



6.3.2 基于协作的交互式过滤与推荐
协作过滤(Collaborative Filtering),又叫社会过滤(Social Filtering),是一种在推荐系统、主动服务中常用的一种信息过滤技术。协同过滤是通过分析用户的历史检索记录,对用户和信息进行聚类,然后根据聚类得到的用户相关性和信息相关性实现用户之间的协同,让具有相近检索需求的用户能借鉴彼此的经验。
传统的协同过滤系统没有考虑用户的自主性,用户不能自主地利用自己的判断力和分类关联知识对信息进行分类,也不能自主地引入或发展自己的社会关系网络,不能利用在现实中发展出来的可信任社会关系网络进行协同过滤。因此,当前的过滤系统在原协同过滤系统的基础上增加用户的自主性,让用户能够自主地对信息进行分类(自定义分类,或自定义信息之间的关联),并能自主地在系统内发展社会关系网络,或把现实中的社会关系网络带入系统之内,由用户自主地选择协同过滤伙伴,自主地建立可信任的社会关系,并从其信任的社会关系网络中学习和借鉴参考,这样改造以后,系统便具有了社会复杂性。在引入用户自主性后,信息系统中存在两种不同方法形成的用户关联网和资源关联网,一种是通过传统的系统聚类算法计算得出的,一种是依赖每个用户的知识和判断力自主发展出来的。在两类关联网间构成了反馈循环,图6-5是两类用户关联网间的相互影响示意图。系统聚类推荐的用户关系网把用户自主发展的关系网作为反馈学习的训练数据,用来改进优化算法;用户在自主发展社会关系过程中也可以参考系统的聚类推荐。正是这一反馈循环让系统的计算智能和用户的群体智能得到了有机的协同。
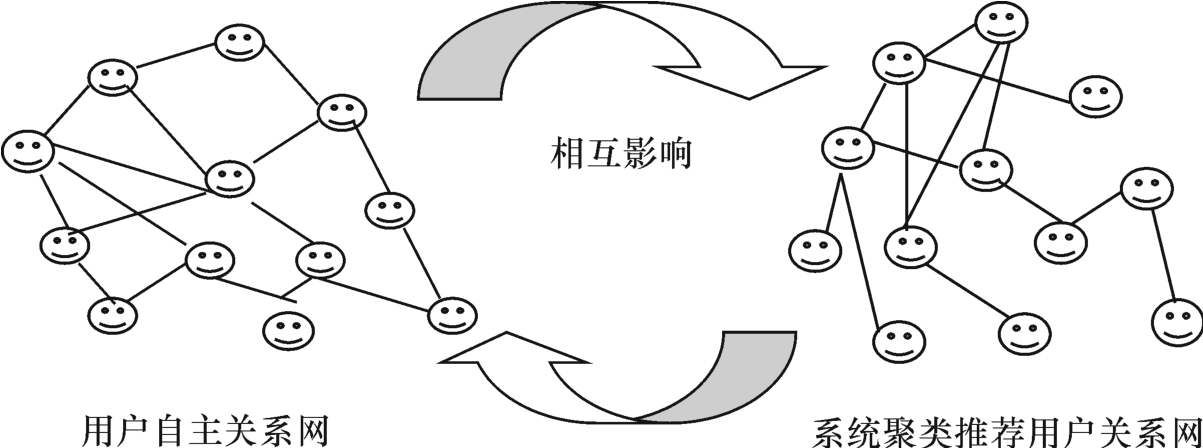
图6-5 两种方法得到的用户关系网之间的循环反馈
协作过滤系统的基本实现机制如下:搜集用户群体的偏好信息:使用相似度评价标准,从用户群体中选择与某一用户(当前信息用户)具有足够相似性的用户子群体,计算该子群体用户的平均偏好(或加权偏好)信息,根据计算结果向寻求推荐信息的用户推荐不带任何个人偏见的预测结果信息。由此可见,协作过滤是在分析用户兴趣的基础上,获取特定用户对某一类信息的评价,在用户群中找到与之兴趣相似的用户,把特定用户感兴趣的信息推荐给这些相似用户的过程,如图6-6所示。这种基于其他人的喜好和评价把信息推荐给相似用户的过滤模式,能够实现基于信息质量的信息过滤。