



第三节 SPSS统计分析系统
SPSS for Windows使用两类统计分析方法,一类是数字分析,另一类是作图分析。数字分析过程在主菜单的Statistics中,通过多种分析过程,得到对数据的数值分析结果。图形分析可以给读者对数据统计特征图形化,以直观的形式出现。
一、SPSS for Windows数值分析过程
1.基本统计分析(图13-3-1)
Descriptive Statistics主要包括5个基本统计分析过程,即:
Frequencies过程,该过程可以作单变量的频数分析表,可以显示数据文件中同用户指定变量的不同值发生的频数,也可以用来获得某些描述统计量和描述数值范围的统计量。
Descriptive过程,可以计算单变量的描述性统计量。
Explore过程,用于计算指定变量的综合描述性统计量,可以对观测量整体分析,也可以进行分组分析。
Crosstabs过程,可作为两变量或多变量的各水平组合的频数分布表,即交叉分析表。
2.分析功能(图13-3-2)
Compare mean分析功能主要包括四个基本统计分析过程,即:
图13-3-1
图13-3-2
Means过程,就是对指定的变量进行单变量的综合描述统计量的计算,还可以对指定的变量进行分组分析。
Independent Sample t Test过程,进行独立样本的t检验,即检验两个不相关的样本是否来自具有相同均值的总体。
Paired Sample t Test过程,对配对样本进行t检验,即检验两个相关样本是否来自均值相等的总体。
One-way Anova过程,就是进行单变量方差分析,检验两个以上彼此独立的组是否来自均值相同的总体。
3.多元方差分析(图13-3-3)
图13-3-3
Anova包含四个基本统计分析过程,是多元方差分析的过程,即:
Simple Factorial过程,完成因子设计的方差分析,可以指定协变量进行协方差分析,也可以指定一种分解偏差平方和的方法。
General Factorial过程,高级统计模块中的分析过程,进行一般的方差分析设计。
