组合属性的精华,原数据可以投影到这个较小的集合。设d1,…,dn为训练文本的n个p维特征向量,这时得到协方差矩阵:
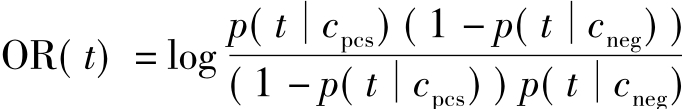
主成分分析法的前q(q<p)个最大的特征值及其对应的特征向量分别为m=(m1,…,mq)和e=(e1,…,eq)。e为新特征空间的基向量,q是维数。训练集d1,…,dn映射到新特征空间以后,得到q维特征向量集1,…,n,实现了特征降维。
3.3 语义处理
在基于TFIDF的向量空间模型中,由于没有考虑词之间存在的概念相似情况,因此影响了数据分类准确性,尤其在文档较短的条件下,例如:“我爱打篮球”和“她更喜欢踢足球”这两句话都描述了对运动的爱好,应该说具有很强的相关性。但在向量空间模型中,因为没有相同的词汇,计算出的相关度为0。这样最终的分类结果也就与人们的直观感受相去甚远。文献[12]提出一种基于语义内积空间模型的文本聚类算法,取得了较好的效果,但仍然有很大的研究空间。
如何运用语义学和统计学的方法来处理文本中同义词、近义词和多义词。问题的关键是将词映射为语义的概念,或称为义原。同义词可以映射为同一个义原,对近义词和多义词可以使用统计学的方法来选择的映射结果,如把多义词映射为在现代汉语中使用频率最高的那个义原或在当前文本中出现频率较高的那个义原,或使用其他更复杂的算法来选择,同时,也要研究是否需要对相应义原出现的词频作一定的调整。
4 文本特征提取及应用框架介绍
文本集特征提取就是一种文本表示方法,通过从文本集中提取一组特征(通常对应于文本中包含的词、词的集合或词的语义),把每个文本表示为一个特征向量。文本集特征提取可定义如下:通过对文本集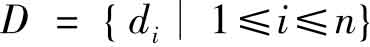 的分析,构建一个m维的向量空间
的分析,构建一个m维的向量空间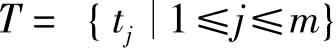 ,使得D中的每个文本di都可以表示为该空间中的一个向量
,使得D中的每个文本di都可以表示为该空间中的一个向量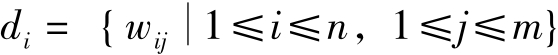 ,其中tj为该向量空间的特征,wij为文本di相对于特征tj的特征值。
,其中tj为该向量空间的特征,wij为文本di相对于特征tj的特征值。
通过研究文本分类、文本聚类和信息提取中文本集特征提取方法的共性,建立一种统一的文本集特征提取方法,同时研究其在文本分类、文本聚类和信息提取中算法的特性,设计不同的特征选择和特征值计算算法;并对文本特征提取过程和涉及的各种算法进行了全面的分析,提取各种算法的共性,设计了一个文本特征提取的通用模型,并以此模型为基础,设计并部分实现了一个面向文本特征提取研究的专用软件包——文本特征提取框架,框架设计如图2所示。

