



5.7.2 人耳识别方法
1.主元分析法(PCA)
PCA是生物特征识别研究中广泛使用的一种方法,在人脸识别领域已经进行了大量研究。PCA是一种降维技术,它根据图像的统计特性进行正交变换,以消除原有向量各分量间的相关性,变换得到对应特征值依次递减的特征向量。
Victor等人比较了PCA应用于人耳识别和人脸识别的性能。他们使用了标准PCA算法:
①将人耳和人脸图像进行剪裁、归一化、屏蔽非耳朵区域、补光等操作;
②用主元分析法训练得到特征脸和特征耳;
③用最近邻法对测试图像的特征向量与注册库中的特征向量进行匹配。
在假设人耳识别、人脸识别之间不存在显著差异的前提下总共进行了三次实验,三次实验的图库和探测集分别取自同一时间但具有不同的表情、不同时间的相同表情、不同时间和不同表情。在所有三次实验中,人脸识别效果均优于人耳识别的效果。Chang等人继上述研究后使用更大样本集做了类似的实验,过程基本与Victor等人的相同。但库中脸和耳朵图像的质量控制更加严格,去掉了图像有被遮挡或覆盖的情况。他们也做了三次实验,分别是时间改变、光照条件改变和姿势改变(旋转22.5°)。结果发现人脸和人耳识别率没有较大差别;耳识别率最高为71.6%,脸为70.5%。Chang等人还进行了多模态识别,发现用脸和耳共同构成的多模态方法效率优于单独使用其中一种方法的识别效率。如在一次实验中可达90.9%的识别率。Victor和Chang的实验得出了不同的结论可能是由于图库的质量。Victor等人所研究的图像数据集对于被耳环、头发覆盖在耳朵上的情况没有控制,从而导致了误识;Chang等人排除了这些图像,提高了人耳识别的效率。
2.使用Voro noi图表的邻接图匹配方法
Burge和Burger提出了一种图表匹配方法进行人耳识别。他们对个体头部灰度图像梯度的高斯金字塔使用可变形轮廓方法进行外耳定位,再使用Canny算子进行边缘检测,较大的曲线段使用边缘松弛法形成,去除较小的曲线段。最后将提取的曲线与模板进行比对。光照和位置的变化使得这种方法非常不可靠。为了克服这种影响,他们将问题转换为描述曲线之间的相邻关系;还使用了一个称为误差改正图匹配算法进行误差校正。然而当文献想实现他们的方法时,却发现基本的耳朵描述是相当不稳定的,图像角度和光照有轻微改变,从图像检测出的边缘变化就非常大。Burger等人建议使用温谱图解决耳朵被头发部分遮挡的问题。他们发现耳朵眼很容易定位,在温谱上,耳朵眼是最热的部分,它和周围头发之间有8℃的温差,因此通过找到这个高温区域,就有可能用温谱图检测和定位出耳朵。
3.使用各种组合技术的神经网络方法
Moreno等人使用神经网络设计了三种分类器。
(1)使用外耳特征点进行识别。使用双Sobel算子得到外耳轮廓图作为外耳特征点构成特征向量,作为神经元的输入,识别率为43%。
(2)使用外耳形态进行识别。使用上述技术构造大小为H×V像素的外耳轮廓图,然后在水平方向上进行h分割,在垂直方向上进行v分割,在对角方向上进行2(h+v)分割,对人耳轮廓图中交叉点个数和不同分割构成的向量进行归一化,得到每幅图像的形态学特征向量,作为神经元的输入,识别率为83%。
(3)使用压缩。网络进行识别。这步分为两个阶段:第一阶段提取原始外耳图像显著的统计特征和宏观特征,即压缩特征。这个压缩向量是原始图像的一个中间编码表示,它构成第二阶段执行识别任务的神经网络的神经元输入。用上面的分类器构造复合分类器,目标是希望通过合并得到更好的识别率。一共使用了三种组合方法,即确定性分类器、等级分类器和不确定性分类器。实验结果显示,压缩网络达到最高的识别率,合并的分类器没有提高识别率;但若考虑拒绝域,这些合并技术还是提高了无错识别率。
