



4.3 数字信息资源组织的方式
数字信息资源组织的方式是指人们利用现代技术,结合数字信息资源的特点,对其进行加工、整理、排列、组合,使之有序化、系统化以后所呈现给用户的结构方式和表现形式。这种结构方式和表现形式,随着信息技术的进步,用户需求的变化而不断创新。到目前为止,已产生多种组织方式,谢晓专根据数字信息资源组织模式的特点,将其划分为微观信息组织模式、中观信息组织模式和宏观信息组织模式三种类型(14)。其中,数字信息资源组织的微观模式包括文件方式、自由文本方式、超媒体方式和主页、页面方式;数字信息资源组织的中观模式包括搜索引擎方式、主题树方式(目录指南方式)和指示数据库方式;数字信息资源的宏观组织模式有学科信息门户模式和信息重组模式。网络环境下,用于组织数字信息资源的常用方式主要有以下几种。
4.3.1 文件方式
文件是一种有组织的数据集合。在计算机出现的早期,信息一般是按物理地址直接存储在媒体上。引入文件概念以后,人们利用计算机所具有的文件处理理论与技术,实现了按文件名对信息进行存取,文件组织方式应运而生。以文件的方式组织数字信息资源简单方便,可以降低信息组织的难度和成本。如FTP(File Transfer Protocol)文件传输协议就可以帮助用户利用以文件形式保存和组织的数字信息资源,在因特网上,几乎所有文件的传输要通过FTP来实现,它是实现数据共享的无价之宝。
FTP的功能是利用网络在本地机与远程计算机之间建立关联,并将文件在远程机与本地主机之间进行传送。用户要想快速获取FTP上的文件,一般要借助于Archie。所谓Archie,是自动追踪因特网上的匿名文件传输站点(Anonymous FTP Sites)及其收藏的文件名称,并定期更新上述信息,以提供网络用户查询的系统,是1991年由加拿大麦吉尔(McGill)大学计算机系的Peter Deutsch和Alan Emtage共同开发的FTP资源检索工具。它的主要功能是通过文件名检索网上匿名FTP服务器中的文件,帮助用户了解所需软件或文件的FTP地址及目录。
文件方式主要适用于对非结构化信息资源进行组织管理,如程序、图形、图像、音频、视频等。虽然,以文件系统来组织和管理数字信息资源简单方便,但是,随着数字信息资源的不断增长与网络利用的普及,以文件方式来组织与日俱增的数字信息资源,就显得捉襟见肘:首先,文件大小是随着网络信息量的增加而同步增长的,如果文件过大,势必使得信息组织过程中网络传输负载越来越大;如果将文件大小限制在适合网络传输的限度内,那么会降低网络信息资源的利用率,也就降低了信息组织的效率(15);其次,文件方式对结构化信息的组织与管理软弱无力,文件系统只涉及信息的简单逻辑结构,当信息结构较为复杂时,就难以实现有效的控制与管理。因此,文件只能是数字信息资源管理的辅助形式,或者作为信息单位成为其他信息组织的管理对象(16)。