WebWatcher,Let's Browse,GroupLens,Firefly等都比较成功地应用了协作过滤技术。目前,协作过滤技术被广泛地应用于电子商务网站,如Amazon,用来向用户推荐图书、音乐CD、电影等产品。当然,这种技术也可作为网络信息导航的依据,应用于导航系统中。与此同时,利用P2P的“合作过滤”功能,可以帮助商务网站分析消费者行为,Amazon就常用合作过滤功能来分析网民的购物行为,然后据此推测他们的好恶,并向他们推荐合适的商品。
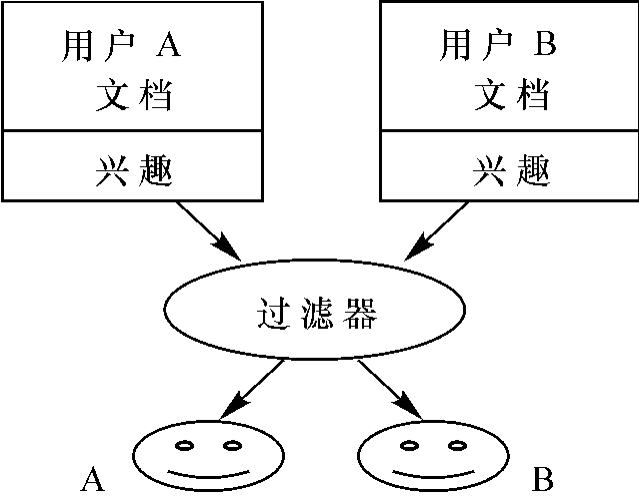
图6-6 基于协作的过滤
用户评价信息的获取和用户相似度计算是协作过滤的两大支持技术。用户评价信息的获取主要指获取用户对特定信息的评价,主要分为显式评价和隐式评价两种。一般来说,显式评价需要用户有意识地表达自己对某一信息的认同程度,可以用数值来表示不同的喜好程度,如Grouplxns、Ringo等协作过滤系统向新用户提供一个信息列表,要求用户对全部或部分信息进行评价,系统获得这些初始信息后,就能将用户加入到用户库中,随着用户不断使用协作过滤系统,用户的信息不断积累和更新。隐式评价则是不需要用户明确标识其对信息的喜好,而是系统从用户的访问记录、访问行为中获取相关信息,如一些系统利用数据挖掘、Agent技术,获取和分析用户的访问记录、浏览行为,从中获取用户的偏好等信息。协作过滤系统中,所有服务器都与用户密切相连,以便能够了解他们的访问记录。用户可以是匿名的,但他们的个人偏好都保存在服务器中。系统通过个人偏好的匹配,把具有类似偏好的用户进行聚类。当用户寻找信息时,可以把与其偏好相同的用户是如何找到相关信息的情况以及其他用户对这一信息的评价告知正在搜寻该信息的用户,指导其信息搜寻活动。协作过滤的好处就是能够使过滤器在过滤信息时考虑信息的质量。过滤不是基于内容,而是基于用户对该信息的评估,因此能够过滤机器难以进行自动内容分析的信息,像艺术品、音乐、电影等;而且,协作过滤系统还可以向用户推荐相关信息,实行主动的、个性化服务。但协作过滤系统也存在一些问题,如协作过滤系统受制于用户的评价和偏好的形成,如果对某一信息其他用户没有评价或者没有生成相关的偏好,那协作过滤系统的推荐、过滤功能就难以实现。另外,用户对信息的判断是否符合信息的真实面貌,能否对信息作出正确的评价也是值得考虑的问题。因为普通用户对信息质量作出明确的评价也不是容易的事情。
