



4.2 数字信息资源组织的标准
标准化是信息资源数字化和共建共享的前提和必要保障。国际上从事信息与文献标准化工作的组织众多,非常活跃,它们通过领域分工和实质性合作与交流等方式,制定和维护包括信息与文献领域基础、业务、管理各阶段的系列标准,为规范和促进信息与文献可持续发展做出了巨大的贡献。数字信息是一种以数字代码方式将图、文、声、像等信息存储在磁、光等介质上的信息,数字信息资源组织体系的建立,需要遵循有关信息加工、描述等方面的标准。数字信息资源组织的标准主要包括:数据格式标准和信息资源描述标准。数据格式是对数字化信息的基本结构描述,它可以实现不同计算机系统间交换数据;信息资源描述的标准化可以实现用户和系统以及系统与系统之间的有效沟通。
4.2.1 数据标记格式标准
数据标记格式标准是指对不同类型的数字文件的格式进行限定,便于不同计算机系统间交换数据的标准。包括页面著录标准(如PDF)、图形格式标准(如TIFF,GIF)、结构信息标准(如SGML)、移动图像与音频格式等。其中超文本标记语言(HTML)、通用标记语言(SGML)与可扩展标记语言(XML)是用于数字信息资源组织方面的结构信息数据格式标准的典型,它们是人工可读格式文献与数据库信息的超文本提供的标记语言。
(1)标准通用标记语言
标准通用标记语言(Standard Generic Markup Language,缩写SGML)是一种元语言,即一种描述标记语言的语言,是由国际标准化组织提出的一种适合书目、文献全文、电子文献及多媒体信息描述的标准(ISO8879-1986)。和MARC编码语言家族不同,SGML并不包含一套预先定义的标记来标记文献,也没有为制作某种特定类型的文件提供标准模版,而是利用通用方式和元标识语言对文献内容和结构进行标记,实现对各类文献结构和内容的系统化、标准化描述,从而建立起通用数字信息。
SGML以实体(事物、对象)、元素、属性(性质)的形式定义数据。实体是被编码的一个事物、一个对象;元素是文本中某一特定部分,如题名、章节题名、出版者的名称、分类号等;属性则是关于某个要素的特定信息(如某个主题词的同义词)。实体、元素、属性之间的关系也可以使用SGML进行描述。在实际使用中,SGML的每一个特定的文档类型定义DTD(Document Type Definition)都定义了一类文件。DTD是一套关于标记符的语法规则。它告诉人们可以在文档中使用哪些标记符,它们应该按什么次序出现,哪些标记符可以出现于其他标记符中,哪些标记符有什么属性,等等。
SGML规定的标记包括分隔符和标识符。分隔符是那些已经定义的符号(如<、>、</),用于构建标识符(<author>就是一个标识符)。标识符一般可出现在元素之前和元素之后,可以实现层层嵌套。下面的例子是从TEI中抽取出来的,包含了标识符的几层嵌套:fileDesc><titleStmt><PublicationStmt>…</titleStmt></publicationStmt></fileDesc>(5)。
SGML作为通用的描述各种电子文件的结构及内容国际标准,可以支持无数的文档结构类型,如报告、技术手册、章节目录、设计规范、信函和备忘录等;可以创建与特定硬件无关的文档,因此很容易与使用不同计算机系统的用户交换文档。基于SGML,我国开发的数字式中文全文文献通用格式,可应用于对普通图书、科技报告、学位论文、古籍、拓片、地图资料、乐谱、录音资料、影像资料、连续出版物、缩微资料、计算机文档等进行标引。其特点可与先进的国际标准接轨,实现文献编码、目录和文献内容的一体化处理(6)。
(2)超文本标记语言
