



第二节 随机变量的概率分布
随机变量的概率分布是指,各个随机变量取值时它们对应的概率取值。比如投掷n次钱币,出现1、2、3、…n次正面的概率;生育3个孩子出现1、2、3个男孩的概率;也可计算出现在等候不同时间(2分钟之内,2~4分,4~6分,……)公交汽车的概率。前两类称离散型随机变量概率分布,最后一类称连续性随机变量概率分布。
一、离散型随机变量
1.概率表示方式
随机变量的取值及其概率值的表示形式有多种,哪一种合适需要具体情况具体分析。
(1)表格形式
设离散型随机变量x的所有可能取值为x1,x2…,xn,…,相应的概率为p(x1),p(x2),…,p(xn),…。可用表格表示如表5.7所示。
表5.7 概率表格表示的一般形式

而连续型随机变量x的概率分布,无法用表格的形式进行表示。
(2)函数形式
这称为离散型随机变量X的概率分布。也可简单记为:
P(X=xi)=p(xi)(i=1,2,…) (5.8)
(3)图示法
以X轴为横坐标,X所对应的概率为纵坐标,由此构成直角坐标图。
[例5.19]掷四个钱币,出现正面数i就是随机现象,其最小为0(全部是反面)、最大为4(全部是正面),共有5种结果:0、1、2、3和4。有16种可能性分别是:0000、0001、0010、0100、1000、0011、0101、0110、1001、1010、1100、0111、1011、1101、1110和1111。出现0个正面——4个钱币都是反面的情况为:0000、……;2个正面的情况分别为:0011、0101、0110、1001、1010和1100等6种可能性;……;4个正面的情况为:1111。于是概率理论分布如表5.8所示。
表5.8 4个钱币出现正面的概率理论分布
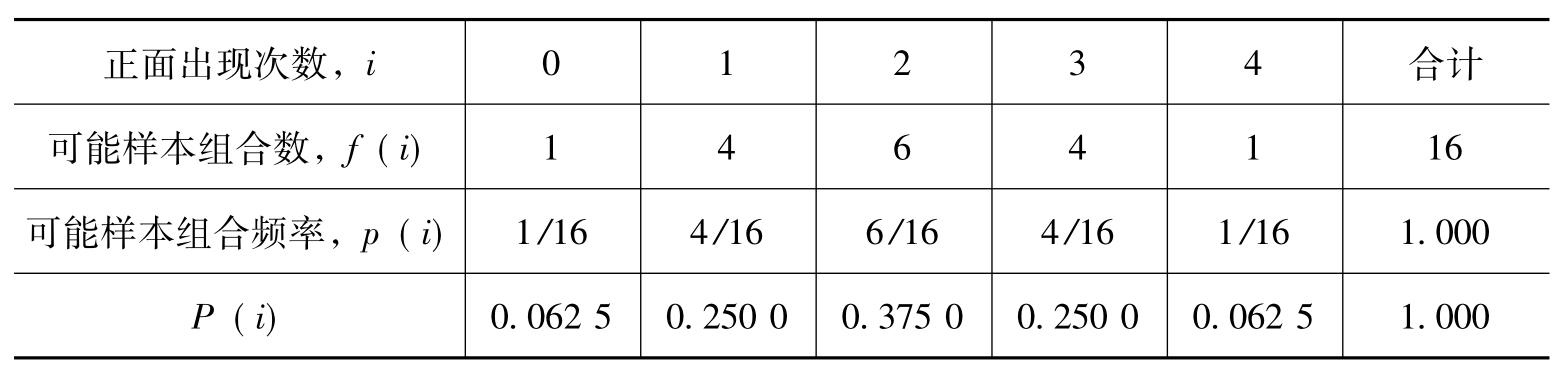
由此可见,概率是一种可能性。4个钱币出现2个正面的概率为37.5%,出现1~3个正面的概率为87.5%。以上是表格形式,实际上,其服从二项分布,可用如下函数表示:
p(i)=C4i(0.5)i(0.5)4.i=C4i(0.5)4=C4i/16(0≤i≤4)
其中Cnm为组合,Cnm=n!/(m!*(n-m)!),其中n>m,m!表示m的全排列。
m!=m*(m-1)*(m-2)*(m-3)……3*2*1
