



第三节 因子分析
在社会研究过程中,为了更具体、全面地把握和认识社会事物,往往采用较多的指标对一个问题进行测量,但是较多的变量会增加分析问题的复杂性,变量之间的相关性也可能会导致变量之间信息的重叠。多元线性回归虽然是处理多变量的问题,但指标太多,会增加分析的复杂性,甚至会引起统计累赘问题。那么如何能用较少的变量替代较多的变量,仍能反映原有的全部信息?因子分析是社会统计中常用的简化变量的方法。
因子分析(Factor Analysis)是多元统计分析技术的一种,主要目的是浓缩数据。它通过对众多变量之间内部依赖关系的研究,探求数据之间的基本结构,并用少数的几个假想变量来表示基本的数据结构。这些假想的变量能够反映原来众多的观测变量所代表的信息,并解释这些变量之间的相互依存关系,这些假想的变量称为因子(Factors)。因子分析就是研究如何以最少的信息丢失把众多的指标(变量)浓缩为少数几个因子。
总的来说,因子分析就是寻求变量之间的基本结构,将多元统计中具有相关关系的众多变量转化为代表数据基本结构,反映数据本质特征的几个因子。可以进一步将原始观测变量的信息转化成因子的因子值,用这些因子代替原来的观测变量进行统计分析。
一、因子分析的原理与概念
因子分析模型在形式上与多元线性回归模型相似,每个观测变量由一组因子的线性组合表示。设有k个变量X1,X2,X3,…,Xk,且X是均值为0,标准差为1的标准化变量,则因子模型的线性表达式为:

其中:
aij称为因子负荷(Factor loadings),是第i个变量在第j个公因子上的负载,相当于多元回归分析中的标准回归系数(i=1,2,…,k;j=1,2,3,…,m);
f1,f2,…,fm称为公因子(Common factors),是各个变量所共有的因子,解释了变量之间的关系;
εi称为特殊因子(Unique factor),是各个变量所特有的因子,相当于多元回归分析中的残差项,表示该变量不能被公因子解释的部分。
因子模型中,每一个变量由m个公因子和一个特殊因子组成,公因子即我们通常所说的因子,公因子的个数最多等于分析的变量数。在因子分析的过程中,总是使第一个因子代表所有变量中最多的信息,后面因子的代表性依次减弱,忽略最后几个因子,对原始变量的代表性也不会有什么损失,所以因子的数目往往少于变量的个数。
因子分析中有以下概念需要注意:
1.因子负荷
因子负荷指的是第i个变量在第j个公因子上的负载。当因子之间完全不相关时,因子负荷aij就等于第i个变量和第j个因子之间的相关系数,在多数情况下,假设因子之间是正交的,即不相关。因此,因子负荷不仅表示变量的因子线性表达,还表示因子和变量之间的相关程度。aij的绝对值越大,表示因子与变量X的关系越密切。
假设我们有如下的观测量和因子模型:
X1=0.8972f1+0.2456f2+0.3257ε1
X2=0.7984f1+0.3125 f2+0.3923ε2
X3=0.2356f1+0.9256f2+0.1557ε3
X4=0.5674 f1+0.8956f2+0.2875ε4
X5=0.8456f1+0.5623f2+0.31823ε5
从这五个模型可以看出,f1与X1,X2,和X5的关系密切,主要代表了这些变量的信息;f2与X3和X4的关系密切,主要代表了这两个变量的信息。
因子负荷还可以用来估计变量之间的相关系数,当因子之间彼此不相关时,Xi和Xj之间的相关系数为:
rij=ai1aj1+ai2aj2+…+aimajm
也就是说任何两个变量之间的相关系数等于对应的因子负荷乘积之和。由因子模型导出的变量间的相关系数和通过计算两个变量的相关系数值的比较,可以判断因子解是否合适,如果两者的差别很小,就可以说模型很好地拟合了观测数据,因子解是合适的。