4.3.2 超媒体方式
超媒体方式将超文本技术与多媒体技术结合起来,将文字、表格、声音、图像、影视等多媒体信息以超文本方式组织起来,使人们可以通过高度链接的网络结构在各种信息库中自由查询,找到自己所需的任何媒体信息。
超文本(Hypertext)和超媒体(Hypermedia)两个词是美籍丹麦学者T.Nelson于20世纪60年代提出的。超文本是一种信息管理技术,它在信息组织上的显著特点是将信息组织在一系列离散的信息节点(Node)中,通过链(Link)建立节点与节点之间的联系,形成一个由节点及链组成的网状(Network)信息结构。它们中既有单向或双向联系,也有因果关系、从属关系或并列关系的联系。采用这种网状连接,各节点的信息很容易按照人们的“联想”关系加以组织。
节点和链是超文本系统中两个最基本的组成元素。节点是围绕某一特殊的主题组织起来的自然数据信息单元,节点中的信息可以是文字、数据、图形、图像、声音、动画、视频、计算机程序或它们的组合。一个词可以构成一个节点,一篇上万字的文章也可以构成一个节点。在超文本系统中,节点与外界的联系存在一个数量、方向问题,一般而言,节点越多为用户提供的检索途径就越多。两个节点之间的连接称为链,它是网页表现信息之间联系的实体,是将不同节点联系起来的工具。
超文本是由节点和链组成的一种非线性的文本组织技术,链定义了超文本的非线性结构,提供了浏览、查询节点的能力。因此,人们称链是超文本的灵魂(17)。超媒体技术继承和发展了超文本的非线性网络结构,其节点内容除文本以外,还可以将图形、图像、视频、音频以及动画等多种媒体信息集成在一起。
虽然,超文本、超媒体都属于新的多媒体信息管理技术,其信息组织是非线性、联想式的。但是,两者之间是有区别的,超文本主要以文字的形式表示信息,建立的链接关系主要是文句之间的链接关系,而超媒体除了使用文本外,还使用图形、图像、声音、动画或影视片段等多种媒体来表示信息,建立的链接关系是文本、图形、图像、声音、动画和影视片段等媒体之间的关系。
用超媒体方式组织数字信息,可以将网上所能获得的各种多媒体资源采用超媒体技术将其有机地以网状结构编织在一起,以便用户从任意节点出发,从不同角度查找信息。其联想式的信息组织方式,不仅符合人们思维联想和跳跃的习惯,而且还能避免检索语言的复杂性;同时,图、文、声、像并茂的信息服务功能,能方便地描述和建立各种媒体信息之间的语义关系,超越媒体类型对信息组织与检索的限制。但是,由于采用浏览的方式进行信息搜索,当超媒体网络过于庞大时,这种方式使信息资源的有序化整理和组织存在较大的难度,用户很难迅速而准确地定位,且很难保存浏览过程中的所有记录,难以避免“迷航”现象。
4.3.3 搜索引擎方式
