



数字信息资源组织的现代发展
胡昌平1 张 敏2
(1.武汉大学信息资源研究中心;2.西南大学计算机与信息科学学院)
【摘 要】网络世界中发现知识、获取知识和利用知识都与数字信息资源组织直接相关。本文探讨了信息资源组织方式与技术的演化,分析了信息资源组织中的内容揭示与控制,同时,就信息资源开发中的知识描述与组织进行了探讨。
【关键词】网络环境 数字信息资源 信息资源组织
The Modern Development of Digital Information Resources Organization
Hu Changping1 Zhang Min2
(1.Center for Studies of Information Resources of Wuhan University)(2.The School of Computer and Information Science of Southwest University)
【Abstract】In the network world knowledge discovery,the knowledge acquisition and the knowledge use are all related with the digital information resources organization.This paper has discussed the evolution of information resource organization way and technology,has analyzed content revelation and the control in the information resource organization,simultaneously,discussed knowledge description and theorganization in the information resource development.
【Keywords】network environment digital information resource information resource organization
信息资源的组织发展不仅体现在组织方式演化与技术发展上,而且反映在信息资源组织中的内容揭示与控制,以及信息资源开发中的知识描述与组织的进展。
1 信息资源组织方式与技术
尽管网络信息资源具有许多不同于传统信息资源的特点,但信息方面开发方法与原理具有相同之处,即借助一定符号系统实现信息的有序化。信息序化方法大致可分为三类:语言信息序化法(如号码法、时序法等)、语义信息序化法(如实物、图表、概念等)、语用信息序化法(如权值法、逻辑排序法等)。还有的研究者结合网络信息资源组织开发的现实,将网络信息资源组织与开发形式归纳为:超文本方式、搜索引擎方式、索引库方式、元数据方式、图书馆编目方式等。从结构上看,网络信息资源的开发可划分为三个层次:网上一次信息、网上二次信息和网上三次信息的组织与开发。其中,网上一次信息的组织开发方式主要有:文件方式、超媒体方式、数据库方式;网上二次信息的组织与开发方式主要有:搜索引擎、主题树、图书馆编目方式、数字图书馆等;网上三次信息开发的规模还有限,主要是以超文本说明的形式辅助用户掌握并利用网络检索工具,以便进一步获得信息。
下面根据因特网的技术特点、网络信息资源的特征与构成以及用户对网络信息资源开发与利用的需求,将网络信息资源开发形式归纳为以下几类。
(1)文件组织
它是网上数字化信息资源的一种主要存储与开发形式,以文件方式组织的网上数字化信息主要有文档文件、图像文件、音频文件、视频文件四种类型,常见的文件格式有:HTML、PDF、PS、DVI、SGML、XML、TXT、DOC、WPS、RTF、BMP、GIF、JPG、PSD、TIF/TIFF、3DS等。
基于本文组织方式的网络信息资源的开发具有两方面的优势:
·简单易操作。计算机有一整套文件处理的理论与技术,在开发网络信息时可以非常容易地利用这些成熟的技术和方法。
·文件方式是存储非结构化信息的自然单位。由于计算机处理的所有最终结果都能以文件的形式保存下来,因而对于图形、图表、音频、视频等非结构化信息,可以方便地利用文件系统来管理。正因如此,以文件方式来管理和开发信息资源在今天仍然使用频繁。因特网也提供了诸如FTP之类的协议来帮助用户传递那些以文件形式保存的信息资源。
文件方式的不足之处主要有:
·随着网络信息资源利用的普及和信息量的增加,以文件来传递信息会使得网络的负载越来越大。
·对结构化信息管理与开发显得不足。文件系统只涉及信息的简单逻辑结构,当信息结构比较复杂时,难以实现有效的开发。
随着以文件形式保存和管理的信息资源增多,文件本身也需要作为对象来管理。因此,文件只能是网络信息资源管理与开发的辅助形式,或者作为信息单位成为其他信息组织的管理对象。
(2)编目组织
如何组织和管理网上信息资源,人们一直在努力探索。目前,图书馆编目已成为一种组织网络信息资源的方式,它用传统的机读目录格式来组织整理网络信息资源。OCLC因特网资源编目计划是较为成功的典型例子。1993年4月,OCLC和美国国会图书馆联合发起了一项建议,修改USMARC书目格式适应因特网络资源编目的要求。修改的主要内容之一就是建立新的MARC856字段——“电子网址和索取”,用以著录因特网络资源的获取方式及其获取的必要信息,如电子邮件、文件传输、远程登录、主机名称、存取号码、文件大小、电子格式、操作系统等。这些都为网上资源编目的展开奠定了基础。
网上资源编目旨在对网络资源进行编目。分为三个步骤:第一,选择网上资源,填写“网络资源著录申请表”;第二,由编目人员对网上资源进行编目;第三,由系统工作人员将确切的网址和检索方式添加到有关字段中。
由于网上信息的修改、变动,人们要时刻关注字段相关内容的变化,致力于其技术研究与发展。
(3)目录指南组织
目录指南方式,又可称为主题树方式,组织信息资源的方法是将信息资源按某种事先确定的主题分门别类地加以组织,用户通过浏览的方式层层遍历,直到找到所需的信息的线索,再链接到相应的网页,代表性的目录指南方式搜索引擎有Yahoo等。
目录方式的优点是信息的专题性较强,信息质量高,且能较好地满足族性检索的要求,用户按规定的范围分类体系,逐级查看,按图索骥,目的性强,查准率高。目录指南方式屏蔽了网络资源系统相对于用户的复杂性,提供了一个基于树浏览的简单易用的网络信息检索与利用界面,并且具有严密的系统性和良好的可扩充性。
该方式也存在一些不足。一方面,由于网络信息资源的海量,使得很难确定一个全面的范畴体系作为目录指南结构的基础,来涵盖所有的网络信息资源。另一方面,用户为了迅速地找到所需信息还须对相应的体系有较全面的了解,这就增加了用户的智力负担。再者,要保证目录结构的清晰性,每一类目下的条目也不宜过多,这就大大限制了所能容纳网络信息资源的数量。