Multivariate过程,是高级统计模块中的分析过程,它可以实施有两个或多个相关的因变量的方差和协方差分析。多变量方差分析检验相互有关的因变量集与一个或几个因素或分组变量之间关系的假设。
Repeated Factorial过程,也属于高级统计模块中的分析过程,用于检验因变量的均值的假设,尤其是当研究对象的同一因变量在不同条件下测定时。
4.相关分析(图13-3-4)
图13-3-4
Correlate包括进行各种相关分析的功能,主要是三个分析过程,即:
Distance过程是计算许多相似性、非相似性或不同距离的测量,这些测量用于定量两个观测量或两个变量相似度和非相似度。
Partial过程是计算两个变量间的相关系数。
Bivariate过程是计算Pearson积矩相关矩阵和Kendall、Spearman非参数相关。
5.回归分析(图13-3-5)
Regression是进行各种回归分析,例如:
Linear过程,用于确定一个因变量和一组自变量之间的关系。
Logistic过程,用于估计因变量为二分变量的回归模型。
Probit过程完成概率分析,这种分析是测试刺激强度与反应比之间的关系。
Nonlinear过程,用于估计带有表明观测度的不等权数的线性回归模型。
2-stage Least Squares过程可以完成二阶最小平方回归,在模型中误差项与预测值有关联。
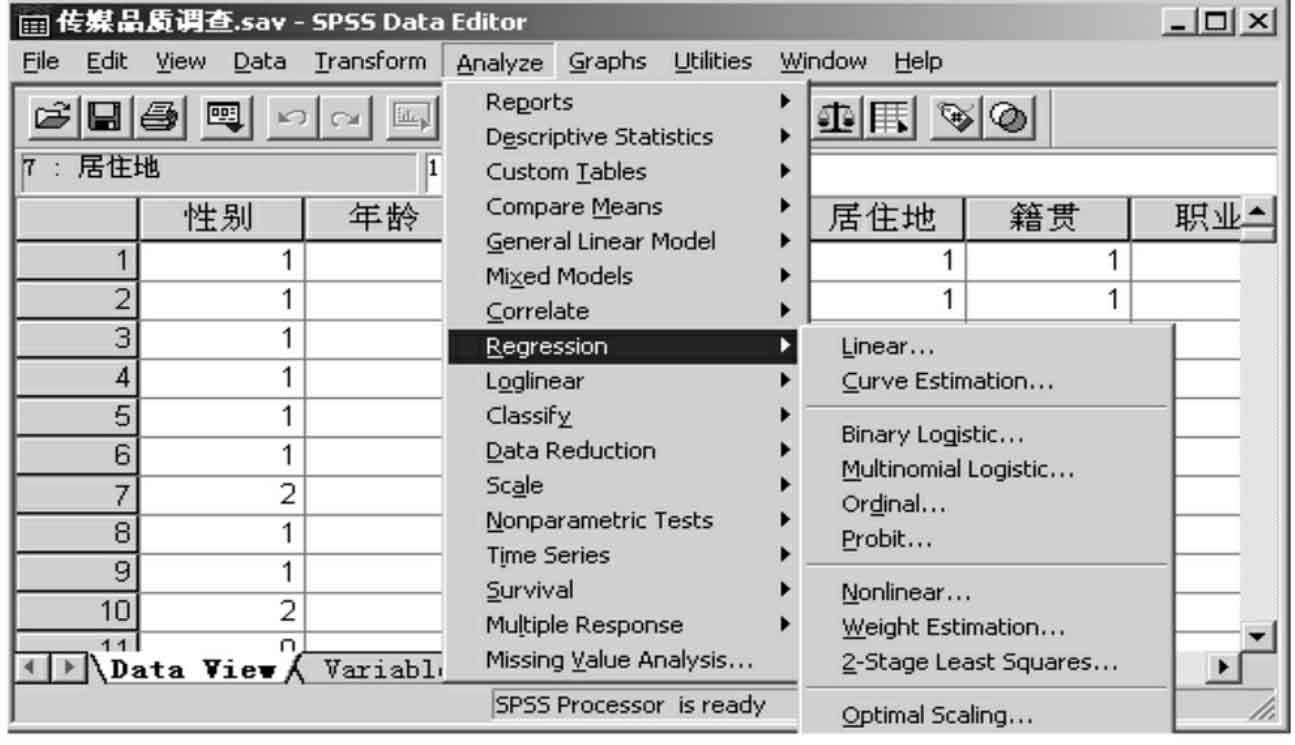
图13-3-5
6.聚类和判断分析(图13-3-6)
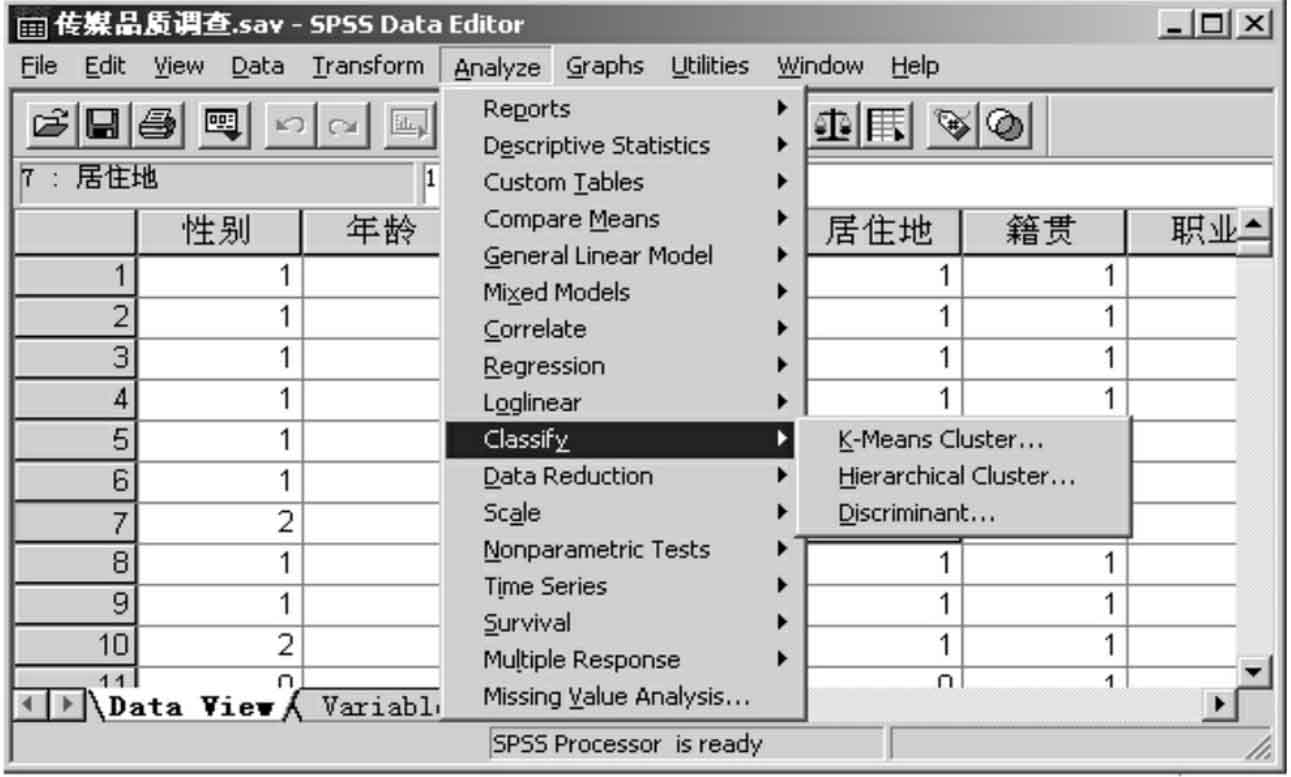
图13-3-6
Classify包含多种聚类和判断分析过程,主要是:
K-means Cluster过程使用可以处理大量观测量聚类算法完成聚类分析,但要求指定分类的数目。
Hierarchical Cluster过程,将观测量分组聚类,它使用密集存储的算法,简单地对许多不同结果进行检验。
Discriminant过程,根据已知的按某些特性的观测量分类,找出判别函数,以根据一组变量组预测因变量的值。
7.对数线性回归分析(图13-3-7)