4.力场转换方法
Hurley等人模仿自然界的电磁力场过程,提出了一种力场转换理论。在该理论中,整幅图像被转换为一个力场,该力场的形成是通过假定图像上每一个像素点对其他所有像素点均施加一个等方向性的力;力与像素灰度成正比,像素间距离的平方成反比。由此,在一个与力场相关的势能面。在待检测的耳周围放置一组单位亮度的测试像素点,它们呈封闭形将耳包围。每一个测试像素点在力场的拉动下朝着潜在势阱运动,直至到达平衡位置,即势阱的中心,其产生的运动轨迹形成场线。
由于在每一点的力场是唯一的,所有到达给定点的场线都会沿着同样的路径,并从该点继续向前运动从而形成“渠”。50个测试像素点呈椭圆形被放置在力场中,测试像素点经过多次计算形成场线,并且能够从图像中观察到渠的形成过程。潜在的势阱位置被提取出来作为基本特征向量描述人耳的特征点,并证明不同的耳朵,其势能通道与势阱是唯一的。该方法中特征点数量和位置不受初始点位置选取的影响,但初始点数量不能太少,否则会导致势阱丢失;而且在分辨率较低情况下仍能获取力场结构。这样可以先利用较低的分辨率定位目标,然后在较高分辨率下进一步提取特征信息。它还具有抗噪声能力,在受到高斯噪声的干扰下力场结构基本不变。该方法具有很强的鲁棒性,这项技术的好处在于并不需要一个对目标拓扑结构的清晰描述,对阱的提取仅仅是场线以及观察到的最终坐标。而若考虑到渠的形状和最终能量表面的形状,则可以提高描述细节程度,以达到任意需求。
5.遗传局部搜索算法
YuizonoT.等人把耳识别问题转换为图像的模板匹配问题,用遗传算法进行全局搜索在基本的选择、交叉、变异操作中加入了局部搜索。这种改进提高了局部最优值的搜索效率。搜索空间包括50个耳图像,每行10幅,共五行;同时在每个注册图像四周分别加了20个像素。
染色体被设计成模板匹配过程中耳朵图像最左上角顶点的X、Y坐标,一共包含21bits。其中,10bits表示X坐标、11bits表示Y坐标。适应度函数S定义为每两个网格交叉点的灰度差值的总和。模板匹配在网格结构中进行,以节省计算时间,计算时间与网格数量是等比例的。实验中选择的染色体数目是800,遗传代数为250代,两点交叉率为0.6,使用了12×16的网格结构。在选择策略中,局部搜索被应用到具有最佳适应度的五个精英中;同时选择精英保留策略,保存具有最佳适应度的个体。在局部搜索算法中,一个(X,Y)坐标的父坐标四个已知点,他们是在X±6像素,Y±10像素范围中选取的。父代中具有最佳适应度的坐标和它的四个坐标作为产生下一代的新父类。这种方法对已注册图像的最高识别率可达到100%,对未注册图像的拒绝率是100%。
6.几何学方法
Michal提出了一种几何学方法来提取特征点。他用自己提出的算法进行轮廓提取,然后进行二值化、坐标归一化,找出其质心。质心是为特征提取所找的参考点,以质心作为参考点可以使图像满足平移、旋转、大小不变性。第一个特征向量V由几何信息构成。以质心为圆心画Nr个不同半径的同心圆;对每一个圆算出其与耳轮廓的交点数量lr以及相邻交点之间的距离d。根据圆半径的不同,把所有交点及相应信息存入第一个特征向量V中。第二个特征向量F由特征点信息构成,即由耳轮廓线端点、分叉点和与圆的交点构成。对耳轮廓线上的每一点(g0=1),找出其相邻八个点中属于耳轮廓g=1的个数N8c。若N8c=1则说明该点是耳轮廓线端点;若N8c>2则说明该点是耳轮廓线的分叉点。