2.公因子方差
因子分析中,变量的方差由两部分组成,一部分由特殊因子决定,一部分由公因子决定。公因子方差(Communality)又称变量共同度,指的是变量方差中由公因子决定的比例。当公因子之间彼此正交时,公因子方差等于与该变量有关的因子负荷的平方和,即: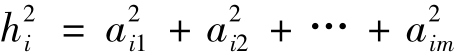
公因子方差表示了变量方差中能被公因子解释的部分,公因子方差越大,变量能被因子解释的程度越高。公因子方差以变量为中心,它的意义也说明如果用公因子代替变量,原来每个变量的信息被保留的程度。
3.因子贡献度
每个公因子对数据的解释能力,可以用该因子所解释的总方差来表示,称为该因子的贡献度(Contributions),它等于和该因子有关的因子负荷的平方和,即: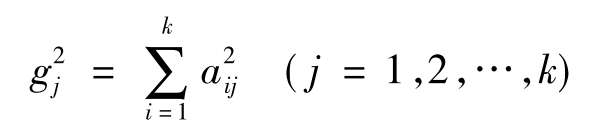
表示用一因子fj对各变量的方差贡献之和,反映了因子fj对原有变量总方差的解释能力。所有因子的总贡献度为: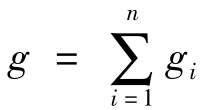 。因子方差贡献度的值越高,说明相应因子的重要性越高。实际应用中,也常用相对指标,即每个因子解释的方差占所有变量总方差的比例。相对指标衡量了公因子的相对重要性。
。因子方差贡献度的值越高,说明相应因子的重要性越高。实际应用中,也常用相对指标,即每个因子解释的方差占所有变量总方差的比例。相对指标衡量了公因子的相对重要性。
二、因子分析的步骤[5]
因子分析通常包括以下主要步骤:(1)计算变量相关矩阵,判断因子分析的适用性。(2)提取初始因子,确定因子的个数和求解因子的方法。(3)进行因子旋转,明确变量结构。(4)计算因子值,确定因子变量。SPSS软件提供了专门的命令进行选择和计算,下面对各部分的基本原理和方法进行简单介绍。
1.因子分析的适用性判定
因子分析的目的是简化数据或找出数据间的结构,使用因子分析的前提是观测变量之间有较强的相关关系。因此在进行因子分析之前,需要先对各个变量进行相关分析,并判断是否适合采用因子分析的方法。一般来说,如果相关矩阵中大部分相关系数都小于0.3,则不适合作因子分析,除此之外,SPSS软件还提供了专门的统计量。
(1)反映象相关矩阵(Anti-image correlation matrix),等于负的偏相关系数。偏相关是控制了其他变量后,两个变量间的相关程度,如果数据中确实存在公因子,它与其他变量重叠的影响被扣除了,变量间的偏相关系数应该很小,所以如果反映象相关矩阵中很多元素的值较大的话,观测数据可能不适合作因子分析。
(2)Bartlett球体检验(Bartlett test of sphericity),该统计量检验整个相关矩阵,零假设是相关矩阵的单位阵。如果不能拒绝该假设,就不适用于因子分析。
(3)KMO(Kaiser-Meyer-Olkin Measure of Sampling Adequacy),该测量是比较变量之间的相关系数和偏相关系数的大小,其值的变化从0到1,当所有变量偏相关系数的平方和远远小于简单相关系数的平方和时,KMO值接近1。当KMO值较小时,表示变量不适合作因子分析。
2.因子求解的方法
初始因子求解的主要目的是要确定能够解释变量相关关系的最小因子数。根据依据标准的不同,求解初始因子的方法主要可以分为两类:一类是基于主成分分析模型的主成分分析法;另一类是公因子分析法,主要包括主轴因子法,极大似然法,最小二乘法,Alpha法等。主成分分析是独立于因子分析的一种数据简化方法,因子分析把主成分分析的结果作为一个因子解,在确定因子个数时,主要包括主成分分析的一个统计量——特征值。主成分分析在因子分析中占有重要地位。