因此,目录指南结构不适合建立大型的综合性的网络资源系统。但在建立专业性或示范性的网络信息资源体系时,就显示出其结构清晰、使用方便的优点。
(4)超媒体组织
这是一种基于知识单元的新型信息组织方式,它借助超文本技术来实现。超文本技术是一种非线性的多媒体信息网络结构和信息管理技术,它将文本信息存储在无数节点(Node)上,一个节点就是一个相对独立的“信息块”,节点之间用“链”(Link)连接。超媒体方式不但可以链接文本,还可以链接声音、图像(形)、影视等多媒体信息,因此,它具有极强的包容性和可扩充性,能体现文献间的引用与被引用关系。随着未来超媒体技术的进一步发展,超媒体方式必将是未来信息组织的发展方向。
超媒体优势在于:
·非线性编排,符合人们思维联想和跳跃的习惯。
·节点中的内容可多可少,结构可以任意伸缩,具有良好的包容性和可扩充性。
·这种方式可组织各类媒体的信息,方便地描述和建立各媒体信息之间的语义联系,超越了媒体类型对信息组织的限制。
·通过链路浏览的方式搜索信息,将信息控制机制融合进系统数据中,避免了检索语言的复杂性。
超媒体方式的不足之处在于:
·采用浏览方式进行信息搜寻,当超媒体网络过于庞大时,难以迅速而准确地找到真正所需要的信息。
·很难保存遍历过程中所有的历史记录,在需要时不能立即返回到曾经浏览过的某一节点,即出现“迷航”现象。
(5)数据库组织
所谓数据库方式,就是将因特网信息资源以固定的记录格式存储,并提供一些检索入口,用户通过检索入口就可以找到所需要的信息线索,并利用超级链接功能直接链接到相关站点或原发信息本身。这种组织方式利用数据模型对信息进行规范化处理,利用关系代数理论进行数据查询的优化,从而大大提高了数据的可操作性,因而成为一种被广泛使用的网络信息资源组织方式。
利用数据库技术组织网络信息资源具有如下优势:
·数据库技术利用严谨的数据对信息进行规范化处理,利用成熟的关系代数理论进行信息查询的优化,从而大大提高了信息管理效率。
·数据的最小存取单位是信息项(字段),可根据用户需求灵活地改变查询结果集合的大小,从而大大降低了网络数据传输的负载。
·以数据库技术为基础已建立了大量的信息系统,形成了一整套系统分析、设计与实施的方法,为人们建立网络信息系统提供了现成的经验和模式,因此,数据库方式是当前普遍使用的网络信息资源组织方式,特别是在大数据量的环境下,其优势更为突出。
数据库方式的不足之处在于:
·对非结构化信息的处理困难较大,对网络环境中日益增加的多媒体信息及表格程序、大文本等非结构化信息的组织处理能力较差。
·无法有效处理结构日益复杂的信息单元。随着网络信息单元的结构日益复杂,关系数据库难以表示复杂信息对象的语义。
·关系数据库系统的检索结果以记录集合的形式出现,必须由应用程序将之进行适当处理,方能以较直观的方式提供给用户,因此,缺乏灵活易用的界面。
为了满足利用数据库技术处理非结构化文本信息的需要,人们试图对全文文本进行结构化处理,并用数据库技术对经过处理的文本信息进行管理,我们称为全文数据库。它是将一部书,一篇文章或杂志报纸中的全文输入计算机,使之成为计算机可以阅读处理的文本。这种文本数据库在全文检索软件的支持下,对文本中的各种大小知识单元——关键词、作者、篇名,甚至全文中的每一字段进行检索,并可按用户的需要,对检索的结果按章节、段落、句子等形式输出。因此,全文数据库广泛应用于组织网上一次信息,特别是非结构化的文本信息。
(6)搜索引擎组织
搜索引擎方式是目前网上二次信息组织最常用的一种方式,它不是人工构建的,而是依据计算机软件程序来进行运作的。它根据TCP/IP网络协议在网上漫游,发现新的网址、网页信息,然后对有用的信息进行抽取、排序、归并后建立网络索引数据库。网络索引数据库按一定方式、结构存储,并提供特定处理系统需要的相关信息,如网址、一些相关性描述的信息和一些可被计算机识别的字段字符等。这种方式的自动化程度高,更新速度快,并可提供位置检索、概念检索、截词检索、嵌套检索等多种检索方式。但用户查检到的信息内容过于庞杂,需要的与不需要的信息都堆积在一起,需用很多的时间来加以辨别与筛选,查准率较低。
自动搜寻引擎主要有自动搜寻网络资源、自动索引、自动摘要、提供检索方法和用户界面等部分。我们把这种自动搜索工具称为网上机器人(Spider或Robot)。这类自动代理软件定期或不定期在网上搜索,通过访问网络中公开区域的站点,对网络信息资源进行收集,然后利用索引软件对收集到的信息进行自动标引,创建一个可供用户进行按关键词查询的Web页数据库。这种数据库一般有标题、摘要或简短描述、关键词和URL、文件大小、语种以及词出现的频率与位置等信息。由于是自动搜寻,这种方式的不足之处是收录的信息良莠不齐,耗费大量的计算机资源,查全率高但查准率低等。用户输入自己的检索式,由搜索引擎自动将其与存储在网上的一次信息特征进行比较匹配,将符合用户要求的网上一次信息的描述记录以超文本方式显示出来。搜索引擎“命中”网上一次信息动辄上百成千,因此越来越多的搜索引擎提供二次检索功能,以及对检索结构进行再处理的功能,如按用户要求进行排序,或者按符合用户检索式要求的程度由大到小排列出结果等。
(7)Web 2.0环境下的协同信息组织
在Web 2.0的相关技术中,直接应用于信息组织的主要技术有:博客(Blog)、简易聚合(RSS)、维基(Wiki)和标签(Tag)等,它们都为网络用户提供了创建、组织、发布、更新和共享信息的开放式技术平台。2007年,学者们在继续研究以上这些技术的实际应用的同时,还将焦点集中在Web 2.0环境下新的信息组织技术的开发上。
协同分类(Folksonomy)是带有Web 2.0思想的社会性软件,它容许使用者采用任意自由词对资源进行标注,即将描述内容主题的权利赋予一般使用者,使用者在查找资源的时候不再完全依赖分类法,而是可以根据其使用习惯描述存放的内容[1]。2007年图书情报界集中研究了协同分类法的应用。Sinclair,J.和Cardew-Hall,M.深入地对标签云(TagClouds)是否能用于发现资源、信息检索进行了讨论[2]。他们通过实验发现,用户在进行一般信息检索时,更乐于使用标签云。标签云的方式对于浏览和资源发现具有重要意义,并能够提供数据库内容的可视化聚合。此外,混搭(Mashup)是Web 2.0的另一核心思想,利用网站提供的Web Service服务,经过重新组合,将可以用来重新调用和转化的数据以无缝的方式链接呈现给使用者。2007年,国外图书情报界继续利用混搭的理念更好地进行信息组织实践活动,从而提升图书馆服务。
2 信息资源组织中的内容揭示与控制
信息资源控制是将无序的信息资源按其外部特征和内容特征有序化,然后进行重新组织与控制的活动,其目的在于提供可控性的高效信息服务。信息资源控制的直接产物是各种信息存储与检索工具和系统。在信息资源组织揭示中,为充分地开发和利用信息资源,要利用先进的信息组织和开发技术,对信息资源进行多维的揭示。