如C42=4!/(2!*(4.2)!)=4!/(2!*2!)=6而若以为i横坐标,p(i)为纵坐标就可获得如图5.2所示。
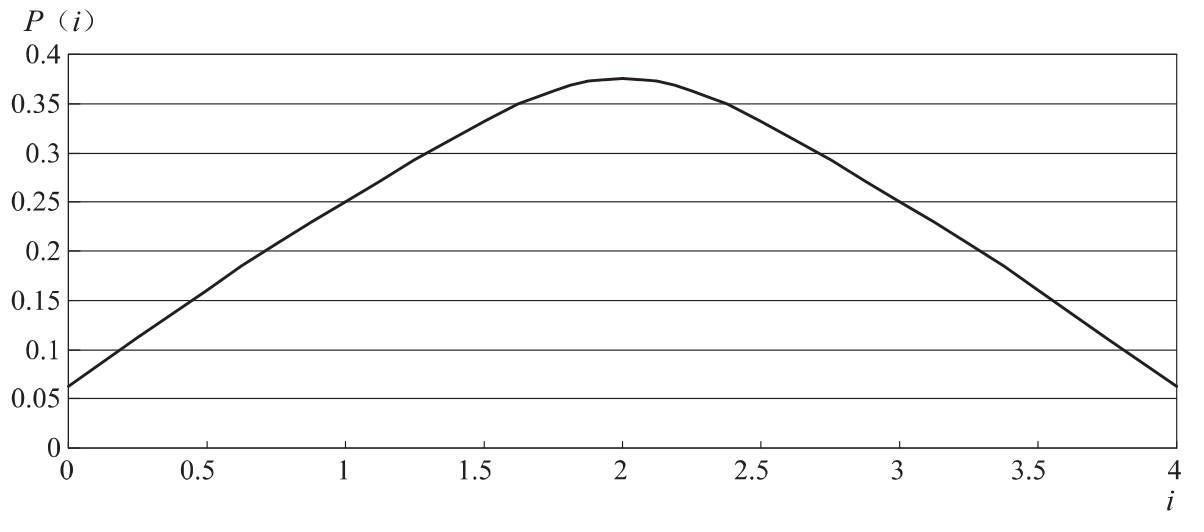
图5.2 概率图形表示形式
[例5.20]掷两颗六面体骰子的试验,点数之和i是随机现象,其最小为2、最大为12,共有11种结果:2,3,4,5,6,7,8,9,10,11,12,其对应出现的概率p(i)如表5.9所示:
表5.9 两颗骰子点数之和的概率表格表示形式

由此可见,2颗骰子点数之和i为6~8的概率为44.4%,i为10以上的概率为16.7%。以上是表格表示,下面是图形表示(如图5.3所示)。
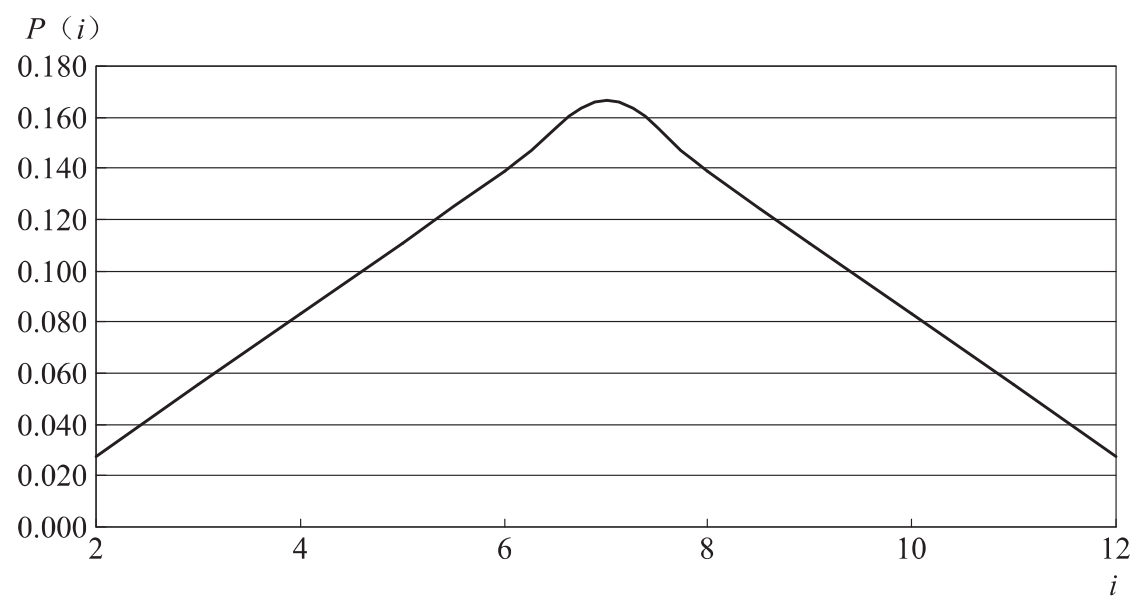
图5.3 两颗骰子点数之和的概率图形表示形式
2.特征值
离散型随机变量X的特征值是指随机变量X的期望值、方差等。
(1)期望值: μ=E(X)=∑xip(xi) (5.9)
随机变量的期望值即其平均位,是随机变量分布的集中趋势,即分布的中心位置。容易验证期望值满足性质:E(αX1+βX2)=αE(X1)+βE(X2),其中X1,X2都是随机变量,α,β是任意常数。并且这个性质可推广到多个随机变量情形。
在[例5.19]中,μ=∑xip(xi)=0*1/16+1*4/16+2*6/16+3*4/ 16+4*1/16=2,即如果一次抛4个钱币,平均可出现2个正面的钱币。
(2)方差:σ2=Var(X)=E(x-μ)2=∑(xi-μ)2*p(xi) (5.10)
方差的平方根,称为标准差,方差σ2或标准差σ反映随机变量X对其期望值的离散程度,σ2或σ越小,说明期望值的代表性越好;σ2或σ越大,说明期望值的代表性越差,也容易验证。对于任意的α,σ2(αX)=α2*σ2(X)成立。
在[例5.19]中,σ2=∑(xi-μ)2*p(xi)=22/16+1*4/16+0+1*4/ 16+22*1/16=1
读者能否计算一下,在[例5.20]中μ和σ2分别是什么。
3.离散型随机变量的概率分布
离散型随机变量的概率分布,主要研究均匀分布、二点分布、二项分布、超几何分布和泊松分布情况下的随机变量概率分布形式及其参数(均值、方差等)表示。
(1)两点分布