(1)主成分分析法。主成分(Principal components)分析是一种数学变换的方法,它把给定的一组变量通过线性转换成一组不相关的变量,这些新的变量按方差依次递减的顺序排列,假设变量的方差能够被主成分解释掉,在数学变换中保持变量的总方差不变,使第一个变量具有最大的方差,称为第一主成分,第二个变量的方差次之,并且和第一个变量不相关,称为第二主成分,依次类推。n个变量就有n个主成分。求解主成分的主要数学工具是特征方程,通过求解变量相关矩阵的特征方程,得到k个特征值和对应的单位向量,把k个特征值按从大到小的顺序排列,分别代表k个主成分所解释的变量的方差。对求解过程感兴趣者,可以参考专门书籍。
通过主成分分析之后,确定几个主成分作为初始因子呢?最常用的确定因子个数的方法是特征值大于等于1的主成分作为初始因子,放弃特征值小于1的主成分。有些情况下,也可以根据研究者事先确定的因子个数,直接提取因子。另外,保留的因子是否有意义,是否能被解释,也是在确定因子时应该考虑的因素,如果保留的因子太多,解释因子时可能会比较困难。
(2)公因子法。公因子法与主成分法不同,它从解释变量之间的相关关系出发,假设变量之间的相关能够完全被公因子解释,变量的方差不一定能被公因子解释,因此,每个变量被公因子解释的方差不再是1,而是公因子方差。因此在求解之前,需要对公因子方差进行估计,常用的估计方法有:
①用主成分分析的结果作为公因子方差的初始估计值,即取特征值大于1的主成分,得到每个变量的公因子方差,作为公因子方差的初始估计值。
②取每个变量和其余变量的相关系数中绝对值最大的,作为变量的公因子方差的初始估计值。
③用每个变量和剩余变量的复相关系数的平方,即R2作为该变量公因子方差的初始估计值。
公因子分析法包括主轴因子法,最小二乘法,最大拟然法,Alpha法等形式。
一般来说,各种求解初始因子的方法产生的变量的公因子方差差别不大,当公因子方差为1时,主成分分析法和公因子法的实质是一样的,当公因子方差较低时,两者的差别较明显,因为公因子方差只是因子解的一个副产品,所以如果提取相同数目的因子,主成分分析法比公因子法能够解释更多的方差。
决定选择哪一种方法,有两点需要考虑:一是进行因子分析的目的;二是对方差的了解程度。如果因子分析的目的是以最少的因子最大限度地解释原始数据中的方差,或者知道特殊因子和误差带来的方差很小,则适合用主成分分析法。如果因子分析的目的是确定数据结构但并不了解变量方差的情况,则适合用公因子分析法。在大多数情况下,两种方法得到的解很接近。
3.因子旋转
根据初始因子解求得的大多数因子都和很多变量有关,因为初始因子是按因子的重要程度顺序提取因子的,第一个因子能够解释最大比例的方差,其他因子的解释力依次递减。因子是通过数学计算获得的,为了更好地理解和把握因子分析的结果,我们还希望知道每个因子的实际意义。因子旋转的目的是通过改变坐标轴的位置,重新分配各个因子所解释的方差的比例,使因子结构更简单,更易于理解,因子旋转不改变模型对数据的拟合程度,不改变每个变量的公因子方差。因子旋转的方式分为两种:一种是正交旋转;另一种是斜交旋转。正交旋转是使因子轴之间仍然保持90°角,也就是因子之间是不相关的。斜交旋转中没有因子之间是不相关的限制,因子之间的夹角是任意的,用斜交因子描述变量会使因子结构更简洁。