7.基于长轴的形状特征提取方法
Mu等人提出了基于长轴的形状特征提取方法LABSSFE。首先,在外耳轮廓上找到距离最长的两点(x1,y1)和(x2,y2)形成长轴,取长轴的中点O(x0,y0);然后外耳曲线通过中点被分成两部分Line1和Line2,所示;对每一部分应用最小二乘法进行曲线拟合,将两个拟合曲线的参数向量作为Line1和Line2的形状特征向量。A、B是长轴与外耳轮廓的交点,长轴的长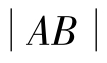 度为。短轴FOH为长轴的中垂线。用长短轴与内耳的交点之间的长度和长轴的比率作为特征向量,即[OA/AB、OB/AB、OC/AB、OD/AB、OE/AB、OF/AB、OG/AB、OH/AB]。这样,当耳朵图像旋转或缩放时,这个特征向量是不变的;然后把两个向量合并成一个向量,使用BP神经网络作为分类器进行识别。
度为。短轴FOH为长轴的中垂线。用长短轴与内耳的交点之间的长度和长轴的比率作为特征向量,即[OA/AB、OB/AB、OC/AB、OD/AB、OE/AB、OF/AB、OG/AB、OH/AB]。这样,当耳朵图像旋转或缩放时,这个特征向量是不变的;然后把两个向量合并成一个向量,使用BP神经网络作为分类器进行识别。
8.基于3D耳朵检测和识别方法
用2D灰度图像进行识别不可避免地会遇到类似阴影、姿势和光照条件改变等问题。Chen Hui等人使用距离传感器直接获取人耳的3D图像数据,提出基于3D人耳检测和识别方法。
(1)基于3D的外耳检测方法。
Chen Hui等人提出了一种简单高效的从侧脸图像中检测人耳的方法。首先,用形状指数的直方图获取耳朵的几何信息,根据此信息建立耳朵的模型模板;然后,利用三维外耳轮廓的高度差会有很大跳跃的特点得到侧脸的阶跃边缘图像后,域值化为二值图像。这个二值图像上有一些小洞,对它进行膨胀以填充这些小洞。利用一个阈值移去一些过小不可能包含耳朵的区域。最后计算可能存在耳朵的区域形状指数直方图,将其与第一步中得到的耳朵模板进行比较,找到一个非近似程度最小的区域就是耳朵所在的区域。实验采用真实的耳朵图像,正确检测率达到91.5%,错误警报率为2.52%。
(2)基于3D的人耳识别方法。
首先,利用基于3D的外耳检测方法检测出外耳轮廓;然后,利用ICP(Iterative Closest Point)算法找到一个初始变换使得一个模型耳与测试耳对应。注意:一个待检测耳朵需要与模型库中的所有耳朵都执行一遍ICP算法。在粗匹配中得到的模型耳中,再次利用ICP算法,通过在耳朵中间部位取出的一些点来改进变换矩阵,细化得到的变换矩阵,使得模型耳与测试耳更好地对应。利用RMS错误匹配标准找出有最小RMS错误的模型耳,此时认为匹配成功。这种用两步ICP过程实现3D人耳识别方法的实验结果具有很高的识别率,可以达到93.3%,而且鲁棒性强。
总结上述人耳识别方法,有以下两个方向:基于整体的研究方法,考虑了模式的整体属性;基于特征分析的方法,也就是将描述人耳结构特征和形状参数等一起构成识别特征向量。由于使用的人耳图像库不同,而且多数方法是在理想条件下高质量的图像上进行实验,甚至有的识别方法没有进行实际仿真实验,只是一个理论上的模型,因此不同识别算法之间的优劣没有可比性。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