2.1 信息资源控制的基本含义
人类社会的每一名成员总是根据自己的需要接收和利用某些特定信息资源。用户获取和利用信息资源的过程是一个复杂的随机过程。信息的自然产生造成了人类信息量的堆积。由于信息的自然老化及在信息系统中表现的量的增长和紊乱程度的加剧,人们引进了热力学中的“熵”的概念来描述这一现象。它说明,信息系统呈现“熵”增加的自然规律。面对信息增长和老化,用户利用信息愈来愈困难。如果不对信息资源流通过程及其相关活动进行有效控制,势必导致人类信息利用率的下降。
为了维持或提高人类对信息资源的利用率,保证用户对信息的正常使用,必须对其进行全面控制,使信息资源流通与利用科学化和有序化。控制的基本含义不仅仅局限于信息资源客体本身,它包括了以信息资源为中心的各种控制,其主要内容有:①信息资源客体控制(简称信息资源控制);②信息资源过程控制;③信息系统与工作控制;④信息用户及其活动控制。其中,对信息资源客体控制是基本的。
信息资源控制主要通过有序化工作来实现。它包括用户使用信息资源时对信息资源的自然有序化和信息工作者对信息资源加工有序化两方面。自然有序化伴随着信息资源传递与利用者的思维过程,表现为人们对信息资源的自然选择、排序、评价、吸收等过程。在社会的图书、信息工作产生之前,自然有序化是人类控制的主导方面;在社会信息工作产生之后,它仍不失为一种重要的控制形式。在这一原始的控制中,其有序化标准是复杂的,人类的个体差异决定了按知识结构、信息需求、信息价值等方面的特性对信息资源进行系统有序化工作。然而,社会的信息工作源远流长,社会发展的不同时期,对包括文献信息在内的信息资源加工有序化工作有着不同的内容,存在着多种有序化方式。
信息资源过程控制是一个基本的控制问题。它包括信息资源产生过程的控制、交流与流通过程控制、加工过程控制和利用过程控制等。从宏观上看,过程控制的结果关系到信息工作社会基础的优化;从微观上看,过程控制的效果又直接影响着实际效益的发挥。
长期以来,信息系统与信息工作控制属于工作管理的范畴。但是,随着社会的发展,这一控制显得愈来愈重要。对于一个国家来说,其控制水平往往是信息业发展水平的标志。信息系统与信息工作控制的内容十分丰富,涉及对系统与工作的全面控制以及对所有环节的控制,关系到社会模式的优化。
用户及其活动控制主要指部门对用户及其活动的管理控制规划。用户既是信息资源的使用者,又是新信息资源的创造者。简而言之,用户是信息资源得以存在并具有实际价值的支柱。一般说来,用户及其活动控制的内容包括用户管理、心理控制、行为控制及活动规划等。在控制中,以上四个方面的控制问题是密切相关的,在解决某一方面的控制问题时必须同时考虑其他方面的影响。
2.2 文献信息资源控制理论及其发展
1949年,美国学者伊根(M.E.Egan)和谢拉(J.H.Sheran)发表了《书目控制引论》一文。第一次提出了书目控制的概念。书目控制的目的在于提供文献内容的可检索性和物理可利用性。目前,国际上对书目控制的定义很不一致。联合国教科文组织和美国国会图书馆曾将书目控制定义为:“控制掌握书目所提供的人类已出版的文献,达到书目原有的目的”。此后,人们从不同的角度对书目控制下了各种定义。这些定义反映了书目控制的某一或某些特征。尽管人们对书目控制有着不同的说法,但从总体上可对它作这样的理解:通过目录形式扼要提取文献内容,经过科学排列将文献主要信息有序化,向人们提供索取文献的各种可能的线索。书目控制的主要内容可以概括为编目和排序,其主要控制方法则是分类法、主题法等。
事实上,文献信息的书目控制工作可以追溯到古代。在人类第一部书目问世之时便已产生了文献信息的书目控制活动。当时人们所偏重的只是自然的目录编制工作,即通过书目工作实现文献信息的有序化。中国古代的《别录》、《七略》等都是当时的书目巨著;西方卓有成效的书目工作在文艺复兴时代发展很快。显然,当时的书目工作是以古典目录学理论为指导的,但它作为一种思想,与目前所说的“书目控制”没有本质区别。它反映了人类从很早时候起就企图利用书目来有效地揭示、掌握文献信息的事实。古典书目工作在人类最初的知识控制、交流与利用方面取得了成功。
随着人类社会的进步和科学技术的发展,文献信息量急剧增长,简单的目录工作已不适应人类对文献信息的有序化要求。一方面,人们要求较高程度的有序化;另一方面,又希望文献处理中所损失的信息量不至于太大。于是,在文献目录存在的同时,出现了文献索引、题录,随后又发展了评论文献系统。在此基础上,人们致力于书目控制理论的研究,逐步形成了目前的状态。
评论文献在文献信息总体控制中的作用是值得重视的。评论文献是对原始文献信息进行系统研究的产物,是对文献信息的一种高级有序化,是一种指导人们去掌握相关文献信息的概括性和制约性文献。评论文献与原始文献存在着一定的控制比。在文献信息数量激增的情况下,如果评论文献不相应增长,势必影响对原始文献的总控制,将导致文献利用效率的下降。在科学技术领域内,评论文献与原始文献之间存在着最佳的数量比(有人认为基础科学的比值为1∶40)。过高的比值虽然有利于提供原始文献线索,然而由于评论文献总体熵的增大,将降低控制的稳定性和可靠性。因此,保持评论文献与原始文献之间较佳的数量比,提高评论文献的质量,是确保控制有效的关键。
目前所说的文献信息的书目控制,就是书目系统按一定的预期目标,对输入信息进行处理、约束和调节的方式与方法。它的特点是,确认每一书目活动机构均为同外界具有广泛联系的动态系统,而不是孤立静止的工作单元。如果将文献信息的控制分为层次,则可概括为:直接控制;书目控制;评论控制。这三方面的控制相互补充,形成整体。
现代电子计算机技术和通信技术的发展为书目控制提供了强有力的工具,在一定程度上引起了书目控制系统的变革。联合国书目信息系统(UNBIS)是一个对联合国出版的全部文献和联合国所需的外界文献进行全面书目控制的文献信息系统。它于1977年开始运行,其主要目的是通过书目控制来扩大对联合国各机构的信息参考服务。该系统显示了完备的书目控制系统的特点,是一个既进行描述控制,又进行检索控制,并具有反馈功能的书目控制系统。目前,世界上存在着各种自动化检索系统(如DIALOG、ORBIT、ESA IRS等)。这些系统的建立和运行不仅在一定程度上满足了人们对文献信息检索的需求,而且丰富和发展了文献信息控制理论。它们的存在和发展,提出了新的信息控制模式问题。
文献信息资源是一种主要的信息资源,对此研究较多,在其他信息资源控制中,人们亦采用了类似于文献信息资源书目控制的方法。对信息过程、信息系统和信息用户等方面的控制,基本上也是以书目控制为核心的。例如,人们总习惯于按文献信息资源的类属来划分信息用户类型,进行用户管理中的控制工作;在文献信息资源交流过程中,大部分工作也离不开书目控制理论的指导。这些事实说明,以书目理论为基础的信息控制,实际上是以文献信息流的书目控制为基础的多层次控制,属于传统的管理控制范畴。