目前,究竟选择哪种旋转方式没有统一的标准,可根据研究问题的需要确定,如果因子分析的目的只是进行数据简化,把更多的变量浓缩为少数几个因子,而因子的确切含义并不重要,应该选用正交旋转。如果研究的目标是要得到几个理论上有明确意义的因子,则应该选择斜交旋转。但因为斜交旋转中因子的斜交程度受使用者定义的参数的影响,而且斜交旋转允许的因子之间的相关程度是很小的,如果两个因子高度相关,则大多数研究者会选取更少的因子重新进行分析,因此斜交旋转的优越性被大大削弱了,正交旋转的应用更广泛。
得到因子之后,便希望给每个因子一个有意义的解释。解释因子主要是看因子的负荷矩阵,找出每个因子上有显著负荷的变量,根据这些变量的意义给因子一个合适的名称,具有较高负荷的变量对因子名称的影响较大。一般来说,绝对值大于0.3的因子负荷就是显著的,因子负荷的绝对值越大,在解释因子时就越重要。把因子负荷矩阵重新排列,使得在同一因子上有较高负荷的变量排在一起,很小的负荷可以忽略不计,可以帮助研究者方便地识别出每个因子上重要的负荷。
4.因子值的计算
计算机完成的各个因子的取值都是一些与变量无关的数字,这些数字是怎么得来的呢?因子对应的每个个案上的值称为因子值(Factor scores)。因子值是用观测量来描述因子,第p个因子在第i个个案上的值可以表示为: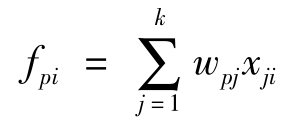
其中,xji是第j个变量在第i个个案上的值,wpj是第p个因子和第j个变量之间的因子值系数。因子分析模型是用因子的线性组合来表示一个观测变量,因子负荷实际是该组合的权数,因子求值的过程正好相反,它是通过观测变量的线性组合来表示因子,因子值是变量的加权平均。因为各个变量在因子上的负荷不同,不能简单地相加,权数的大小表示变量对因子的重要程度。
三、因子分析的SPSS操作过程
SPSS软件提供了进行因子分析的命令Factor,见图11-11。通过Factor可以对前面介绍的因子分析过程的每一步进行统计,简化了计算过程。

图11-11 调用Factor命令
1.因子分析的步骤
因子分析的操作步骤如下:
(1)点击Analyze→Data Reduction→Factor,打开如图11-12的对话框。将要分析的多个变量放入Variables窗口。如果不想用全部的样本进行分析,且数据文件中存在一个选择变量,则将选择的变量放入Selection Variable窗口,对指定数据进行分析。
(2)Descriptives:选择变量的描述统计量。单击Descriptives按钮,打开Factor Analysis对话框,点击Descriptives按钮,见图11-13,选择要分析的统

图11-12 Factor对话框
计量。此对话框中包括两方面的内容:

图11-13 Descriptives对话框
①Statistics:统计量,包括:
●Univariate descriptive:单变量的描述统计量,选择此项会输出变量的基本统计量,包括变量的有效个案数、均值和标准差。
●Initial solution:初始分析结果。选择此项,会输出原始变量的公因子方差,协方差矩阵对角线上的元素,以及解释的方差占总方差的百分比。这是系统的默认选项。
②Correlation Matrix:相关矩阵。
●Coefficients:相关系数。选择此项会输出原始变量间的相关系数矩阵。
●Significance levels:显著性水平,给出每个相关系数单尾检验的显著性水平。
●Determinant:相关系数矩阵的行列式。
●Inverse:相关系数矩阵的逆矩阵。
●Reproduced:再生相关项。选择此项给出因子分析的相关矩阵后,还给出残差,即原始相关和再生相关之间的差值。