超文本标记语言(HyperText Markup Language,缩写HTML)是万维网上最流行的标记语言。HTML是SGML(Standard Generic Markup Language)的一种应用,其目的是建立超文本、超媒体文档。它是用于信息表示的标记语言,使其能够在浏览器上呈现给访问它的用户。HTML是对ASCⅡ文件的一种增强版本,能在文件中加入标签,使其可以显示各种各样的字体、图形,还增加了结构的标记,如头元素、列表和段落等,并且提供了Internet上其他文档的格式。HTML的简洁性和Web规范使得人们能迅速创建基于Web的系统和工具,当前Web语言还是以HTML为主,因为HTML拥有很多优点,可以作为开发其他标记语言的基础。虽然HTML是成功的,但它只是一种标记技术,并不揭示信息的本质,也存在诸多缺陷:①有限的、预定义的标记集合,使得用户不能定义自己的标记,例如,<h1></h1>、<h2></h2>、<table></table>、<tr></tr>、<td></td>等标记都是事先定义好的,用户无法改变,也无法自行增删;②HTML文档为显示而设计,缺乏针对内容的描述;③结构不规范,其高度的容错性虽然能给编码人员以灵活性,但也使得HTML代码太过随意,给分析文档结构这样的工作带来了极大的麻烦(7)。现在W3C(万维网联盟)使用XML语法重写了HTML,这导致XHTML的诞生,它继承了HTML的许多优点,其标记与HTML标记是等同的,但语法更加严格。XHTML的特色体现在模块化上,如果需要简化标记则可忽略其中某些模块。
(3)可扩展标记语言
可扩展标记语言(eXtensible Markup Language,缩写XML)是W3C组织于1998年2月发布的标准。XML是SGML的一个分支,是SGML的一个应用文档或限制格式。随着网络技术的发展,人们感到HTML过于简单,应用起来很难达到满意的效果。一段时间以来,人们一直在探索一种全力支持SGML的方法,但是SGML又异常复杂,用SGML进行程序编制变得非常复杂和冗长。早期的HTML语言,仅仅用以表示数据显示的布局,它所表达的页面信息和组织方式,主要面向用户直接阅读,没有将信息的表现形式、内容结构和表达内容相分离,因而非常不利于计算机直接阅读和处理。为了弥补HTML的不足,人们又开发了很多的插件,但是这些插件需要使用者下载并安装。开发XML是解决上述问题的一种方法。由于XML将SGML的丰富功能与HTML的易用性结合在一起,应用于数字信息组织,因此自推出以来,迅速得到软件开发商的支持和程序开发人员的喜爱,显示出强大的生命力。
在网络环境下,XML的主要用途有两个:一是作为元标记语言,定义各种实例标记语言标准;二是作为标准交换语言,担负起描述交换数据的作用。(8)正因为如此,XML的开发者把XML作为一种像HTML语言那样,在网上用起来非常简单而又不失SGML的强大功能语言来极力推广。而且,由于XML开发出来的时间比SGML晚很多,有条件吸纳多种技术来处理多媒体文件,较好地解决了HTML无法表达数据内容的问题,使它在政府、金融、证券、邮电、保险、税务、司法、出版以及电子商务等方面得到广泛的应用。作为一种标记语言,XML具有很多特点。
①简洁、开放。XML是简单的。它由若干规则组成,这些规则可用于创建标记语言,并能用一种被称作分析程序的简明程序处理所有新创建的标引语言。XML是开放的。市场上有许多成熟的软件可用来帮助编写、管理XML,有很多业界公司与W3C的工作组合作,协助确保交互操作性,支持各种系统和浏览器上的开放人员、作者和使用者开展工作,并在工作实践中不断改进XML标准。