当前,书目控制理论在信息资源控制中的应用正处于变革之中,人们正在多方面进行新的管理控制方法的应用研究。由于传统的书目控制理论运用于信息资源控制存在着局限性,这就是当代信息资源控制得以迅速发展的原因。
2.3 基于信息内容揭示的资源控制深化
传统的文献控制方式可归纳为“外部描述控制”和“内容特征控制”两类。“外部描述控制”通过文献外表特征的揭示将文献信息有序化,以达到控制文献的目的,其中的描述内容包括作者、时间、类型、来源等。理论研究和实际工作的结果表明,这种描述控制是完全可以实现的。“文献内容控制”远比“外部描述控制”复杂,这是一种通过文献内涵知识信息的揭示所进行的实质性控制,是文献控制的主体和核心。鉴于知识结构和演化过程的复杂性,其基本问题作为传统目录学、文献学和现代知识信息处理理论的中心,是学术界和实际工作部门长期探讨的主要课题。
在社会信息化时代,知识的指数增长、科学技术的微分化和积分化趋势、知识信息无序状态的加剧,造成了用户利用文献内涵知识的困难。与此同时,建立在高科技基础上的现代产业模式又迫使人们吸收和利用范围更广、起点更高的知识信息资源。与社会的知识信息利用模式相对应,社会的信息服务开始进入以提供知识信息为主的发展阶段。此外,现代电子计算机技术、通信技术和远程数据处理技术的发展,使文献内涵信息的全面提取、组织、加工和利用得以实现。基于信息内容揭示的信息资源控制体现在以下方面的深化和发展:
(1)控制内容的知识单元化发展
文献信息资源记录的知识内涵丰富,从应用角度和知识产生角度看,它并非如布鲁克斯所描述的静态结构,而是具有动态结构的特征。从知识的性质上看,文献单元相对静止,而知识单元是动态衍变的,一篇文献不仅包含了许多知识单元,体现了知识单元之间的各种有机联系,而且反映了文献作者对各种知识的处理、加工、思维和推理过程,反映了知识的演化。文献信息资源所含的这些动态性信息,对于使用者来说甚至比静态知识结构信息(如结果)更重要。事实上,在现代科学技术条件下,用户利用文献往往不是为了查询单一的、固定的知识概念,而是为了借鉴文献并未明确表达的作者思维和创造活动的方法,从中得到启示,引起灵感。对于这种知识过程的揭示,任何静态控制方式都显得无能为力,其问题的解决必然求助于新的模式。
迅速普及的网络技术和数字技术使任意层次的任意信息元素、信息单元和信息集合体系正在逐步以计算机可识别和可理解的方式被定义、描述、指向、链接、传递和动态组织。信息资源内容揭示的对象不仅停留在对信息特征的描述,而且深入到知识单元,信息资源内容揭示的深度和广度都极大地拓展,通过多层次、多方位的描述与揭示控制信息资源,促进信息资源的合理利用。当前,信息资源控制的内容已从文献整体控制向知识单元及其知识组织控制方面延伸,因为知识产生、老化和利用周期缩短,最新知识信息控制已成为信息资源控制的重点。同时,语义Web技术的出现及其在信息资源组织与控制中的应用,带来了知识揭示与组织工具的变革,重构了知识组织控制体系,知识组织从物理层次上的文献单元上升到认知层次的知识单元,从单纯的语法处理(主题法、分类法)转变为语义处理(如专家系统、语义网络表示法),从语义处理到“模拟个体知识记忆结构”考虑语境的语用处理方式;知识组织消除了含混性和歧义性,其传递的语义直指语用,可以更好地为用户提供易于理解、准确无误的语用服务[3];基于内容揭示的资源控制必将实现“语法-语义-语用”的新跨越发展。
(2)控制方法的集成化发展
在信息资源内容控制中,分类法和主题法(包括由此派生的关键词法、叙词法和元词法等)是文献信息资源控制通用的基本方法,其要点是按一定的知识处理法则将文献有序化。分类法在揭示文献所含知识方面,虽然具有较强的系统性,但是缺乏应有的灵活性和揭示深度;主题法从某种程度上弥补了分类法的缺陷,却显得系统性不够。当前,科学技术高度发展,其知识领域愈分愈细、愈来愈专。与此同时,任何一个狭窄的专门领域又必然涉及多方面的知识门类。这一现实在文献中的体现便是文献内容(知识)的高度专门化与高度综合化趋势的并存。科学技术和其他知识领域学科发展中的“微分化”与“积分化”效应是人类知识高速增长、迅速分化和组合的结果。面对人类知识生产的变化,无论是分类法还是主题法,分别用于控制信息资源的效果必然会愈来愈差。
传统书目控制的局限性表明,在信息资源内容控制中必须借助多种方法和手段的集成运用,必须求助于普遍适用的控制理论。信息资源的充分开发与利用和人类信息实践的极大丰富,为信息资源控制理论与方法的发展和完善奠定了实践基础,现代信息技术和通信技术的发展,为信息资源的集成控制提供了必要的物质和技术条件。
如图1所示,在以本体为核心的语义Web技术的驱动下,信息资源内容控制方法不再仅仅局限于传统的分类法、叙词表、编目规则等,而是出现了能够更好适应数字环境的新型知识组织工具:概念地图(Concept Map)、语义网络(Semantic Network)、实用分类法等。语义Web技术在信息资源内容控制中的应用,为信息资源控制提供了新的思维方式和新的理念,基于信息内容揭示的资源控制方法必将随着信息资源揭示与组织技术的发展而不断深化拓展,网络环境下信息资源的控制必然是多种方法的结合使用。
(3)控制主体的多样化发展
在信息资源的内容控制中,无论是传统的分类法或是主题法(关键词法、单元词法和叙词法等),还是用于数字资源描述与揭示的元数据,大多由专业人员制定和标引。网络环境下,数字化存储、网络途径获取已成为人们利用信息资源的主流方式,信息资源的控制对象也随之扩展到专业不同、层次各异的各种终端用户。基于信息内容揭示的资源控制逐渐呈现出开放性、共享性、交互性的特点,体现专业化与社会化并存的发展趋势。

图1 知识组织系统的发展[4]
以下我们通过元数据和大众分类法的对比分析说明信息资源控制的专业化和社会化控制的发展。
2005年初,大众分类法(Folksonomy)作为一种由用户参与和主导的信息资源组织控制方式[5],在Yahoo等门户网站迅速流行,与长尾(The Long Tail)、简单信息同步(RSS)、博客(Blog)、异步JavaScript、XML(Ajax)和播客(Podcast)共同构成下一代互联网(Web 2.0)的核心要素。大众分类法是用户自发的用标签(Tag)对感兴趣的资料进行分类,并与他人共享标签的过程和结果。它扬弃了以往信息资源控制事先确定大纲的方式,由用户自由选择关键词甚至颜色来分类和描述信息内容。
作为网络环境下数字化信息资源的控制方式,如果说元数据是“关于数据的数据”(Data about Data),那么大众分类法就是“关于数据的标签”(Tag aboutData)。两者的出发点都是组织信息以便利用户的使用,但前者是通过专业人士和标准化推行,后者则更多依赖大众的参与和“重量级应用”。随着互联网上信息内容的快速增长、信息类型的日益复杂化,任何标准不但有“滞后”的风险,而且面临被公司或者产品“垄断”的危机。大众分类法虽然也存在滥用风险,但在使用和控制方面比元数据要简单得多,加上它面向互联网大众,简单易用[6],因此,当前大众分类法受到了广泛关注和推广运用。