如果随机变量仅能取0和1值,取1的概率为ρ,取0的概率为1-ρ,则称X服从两点分布或0-1分布,ρ是X的参数。如果将随机事件的所有结果分为对立的两类,成功事件和失败事件。成功的概率为ρ,而不成功事件1-ρ。若用随机变量X来描述这种随机试验的结果,把“成功”事件记作1,把“失败”记作0,那么,X服从参数为ρ的两点分布。
[例5.21]已知某100件产品中有次品15件。现从中任抽一件,写出抽中成品或次品分布列。
解:用随机变量X表示抽取结果。若结果是正品记作X=1,若结果为次品记X=0。分布列如表5.10所示:
表5.10 二点分布表

该分布的数字特征如下:数学期望E(X)=ρ,方差V(X)=ρ(1-ρ)
(2)二项分布
在一些问题中,人们仅对试验中某事件A是否发生有兴趣,如果A发生,常称“成功”,否则称“失败”。这种只有两种结果的试验称为贝努里试验。设A出现的概率为p、不出现概率为1-p;重复进行n次贝努里试验,称为n重贝努里试验,或称二项分布。
二项分布(贝努里试验)必须满足如下四个基本条件:①仅有两个互斥的结果;②每次试验成功的概率不变;③每次试验相互独立,即任何一次试验结果都不会对另外一次试验结果有影响;④重复试验的次数固定不变。
以Bk表示n重贝努里试验中,事件A出现k次的事件,则b(k;n,p)表示试验n次后,事件A出现k次的概率:
b(k;n,p)=Cnkpk(1-p)n-k(k=0,1,2,3……,n) (5.11)
由于该公式仅依赖于k,n,p三个参数,故也简化记录为P(Bk)。二项分布的数学期望为E(x)=n*p
二项分布的方差为:σ2=Var(x)=n*p*(1-p)
二项分布的偏态系数为: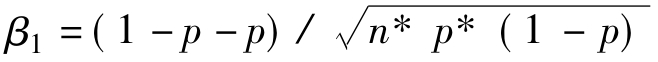
二项分布的峰态系数为:β2=3+[1-6*p*(1-p)]/[n*p*(1-p)]
[例5.22]设想一个盒子内有10个球,6个红球4个白球,现随机抽取1个球看一下,然后放回原盒子,连续进行三次试验(抽取),问出现2个红球的概率是多少?
这是一个典型的二项分布问题。仅有两个互斥的结果,红球与非红球;因为抽取后放回,抽样概率不变(出现红球的概率p=0.6;出现白球的概率为1-p=0.4);本次抽样结果不影响下一次抽样;抽样次数固定,本例为n=3; k=2。
故实际上是求:P(B2)=b(k;n,p)=b(2;3,0.6)=C32(0.6)2(0.4)1=0.432