●Anti-image:反映象相关矩阵,包括偏相关系数的负数,反映象协方差阵,包括偏协方差的负数。
●KMO and Bartlett's test of sphericity:KMO和Bartlett检验。选择此项给出对采样充足度的Kaisex-Meyer-Olkin测度,检验变量间的偏相关是否很小。Bartlett检验的相关阵是不是单位阵,表明因子分析是否适合。
(3)Extraction:因子提取选项。Extraction选项包括以下内容(见图11-14):

图11-14 Extraction对话框
①Method:因子提取方法。这里提供了七种因子提取的方法:
●Principal components:主成分分析法。
●Unweight least square:不加权最小平方法。该方法使观测的和再生的相关之差的平方和最小,不计对角元素。
●Generalized least squares:变量的倒数值加权,使观测的和再生的相关阵之差的平方和最小,最高值比较低值给予的权重小。
●Maximum Likelihood:最大似然法。不要求多元正态分布,通过构造样本的似然函数,使似然函数达到极大,其中因子负荷为未知参数,求得因子解。
●Principal axis factoring:使用多元相关的平方作为公因子方差的初始估计。
●Alpha factoring:α因子提取法。
●Image factoring:映象因子提取法。
②Analyze:指定分析矩阵。
●Correlation matrix:以分析变量的相关矩阵为提取因子的依据。
●Covariance matrix:以分析变量的协方差矩阵为提取因子的依据。
③Display:与因子提取相关的输出项。输出结果可以选择:
●Unrotated factor solution:输出未经旋转的因子提取结果、因子解的特征。
●Scree plot:输出与因子相关的方差的碎石图,用于确定应保留多少因子。一般而言,碎石图都会有一个拐点,在此拐点之前是大因子连接的陡峭的折线,在此点之后是小因子连接的缓坡折线。
④Extract:控制提取过程和提取结果。
●Eigenvalues over:特征值。系统默认项。若选择此项,则提取特征值大于1的因子或特征值大于平均方差的因子。可以自己设置因子提取的阈限。
●Number of factors,根据用户确定的因子个数提取因子,不考虑特征值。
⑤Maximum iterations for:因子分析的最大迭代次数,系统默认为25。
(4)Rotation:旋转方法。单击Rotation按钮,打开旋转方法对话框,见图11-15。
①Method:旋转方法。
●None:不选择旋转。它是系统默认选项。
●Varimax:方差最大正交旋转,它使每个因子上具有最高负荷的变量数最小。这是常用的方法。
●Direct Oblimin:直接斜交旋转,选择此项可以在下面的框中输入Delta(δ)值,此值在0~1之间。0产生最高相关因子。
●Quatimax:四次最大正交旋转。该方法使每个变量中需要解释的因子个数最少。
●Equamax:平均正交旋转,是Varimax和Quartmax的结合,结果在一个因子上有高负荷的变量数和需要解释的变量的因子数最少。

图11-15 旋转对话框
●Promax:斜交旋转,允许因子彼此相关,它比直接斜交旋转更快,适合于大数据集的因子分析。
②Display:输出显示项。
●Rotated solution:旋转结果。指定旋转方法才能指定此项。