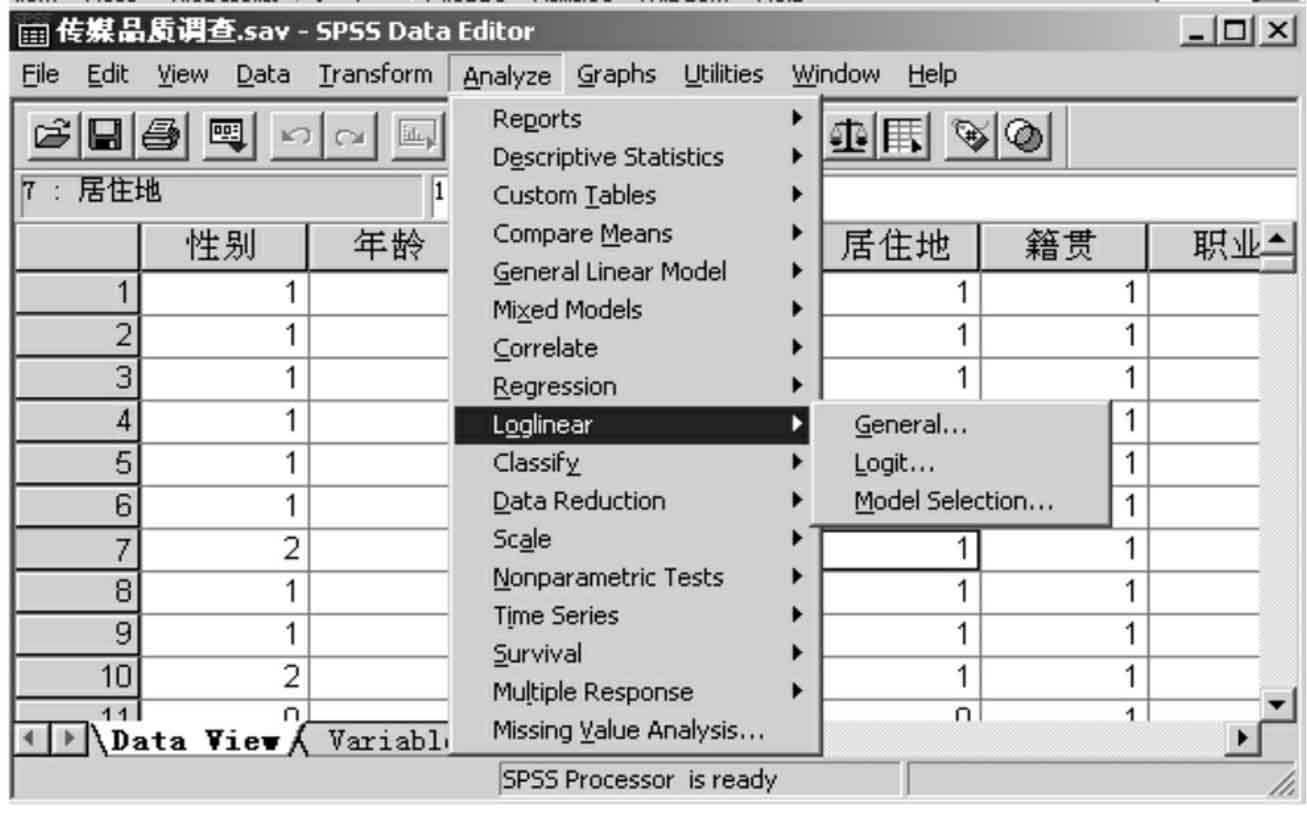
图13-3-7
Loglinear包含对数线性回归分析过程,具体的过程有三个,即:
General过程是用最大似然法估计一般对数线性模型的参数,检验其效应,用以认定分类变量的关系。
Hierarchical过程用于建立多维交叉表中变量间关系的模型。
Logit过程用于检验一个分类因变量和一个或多个分类自变量间的关系。
8.数据简化(图13-3-8)
Data Reduction包含五个不同过程,是简化数据的过程,如:
Factor过程,属于专业统计分析过程,用于确认能够说明一组变量综合大批变量。
Correspondence过程用于分析对应表(交叉表等),是对类别之间或变量之间距离的最佳测度。
Homogeneity Analysis过程在Categories选择项中,是一项最佳换算过程,类似于因子分析,但该过程能够分析分类变量或有序变量。该过程亦可称为多重对应分析。
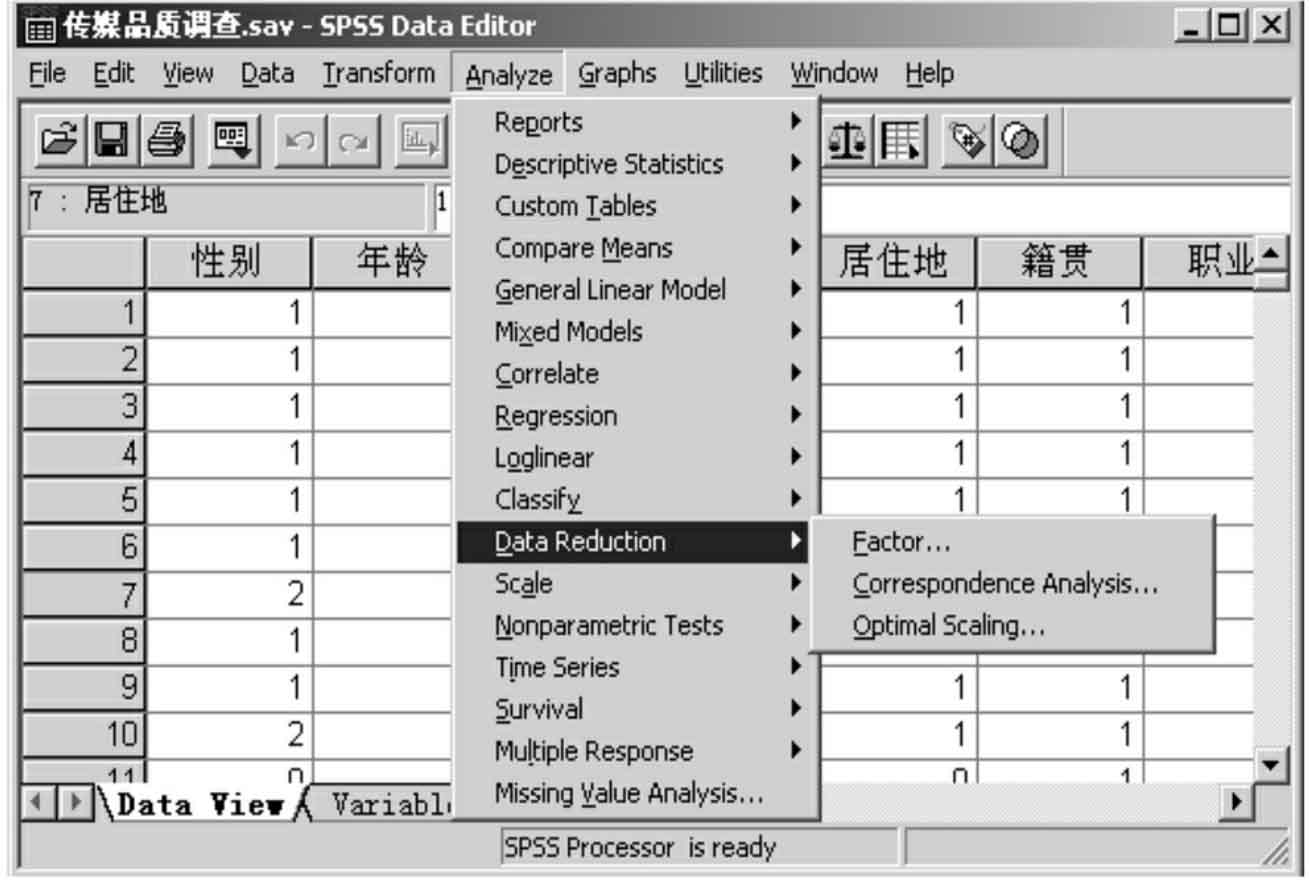
图13-3-8
Nonlinear Components是非线性分析,它的过程在Categories选择项中,完成非线性主要成分分析,以试图减少一组变量的维数。
9.Conjont过程(图13-3-9)
图13-3-9
Conjoint过程共包含三个过程,它们是:
Genrate Design过程,产生“正交”设计,这个设计在没有对每种因子水平组合进行检验情况下,允许对几种因子进行统计检验。
Print Design过程是打印Genrate Design过程完成的设计,供在数据收集中使用。
Analysis Design过程对以上得出的设计而汇集的数据结果进行联合分析。
10.Scale过程(图13-3-10)
图13-3-10
Scale包含两个过程,即:
Multidimensional Scaling过程代表多维空间的对象,从配对对象之间的相似性和距离方法估计对象的位置。
