



数字信息资源组织研究现状 与实践进展(1)
毕强 韩毅 牟冬梅
吉林大学管理学院 长春 130022
【摘要】本文回顾了Web环境下、网格环境下、语义Web环境下数字资源组织的理论研究现状与实践进展,分析比较了这3种环境下数字信息资源组织的理论、方法与技术工具的异同,并对语义网格环境下数字资源组织理论与实践的现状进行了综述。最后,从理论研究和应用技术两方面展望了数字信息资源组织的发展趋势。
【关键词】数字信息资源组织 Web服务 网格语义Web 语义网格
Reviews on the Evolution of the Theories
and in Digital Information
Organization
Bi QiangHan YiMu Dongmei
School of Management of Jilin University,Changchu,P.R.China,130022
【Abstract】The authors review the development of the theories on digital information resources organization in the context of Web,grid and semantic web,and analyze the different and common aspects of the theories,methods and technologies of digital information resources organization in the three contexts mentioned above.Also the authors review the status quo of the theories and practice of digital information resources organization on the basis of semantic web.Eventually,the authors discuss the tendency of digital information resources organization both in the theories and applications.
【Keywords】Digital Information Resources OrganizationWeb ServiceGridSemantic WebSemantic Grid
数字信息资源组织是信息资源管理的重要环节和建设重点。以数字化、网络化为基础特征的现代信息环境的建设与发展,使越来越多的用户(尤其是科研用户)把获取文献信息的重点从物理的图书馆转移到了网络;国内外越来越多的学者把研究的目光转向了数字信息资源的组织建设。理论与实践上的种种努力在局部上解决了“数字资源超载”和“数字资源孤岛”的一些基础性问题,且在一定程度上反映了数字信息资源组织理论、方法与应用技术由表及里的变化过程。但从整体上看,目前数字信息资源组织建设的理论方法在实践应用中仍然存在着许多问题,尤其是数字信息资源的组织和揭示能力还远远落后于数字信息资源的增长速度,以及与用户应用需要还存在很大差距。因此,本文试图对数字信息资源组织目前的研究现状与实践进展作全面综述,分析存在的问题和展望未来的发展趋向。
1.Web环境下数字资源组织的理论与实践
现代信息环境变化的基础特征是网络化数字化,信息资源空间数字化和学术交流空间数字化,使Web信息资源迅速增加并呈现出分布、异构、动态与海量等特征。为应对这种变化的信息环境,一方面,传统的高度专业化、规范化的信息资源组织理论、方法和工具的改造与创新被提到议事日程;另一方面,催生了适应数字信息资源组织的新理论、新方法和新工具。
1.1基于传统的信息资源组织理论与实践1.1.1利用元数据对数字信息资源进行描述
元数据是关于数据的数据,或关于数据的结构化的数据,专门用来描述数据的特征和属性。一个元数据款目构成一个信息资源的基本数据,是检索系统的基本构成单元,它可以代表信息资源用来组织目录、索引、数据库、搜索引擎等检索系统。信息描述的目的就是以元数据为中介,对信息资源进行各种操作。元数据的类型大致可分为:以详细记录为目的的元数据——MARC、以发现为目的的元数据——DC(都柏林核心)、以网络查询为目的的元数据——搜索引擎。
(1)MARC
MARC即机读目录,就是以代码形式和特定结构记录在计算机存储介质(磁带、磁盘、光盘)上的,用计算机识别和阅读的目录。MARC作为一种以详细记录为目的的元数据,是电子化管理、发布类表、词表、人名、机构名等规范档的标准方式。例如LCSH、LCC都提供MARC版本并可以在网上查询。用MARC格式表示的KOS可以植入OPAC系统中与书目数据统一管理。
(2)搜索引擎
搜索引擎是一种以网络查询为目的的元数据,它使用自动索引软件来发现、收集并标引网页,建立数据库;以Web形式提供给用户一个检索界面,供用户输入检索关键词、词组或短语等检索项;代替用户在数据库中查找出与提问匹配的记录,并返回结果且按相关度排序输出。它的特点是:由自动索引软件生成数据库,收录、加工信息的范围广、速度快,能及时地向用户提供新增信息。检索时直接输入关键词或词组、短语,无需判断类目归属,比较方便。但由于标引过程缺乏人工干预,准确性较差,加之检索软件的智能化不是很高,导致检索误差较大。虽然一次检索输出的结果可能很多,但会包含许多的重复、虚假信息,即检索噪音较大。另外,不同的搜索引擎有不同的检索项选择、检索界面,不同的句法要求和对标识符的处理,因此检索策略的构造和输入方式也会直接影响检索结果,造成查准率极低。
早期的研究以概要研究为主,如王忠、周士波对一些独立搜索引擎的基本查寻、高级查寻、限定查寻、结果排序、结果输出等检索性能进行比较分析[1]。随着研究的不断深入,研究重点转入到了搜索引擎性能的比较上,如孙丽等选取了比较常用的中文搜索引擎,从性能方面分析其优劣[2];徐建华等从主要性能指标方面对国外一些搜索引擎逐一进行分析[3]。
随着研究的深入,业界开始对搜索引擎评价指标进行研究。许多学者在Lancaster和Fayen提出的6条关于信息检索系统效果评价指标[4]的基础上进行细化与扩充,提出搜索引擎质量评价标准。这些评价标准主要从搜索引擎的查全率、查准率、功能、用户满意度等方面来进行构建。如储荷婷[5]、孙丽、曾民族[6]等从用户角度提出了一些标准:如数据库指标、检索结果输出格式、检索性能完善程度、响应时间、查全率、查准率、用户满意度等方面。黄如花[7]、曹东[8]、尚克聪、杨立英[9]等从技术角度提出搜索引擎的评价指标:收集网络站点数目的广泛性、搜索结果的满意度、数据库更新的频度和时效性、使用的便利性、目录设置的合理性和分类的深度及广度、内码转换的准确性。可见,从用户角度和技术角度出发,是目前评价搜索引擎较普遍采用的基本指标。
搜索引擎的不断发展,指南型分类系统也逐步建立,对其研究逐步受到重视。陈树年[10]在《搜索引擎及网络信息资源的分类组织》一文中论述了综合性搜索引擎具备的功能、对网络信息进行组织使用的语言、网络信息的组织模式、中文搜索引擎与传统分类法的比较、建构网上知识分类体系的原则和技术等,可称为这方面研究的一篇力作。马张华对分类搜索引擎的类目体系进行了较为全面的研究[11][12],深入到类目结构的编制依据、大类结构、类目体系的特点等,并探讨了存在的问题。研究者还对某一具体搜索引擎的信息组织方式进行了探讨,如,对Yahoo、搜狐等搜索引擎分类体系进行研究。
鉴于目前网络信息分类体系类目设置缺乏科学性、逻辑性,知识领域不全,知识体系不严密,分类标准、引用次序缺乏规律性,关键词式搜索引擎多为非控关键词索引,其查准率低。人们逐渐认识到搜索引擎应该以完善的情报检索语言原理为基础。曹东等提出:要运用分类检索语言的原理与方法,加强因特网信息资源分类表和电子化叙词表的理论研究,对自然语言实施控制机制;建立后控词表等情报检索语言的原理与方法来完善搜索引擎功能。
比较理想的传统的网络数字信息资源组织模式应当是分类主题一体化。其组成为:①一个结构简明的知识分类体系,通过对信息的系统分类,实现对信息知识领域的宏观控制;②一个智能化的控制词表,实施对作者语言与用户语言的控制与转换;③建立分类体系与控制词表的系统联系,将标引语言纳入分类体系,实现自然语言检索和类与语词的组配检索[13]。
(3)Dublin Core元数据
Dublin Core(简称DC)是为描述数字信息资源、支持数字信息资源检索而建立的元数据模式。它是一种基于资源发现为目的的元数据,旨在为数字信息资源的著录提供一种更简单、更有效的方式。它通过电子资源提供者对数字资源属性信息的描述,粗略地对资源内容进行编目,来帮助人们尽快地在网上发现所需要的资源。DC元数据避免了搜索引擎结构过于简单而MARC格式又过于复杂等问题,它不需要进行专业化训练就能对网络信息资源进行恰当的著录,降低了编目的成本,而且能迅速适应网络资源的巨量增长,目前,在数字信息资源组织中得到了广泛应用。但是,从根本上来说,这种元数据信息没有语义关系描述的基础,无法进行逻辑的推理,因此,依然不能被机器理解和智能地处理。同一词汇的语义过载、或者同义词汇的不完全描述都导致了现有数字信息资源组织的缺陷。
1.1.2虚拟图书馆(专题指引库)
虚拟图书馆是因特网上组织信息资源的一种有效而又经济的形式。具体说来,虚拟图书馆就是根据特定的目标,选定信息资源的学科领域,对有关的网站网页进行搜索和收集,加以鉴定核实,并对核实后的网址进行合理组织,使之能够提供检索、浏览和链接的信息集合[14]。与搜索引擎的主要区别在于,它属于专题性和学科专业性的,系统性和易用性强。虚拟图书馆对网络资源的组织是优越于搜索引擎的关键环节。该环节由专业图书馆员把关,在自动系统的协助下,利用某种分类法和主题词表,对收集来的原始资源进行描述和组织,改善了搜索引擎采用自然语言标引的根本缺点[15]。这方面实践和研究集中在:
(1)重点学科导航库建设
研究者主要对导航库建设、更新与维护的技术与方法以及存在的问题进行研究。重点学科导航库是以学科为单元对因特网的相关学术资源进行搜集、评价、分类、组织的序化整理,并对其进行简要的内容揭示,建立分类目录式资源组织体系、动态链接的学科资源数据库的检索平台并发布于网上,为用户提供网络学科信息资源导引的检索线索的导航系统[16]。我国“211工程高等教育文献保障体系”(CALIS)提出构建重点学科导航库系统,建议其内容可分为7项:研究机构;相关电子出版物、电子文献等;相关国际会议预告;其他相关机构信息介绍;本学科与行业的相关标准、规范、协议等;主要新产品与市场;新成果、新创造与发明、专利等。规定各子项目必须有分类浏览功能,以主题树浏览方式组织信息。
(2)专业网络资源导航库建设
所谓指引库是指在所建立的数据库中,从物理上讲并不存储各种实际的信息资源,但对其进行访问却可以检索到有关数据库的实际资源,即指引用户到特定的地址获取信息。其原理与方法是把因特网上与某一或某些主题相关的节点进行集中,按方便用户检索的原则,向用户提供这些资源的分布情况,指引用户查找指引库中的信息。指引库采用主题树方式组织资源。研究者们探讨了专业网络导航库建设中专业网络信息资源收集的手段与方法、导航库的构成、更新与维护问题[17]。
(3)热门站点链接或相关站点推荐
这是因特网上被广泛使用的最简单、最直接的信息组织与开发利用模式[18]。
1.1.3文献分类法在数字信息资源组织中的应用研究
(1)传统的知识组织工具——文献分类法在网络环境下的延伸和发展
国内外学者就图书馆分类法特性、具体分类法与搜索引擎分类体系比较(类目涵盖范围、揭示深度、类表结构和功能)进行研究[19],认为传统分类法知识系统性和标识语言的通用性以及族性检索能力和扩检、缩检功能,是其他情报检索语言所不具备的[20]。它在网络中的应用主要表现:①用于联机浏览检索;②用于非文本信息的组织;③用于超文本系统的管理;④作为网络信息组织的通用工具;⑤促进分类主题一体化。[21]
传统的知识组织工具——文献分类法,应从以下几个方面进行改造:①多维揭示;②适当降低分类难度(增加直观性、透明性);③提高分类法类目标题语词的表达性和现时性,选择、积累、增添终端用户检索的自然语词,及时反映网络资源建设和利用中的新主题:④重视分面分类思想和方法;⑤扩展同主题法即主题词表的联系;⑥粗分类原则,采用分面分析方法、建立强大的参照系统、加强标引深度,打破传统的线性资源组织方式,走分类主题一体化道路;⑦分类法应当解决机读化和网络化、兼容性和国际通用性:分类—主题—自然语言一体化;⑧充分利用新技术、新方法(超文本技术、分面分析方法)改造原有的分类法,提高分类法描述网上信息主题的能力[22]。
(2)文献分类法用于数字信息资源组织研究
以文献分类法为工具的网络资源检索服务系统,从学科角度揭示网络信息,成为组织网上学术性知识内容的主要应用模式。国外在这方面的理论与实践均走在我国的前列。早在1994年10月23~25日,在美国伊利诺伊大学的第36届阿勒顿研究会上,与会者围绕电子时代图书馆分类法的新角色与新地位这一主题进行研讨;欧洲科研与教育信息服务发展计划DESIRE(Development of a European Service for Information on Research and Education)在“因特网资源描述与发现”的专题研究报告(RE1004,1997年8月)中,全面介绍、总结了分类法在因特网资源组织中的应用情况:17个网上服务系统使用DDC组织资源,5个使用UC,5个使用LCC。
1997年,Nacy J.Williamson[23]对38个使用分类法组织资源的网站进行调查,记录每一网站所使用分类法的名称、联机分类法索引展示形式、主题树的特点、类目使用级次、分类法的变通、结果显示方式以及应用上的特点,并选取9个网站(其中使用DDC、UDC、LCC各3个)以及一些未采用分类法组织资源的网站,对艺术、历史、健康和旅游方面的信息进行检索,用以分析与确定运用分类法的特点、趋势和存在的问题。结果显示:绝大多数网站仅使用一至二级类目,二级或三级以上不采用分类方式,而以字母或其他的顺序。最引人注目的实验是:使用DDC的CYBERDEWEY,使用LC的WWW Virtual Library和早期使用UDC的BUBL's。研究表明,分类法能够提供组织网络资源框架。