●Loading plot(s):因子负荷散点图。指定此项给出以两两因子为坐标轴的各变量的负荷散点图。选择此项后给出的是经旋转后的因子负荷图。
●Maximum iterations for Convergence:指定旋转的最大迭代次数,系统默认为25。
(5)Scores:因子得分。单击Scores按钮,打开如图11-16的对话框。
①Save as variables:将因子得分作为新变量保存到数据文件中。程序运行结束后,在数据窗口显示出新变量。每次分析中产生多少个因子就产生多少个新变量。
②Method:计算因子得分的方法。
●Regression:回归法,其因子得分均值为0,方差等于估计因子得分与实际因子得分之间的多元相关的平方。
●Bartlett:Bartlett法,因子得分均值为0,超出变量范围的各因子平方和被最小化。
图11-16 Save对话框
●Anderson-Rubin:Anderson-Rubin法,因子得分均值为0,标准差为1,且彼此不相关。
③Display factor score coefficient matrix:显示因子得分系数矩阵,是标准化的得分矩阵,原始变量经过标准化后,可以根据该矩阵给出的系数计算各观测量的因子得分。
(6)Options:其他输出项。单击Options按钮,打开如图11-17的对话框。Options对话框提供了缺省值和其他一个结果的显示形式。
图11-17 Options对话框
①Missing Values:缺失值处理方法。缺失值的处理方法主要有三种形式:
●Exclude cases listwise:删除有缺失值的观测量,也就是说有缺失值的观测量都不参与分析。
●Exclude cases pairwise:成对删除带有缺失值的观测量。指的是在计算两个变量的相关系数时,把这两个变量中带有缺失值的观测量删除,如果一个观测量在进行相关分析的变量没有缺失值,则其他变量即使有缺失值,也不影响正在进行的相关分析。
●Replace with mean:用变量的均值代替分析变量的缺失值。
②Coefficient Display Format:负荷系数的显示模式。
●Sorted by size:负荷系数按数值的大小排列并构成矩阵,使在同一因子上具有较高负荷的变量排在一起。
●Suppress absolute values less than,不显示那些绝对值小于指定值的负荷系数。此框中的数应该在0~1之间,系统默认的临界值为0.10,选择此项可以突出负荷较大的变量,便于得出结论。
2.实例分析
例4 以数据11.3中青年白领调查中孩子对婚姻/家庭的影响变量的因子分析。
分析:此次调查中通过15个变量反映了孩子对婚姻/家庭的影响,这些变量在设置的时候采用李克特量表的形式,并进行了赋值:5=非常同意,4=比较同意,3=说不清,2=不太同意,1=很不同意。
打开数据,执行以下操作:
(1)点击Analyze→Data Reduction→Factor,打开对话框。
(2)将“孩子态度1”~“孩子态度15”变量放入Variables窗口。
(3)点击Descriptives按钮,选择Statistics中的Univariate descriptives,显示单变量的描述统计量;选择Initial solution,显示初始因子分析结果。选择Correlation Matrix中的Coefficients,显示相关矩阵;选择Significance levels显示显著性水平。