Reliability Analysis过程是通过计算诸如“Cronbachs alpha”等级普通可靠性的度量,来完成加性等级的项目分析。当有一个通过求对独立项目响应而得到的等级,可以了解这些项目的相关程度。
11.Nonparametric Tests(图13-3-11)
Nonparametric Tests包含较多的过程功能,即:
Chi-Square过程用于检验落入几个互不相交组的观测量数目相对比例的假设。
Binomial过程用于对一个来自二项分布的总体,检验变量具有指定的事件发生的概率的假设,该变量只有两个值。

图13-3-11
Runs过程用于检验二分变量的两个值是否以随机序列发生,但仅适用于在数据文件中观测量的顺序为有意义的情况。
1—Sample Kolmogorov-Smimov过程用于检验一个样本是否来自一种指定的分布,可以对照一致分布,正态分布或Possson分布进行检验。
2—Independent Samples过程用于比较一个变量在两个不相关的组中的分布。
K Independent Samples过程用于比较一个变量在两个或两个以上组别之间的分布。
2—Related Samples过程用于比较两个相关变量的分布。
McNemars Test过程用于确定相关样本比例的变化,当因变量是二分变量时它可以用于“前和后”的实验设计。
K Related Samples过程是用于比较两个或两个以上相关变量的分布。
Cocharns Q test过程用于检测不同二分变量是否具有相同的均数。
Kendalls W过程用于测定评判的一致性,每个观测量对应一个评判人,所选的每个变量是一个评估的项目。
12.Time Series(图13-3-12)
图13-3-12
Time Series包含四个过程,包括Exponential Smoothing,Curve Estimation,Autoregression,ARIMA。
Exponential Smoothing过程通过使用任何一种合并不同类型的趋势和模型,执行时间序列数据的指数光谱。这个命令在trends选择项中,建立包括预测值和残差的新序列。