如图2所示,左边的“元数据”通常是采用结构化、规范化或标准化的方式对“数字资源”进行标识,并且不是由使用者自己进行标识,已有标识“数字资源”的元数据规范标准有Dublin Core、LOM等,是由专业机构专业人员制定的。当前,由于元数据种类繁多,相互之间缺乏有效的互操作机制,一定程度上阻碍了元数据控制信息资源的应用推广;右边“Tag标签”是由用户根据个人需要在提交汇聚数字资源过程中,对数字资源加上个性化的标识说明,“Tag标签”是在应用过程中不断生成优化,而非采用预设的结构模式。基于标签的大众分类法降低了信息资源控制的使用门槛,但仍然存在不够精确、垃圾标签的处理以及商业应用等问题,目前正处于快速的演化升级过程中。
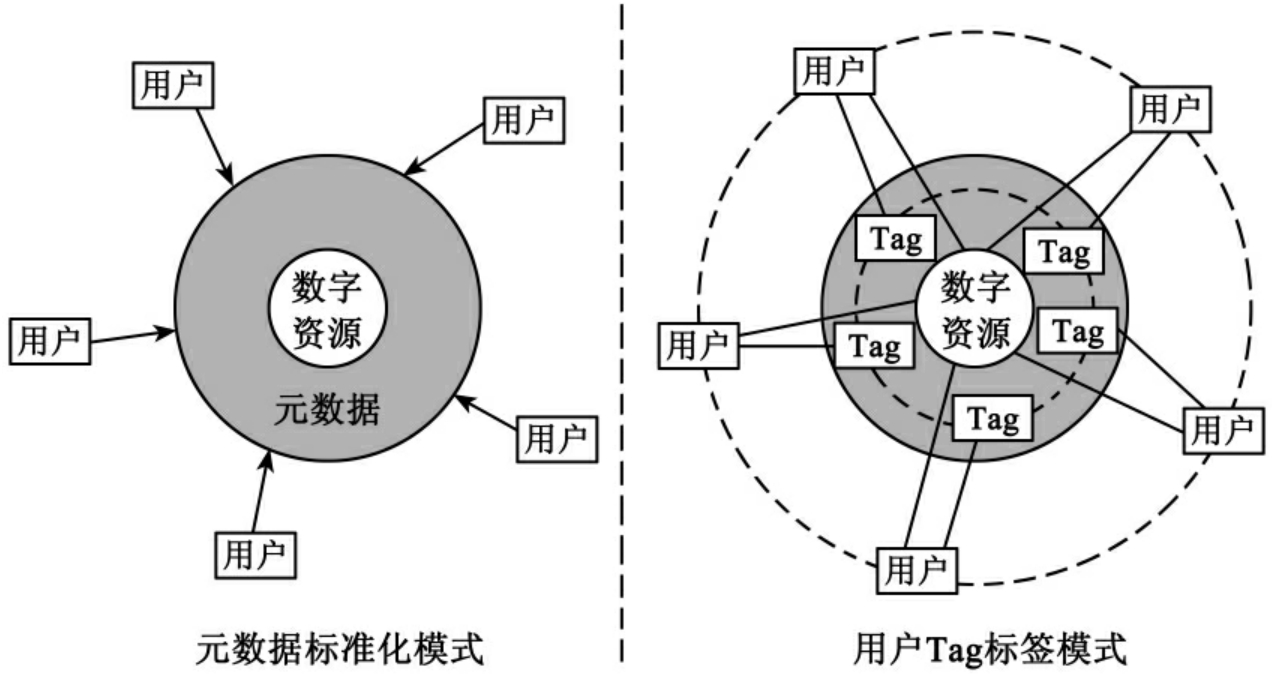
图2 元数据标准化控制模式与用户标签自由化控制模式[7]
事实上,在元数据标准化控制模式和用户标签控制模式中,“用户”应用的社会互联效应不同。在“用户Tag标签模式”中,用户不仅是信息资源的使用者,同时也是信息内容的建设汇聚者,在应用与建设“数字资源”与“Tag标签”的过程中,用户之间能够不断建立社会联系。
目前无论是元数据,还是基于Tag的大众分类法还没有从全局或者根本上解决信息资源的组织控制问题,从某种程度上讲,大众分类法提供了新的视角,来看待如何控制信息资源,以及用户的参与对信息资源控制的影响。总体而言,信息资源的控制总是处于有序和无序、标准和自由之间保持某种动态的均衡。
(4)控制技术的智能化的发展
目前的信息资源内容揭示主要以文献单元为基础和以数据(各种事实、概念、数值的总和等)单元为基础,但都是静态的、列举式的。未来的信息资源内容控制将以专家系统为基础,具有动态联系、判断、分析、比较、推理等新型的知识处理与组织功能。
解决信息资源智能化揭示与控制的主要困难,首先是信息按思维程序要求的有效排列和多方面处理之间的矛盾;其次是输入文献知识单元的显示和作用,以及人工智能的智能化水平的提高。尽管智能化信息揭示与控制系统的实现困难重重,然而人们从道金斯(Dowkins)等人的理论研究中,仍可以看到它的发展前景。
当代人工智能技术的发展也为信息资源的动态结构揭示和智能化控制提供了可能。当前不断发展的专家系统被称为体外大脑,其中的知识库相当于人脑的知识存储结构,是接受新知识的必要条件,其推理机构类似于人脑的特殊思维活动机制。专家系统对输入知识的处理和判断可以类比人对知识的处理过程。基于这一事实,如果向系统输入文献中的静态知识单元,并提出显示知识组织和推理的要求,则系统可以显示文献作者的推理和思维信息,而这正是所需求的动态知识信息。智能系统将知识揭示与文献控制融为一体,除提供动态知识外,还可以在更广的范围内进行知识组织与处理,将反映相关知识的文献进行有机结合,从而取得浓度很高的高层次信息。应该说,这是信息资源控制工作的一场变革。当前,这一研究尚处于初级状态,在某些方面仅仅存在某些学者和用户的设想。
人工智能技术和信息推送等新技术促进了信息内容的挖掘与深层次揭示,以更好满足不同用户的各种需求,提供个性化的信息服务。从信息中采掘知识,再将知识转变为社会财富,体现信息资源控制深化的方向,目的是向人们提供便于利用的、可以帮助解决问题的有序化的知识,实现从信息层次向知识层次的根本转变,组织的知识包括显性知识与隐性知识。
3 信息资源开发中的知识描述与组织
数据挖掘是面向用户的一项信息服务技术,在获取网络信息资源时,数据挖掘技术是处理网络上动态数据的一个极好方法,其目标是分布式、专业性、集成化搜集高质量信息资源。在网上进行数据挖掘需考虑的重要问题是不确定性处理、丢失数据处理、垃圾数据处理、有效算法及与专业相关的分类处理、知识处理、数据复杂性处理等。在线挖掘的相关问题是安全性、可执行性与灵活性。同时,基于数据挖掘的知识组织与管理技术是技术发展的核心方向。
当前,随着社会信息化发展,社会对信息资源控制质量提出越来越高的要求,信息资源控制的传统方式正受到来自各方面的挑战。传统分类法和主题法中的知识揭示与组织方式的局限性显得十分突出。其主要表现在:①难以适应科学技术微分化和积分化的趋势;②难以适应对信息内涵的全面揭示;③难以适应以知识单元为基础的智能组织系统的信息控制;④难以适应知识形成和演化过程的控制。
这些情况表明,研究新的信息资源组织与控制方式已成为关系信息资源工作全局的关键课题之一。同时,高技术的发展和新的信息处理技术的出现,使寻求高效化的信息资源组织与控制理论成为可能。其中,信息资源内涵的知识描述与揭示成为资源控制理论的新的生长点。知识描述与揭示常常取决于人类知识的结构及环境运行机制,它不仅决定了知识应用的形式,而且也决定了知识处理的效率和实现的域空间规模的大小[8]。
3.1 知识描述的基本方式
知识的描述与揭示是知识获取和利用的基础,只有确定了知识描述的恰当形式,才有可能将客观世界的知识有效地在计算机中表示,也才有可能让获取的知识充分发挥作用,同一知识可以有不同的描述表示方法,不同的表示形式可能产生不同的效果。
一般地,知识的描述表示模式为:K=F+R+C。
其中,K表示知识项(Knowledge Items)。
F表示事实(Facts):指人们对客观世界和世界的状态、属性和特征的描述,以及对事物之间关系的描述。
R表示规则(Rules):指能表达在前提和结论之间因果关系的一种形式。
C表示概念(Concepts):指事实的含义、规则的语义说明等。
为了把这些知识(事实、规则和概念)明白无误地用计算机所能接受的形式表示出来,必须建立一组约定的、利于知识编码的适当的数据结构,在计算机中存储起来。一旦计算机以适当的方式使用这些知识,就会产生智能行为[9]。
目前,知识描述的方法种类繁多,主要有:谓词逻辑表示法、产生式表示法、语义网络表示法、框架表示法、面向对象表示法等。以上所列的表示方法各有特点,没有绝对的优劣之分。只有根据求解问题的性质和方法灵活地选用合适的知识表示法,才能使信息资源控制取得较高的效率,因此知识的描述方法往往是多种表示方法的组合。
(1)谓词逻辑表示法
谓词逻辑表示法是指各种基于形式逻辑(Formal Logic)的知识表示方式,利用逻辑公式描述对象、性质、状况和关系,例如:
“宇宙飞船在轨道上”可以描述成:In(spaceship,orbit)。
“所有学生都必须通过考试才能毕业”可以描述为:
Ax(student(x)∧passed(x)→graduate(x))
基于逻辑的知识表示是最早的知识表示方法。它简单、自然、灵活、模块化程度高、理论严谨、表达能力强,同关系数据库一样具有坚实的数学理论基础,能够采用数学演绎的方式进行推理、证明,因此,在知识库系统及其他智能系统中得到广泛应用。在这种方法中,知识库可以看成一组逻辑公式的集合,知识库的修改是增加或删除逻辑公式。使用逻辑法表示知识,需将以自然语言描述的知识通过引入谓词、函数来加以形式描述,获得有关的逻辑公式,进而以机器内部代码表示。