Hamid Saeed和Abdus Sattar Chaudry[24]对每个网站现状、受控词汇、检索选择、主题范围及类目级次进行了调查。结果近50%的网站只局限于使用一级类目;显示标记符号与类名,其类名未作修改,内涵不好理解;绝大多数网站仅提供浏览功能,不具备语词检索能力。尽管如此,目前的实验及研究结果显示,DDC作为网络环境下的浏览工具已经取得了令人鼓舞的成绩。
马张华对文献分类法在网络资源组织中的应用进行总结[25],认为其特点在于:收入资源大多经过精选;对类目进行必要调整;对类目体系的深度进行控制;加强类下说明;多种检索途径界面;显示形式、处理层次多样、编制方式多样。这是我国在此领域研究的最早的一篇文献。
我国有学者提出,在虚拟图书馆中,为了使文献资源分类一致,可结合网站的特点,使用图书分类法,如,用《中国图书馆分类法》将这些网址进行分类管理,使其有序化。
(3)建立我国网络信息资源分类法研究
现有众多的中文搜索引擎均采用各自分类体系组织网络资源,用户必须熟悉不同的分类体系才能较快地检索信息,这样给用户带来极大不便。专家们提出,要建立网络信息分类法,提供网络资源的统一分类体系。陈树年提出建立网上信息的知识分类系统的基本结构与编制方法:有一个涵盖各知识领域、结构清晰、层次简明、能满足网上信息组织需要的分类体系;采用等级结构展示知识的系统联系,构成枝干分类的主题树或脉络清晰的地图;应采用对用户最有利的排列次序等并提出了中文信息分类大纲。在《文献分类学》一书中,从知识分类体系的构建、类目的划分与设置、类目交叉关系的处理、类目与信息的排列、类目注释和说明、用户界面等对网络分类法的编制进行了详细讨论[26]。
邓均华提出要编制我国数字化分类法,应以我国信息组织推荐
标准《中国图书馆分类法》为蓝本,综合国内外优秀的分类法及现代各种搜索引擎分类体系的长处,充分利用超文本技术的特征来表现分类法的体系特点[27]。
卜书庆提出从数字信息资源词频统计出发,从国际通用数据交换格式的研制出发,从最终用户检索需求出发,从适应新技术环境出发的主要思路,改造中国传统文献分类法主题法《中国分类主题词表》,用于组织数字信息资源[28]。
1.1.4主题法在数字信息资源组织中的应用研究
近年来,国内外的一些学者及研究机构已认识到主题法在数字信息组织中的重要作用,在这方面的研究主要集中在:
(1)关键词法的应用。由于关键词法具备:①在标引时不必查表,选词、标引速度快,成本低;②不依赖专职标引人员,可由作者或机器自动标引;③不存在人为性或滞后性,能及时应用最新的提法以及最新词汇等优点,因而,目前由搜索引擎软件自动建立的网络信息资源索引数据库所支持的就是关键词检索。但是,由于关键词法未进行同义词及反义词控制,未能揭示词间关系,这种关键词检索的致命缺点就是查准率太低。人们提出网络信息检索应导入受控语言机制,使用后控词表即“标引不控制+检索控制”模式是改进关键词法性能的比较有效的措施之一[29]。
(2)主题词表的应用。少数搜索引擎中提供主题词检索方式,在用户界面上,可直接浏览主题词表,从中选中主题词,作为搜索引擎的检索提问。用户可以在检索界面中修改检索提问,也可返回到主题词表界面重新选择主题词。其共同的特征是:词表内超文本导航[30]。
(3)标题词表的应用。标题词表在网络信息组织中的应用可以分为两种情况:①检索前使用。即通过标题词表规范用户的检索表达式。用户可以首先在网络信息组织工具提供的词表中检索到标准标题词及相关联的词汇。以该词作为检索词,点击表中超链接即可得到检索结果。②检索后使用。即在给出用户所用检索表达式,得出检索结果的同时,提供相关词作为用户进一步检索的线索,用户可自由进行扩检和缩检,从而提高检索效率[31]。
1.2异构数字信息资源组织的理论与实践
异构数字信息资源集成是为解决“数字资源孤岛”和“数字资源超载”而提出的一种理念和方法。随着语义网、知识网格大环境的逐步形成,数字资源集成支撑技术的日渐完善,数字资源集成领域的理论研究与实践正在迅速发生着变化。
1.2.1异构数字资源组织的实践研究
目前,异构数字资源组织中的数据集成技术已经有了很多研究项目和实际应用。比如IBM的DB2 II(DB2 Infor2mation Integration)家族产品提供了访问各种各样、分布式的和实时的数据的能力;Stanford大学设计的Lore(Light2weight Object Repository)是一个专门用于管理半结构化信息的数据库管理信息系统[32];同样是Stanford大学设计的Ozone是一个可以对结构化和半结构化数据进行集成的模型[33];东南大学开发的Versatile是一个基于CORBA的可扩展的异构数据源集成系统原型[34]。
中国科技大学开发的KD2IR IS系统[35],是为实现不同结构数据源(如关系、对象、空间地理数据库)间数据融合和信息处理需求设计。KD2IR IS系统采取关系模型来输出全局模式,从而方便用户使用熟悉的SQL语言进行查询。该系统既能以协调器方案满足用户对数据源扩展的灵活性要求,又使用集成实例化方式,较好地满足了用户对查询数据的可用性和速度的要求。另外,还为用户提供方便友好的GUI接口定义全局模式,实现了DBA和程序员分工明确的原则。浙江大学开发的WrapperBase是一个基于CORBA网络的Web信息集成系统[36],通过把各个网站的页面信息表述成特定结构模式的XML语言,并通过DOM解析把Web站点上的异构信息集成起来。
实现异构多信息源集成的关键在于找到一个合适的公共数据模型。国内外都有人尝试各种数据模型去实现异构多数据库的集成。例如MRDSM使用关系数据模型(Relational Data Model)[37],Superviews使用函数数据模型(Funcational Data Model)[38],TSIMM IS使用对象交换模型(Object Exchange Model)[39],InfoSleuth使用本体论模型(Ontologies)[40],Pegasus使用面向对象数据模型(Object Oriented Data Model)[41],UniSQL/M使用对象关系模型(Object Relational Model)[42],国内也有学者提出使用对象代理模型(Object Deputy Model)[43]。
1.2.2关于异构数据集成架构的研究
一个好的架构可以为软件带来很多好处,数据集成的核心是从数据源抽取信息,按照需求和数据模式转换成公共的数据格式,提供给目标程序使用,一般是加载到数据仓库中。但数据转换过程中还必须实现对数据的转移,因此数据集成是将许多不同的功能综合在一起的一个复杂的系统。下面总结一下当前的几种主流异构数据集成架构[44]。
(1)基于传统数据仓库的集成架构
该集成架构是将不同的数据源的数据组织在一起,给用户提供一个透明的统一视图。如将不同数据源的数据按照一定的主题装载到数据仓库中,以方便用户能够从大量的数据中发现信息。数据集成作为建设数据仓库的一部分,是数据仓库质量的关键。
但是,该集成架构也有它的弱点。一是该架构在反映实时(Real Time)信息的能力上存在不足。一般而言,存储在数据仓库中的信息大多是“历史”的,数据仓库的更新存在一定的周期,并且每次装载数据的资源消耗也很大,因此对于两次数据更新期间的数据就无法得到及时的反映。由于信息系统对于实时信息的要求越来越高,如何缩短数据反映周期成为当前建设数据仓库集成项目的一个问题。二是灵活性不够,对于数据源的改变不能及时得到反映。一旦数据源的数据结构、数据格式等发生变化,在下一次更新之前不能在数据仓库中得到反映。如果变化比较大,那么还有可能会损害到数据仓库本身的质量。三是建立数据仓库的成本比较高。由于要把各个数据源的数据都统一存放在数据仓库中,因此必然存在数据冗余现象,而且随着数据的不断增加,对于数据处理和存储设备的要求也会随之增加。这使得数据仓库架构的成本增加。
(2)虚拟数据组织系统
虚拟数据组织架构和传统数据仓库组织架构的最大区别就是对于数据处理的不同。后者将数据按照一定的模式集中到一起,而前者主要是通过一系列中间组件将数据访问转换成数据源能够接受的模式,然后通过网络分发给各个数据源进行处理,最后把结果返回给调用者。因而,使用这种架构不仅可以弥补数据仓库架构不能反映实时数据的弱点,而且特别适合于数据变化频繁,或者数据源对数据采集有限定的情况。
虚拟数据组织架构的弱点,一是数据源之间的数据清洗和语义匹配实现起来比较难,代价昂贵;二是由于所有的查询都要通过数据源进行,加重了数据源的负担;三是检索效率依赖于网络等硬件的情况,对于查询后的结果处理比较困难。
(3)联邦数据库系统
联邦数据库系统(Federated Database System,FDBS)是由一系列独立、自治的数据库系统组成的。FDBS没有全局模式,各联邦成员按自己的需求建立各自的数据模式,其成员之间的数据共享关系,通过由协商确定的输入/输出模式来建立。因此,它能够支持多库系统的分布性、异构性和自治性,使之产生满意的集成效果。联邦数据库系统用于异构数据源的集成,能够正确、高效、方便地共享各个局部数据库的数据。目前,联邦数据库系统的实现方法有以下两种:
①数据库转换法。首先将源数据库转换为用户可以使用的等价数据库,然后装入数据提供给用户以实现数据共享。数据库转换的方法能够实现对数据的透明访问,因为用户看到的并不是源数据库,而是源数据库的等价目标数据库。这个目标库和用户熟悉的数据库没有区分,用户可以用自己熟悉的数据操作语言书写事务,对数据进行处理。例如:用户使用的是关系数据库,要访问的是一个对象数据库,那么在数据库转换的方法中,我们就先拷贝对象数据库并将副本转换为关系型的目标库,用户和目标库打交道,自然可以使用关系数据语言,就像访问本地数据库一样。数据库转换方法的多模型和多语言能力主要体现在数据库转换器上。目前商用的产品主要采用多对支持双模型和双语言的转换器的方法来实现系统的多模型和多语言能力。
理论上已经证明,语义丰富的模型和语义缺乏的模型之间的互相转化都是行得通的,因而数据库转换的方法是可行的,但这种方法很难做到局部数据库自治。因为采用这种方法将产生一个数据库的多个副本,而在多个副本间很难维护数据的一致性和保证安全性限制,除非将完整性、安全性等限制一起转化,但这样做的代价太大。
②模式转换的方法。模式转换是一种逻辑方法,它是将异构数据模型转化为用户熟悉的数据模型,然后用户用自己熟悉的数据操作语言书写事务,事务通过事务翻译后直接对异构数据进行处理。模式转换的方法并不产生数据的副本,而仅仅产生了不同的数据模式,操作最终还是要在异构的局部数据库上进行,而这些局部数据库并不能识别其他语言书写的事务,因此需要对事务进行翻译。这一点不同于数据库转换法,后者已实际地将异构库转化为了和用户同构的目标库,操作在目标库上进行,所以不需要事务翻译。
根据模式转换器功能的不同,模式转换的方法可以分成四种:
▲一对一映射;
▲一对多映射;
▲多对一映射(即核心数据库系统);
▲多对多映射。
其中多对一映射是一种逻辑上异构,物理上同构的集成系统,所有操作都在核心库上进行;另3种对数据的访问归根结底总是要转化为对系统中某一局部数据库的操作,所以模式转换的方法不会产生完整性和安全性方面的问题,各局部数据库可以自治。
1.2.3关于异构数据集成方法的研究
实现数字图书馆异构数据集成的方案较多,考察当前的技术水平和主流平台,XML是现在得到广泛应用的数据交换语言接口,数据仓库在信息的组织和信息提供方面具有强大的功能,.NET在分布式应用中表现出优秀的特性。因此,这里有针对性地分析研究XML、数据仓库和Web Services等3项技术。
(1)XML与信息集成
由于XML具有可扩展性好,数据表达能力强,具有自描述性以及设备和平台无关的特点,XML已经在信息转换和集成领域得到了广泛的应用。数据集成中核心的问题是信息描述的标准化,主要解决信息的可理解性问题,包括人和机器对信息的理解。而且更重要的是机器对信息的识别,并能根据数据进行自动处理,因而XML可以充当数据交换的中间语言。
IBM的研究人员认为,在信息集成中对XML的支持可分为两个方面。一是信息集成支持用SQL直接访问XML文件中的数据。其机制是动态地将XML的层次型结构映像为一张或多张关系型的表来实现。数据的层次关系转化为虚拟表之间的主外键关系。这样对本地或远程XML的访问就转化为对虚拟表的访问。在应用XML作为标准信息接口规范的同时,大大简化了访问的复杂性。二是信息集成应该提供一组用于生成XML的函数,可直接将数据库中的内容动态地转换为XML格式输出,并在此基础上提供XML元素分类及排序等能力。XML技术和信息集成技术的结合能更有效地发挥XML的价值,满足不同层面的集成需求。
(2)数据仓库与数据集成
数据集成是建立数据仓库的基本要求。从数据仓库的建立过程来看,由于数据仓库是面向主题的,所以首先应该根据具体的主题进行建模,然后根据数据模型的需要从多个数据源加载数据。由于不同数据源的数据结构可能不同,因而在加载数据之前要进行数据清洗和数据集成,使得加载的数据统一到需要的数据模型下。
近年来,由于信息技术的高速发展,对数据仓库的要求也越来越高,这些要求涉及数据的时效性和可扩展性,其目的在于使用户在需要时可以得到当前的、远程的或非结构化的数据。传统的不断将新的数据源数据加载到数据仓库的方法成本很高;而且有些数据,由于它们的用法、大小或格式不适合于数据仓库或用户查询,因而不能或不需要保存在数据仓库中。通过信息集成对数据仓库进行扩展是数据仓库技术逻辑发展的必然结果。信息集成的最终目的是屏蔽数据源的复杂性,为用户提供单一的数据视图;而数据源可以分布在不同的地方,以不同的语义、格式存储,访问方法也各不相同。用户通过SQL或XML、标准网络服务等对数据进行访问。目前,IBM DB2、Microsoft SQL Server、Oracle等主流数据库管理系统都支持数据仓库。
(3)Web Services新兴分布式应用技术
Web Services技术是一项新兴的Web应用技术,是建立可互操作的分布式应用程序的新平台。当把应用扩展到广域网时,传统的DCOM模型就不能完全满足分布式应用的要求,一是DCOM在进行网间数据传递时一般采用Socket套接字,要求开放特定的端口,这会给带防火墙的网络带来安全隐患;二是DCOM进行远程对象调用使用的协议是远程过程调用(Remote Procedure Call,RPC),这使得基于DCOM的构件无法与其他组件模型的构件进行相互的调用,比如CORBA使用的是IIOP(Internet In2ter2ORB Protocol),J2EE使用的是远程方法RM I(Remote Method Invocation)。