类似可以求出b(0;3,0.6)=0.064;b(1;3,0.6)=0.288;b(3;3,0.6)=0.216
即抽样中出现0、1、2、3个红球的概率分别是0.064、0.288、0.432和0.216,合计为100%。
常用B(k;n,p)表示二项分布的递增累计概率,F(x)=B(k;n,p)= P(x≤k)=∑Cnkpk(1-p)n-k
如在上例中:
B(1;3,0.6)=b(0;3,0.6)+b(1;3,0.6)=0.352;
B(2;3,0.6)=B(1;3,0.6)+b(2;3,0.6)=0.352+0.432=0.784;
即出现1个及以下红球的概率为0.352,而出现2个及以下红球的概率为0.784。
显然,n重贝努里试验中事件A出现的次数A是个随机变量,其取值范围是从0到n。其分布如表5.11所示。
表5.11 二项分布表

由于式(5.11)是二项展开式的通项,故该分布称为二项分布。
[例5.23]某地区家庭中有老年人口家庭占15%,现在该地区有放回地进行随机抽取10户进行调查,问老年人口家庭在3户以内的概率,老年人口家庭恰好为3户的概率,老年人口家庭为3~5户的概率,老年人口家庭超过4户的概率。
P(x≤3)=B(3;10,0.15)=∑C10k(0.15)k(0.85)10-k=0.95(K=0、1、2、3)
P(x=3)=b(3;10,0.15)=C103(0.15)3(0.85)10-3=0.1298
P(3≤x≤5)=P(x≤5)-P(x≤2)=B(5;10,0.15)-B(2;10,0.15)= 0.9986-0.8202=0.1784
P(x>4)=1-P(x≤4)=1-B(4;10,0.15)=1-∑C10k(0.15)k(0.85)10-k= 1-0.9901=0.0099
若使用计算机Excel软件,则可用函数BINOMDIST(k,n,p,0)就可以求得b(k;n,p)。在上面公式中若将其中0改为1,则可以求得B(k;n,p)或F(x),请尝试计算。
实际上,样本抽样都是一次抽多少样本,都是无放回的。如果是无放回地进行随机抽样,那么其概率就不服从二项分布,而是服从超几何分布。
(3)超几何分布
超几何分布的出现概率常用古典概率方法来求。
[例5.24]和例5.22类似,设一个盒子内有10个球,6个红球4个白球,现随机无放回地抽取3个球,问出现2个红球的概率是多少?
