



8.6.1 简化与改进的KNN模式识别方法(IS-KNN)
8.4.1节介绍了KNN及其简化的类重心法进行未知样本的模式识别。例8-6中类重心法对11号样本未能正确归类,在例8-7中分析了7个描述地层样本的变量间的相关性,发现有3个变量间存在强线性相关和较强线性相关。采用独立的主成分作为地层样本的特征后结果得以改进,可对所有样本进行正确分类。
因此,在模式识别中特征变量的独立性非常重要。采用近红外光谱信息进行模式识别有两个问题需要解决。
(1)特征变量的个数p(光谱点数)往往是大于样本数n的,不满足特征个数应大大小于样本数的要求。
(2)很多光谱点的信息间存在强相关,即特征变量间并不独立。
这两个特点使得直接运用光谱信息进行模式识别很难获得好的分类效果,为了保证样本数n能大于特征个数并消除光谱信息间的相关性,在利用近红外光谱进行模式识别时,通常采用主成分分析来压缩样本光谱信息并抽提独立的特征变量。
但此时又带来了一个新的问题:引入多少个主成分才能建立一个好的模式识别模型,Marina Cocchi等在采用近红外光谱建立面粉分类模型时,根据留一样本的最小PRESS确定模型中的主成分个数,指出特征的选取比光谱的预处理更为重要。在很多文献中,主成分个数m通常根据前m个主成分的累积贡献率来确定而不是根据模式识别的结果选取合适的主成分个数,按照这种方法选择的主成分不一定能保证最好的分类效果。而选择过多的主成分会导致引入噪声、使近红外模型产生过拟合的风险(即对建模样本可以获得很好的分类效果但对于检验集样本模型的分类识别准确率很差),而主成分选取过少会丢失一些重要的光谱信息。
从误差分析角度而言,主成分个数应当限制在一个合理的范围,不宜取得太多又不宜取得太少,应该能够反映足够和有效的原始光谱的信息同时又尽量避免引入不必要的噪声和误差。在近红外分析中总体误差(Overall Error,OE)可表示如下
![]()
来自参比的误差很大程度上可以通过对近红外光谱的预处理消除;改进模式识别算法及模型参数可以减少由近红外模型产生的误差;实验误差通常与仪器噪声、操作误差及仪器的精密度有关,仪器的精密度在出厂前就已经确定,其对OE的贡献和影响是确定的,因此可以不考虑精密度对总体误差的影响。由于操作误差很难事先估计,因而主成分的范围(即最大主成分个数)通过比较所有样本剩余主成分的标准方差(Standard deviation,SD)与仪器噪声水平(Noise level,NL)来确定。