新出现的Web Services技术的特点是跨平台调用和接口可机器识别,使用简单对象访问协议SOAP作为服务调用协议。SOAP是在XML基础上定义的,完全继承了XML的开放性和描述可扩展性;使用基于TCP/IP的应用层协议(比如HTTP,SMTP等),可以很好地解决穿越防火墙的问题;更重要的是各种组件模型都可以将数据包装成SOAP,通过SOAP进行相互调用。SOAP可以消除组件平台之间的差异。因此,选用Web Services作为分布式应用的层间交换技术是目前较好的一种。
2.网格环境下数字信息资源组织的实践
传统因特网实现了计算机硬件的连通,Web实现了网页的连通,网格将实现互联网上所有资源的连通,包括计算资源、存储资源、通信资源、软件资源、信息资源、知识资源等[45],如图1所示。网格能让人们透明地使用这些资源[46]。
挺进网格研究领域,已经成为国内外数字信息资源组织研究领域的共识。网格技术作为数字信息资源组织模式变革的思想平台和技术支撑,为数字信息资源组织提供实践理性化的操作样式。
近年来,国内外一些研究机构针对网格技术在数字图书馆分布和异构知识的整合方面进行了深入的研究。
2.1国外具有代表性的研究项目
DELOS[49](DELOS Network of Excellence on Digital Libraries)项目是由欧盟信息社会技术的Frameworks Programme5(IST-FP5)创建,主要是从以下7个方面出发研究数字图书馆的相关问题:(1)DELOS数字图书馆体系结构;(2)信息的存取与个性化;(3)视听和非传统对象;(4)用户接口与可视化;(5)知识提取与语义互用;(6)数字资源保存;(7)数字资源评估。
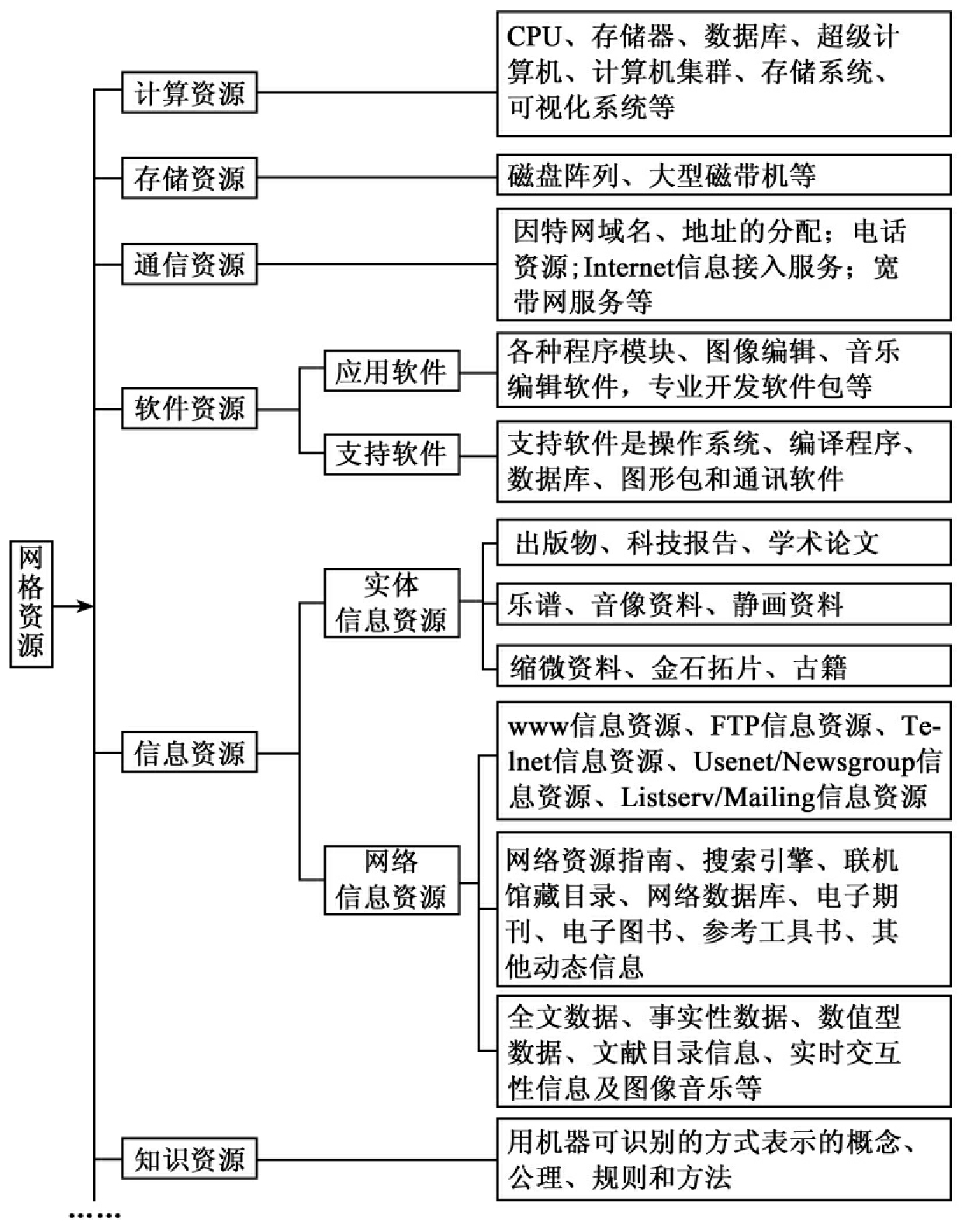
图1 网格资源构成图[47][48]
Old Dominion大学数字图书馆研究组在其原有的OAI(Open Archives Initiative)系统研究和实践基础上提出项目——“Digital Library Grid”[50],目的在于通过网格来降低数字图书馆的整体运行成本,同时增强服务的可用性和服务质量,该研究组提出了“数字图书馆网格”项目的系统体系结构。
FreeLib[51]项目是由Old Dominion大学数字图书馆研究组提出的基于P2P网络的新型数字图书馆试验系统,主要目标在于建立一个可持续的、对动态演变社区提供支持的数字图书馆,并对该数字图书馆在设计、实施、发布和评估过程中面临的主要问题进行研究。同时FreeLib通过与Archon相结合,从而整合到美国国家科学数字图书馆的体系中去,以提供一种不同于传统数字图书馆的可替代服务。
ARCO[52]是葡萄牙国家数字图书馆(BND,Biblioteca Nacional Digital)中进行海量多媒体数据存储的一个试验性网格项目。ARCO项目主要研究网格环境下海量数据的存储,它的结构体系主要基于网格结构。在ACRO的结构体系中,主要研究系统与操作系统、网络资源以及Globus中间件之间的交互。
DILIGENT[53]是由欧盟IST-FG6提供支持,采用EGEE网格
项目的研究成果的一个研究项目。它的主要目标是建立一个先进的测试环境,使用e-Science公用平台共享知识并能通过安全的、协同的、动态的和经济的途径进行协作。DLIGENT项目测试环境将建立在整合网格和数字图书馆技术的基础上,整合这些技术将引发不可预期的功能上的突破,并为下一代的e-Science协作平台奠定基础。
GRACE[54]项目主要是一个关于信息检索的项目。该项目计划在欧洲Data Grid技术的基础上开发一个分布式的搜索和分类引擎。它不使用集中式的数据库,而是在每个网格结点本地索引文档并使用和存储位置邻近的计算资源。这种分布式的应用比以前的集中数据库更加规模化,并且可以为不同的数据源提供更多的个性化的搜索选项。它支持多种语言,尤其是欧盟各国的语言,并在此基础上创建功能强大的网格工具组。
国外这些研究项目的研究内容和方向各有侧重:DELOS侧重于结构体系的理论构建,偏重于网格结构、P2P结构和面向服务结构三者的融合;Digital Library Grid与Free Lib基于OAI模型,使用网格结构和P2P结构;ARCO、DILIGENT、GRACE和GridIR的结构体系都以网格结构为主,不同之处在于ARCO主要研究网格环境下海量数字资源存储结构,目标在于为数字图书馆的海量资源提供透明的、可管理的接口;DILIGENT结构体系主要侧重点在于为用户提供强大的个性化服务,对数字图书馆结构体系进行整体的研究;GRACE结构体系侧重于本体与语义互用在数字图书馆系统结构中的应用,从语义层面入手研究数字图书馆。它们的共同目标都是为实现分布异构的数字图书馆知识组织提供基于网格的解决方案。
2.2国内基于网格技术的数字资源应用研究
武汉大学的“数字图书馆网格应用模型研究”项目,提出了基于OAI的数字图书馆网格应用系统的框架结构,认为该方案能够有效解决多个异构数字图书馆之间的资源共享问题[55]。
北京理工大学郑志蕴等人在OAI-PMH框架的基础上,结合网格技术,提出全新的数字图书馆互操作框架——数字图书馆网格DL Grid,利用网格技术解决数字图书馆资源发现、整合、跨仓储检索、安全等问题,为实现大规模数字图书馆的互操作提供一种新途径[56]。
上海交通大学杨宗英主要从用户的角度出发,认为网格技术为数字图书馆中的单点登录、无障碍的语义理解、知识的智能聚合、知识的映射等服务的实现提供了技术支持,但对于如何实现,尚未提出具体可行的方案[57]。
国内外研究者发现网格技术在解决数字信息资源的分布与异构,实现信息资源全面整合等问题上具有巨大潜力,利用网格实现平台与环境的无关性和独立性,形成虚拟计算组织,用户可以在全球任何地方访问所需的知识,从而使知识得到充分的共享。但是这些基于网格的数字信息资源组织研究更侧重于解决资源物理上的分布和异构,而对资源语义互联和互操作缺乏足够重视。
3.语义Web环境下数字信息资源组织的理论与实践
传统的数字资源组织以数据层面的组织和信息层面的组织为主。在语义Web环境下,数字资源的组织以知识组织为主。我们一直在信息组织的框架下研究知识组织,从而导致知识组织与信息组织(在一些基本问题上)的概念界限不清,最终导致知识组织水平仍停留在数据和信息层面。因此,要对知识组织的概念、目标、原则、特性、方法、功能等基本理论进行反思,进行基于信息组织但又超脱于信息组织的深入研究。
从信息组织到知识组织,即从对信息载体的组织上升到信息内容、知识本身的组织,是学者们从深度上展开的组织研究。顺应信息化向知识化转变的趋势,不仅仅是概念名称的变更、组织范式的变革,而且还有研究内涵的创新和研究深度的探索。当前,所面临的技术环境是语义Web(Semantic Web)技术和本体(Ontology)技术,语义Web技术致力于开发“以计算机可处理形式表示信息含义的语言”,以在资源之间建立起机器可处理的语义联系;本体的目标是获取、描述和表示相关领域的知识,提供对该领域知识的共同理解,确定该领域内共同认可的词汇,并从不同层次的形式化模式上给出这些词汇和词汇间相互关系的明确定义[58]。从Berner-Lee提出的语义Web七层体系结构中可以看出,本体位于底层的Unicode字符集和XML语法结构之上,位于逻辑层和验证层之下,是基于XML为语义的逻辑推理和验证功能,提供基础的语义网最关键部分。传统知识组织体系中的叙词表和语义Web体系结构中的本体都是用来描述概念词汇之间语义关系的,具有很多相似点:在取词上,它们都取自本领域中的概念术语,类目体系都是等级结构,都包含注释信息;在词汇的关系表达上,都选择一定的标识符来体现各种概念之间的关系,以上这些相似性也是领域本体构建中的关键问题。
从知识组织的意义上来看,如同过去信息组织中的检索语言的作用和地位,在以本体为核心的语义Web技术的驱动下,凸显了知识组织由观念与理论探讨全面转向实际应用的契机[59]。
3.1语义Web技术国内外研究现状3.1.1语义Web技术的理论与应用研究现状
国外学者对语义Web技术在数字图书馆知识组织中的应用展开了深入研究,荷兰埃丁霍温科技大学学者Brendan Rousseau等人认为数字图书馆应智能化地选择、组织、管理、发布知识,为用户提供知识服务;对于数字图书馆的设计和进一步的开发,应使用语义Web的层次结构来构建数字图书馆的语义互联基础和信息表达框架;目前认为已经存在语义Web的基础构件,但是仅依靠这些构件还不足以实现数字图书馆的语义互联[60]。
德国Karlsruhe大学AIFB研究中心的学者York Sure和Rudi Studer认为应用语义Web技术推动了数字图书馆知识组织的发展。语义Web重点在于对数字图书馆中知识库和对象进行语义描述,并利用本体技术建立通用模型,解决分布式异构知识库的互操作。进而对语义Web技术在数字图书馆具体应用进行展望,认为语义Web技术可以解决用户接口和人机交互、信息空间中用户统一模型、个性化服务及用户交流协作。目前基于语义Web的数字图书馆要解决的关键问题是如何为用户提供多知识库的统一视图[61]。
美国斯坦福大学学者Deborah与L.McGuinness讨论了利用增加语义解释层的办法处理语义Web环境下用户提问的问题[62];意大利Trento大学F.Giunchiglia与P.Shvaiko就语义匹配进行了深入研究[63];斯坦福大学知识系统实验室R.Guha等人研究了语义检索问题[64];IBM阿尔马登研究中心的S.Deill[65]、美国佐治亚大学LSDIS实验室B.Hammond[66]等人提出了一系列语义标注的新方法,美国佐治亚大学LSDIS实验室A.Shet与C.Ramakrishnan则报告了他们关于本体驱动的信息检索、分析与整合应用系统的研究情况[67]。
国内学者同样针对这一问题从不同的角度进行研究。其中武汉大学黄如花博士提出利用知识地图和语义Web技术实现数字图书馆3个层次的可视化知识组织(词汇表、分类体系和关系列表)[68],张振海提出利用Ontology解决知识获取、知识重用和知识共享,并提出下一代数字图书馆运行环境是基于Ontology+ Grid[69];但对如何实现,并没有详细展开,也未给出具体的方法与模型。
南京理工大学颜端武等人认为数字图书馆要满足用户知识需求和个性化需求,提出了基于语义Web和数据挖掘的智能推荐检索机制[70];其他与用户需求相关的研究主要集中于对基于语义Web检索的理论探讨,在技术上并未真正实现。
北京理工大学余正涛等人以数字图书馆领域个性化服务为例,以空间向量模型表示用户兴趣和资源特征,并借助于构建的领域本体和“知网”知识词典对向量进行概念上的扩展,形成用户和资源特征概念空间向量,并通过向量相似度计算寻找最优的资源,从而有效地将用户和资源虚拟组合在一起[71]。
上述国内外学者从用户和知识库的角度对语义Web技术在数字图书馆知识组织中的应用进行研究,主要关注于知识库之间和知识库与用户之间的语义互联互操作,尚未对用户之间具有语义关联的需求进行语义匹配和语义整合,也没有对数字图书馆系统本身的异构性和分布性给予过多关注。
3.1.2语义标注工具研究现状
基于本体的语义标注工具被定义为利用已有本体在网页与文档中插入标记,或通过标注文档媒介产生知识库[72]。利用语义标注工具对现有的大量Web信息进行标注,将使得Web页的内容成为机器可识别和理解的数据,从而构成语义Web的基础。
(1)语义标注工具简介
2004年10月语义Web写作与标注界主页[73]上列出了13个基于本体的语义标注工具:KIM Semantic Annotation Platform、OntoMat Annotizer、MnM、SHOE Knowledge Annotator、Annotea、Annozilla、SMORE、Yawas、Melita、GATE、Briefing Associate、Semantic Word和Semantic Markup Plug-in for Internet Explorer。
①SHOE Knowledge Annotator由MaryLand大学开发,可以认为是第一个在真正意义上实现语义标注的工具,它使用SHOE本体的实例(Instance)和声明(Claim)来标记Web页,可以打开多个本体来标记一个文档,适合于手动标注的场合。
②Semantic Markup Plug-in for MS Internet Explore[74]和SemanticWord[75]是在TeKnowledge项目下开发的,它们的特点是通过将标注功能以插件的形式加入已有工具的方式支持语义标注,这一思想有助于对现有的文本或网页编辑工具进行语义标注功能的扩展。
③Annotea[76]由W3C组织开发,是开放的RDF框架,它采用Client/Server模式将可共享的Web页标注信息存于标注服务器中,这使得标注内容的应用将更加方便。
④Melita[77]是在AKT(http:∥www.aktors.org/akt/)项目下研究开发,同时集成自适应信息抽取(AIE)引擎Amilcare。Melita是半自动的文本标注工具,它的性能可分为:管理任务、信息提取、自动学习和信息标记,这些性能的实现要借助于良好的界面操作和高效的信息提取算法的支持。
⑤GATE(General Architecture for Text Engineering)[78]由Sheffield大学NLP工作组开发,是基于构件(Component)的体系结构,它通过在其中加入JAPE(Java Annotation Patterns Engine,为标注提供基于规则表达式的模式/行为规则)和AnnotationDiff工具(为标注比较计算准确度和查全率等性能指标)等构件来实现标注的性能。
⑥Briefing Annotizer[79]是在TeKnowledge项目下开发的基于PowerPoint环境的语义标注工具,它将标注保存在PowerPoint文档中,但这些标注是不可见的。
⑦OntoMat Annotizer[80]由德国Karlsruhe大学AIFB研究院开发,是用户界面友好的Web页标注工具。该工具的目标是生成带标注的Web页面,其内容可供语义WebAgents推理。它支持用户创建和维护基于本体的DAML+OIL标记,它所面向的用户是个体标注者,即用户用DAML元数据来丰富它的网页。