P(x=3)=C62*C41/C103=15*4/120=0.5
一般情况下,如果有限总体单位数为N,其中有某特征(比如红球)的单位数为m,对这个总体进行n次不放回的简单不放回随机抽样(或一次抽n个样本),其中具有某特征的单位数为k的概率为:
![]()
若使用Excel软件,则可以用函数Hypgeomdist(k,n,m,N)就可以求得P(x=k)的具体数值。比如是Hypgeomdist(2,3,6,10)=0.5,请尝试一下。
超几何分布的数学期望为E(x)=n*p=n*(m/N)(其中:p=m/N)
超几何分布的方差为:σ2=Var(x)=n*p*(1-p)*[(N-n)/(N-1)]
其中(N-n)/(N-1)是有限总体校正因子,当采用不重复抽样时才应该考虑,因此又称不重复抽样校正因子。
二、连续型随机变量的概率分布
对于连续型随机变量X,它的取值不能一一列出,因此其概率分布形式不能同离散型随机变量一样,通过表格方式全部表现出来。但是,对任意的实数x,由随机变量的定义知,X<x是一随机事件,可以对它求概率,记为F(x)=p(X<x),该函数就是随机变量的分布函数。分布函数的导数称为密度函数,记作p(x)。通过对密度函数积分,可得到随机变量X在点x附近或在一个区间上取值的概率。注意,连续型随机变量在某固定值的概率为0。
连续型随机变量的密度函数有以下的性质:
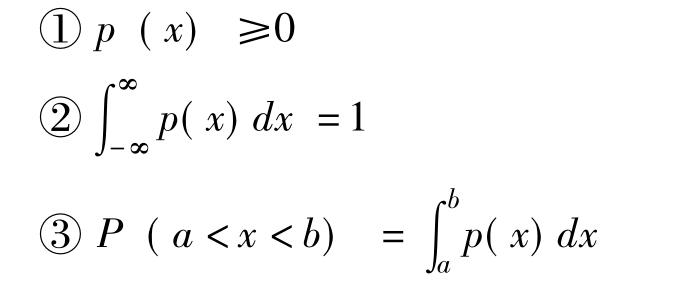
其中,P(a<x<b)表示事件a<x<b,即随机变量x的取值落在区间(a,b)内的概率。连续型随机变量在(a,b)区间上定积分的几何意义就是由x轴、被积函数p(x)、直线x=a和x=b所围成的面积,如图5.1所示。可以验证,对连续型随机变量,E(αX1+βX2)=αE(X1)+βE(X2)和σ2(αx)=α2*σ2(X)也都成立。