剩余的p-m个主成分(p为光谱点数,m为选取的主成分个数)的标准方差计算公式如下
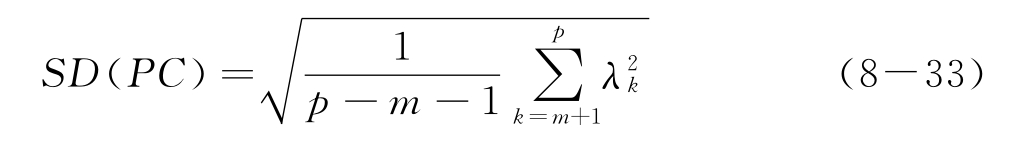
式中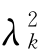 是第k个主成分的方差。
是第k个主成分的方差。
由于噪声的干扰,即使在很短间隔下在同一仪器上测试同一样品的近红外光谱间也会有细微的差异。连续测试q次同一样品,可获得q条样品近红外精密度测试光谱,采用精密度测试近红外光谱的标准方差来度量仪器噪声水平,则
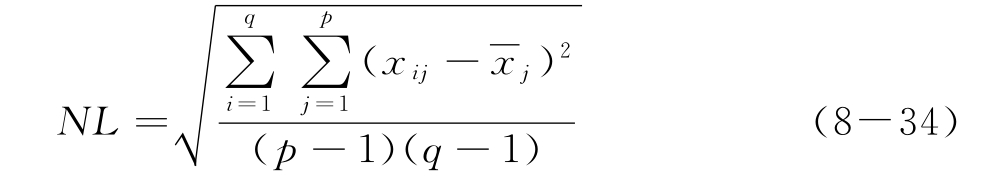
其中xij是第i条精密度测试光谱在光谱点j处的吸光度。
![]()
最大主成分的阈值可由下式确定
![]()
如果不考虑操作误差,则SD(PC)=NL,ρ=1。实际上操作误差是不可能避免的,SD(PC)通常应比NL高,故定义ρ=1.5。满足式(8-33)~式(8-36)的主成分个数m则为允许选择的最大主成分个数mmax。
在所有可能的主成分个数m(1<m<mmax)下,对建模样本采用8.4.1介绍的类中心KNN法进行判别,统计不同主成分下的判别正确率,选取正确率最高时的主成分个数为最佳模型参数,这样建立的近红外模式识别模型既可包含足够的有效信息又可避免过拟合并避免引入不必要的噪声。
本书作者等提出在主成分空间比较各样本到不同类中心的马氏距离判别样本归属的模式识别方法,采用上述准则确定最大主成分个数及最佳主成分个数。这一方法命名为简化与改进的KNN方法(Improved and Simplified KNNmethod,IS-KNN)。
IS-KNN方法的主要步骤如下。
(1)采用建模集样本进行主成分分析(PCA),根据样品的精密度测试近红外光谱确定最大主成分个数mmax,保留前mmax个主成分得分及其载荷向量。
(2)从建模样本中依次轮流选取1个样本作为检验集,在m维(1<m<mmax)主成分空间下计算各样本到每个类中心的马氏距离。