⑧SMORE[81]由Maryland大学MIND(Maryland Information and Network Dynamics Lab)SWAP(Semantic Web Agents Project)研究小组开发,该工具的目标是无缝集成内容发布和语义标注。
(2)当前语义标注工具的技术局限性
语义标注技术可从3个不同的角度来考虑:从标注对象上分可分为是对静态Web页标注还是对动态Web页(由数据库中产生的Web页)标注;从标注的方式上可分为手动、半自动和自动,手动标注是标注人员手工直接将语义元数据信息写入Web页的源码中,半自动标注是借助工具用鼠标拖拉等方式决定要标注内容后由工具将信息写入Web页中,自动标注从概念上是自动将语义信息写入Web页中,但实际上写入什么内容要借助大量类似页面的训练集训练后再以人类知识判别后才能决定(从理论上也不能归为完全自动),所以标注少量的或不同类型的Web页时用自动标注效果并不理想;从标注元素的选择上可以用采用的不同类型元素来加以区分。
当前基于本体的语义标注工具均具有各自的特点和适用范围,但现有工具普遍存在以下的不足:几乎所有标注工具的本体语言使用RDF(S)、DAML、OIL、DAML+OIL、SHOE或F-Logic,标注语言使用XML、RDF(S)、DAML、DAML+OIL或SHOE,而没有工具支持最新的W3CWeb本体语言OWL;除少数工具如SMORE支持本体词汇的编辑、修改和扩充外,多数工具都不支持本体词汇扩充,这与语义Web的应用环境相悖;一个页面上的词汇往往涉及多个本体中的概念,少数工具如SMORE允许用户使用多个本体标注页面,多数工具不支持同时打开、浏览多个本体,并使用多个本体标注页面,这与语义Web的本体环境不符;要建立全球共享的语义Web,不同语言的用户都能使用自己的语言标注页面,标注工具的多语言支持是关键,这对推进语义Web应用很重要。而所有工具只是英语标注,不支持多语言;所有工具的标注对象为HTML页、Image、E-mail、Word、PowerPoint及Plain Text,且以静态内容为主,而Web上含有大量多媒体对象、电子商务应用中的业务(数据库/XML)数据、E-Science中的科学数据等动态内容;大部分工具采用先创建内容、后进行标注的“两步法”,只有少数工具支持内容写作与语义标注的同步进行(Simultaneous Creation of Content and Annotation);语义标注过程中本体查询、辅助推理支持及元数据产生的自动化程度还不够。这些都影响了大量一般Web用户(非逻辑专家、本体工程师和领域专家)使用工具创建语义Web内容的积极性和可能性。
3.2语义Web技术对知识组织基础理论的影响
(1)对知识组织概念的新拓展
英国著名分类学家H.B.Bliss最早于1929年提出“知识组织”概念,此后国内外不同领域学者结合领域特点对“知识组织”加以解释。国际知识组织学会德国分部“知识组织与网际网络”工作小组Alexander Sigel认为“知识组织是将含有知识的集合物加入信息价值的一种跨学科领域的文化活动,以便为用户群提供最好的相关信息体系”[82]。我国最早使用“知识组织”的是著名文献情报学专家袁翰青教授,他在1964年指出“文献工作是组织知识的工作”。后来郭星寿同志在《社会科学文献学》讲义中又有所发展:“文献工作是以特定的文献为工作对象,采用科学的方法搜集、评价和选择文献,并通过书目索引、主题索引、文献题录、文献综述或述评等多种途径,以传递社会科学知识为目的,来满足广大读者和研究工作者对社会科学情报和资料以及文献检索方法等的要求的一系列的活动”。J.D.Anderson认为“知识组织是有关文献的描述、内涵、特色、目的及将前述这些活动予以组织,以利于使用者的寻找。知识组织包含了索引、摘要、编目、分类、记录管理、书目,以及相关文献信息的产生和检索用的书目数据库”[83]。这个时代是以文献单元作为知识组织的对象,认为知识组织就是文献工作。20世纪80年代末,丰成君等学者认为知识组织的对象发生了变化,除知识内容本身组织化外,还要通过语言组织化和载体组织化来实现知识组织化[84]。图书馆界大家马费成先生认为知识组织系统的基础应从文献单元→数据单元→智能单元进行转变[85]。到90年代,知识组织这一概念在学者们的研究下逐渐清晰,贾同兴认为“所谓知识组织,是指对事物的本质及事物间的关系进行提示的有序结构,即知识的序化”[86]。王知津将其定义为“对知识进行整序和提供”[87]。蒋永福则认为“知识组织是指为促进或实现主观知识客观化和客观知识主观化而对知识客体所进行的诸如整理、加工、引导、揭示、控制等一系列组织化过程及其方法”[88]。储节旺等认为,知识组织是按照知识的内在逻辑联系,运用一定的组织工具、方法和标准对知识对象进行诸如整理、加工、表示、控制等一系列的序化、系统化的活动[89]。纵观知识组织理论研究的历程,不同学者对“知识组织”从不同角度进行了描述,尽管目前“知识组织”没有统一权威的定义,但已对“知识组织”的本质特征有了相同的认识:即用一定的方法和手段对知识的各种要素加以组织,以便知识传播、提供和利用;同时,“知识组织”概念随着技术发展进步不断发展完善,呈现与时俱进的特点。
语义Web环境下,知识组织工具不再仅仅局限于传统的分类法、叙词表、编目规则,还出现了能够更好适应数字环境的新型知识组织工具——概念地图(Concept Map)、语义网络(Semantic Network)、以本体为核心的语义Web技术和语义网格(Semantic Grid)等。知识组织方法相应发生一系列革命性的变化,从单纯的语法处理转变为语义处理,从语义处理到语用处理。由于语义Web技术的引入,知识组织消除含混性和歧义性,其传递的语义直指语用,更好地为用户提供易于理解、准确无误的语用服务。因此,图书情报领域研究者对“知识组织”概念的内涵会有更为清晰和丰富的认识。
在知识组织活动的具体实践中,语义Web驱动下的知识组织方法和形式不仅保留了文本秩序的分类、编目、关键词、索引、主题标引,增加了Web环境下的搜索引擎、网络分类体系、数据库、主题树、超媒体,而且已经发展到语义Web知识库、语义门户、基于语义Web的数字图书馆等更多种类、更多形式,知识组织活动更加多样、灵活和便捷,基于语义Web的知识组织进行知识库语义描述,实现知识库的语义互联和语义互操作;对用户需求进行语义描述,实现用户需求语义上的忠实、无差异表达;将用户需求与知识库进行语义匹配,实现用户需求与知识库的互理解;优化利用数字图书馆中的知识资源,提供知识化的服务,从而提高资源的利用率。从理论研究层面看,显而易见,“知识组织”概念的外延已经有深远意义的拓展。
(2)对知识组织原则的新要求
HjΦrland在1997年提出了9项知识组织的原则[90]。付小红以知识保障和用户保障两大原则为基点,将知识组织的原则展开为10个方面:全面性、客观性、充分性、有序性、标准化原则和用户可近性、经济性、逻辑性、思想性、发展性原则[91]。盛小平根据数字图书馆中知识的特点、资源的分类、数字图书馆建设使用的标准、要求提出了数字信息资源组织原则,即科学性、系统性、标准化、共享性、效益性、特色性、安全性原则[92]。语义Web技术构筑的环境不同于数字图书馆环境,语义Web技术更关注网络结构和语言的设计,目的是使数据、程序、页面以及其他网络形式具有明确的语义表示,而使机器能够理解自然语言。它对知识组织原则提出了新的要求,主要体现在以下几个方面:(1)以人为本的原则:以用户的需求为知识组织的出发点和落脚点。语义Web技术的出现,使得知识表达和知识组织从物理层次上的文献单元上升到认识层次的知识单元,从单纯的语法处理(主题法、分类法)转变为语义处理(如专家系统,语义网络表示法),从语义处理到“模拟个体知识记忆结构”的基于语境的处理方式。语义Web技术最终目标是使机器理解人类的自然语言[93]。因此基于语义Web技术的知识组织首要原则是以人为本,即模拟人的记忆结构组织知识单元,再理解人类的自然语言提供知识服务。(2)效率优先原则。目前的网络以词的匹配程度(通过词频加权和词序加权)提供给用户大量的、零散的、杂乱无章的信息,用户需要再利用大量的时间选择、分析、理解和综合这些信息;语义Web技术驱动下的知识组织,更应注重准确和效率,无需现在Web环境下用户得到信息后的后期处理。(3)个性化原则。个性化信息服务要求根据不同用户的不同特点和需求为用户提供特定的信息服务,这要求知识组织对知识内容的揭示兼具深度和广度,内容清晰、针对性强,具有很好的开放性和广度的柔性。这正是语义Web技术和本体技术的优势所在。(4)可重用原则。语义Web技术要求人和机器都理解信息的含义,这要求知识组织必须遵循标准化、可重用原则。语义Web的关键技术本体是获取、描述和表示相关领域的知识,提供对该领域知识的共同理解,确定该领域内共同认可的词汇,并从不同层次的形式化模式上给出这些词汇和词汇间相互关系的明确定义。本体通过概念的严格定义和概念与概念之间的关系来确定概念精确含义,表示共同认可的、可共享的知识。基于本体进行知识组织更易标准化,更易重用。(5)互操作性原则。本体有许多不同的定义,但是从内涵上看,研究者的认识是统一的,即本体是领域(可以是特定领域、特定主题,也可以是更广范围)内部不同主体(人、机器等)之间进行交流(对话、互操作、共享等)的一种语义基本。本体提供了一种共识,是一座架在“语义鸿沟”上的桥梁。在语义Web中,本体是解决语义层次上网络信息共享和交换的基础。未来语义Web环境中的知识组织是基于标准化的本体,使得知识组织的过程和知识组织系统具有互操作性。
(3)对知识组织的目标和任务新深化
知识组织的目标是对知识存储进行整序和提供知识,任务是提供文献、评价科学文献、系统表达[94]。这一观点得到大多数人的认可。由于语义Web技术的出现以及对语义Web关键部分本体的深入研讨,带动了知识组织的目标和任务的新深化。知识组织是知识的序化,是基于知识的组织。知识是信息的一部分,是人类主观世界对客观世界的反映与认识的结晶。知识本身具有多重属性,包括模式(显性与隐性)、类型(描述性、过程性和推理性)、认识环境(域、关系和自身属性)、可应用性(地方性和全球性)、可获取性(公共知识和个体知识)、即时表现性(激活的知识和隐伏的知识)、消逝性(迅速消逝的知识和无消逝性知识)等。知识属性如图2所示[95]。
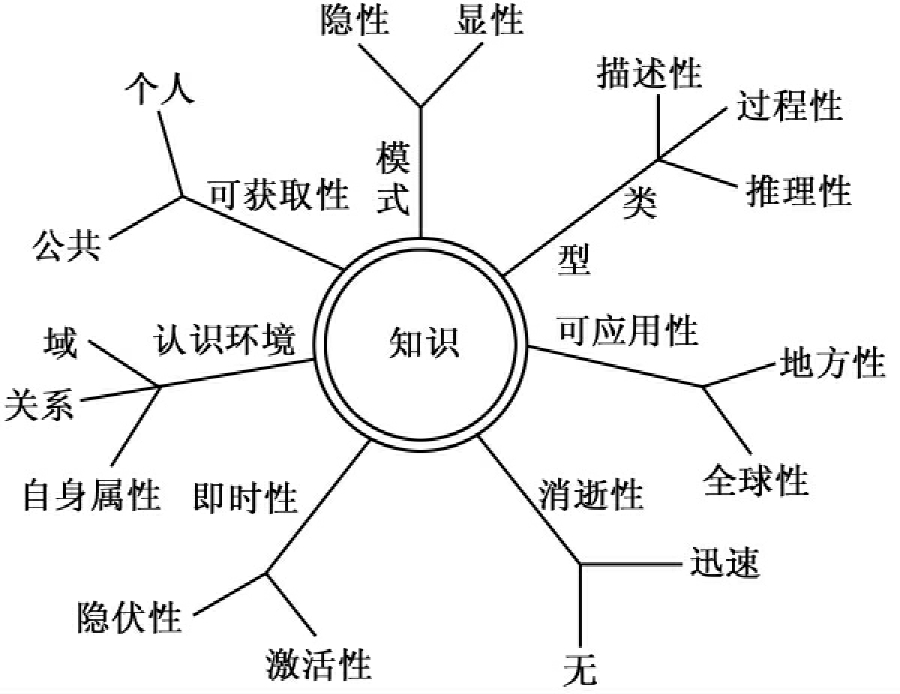
图2 知识属性网图
语义Web技术的出现为知识组织的目标和任务注入了新内容。语义Web体系结构的第2层(XML+NS+XMLs)允许用户在文档中加入任意的结构,而无需说明这些结构的含义,该层负责从语法上表示数据的内容和结构,通过使用标准语言将网络信息的表现形式、数据结构和内容分离[96],极利于从各个角度充分描述知识属性;第3层(RDF+RDFs)建立一种供多种元数据标准共存的框架,使描述资源的元数据信息成为机器可理解的信息,大大提高信息检索的准确率,从而弥补基于词条匹配的全文检索知识服务机制的弱点;第4层在RDF(s)基础上利用“概念、类、关系、函数、公理和实例”六要素定义概念及关系,描述领域知识,将已经得到充分描述的知识属性组织成网状结构;第5~7层负责提供公理和推理规则。这样的语义网具有描述知识的全面性,知识组织的立体多维性,知识语义的机器理解性,知识检索的智能推理性,这些特性使得语义Web技术驱动下的知识组织目标和任务进一步深入,目标是实现主观知识客观化和客观知识主观化,任务也不再停留于提供文献、评价科学文献和系统表达等信息服务的层面,而是提供知识服务,即提供以用户需求目标驱动的、面向知识内容的、融入用户决策过程并帮助用户找到或形成问题解决方案的增值服务。
3.3语义Web技术对知识组织实践的影响
(1)实现知识组织方法的新跨越
知识组织方法有很多种,王知津依据知识的内部结构特征,将其分为知识因子组织方法和知识关联组织方法[97];蒋永福依据知识的不同存在形态,分为主观知识的组织方法和客观知识的组织方法;依据知识组织的语言学原理,分为语法组织方法、语义组织方法和语用组织方法。这些知识组织方法理念受到大多数学者的认同。但是一方面由于知识的描述、揭示、表达和组织十分困难,人们对知识的认识水平还比较粗浅,不能准确地描述和表达知识;另一方面由于当时技术手段也不能支持知识的揭示与组织[98],使得这些方法仅仅停留在理论构想的层面,究其原因,主要是理念一直超前于技术。现在,由于语义Web技术的出现,解决了技术落后于理念的局面。信息资源可以利用本体表示语言进行标注,它主要能提供如下基本功能:(1)为本体的构建提供建模元语;(2)为本体从自然语言的表示格式转化成为机器可读的逻辑表达格式提供标引;(3)为本体在不同系统之间的导入和输出提供标准的机读格式;(4)形式化语言表示,利用机器可读的形式化表示语言表示本体,可以直接被计算机存储、加工、利用,或在不同的系统之间进行互操作[99]。依据本体进行标注后,其语义特征才能够为知识组织系统所识别,知识组织系统将自身所获得的语义信息存储在知识库中,并利用知识库中的知识搜索引擎对语义内容进行重构,形成关于某个特定学科领域的全面的知识网络,完全可以达到对知识语义层面的组织。同时由于语义Web技术是基于语境(Context)产生并不断发展的,该技术使得知识组织系统和用户可以相互理解,为知识的语用服务提供平台。在语法规则、语义表示和语境分析的综合作用下,知识组织消除含混性和歧义性,其传递的语义直指语用,基于语义Web的知识组织将达到语用境界,更好地为用户提供易于理解、准确无误的语用服务,可见语义Web技术的发展必将实现知识组织方法“语法—语义—语用”的新跨越。
(2)对知识组织工具的新丰富
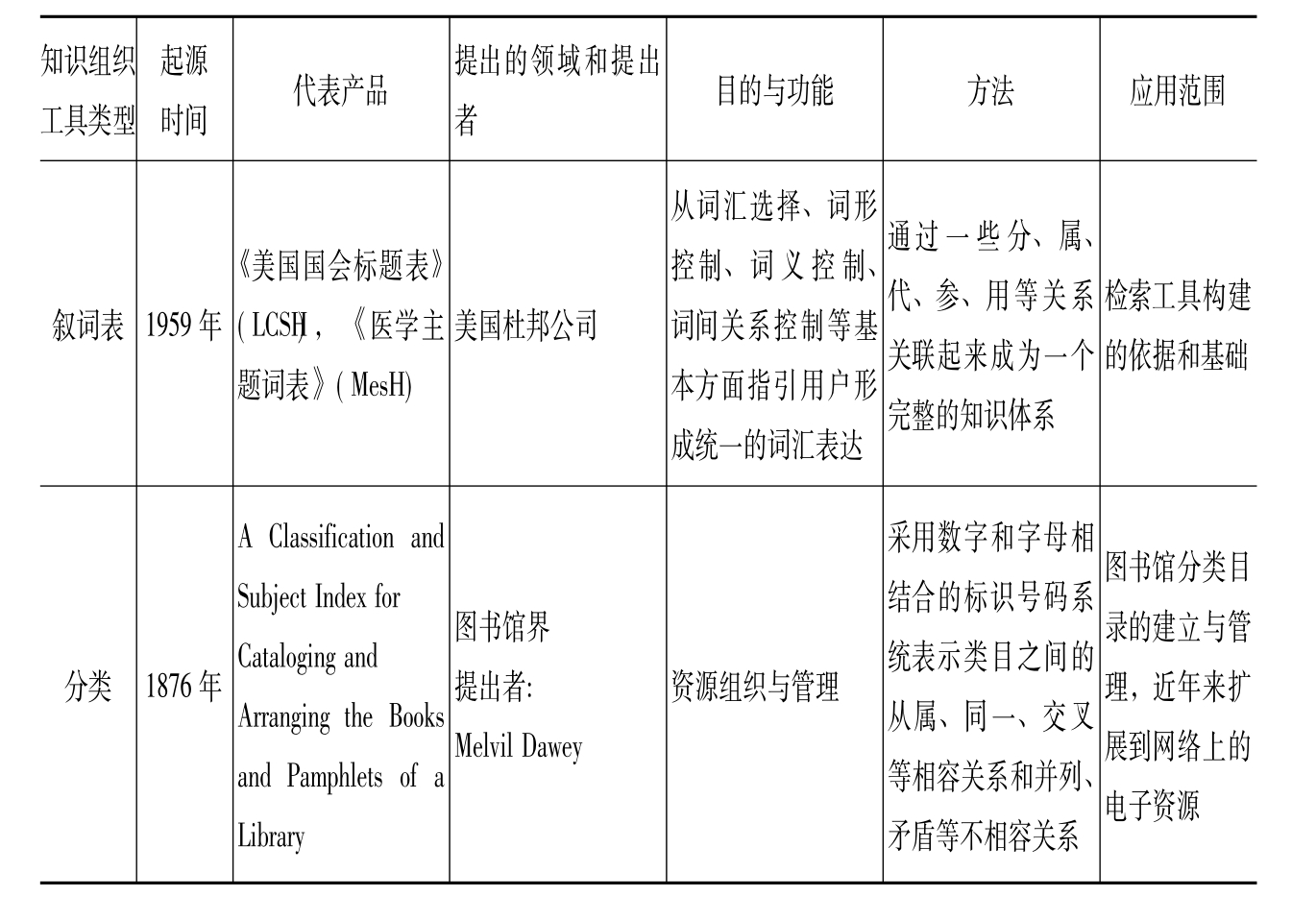
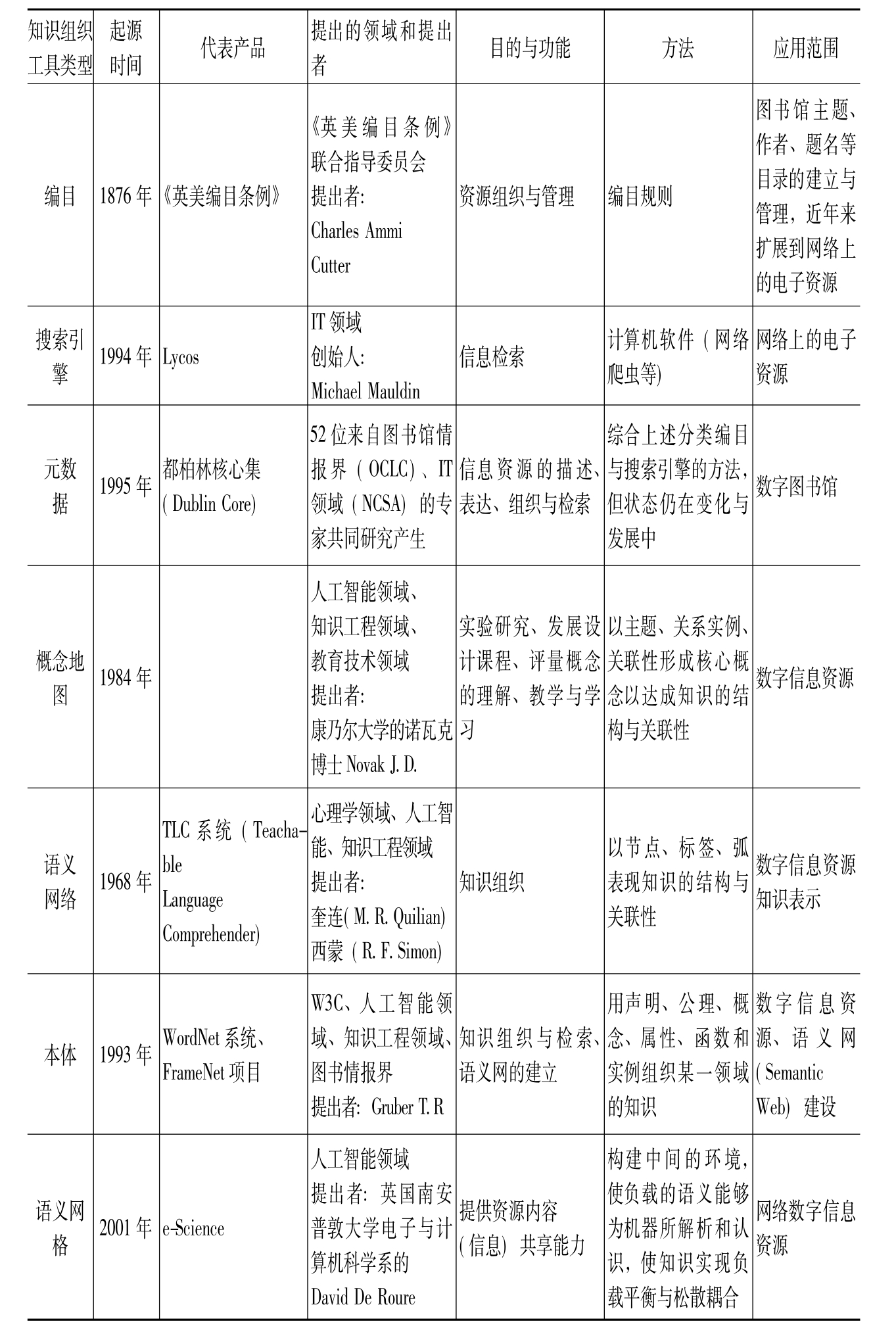
知识组织是用户检索获取信息的基础,知识组织的工具随着信息技术的发展不断变化,一方面为了适应数字环境,传统的适应文本秩序的信息组织方法——分类法和主题词表不断进行改造;另一方面数字环境的复杂境况,又迫使产生新的适应数字秩序的组织工具。尤其是语义Web的出现,知识组织工具不再仅仅局限于传统的分类法、叙词表,而且产生了能够更好地适应数字环境和数字秩序的新型知识组织工具——概念地图、语义网络、以本体为核心的语义Web和语义网格。知识组织工具比较见表1。