②结构良好。XML文档由3个部分组成:文件头(Prolog)(该部分是可选的,不是必须的)、正文部分(Body)和结尾部分(Epilog)(该部分也是可选的)。
③可扩展,用户可以根据需要定义自己的标记。XML支持复用文档片段,用户可以创建和使用自己的标记,也可以与他人共享,具有很大的扩充性。随着世界范围内众多机构逐渐采用XML标准,将会有更多的相关功能出现。
④支持以全球统一的标准来定义自己的标记。XML是一个国际化的标准,且支持世界上的大多数文字。与HTML相比,XML具有很明显的国际性优势,它不仅能在不同的计算机系统之间交换信息,而且能够跨越国界和不同文化疆界交换信息,因此成为通用的网际语言。而在HTML中,一个文档一般是用一种特殊语言编成,如果用户的软件不能阅读特殊语言的字符,那么该用户就不能使用该文档。
⑤具有创建标记的能力。在XML中可以自定义一定语义的标记。这样做的好处是,XML的标记携带语义信息,能够明确地提示所标注的内容,从而实现更加精确的搜索,使得智能代理的实现切实可行,有利于数据库数据的相互转化。
⑥数据内容与数据显示相分离。XML文档只描述相关的数据,而把数据的显示描述在其他文档中。这样做可以使XML文档的编写者集中精力于数据本身,而不受显示方式的细枝末节的影响。此外,它还带来另一好处就是,不同的样式表可以使用相同的数据呈现不同的显示外观,从而适合不同应用,可以在不同显示设备上显示。
由于XML具有良好的可伸缩性和灵活性,不仅提供对信息资源内容的表示,同时也提供信息资源所具有的结构信息,适合于表示各种信息,所以被广泛接受。
4.2.2 信息资源描述标准
资源的规范化描述是通过元数据规范和著录规范控制的。即在数据库中以字段的方式对数字信息资源的各种属性进行描述,如题名、作者、URL等。这些描述信息是读者评判某一数字信息资源的依据、访问所选择站点的入口,也是导航系统检索的基石。元数据是对数据进行组织和处理的基础,是用来描述数字化信息资源并确保这些数字化信息资源能够被计算机自动辨析、分解、提取和分析归纳的一种框架或一套编码体系。在信息资源组织中,就元数据的功能而言,它具有定位、描述、搜索、评估和选择等功能,而其最基本的功能在于为信息对象提供描述信息。
所有信息资源的属性都可以使用特定团体或相关元数据方案的规则进行描述。为了规范对信息资源的描述,国际上从事信息与文献工作的标准化组织和相关机构曾制定过多种标准、规则,包括书目及通用元数据方案(如ISBD、AACR2R、DC)和专业领域元数据方案(如ISAD(G)、EAD、FGDC)。在图书馆界,ISBD、AACR2R、DC影响较大。
(1)ISBD(《国际标准书目著录》)
ISBD是IFLA组织为了促进国际书目信息交流,实现文献信息资源共享,于20世纪70年代初设计的。它规定了描述所用的元素、元素的排列顺序及标记元素的符号系统。一经发布,就得到世界各国的赞同和应用。由于被描述的信息资源的类型不同,IFLA又相继发布了分则,形成了ISBD系列标准。在ISBD系列标准中,ISBD(G)为国际标准书目著录总则,是制定各种分则的框架,对各分则起控制作用,而各分则则是总则编制原则具体化的产物,它们是设计独立的ISBD,能系统地解决具体类型信息资源的描述。虽然,各分则的设计是独立的,但它们与总则以及各分则之间都相互联系、相互参见,构成了一个有机的整体。
到目前为止,IFLA颁布的ISBD系列标准有ISBD(M)专著图书、ISBD(S)连续出版物、ISBD(NBM)非书资料、ISBD(CN)测绘制图资料、ISBD(PM)乐谱、ISBD(A)古籍、ISBD(CF)计算机文档、ISBD(ER)电子资源以及ISBD(CR)连续出版物与其他连续资源。