(4)点击Extration按钮,选择Method中的Principal components。选择Analyze中的Correlation matrix;选择Display中的Unrotated factorsolution和Scree plot;在Extract栏中选择Eigenvalues over 1。
(5)点击Rotation按钮,选择Method中的Varimax最大方差旋转。选择Display中的Rotated solution,显示旋转后的结果,选择Loading plot(s)显示因子负荷图。
(6)点击Scores按钮,选择Save as variables→Regression,将生成的因子保存为新变量。点击Display factor score coefficient matrix显示因子得分。
(7)点击Options按钮,在Missing Values中选择Exclude cases listwise,选择Coefficient Display Format中的Sorted by size。
(8)在主对话框中,单击OK按钮,提交运行。在结果窗口中看到如表11-5所示的结果。
表11-15是各个变量的均值,标准差,参与分析的个案数。表11-16是公因子方差表,Initial表示提取公因子之前变量的方差,Extraction是提取公因子之后变量的方差。
因参与分析的变量较多,表格较大,此处省略了原始变量的相关分析矩阵。
表11-15 描述统计结果

表11-16 公因子方差表

表11-17是总体方差的分解表,Initial Eigenvalues表示相关矩阵或协方差矩阵的特征值,这个值用于确定哪些因子该保留,Total表示各成分的特征值,%of Variance表示各因子所解释的方差占总方差的百分比,Cumulative%表示各因子所解释方差的累计百分比。Extraction Sums of Squared Loadings是因子提取结果,表示没有旋转的因子负荷的平方和,给出的是每个因子的特征值,方差占总方差的百分比和累积百分比。Rotation Sums of Squared Loadings是旋转后的因子提取结果,表示旋转后的因子负荷的平方和,给出的是每个因子的特征值,方差占总方差的百分比和累积百分比。从中可以看出特征值大于1的因子只有四个,从累积方差解释里可以看出,这四个因子可以解释总方差的63.941%。
表11-17 总方差分解表
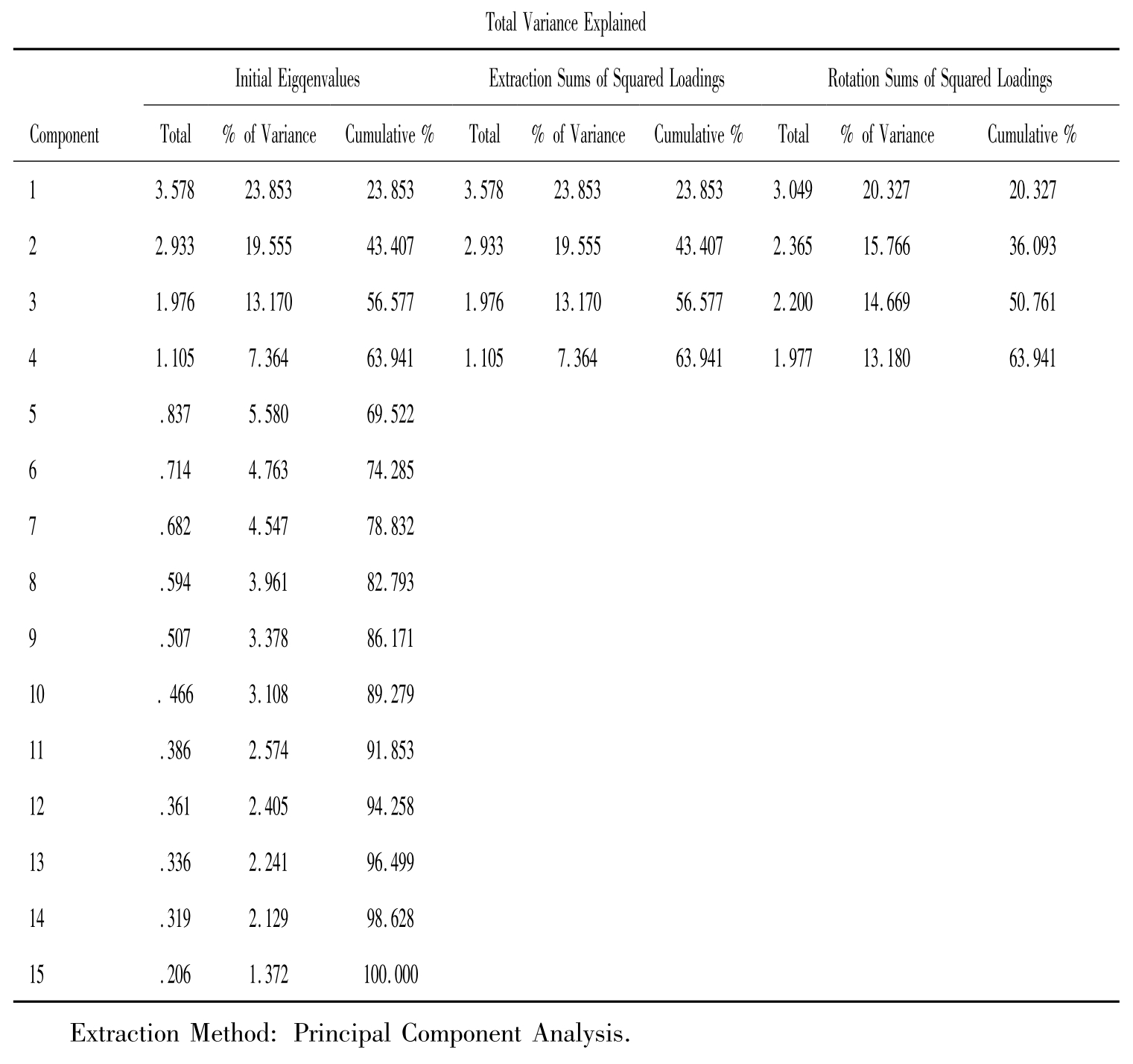
从图11-18中因子的折线也可以看出特征值大于1的因子有四个。
表11-18 旋转前的因子提取结果

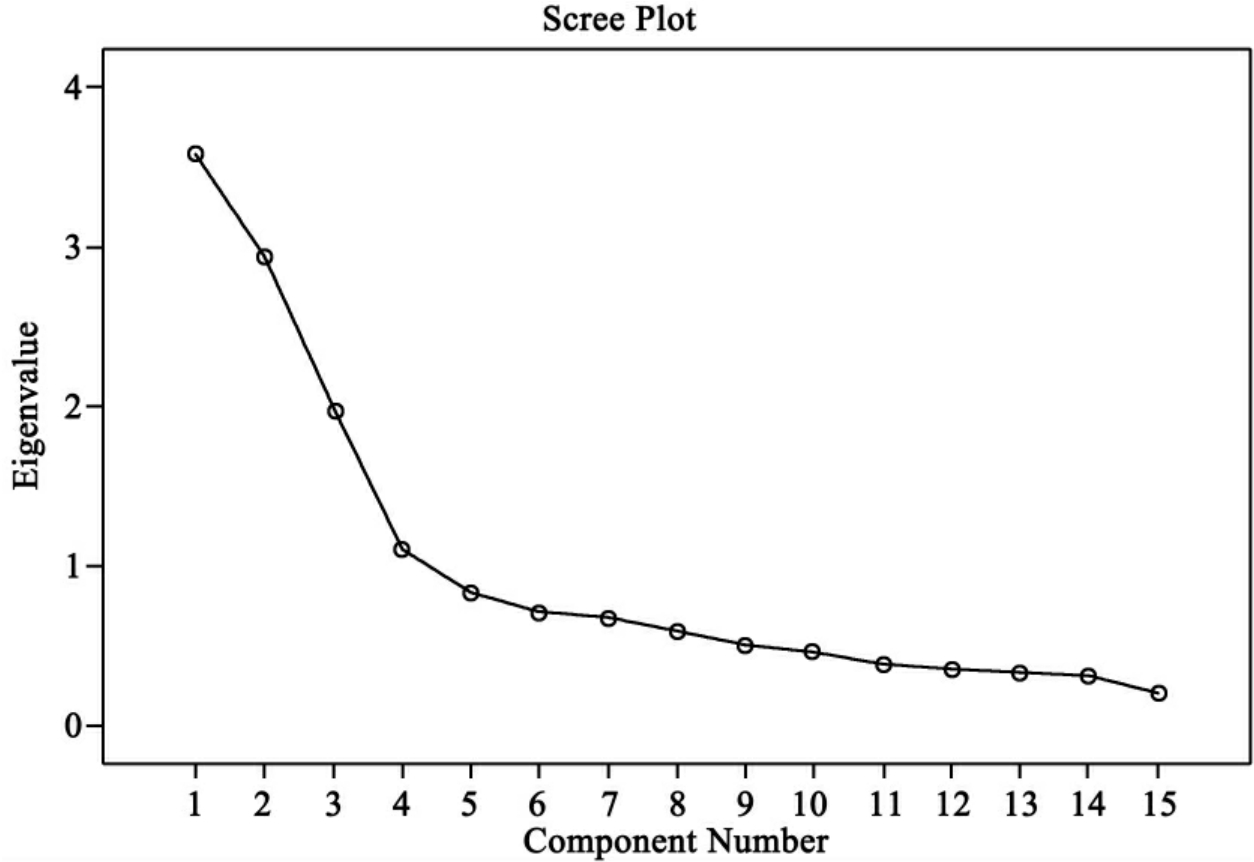
图11-18 表现各因子特征值的碎石图
续表

表11-18和表11-19分别表示的是旋转前和旋转后因子值的大小,从旋转后的因子提取结果中可以看出因子和变量之间关系的强弱。
表11-19 旋转后的因子提取结果
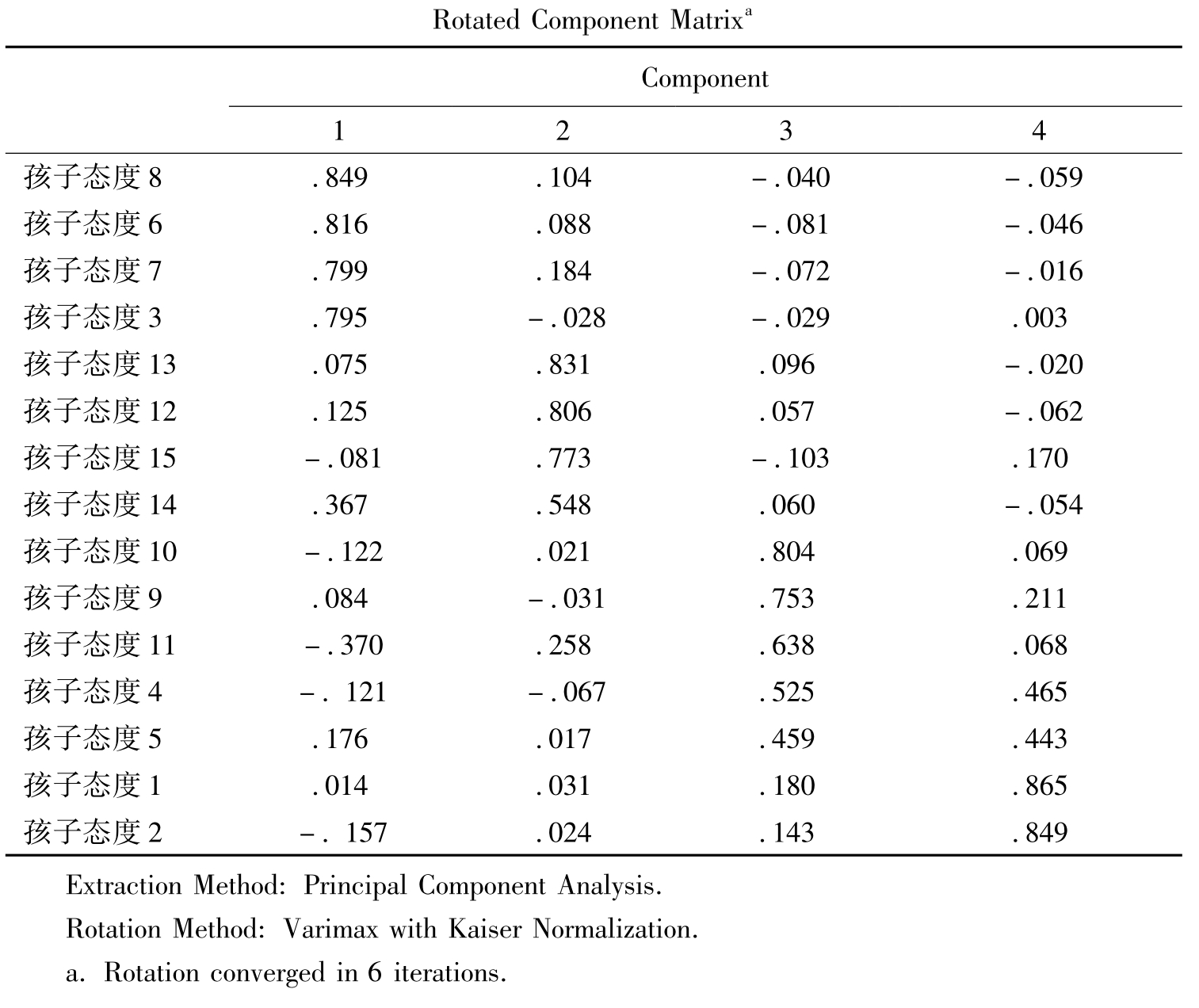
表11-20 因子旋转的转换阵

表11-21是估计回归因子分数的协方差矩阵,即因子间的相关矩阵。表11-22是因子得分系数矩阵,根据因子得分系数和原始变量的标准化值可以计算各个观测量的因子得分数(见图11-19)。
表11-21 因子得分协方差矩阵
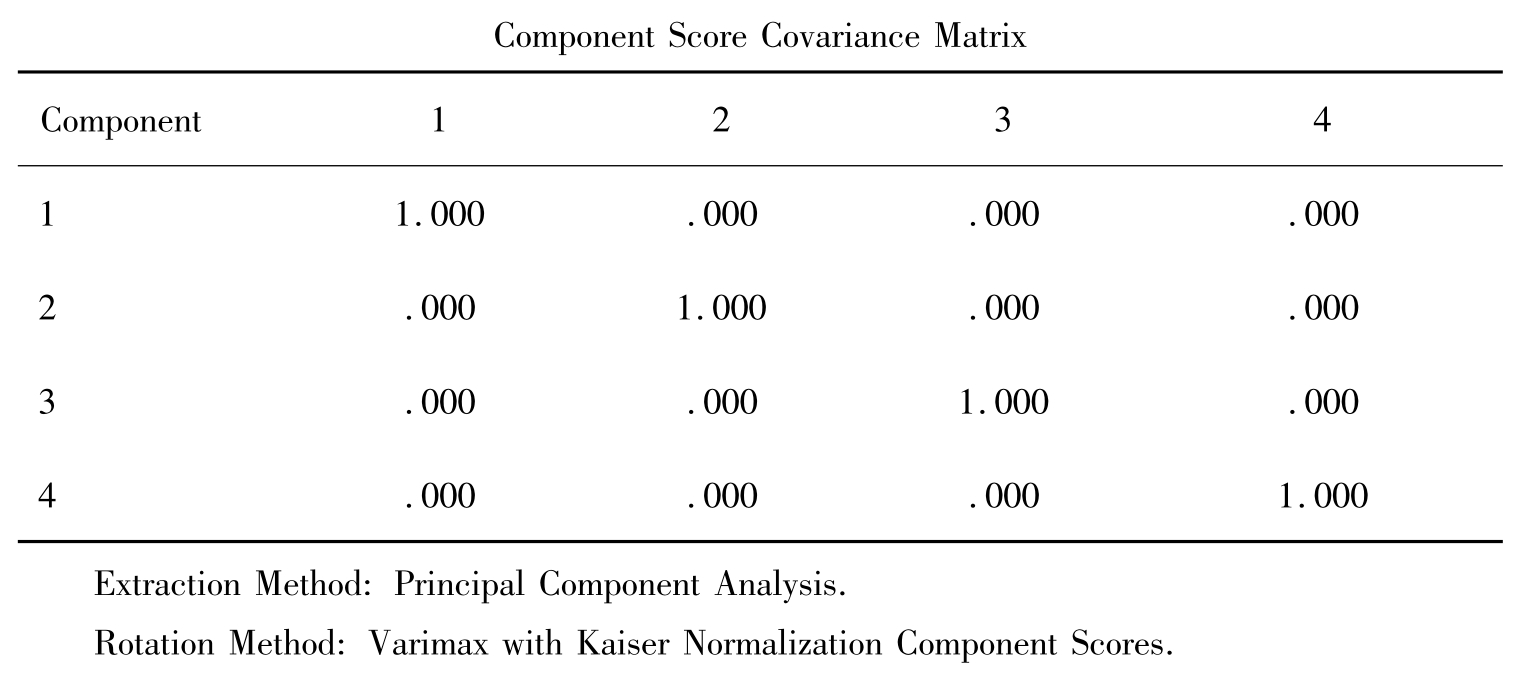
表11-22 因子得分信息

续表
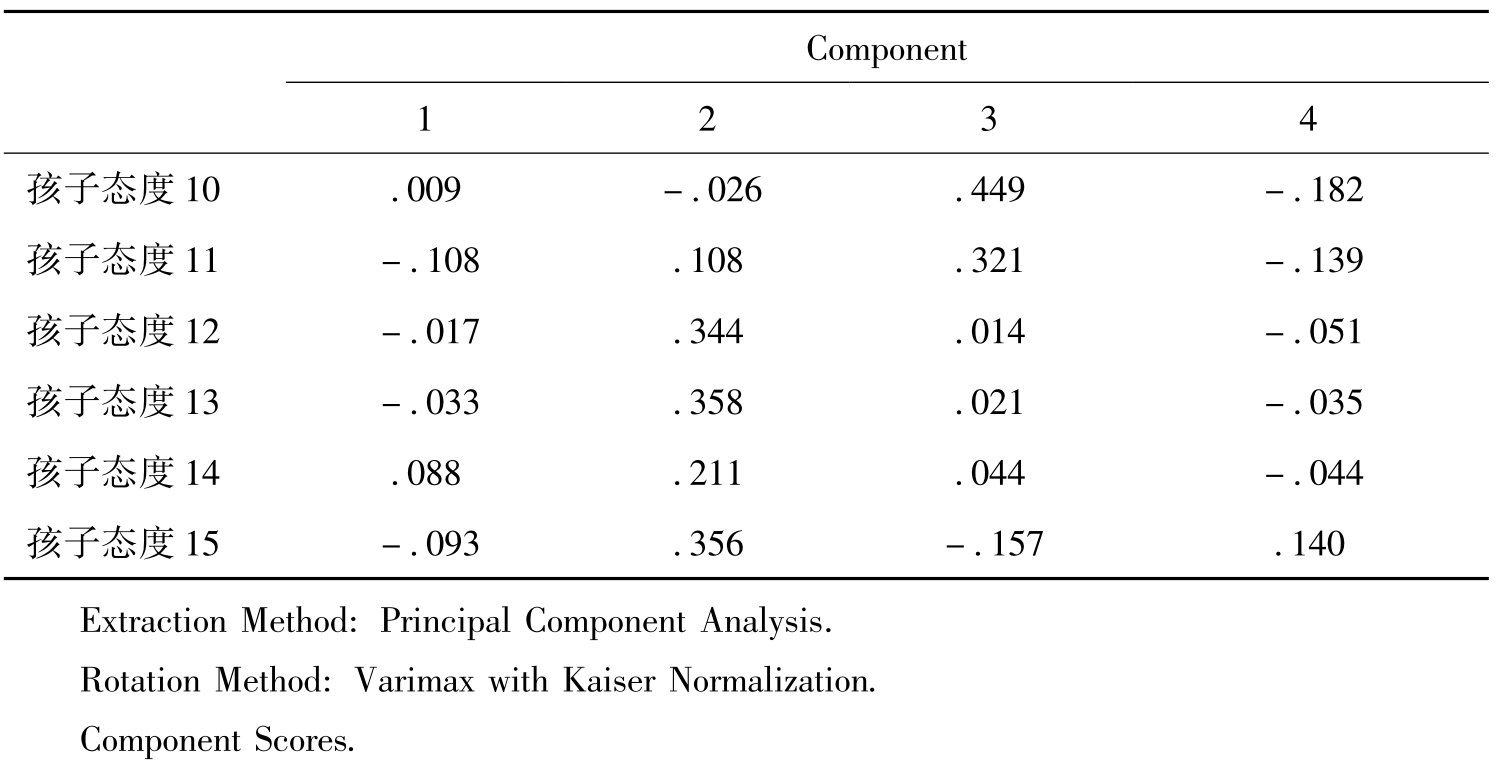
图11-20是通过因子得分获得的保存在观测数据中的新的变量,四个因子保存为四个新变量。
