



实验一 老年痴呆症的生物学发现——生物学网络资源检索
毫无疑问,最基本的生物学数据就是序列,序列是非常直观的数据,如DNA包括基因组序列和基因序列,它是由A,T,C,G四种脱氧核糖核苷酸构成的有序的集合,而RNA则由A,U,C,G四种核糖核苷酸组成,蛋白质的组成较为复杂,主要有20种较为常见的氨基酸。因此,生物信息学的一个重要任务就是收集、组织和存储生物序列数据。
作为入门级的教程,为了让同学们对生物序列有一个更加直观的认识,在这里我们从一种常见的疾病入手,并找到与该疾病相关的基因、蛋白以及序列的相关功能注释信息和代谢通路。
OMIM数据库是在线人类孟德尔遗传数据库(Online Mendelian Inheritance in Man)的缩写。数据库涵盖了关于人类遗传疾病和基因座位(locus)相关信息和文献的中心数据库。OMIM可以为研究人员提供迅速、简练的对于某一基因或遗传疾病研究的关键信息和综述,并且提供对于其表型和基因型的相关分析,让科研人员迅速获取疾病遗传研究的进展情况以及活跃于该领域的学者的资料。
OMIM的每一条记录都有唯一对应的MIM记录号(表5-1),对应于某种基因或者是疾病,如果是序列,则必然包含对应的基因功能注释。一般而言,每一个基因座位和记录存在一一映射的关系。另外,许多疾病虽然在基因和生物化学水平上没有详细的描述,但仍然包含在记录中。OMIM的另一个主要目标是实现已定位表型和对应基因序列的关联(图5-10)。
表5-1 MIM记录号的含义

续 表


图5-10 OMIM数据库页面截图
(http://www.ncbi.nlm.nih.gov/omim)
OMIM的查询方式有简单查询、高级查询和复杂布尔(Boolean)查询(图5-11)。
(1)简单查询 OMIM默认的查询方式,不指明搜索范围、限制(limits)或布尔算子(如AND/OR/NOT等)。假如我们要查询“与心肌病相关的定位于11号染色体的常染色体隐性遗传疾病基因”,只需要在输入栏填入“cardiomyopathy 11autosomal recessive”,就可以得到相关记录。
(2)高级查询 可通过历史(history)、索引(index)和限制(limit)三个菜单的组合实现比较多样的查询。历史菜单可以提供之前的查询历史结果,并支持布尔算子的组合,可以对之前的查询进行修改。布尔算子必须为大写,支持“*”等通配符和“()”的限制。限制菜单可指定关键词的搜索范围,如标题(title)、MIM记录号(entry)、参考文献(reference)、染色体位置(chromosome)、记录号前缀(prefix)、记录建立和修改的时间等。索引包括有关术语(terms)的字母列表及其对应术语的记录数。

图5-11 OMIM查询限制
(3)复杂布尔查询 是高级查询的命令行方式,其优点是可以一步即可完成高级查询的任务,但前提是必须熟悉布尔算子的语法。
1.OMIM数据库检索
(1)打开浏览器,进入NCBI主页(http://www.ncbi.nlm.nih.gov)。
(2)从页面的下拉菜单中选择OMIM并按下GO,进入如图5-12所示的OMIM数据库主页。
(3)输入你希望查询的疾病的名称进行简单查询,例如老年痴呆症(Alzheimer),近年来,上海的老龄化趋势非常明显,老年痴呆症已经成为非常明显的威胁之一,因此需要我们对老年痴呆症有更加清楚的认识。
(4)在搜索栏输入“Alzheimer”,我们可以看到返回许多记录,如图5-13所示,从这里你可以得到多少条记录?
(5)如果需要对结果进行限制,可以相应地在Limits栏加入限制,例如该关键词出现的位置,基因座位所在的染色体,提交和最后修改的日期,还有对前缀(Prefix)的限制等,这样可以大大缩小搜索范围,确定我们真正想要获取的信息。如果我们要将范围限制在具有明确分子机制的形状描述,则页面记录减少到多少条?