(3)样本距哪个类中心的马氏距离最小则认为该样本属于哪一类。
(4)统计不同主成分个数m(m=1~mmax)下留建模集样本的判别正确率ζ(m),取ζ最大时对应的m值为最佳主成分个数。
(5)在最佳主成分个数下计算各样本(建模集、检验集或预测集)样本到不同类重心下的马氏距离,样本距哪类的类重心距离最小则判别为该类样本。
(6)统计整体正确率和预测正确率。
根据式(8-10)可知在m维主成分空间下样本i,j之间的马氏距离计算公式为
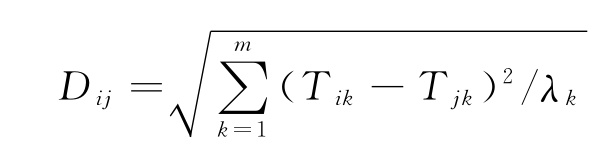
其中Tik、Tjk分别为样本i、j的第k个主成分得分,λk为第k个主成分的方差。
设类j的中心在主成分空间的坐标为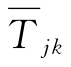 (k=1,2,…,m),则样本i到第j个类重心的马氏距离为
(k=1,2,…,m),则样本i到第j个类重心的马氏距离为
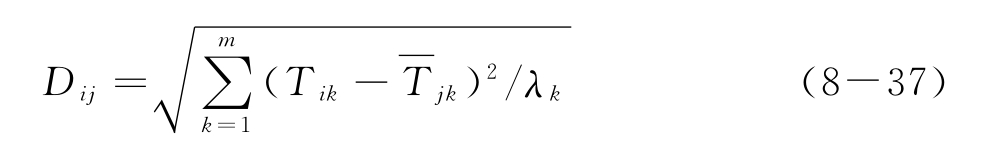
例8-16 不同产地烟叶具有不同的香气风格,本例收集2003年125个国产烤烟烟叶样本,分别来自云南(17个)、陕西(17个)、山东(32个)、黑龙江(24个)和重庆(35个)。将烤烟烟叶磨成粉,在低于50℃下烘0.5h,使含水率达到10%~12%。过60目筛,取适量烟末(高度约占样品杯总高度的1/5),放入样品杯中,取一固定重量砝码放置在样品上方,使其自然压实后进行近红外扫描,NIR仪分辨率设定为8cm-1,扫描次数64。最终获得125条近红外光谱,以这些样品的近红外光谱为基础采用IS-KNN法进行样品的产地识别。
图8-12为采用一阶导数预处理后5个产地样品前10个主成分得分的平均值示意图。该图显示,不同产地烟叶的主成分有明显的差异,说明可用烟叶近红外光谱的主成分作为模式特征来描述烟叶的产地风格,进一步以主成分得分为基础进行产地的识别和分类。然而,取多少个主成分合适,近红外仪上所带商业软件不能像定量分析一样根据交叉验证结果提供最佳主成分数。采用留一交叉验证法考察预测准确率与主成分个数的关系时发现,预测准确率随主成分个数的增大而增大,到后期呈锯齿状跳动(见图8-13)。但主成分数过多会引入仪器噪声和误差,太少则信息量不足,难以完全体现不同产地的风格特征。