多变量的统计分析较为复杂,但也是社会研究中进一步对变量之间的关系进行分析的重要方法。少数介绍的几种多变量的分析方法,都是现阶段常用的分析方法。研究者可根据自己的研究需要,选择适合的研究方法,查找相关的书籍进一步系统地学习。
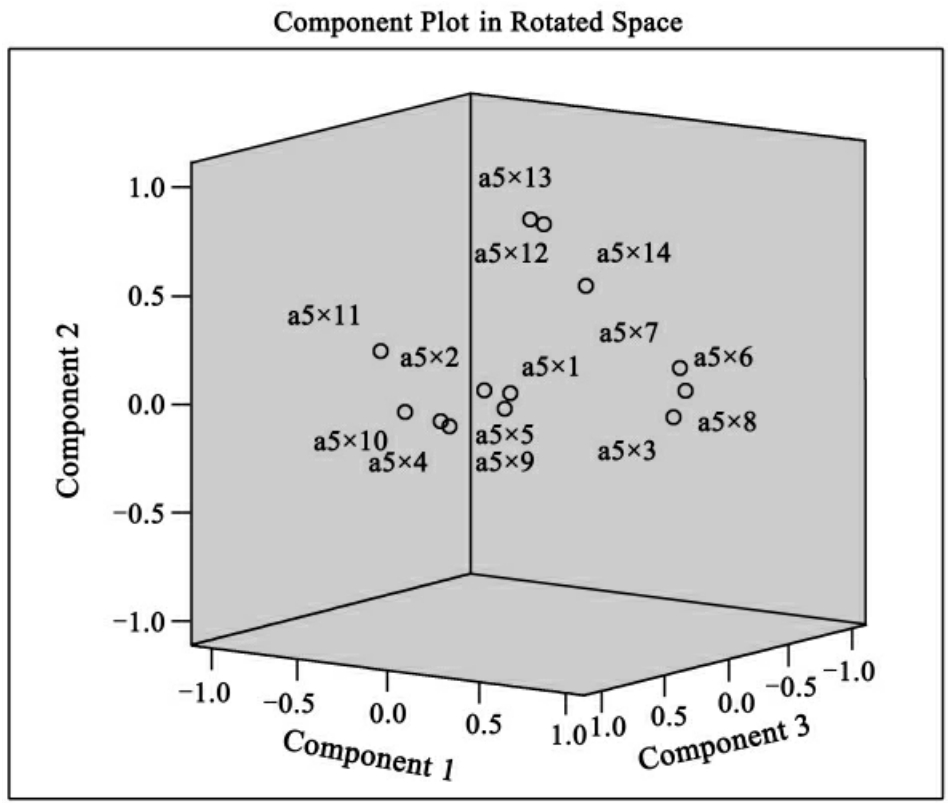
图11-19 旋转后的主成分图

图11-20 通过因子得分获得的新变量
本章小结
社会现象的复杂性决定了社会中各事物之间的关系并不是简单的两两相关,因此,当前社会学的研究不仅关注两个变量的关系,更关注对多个变量的分析。详析分析、多因分析等提供了多变量分析方法。偏相关分析和线性回归分析是常用的多变量统计方法。
偏相关分析也称为净相关分析,它是通过计算在控制其他变量的影响下,两个变量之间的偏相关系数来反映这两个变量真实关系的大小。偏相关系数涉及多个两个变量的两两相关,计算起来较为复杂,Correlate子菜单中的Partial命令提供了偏相关系数和假设检验的计算结果,从而简化了计算的过程。
回归分析研究的是一个或多个变量(自变量)对一个变量(因变量)的影响。根据变量之间的关系,回归分析又可分为线性回归和非线性回归。社会学研究中最常用的是线性回归,如果参与回归分析的自变量只有一个,则称为一元线性回归;如果参与回归分析的变量有多个,则称为多元线性回归分析。线性回归模型不仅分析变量之间的变化规律,还可以对社会现象发展趋势作进一步的预测,因此就对模型提出了较多的要求,如要求模型的正态性、等方差性、各变量的独立性等,并通过决定系数、方差分析、残差散点图等来检验模型的拟合优度。SPSS软件中的Regression子菜单提供了多种回归分析的过程,最常用的是Linear命令。
社会现象的复杂性,决定了只采用一个指标很难对其进行准确测量,因此往往在测量的过程中引进多个指标或变量,这样就增加了分析问题的复杂性,导致变量之间的信息重叠。因子分析提供了用较少变量代替较多变量,仍能反映原有信息的方法。通过Factor因子分析命令,生成的新的公因子不仅可以简化指标,分析变量之间的基本结构,而且新生成的变量又可成为回归分析的变量。
关键术语
偏相关 回归分析 决定系数 共线性 虚拟变量 线性分析
公因子 因子负荷 主成分分析 因子旋转 因子分析
思考题
1.什么是偏相关?偏相关分析的意义是什么?怎么用SPSS软件进行偏相关分析?
2.什么是线性回归分析?线性回归模型成立的条件有哪些?
3.什么是虚拟变量?如何将居住地:城市、城镇、农村变成虚拟变量?
4.什么是统计累赘?统计累赘判断的标准有哪些?如何避免统计累赘?
5.如何用SPSS软件进行回归分析,并能够准确解释统计结果?
6.什么是因子分析?如何用Factor命令进行因子分析,并准确解释各统计结果?
7.对自己手头的数据进行多变量统计分析,熟练掌握各命令。
【注释】
[1]张翼.中国人社会地位的获得——阶级继承和代内流动.社会学研究,2004(4): 76-90.
[2]卢纹岱.SPSS for Windows统计分析.北京:电子工业出版社,2000:287-288.
[3]李沛良.社会研究的统计应用.北京:社会科学文献出版社,2001:267.
[4]卢纹岱.SPSS for Windows统计分析.北京:电子工业出版社,2000:295-296.
[5]郭志刚.社会统计分析方法——SPSS软件应用.北京:中国人民大学出版社,2001:92-110.
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