图5-12 老年痴呆症在OMIM数据库中的查询结果

图5-13 老年痴呆症MIM#104300记录
(6)打开其中一个记录“#104300”,可以看到如图5-13所示的结果。TEXT(文本)部分简单陈述了家族性阿尔茨海默症-1(familial Alzheimer disease-1,AD1)及其位于21号染色体短臂上的相关的基因——淀粉样蛋白前体(amyloid precursor protein,APP),该基因突变的遗传方式,还提到了与APP基因相关的脑淀粉样血管病。DESCRIPTION(描述)部分则对该疾病的特征和定义进行了简单的描述,并对可能相关的遗传因素和多态性位点、其他AD类型等进行了综述说明。CLINICAL FEATURES(临床特征)则重点介绍了临床研究的历史及临床特征。BIOCHEMICAL FEATURES(生化特征)则介绍了AD1的生物化学特征。PATHOGENESIS(病因)部分是对可能病因的分析的研究进展进行了综述介绍。INHERITANCE(遗传)从遗传方式的角度对AD1进行了分析。DIAGNOSIS(诊断)说明的是AD1各种临床诊断方式的研究进展情况。采用连锁分析(linkage analysis)的相关基因定位结果出现在MAPPING(定位)部分。分子遗传学、群体遗传学和动物模型研究的结果则分别在MOLECULAR GENETICS(分子遗传学)、POPULATION GENETICS(群体遗传学)、ANIMAL MODEL(动物模型)这几个部分逐一进行了详细介绍。其他如历史和参考文献就不在这里赘述了。
(7)图5-13中左下栏“Entrez Gene”列出了Nomenclature(命名)、RefSeq(参考序列)、GenBank(GenBank核酸序列)、Protein(蛋白)、UniGene(单基因簇)等其他数据库链接。下面我们以Protein库为例说明,Protein链接列出了目前已知与老年痴呆有关的一些蛋白质(图5-14)。

图5-14 与老年痴呆相关的蛋白列表
(8)打开Alpha 2macroglubulin variant[Homo sapiens](人α-Ⅱ巨球蛋白),输出如图5-15所示。
默认的显示格式是GenPept,其他可选的格式还包括FASTA、Graphics(图形)、GenePept(Full)、ASN.1等。右边还有其他一些功能键如Download(下载)可以把各种不同格式的文件保存到本地,Save(保存)到Clipboard(剪贴板)等,而Links则列出了相关的链接如Blink、Related sequences(相关序列)、BioSystems(生物系统)、Conserved domain(保守结构域)、Domain relatives(结构域相关)、Gene(基因)、Gene genotype(基因型)、GeneView in dbSNP(单核苷酸多态性库中的GeneView)、Nucleotide(核苷酸)、PubMed(相关文献)、Related Structure(相关结构)、Taxonomy(物种分类库)等。

图5-15 人Alpha-2巨球蛋白突变体的GenPept格式
(9)让我们来仔细看看GenPept格式文件的条目,如图5-15所示,所包含的条目的详细信息主要包括以下内容。
①Locus(位点信息)主要列出了蛋白序列在数据库中的身份证号码——Accession number(登录号:BAD92851),序列长度(1482aa,aa为氨基酸残基),序列为linear(线性),来源于哺乳动物(PRI,Primate的缩写),序列的提交日期是2009年9月12日。
②Definition(描述)是对序列的简单描述,事实上常常就是给出序列的完整名称。
③Accession和Version分别给出序列的登录号(Accession number)、版本号(Version)及其Gene Identifier(GI)。
④Source给出了序列的物种来源及其相应的分类信息,如本例中为人(Homo sapiens),分类信息都是用拉丁语描述的,我们不必深究。
⑤Reference(参考文献)则给出了与序列相关的参考文献的信息,或者期刊文章或者是其他格式的文献,对应每一篇参考文献有对应的Author(作者)、Title(文献标题)、Journal(期刊)等。
⑥Comment给出的是序列的一些注释信息,例如本例给出的是支持本工作的项目(Project)的一些信息。
⑦紧接着的是Feature,其给出了一些序列特征信息,例如Source(来源与其他数据库链接)、Region(对应于不同结构或者功能域的片段以及功能等相关信息)。
⑧最后是从Origin(起始)开始后面的真正的蛋白序列,每60个氨基酸残基为一行,结束后有一行结束符“//”。
(10)接着我们再来看看相关的基因信息,从Links(链接)弹出菜单中选择Gene(基因),就可以得到如图5-16所示的信息。Summary(小结)部分给出包括official symbol(学名)、Official Full Name(完整的学名)、Primary Source(主要来源)、Gene type(基因类型)、Organism(物种)和Summary(概括了该基因编码蛋白的功能以及与老年痴呆症的相关性)等信息。第二部分Genomic regions(基因组区域)、transcripts(转录本)和Products(产物)给出了基因组序列、以及转录RNA产物、蛋白翻译产物的详细信息及链接。后面部分则给出了更加详细的一些关于genomic context(基因组上下游)、Bibliography(参考文献)、Interaction(与其他基因相互作用列表)、marker(遗传标记)、Homology(同源基因)、Pathway(代谢通路)等一系列的信息,这里略过,同学们有兴趣的自己去阅读。