表1 知识组织工具比较表
续表
①当传统信息组织工具分类法用于数字环境时,抛弃了极为科学、严格、规范的类目设置,并不在意同位类之间不交叉的要求,而把重点放在信息内容本身的揭示上,通过不同的角度和入口引导普通用户找到所需的信息,从而更好地揭示内容上的参照、交叉关系。
②利用传统主题词原理产生的搜索引擎,没有采用严格规范的科学用词,也没有采用主题词中入口词规范原则,利用关键词查寻相关信息,显示了快速定位的优点,但在查准率上显得力不从心,从而导致网络产生新的知识组织和知识发现方法。
③概念地图和语义网络的最大特点是将知识结构化,并发展出语义的描述机制,以及着重表现知识的关联性[100]。
④本体继承了主题词表在规范用词上的优势,将同义词组织成同义词集,同时扩展了主题词表原有的“用、代、属、分、参、族”等简单语义关系,并在知识组织中,将传统主题词表的静态列举式的结构改变为展示人类知识创造的动态逻辑过程;将主题词表一维、线性的展示知识点拓展为本体的网状形式展示知识点;本体是语义Web的基础,基于本体构建的互联网将是机器和人都可以理解的。
⑤网格(Grid)技术是通过高性能计算环境实现全球分布资源的共享、管理、协同和控制[101]。语义网格(Semantic Grid)通过语义Web技术与网格(Grid)技术的结合,提供资源内容(信息)共享能力,即信息系统的语义互操作能力。一方面,网格是Web在计算能力上的提升,而语义网格是网格在语义能力上的扩展;另一方面,语义Web是在现有Web上增强了语义能力,而语义网格是语义Web对计算能力的扩展[102]。值得注意的是“语义”是从下到上弥漫在整个网格中而不是仅仅增加了一个语义(知识)层。使用语义网格技术可以为广域网中的数字资源构建中间环境,一方面能够形式化地描述知识,使其负载的语义能够为机器所解析和认识,另一方面使数字图书馆中的知识实现负载平衡与松散耦合,从而将知识、服务和用户有效地整合起来。
人类知识原本是一个有机联系的整体,不能因为海量、分布、动态的数字外在形式而割裂内部的联系,因此当知识载体从文本环境走向数字环境,从第一代语法字面匹配的Web环境走向第二代语义Web环境,知识组织工具不断丰富和发展,使数字信息资源体现出人类知识体系的整体性和关联性。
(3)对知识组织体系的新影响
知识组织体系(Knowledge Organization Systems,KOS),是各种对人类知识结构进行表达和有组织的阐述的语义工具(Semantic Tools)的统称,包括传统图书馆建立在文献单元基础上的分类法、标题表、叙词表以及更泛指的情报检索语言、标引语言,也包括网络时代建立在概念单元或知识单元基础上的概念地图、语义网络、本体等(如图3所示)[103]。
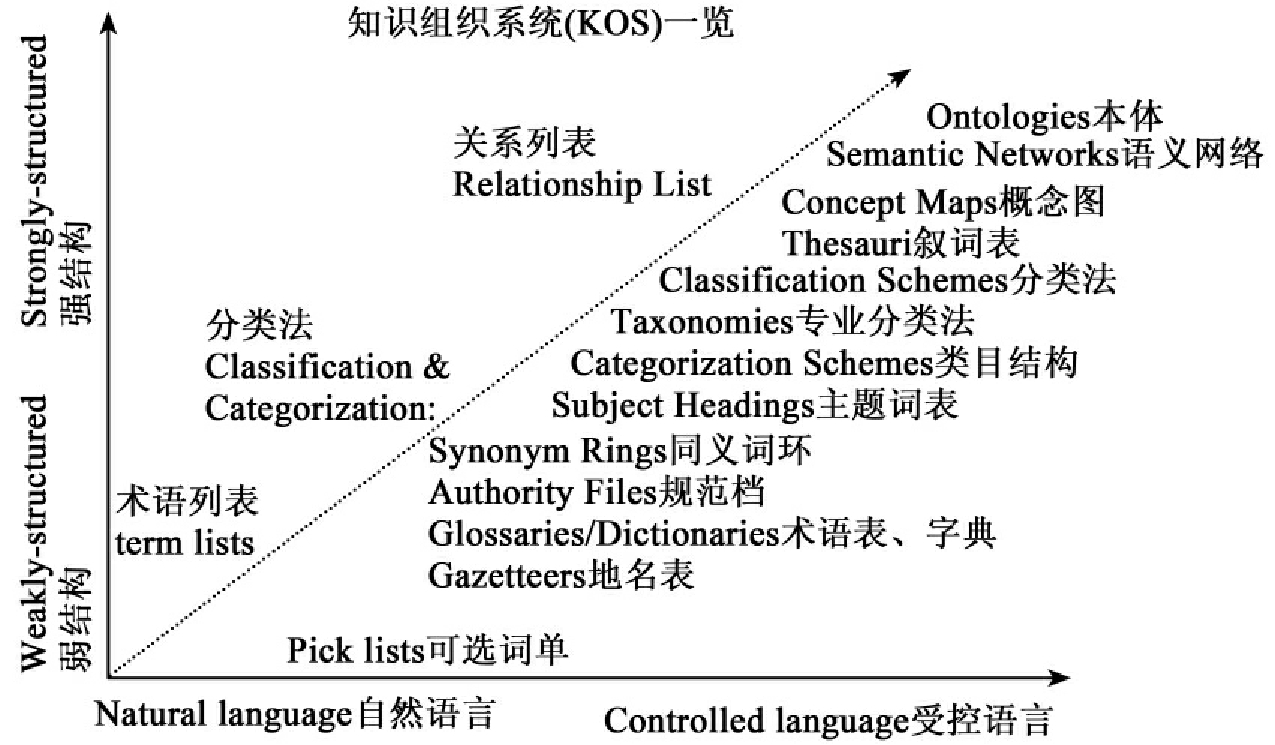
图3 KOS类型分布图
对知识组织体系发展产生最大影响的理念就是本体和语义Web。本体使知识组织体系从传统的树型结构向网状结构进化,为各类不同知识体系的结构和结合方式提供理论基础,很可能会极大促进信息/知识检索和导航功能的更新换代[104]。国外许多学术团体相继进行了利用现有叙词表转换建立本体的尝试,已经有十多种叙词表被用各种方法转换为本体[105]。
在对叙词表向本体的转换中,学者们尝试了很多方法,最常用的转换方式就是基于本体的描述语言RDF/RDF Schema。RDF是W3C推荐的一种Web资源描述语言,它提供了一种描述资源的通用的框架,使得信息可以在应用程序间交换并保持原来的语义。RDF本身没有提供专门的机制来描述属性及其关系,RDF Schema是RDF词汇描述语言,用来描述资源类之间以及类与属性之间的关系和约束[106]。
RDF Schema定义了包括描述类之间关系的Rdfs:Class和Rdfs:subClassOf,描述特性的Rdf:Property、Rdfs:Domain(定义域)、Rdfs:Range(值域)以及Rdfs:subPropertyOf等等。采用RDF Schema语言所定义的词汇描述(Schemas)也是合法的RDF图。国外已经开展应用RDF Schema进行本体转换的研究,一些具有代表性的项目包括:加州环境资源评估系统(CERES)和国家生物信息基础工程(NBII)联合开发了一套基于RDF的集成的有关环境的叙词表和叙词网络工具;联合国粮农组织(FAO)利用RDFS将Agrovoc叙词表转换为农业本体;阿姆斯特丹大学的J.Wielinga等将艺术和建筑叙词表(AAT)转换为本体。从以上项目可以看出,RDF Schema作为一种本体描述语言在灵活性以及易用性方面适合表达传统的知识组织体系。
语义Web将改变传统互联网只是实现计算机硬件和网页的连接,而数据和信息资源零散分散在各个网站的情况,对信息进行解释、交换和处理,更关注网络结构和语言的设计,可使分布于全球的成千上万的独立数据库融合,最终使用户独立运用Internet上庞大的信息资源。这种知识组织体系是采用自下而上的方式形成的,与文本秩序中的组织体系自上而下的方式不同。这种组织不是从整个知识领域入手,而是从专门的知识领域开始,创建一个个较小的块,最终形成一个更大的、更综合的结构[107]。
语义Web技术的理论和实践研究日益为图书情报界所关注和热衷。在语义Web技术的驱动下,知识表达和知识组织从物理层次上的文献单元上升到认知层次上的知识单元,从单纯的语法处理(主题法、分类法)转变为语义处理(如专家系统、语义网络表示法),从语义处理到“模拟个体知识记忆结构”的考虑语境的语用处理方式,从而使知识组织的理论和实践都发生巨大的变化,使其本身具有更大的发展空间和更强的生命力。特别是在知识组织的原则、方法和技术等方面语义Web技术必将显示出巨大的优势和强大的驱动作用,需要图书情报界给予持续关注和不断深入的研究。
4.Web、网格、语义Web环境数字信息资源组织的理论、方法与工具比较
4.1理论体系的比较
4.1.1Web信息资源组织
Web信息资源组织是以信息集成作为理论指导。Web信息资源,在类型和格式上显示出多样性,从文件、多媒体到数据库、计算工具等,几乎包括所有被数字化的资源。在集成的理念下,Web信息资源组织的研究与实践正在信息级、系统级和应用级3个层面展开,通过松散整合的方法无缝化和动态集成跨Web的不同域的分布数字信息资源[108]。
4.1.2网格信息资源组织
网格信息资源组织是以信息构建为理论指导。网格是一组一体化的共享资源,将计算机、网络、软件、数据库、仪器和人通过公共的分布式服务连接起来。网格实现统一软件标准,互操作环境(COE);服务层能提供无缝的基础设施,形成用户希望的问题求解环境。信息构建是一门组织信息和界面的艺术和科学,在信息构建的理念下,信息资源组织包括组织系统、标识系统、导航系统和搜索系统。组织系统决定内容如何分组,是内容分类的途径。标识系统决定如何称呼和调用那些分组内容,并创建一致的标识方案。导航系统决定用户如何浏览和检索分组内容,通过精心制作不同的导航路径(如导航条和知识地图),帮助用户游历和浏览内容。搜索系统帮助人们制定与相关文档相匹配的检索表达式,以满足用户的信息需求。在信息构建理论指导下,网格环境下的信息资源组织屏蔽了信息资源的来源、信息资源的不同结构、信息资源储存差异,最终形成统一的信息访问平台。4.1.3语义Web信息资源组织
语义Web信息资源组织是以知识构建为理论指导。知识构建是在传承信息构建精华后又吸收了知识管理理论而形成的[109]。
从信息构建到知识构建,就其本源来说,则对应着从信息到知识的转化;就其管理机制来说,则对应着从信息管理到知识管理的发展;就其服务体制来说,则对应着从信息服务到知识服务的进化。语义Web信息资源组织以知识元为起点,进行知识描述、知识标引,通过知识链提示知识的逻辑关系,挖掘隐性知识,提供知识服务。在知识构建的理念下,信息资源组织更加重视用户需求的范畴分类和界面设计,使之更具个性化和可视化。在内容方面,重视知识与信息的转化、知识元的抽取与标引、基于知识元链接的知识网络的形成与应用、知识结构的学科分类与完整性,以及知识仓库和知识元数据库的建设与应用,从而为数字信息资源服务营造一个和谐的知识生态环境[110]。
4.2组织方法的比较
Web、网格与语义Web的信息资源组织方法如图4所示。
Web的信息资源组织方法在宏观上采用搜索引擎和网络资源分类导航方法。在微观层面主要分为两大类:传统的文献组织方法,包括主题法、分类法;网络信息组织方法,包括数据库、主题树、超文本、搜索引擎。依知识组织的语言学原理,属于语法组织方法。
图4 信息资源组织方法
网格的信息资源组织方法在宏观上采用虚拟组织方法,即构造虚拟运行环境,将可能跨越异构、地理分布的多个运行环境的资源虚拟组织在一起,而这一虚拟运行环境为客户端提供相同的访问接口。在微观上采用网格体系结构的设计方法,即根据元数据、资源、服务、协议等概念的不同形成不同的概念空间,根据这些概念之间的关系形成网格体系结构,这一结构的层次结构不是十分清晰,各部分的关系形成一个网状图,它强调的是各部分在概念上的关联[111]。
语义Web的信息资源组织方法在宏观上采用知识表示、知识重组、知识聚类、知识存检、知识编辑、知识监控方法[112],在微观层面主要采用一阶谓词逻辑,面向对象数据库,利用语义网格、专家系统和人工智能进行数据挖掘。依知识组织的语言学原理,属于语义组织方法。
4.3技术工具的比较
Web、网格与语义Web的信息资源组织工具如表2所示。
表2 信息资源组织技术工具比较
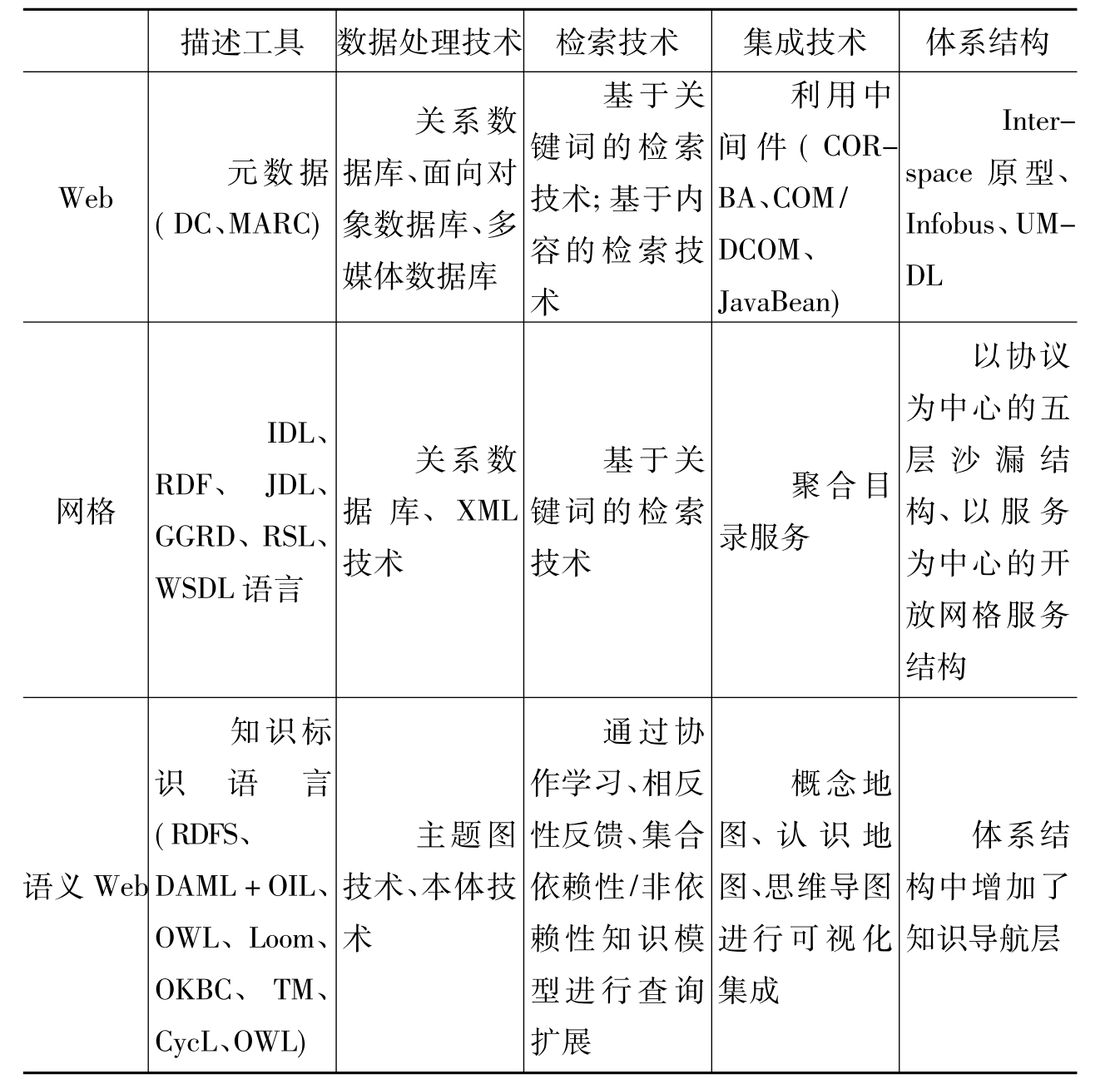
Web的信息资源组织工具利用DC、MARC等元数据对数据进行描述和标引,利用关系数据库、面向对象数据库和多媒体数据库对原始数据、管理数据、描述数据等进行存储,利用基于关键词和基于内容的检索技术提供信息服务,利用对象管理集团OMG的CORBA、Microsoft公司的COM/DCOM、Sun公司的JavaBean等中间件技术进行系统集成,形成的体系结构以Interspace原型、Infobus和UMDL最为典型。Intersapce是一个互联的信息空间的集合,每一份电子文献在信息空间中都表示为一个对象,该模型以信息单元(IU)为系统中的基础组织单元,通过IU的拼合和协作,支持复杂的互操作应用;Infobus是一个虚拟的软“总线”结构,各异构的仓储、服务和界面如同插件一样插入到信息总线中,集成在一起,通过元数据实现翻译功能;而UMDL是一个基于交互的软件代理的体系结构,其中异构的、分布的信息资源、服务、客户界面都由自主的、自治的代理表示,构成一个开放的、分布的、灵活的、可扩展的信息资源系统[113]。
网格的信息资源组织工具通过网格实现技术包括资源管理、数据管理、信息管理、通信与安全。具体表现为利用IDL(Interface Definition Language)、RDF(Resource Description Framework)、JDL(Job Description Language)、GGRD(Generic Grid Resource Description)、RSL(Resource Specification Language)、WSDL(Web Service Description Language)语言对网格中的接口、任务、计算资源、数据资源和服务资源进行描述[114][115],通过结构化数据进行数据的管理。数据的结构化通常会采取关系型数据模型或者采用XML技术,通过网格信息服务结构和组成协议(网格信息协议GRIP和网格注册协议GRRP)为高度分散的信息提供者提供专门的聚合目录服务。网格信息服务在信息索引完整性的程度、信息查询的开销和信息更新的维护这三者上不可避免地会有权衡和调节。使用元数据时间戳和信用评估可以知道保存在索引里信息的更新频率,信息传送的“推”模式和“拉”模式都可以用来将信息从提供者转移到目录[116]。目前,常用的网格体系有:以协议为中心的五层沙漏结构和以服务为中心的开放网格服务结构(Open Grid Services Architecture,OGSA)[117]。
(1)五层沙漏结构
这是一种早期的抽象层次结构,以协议为中心,强调协议在网格的资源共享和互操作中的地位。通过协议实现一种机制,使得虚拟组织的用户与资源之间可以进行资源使用的协商、建立共享关系,并且可以进一步管理和开发新的共享关系。
(2)开放网格服务结构(OGSA)
OGSA是Global Grid Forum4的重要标准建议,是目前最新也是最有影响力的一种网格体系结构,被称为是下一代的网格结构。OGSA的目的就是要将Grid的一些功能,更确切地说是Globus的一些功能融合到Web Service这个框架中。网格的核心是知识服务,而知识发现是服务里的关键技术,它要对大量的不确定的知识和信息进行处理,重用和融合,从而有效地利用知识,达到知识服务的目的。
语义Web的信息资源组织工具利用有效的知识标识语言(RDFS、DAML+OIL、OWL、Loom、OKBC、TM、CycL、OWL等),对知识库和用户需求表达进行语义描述;利用主题图技术和Ontology技术对数据进行组织,并构建包含事实库和规则库的知识库,通过概念地图(Concept Map)、认识地图(Cognitive Map)和思维导图(Mind Map)[118]等工具进行知识的可视化组织;利用协作学习方法选择新词进行查询扩展[119],通过增加语境分析选取特定域的集合来增强相关性、反馈性能,从而提高查准率;利用集合依赖性知识规模进行查询扩展[120],本体模型可以有效地辨析来自于自由文本句子的词义。本体是表达和限制语境的方法之一[121],采用以本体形式存在的集合非依赖性知识模型进行查询扩展[122],这些基于语境的查询扩展技术提高查全率和查准率。语义Web的信息资源组织在体系结构中增加了知识导航层,用于知识编辑、知识导航、知识查询。
5.语义网格技术对数字信息资源组织理论与实践的影响
基于语义Web和网格技术的数字信息资源组织的研究已经取得了较多的研究成果,但这些成果都没有真正实现“以用户为中心”的数字信息资源组织。基于语义Web技术的研究着重解决资源描述、语义互联和语义互操作,基于网格技术的研究着重解决资源的分布和异构,实际上数字资源的语义互联性和分布性、异构性是紧密联系不可分割的,融合这两方面有助于提高数字资源组织效率。
5.1语义网格的提出