ISBD要求通过描述可以将各种信息资源的全部特征都进行标记,而独立于任何检索点。ISBD(G)包含8个著录项目,其中的6项又分为若干元素:
著录项目1——题名与责任说明项
著录项目2——版本项
著录项目3——资料(出版类型)特殊细节项
著录项目4——出版发行项
著录项目5——载体形态项
著录项目6——丛编项
著录项目7——附注项
著录项目8——标准号及获取方式项
在利用ISBD描述信息资源制作替代记录时,应该按照ISBD规定的著录项目、著录项目的顺序以及著录表示符使用,因为,ISBD符号是预先设定好的,它规定并预示着紧跟其后的数据要素;数据的顺序也是事先规定好的。
ISBD的颁布实施具有重大意义和深远影响,它为统一世界各国文献信息条例,实现信息资源著录标准化奠定了坚实的基础。作为国际标准,ISBD对于不同地区、不同语言、不同规模、不同类型的文献机构都具有通用性。目前,亚、非、欧美的一些国家都采用了这个条例,而且,许多国家还以此作为制定或修改各类编目条例的重要依据(9)。
(2)AACR2(《英美编目条例》第2版,2002年修订版)
自《英美编目条例(第2版)》(AACR2)1978年出版以来,AACR2一直是国际编目界的重要规则,许多国家的编目规则都在很大程度上参考了AACR2。20多年来,该规则经历过若干次修订(1988年,1998年,2002年),使其不断得以完善。在西方,AACR2被誉为“21世纪的编目条例”,其影响不仅在英语国家,就是非英语国家(含非罗马语言文字国家)也不例外。
2002年,AACR2再次被修订出版,主要是为了解决编目工作中出现的新问题。针对新的信息环境和信息需求,AACR2-2002选择重点内容进行修订,主要修订了测绘资料、电子资源、连续出版物和组合资源的著录规则,其描述部分是基于ISBD的。
电子资源的修订是AACR2的重要举措之一。自1978年以来,AACR2已经作过许多修订和增删,但内容变化最大的还是近几次的修订,这主要与电子资源的飞速发展有关。20世纪90年代中期开始涌现的电子资源与网络资源,由于没有被纳入到它过去的版本中,因而许多图书馆只好采取一些变通的办法来编目。如对期刊的电子版用单记录著录,对于网站不作任何记录或用流行的元数据来处理等。为改变这种状况,AACR2-2002对第3章作了全面的修改,增加了“电子测绘资源”的著录规则,使它能更好地容纳测绘资料的特征及其著录规则;对第9章的名称由原来的“Computer File”(计算机文档)更名为“Electronic Resource”(电子资源),使这一章的名称更能确切的表达其所涵盖的内容,并且对电子资源的概念、范围、存在的方式及著录的主要信息源等都做了更明确的说明;规定主要信息源是整个电子资源本身,包括:题名屏、主菜单、程序说明、初始显示信息、主页、文件标题、元数据、载体或标签。其中“主页”、“编码元数据”是新增加的,载体或标签原来只能作为辅助或替代信息源,现在也成为主要信息源;对各著录项目的著录要求作了详细的规定。此外,2002年修订本还对舆图资料、连续资源两章做了全面修订。AACR2的每一次修订都尽可能与有关的国际标准,特别是与ISBD、使用AACR的团体所用的标准,以及与世界书目控制的原则保持一致,2002年的修订更是如此。
AACR2-2002对各项规则都编了号,以便ISBD各项目的编号与各章节的编号相对应,例如:
规则5.1——题名和责任者项
规则5.2——版本项
规则5.3——资料特殊细节项