搜索引擎(Search Engines)是一种利用网络自动搜索技术,对因特网各种资源进行标引,并为检索者提供检索的工具,也是目前网上二次信息组织最常用的一种方式。现代意义上的搜索引擎其实是在近十几年的不断发展中逐步形成的。1994年7月,当时Michael Mauldin将John Leavitt的蜘蛛程序接入到其索引程序中,创建了大家现在熟知的Lycos。同年4月,斯坦福(Stanford)大学的两名博士生,David Filo和美籍华人杨致远(Gerry Yang)共同创办了超级目录索引Yahoo,并成功地使搜索引擎的概念深入人心。从此搜索引擎进入了高速发展时期。目前,互联网上有名有姓的搜索引擎已达数百家,其检索的信息量也与从前不可同日而语。
按搜索的内容划分,搜索引擎大致可以分为两大类:全文搜索引擎(Full Text Search Engine)和分类目录(Directory)。全文搜索引擎通过一个叫网络机器人(Spider)或叫网络蜘蛛(Crawlers)的软件,自动分析网络上的各种链接并获取网页信息内容,按规则加以分析整理,记入数据库。Google、百度就是比较典型的全文搜索引擎系统。分类目录则是通过人工的方式收集整理网站资料形成数据库的,比如雅虎中国以及国内的搜狐、新浪、网易分类目录等。
搜索引擎方式并不真正搜索互联网,它搜索的实际上是预先整理好的网页索引数据库。被称为“网络机器人”或“网络蜘蛛”的实际上都是一种自动跟踪、浏览网页并进行标引的智能软件,这类软件一般由采集系统、建库系统、索引查询系统、备份复制系统、目标缓存系统和目标管理系统组成。相应地搜索引擎方式的工作原理可概括为以下过程:
(1)信息的采集和存储
搜索引擎方式一般根据TCP/IP网络协议,采用自动方式搜集和存储信息,即运用“网络机器人”在网上漫游,发现Web页就将它们调出,对有用的信息进行排序、归并后建立可访问的网络数据库。
(2)信息索引的建立
信息采集和存储后,要建立索引查询系统,实际上就是创建文档信息的特征记录。有了按一定方式、结构建立的索引查询系统,用户就能够快速地检索到所需信息。一般而言,建立索引需要处理好如下事宜:
●信息语词切分和语词词法分析
●进行词性标注及相关的自然语言处理
●建立检索项索引
(3)检索界面的建立
搜索引擎的检索界面是用户提交查询请求的Web页面,一般列有简单搜索界面和高级搜索界面。搜索引擎根据用户所输入的关键词在其中查找,并寻找相应的Web页地址。
(4)检索结果的相关处理
通常情况下,搜索引擎要对庞大的检索结果进行相关处理,当然,每个搜索引擎评判结果相关性的方法均有不同。一般而言,搜索引擎确定相关性的方法有概率方法、位置方法、摘要方法、分类或聚类方法等。