Curve Estimation过程使各类型数学函数拟合数据。就时间序列而言,独立变量可以是观测量的序列号,结果包括带有预测值、置信区间和残差的新序列。
Autoregression过程估计检验第一阶自回归误差的线性方程,它提供三种估计方法,包括容许嵌入缺失值的方法。时间序列数据可能违背回归假设,因为这种回归假设所有观测必须是独立的,因此自回归模型对时间序列特别有用处。
ARIMA过程估计非季节和季节单变量的综合自回归移动平均模型(ARIMA),该模型可选择固定回归自变量,这种算法在序列中容许嵌入缺失值。综合自回归移动平均模型建立包括预测值、标准误、置信区间和残差的新序列。
XⅡARIMA过程估计增倍和加性季节分子,这是由于具选择的ARIMA向前和向后的方法,以及使用了一般的XⅡARIMA算法。
Seasonal Decomposition过程使用Censlls MethodⅠ方法对时间序列进行增倍和加性季节分子估计,它建立包括序列调节分子、季节调整序列、趋势图期分量和误差分量的新序列。
13.Survival(图13-3-13)
图13-3-13
Survival包含个四个过程,它们是:
Life Tables过程用于检测两个事件分布,但第二个事件不一定发生。
Kaplan-Meier过程用于检测两个条件分布但第二个事件不一定发生的情形。
Cox Regresssion过程用于研究某个事件和一组时间自变量之间的相互关系。
Cox W/Time Dep COV过程在时间函数是一个或一个以上的自变量时,该过程执行Cox回归。
14.Multiple Response(图13-3-14)
Multiple Response包括三个过程,即:
Define set过程以指定变量组成一个多重影响或多重两分数集,并应有频数表和交叉列表。
图13-3-14
Frequencies过程对定义的多重响应或多重两分集数提供一个频数表。
Crosstabs过程提供带有另一种变量的、已定义的多重或多重两分数据集交叉表。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