规则5.4——出版发行项
上述例子是AACR2-2002第5章的ISBD项目的规则。由此可以看出,这样做不仅能有效指导编目实践,而且还能促进各国各地区编目规则的统一。
AACR2-2002出版以来,业界人士十分关注。张秀兰认为,AACR2-2002对电子资源的修订迎合了时代的要求,有利于各国信息机构能够在统一规则下,有效、规范地整理和组织电子资源,并认为修订以后的AACR2使用面更广,实用性更强(10)。孙更新等认为,AACR2-2002继承了前期各版的精华,融合了1999年、2001年修订本的内容,增加了2002年批准确定的新条款。修订的重点突出,在编目理论上也有新的开拓,并归纳4个主要特点:①关注编目标准的国际化,特别注意与ISBD、ISSN,以及国际标准化组织(ISO)的标准保持一致;②在组织结构和组织方法上对条例进行了改革,使之与现行的标目程序接轨;③更新了“主要款目标目”的内容,如新界定了“著者”的概念、对责任者统一标目的规定更具通俗性、扩大了统一题名的范围等;④根据不同类型机构对编目的不同要求,增强了条例使用的灵活性,尤其是规定的三个著录级次,可以满足不同编目机构的要求(11)。
(3)DC(都柏林核心)
都柏林核心(Dublin Core,DC)是都柏林核心元素集(DublinMetadata Core Element Set)的简称,因为第一次研讨会在俄亥俄州的小镇都柏林召开而得名。1995年3月,OCLC与国家超级计算机应用中心(National Center for Supercomputing Applications,NCSA)在俄亥俄州的都柏林(Dublin)召开了一次国际研讨会,与会代表一致认为有必要定义一个简单的用于描述网上电子文件特征、提高信息检索效果的方法,随即启动了都柏林核心元数据的研究项目,并最终在这一次研讨会上产生了一个包含13个元素的元数据集,即Dublin Core(DC)Set。DC的简练、易于理解、可扩展及能与其他元数据形式兼容等特性,使它成为了一个良好的网络信息资源描述元数据集。后来,经过会议的研讨、扩充和修改,最终形成了一个包含15个元素的元数据集。由于参与DC发展研讨会的成员都是各个领域的专家(如出版者、计算机专家、图书馆员、软件制作者、文本标识专家等),故它是一个跨行业标准,是各个领域各种类型资源元数据制作的基础。
当前的DC元数据集包括15个核心元素,被分为3组:
①描述资源内容相关的元素
a.题名(Title):资源的名称
b.主题(Subject):资源内容的主题词,建议从受控词表或规范的分类表中取值
c.描述(Description):资源内容的描述或资源文本的说明
d.来源(Source):对象的来源
e.语种(Language):资源知识内容的语种标识
f.关联(Relation):相关资源与现有资源之间的关系
g.覆盖范围(Coverage):对象的空间位置和时间的持续性特征
②描述知识产权的元素
a.创作者(Creator):资源内容的责任者
b.出版者(Publisher):能获取对象的责任代理
c.其他责任者(Contributor):主要负责对象文字内容的人
d.权限(Rights):资源权限管理的声明
③资源外部属性相关的元素
a.日期(Date):发布日期
b.资源类型(Type):对象的类型,如小说、诗歌或者日记
c.格式(Format):对象的数据格式,如后记文件
d.标识符(Identifier):唯一标识对象的字符串或数字
