



一、港城互动系统模型构建的原则与方法
(一)港城互动系统动力学模型构建的原则
1.目的性原则
港口与城市互动系统模型构建的目标是分析港口与城市之间的互动关系,进而分析港城互动的机理。因此,在模型的构建过程中始终以该目标为导向,将目标作为港城互动模型的判断和评价标准。
2.系统性原则
在构建模型时,并不是孤立地分析港口与城市的发展之间的关系,而是将港口与城市视为港城互动系统的两个子系统。充分考虑港口与城市之间的紧密联系和互动关系,以系统整体目标的优化为准绳,协调系统中各分系统的相互关系,使系统完整、平衡。
3.简明性原则
港城互动系统是一个复杂大系统。一方面,港口和城市之间的互动涉及社会、经济的各个领域,内容广泛,需要考虑的因素非常繁杂。另一方面,港口和城市也都是较为复杂的大系统,各自都包含着多层子系统。因此,在考虑系统结构时,必须对系统进行简化,分析港城互动的内在动力,进而提炼出港城互动系统的主要因素。
4.可量化性原则
系统动力学以系统思考为理论基础,对系统进行动态模拟,进而揭示系统运动的内在机理。而动态模拟的基础就是建立系统各个要素之间的动态方程。因此,系统动力学模型的各个要素必须是可以量化的。构建港口与城市互动系统时,在保证系统完整的基础上,选择可量化的关键要素,是构建港城互动系统动力学模型的内在要求。
(二)港城互动系统动力学模型构建的方法
1.系统动力学
系统动力学以系统思考为理论基础,但更进一步,融进了计算机仿真模型。系统动力学研究起源于美国麻省理工学院Jay W.Forrester教授的名著《工业动力学》。由于初期它主要应用于工业企业管理,故称为“工业动力学”。后来,随着该学科的发展,其应用范围日益扩大,遍及经济社会等各类系统,故改称为系统动力学。
系统动力学法的步骤:
(1)找出问题;
(2)对问题产生的原因形成动态假设;
(3)从问题根源出发,建立计算机仿真模型系统;
(4)对模型进行测试,确保现实中的行为能够再现于计算机模型系统;
(5)设计、测试各选择性方案,减少问题;
(6)实施方案。
2.回归理论
在许多实际问题中,某个变量y往往相关于另外一些变量x1,x2,…,xp—1,但这种相关关系或者由于其机理不甚明确,或者由于问题的复杂性而不能确切知道,因此只能说由x1,x2,…,xp—1的取值部分地决定y的取值。如港口吞吐量y与国内生产总值x具有一定的相关关系;又如,某种商品的销量y与众多的社会经济学和人口统计学变量如消费者年龄x1、性别x2、经济收入x3以及商品的价格x4等有关,同样,由这些变量的取值不能完全决定该商品的销量。在这些情况下,y的值由两部分构成,一部分是由x1,x2,…,xp—1能够决定的部分,它是x1,x2,…,xp—1的某个函数,记为f(x1,x2,…,xp—1);另一部分是众多未加考虑的因素(包括随机因素)所产生的影响,被看作是随机误差,记为ε。于是y与x1,x2,…,xp—1的关系可表示为
y=f(x1,x2,…,xp-1)+ε
回归分析即是利用y与x1,x2,…,xp-1的观测数据,并在误差项的某些假定下确定f(x1,x2,…,xp-1).利用统计推断方法对所确定的函数的合理性以及由此关系所揭示的y与各x1,x2,…,xp-1的关系作分析,进一步应用于预测、控制等问题。
特别,当f(x1,x2,…,xp-1)是x1,x2,…,xp-1的线性函数时,有
y=β0+β1x1+β2x2+…+βp-1xp-1+ε
称此模型为线性回归模型,它是本章研究的基本模型,其中β0,β1,β2,…,βp-1是未知常数,称为回归参数或回归系数;y称为因变量或响应变量;x1,x2,…,xp-1称为自变量或回归变量;ε称为随机误差项并假定E(ε)=0。ε是不可观测的随机变量,而y 和x1,x2,…,xp-1之间呈线性关系,而只要求y与未知参数β0,β1,β2,…,βp-1具有线性关系即可。在此意义上,一个最一般的线性回归模型为
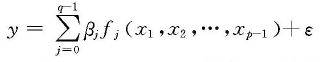
其中fi(x1,x2,…,xp-1)(j=0,1,…,q-1)是q 个线性无关的已知函数,这时只要设置新的变量
zj=fj(x1,x2,…,xp-1),j=1,2,…p-1
便可将模型化为线性回归模型。
3.聚类分析
聚类分析又称群分析,它是研究(样品或指标)分类问题的一种多元统计方法。聚类分析能够将一批样本数据(或变量)按照它们在性质上的亲疏程度在没有先验知识的情况下自动进行分类。这里一个类就是一个具有相似性的个体的集合,不同类之间具有明显的非相似性。在分类过程中,人们不必事先给出一个分类标准,聚类分析能够从样本数据出发,客观地决定分类标准。
聚类分析一般有两种方法:一种是把每个对象看作是空间中的一个点,然后定义点与点之间的距离;另一种是用某种相似系数来描述对象之间的紧密程度。
变量聚类在实际中也有广泛应用,一方面,通过变量聚类可以发现某些变量之间的一些共性,以有利于分析问题和解决问题;另一方面,变量聚类也可作为某些数据分析的中间过程。例如,在回归分析中,若涉及的自变量很多,则可先考虑用变量聚类,再在每一类变量中进行主成分分析,选取各类中的某些主成分作为新的自变量,这样不但可以消除变量间的复共线性,而且还可达到降低自变量维数的目的。
4.因子分析
由于港城互动系统中多个要素之间都存在着较高的相关性,因此采用回归分析时会产生各个要素的共线问题。为了降低要素之间的相关性,本书采取了因子分析方法。
因子分析的基本思想是:通过变量(或样品)的相关系数矩阵(对样品是相似系数矩阵)内部结构的研究,找出能控制所有变量(或样品)的少数几个随机变量去描述多个变量(或样品)之间的相关(相似)关系。但在这里,这少数几个随机变量是不可观测的,通常称为因子。然后根据相关性(或相似性)的大小把变量(或样品)分组,使得同组内的变量(或样品)之间相关性(或相似性)较高,但不同组内的变量(或样品)相关性(或相似性)较低。
因子变量具有以下特点:(1)因子变量的数量远少于原有指标变量的数量,能减少分析中的计算工作量。(2)因子变量并不是原有变量的简单取舍,而是对原始变量的重新组构,它们能够反映原有众多指标的绝大部分信息,不会产生重要信息的丢失问题。(3)因子变量之间没有线性相关关系,能为研究工作提供较大的便利。(4)因子变量具有命名解释性,有助于对因子分析结果的解释评价。
相关矩阵R也是P维观测数据的最重要的数字特征,它刻画了变量观测值之间的线性相关的密切程度。R往往是多维数据分析的出发点。S及R总是非负定的,在实际应用中,S及R常是正定的。
不同的变量往往有不同的量纲,由于不同的量纲会引起各变量取值的分散程度差异较大,这时变量的总方差则主要受方差较大的变量控制,若由原变量的协方差矩阵出发进行主成分分析,则优先照顾了方差较大的变量,这不但会给主成分变量的解释带来困难,有时还会造成不合理的结果。为了消除原变量彼此方差差异过大的影响,通常将原变量进行标准化再作主成分分析。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