图2 特征提取框架概念图
该框架采用了模块化方法来设计和实现,所以很容易扩展,新的算法可以很方便地添加到框架中,并通过实验来进行评估。这使得研究者可以专注于所研究的算法,而不需要在整个文本分类过程中的其他环节和许多细枝末节上花费额外的精力。
另外,由于文本分类的不同应用可能适用不同的算法,所以,当需要为具体应用选择合适的算法时,也可以通过这个框架来完成实验过程。新的、针对新应用准备的文本集和分类集快速的引入到框架中,各种文本索引、特征降维和文本分类算法只需要通过简单的配置,就可以在新的文本集上进行测试,并选择出最适合新应用的方法。
该框架具有以下特点:
①该框架不是一个简单的包含各种算法的类库或软件包,而是一个内含文本分类模型、专为文本分类研究而设计的系统。研究者可以通过简单的配置来选择文本分类各步骤中需要使用的文本集合、算法和参数,完成自己的文本分类实验,并获得可视化的实验结果。
②研究者可以使用该框架自动记录实验中各个步骤的配置和中间结果,并在后续的实验中使用,也可以提供给其他的研究者使用。
③该框架为相关算法提供了相应的接口,实现了相应接口的算法,就可以加入框架中供研究者使用。
④该框架易于使用,可扩展性强,这使得研究者可以专注于所研究的算法,而不需要在整个文本分类过程中的其他环节和许多细节上花费额外的精力,有效提高文本分类研究的效率。
⑤研究者可以使用文本抽取模块从网页上抽取正文信息,为构建研究领域的文本集服务。
⑥框架提供了统一的应用接口,研究者使用这个应用接口,就可以调用特征提取的结果,方便了研究者的使用。
4.1 核心数据模块
(1)数据准备模块
本模块使用了WNBTE方法去获取网页中的正文信息,构造实验数据。WNBTE(Words Numbers-Based Text Extraction)是基于文本字数的正文抽取方法的简称。它是利用网页上各种文字的特点,构造的一种具有普遍适用性的网页正文抽取方法。具体抽取方法如下:
T—总字数;A—链接文字字数;p—正文文字占整个网页内文字的比值;t—链接块内文字数目与链接块总字数的比值。
ITS(Invalided Tag Set):不会包含需要的文字的标签集合。如SCRIPT、STYLE、#comment等。
CTS(Container Tag Set):专指以下四种标签DIV,TABLE,SPAN,CENTER。
A.计算每个节点包含的所有不属于ITS的子节点的文字数和链接文字的字数,作为该节点的字数T和链接文字字数A。
B.对于属于CTS的节点,如果(A/T)>t,就把该节点标识为链接块。
C.标识为链接块的节点的字数不计入父节点的字数。
D.寻找字数刚好超过T×p的节点s。
E.s节点的所有子节点中未被标识为链接块的节点所包含的文字就是正文信息。
(2)向量空间模型