正态分布是最重要的连续型随机变量分布,原因有三:第一,它是最常见的一种分布,许多随机变量服从或近似服从正态分布。如同龄人的身高、体重,农作物的产量和学生考试的成绩等等;第二,许多有用的分布可以由正态分布推导出来,如卡方分布、t分布和F分布都可出正态分布导出;第三,正态分布在一定条件下,还是一些其他的近似分布,如大样本下的t分布与正态分布近似。
连续型随机变量x的密度函数为
![]()
则称随机变量X服从均值为μ,方差为σ2的正态分布,记为X~N(μ,σ2)。正态分布的密度函数图形一般称为正态曲线,它是—条以均值为中心的对称钟型曲线,如图5.4所示。
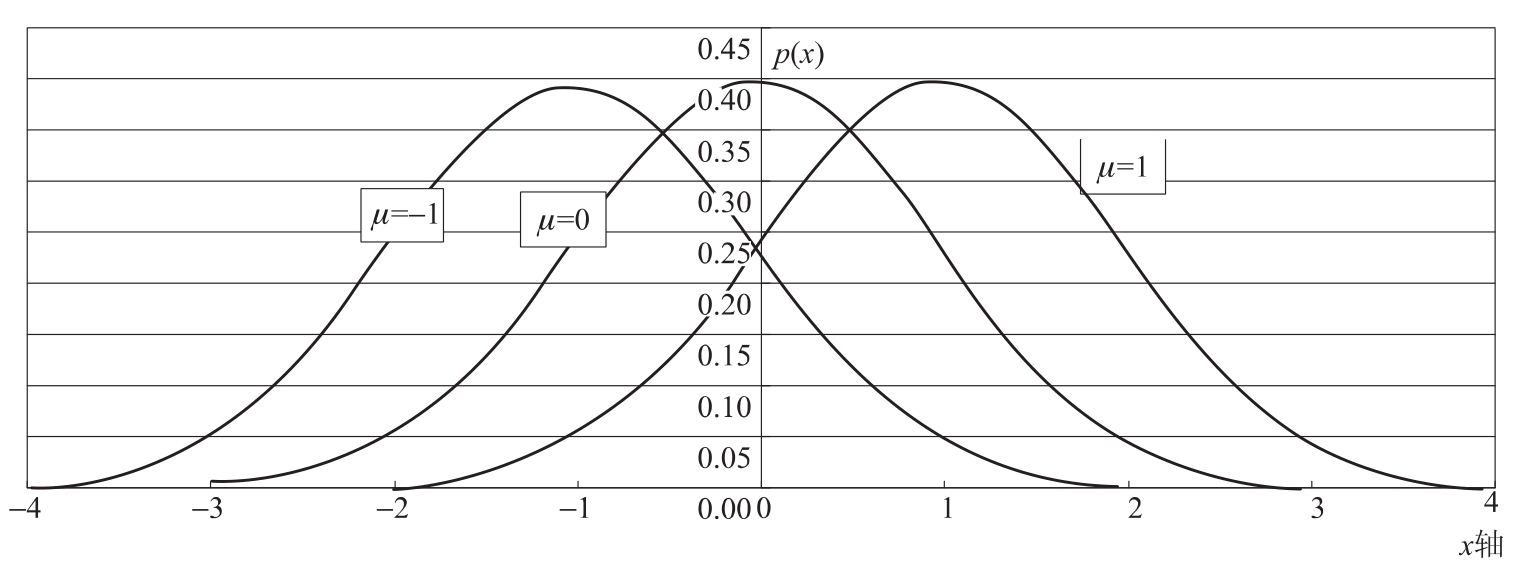
图5.4 不同均值情况下的正态概率分布图
连续型随机变量x的期望值为: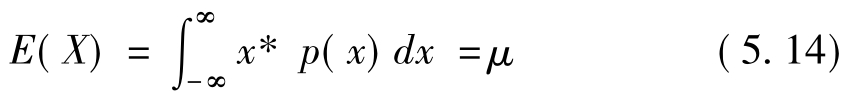
方差为: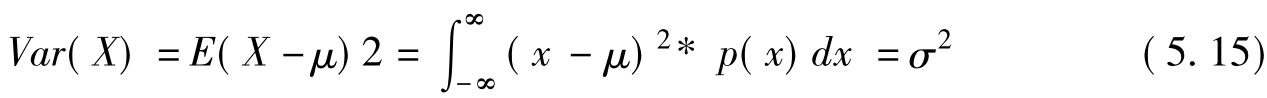
从图5.5可看到,μ是该分布的中心,σ2是标准差,反映分布的离散程度,σ越大,分布曲线越平缓,离散程度越大;σ越小,分布曲线越陡峭,说明分布越集中。标准正态分布的偏态系数、峰态系数分别为0和3。
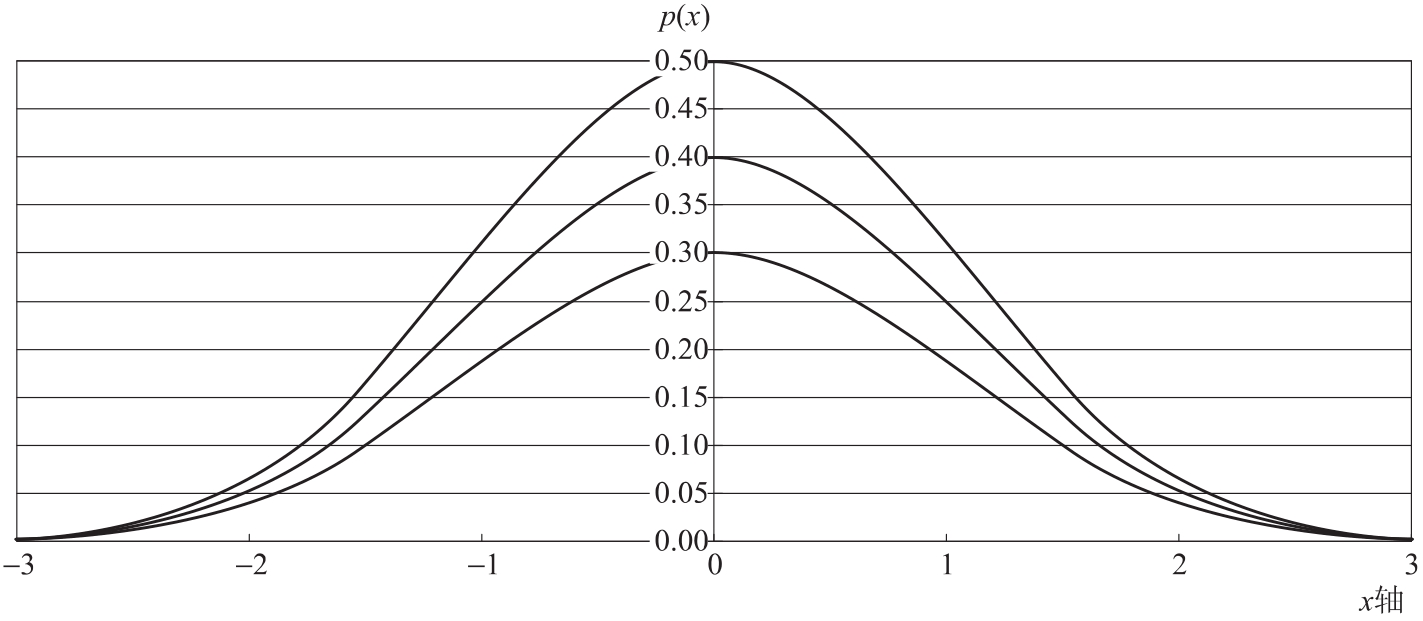
图5.5 不同标准差情况下的正态概率分布图
如果一个正态分布的μ=0,σ=1,则称该正态分布为标准正态分布,相应的随机变量称为标准正态随机变量,用Z表示,即Z~N(0,1),与(5.13)式相应的分布密度函数为:
![]()
标准正态随机变量在区间[-Z,Z]取值的概率F(Z),可通过查标准正态分布概率表获得。