谓词逻辑表示法的缺点是表达的知识主要是浅层知识,不宜表达过程和启发式知识,且难以管理,其证明过程易发生“组合爆炸”。
(2)产生式知识表示法
产生式知识表示法是依据人类大脑记忆模式中各种知识块之间大量存在的因果关系或“条件—行动”式,用“IF—THEN”型的产生式规则来表示知识的方式。由于这种知识表示方式接近人类思维以及交流的方式,捕获了人类求解问题的行为特征,并通过认识-行动的循环过程求解问题,因而得以应用到各种不同的领域。
产生式的基本形式为:P→Q或者IF P THEN Q
其中P部分成为前件,而Q部分成为后件。前件部分通常是一些事实的合取与析取,而后件通常是某一事实。如果考虑不确定性,则需要另附加可信度量值。
产生式的语义可以解释为,如果前件满足,则可以得到后件的结论或执行后件的相应结果,即后件由前件触发。一个产生式生成的结论可以作为另一个产生式的前提或语言变量使用,进一步可构成产生式系统。
例如:地上有雪─→汽车带防滑链;
发烧∧呕吐∧出现黄疸─→肝炎,可信度0.7。
在自然界的各种知识单元中存在着大量的因果关系,这些因果关系转化为前件和后件,用产生式规则表示非常方便。基于产生式知识表示法的突出优点是与人类的判断性知识基本一致,直观,自然,便于推理;规则之间相互独立、模块化好,因此,产生式方法是目前专家系统首选的知识表示方式。例如用于化工工业测定分子结构的DENDRAL系统,用于诊断脑膜炎和血液病毒感染的MYCIN系统,以及用于估计矿藏的PROSPECTOR系统等,都是用这种方法进行知识表示和推理。然而,产生式知识表示在不确定性推理方面还存在一定问题。
将一组产生式放在一起,让它们相互匹配,协同工作,一个产生式的结论可以供另一个产生式作为前件使用,以这种方式求解的系统就称为产生式系统。一个一般的产生式系统如图3所示,由知识库和推理机组成,而知识库又由数据库和规则库组成。
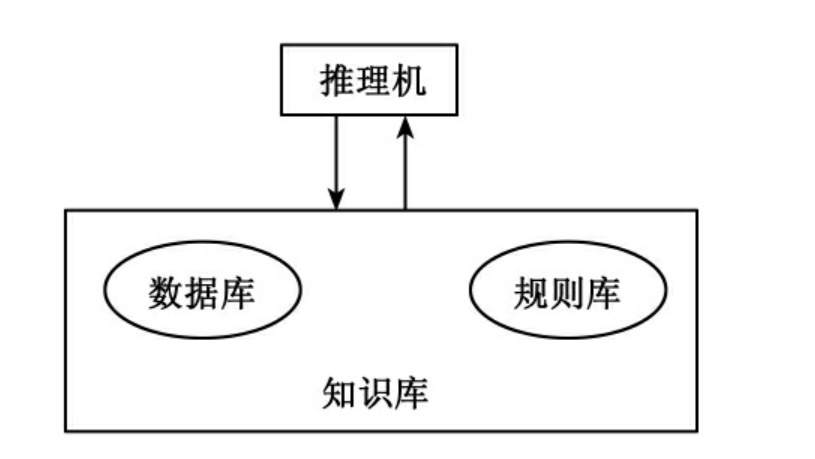
图3 产生式系统结构
(3)语义网络表示法
语义网络知识表示是一种用带标记的有向图来描述知识的形式。语义网作为人类联想记忆的显示心理学模型,由一些以有向图表示的三元组(节点1,弧,节点2)连接而成。节点表示各种事物、概念、对象、实体、事件等,带标记的有向弧表示所连接的节点之间的特定关系。图4给出了一个语义网的简单例子,其内容是“职员John拳击经理Tom”。
图4中,客体节点间存在的成员(个体)和包含(类、子类、子子类……)关系,分别用EL(Element)和“ISA”标志边来显示表达。
①John是一个职员表示为:
![]()
②职员是人的一部分表示为:
![]()
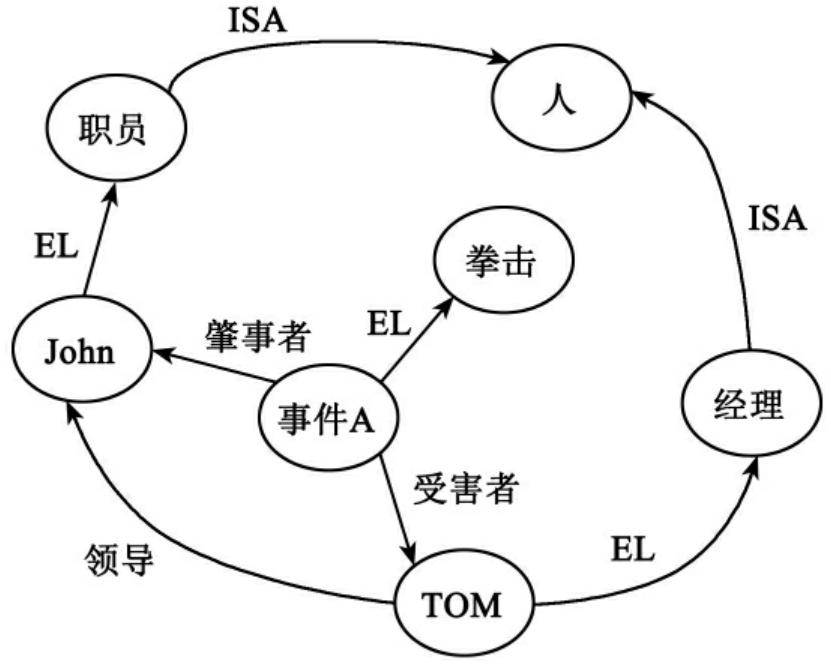
图4 语义网络知识表示的实例
语义网络描述各个概念之间的关系,除了上面讲到的ISA(表示“具体-抽象”关系)外,还包括PART-Of(表示“整体-构件”关系),IS(表示一个节点是另一个节点的属性),HAVE(表示“占有、具有”关系),BEFORE/AFTER/AT(表示事物间的次序关系),LOCATED ON(表示事物间的位置关系)等谓词表示。
在语义网络中,程序可以从感兴趣的任何节点出发,沿着弧到达相关联的节点,还可继续沿弧到达更远的节点,这种方法非常自然,类似于人类的联想记忆。但是,鉴于每个节点连接多条弧,当我们从开始节点出发后,如果没有很好地组织和强有力的搜索规则指引,就会容易陷入无穷支路而无解。
(4)框架表示法
框架知识表示是一种可以把对象的所有知识存储在一起构成的复杂数据结构。框架理论是明斯基(Minsky)于1975年提出的,将知识表示成高度模块化的结构。框架把知识的内部结构关系以及知识之间的特殊关系表示出来,并把与某个实体或实体集的相关特性都集中在一起。
框架由框架名和一些槽组成,每个槽可以拥有若干个侧面,而每个侧面可以拥有若个个值。这些内容可以根据具体问题的具体需要来取舍[10]。一个框架的结构如下:
<框架名>
<槽1> <侧面11> <值111>……
<侧面12> <值121>……
<槽2> <侧面21> <值211>……
…………
<槽n> <侧面n1> <值n11>……
为了能从各个不同的角度来描述一个事物,可以对不同角度的视图分别建立框架,然后再把它们联系起来组成一个框架系统。框架系统中由一个框架到另一个框架的转换可以表示状态的变化、推理或其他活动。不同的框架可以共享同一个槽值,这种方法可以把不同角度搜集起来的知识信息较好地协调起来。
框架系统和语义网络知识表示的不同之处在于,语义网络注重表示知识对象之间的语义关系,而框架表示法更强调对象的内部结构。由于节点(框架)集中了概念或个体的所有属性描述和关系描述,又可用槽作为索引,所以这两种方法在知识库检索时具有较高的效率,但是由于这两种结构化的知识表示方式在刻画真值理论方面过于自由化,容易引起二义性,而且由于结构化表示的复杂性,知识库维护需要付出更高代价[11]。
(5)面向对象的知识表示
用面向对象的类或对象表示知识的方法,都可以称为面向对象的知识表示。借助面向对象的抽象性、封装性、继承性和多态性,以抽象数据类型为基础,能方便地描述复杂知识对象的静态特征和动态行为。
面向对象的知识表示的一个重要特性是继承性。超类的知识可以被子类所共享,超类包含了各个子类的公共属性和方法,在建立子类对象时,只需表达子类的特殊属性和处理方法,各知识对象以超类、子类、实例的关系形成ISA的层次结构。复杂的知识类可以由此派生得到。
本质上,面向对象的知识表达方法是将多种单一的知识表达方法(规则、框架和过程等)按照面向对象的程序设计原则组成一种混合知识表达形式,即以对象为中心,将对象的属性、动态行为、领域知识和处理方法等有关知识“封装”在表达对象的结构中。这种方法将对象的概念和对象的性质结合在一起,符合专家对领域对象的认知模式。面向对象的知识表示方法封装性好、层次性强、模块化程度高,有很强的表达能力,适用于解决不确定性问题[12]。
3.2 知识描述与揭示的发展
随着网络技术的发展,语义互联网(Semantic Web)正逐渐将Internet变成一个巨大的全球化知识库。这个知识库为满足人们浏览信息的需要,必须通过标准的语义规范使计算机自动读取和处理信息资源,因此需要寻找新的,适合Web技术的知识描述和揭示方法,以便为基于Web服务的智能共享提供基础,并使网络能够提供动态与主动的服务。
语义互联网环境下,知识描述与揭示的主要技术有:可扩展标记语言(XML);资源描述模型(RDF/RDF Schema);主题图和概念本体(Ontology)等。
(1)基于XML的知识描述与揭示