为了解决信息过滤,从而进行有效推荐的问题,豆瓣网(一个图书、电影、音乐等方面的大众评论和推荐网站)一直在不断完善其协作过滤系统,它采用系统计算和用户智能综合的方案。系统计算是用协同信息过滤算法,对用户的历史操作记录进行分析,得到用户之间的关联和数据之间的关联,再对不同用户群组选择性呈送最可能相关的信息(或对呈现的信息按照相关性排序)。由于系统的计算不一定符合用户真实的需求,因此豆瓣网在系统推荐中添加了用户反馈,系统可以依据用户的反馈数据调整系统内原来计算出的用户相关度和内容相关度。除在用户反馈设计中综合人机智能外,豆瓣网还采用了与计算智能推荐完全并行的人力协作的信息推荐策略,主要体现在自主小组功能的设计和自主友邻的功能设计上。
豆瓣网的自主小组功能让每个用户都可以自主地建立特定的兴趣小组,或自主地选择加入别人创建的小组,与依靠算法对用户分析、划分用户群体不同,自由小组给了用户自主组织起来的权利。系统除依据聚类算法给不同用户推荐其最可能感兴趣的信息外,还根据用户自由小组的参与情况,把整个系统内的大量动态信息(小组讨论)进行了初步分类,避免了用户的信息冗余,对每个用户只呈现与自己有关的、自己可能感兴趣的信息。除小组讨论提供了成员交互场所外,小组的推荐阅读提供了小组成员间就小组主题分享阅读的功能,此功能对小组所有成员开放(而不限于小组管理员),所以形成又一个达成成员间间接协作的渠道。
自主友邻功能是指每个用户可以自主地把另外一些用户添加为自己的友邻,友邻的最新收藏、最近阅读等信息被推荐给用户,作为系统计算推荐的一个补充。选择友邻的过程也是系统计算和用户智能综合的结果。以系统计算出的口味最相似的人的推荐为辅,以基于用户综合判断、自主决策为主,系统负责从大量用户群中为每个用户计算出其最可能感兴趣的人选,解决了人群过大、无从选择的困难,但最终是否添加友邻还依赖于用户的综合判断。由于一般情形下人们只选择自己感兴趣的用户,因此友邻的阅读也具有相互借鉴的价值,系统通过呈现友邻最近的阅读实现了相互之间的借鉴。
豆瓣中系统算法、用户反馈、友邻和小组间形成的复杂的信息交互网络如图6-7所示。[7]其中系统算法分析计算的数据来自于系统所有用户行为的记录日志。系统算法调整的依据是用户对两种推荐(推荐友邻和推荐阅读)的反馈,用户行为不仅受系统推荐的影响,还受友邻和同小组成员行为的影响,也受别的用户设置的“豆列”的影响,系统的设计为用户间的相互影响和借鉴提供了方便。