正态分布在统计学应用中或者统计推断中占有非常重要的地位,这是因为许多客观现象的分布大多服从两端小中间大的正态分布,如成人身高、体重、儿童智力、误差分布等;其次,正态分布可以作为一些离散型随机变量概率分布的近似,如二项分布、泊松分布和超几何分布等当n增大时,可以转换为正态分布计算;许多大样本的抽样分布通常以正态分布作为极限,以便进行统计推断。
[例5.25]设随机变量Z服从标准正态分布,求以下分布中概率的大小。
①p(-1<Z<1);②p(0<Z<1.25);③p(1<Z<1.25);④p(Z>1)。
解:①概率p(-1<Z<1)是由标准正态分布的密度函数,在区间(-1,1)上的曲边梯形的面积,如图5.l所示,由于关于Z=0的对称性,该概率(或该面积)可直接Z=1查表得到:
p(-1<Z<1)=2*(0<Z<1)=2*0.3413=0.6826
②由标准正态分布关于Z=0的对称性可知,p(0<Z<1.25),按临界值Z=1.25查表得,
p(0<Z<1.25)=0.3944
③由对称性与面积的分割关系可知: p(1<Z<1.25)=p(0<Z<1.25)-p(0<Z<1)]=0.3944-0.3413=0.0531
④由于标准正态分布密度函数曲线下的面积为1,所以: p(Z>1)=1-p(0<Z<1)-p(-∞<Z<0)=1-0.3413-0.5=0.1587
可以验证,若随机变量x服从正态分布N(μ,σ2),则随机变量z=(X-μ)/σ服从标准正态分布,即z~N(0,1)。
注意:任何正态分布都可以通过z=(x-μ)/σ变换,转变为标准化正态分布。利用这个变换来计算非标准正态分布的概率,计算或查算出随机变量取值落于任何区间的概率。然而统计教材上应用标准正态概率查算表时注意,是从0到x的区间概率、从-∞到x区间的概率还是从-x到x的概率,当然其之间是可以换算的。本文建议采用第一种。
[例5.26]假定学生某门学科的考试成绩服从均值为70分、标准差为12分的正态分布。那么某一学生的成绩在70分到85分之间的概率应为多少?