该模块封装了预分类文本集和相应的文本类别集。文本集实现为一个由每个文本的特征向量共同构成的文本特征矩阵。当一个新的文本集D被文本索引模块提供的工具(见下文对文本索引模块的介绍)转换为文本特征矩阵M后,M将被保存起来,以后对D的文本分类实验可以直接在M上进行(如果需要选择的文本索引和特征降维方法相同),而不需要每次都重新完成文本索引的步骤。
(3)领域数据集
国内外的一些研究表明,利用类别信息,可以有效地改善文本特征选择的精度。Jin[13]在信息检索的特征权重计算研究中引入了监督学习的思想,提出了一种应用类别信息优化特征词权重的方法。文献[14][15]证明了应用类别信息的特征选择能够得到比其他特征选择方法更好的效果。因此,我们提供了一个领域数据集模块。研究者可以使用该框架手动添加或自动导入类别词,需导入的数据放在文本文件中,非常便于编辑。
4.2 特征提取模块
首先对文本集中出现的词统计词频,并进行词条过滤,将文本集表示为文本词条矩阵;然后对词条进行语义映射,处理同义词、近义词和多义词,获得文本义原矩阵;最后进行特征选择,并计算每个文本对应于每个特征的特征值(在这一步骤中,信息提取不需要进行特征选择,而且文本分类、文本聚类和信息提取的特征值算法是不同的),获得每个文本的特征向量,所有文本的特征向量构成了代表整个文本集的文本特征矩阵。
(1)文本索引模块
文本索引模块封装了各种文本索引和特征降维方法。该模块提供了一个工具,可以将新的文本集转换为一个文本特征矩阵。研究者可以使用可视化模块提供的用户界面,选择包含新文本集和相应分类集的文件,以及索引和降维过程中需要使用的算法,调整算法的参数,完成整个文本索引和特征降维过程,查看并保存获得的文本特征矩阵。另外,文本索引模块定义了可扩展的接口,新的文本索引和特征降维方法只要实现了相应的接口,就可以直接加入到模块中,并通过可视化模块调用。
(2)类别词识别模块
结合语义知识,提出了一种类别词识别算法。类别词的识别分为有指导学习和无指导学习两种模式。两者都是利用词语本身的语义信息,计算句子中词语的语义相关度。以相关度大于阈值的词语作为类别词。不同之处在于,有指导的学习方法利用了研究者提供的领域数据集作为以选中的初始特征,然后计算待处理的词语和领域数据集中的数据的关联度,与领域数据集中的数据关联度较大的词语将作为有效特征被保留下来。无指导的学习方法,则完全利用待处理的词语本身的信息,计算这些词语之间的关联度,选择相互之间语义关联度大于阈值的那些词作为有效特征。
(3)特征空间降维模块
特征空间降维模块实现了文档频率、信息增益、互信息、chisquare,优势率等大多数的特征降维算法。同时结合语义词典,引入了特征的类别信息,改进了特征提取算法。经过类别词识别后的特征有不同于一般特征的特点。主要的一点是特征间的语义关联度大。因此,在特征的降维过程中可以充分利用这个特点,对一些特征进行合并,极大地降低了特征空间的维度。