在英国的e-Science[123]计划研究中,人们发现,网格的现有努力和e-Science设想之间存在差距,要达到e-Science的易用性和无缝自动化要求,必须实现尽量多的机器可处理性和尽量少的人类介入,这却和语义Web的目标有一些相似,于是在2001年最先提出了语义网格的构想,并且于2002年在全球网格论坛GGF成立了语义网格研究组SEM-GRD。他们的语义网格构想的关键之处就是把所有的资源,包括服务,都用一种机器可处理的方式来描述,其目标是实现语义的互操作性。达到这个目标的一种实现方法是把语义Web的技术应用到网格计算的开发中,下至基础设施上至网格应用。
语义网格技术是新一代的Internet技术。语义网格(Semantic Grid)通过语义Web技术与网格(Grid)技术的结合,提供资源内容(信息)共享能力,即信息系统的语义互操作能力。一方面,网格是Web在计算能力上的提升,而语义网格是网格在语义能力上的扩展;另一方面,语义Web是在现有Web上增强了语义能力,而语义网格是语义Web对计算能力的扩展[124]。值得注意的是“语义”是从下到上弥漫在整个网格中,而不是仅仅在其上增加了一个语义(知识)层,如图5所示[125]。
5.2语义网格与数字信息资源组织
语义Web和网格技术在数字信息资源建设中的重要性已被业界所普遍关注。基于UDDI、WSDL和SOAP技术的Web的信息资源抽象描述难以支持机器理解语义信息,于是出现了把语义网格技术应用到数字信息资源建设的动向。语义Web能够对数字信息资源进行基于语义的标注,提供基于语义的资源浏览与检索,为实现数字信息资源在语义层上的全方位互换,并在此基础上,实现更高层的、基于知识的智能应用提供了可行性。网格技术应用于数字信息资源建设,为实现整合分布、异构、自治的数字资源,获得资源透明调用的能力提供了可行性。但从数字信息资源组织要求基于语义的资源整合来看,上述两种技术各有其局限性。数字信息资源组织的实现需要一个新型的技术基础,这个基础应充分支持虚拟资源体系的语义资源集成,充分支持知识语义析取和语义描述,为实现虚拟资源体系的语义映射、语义导航、语义查询以及推理机提供可行性。
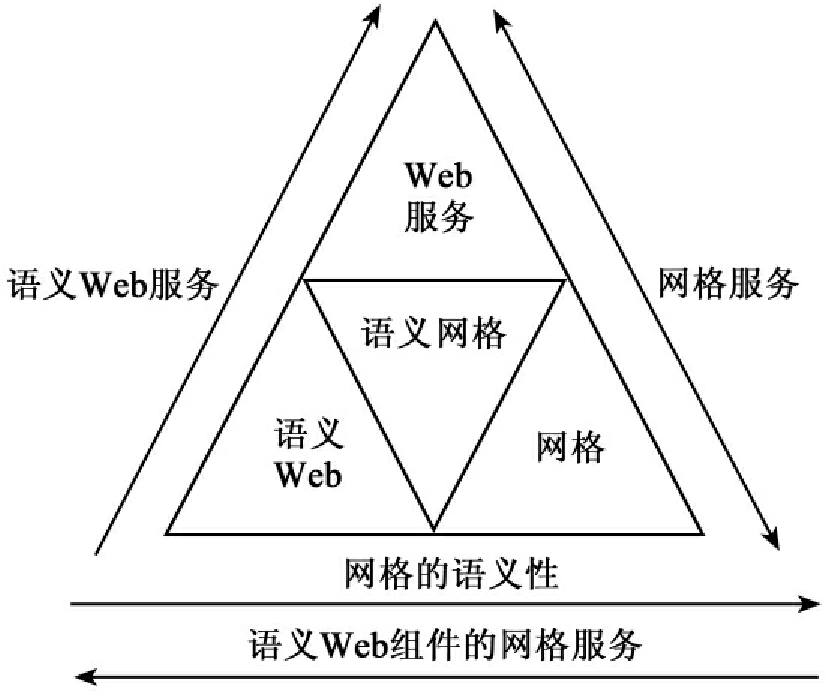
图5 语义网格与网格、语义Web、Web服务的关系
语义网格技术的出现,打破了网格、语义网格和Web服务各自独立发展的限制,体现了3种技术在数字信息资源建设中走向融合的趋势,体现了下一代数字信息资源的发展方向,为数字信息资源实现语义资源组织提供了良好的基础。语义网格技术可以为数字信息资源构建一个中间的环境:一方面能够形式化地描述知识,使其负载的语义能够为机器所解析和认识;另一方面使数字信息资源中的知识实现负载平衡与松散耦合,从而将知识、服务和用户有效地整合起来。
5.2.1理论体系
基于语义网格的数字信息资源组织以知识服务为前提,以知识管理为依托,将所有信息和服务进行有效的组织,而且能够非常明显地表示其意义,达到信息可理解[126],达到计算机和用户互操作。
(1)组织目标
将数字信息资源从集成的中央控制系统跃到可动态进行资源体、服务体联邦配置的虚拟组织,解决分布式异构信息资源和服务提供者的组织问题[127]。具体目标包括:①知识获取与知识表示的理论、模型、方法和机制;②知识可视化和创新;③在动态虚拟组织间进行有效的知识传播和知识管理;④知识的有效组织、评估、提炼和衍生;⑤知识关联和集成。
(2)组织起点——知识元
知识元是知识的最小功能单元,知识元是构造知识系统的核心。知识元的独立性、拓扑性与知识元的链接性是进行语义网格环境下数字信息资源组织的出发点。通常由知识元、知识单元组成的知识资源被认为是不含语境的。但是Ruthven I指出知识资源在产生语境当中是有用的[128],知识资源基于他们如何被创建以及为什么被创建也是带有一定的语境的,而且对于特定领域的数字信息资源来说,语境是由包含专业领域信息的数据库暗示的,同时在特定领域内用户的信息需求和信息查询行为也由于用户知识背景的不同而有所不同。这就需要从知识库中抽取用户需求表达中的知识元。
(3)组织内容
语义网格环境中数字信息资源分为两种类型:一是网格外在知识或称为网格应用知识;二是网格内在知识或称为网格基础设施知识。前者是同一语义网格平台下数字信息资源生产者发布到该网格上的知识;后者是关于该语义网格本身或数字信息资源本身对知识的运作,比如网格服务的可用性、服务目的以及服务配置方式,以及网格服务的发现、调用和动态变化。前者是语义网格知识管理的内容和对象;后者是语义网格环境下知识管理的技术基础。知识组织不仅要组织网格外在应用知识还要组织语义网格对数字信息资源的管理方式和方法。语义网格环境中存在两种分别被人和计算机理解的知识,共同理解的途径是通过元数据和Ontology对知识进行形式化,即语义注释和概念扩展。
①语义注释
在语义网格环境下,网格外在知识和网格内在知识都要求具有语义性来适应数字信息资源上层的应用。语义Web技术用来自领域本体的语义信息注释网格外在知识和网格内在知识,最终产生具有机器互操作标记的资源。考虑到互操作,一个具有良好定义的语义的数据和服务是确保使用者确实能够共享(同时理解)并使用资源的前提。语义注释远远不止我们所熟悉的关于资源内容的文本注释,语义注释正式地确定了概念以及资源中概念的关系,为机器提供使用。
②概念扩展
Ontology支持下的概念扩展,核心任务是一系列语义推理——同义扩展、语义蕴含、外延扩展及语义相关联想。语义网格环境中数字信息资源的概念空间建立在关联复杂的领域本体上。在扩展概念时,应全面权衡概念间的各种关联,综合语义相似度和相关度两种指标,作为概念词汇在意义上相符合的统一标准[129]。
在语义网格环境中,网格外在知识和网格内在知识都应该得到体现[130]。
5.2.2组织方法
从宏观上看,语义网格环境下的数字信息资源采用虚拟组织方法,因为语义网格是以支持e-Science为目标的网格基础设施,是一个开放的环境,可以兼容各种不同虚拟组织中不同的系统。从微观角度来看,基于语义网格的数字信息资源需要对上述提到的网格应用知识和网格基础设施知识进行组织。这就需要本体技术。利用本体确定知识术语范围以及关系,利用本体描述网格计算资源的有关概念。图6[131]表明本体是这一结构的特殊层级。用户查询到达模型的本体部分。本体组件利用元数据和语义视图组件获得计算资源相关信息。元数据和语义视图组件有助于本体获得用户查询答案。元数据模块直接从资源和数据文件中获得信息,而语义视图构件与元计算字典服务(Metacomputing Directory Service,MDS)进行联系,MDS提供一个分布式路径到达网格结构和系统组件相关信息。
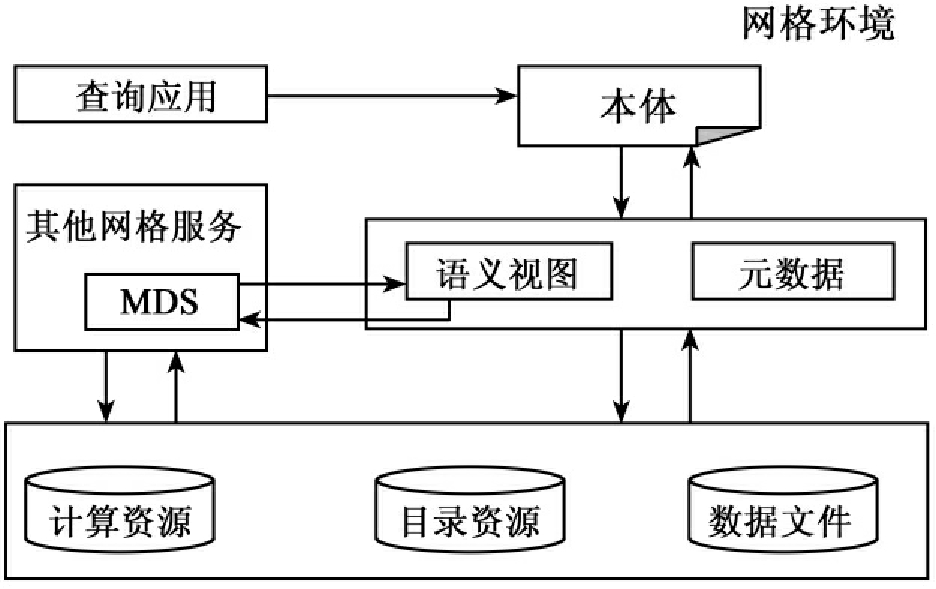
图6 基于本体的网格环境
图7说明了在网格环境中,一个数据流通过使用本体方法获得含有语义的信息。
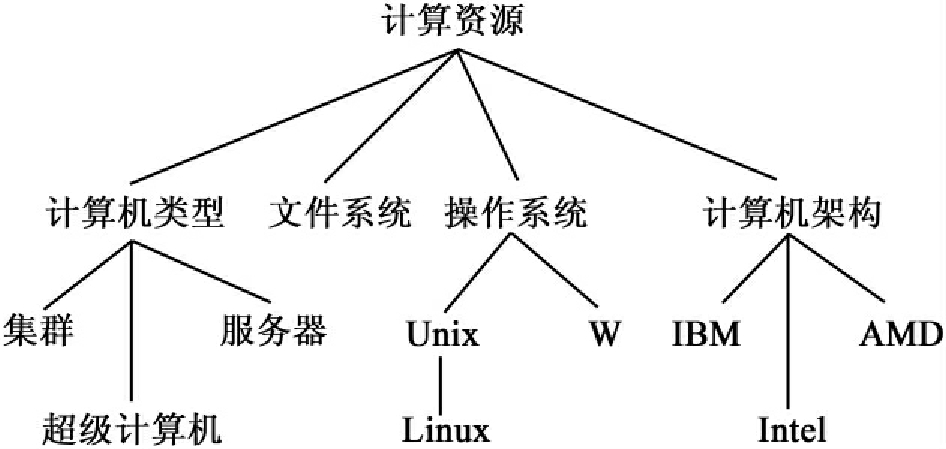
图7 计算资源的本体概念树
通过本体的属性来描述计算资源包括,构建数据字典、概念分类树、类属性、实例表和属性分类表。图3计算资源的本体概念树,对计算资源语义分析,并利用本体编辑工具(protégé-owl)建立本体。
对于网格应用知识的组织,需要语义注释,构建本体及多系统之间的本体映射,以支持语义网格环境下数字信息资源的异构和分布。
5.2.3组织过程
知识发现→知识获取→知识抽取→知识建模→知识注释→知识推理完成知识组织,组织过程如图8所示:
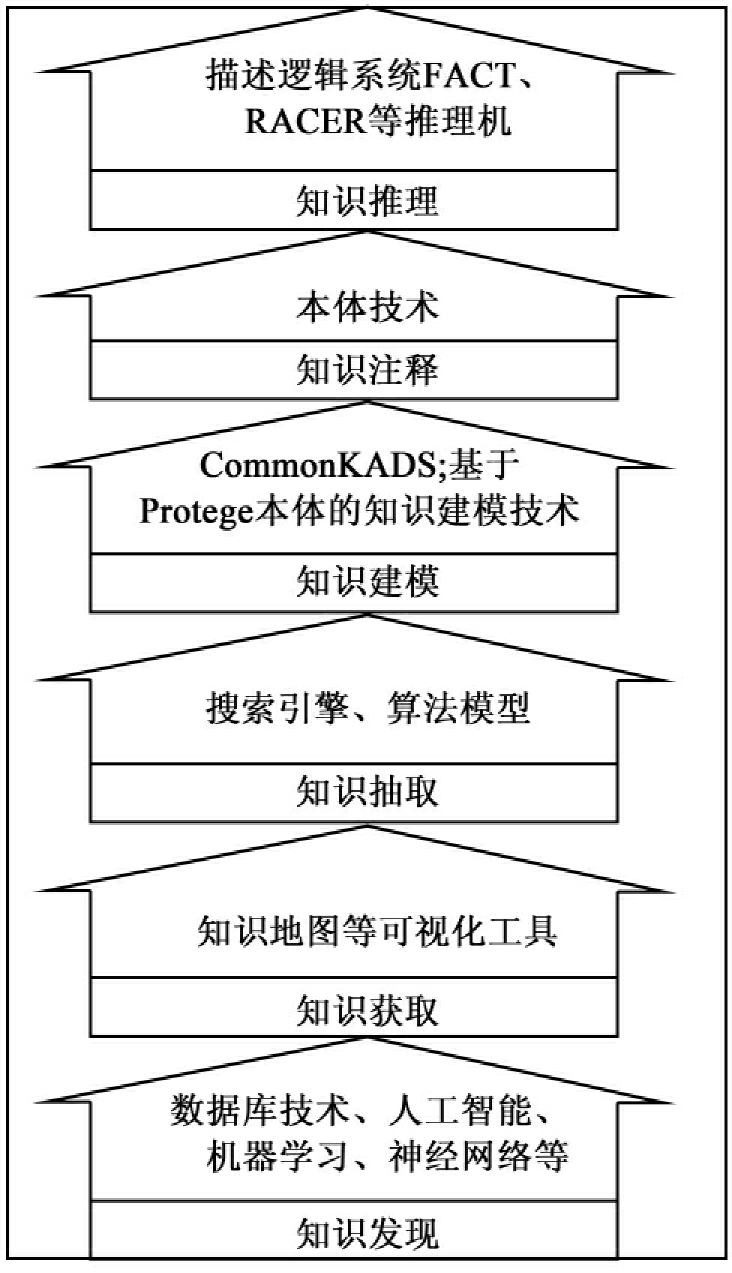
图8 语义网格环境下数字信息资源组织过程及技术工具
5.3研究实践
随着语义网格概念的提出,国内外一些学者试图将这种新技术应用于数字资源的组织研究中。英国Ali Shiri在e-Science项目报告中提出利用本体为数字资源构建基于网格的语义框架[132]。斯洛文尼亚Liubljana大学的iga Turk指出语义网格技术对于识别和标注概念和术语、本体描述、体系结构构建以及用户需求分析起着至关重要的作用,并指出语义网格技术在互操作、数字资源、虚拟组织等方面扮演重要的角色,但对于如何将语义网格技术应用于数字资源组织尚未作出详细阐述[133]。
希腊学者Ioannis Papadakis等人提出一种基于网格技术的语义数字图书馆框架,这种框架遵循OGSA规范以优化网格的基础结构,从而使之能够高效地处理某类信息。它基于面向服务的B/S结构,这种框架的设计原则能够通过开放的标准技术(如RDF和OWL)的运用来挖掘潜在信息的语义,从而满足用户的需求[134]。
美国圣地亚哥超级计算机中心的Reagan W.Moore认为,语义网格技术能够表述指定的实体和与其对应的元数据之间的关系。语义Web技术与数字图书馆和数据网格技术的整合具有管理数字图书馆和数据网格命名空间的能力,本体的使用可以表示命名空间内部关系和命名空间之间关系、数据网格管理数据和工作流的状态信息,从而构建一个推理引擎来映射网格服务间的属性并开发本体工具来管理网格服务[135]。
武汉大学信息资源研究中心的董慧认为数字图书馆知识组织体系的建设应该基于语义网格,语义网格和数字图书馆共同的目标都是资源的规范组织、语义互联和智能聚合,提出了语义网格环境下的数字图书馆新的知识组织体系标准,认为语义网格环境下的数字图书馆知识组织体系研究应该与现有知识组织体系兼容,应该加快标准化研究工作和应用模型及系统的建设[136]。
从这些研究中,我们认为使用语义网格技术可以为数字信息资源构建一个中间的环境,一方面能够形式化地描述知识,使其负载的语义能够为机器所解析和认识,另一方面使分布、异构的数字信息资源实现负载平衡与松散耦合,从而将知识、服务和用户有效地整合起来,这也是数字信息资源组织梦寐以求的目标。
6.数字信息资源组织的理论与应用技术发展
趋势
从满足文献需求向满足知识需求发展,从提供信息向提供知识化的资源系统发展,从提供信息的物理入口向构建到知识的智能入口发展,以及从关注物的因素向关注人的因素发展,数字信息资源组织领域的情景日益复杂,其理论与应用技术呈现如下发展趋势:
6.1理论研究发展趋势
(1)知识组织体系统一标准与规范
“知识组织体系”(Knowledge Organization Systems,KOS)是我们用来定义并组织表述现实世界物体的术语和符号系统,在具体应用中我们往往将它们泛指为语义工具。
目前结构化的知识组织体系在数字图书馆、数字分类系统中发挥重要的作用。随着学科深度分化、边缘融合和层次拓展,新的术语不断出现,现有概念分支也需要重新结构化;在语义Web环境下,语义之间关系更加复杂,语义关系的描述要求更加精确;不同学科不同类型的资源需要统一的知识组织体系框架进行整合,通过知识组织体系(概念术语、约束、关系、公理的表达)的参照、映射或其他方法,理解多个领域的知识表达,使信息系统具有语义交互的能力;语义Web中本体表示技术提供了比我们以前所用等级关键词树结构更丰富的表达能力,建立统一的知识组织体系标准和规范,用一种通用的结构来表达知识组织体系成为数字资源组织需要认真研究并加以解决的关键问题。其研究内容包括:①KOS表示:以结构化或半结构化的方式存储,以机器可理解的形式描述;②KOS的互操作:在异构的KOS之间实现交换、共享和集成;③标准化问题;④KOS的生成和维护:包括传统KOS的改造、向语义Web KOS的演化和KOS的自动更新与维护等;⑤KOS的应用。
(2)知识描述的本体论抽象及其进化
领域本体在知识组织体系中的地位日益重要。领域本体进化是领域本体建设的首要环节。所谓领域本体进化,即在现有领域本体基础上,依据一定的理论、方法和标准,根据应用的需要,对本体概念结构、概念关系不断进行丰富、完善、改进、更新和评估的过程与方法。领域本体进化的研究内容包括3个层面:第一个层面是本体进化的基础,即研究本体进化的依据;第二个层面是本体进化的机制,即研究本体进化的方式以及本体进化的方法和技术;第三个层面是本体进化的评估,即研究本体进化的正确性和有效性的评价指标。这3个层面的研究内容是知识描述本体论抽象及其进化需要关注的重要问题[137]。
(3)建立以本体分子为基础的多粒度知识组织模型
当前,本体知识组织面临着两难的局面:一方面以本体实例和三元组这些本体基本元素作为知识单元,显得粒度太细,会产生语义缺失问题;另一方面,如果以本体库和本体文档作为知识单元,又显得粒度太粗而且缺乏知识揭示、演化与利用的灵活性。目前迫切需要一种粒度适中的知识单元作为知识组织的基础。
董慧教授提出的本体分子理论就是一种合适的知识组织粒度。所谓本体分子,是在本体基本元素(本体实例、三元组)基础上,用唯一标识符标注的,根据语义或语用划分的,无缺失的、最小冗余的本体知识单元。建立以本体分子为基础的多粒度知识组织模型是摆在理论工作者面前的一项重要任务。其主要研究内容:①本体分子结构研究;②本体分子整合研究;③基于本体分子的本体进化应用研究等。
上述研究在理论与方法上有了实质性的进展,数字信息资源组织的理论体系才能走向成熟,才能对数字信息资源组织的实践真正起到具有可操作性的指导和推动作用,即从信息世界进入到知识内容世界。
6.2应用技术发展趋势
数字信息资源组织理论及其实践进展与应用技术的变革密切相关,数字信息资源组织应用技术变革与创新的路径,即从Web环境→语义Web环境→网格环境→语义网格环境渐变和渐进,实质是新兴技术对传统图书馆资源管理的一场深刻变革。其未来发展呈现出如下趋势:
(1)Web服务与网格融合将是网格技术的发展趋势
网格有别于Web的基本特征就在于服务的形式。目前,Web要创建应用环境,还要靠开发人员按照Web协议开发,而网格是在更高层次上对这些应用提供的一种服务形式。因此,将来的应用系统所基于的平台,应该是网格所提供的基本服务。而这种服务的本身,又会不断动态地加入到网格当中,使得网格服务内容不断丰富。
对网格计算的发展来说,目前相当重要的一项工作就是建立一个通用的网格服务标准规范,把网格计算与目前的Web服务能够很好地融合。OGSA就是在这种需求基础上诞生的,它是在Globus网格计算工具包和Web服务技术融合的基础上提出的一套规范和标准。OGSA采用Web服务框架具有两项优点:一方面,通过注册和发现接口定义和终端(Endpoint),实现描述以及动态产生特定接口绑定的代理,在异构环境中能够支持服务的动态发现与合成;另一方面,由于Web服务机制在数字信息资源组织领域广泛被采用,OGSA采用Web服务框架,使人们能够利用许多现有的开发工具和扩展服务,如产生语言绑定的WSDL处理器。