尽管搜索引擎方法被广泛应用于网络信息的组织,但是,当前的搜索引擎只是将信息的采集、检索界面以Web方式提供给了用户,而并没有将信息搜索、个性化的信息提供技术“引擎”化。因而,用户查到的信息内容过于庞杂,需要的与不需要的信息都堆积在一起,其甄别的工作量很大,检准率较低。
在搜索引擎方式中,还有一种多元搜索引擎(Meta-search Engine),它是将多个搜索引擎集成在一起,并提供一个统一的检索界面。又被称为集合式搜索引擎或元搜索引擎。这种搜索引擎不同于传统的独立的搜索引擎,其本身没有搜索引擎的网页搜寻机制,也没有自己独立的索引数据库,而是定制统一的检索界面,通过调用其他搜索引擎的检索功能来实现网络资源的查询。由于它借用了多个独立搜索引擎,其信息的覆盖面更为广泛;此外,多元搜索引擎还对返回的结果进行了适当的整理,从而避免了用单一搜索引擎进行重复查询而造成时间和信息的浪费,提高了网上检索效率;用户只须一次输入提问词就可以同时对多个独立搜索引擎进行检索。这种搜索引擎方式适合于对三次数字信息资源的组织与管理。
4.3.4 主题树方式
主题树方式是将信息资源按照某种事先确定的概念体系结构,分门别类地逐层加以组织,用户通过浏览的方式逐层加以选择,层层遍历,直至找到所需要的信息线索,并通过信息线索直接找到相应的网络信息资源。
在因特网上,主题树方式一般采用人工方式采集和存储信息,即由网络研究人员对网站进行调查收集、分类、存储和组织,由专业人员手工编制关键字索引,然后建立索引数据库。其建库和检索界面的建立过程类似于搜索引擎,但检索质量优于搜索引擎。因为,采用主题树方式,网页由专家人工精选,内容丰富,学术性强;由于将“主题和专题”作为聚类的主要标准,而把学科和专业作为辅助的聚类标准,符合网络用户的检索习惯,其分类浏览方式较为直观易用;等级式的主题目录,有助于用户按模糊的主题概念,在浏览查询中分步骤地组织自己的问题,通过分析和匹配获取所需信息,其检准率较高。但是,利用主题树方式必须事先建立一套完整的主题目录分类体系,而用户必须对这种分类体系有一定的认识,从某种意义上说,增加了用户负担;此外,为保证主题树的清晰性和资源的可用性,主题目录体系结构又不宜过于复杂,每一类目下的信息索引条目也不宜过多,这就与体系的完整性产生了冲突。
目前,主题树方式广泛应用于专业性或示范性的网络数字信息资源组织,一些著名的网络检索工具,如Yahoo!、Gopher等都采用主题目录方式组织网上的数字信息资源。
4.3.5 数据库方式
数据库方式是将所有已获得的数字信息资源以固定的记录格式存储,用户通过关键词及其组配查询,就可以找到所需要的信息线索(即相关站点链接),并通过信息线索直接连接到相应的数字信息资源。
数据库方式是一种比较成熟的数字信息资源组织形式。像联机数据库是网上重要的学术信息资源,其信息组织方式与一般大众性的网络信息的组织方式不一样(18)。