DC产生之初,曾确立了四个原则:①核心集可以根据特定团体的需要补充更多的元素;②所有元素都是可选的;③所有元素都是可以重复的;④任何元素都可以利用一个修饰词或多个修饰词进行限制。(12)其中,既可以选择,又可以重复的原则,使核心元素成为可被用于简单或复杂的元数据描述,以创建任何搜索引擎和数据库结构可用的元数据。它提供了跨学科和格式的语义互操作性,与其他元数据兼容,可作为结构化元数据进行编码和转换的模块化基础结构,是可被任何单位用于描述和标引电子资源的有利工具。
DC的独特优越性,使它俨然已成为一个国际范围内通用的适用于网络资源组织系统的元数据标准。美国国家信息标准组织已接收其为国家标准Z39.85-2001,并申请成为国际标准。目前,DC已在世界范围内广泛使用,人们利用基本的DC作为起点为专业开发了很多的应用框架。如北美的数字图书馆目录、佛罗里达国际大学数字图书馆、华盛顿大学数字图书馆、蒙蒂塞洛电子图书馆等项目均使用了元数据格式,这就充分表明元数据格式能够适应数字化信息资源的描述。
(4)RDF(资源描述框架)
资源描述框架(Resource Description Framework,RDF)是W3C组织于1999年颁布的。它是一种元数据框架,这种元数据框架可以推进互操作的实现。它提供的一个基础结构,使得编码互换、元数据的再利用都采用比较明确的方式,从而使机器理解元数据的语义,灵活方便地自动处理网络资源。
RDF定义了一个简单的数据模型,通过性质(Property)和值(Value)来描述资源以及资源与资源之间的关系。在RDF(资源描述框架)模型中,资源可以具有某种性质,性质则具有某种值。这个“值”可以是一个字符串,也可以是一个数字或另一资源。资源性质的集合被称为描述,图4-1是一个RDF描述的数据模型图。
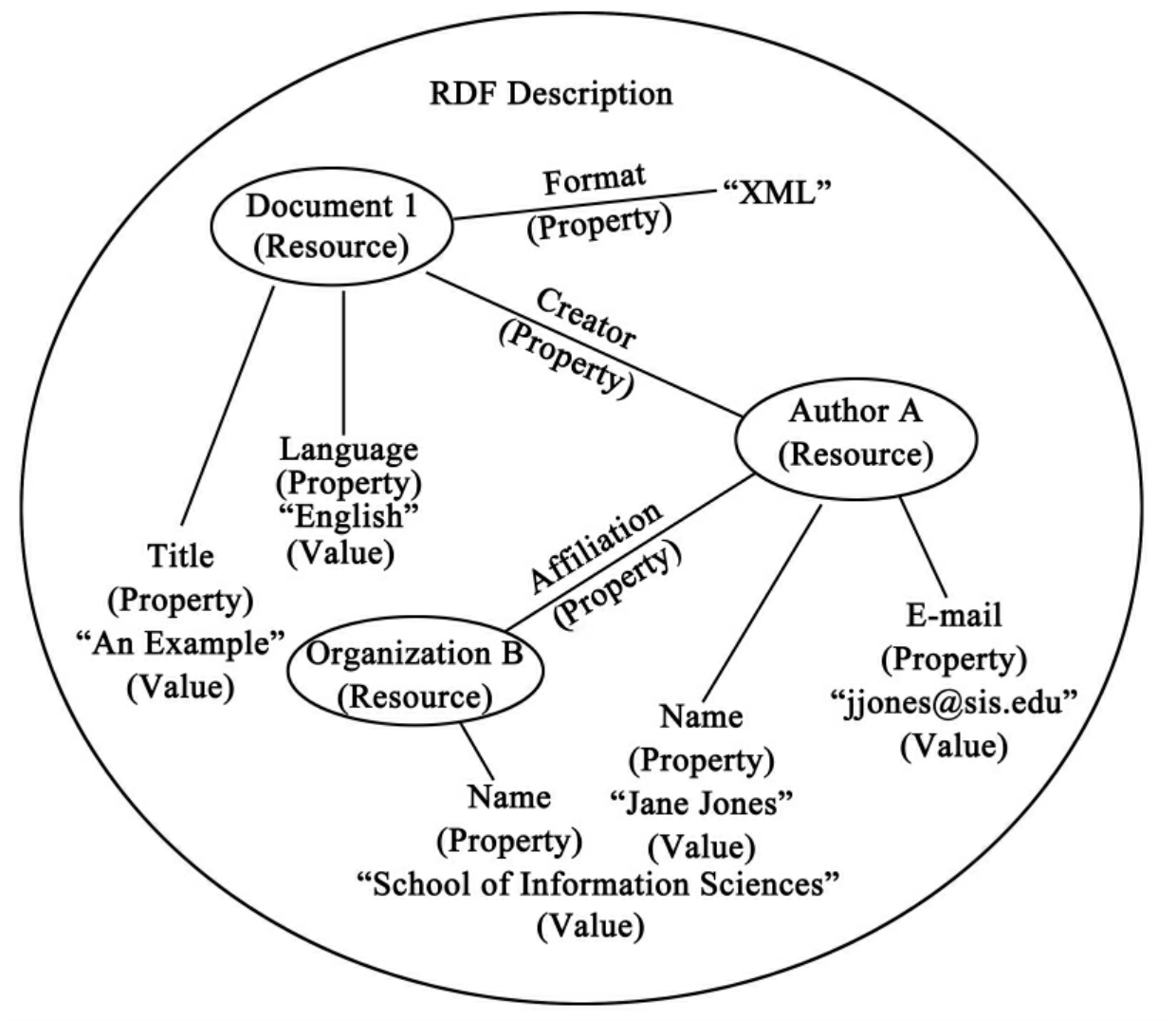
图4-1 RDF描述的数据模型(13)
图4-1中,“Document(文件)1”被称为一个资源,Format(格式)、Creator(创建者)以及Language(语种)是其性质。每一种性质有一个值,如创建者(Creator)的性质值是叫做“Author(作者)”的另一资源,这一资源又具有机构(Affiliation)、名称(Name)、E-mail等三个性质。这样,可以一层一层继续下去,通过资源的性质值又可以再链向另外一个资源。
如前所述,RDF模型通过给定的性质和性质的值来描述资源之间的联系。RDF定义了由资源(Resource)、性质(Property)和语句(Statement)3种对象组成的基本模型,通过这个抽象的数据模型为定义和使用元数据建立了一个框架,元数据可以看成其描述的资源的性质。不过,这个模型如果被用于交换元数据则一定要明确说明。W3C已经指出,RDF是以XML为语法基础。利用XML,在RDF描述语句中可以应用已定义的RDF模式,从而达到复用的目的,减少了创建新元数据模式的工作量。
下面列举的是一个简单的XML编码的RDF语句:
<?xml version﹦″1.0″?>
<rdf:RDF
xmlns:rdf﹦〃http//www.w3.org/1999/02/22-rdf-syntax-ns#″
xmlns:dc=″hppt://pur.org/dc/elements/1.0″>
<rdf:Description rdf:about=〃http//www.dra.com/SR/ rdfarticle.html〃>
<dc:Creator>Mark Needleman</dc:Creator>
<dc:tile>RDF:Resource Description Framework</dc:tile>