从数字资源组织的发展角度来看,Web服务提供基于XML的组件式开放标准化组织软件,而网格计算则满足了海量数据分析所需的CPU资源要求。因此,Web服务技术与网格计算技术的融合,是把Internet作为数字资源组织的计算平台,推进数字资源组织进一步发展的利器,将极大地改变传统数字资源组织的模式。
(2)P2P技术将不对称网络变为动态的、均匀的网络
P2P技术为数字信息资源组织提供了强有力的新型计算方式,更具体地说主要体现在三大类型的应用上:以资源共享为基础的协同计算、在P2P网络上开展电子商务、以P2P为基础的深度搜索引擎。
①以资源共享为基础的协同计算
协同工作是协调P2P网络中的计算机完成同一计算任务,有时这种计算模式也被称为“网格计算(Grid Computing)”,更形象的比喻是“蚂蚁搬家”。一个成功典范是1999年的SETI@HOME项目。在该项目中分布于世界各地的200万台个人电脑组成计算机阵列,搜索射电天文望远镜信号中的外星文明迹象。项目组称,在不到两年的时间里,这种计算方法已经完成了单台计算机345000年的计算量。
②在P2P网络上开展电子商务
在P2P网络上开展电子商务是人们根据P2P本身的特点就能直接想到的,而且这种模式尤其适于用户之间的商品买卖。目前,Lightshare正在P2P网络上开展电子商务,用户可以在P2P网络上购买或出售商品。用户可以搜寻待售商品信息或者列出自己欲售商品的信息。而Interbind公司将P2P技术和B2B的商务模式结合起来,为B2B商务公司开发P2P网络和分布式计算软件。该公司的软件可以使B2B用户实现文件共享,并在P2P网络上进行合作。该公司打算从软件注册、文件备份、档案管理等各种服务中赢利。
③以P2P为基础的深度搜索引擎
P2P技术的另一个优势是开发出强大的搜索工具。P2P技术使用户能够深度搜索文档,而且这种搜索无需通过Web服务器,也可以不受信息文档格式和宿主设备的限制,可达到传统目录式搜索引擎(只能搜索到20%~30%的网络资源)无可比拟的深度(理论上将包括网络上的所有开放的信息资源)。以P2P技术发展的另一先锋Gnutella进行的搜索为例:一台PC上的Gnutella软件可将用户的搜索请求同时发给网络上另外10台PC,如果搜索请求未得到满足,这10台PC中的每一台都会把该搜索请求转发给另外10台PC。这样,搜索范围将在几秒钟内以几何级数增长,几分钟内就可搜遍几百万台PC上的信息资源。可以说,P2P为互联网的信息搜索提供了全新的解决之道。著名的搜索引擎公司Google也宣称要采用P2P技术来改进其搜索引擎。
简单地说,P2P技术将实现互联网的大部分潜力,将互联网从一个网页和电子邮件网络转变成一个动态的、均匀的网络。在这个网络中,网络与计算机将不再有什么差别了——网络就是计算机。
(3)SOA是数字信息资源组织基础架构的发展归宿
现在随着网络技术的发展,数字信息资源建设中产生了大量为满足资源组织或资源服务需要的软件系统,这些系统一般都是单独实施、独立存在的。由于数据标准不统一,接口不一致,系统间往往缺少联系与合作,这也就导致了一个系统成为一个“孤岛”。而基于SOA的理念,则使数字资源组织系统的灵活性大为增加。
SOA是一种软件设计架构和方法,它将应用程序的不同功能组件定义为“服务”,通过“服务”之间的良好接口联系起来(也就是“服务”之间的松散耦合)。接口是采用中立方式进行定义的,独立于实现“服务”的硬件平台、操作系统和编程语言。而且这些构建在各种各样系统中的“服务”可以以一种统一和通用的方式进行交互,保证系统灵活性,另外,还可以保证“服务”的重复利用,而Web服务是实现SOA最好的方式。
可以看出,SOA的核心概念是“重用”和“互操作”,从而使数字资源组织系统拥有极大的灵活性。SOA的另一层意义就是整合,它将数字信息资源整合成标准的、可操作的服务,使其能被重新组合和应用。在这种架构下,组织系统的复杂性并没有增加,相反,随着系统的不断完善,整个系统的架构将变得更加清晰。SOA的重用性和互操作性所带来的灵活性实现了数字信息资源的无缝整合,使数字信息资源真正实现面向于服务。
(4)基于本体的语义注释技术与基于语义的服务发现组合技术融合
数字信息资源包括资源和其所提供的服务。数字信息资源的组织要求能够自动发现资源的语义和其包含的服务,并对其按照用户需求进行组合。目前主流的Web服务描述语言和查询手段是WSDL和UDDI。它们并没有很好地实现自动化和互操作的目标,不能表达服务的用途和能力等语义内容[138],因此其发现和组合的服务可能不能满足数字资源服务请求者的需求。
语义Web技术用来自领域本体的语义信息注释数字资源和服务,最终产生具有机器互操作标记的资源。考虑到互操作,一个具有良好定义的语义的数据和服务是确保使用者确实能够共享(同时理解)并使用资源的前提。
语义注释带来了两个优点,即改善了信息检索和互操作的能力:改善了信息检索是因为执行检索的能力,即其可以利用本体使来自异构资源的数据互为参照;互操作对于拥有遗留数据库的组织来说是非常重要的,因为这些数据库的格式通常不同,交互起来不是很容易。在这样的环境下,基于一个通用本体的注释就能为来自异构资源的信息整合提供一个通用框架。
运用语义Web服务来实现数字信息资源及其服务发现和组合的一个最显著的优势就是在于它能够在现有的Web服务标准的基础上为Web服务扩展语义信息[139],以一种机器可解释的形式来标识用于服务发现的信息[140],在可接受的时间和资源的限制下,自动操作和推理,极大地减少了人为参与。Web服务的OWL-S标记用以方便Web服务任务的自治操作,包括自动化Web服务发现、执行、互操作、合成以及执行监控[141]。
(5)知识地图技术与本体映射技术的融合
近年来,数字资源建设的迅速发展,导致数字资源愈来愈庞大,愈来愈多样化,使用单一的本体难以描述和表达多领域的知识特性,这是资源的无限存在和有限表达之间的根本矛盾。因此,数字资源的描述需要使用多个本体,即每一信息源由其自身本体所描述。“源本体”可以是多个其他本体的结合,而且不同的“源本体”并不共享相同的词汇表。其优点是它并不需要对某一全局本体的公共最小化本体进行约束,每一个源本体的开发也不用顾及其他信息源或其本体,这种本体架构可简化集成任务,并支持源的变化。但另一方面,公共词汇表的缺乏使不同源本体的比较变得困难。
一般的研究认为,为了解决这种问题,可以将多个领域本体集成起来,形成一个虚拟的关于这几个领域的领域本体,这样不仅可以避免重复建设而且更容易通过交流合作形成领域内共享的本体。领域本体集合的关键技术是本体映射,本体映射定义一套规则指明一个本体中的术语在另一个本体中的相关含义,由中介在应用程序运行时执行。
由于本体结构的复杂性,及组织本体形式上的多种异构性的存在(如:对领域认识的不一致,应用所要求的特殊性处理)等,使本体映射在实现上还存在诸多问题:①构建本体映射大多还需要领域专家大量地手工介入,自动化程度还达不到大规模本体共享与交流的要求。②本体映射采用的语言规范以及映射规则的表示、结果和处理方法还没有规范统一,这给本体的共享使用带来阻碍。③实际的本体映射并不简单地是一对一的映射(类名、关系名、属性名从一个本体到另一个本体的映射),还需要对继承和推理的一致性进行校验和确认,这使得本已复杂的本体映射规则的构建变得更加困难[142]。④单领域或跨领域的本体映射还存在多对一、一对多和多对多的关系。简单的一对一映射不能解决这样的问题。
知识地图技术可以有效地解决目前多领域本体互联研究中所面临的问题。首先,避免了为每一个领域本体提供一组转换函数使得它在没有中介本体的情况下直接跟其他领域本体交流所面临的计算复杂度;其次,它无需创建一个超复杂的共享本体。它类似于本体聚类技术,只需将现存的本体进行简单加工,进行简单的语义标注,增加必要的语义链,即可与相关的本体进行关联。多个领域本体根据其相关性,利用语义知识链连接起来,形成一个既关联,又相对独立的知识地图。为了便于在大量的领域本体中快速定位,在本体知识地图之上附加一个索引层,对知识地图进行语义索引,以便使用者在知识地图中快速定位。
在数字信息资源组织中,利用知识地图技术,可以有效地对领域本体进行知识连接和引导,从而将本体与知识地图融合起来,形成本体知识地图。在本体知识地图中,其基本单元是领域本体,领域本体描述的是某个领域的数字资源的知识属性。知识地图可以揭示领域本体之间的语义关联。
7.结语
数字信息资源组织随着人类信息环境向数字化、网络化平台迁移,传统知识组织工具的数字化、网络化势在必行,数字信息资源主流化需要相应的语义工具而逐渐形成的一个新的研究领域与实践领域。目前较为成熟的数字信息资源组织技术都与语义网格计划有着密切的关系。语义网格旨在将现有网络发展成为一个数据交换与集成、知识化利用与管理的基础环境,其架构需要新的信息组织机制的支持,其实践需要以一定的理论为指导,同时也需要遵循相应的标准与规范。由于数字信息资源组织实践尚不成熟,其研究的基础相对薄弱,本文只是概括性地分析了目前的研究现状与实践进展,许多问题还需要进行深入而细致的研究与总结。
【参考文献】
[1]王忠,周士波.Internet英文搜索引擎评价[J].图书情报工作,1999(4):33-37.
[2]孙丽,陈通宝,乔晓东.网上中文检索工具的比较研究[J].情报学报,1999,18(3):225-234.
[3]徐建华,伍宪,胡燕菘.国外六个著名搜索引擎的特征和评析[J].现代图书情报检索技术,2001(1):48-51.
[4]Lancaster F.W,Fayen E.C.Information Retrieval On-line[M].Los Angeles,Melville,1973.
[5]储荷婷.国际互联网检索工具:特点、比较和发展方向[J].大学图书馆学报,1997,15(3):6-11,14.
[6]曾民族.网络信息检索现状和性能评价[J].情报学报,1997,16(2):90-99.
[7]黄如花.网络信息的检索与利用[M].武汉:武汉大学出版社,2002.
[8]曹东,韩全惜,庄军.运用情报检索语言理论与方法完善搜索引擎的功能[J].情报理论与实践,2000,23(1):58-61.
[9]尚克聪,杨立英.网络环境下情报检索系统性能评价研究[J].图书情报工作,2002(1):68-71.
[10]陈树年.搜索引擎及网络信息资源的分类组织[J].图书情报工作,2000(4):31-37.
[11]马张华,张宇萌.指南型网络分类体系初探[J].大学图书馆学报,2000(3):22-25.
[12]马张华.分类搜索引擎类目体系研究[J].图书情报工作,2001(2):36-40.
[13]黄建年.网络信息分类浅议[J].情报学报,1999,18(6):514-518.
[14]陈光祚.论“图书情报学虚拟图书馆”的建设[J].中国图书馆学报,2000(1):19-23.
[15]贺亚锋,张颖.Web资源虚拟图书馆研究[J].大学图书馆学报,2000(5):31-34.
[16]楼宏青.高校重点学科导航库建设探析[J].大学图书馆学报,2001(4):30-33.
[17]隋利玲,郭瑜.Internet上专业性网络资源导航库的建设[J].现代图书情报技术,1997(2).
[18]刘静.建立Internet电子专业网络资源导航库的构想[J].图书与情报工作,1998(1):6-9.
[19]司莉.网络信息资源组织研究进展[J].情报科学,2003,21(6):653-658.
[20]P.A.Cochrane.New Roles for Classification in Libraries and Information Network[J].Catalog&Classification Quarterly,1996,21(2):1-2.
[21]T.Koch.The Role of Classification Schemes in Internet Resources Description and Discovery[EB/OL].[2002-07-27].http://www.ub.lu.se/desire/radar/reports/D3.2.3/class-v10.html.
[22]洪漪,梁树柏.分类法在信息网络中的应用[J].情报学报,1998,17(1):19-22.
[23]Nacy J.Williamson.Knowledge Structures and the Internet.In Knowledge Organization for Information Retrieval[C].Proceeding of the 6thInternational Study Conference on the Classification Research.The Hague:FID,1997:23-27.
[24]Hamid Saeed,Abdus Satter Chaudry.Potential of Bibliographic Tools to Organize Knowledge on the Internet:the Use of Dewey Decimal Classification Scheme for Organizing Web-based Information Resources[J].Knowledge Organization,2001,28(1): 17-26.
[25]马张华.文献分类法在网络资源组织中的应用[J].图书情报工作,1999(12):24-29.
[26]俞君立,陈树年.文献分类学[M].武汉:武汉大学出版社,2001.
[27]邓均华.数字图书馆与数字分类法[J].中国图书馆学报,2001(4):76-77.
[28]卜书庆.试论数字信息资源的组织方法[J].国家图书馆学刊,2001(4):46-49.
[29]杨涛.主题法在网络信息组织中的应用[J].图书馆建设,2002(1):50-52.
[30]邱君瑞,耿亦兵.主题词表在网络检索系统中的高水平运用调查分析[J].图书馆杂志,2001(11):20-22.
[31]王亚军,张和芬.面向用户的图书馆网络信息资源组织与服务[J].情报资料工作,2001(5):47-49.
[32]Zachary G.Ives:Efficient Query Processing for Data Integation[J].University of Washington,2002.