①联机数据库中的信息资源大多数是数字化的文献信息,其组织与检索有较强的理论和实践基础,一般而言,这种数字化的文献信息检索系统的组织与检索方式,与传统的信息组织理论、方法的联系较为紧密,受控程度较高,如有些数据库除编有关键词表外,还利用专业禁用词表规范关键词的用法;
②有专门机构或开发商组织开发,并配有专业信息加工、组织人员,其信息组织更规范,描述更准确,如由美国ProQuest Information Learning公司开发的《商业信息全文数据库》、清华大学等单位支持并开发的CNKI(中国知识基础设施工程)的一系列联机数据库及镜像站点等;
③信息内容学科性、专业性强,如由英国电机工程师学会(IEE)编辑的INSPEC(Information Service in Physics,Electronics Technology and Computer and Control)是物理学、电子工程、电子学、计算机科学及信息技术领域的权威性文摘索引数据库,类似这种类型的数据库较适宜用受控型检索语言来进行组织;
④一般提供有多种检索途径,检索功能相对完善,检索效率高,如美国ProQuest Information and Learning公司的学术期刊图书馆(Proquest Research Library)数据库,除基本检索和高级检索外,还提供主题指南和出版物检索等功能,另外还有检索技巧和主题浏览等工具。
一般说来,大多数数据库基本上都使用的是全文关键字词检索技术,为了提高检索效率,开发多种辅助的检索功能是非常必要的。实践证明,在联机全文数据库方式中,使用包括基本关键词检索、高级关键词检索、数据库限定、主题指南、历史检索等在内的全文关键字词检索技术,其检索效率大大优于搜索引擎方式。但是,由于数据库方式处理的对象通常是结构型的、以数值形式为主的数值类型信息,对非结构化信息的组织与处理难度较大,此外,数据库方式对信息处理的规范化程度高,对用户的检索技巧有一定的要求,缺乏人机交互性的灵活易用的检索界面(19)。
4.3.6 学科信息门户方式
学科信息门户(Subject Information Gateway,简称SIG),是将特定学科领域的信息资源、工具和服务集成为一个整体,为用户提供一个方便的信息检索和服务入口。它是提供经过图书情报机构工作人员对信息选择和筛选后,按学科组织的、可检索和可浏览的因特网资源和资源目录的联机服务系统,其最具特色的部分是详细的元数据(或目录)记录数据库,这些记录对网上资源进行描述并提供指向资源的链接,指引用户获取所需信息。从所具有的功能来看,可以将学科信息门户视为对网络指南、资源导航、指示数据库的进一步发展。
学科信息门户的研究与开发始于20世纪90年代中期。近年来,伴随互联网信息技术和标准的发展,发端于图书馆领域的学科信息门户建设得以不断成熟与完善,已经成为数字信息资源组织的一种重要方式。这种组织方式的特点在于:
(1)学科性
针对特定学科或主题领域,按照一定的资源选择和评价标准,根据用户的信息需求,对具有一定学术价值的网络资源进行搜集、选择、描述和组织。国内外一些著名的学科信息门户,如美国加州大学的图书馆员因特网索引(Librarians'Index to the Internet,LII)、德国哥丁根Lower Saxony State and University Library开发的Geo-Guide、英国诺丁汉大学等开发的BIOME(生命与健康)以及中国科学院国家数字图书馆的环境资源科学信息门户等都具有很强的针对性。
(2)集成性
学科信息门户将专业领域各种有价值的网络信息资源集中到一个知识体系中,既收录机构网站、数据库等,还收录一些特有的网络信息资源类型,如学术论坛、新闻组、邮件列表等。
(3)规范化
学科信息门户建设有严格明确的规范。如规定信息资源收录范围、选择标准以及选择步骤;规定信息资源组织体系标准和信息资源描述标准。标准化是实现不同系统间网络信息资源交流的基础,实现数字信息资源整合的关键在于要遵循标准化的规范体系。如果没有统一的数字信息资源建设标准和相应的规范,就不可能实现各分布式资源之间的互操作和信息的共享(20)。
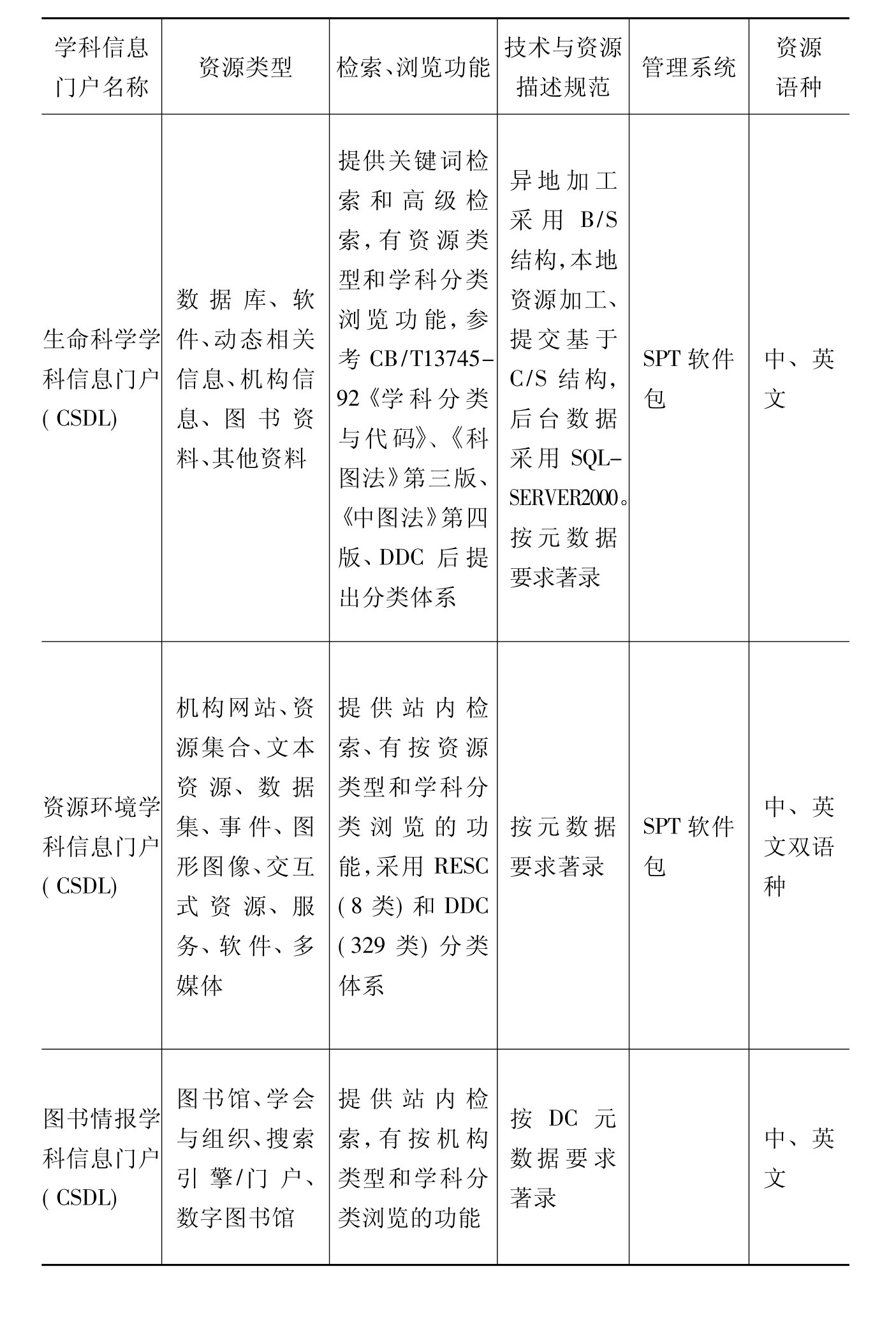
就目前国内外建立的学科信息门户来看,大致可分为两大类:综合类(多科类)和单科类,但单一学科信息门户的比例略强(国内目前仍以单一学科信息门户为主)。无论哪种类型的学科信息门户,都是围绕特定学科或主题,对具有一定学术价值的信息资源进行搜集、选择、描述和组织,大多运用了多种技术手段揭示和表达信息概念之间的关系,利用关联列表揭示学科信息体系。如美国教育资源的GEM(The Gateway to Education Materials)将控词表转换成了教育学科ontology(EduOnto)来组织门户信息资源,建立了从传统受控词表到门户ontology的知识结构参考链接。提供有学科门类、资源类型、资源级别、关键词等多种浏览途径,并在各浏览体系的每条资源下设置相关链接,以便于扩检。英国社会科学信息门户(SOSIG)、德国环境信息网(GEIN)和由中国科学院承建的中国国家学科信息门户(CSDL)都是应用了标准或自建的学科分类体系来组织信息资源的。表4-1反映了国内学科信息门户方式的基本概况。
表4-1 中国五大学科信息门户基本概况(21)(22)
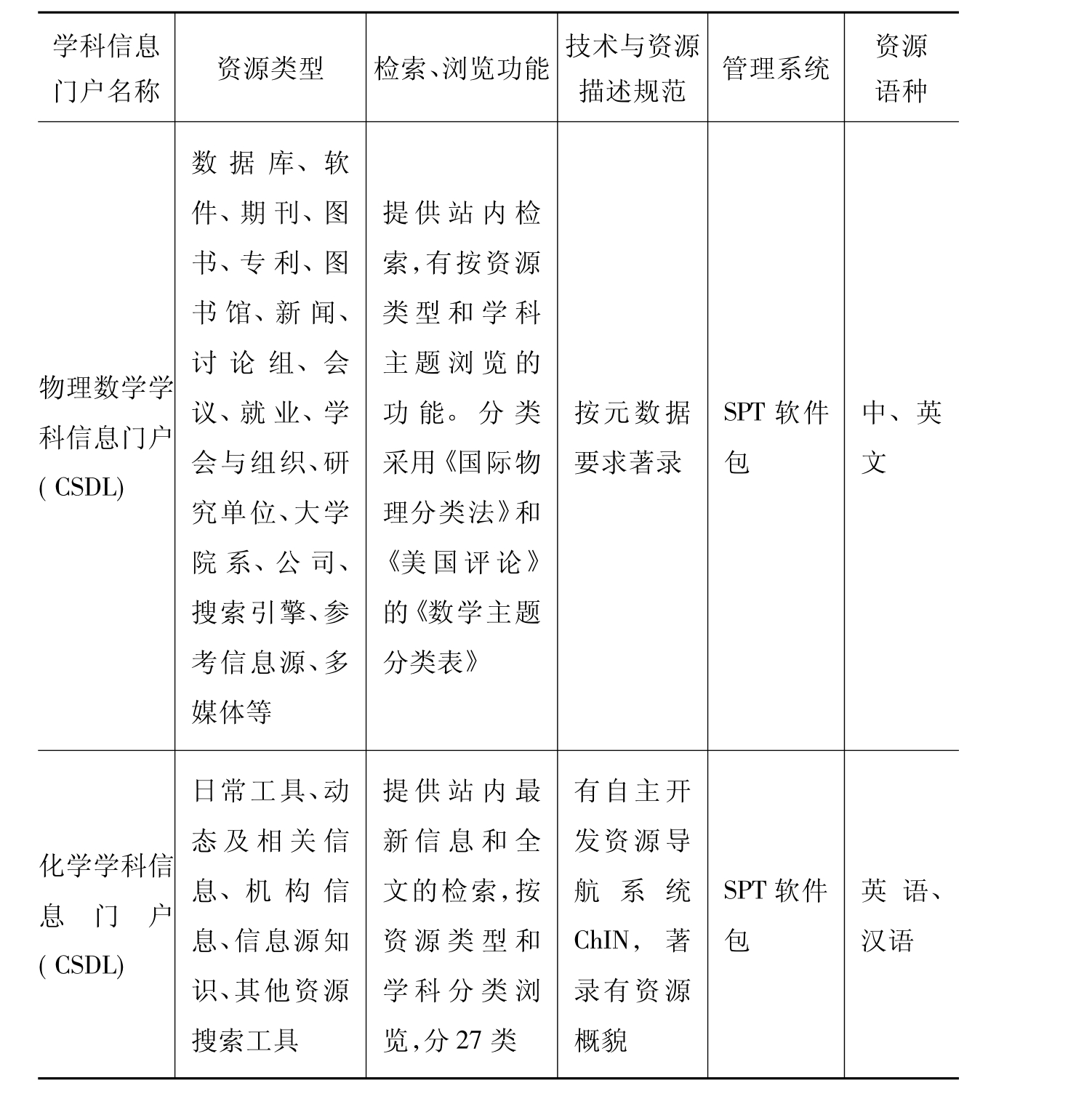
续表
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