XML(eXtensible Markup Language,可扩展标记语言)是SGML的一个简化子集,它将SGML丰富功能和HTML的易用性结合到应用中,以一种开放的自我描述方式定义了数据结构,在描述数据内容的同时突出对结构的描述,从而体现数据之间的关系。XML既是一种语义、结构化标记语言,又是一种元标记语言。XML主要包括3个元素:DTD(Document Type Definition,文档定义)/Schema(模式)、XSL(eXtensible Stylesheet Language,可扩展样式语言)和XLink(eXtensible eLink Language,可扩展链接语言)。DTD规定了XML文件的逻辑结构,定义了XML文件中的元素、元素的属性以及元素与元素属性的关系;XML通过其标准的DTD/Schema定义方式,允许所有能够解读XML语句的系统辨识用XML-DTD/Schema定义的文档格式,从而解决对不同格式的释读问题。XSL定义了XML的表现方式,使得数据内容与数据的表现方式独立;XLink是XML关于超链接的规范,XLink可以把一个节点和多个节点相联系,即实现一对多和多对多的对应,进一步扩展了目前Web上已有的简单链接。XLink使得XML能够直接描述各种图结构。这样由XML所表示的属性和语义再加上XLink,就可以完整地描述任何语义网络。由此可见,XML提供了一种统一的形式来描述逻辑、产生式、框架、对象等多种类型的知识表示方法,这样就能够把不同类型的知识融合在一个完整的知识库中。
XML为计算机提供可分辨的标记,定义了每一部分数据的内在含义。脚本(或者说程序)可以利用这些标签来获取信息,XML以一种开放的自我描述方式对信息模式进行定义、标记、解析、解释和交换。XML允许使用者在他们的文档中插入任意的结构,而不必说明这些结构的含义,还允许用户自定义基于信息描述、体现逻辑关系的“有效的”标记。XML使用非专有的格式,独立于平台,不受版权、专利等知识产权的限制,具有较强的易读、易检索和清晰的语义性,通过它不仅能创建文字和图形,而且还能创建文档类型的多层次结构、文档相关关系系统、数据树、元数据超链接和样式表等,实现多个应用程序的共享。
XML最重要的特点是能够用结构化方式表示数据的语义,所以利用XML能改善信息资源的控制效率。例如,一位用户输入检索词:莎士比亚。他有可能是查询莎士比亚的作品,也有可能是查询关于莎士比亚的研究论文,如果他能确定如下的表达:<Creator>莎士比亚</Creator>;<Subject>莎士比亚</Subject>,文档就能够用模式来分类,一个XML文档的模式确认了其结构和意图。这样,可以将搜索范围限定在与特定模式或感兴趣的模式匹配的文档,从而使检索结果更加准确。
(2)基于RDF的知识描述与揭示
RDF(Resource Description Framework,资源描述框架)是为描述元数据而开发的一种XML应用,特别适用于对元数据结构和语义的描述。RDF提供一个支持XML数据交换的主、动、宾三元结构,解决如何采用XML标准语法无二义性地描述资源对象的问题,使得所描述的资源的元数据信息成为机器可理解的信息。RDF通过资源—属性—值的三元组来描述特定资源(图5),包括有序对表示、图形表示和XML文件表示三种方式。
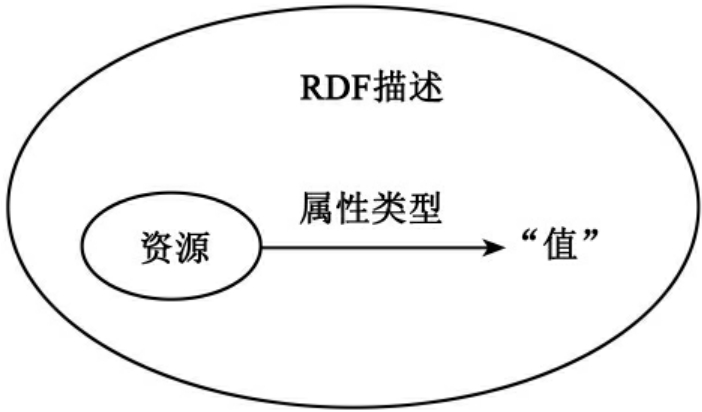
图5 RDF的基本数据模型
RDF以一种标准化的方式来规范XML,利用必要的结构限制,为表达语义提供明确的方式。RDF使用XML作为句法,故其在任何基于XML的系统平台上都可被方便地解析,这就构造了一个统一的人/机可读的数据标记和交换机制,从而从句法和结构角度提供了数据的交换与共享。
下面通过一个实例来说明基于XML/RDF的知识描述与揭示。所标记的资源是:“莎士比亚是戏剧《哈姆雷特》的作者”,如果它是通过http://hamlet.Org/引用,那么这句话用XML标记的完整记录如下:
<? xml version=“1.O”?>①
<rdf:RDF xmlna:rdf=“http://www.w3.org/1999/02/22-rdf-syntax-ns#”
xmlns:dc=“http://pur1.org/dc/elements/1.1/”>
<rdf:Description rdf:about=“http://hamlet.org/>②
<Title>哈姆雷特</Title>③
<dc:Creator>莎士比亚</dc:Creator>
<dc:Type>话剧</dc:Type>
</rdf:Description>
</rdf:RDF>
这是个简单的RDF,语句以标准的XML格式表示,遵循XML的语法规则。上例中①是XML声明语句,指出所使用的命名域及其URL;②是rdf的Description元素,指明资源通过http://hamlet.org/引用;③用dc的Tile、Creator、Type来表示标题、作者和类型,并附值为哈姆雷特、莎士比亚和话剧。这个例子的完成是先从分析信息对象开始,分解出信息对象的资源、属性、属性值,然后选用合适的元数据进行描述,采用Dublin Core作为元数据的语义规范、RDF为语法规范,最后以XML为表现或存储形式,这样在任何基于XML的系统平台上这条信息都可被方便地解析。
在RDF技术的基础上,W3C又提出了资源描述框架定义集(Resource Description Framework Schema,RDFS)。RDFS就是将实例信息中概念与概念之间的关系抽取出来,表示为知识库中的本体。它允许用户自定义除了RDF基本描述集合以外的特定领域的概念元数据集合,即本体(Ontology)。目前,已有一些通过RDFS来定义的通用知识库概念集合,如DublinCore、Ontology Inference Layer等。
(3)基于XML主题图的知识描述与揭示
XML主题图(XML Topic Maps,XTM)是一种用于描述信息资源的知识结构的数据格式,它可以定位某一知识概念所在的资源位置,也可以表示知识概念间的相互联系。一个主题图就是一个由主题(Topics)、关联性(Associations)以及资源实体(Occurrences)组成的集合体[13]。主题图将所有可能的对象,例如人、事、时、地、物等,不论此对象是具体存在的物质还是抽象的概念,均称为主题。从描述主题本身的属性开始,进而组织与此主题相关的所有资源,并对这些资源进行定位,最终将所有相关的主题,依据彼此间的关系及相对于该关联的角色,建构出一个多维的主题空间,在该空间中直观地展示了一个主题到另外一个主题的路径。
XTM最大的优点在于通过知识概念关联的显性表示来解决知识的可发现(Findability)。主题图表现方式除了直观地以图的方式展现外,还可以提供以被机器理解和处理为目标的标记语言的文件方式。XML基于ISO13250标准,定义了用XML描述和标记主题图的方式。由XML标记的主题图是XML文件,可开放地标记叙词表和语义网络。