<dc:publisher>Serials Review</dc:publisher>
<dc:format>text/html</dc:format>
<dc:language>en</dc:language>
</rdf:Description>
</rdf:RDF>
(注:该例系使用都柏林核心集(DC)和XML的RDF语句的例子)
上例中,前两行说明正是使用RDF作为描述语句集的XML。下面两行表明标识来源是RDF和都柏林核心集的命名域,并提供了这两个命名域的可访地址,剩下的是对资源的具体描述,最后是必需的终止表示符。这种语法形式简洁,其优点在于,它允许那些遵循高度结构化的XML文档类型定义(XML、DTD)文档可以直接被解释成RDF模型。
4.2.3 中文信息资源描述标准的研究与应用
信息资源描述标准是一种文献著录规则,也是一种文化成果,它总是伴随着继承与发展,国际化与民族化等问题讨论、编制。ISBD、AACR2等都是文献信息领域开发出来的、得到世界普遍接受的标准和条例。尤其是ISBD,它成功地解决了各国的文献著录项目及其排列顺序,实现了文献著录的国际统一;它克服了语言障碍,使不认识某种文字的用户,也能通过标识符号系统,识别描述项目;它有助于将一般书目转换为机读目录形式。但是,由于存在文化和语言的差异,不可能强求一律。对于中文文献而言,如何在遵循国际规则的基础上,继承和发展本民族的传统,制定出既能与国际规则接轨,又能适应中文文献特点的文献著录标准,是我国文献信息工作者长期探索的课题。直到20世纪70年代末,国内才开始对规范控制进行研究,几十年来,我国共颁布信息与文献的国家标准45项,其中采用ISO国际标准29项,采用IFLA(国际图联)国际标准6项。为了建立和健全我国统一的文献报道体系,开展国际书目信息交流,共享信息资源,仅国家标准局就先后批准了20多项有关文献信息著录的标准,如GB3792.1-83文献著录总则,GB3792.2-85普通图书著录规则,GB3792.3-85连续出版物著录规则,GB3792.4-85非书资料著录规则等。
此外,国家图书馆作为国家文献编目中心,在政府部门的资助下,对文献信息的规范进行了卓有成效的研究,依据IFLA的GARE和《UNIMARC/规范格式》,于1990年主持制定了《规范数据款目著录规则(草案)》和相应的《中国机读规范格式(试用本)》;1995年制定了《中文图书规范数据款目著录规则》,并推出《中国机读规范格式(试用本)》的修订本;1997年出版了《中国机读规范格式使用手册》与《中文图书主题规范款目著录规则》;2002年,其所编制的《中国机读规则格式》经审核后,由文化部作为行业标准(WH/T15-2002)颁布、实施;2004年修订出版了《中国文献编目规则》(第2版)。
为适应网络信息资源编目的需要,CNMARC也同MARC21/B、UNIMARC等书目记录格式一样,增加了856等字段。与此同时,开展了对DC的研究和应用。国内对元数据的研究与应用,非常注意引进并利用一些成熟规范的编码体系,将其中的元素有机地加以组合,从而形成适应具体需求与中文资源特点的应用规范,提高互操作性,摈弃了从头开始设计自己专用元数据格式的做法,而是遵循标准、开放和可扩展的原则,按照元数据应用规范的模式来制定其元数据标准。像国家图书馆、中国国家科学数字图书馆、上海数字图书馆、北京大学图书馆、清华大学建筑数字图书馆、超星数字图书馆、万方数据公司、书同文公司等均是基于DC元数据设计的。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