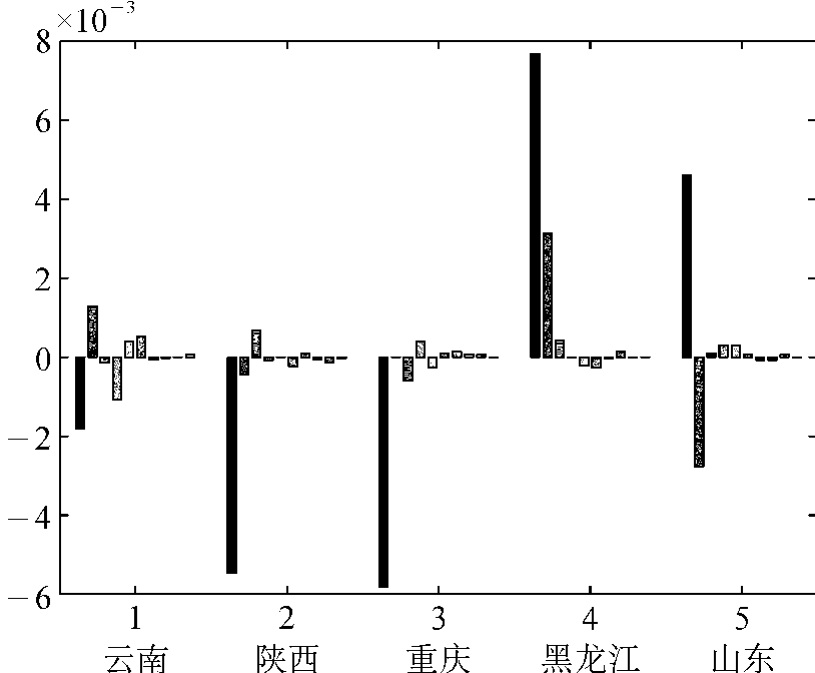
图8-12 5个产地烤烟一阶导数NIRS的前10个主成分得分柱状
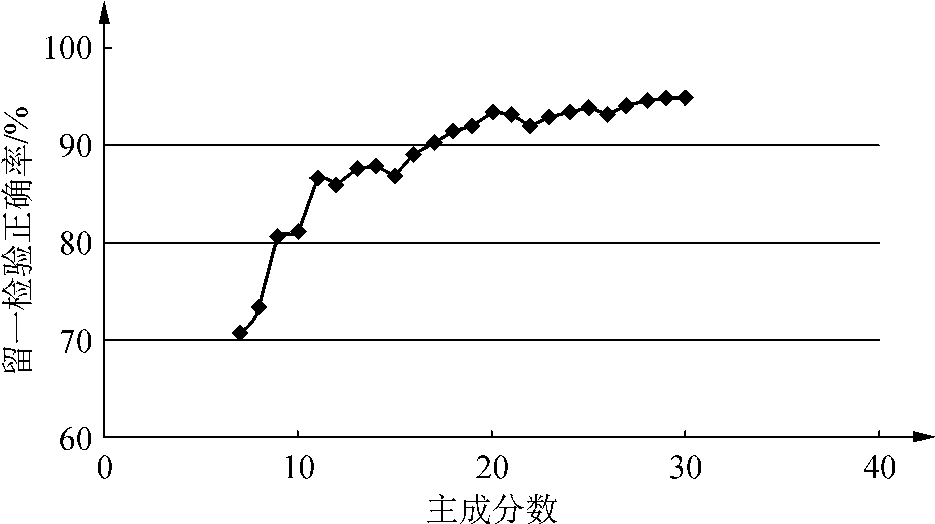
图8-13 主成分个数与留一检验正确率之间的关系
对于125个烤烟烟叶样本,随机抽取5组样本集(建模集99个样本,预测集26个样本),分别以原始光谱、SNV处理后光谱及一阶导数后光滑处理光谱为信息基础,采用IS-KNN方法进行其产地识别(在整个光谱区间),发现在小于最大主成分个数的前提下,采用SNV与一阶导数光谱时最佳主成分个数随样本集光谱而变(在8~14间波动),所得5组样本下的平均正确率见表8-9。
表8-9 采用不同预处理近红外光谱时IS-KNN方法对烟叶产地识别的结果

注:①AAP表示5个随机分组样本集下对预测集样本识别的准确率的平均值,即平均预测准确率;②WAA表示对建模及预测集样本(所有样本)识别的准确率的平均值,即整体平均准确率;③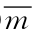 为5组样本集下得到的最佳主成分个数的平均值。
为5组样本集下得到的最佳主成分个数的平均值。
由表8-9可知,采用IS-KNN方法根据一阶导数光谱的主成分得分进行烟叶产地识别可获得最高整体正确率与预测正确率(>97%)。
图8-14为125个样本在第一、第二主成分空间的投影图,该图表明陕西、重庆的烟叶样本交叉严重,云南样本也与这两个产地样本有部分重合。显然根据第一、第二主成分投影很难将5个产地的样本进行良好区分。这说明仅仅由两个主成分不能完全描述不同产地烟叶的风格特征,因此需要选取更多的主成分进行烟叶产地模式识别。表8-9的结果表明对于分类效果较好的SNV及一阶导数光谱,最佳主成分个数为11~13,其个数随样本集的变化而变。
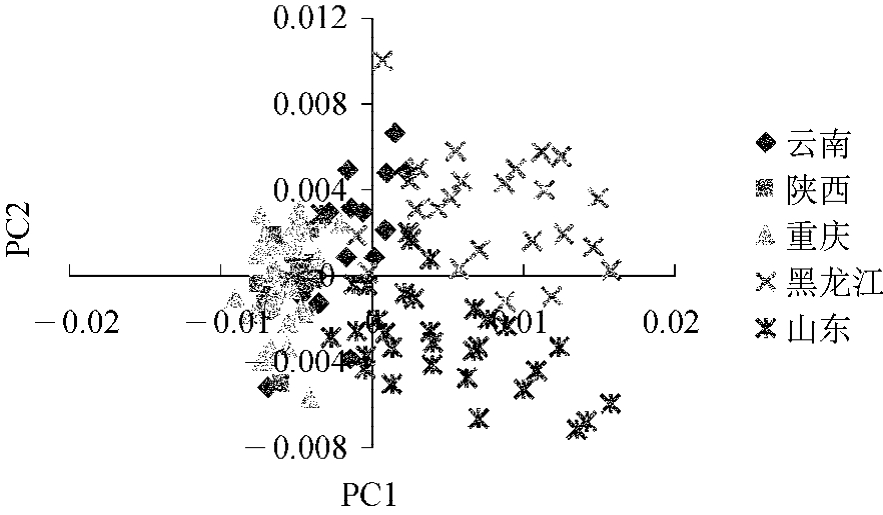
图8-14 SNIRS125N中烟叶样品的第一、二主成分投影
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