[33]T.Lahiri,Sahiteboul,J.Widom.Ozone:Integration Structured and Semi-structured Data[J].Techniques University,1999: 95-106.
[34]王宁,王能斌.异构数据源集成系统查询分解和优化的实现[J].软件学报,2000,1:222-228.
[35]岳丽华,韩恺,龚育昌.异构数据源集成系统KD-IR IS[J].计算机科学,2001,28:252-255.
[36]吴啸鹏等.WrapperBase:基于CORBA网络的Web信息集成系统[J].计算机科学,2001,28:264-268.
[37]Wong K.K,Bazex P.MRDSM:a Relational Multidatabase Management System[C].In:Proc.Third Int.Seminar Distributed Data Sharing System,Mar.1984.
[38]Motro A.Superviews:Virtual Integration of Multip le Databases[J].IEEE Trans.on Software Engineering,1987,SE-13(7): 785-798.
[39]Li C,et al.Capability Based Mediation in TSIMMIS[C].In: Proc.of the ACM SIGMOD Conf,1998:564-566.
[40]Bayardo R.J,et al.Infosleuth:Agent-based Semantic Integration of Information in Open and Dynamic Enviroments[C].In: Proc.of ACM SIGMOD Intl.Conf,1997:195-206.
[41]Ahmed R,et al.The Pegasus Heterogeneous Multidatabase System[J].IEEE Computer,1991,24(12):22-29.
[42]Kim W,et al.Classifying Schematic and Data Heterogeneity Inmulti-database Systems[J].IEEE Computer,Dec.1991:12-18.
[43]彭智勇.基于对象代理模型的异构多数据库集成[J].计算机科学,2002,29:256-258.
[44]王兰成,敖毅,曾琼.异构多信息源组织与集成技术的研究现状及其进展[J].现代图书情报技术,2006(3):68-71.
[45]张俊.网格环境下的应用模式的研究[D].北京:北京理工大学,2003(1).
[46]王丽华.基于网格技术的虚拟图书馆[J].情报科学,2004(4):482-487.
[47]王艳峰,王峰,王恩海,李慧,唐俊华.网格资源描述与发现[EB/OL].[2002-11-21].http://www.chinagrid.net/grid/ paperppt/gct/gct08.ppt.
[48]杨玉麟.信息描述[M].北京:高等教育出版社,2004:4-5.
[49]The DELOS web-team.Activities within the DELOS Network of Excellence on Digital Libraries[EB/OL].[2005-11-27].http:∥www.delos.info/.
[50]Digital Library Grid项目组.Digital Library Grid[EB/OL].[2005-11-20].http://128.82.7.230/grid/.
[51]FreeLib项目组.P2P Digital Library[EB/OL].[2005-11-10].http:∥p2pdl.cs.odu.edu.
[52]Han Fei,Nuno Almeida,Miguel Loureno.ARCO:Moving Digital Library Storage to Grid Computing[EB/OL].[2005-11-10].http://citeseer.ist.psu.edu/664659.html.
[53]DILIGENT项目.DILIEGNTProjectOverview[EB/OL].[2005-11-15].http://diligentproject.org/.
[54]GRACE项目.Project Overview[EB/OL].[2005-12-11].http://www.grace-ist.org.
[55]董慧,王国育.基于OAI的数字图书馆网格应用系统框架体系研究[C].数字图书馆网格应用模型研究:2005年信息化与信息资源管理学术研讨会论文集[D].武汉:湖北人民出版社,2005:96-104.
[56]郑志蕴,闭乐鹏,牛振东等.数字图书馆网格互操作框架[J].计算机工程与应用,2005(25):186-189.
[57]曲建峰,杨宗英,郑巧英等.基于网格的数字图书馆服务模式探讨[J].现代图书情报技术,2006(2):10-14.
[58]李宁,宋文.对于知识组织体系概念以及构建模式的一些思考[J].图书情报工作,2005(10):37-40.
[59]罗昊.语义网信息组织论纲[J].图书情报工作,2005(7):16-17.
[60]Brendan Rousseau,Ronald Rousseau.Some Ideas Concerning the Semantic Web[J].Library and Information Service,2002(8):39-49.
[61]York Sure,Rudi Studer.Semantic Web Technologies for Digital Libraries[EB/OL].[2006-02-24].http://www.aifb.unikarlsruhe.de/WBS/ysu/publications/2005_sw_for_dl.pdf.
[62]Deborah,L.McGuinness,Paulo Pinheiro da Silva.Explaining Answers from the Semantic Web:the Inference Web Approach[EB/OL].[2005-04-06].http://www.websemanticsjournal.org/ps/pub/2004-22.
[63]F.Giunchiglia,P.Shvaiko.SemanticMatching[J].The Knowledge Engineering Review,2003(3):265-280.
[64]R.V.Guha,R.McCool,E.Miller.Semantic Search[EB/OL].[2006-01-25].http://tap.stanford.edu/ess.pdf.
[65]S.Deill et.Sem Tag and Sem Seeker:Bootstrapping the Semantic Web Via Automated Semantic Annotation[EB/OL].[2006-01-25].http://www.almaden.ibm.com/webfountain/resources/semtag.pdf.
[66]B.Hammond,A.Sheth,K.Kochut.Semantic Enhancement Engine:a Modular Document Enhancement Platform for Semantic Applications over Heterogeneous Content[EB/OL].[2006-01-24].http://lsdis.cs.uga.edu/lib/download/HSK02-SEE.pdf.
[67]A.Sheth,C.Ramakrishnan.Semantic(Web)Technology In Action:Ontology Driven Information Systems for Search,Integration and Analysis[J].IEEE Data Engineering Bulletin,Special Issue on Making the Semantic Web Real,December 2003: 40-48.
[68]黄如花.数字图书馆信息组织的优化[J].情报科学,2004(12):1435-1439.
[69]张振海.Ontology与网格计算[EB/OL].[2006-02-24].http://tpi.cnki.net/meeting/tpi40/pdf/ontology.pdf.
[70]颜端武,王日芬,岑咏华等.数字图书馆中基于语义Web和数据挖掘的智能推荐检索机制研究和探讨[C].2005年信息化与信息资源管理学术研讨会论文集[D].武汉:湖北人民出版社,2005:193-203.
[71]余正涛,宋面,樊孝忠.基于本体的个性化领域信息服务[J].计算机工程,2005(5):22-24,81.
[72]A Survey on Ontology Tools.IST Project2001-29243 OntoWeb Deliverable1.3,Finalversion[EB/OL].http://babage.dia.fi.upm.es/ontoweb/wp1/OntoRoadMap/documents/D13_/v1_0.pdf,2002.
[73]Semantic Web Annotation and Authoring Community Homepage[EB/OL].http://annotation.semanticweb.org/current,20040418.
[74]UBOT Applications.Semantic Markup Plug-in for Internet Explorer[EB/OL].http://mr.tecknowledge.com/DAML/IEMarkup-PlugIn/IESemanticMarkupPlugin.htm,2004.
[75]Marcelo Tallis.Semantic Word Processing for Content Authors[C].Workshop Notes of the Knowledge Markup and Semantic Annotation Workshop(SEMANNOT2003),Second International Conference on Knowledge Capture(K-CAP2003).Sanibel,Florida,USA.Octorber 26,2003.
[76]Jose Kahan.An Open RDF Infrastructure for Shared Web Annotations[EB/OL].http:∥www.w3.org/2001/Annotea/Papers/www10/annotea-www10.html,2001.
[77]FabioCiravegna,AlexieiDingli.User-SystemCooperationin Document Annotation based on Information Extraction[C].Proc.of the 13thInternational Conference on Knowledge Engineering and Knowledge Management(EKAW02),Siguenza,Spain.October 14,2002.
[78]Hamish Cunningharm,Diana Maynard.Developing Language Processing Components with GATE(a User Guide).For Gate version2.1[EB/OL].http://gate.ac.uk/sale/tao/,2003.
[79]Marcelo Tallis,Neil M.Goldman,Robert M.Blazer.The Briefing Associate:Easing Authors to The Semantic Web[C].IEEE Intelligent Systems,2002,17(1):26-32.
[80]Siegfried Handschuh,Steffen Staab.Authoring and Annotation of WebPages in CREAM[EB/OL].http://www.aifb.unikarlsruhe.de/WBS/sha/papers/aa_cream_www11.pdf,2002.
[81]Aditya Kalyanpur,James Hendler.SMORE-Semantic Markup,Ontology and RDF Editor[EB/OL].http:∥www.mindswap.org/papers/SMORE.pdf,2002.
[82]Alexander Sigel.The Knowledge Organization on Internet mini-FAQ[EB/OL].[2005-03-30].http://ceiba3.cc.ntu.edu.tw/course/cb9879/92-paper1/The%20Knowledge%20 Organization%20on%20 Internet%20Mini-FAQ-1.pdf.
[83]J.D.Anderson.The Knowledge Organization on Internet[EB/ OL].[2002-04-20].http://index.bonn.iz-soz.de/~sigel/ISKO/wiss-org.faq.html.
[84]丰成君.知识组织与图书情报工作[J].知识工程,1989(3):11-14.
[85]马费成.知识组织系统的演进与评价[J].知识工程,1989(2):39-43.
[86]贾同兴.知识组织的进步[J].国外情报科学,1996(2): 36-38,42.
[87]王知津.知识组织的研究范围及发展策略[J].中国图书馆学报,1998(4):3-8.
[88]蒋永福.知识组织论:图书情报学的理论基础[J].图书馆建设,2000(4):14-17.
[89]储节旺.信息组织:原理、方法和技术[J].安徽大学出版社,2002.6.
[90]Birger Hjφrland.Information Seeking and Subject Representation: An Activity-Theoretical Approach to Information Science[C],Chapter 3“Subject Analysis and Knowledge Organization”.Greenwood Press,1997.
[91]付小红.论知识组织的原则[J].情报资料工作,2001(5):11-15.
[92]盛小平.数字图书馆的知识组织[J].图书情报工作,2001(3):26-29.
[93]刘洪波.知识组织论——关于图书馆内部活动的一种说明[J].图书馆,1991(2):13-18,48.
[94]王知津.知识组织的目标与任务[J].情报理论与实践,1999(2):65-68.
[95]C.W.Holsapple,K.S.Joshi.A Formal Knowledge Management Ontology:Conduct,Activities,Resources,andInfluences[C].Journal of the American Society for Information Science and Technology.2004(5):593-612.
[96]田稷.语义Web与网络信息和知识的表达[J].情报杂志,2003(6):43-44.
[97]王知津,王乐.文献演化及其级别划分——从知识组织角度进行探讨[J].图书情报工作,1998(1):4-7.
[98]马费成.在数字环境下实现知识的组织和提供[J].郑州大学学报(哲学社会科学版),2005(4):5-7.
[99]李景.主要本体表示语言的比较研究[J].现代图书情报技术,2005(1):1-4,8.
[100]陈亚宁,陈淑君.以知识探索为本之知识组织方法论及研究分析[EB/OL].[2004-01-24].http://www.sinica.edu.tw/~metadata/bibliography/journal/blis2001_3900.pdf.
[101]H.Zhuge.Clustering Soft-Devices in Semantic Grid[J].IEEE Computing in Science and Engineering,2002(6):60-62.
[102]Marije Geldof.The Semantic Grid:will Semantic Web and Grid Go Hand in Hand?[EB/OL].[2006-02-26].http://www.semanticgrid.org/documents/Semantic%20Grid%20report%20 public.pdf.
[103]闫巍,曾民族.构筑知识基础结构的关键技术[J].现代图书情报技术,2005(8):1-6,31.
[104]李宁,宋文.对于知识组织体系概念以及构建模式的一些思考[J].图书情报工作,2005(10):37-40.
[105]唐静.叙词表转换为Ontology的研究[J].信息系统,2004(6):642-645.
[106]RDF入门推荐标准[EB/OL].[2006-02-18].http://zh.transwiki.org/cn/rdfprimer.htm.
[107]王知津,张国华.Web环境下个性化知识组织初探[J].情报资料工作,2005(1):51-55.
[108]杨晓航,张晓林.语义空间系统:语义Web技术的新应用——基于语义整合Web资源与服务[J].情报杂志,2006(2):7.
[109]柯平,王平.从信息构建到知识构建:基于知识构建的第二代知识管理[J].图书情报工作,2004(6):20-24.
[110]姜永常.CNKI数字图书馆知识服务研究[J].情报学报,2akl(3):265-274.
[111]都志辉,陈渝,刘鹏,王小鸽,杜江,周念生.以服务为中心的网格体系结构OGSA[J].计算机科学,2003.
[112]蒋永福,李景正.论知识组织[J].中国图书馆学报,2001(1).
[113]王军,杨冬青,唐世谓,杨烈勋.数字图书馆的体系结构[J].情报学报.2000(6):564-572.
[114]王艳峰,王峰,王恩海,李慧,唐俊华.网格资源描述与发现[EB/OL].[2007-03-06].http://www.chinagrid.net/grid/paperppt/gct/gct08.ppt.
[115]樊宁.网格的资源管理和信息管理概述[EB/OL].[2007/ 03/06].http://www.ibm.com/developerworks/cn/grid/grfannl/.
[116]李进华.网格知识管理[D].武汉大学硕士论文,2005年4月.
[117]I.Foster,C.Kesselman,J.Nick,S.Tuecke.The Physiology of the Grid:an Open Grid Service Architecture for Distributed Systems Integration[EB/OL].http://www.globus.ord/research/papers/ogsa.pdf.
[118]周字,张芳芳,余肖生.可视化技术在知识管理领域的发展[J].图书情报工作2006(11):68-71.
[119]Klink S.Improving Document Transformation Techniques with Collaborative Learned Term-based Concepts[J].Reading and Learning:Adaptive Content Recognition,2004(2956):281-305.Berlin,Heidelberg,New York:Springe-Verlag.
[120]J.Bhogal,A.macfarlane,P.Smith.A Reviews of Ontology Based Query Expansion[J].Information Processing&Management,2006(9):1-21.
[121]Buckland M.Translingual Information Management Using Domain Ontologies[EB/OL].[2006-10-15].http://metadata.sims.berkeley.edu/GrantSupported/tides.html.
[122]Leroy,G.Tolle,H.Chen.Customizable and Ontology-enhanced Medical Information Retrieval Interfaces[EB/OL].[2006-10-10].http://dlist.sir.arizona.edu/436/01/leroy5.pdf.
[123]De Roure D,Hendler J.A.E-Science:the Grid and the Semantic Web[J].IEEE Intelligent Systems,19(1):65-71.
[124]语义网格[EB/OL].[2005-12-26].http:∥wiki.donews.com/index.php?title=%E8%AF%AD%E4%B9%89% E7%BD%91%E6%A0%BC&diff=next&oldid= 24516&printable=yes.
[125]同[102].
[126]荣毅虹,田也壮.论信息的可理解[J].情报学报,2006(4):393-398.
[127]张付志,胡媛媛.下一代数字图书馆的体系结构及其信息访问技术研究[J].情报学报,2006(5):540-545.
[128]Ruthven I.Re-examining the Potential Effectiveness of Interactive Query Expansion[A].Annual International ACM SIGIR Conference 2003[C].Toronto:ACM,2003.
[129]聂卉.基于本体的查询扩展与规范[J].现代图书情报技术,2007(3):35-36.
[130]同[128].
[131]同[117].
[132]Ali Shiri.Schemas and Ontologies:Building a Semantic Infrastructure for the Grid and Digital Libraries,Workshop Report from E-Science Institute,Edinburgh 16 May 2003[EB/OL].[2006-02-26].http:∥www.cis.strath.ac.uk/research/publications/papers/strath_cis_publication_41.pdf.
[133]iga Turk.Semantic Grid Roadmap[J].Semantic Grid,the Convergence of Technologies,Dagstuhl,2005(7):3-8.
[134]Ioannis Papadakis,Agapios Avramidis,Vassilis Chrissikopoulos.Reasoning against a Semantic Digital Library Framework Based on Grid Technology[EB/OL].[2006-02-26].http:∥www.emeraldinsight.com/Insight/ViewContentServlet?Filename= Published/EmeraldFullTextArticle/Articles/ 0150260408.html.
[135]Reagan W.Moore(San Diego Supercomputer Center).Dagstuhl Seminar Proceedings 05271 Semantic Grid:The Convergence of Technologies[EB/OL].[2006-02-20].http:∥drops.dagstuhl.de/opus/volltexte/2005/390.
[136]董慧,孙雨生.基于ontology的数字图书馆互操作问题研究[C].数字图书馆网格应用模型研究:2005信息化与信息资源管理学术研讨会论文集[D].武汉:湖北人民出版社,2005:227-234.
[137]马文峰,杜小勇.领域本体进化研究[J].图书情报工作,2006(6):71-72.
[138]Li Lei,Horrocks I.A Software Framework for Matchmaking Based on Semantic Web Technology[EB/OL].[2007-03-25].http://www.cs.man.ac.uk/~lil/papers/ijec.pdf.
[139]史忠植,蒋运承,张海俊.基于描述逻辑的主体服务匹配[J].计算机学报,2004,27(5):625-635.
[140]OWL—S 1.1 Specification White Paper[EB/OL].[2007-03-07].http://www.daml.org.
[141]胡昌平等.面向用户的信息资源整合与服务[M].武汉:武汉大学出版社,2007:339-367.
[142]Y.Ding,S.Foo.Ontology Research and Development,Part 2—A Review of Ontology Mapping and Evolving[J].Journal of Information Science,2002,28(5),375-388.
【作者简介】

毕强,男,教授,博士生导师,吉林大学信息资源研究中心副主任,《情报科学》副主编。中国科技信息学会理事,吉林省科技信息学会副理事长,学术委员会主任委员,吉林省图书馆学会副理事长,学术委员会主任委员。主要研究方向:数字信息资源管理与利用,数字图书馆等。主持完成国家社科基金项目和教育部哲学社会科学规划项目。出版著作与教材8部,发表论文百余篇。
【注释】
(1)本文系教育部哲学社会科学研究重大课题攻关项目“数字信息资源规划、管理与利用研究”(项目编号:05JZD00024)研究成果之一。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。