4.3 性能实验模块
性能实验模块封装了各种文本分类、文本聚类、信息检索算法。该模块提供了一个工具,可以载入已生成的文本特征矩阵,应用选择相应的算法和参数,完成实验过程。研究者可以使用可视化模块提供的用户界面,选择由文本索引工具生成的文本特征矩阵,以及实验过程中需要使用的算法,调整算法的参数,查看实验的结果,并和其他的结果相比较。另外,该模块定义了可扩展的接口,新的算法只要实现了相应的接口,就可以直接加入到模块中,并通过可视化模块调用。
4.4 性能评估模块
性能评估模块以性能实验模块的输出结果为评价数据,自动计算使用不同算法所得到的查准率、查全率和F-MEASURE值等各种评价数据。
4.5 应用接口模块
应用接口模块可以让研究者很方便地将特征提取的结果应用到不同的系统中。特征提取的结果,可以应用于不同的项目中,如舆情分析、文本分类、词义消歧等。框架提供了统一的应用接口,研究者使用这个应用接口,就可以调用特征提取的结果,方便了研究者的使用。
5 局部文本特征选取算法比较及改进
局部文本特征选取算法通过一定的公式来计算每个特征f对类别c的重要程度,即特征f对于区分文本是否属于类别c的贡献程度。通常我们将计算所有特征对类别c的重要程度,并将所有特征按重要程度从大到小排列,从中选择重要程度最大的若干个特征,用来完成类别的文本分类。在下文中,N为文本总数,N(c)为属于类别c的文本总数,N(f)为包含特征f的文本总数,N(f,c)为包含特征f并属于类别c的文本总数。我们比较了互信息算法、χ2统计算法、局部优势率算法和改进的局部优势率算法。
5.1 测试数据的准备
我们使用文本集Reuters-21578作为研究的测试文本集,使用了文本集中内含的代码为“ModLewis”的划分方式,将整个文本集划分为包含13625篇文本的培训集和6188篇文本的测试集,另1765篇文本没有使用。Reuters-21578中包含了5个分类集,共672个类别,但文本在各类别中的分布非常不均匀,甚至有的类别中不包含任何文本。为了避免这一分布特征对最终实验结果的影响,我们选择了至少包含100篇培训文本的50个类别共同组成了实验中使用的分类集。所使用的50个类别是互相重叠的,一个文本可能属于多个类别,是一个多值文本分类问题,因此我们将它转换为50个两分文本分类问题。
5.2 分类算法的选择
在具体的分类算法上,我们选择了K最近邻文本分类算法。为了判断测试文本x≤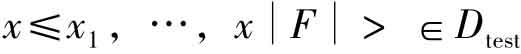 st是否属于类别c,首先使用两个文本向量的夹角余弦来计算两个文本的相似度,即对于x和
st是否属于类别c,首先使用两个文本向量的夹角余弦来计算两个文本的相似度,即对于x和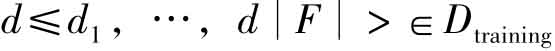 有:
有:
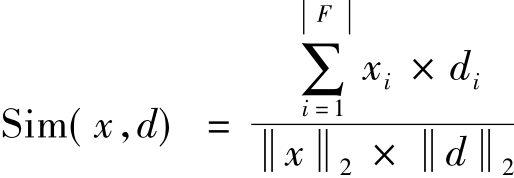
其中xi是x相对于特征fi的权值,di是d相对于特征fi的权值,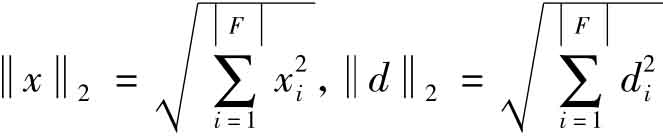 。然后,选择k个与x相似度最大的培训文本d1,d2,…,dk,计算文本x和类别c的相关度:
。然后,选择k个与x相似度最大的培训文本d1,d2,…,dk,计算文本x和类别c的相关度:
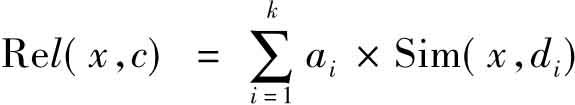
其中,
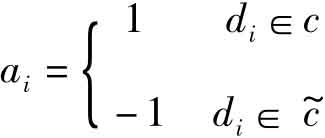
若Rel(x,c)>0,则x∈c,否则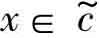 。
。
5.3 实验设计
为了比较这4种文本特征选取算法的性能,我们将按以下步骤来完成性能实验:
①对文本集Reuters-21578,提取其中每个文本d中的实词(包括名词、动词、形容词和副词),作为文本特征,计算d中每个特征f出现的次数,从而将d转换为文本向量<d>。
②使用篇章覆盖率过滤,去掉那些在所有文本中出现次数少于3次的特征。
③使用上文介绍的4种局部特征选取方法,计算每个特征f的重要程度,并把特征按重要程度从大到小排列。我们共获得10358个特征,这就是使用特征选择方法前整个文本集的特征总数。
④计算文本的特征权重,这里我们采用二值权重,即如果特征在文本中出现,则其特征值为1,否则为0。分别取K值为1、2、3、4、5、10、20,和特征数n(取前n个最重要的特征)为10,30,50,100,300,500,1000,3000,用K最近邻方法完成文本分类。
⑤通过比较最终分类结果的性能来比较4种局部特征选取算法。
5.4 实验结果和分析

图3 F-Measure曲线(K=1)
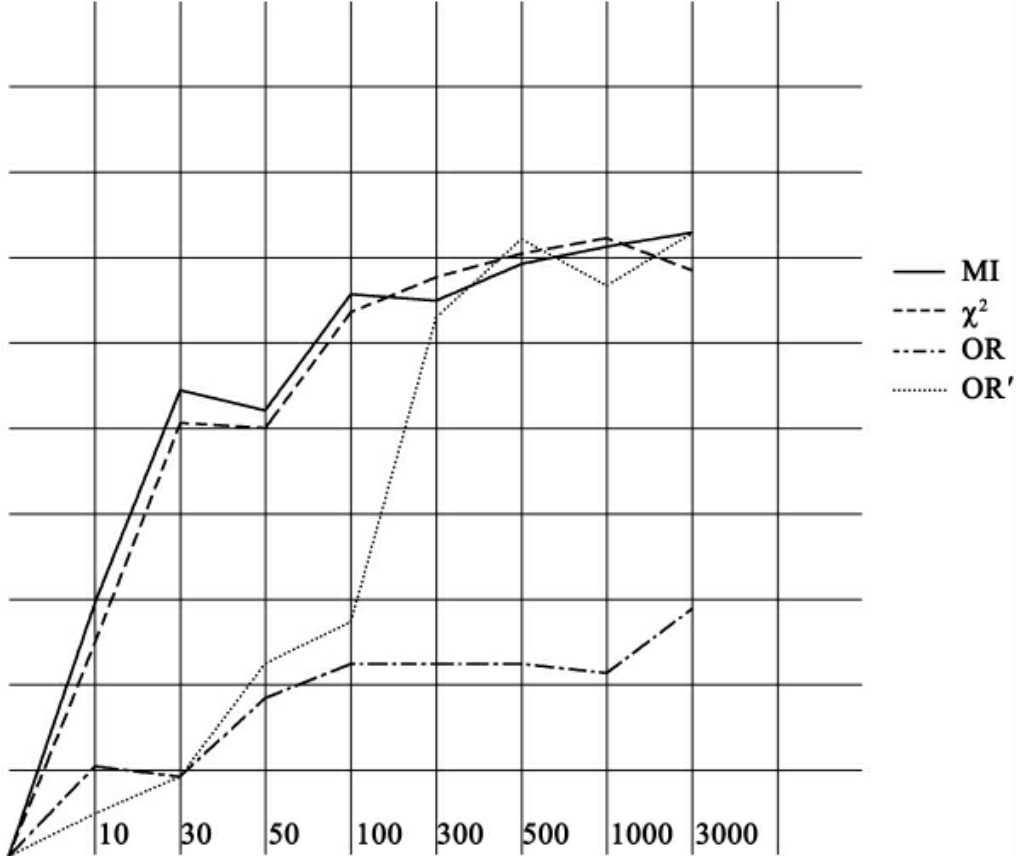
图4 F-Measure曲线(K=2)

图5 F-Measure曲线(K=3)

图6 F-Measure曲线(K=4)
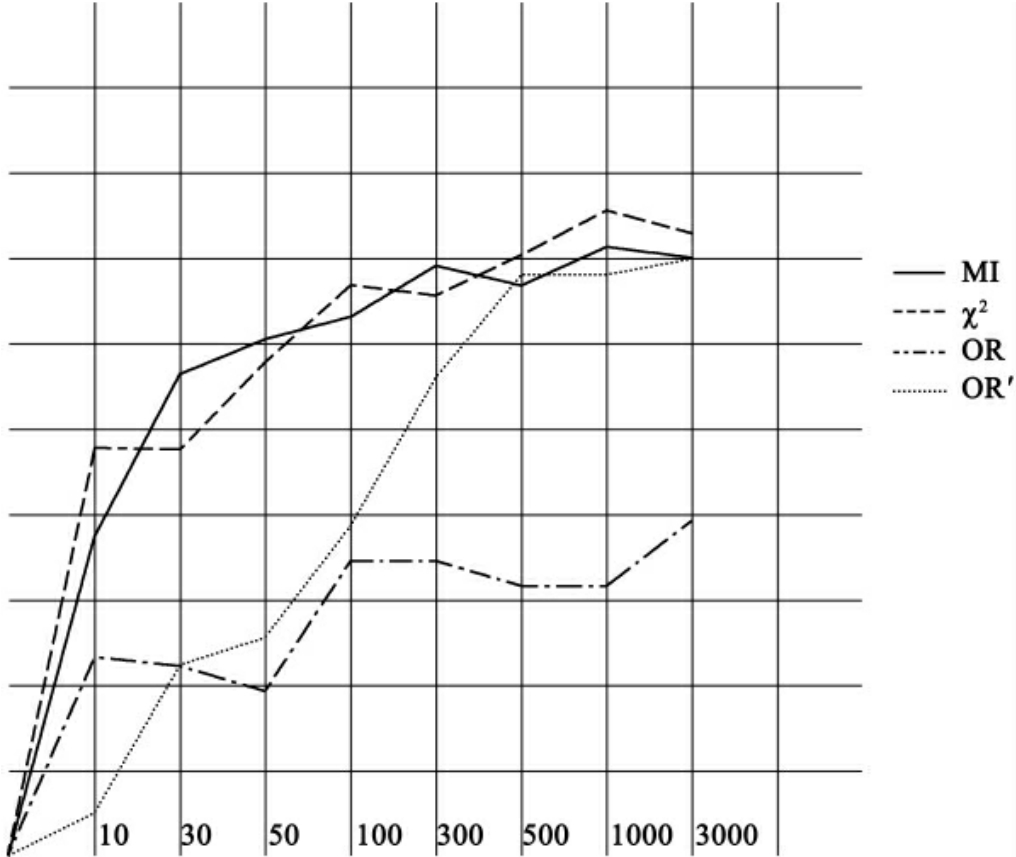
图7 F-Measure曲线(K=10)

图8 F-Measure曲线(K=20)
以上各图(见图3、图4、图5、图6、图7、图8)是当K最近邻文本分类算法的参数K分别为1,2,3,4,10,20时,4种局部特征选取算法的F-Measure曲线,从图中我们可以看出,随着所用的特征增多,4种算法的性能都在上升,但当所取特征数超过一定数量(300左右)后,性能的提升就不明显了,甚至会有所降低。特征选取方法可以将特征空间维度降低90%以上,而不会降低文本分类的性能(甚至还会略为提升)。显然,这是过拟合现象的结果,选用过多的特征,只会使分类结果过于依赖培训文本集的特性,而并不能提升文本分类的性能。