如图6举例说明了主题图的逻辑结构,主题图将信息资源结构分为两层:资源域和主题域,其中资源域包括所有的信息资源,如电子文档、数据库文件、网页、电子书籍等;主题域是在资源域之上定义,包括所需的所有主题,如资源的名称、特性、类型等信息,可以对已经存在的数据库文件或XTM文档建立主题,设置主题之间的关系等。图6所示的一个知识构架中,可发现三种主题类别:人、药物和医疗器材,其中Topic1和Topic2代表“人”类别中的两个主题,Topic3代表一种药物,Topic4代表一种医疗器材。

图6 主题图的逻辑结构示意图[14]
四个主题之间包含三种关系:A1表示Topic1和Topic2之间的医疗关系,A2表示Topic1服用Topic3这种药物,A3表示Topic2使用Topic4这种医疗器材。各主题利用虚线指引与其相关的资源。
XTM中,主题间的链接可完全独立于资源域,即无论主题有无具体的资源,主题都可以存在。从物理上讲,主题图中并不存储各种实际的信息资源,但对其主题的关系实例的访问却可以检索到有关的实际资源,即指引用户到特定的地址获取所需的信息。这样就可以把网络上与某一或某些主题相关的节点进行集中,按照方便用户检索的原则,使用用户熟悉的语言组织起来,向用户提供这些资源的分布情况,指引用户查找。
XTM独立于技术平台,描述主题、主题关系以及主题与具体资源的联系,可“标引”信息资源并建立相应索引、交叉参照、引文体系等,可链接复杂主题范围的分布资源来建立虚拟知识体系,可通过主题概念与资源的不同链接在同一资源集合上定制面向不同用户的界面。
(4)基于本体的知识描述与揭示
知识本体是共享概念模型的明确的形式化规范说明。如果把每一个知识领域抽象成一套概念体系,再具体化为一个词表来表示,包括每一个词的明确定义、词与词之间的关系(例如用代、属、分、参关系)以及该领域的一些公理性知识的陈述,并且能够在这个知识领域的专家之间达成某种共识,即能够共享这套词表,所有这些就构成了该知识领域的一个“知识本体”。一个本体描述了一个特定研究领域的一个形式化的、共享的概念化模型。最后,为了便于计算机理解和处理,需要用一定的编码语言(例如OIL/OWL)明确表达上述体系(词表、词表关系、关系约束、公理、推理规则等)。
本体的目标是捕获相关领域的知识,提供对该领域知识的共同理解。确定该领域内共同认可的词汇和术语,从不同层次的形式化模式给出这些词汇(术语)和词汇间相互关系的明确定义,通过概念之间的关系来描述概念的语义。
本体作为一种知识描述与揭示方法,与分类法、主题法等传统知识描述与揭示方法相比,基于本体的知识揭示与描述根本区别在于,系统中的概念、特性、限制条件等内容都是计算机可读(懂)的,因而本体(Ontology)中的知识定义可以被再利用。同时,本体中概念之间关系的表达要比主题法、分类法更广更深,这是由于基于本体的实用分类系统主要是为机器增加“智能”进而实现自动处理信息,知识分享和再利用而建立,所以在数据模型和表述语言方面,它的结构与数据库很接近,通过简单的处理即可以将整个分类系统转成数据库而直接实施到信息系统的开发和建设当中,并且可以为知识采集、知识库的建立提供框架平台,这是传统图书馆主题法、分类法所不能及的[15]。
本体与谓词逻辑、框架(Frame)等其他方法的区别在于他们属于不同层次的知识表示方法,本体表达了概念的结构、概念之间的关系等领域中实体的固有特征,即“共享概念化”,而其他的知识表示方法,可以表达某个体对领域中实体的认识,不一定是实体的固有特征。这正是本体层与其他层次的知识表示方法的本质区别。
【注释】
[1]Tony Hammond,Timo Hannay,Ben Lund.etc..Social BookmarkingTools(I):A GeneralReview[J/OL].D-lib Magazine.[2005-11-04].http://www.dlib.org/dlib/april05/hammond/04hammond.htm#l 67.
[2]Sinclair,J.,Cardew-Hall,M..The Folksonomy Tag Cloud: When Is ItUseful?[J].Journal of Information Science,2008(1): 15-29.
[3]毕强.语义Web:知识组织的新基点[J].图书情报工作,2006(6):5.
[4]曾民族.知识技术及其应用[M].北京:科学技术文献出版社,2005:122,229,230.
[5]李文举,沈治宏.Folksonomy在中文图书分类中运用的实例分析[J].数字图书馆论坛,2009(7):57-59.
[6]毛军.元数据、自由分类法(Folksonomy)和大众的因特网[J].现代图书情报技术,2006(2):1-5.
[7]庄秀丽.“Tag标签”互联应用[EB/OL].[2008-01-10].http://www.kmcenter.org/ArticleShow.asp?ArticleID=4265.
[8]徐宝祥,叶培华.知识表示的方法研究[J].情报科学,2007(5):690-694.
[9]曾民族.知识技术及其应用[M].北京:科学技术文献出版社,2005:229.
[10]曾民族.知识技术及其应用[M].北京:科学技术文献出版社,2005:230.
[11]王文杰,叶世伟.人工智能原理与应用[M].北京:人民邮电出版社,2004:251.
[12]张帆.信息组织学[M].北京:科学出版社,2005:357.
[13]艾丹祥,张玉峰.利用主题图建立概念知识库[J].图书情报知识,2003(2):48.
[14]Jürgen Beier,Tom Tesche.Navigation and Interaction in Medical Knowledge Spaces Using Topic Maps[J].International Congress Series,2001(1230):381-388.
[15]秦健.实用分类系统与语义网:发展现状和研究课题[J].现代图书情报技术,2004(1):16-23.
【作者简介】

胡昌平,武汉大学信息资源管理学科点负责人。1995—2005年先后任武汉大学原图书情报学院副院长、原传播与信息学院副院长、信息管理学院副院长、学术委员会主任、武汉大学学术委员会委员。现任教育部人文社会科学重点研究基地武汉大学信息资源研究中心副主任,国家“985工程”哲学社会科学创新基地——武汉大学信息资源研究创新基地项目负责人,为国务院颁发的政府特殊津贴享受者,1999年被评为湖北省有突出贡献中青年专家。胡昌平教授出版著作18部,发表学术论文160余篇,主持完成包括国家社科重大项目在内的项目20多项,获省部级以上奖近10项。在教学中,他负责建设的“信息服务与用户”被评为国家级精品课,专著《信息管理科学导论》被教育部评选为研究生教学用书。
张敏,女,西南大学计算机与信息科学学院副教授,发表论文20余篇,研究方向为信息管理理论与应用。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