豆瓣网很好地综合了各类社会性软件系统中的功能和好的设计思想,并且在基于同样设计原则的基础上进行了扩展与延伸。如在系统中普遍采用了社会性标签的设计,以集众人智慧形成各种对象的分众分类;借鉴社会性网络服务(SNS)的思想,在系统内让用户自主发展社会关系(友邻),并可公开分享社会关系;借鉴Wiki的协同编辑功能,允许用户对书目等的介绍按Wiki的方式编辑(即所有用户都可以根据自己的知识对书目介绍等相关信息进行修改,但只有能得到人们广泛认可的内容才能稳定地继承下去),并允许用户自主添加图书、电影等信息,把数据库的添加和维护权限向用户开放,处处体现了相信用户、相信群体智慧的原则;支持RSS的输出,支持面向Blog的API开放接口,为系统的信息分享提供了尽可能的方便等。可以说,这些技术大都实现了在个人行为和集体行为集合效应间建立反馈,从而让先后用户行为之间形成了间接的影响干涉机制(非线性关系),并因此自底向上地涌现出信息内容规范、信息的分众分类、全局社会关系图、各种自组织社会群体来。此外,豆瓣网还内嵌设计了面向第三方信息系统的定向信息检索和竞价排名,从而实现了与多家外部系统间的信息共享(如当当、席殊、亚马逊等网络书店的数据)。因此无论是数据还是功能,豆瓣网都是一个多继承来源的混合体(Mash-ups)。
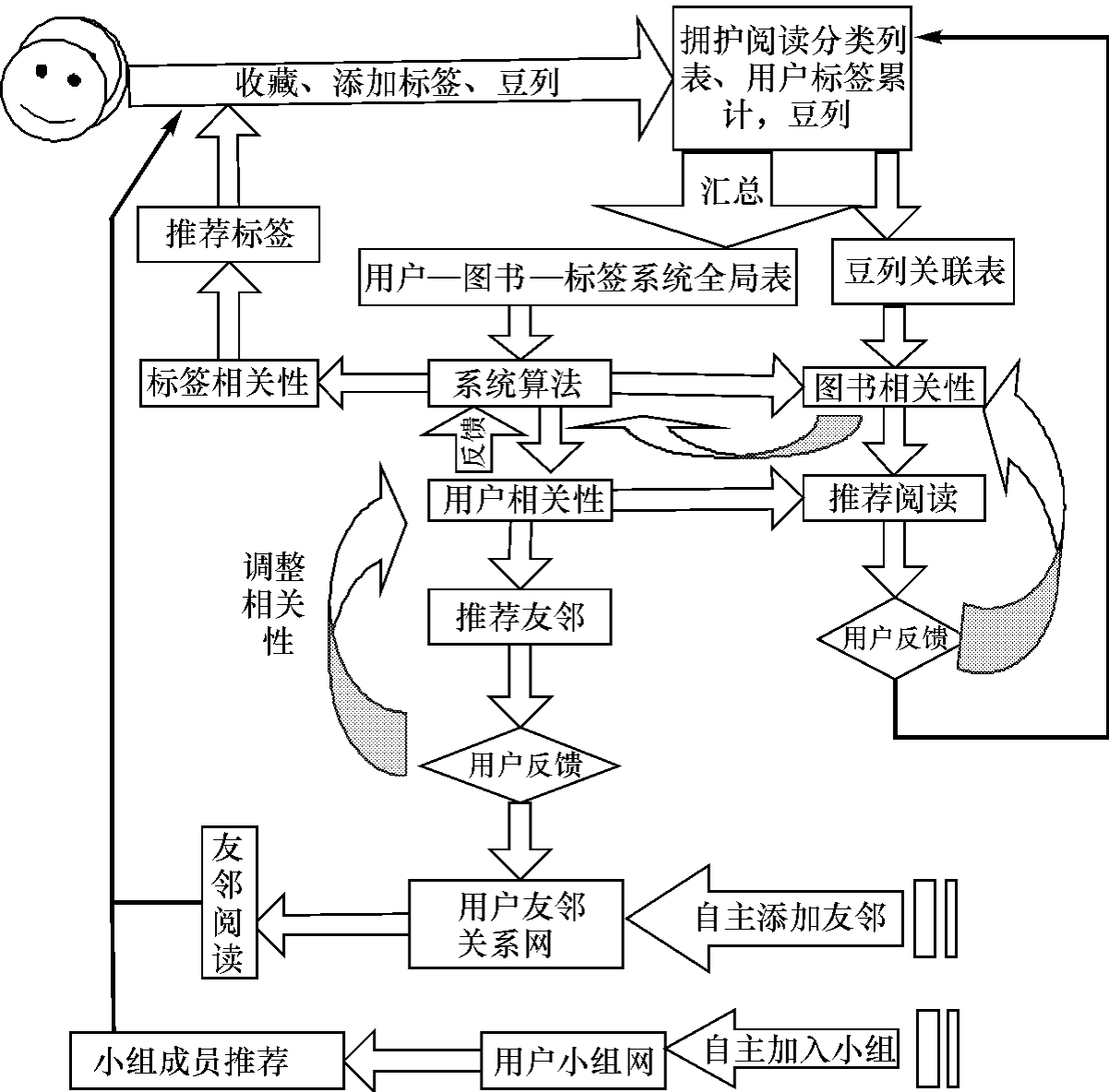
图6-7 豆瓣中的人—机—人信息交互网络图
虽然只是一个商业评论系统,但豆瓣系统中的用户之间自主协作、系统从用户行为中综合分析,并从用户反馈中改进系统算法、处处以人为中心、借用群体智慧的涌现等设计思想及指导原则和一些具体的设计,可被广泛地借鉴和移植应用在大量的多用户信息系统中去,如海量信息检索系统中的个性化检索与协同过滤的实现、图书馆管理系统、知识管理系统(如期刊网)、各类电子商务交易平台、虚拟社区、Web 2.0世界中大量衍生出的各类社会标签和社会评价系统,等等。在传统研究提出的各种个性化推荐和协同过滤算法难以获得用户高满意度的问题背景下,这种综合集成用户智慧、以用户之间协同分享经验为主、系统分析计算为辅的系统实现却获得了很好的成效(快速增长的用户规模、用户良好的体验和口碑反馈证明了这一点),因此值得引起从事信息系统、信息检索方面的研究人员的关注与思考。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