解:设x表示学生的成绩,要计算的概率是p(70<x<85)。首先对X进行标准化:
Z=(X-70)/12
将计算X的概率转化为计算Z的概率:
p(70<x<85)=p((70-70)/12<(x-70)/12<(85-70)/12)
=p(0<Z<1.25)=0.3944
即如果某班60个学生,将有24个同学成绩在70~85分之间。
[例5.27]设随机变量X服从正态分布N(μ,σ2),试分别求X落在以μ为中心。以σ,2σ,1.96σ和3σ为半径的区间内的概率。
解:作变换z=(x-μ)/σ,则Z服从标准正态分布。所求概率分别为:
p(μ-σ<X<μ+σ)=p[(μ-σ-μ)/σ<(X-μ)/σ<(μ+σ-μ)/σ]=p(-1<Z<1)=2*0.3413=68.26%
p(μ-1.96σ<X<μ+1.96σ)=p[(μ-1.96σ-μ)/σ<(X-μ)/σ<(μ+ 1.96σ-μ)/σ]=p(-1.96<Z<1.96)=95%
p(μ-2σ<X<μ+2σ)=p[(μ-2σ-μ)/σ<(X-μ)/σ<(μ+2σ-μ)/σ]=p(-2<Z<2)=95.45%
p(μ-3σ<X<μ+3σ)=p[(μ-3σ-μ)/σ<(X-μ)/σ<(μ+3σ-μ)/σ]=p(-3<Z<3)=99.73%
从计算结果可知:随机变量X落在以μ为中心,以3σ为半径的区间外的概率只有l-99.73%=0.27%,是一个非常小的概率。一般可以认为X不会落到以μ为中心,以3σ为半径的区间之外,这就是所谓的“3σ原则”。
除正态分布外,常用的连续型随机变量的分布还有卡方分布(或称χ2-分布)、t-分布和F-分布。由于篇幅原因,这里从略。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。