另外,我们也可以看出,互信息算法和χ2统计算法的性能要优于原有的优势率算法,而改进后的优势率算法和χ2统计算法的性能相近。其中,当特征数较小(小于300)时,改进后的优势率算法和χ2统计算法的性能要大大优于互信息算法和优势率算法,互信息算法和优势率算法的性能相近,随着特征数增大(大于500),互信息算法的性能上升很快,和改进后的优势率算法以及χ2统计算法的性能不分伯仲,而优势率算法性能变化不大。
显然,我们改进后的优势率算法在用于局部特征选取时,大大改善了原算法的性能,使之达到了其他优秀算法相同的水平。究其原因,我们分析如下:
公式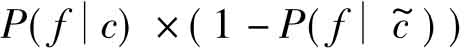 意味着在c类文本中出现的次数越多,同时在非c类文本中出现次数越少的特征f越重要,我们可以简单地认为这一公式代表了特征f作为所有属于c类文本的特征的优势,同样,公式
意味着在c类文本中出现的次数越多,同时在非c类文本中出现次数越少的特征f越重要,我们可以简单地认为这一公式代表了特征f作为所有属于c类文本的特征的优势,同样,公式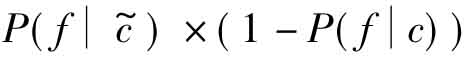 代表了特征f作为所有属于非c类文本的特征的优势。但两者的比率(优势率公式)越大只能说明特征f相对于非c类来说,更适合于作为c类文本的特征,不能说明特征f作为c类文本的特征,具有绝对的优势。这正是我们对优势率公式做出改进的原因,实验结果验证了我们的改进是有效的。
代表了特征f作为所有属于非c类文本的特征的优势。但两者的比率(优势率公式)越大只能说明特征f相对于非c类来说,更适合于作为c类文本的特征,不能说明特征f作为c类文本的特征,具有绝对的优势。这正是我们对优势率公式做出改进的原因,实验结果验证了我们的改进是有效的。
6 结论
本文以文本分类问题为切入点,仔细分析了文本分类、文本聚类和信息抽取中特征提取的过程,抽取它们的共性,构建了一个文本分类特征提取框架。该框架主要用于解决文本分类问题,同时也可作为一个文本特征提取的统一框架。利用该框架,我们改进了用于局部特征提取的优势率算法,并对几种特征提取算法进行了比较。实验证明,使用该框架,可以有效地提高网络信息组织和利用的效率。
【参考文献】
[1]Lewis,D.D.,Ringuette,M..Comparison of Two Learning Algorithms for Text Categorization[C].Proceedings of the Third Annual Symposium on Document Analysis and Information Retrieval(SDAIR'94),1994.