图5-16 人Alpha-2巨球蛋白突变体的GenPept详细信息
(11)图5-16给出的是有关A2M基因的Full Report(完整报告),但有时候我们只想要获取其基因的结构信息,也就是想要了解基因哪些片段是编码蛋白质的(也就是所谓的Coding Exon,编码外显子),哪些是可以转录为成熟RNA的(Exon,外显子),而哪些不包含在成熟的转录产物中(intron,内含子),这时可以用一种比较简洁的方式来呈现相关的信息,这就是Gene Table(基因表)格式,选择Display(显示格式)后面的下拉菜单,选择Gene Table就可以得到图5-17的格式,继而可以得到图5-18的结果。
思考题
①该基因包含多少个内含子(intron),外显子(exon)呢?
②是否外显子都是编码蛋白质的?如果不是,哪几个外显子具有不编码的部分?这些外显子中,不编码蛋白质的长度分别是多少?
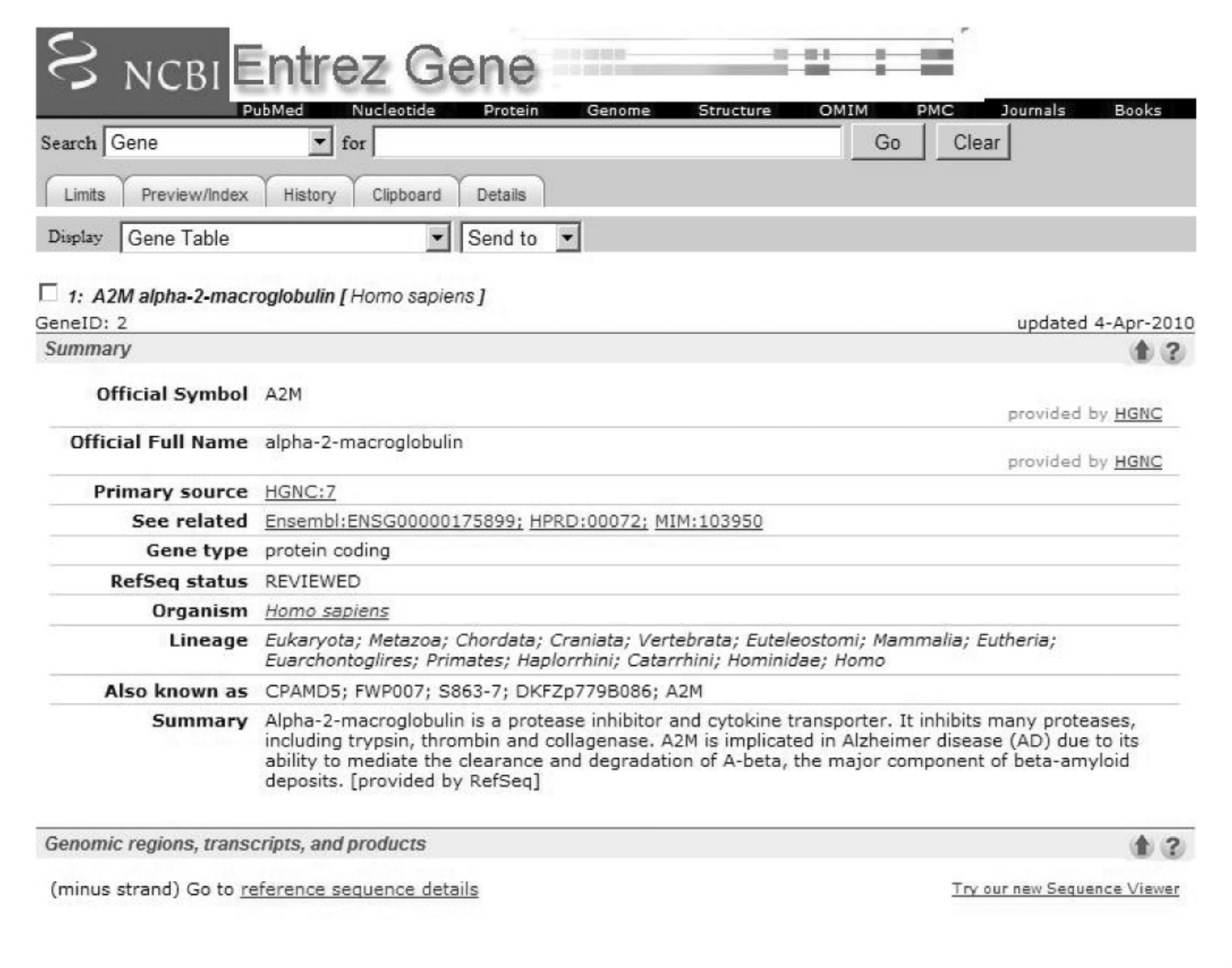
图5-17 人Alpha-2巨球蛋白突变体基因(A2M)信息

图5-18 人Alpha-2巨球蛋白突变体(A2M)的基因结构信息
③我们都知道三联密码子(triplet codons),也就是说每3位核苷酸编码一个氨基酸。那么,根据你的观察,每个编码蛋白质的外显子(coding exon)长度都是3的倍数吗?
2.实验小结
本实验从广受关注的一种常见疾病——老年痴呆症出发,介绍了诸如OMIM、GenBank等一系列位于NCBI的网络数据库资源,帮助同学们熟悉网络数据库的常用检索方法。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