[2]Wiener,E.,Pedersen,J.O.,Weigend,A.S..A New Network Approach to Topic Spotting[C].Proceedings of the Fourth Annual Symposium on Document Analysis and Information Retrieval(SDAIR'95),1995.
[3]Yang,Y.,Wilber,W.J..Using Corpus Statistics to Remove Redundant Words in Text Categorization[C].J Amer Soc Inf Sci,1996.
[4]Andreas Hotho,Gerd Stumme.Conceptual Clustering of Text Clusters[C]//Kokai,G.,Zeidler,J.,eds.,Proc.Fachgruppentreffen Maschinelles Lernen(FGML 2002).37-45,Hannover,2002.
[5]陈涛等.改进的信息增益特征选择方法在文本聚类中的应用[J].现代图书情报技术,2004,12(118):7-9.
[6]Hui Fang,Tao Tao,Chengxiang Zhai.A Formal Study of Information Retrieval Heuristics[EB/OL].http://citeseer.csail.mit.edu/722730.html.
[7]Landauer,T.K.,Dumais,S.T..A Solution to Plato's Problem:the Latent Semantic Analysis Theory of the Acquisition,Induction and Representation of Knowledge[J].Psychological Review,1997(104):211-240.
[8]Deerwester,S.,Dumais,S.T.,Furnas,G.W.,Harshman,R.et al. Indexing by Latent Semantic Analysis[J].Journal of the American Society of Information Science,1990,41(6):391-407.
[9]曾雪强,王明文,陈素芬.一种基于潜在语义结构的文本分类模型[J].2004年度全国搜索引擎和网上信息挖掘学术研讨会,华南理工大学学报:自然科学版,2004(32):99-102.
[10]Wang,M.,Nie,J..A Latent Semantic Structure Model for Text Classification[M].ACM-SIGIR-2003,Workshop on Mathematic/Formal Methods in Information Retrieval,Toronto,Canada,2003.
[11]付雪峰,王明文.基于模糊-粗糙集的文本分类方法[J].2004年度全国搜索引擎和网上信息挖掘学术研讨会,华南理工大学学报:自然科学版,2004(32):73-76.
[12]彭京,杨冬青,唐世渭,等.一种基于语义内积空间模型的文本聚类算法[J].计算机学报,2007,30(8):1354-1363.
[13]Rong Jin,Joyce,Y.C.,Luo Si.Learn to Weight Terms in Information Retrieval Using Category Information[C].Proceedings of the 22nd International Conference on Machine Learning,Bonn,Germany,2005:353-360.
[14]Li,SS,Zong,CQ.A New Approach to Feature Selection for Text Categorization[C]//Ren,FJ,Zhong,YX,eds.Proc.of the IEEE Int'l、Conf.on Natural Language Processing and Knowledge Engineering(NLP-KE).Wuhan:IEEE Press,2005:626-630.
[15]Bong CH,Narayanan K..An Empirical Study of Feature Selection for Text Categorization Based on Term Weightage[C/OL].Proc.of the IEEE/WIC/ACM Int'l Conf.on Web Intelligence(WI 2004).Beijing:IEEE Computer Society Press,2004:599-602.http://www.comp.hkbu.edu.hk/IAT04/.
【作者简介】

李纲,男,教授,博士生导师,1966年生,武汉大学信息管理学院副院长,武汉大学信息资源研究中心研究员。研究方向:企业竞争战略,信息资源管理,发表论文40余篇。
戴强斌,男,1983年生,管理科学与工程在读博士生,研究方向:信息系统。
夏晨曦,男,1975年生,情报学博士研究生,研究方向:情报学,已发表论文8篇。
【注释】
[1]本文系国家自然科学基金项目(项目编号:70673070)研究成果之一。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。












