



4.2 汉英双语者家族词汇行为实验与语码转换
4.2.1 研究背景
词汇辨认能力是指阅读或朗读词汇的能力,通常指通过视觉和听觉辨认词汇的能力。词汇判断任务(lexical decision task)广泛应用于心理语言学领域。词汇判断任务不仅涉及词汇识别,而且涉及真词和假词的区分,而真词和假词的区分需要考虑词频/熟悉度,以及刺激的意义等因素(Balota &Chumbley,1984)。视觉词汇判断的一个重要方面就是家族词汇对阅读和词汇判断任务的影响(Perea,et al.,2003;Ferraro &Hansen,2002)。许多研究人员认为,一个词汇的视觉表征(如:horse)会部分激活拼写类似的词汇,也就是通常所说的家族词汇(如:worse,gorse,house或horde),并影响词汇提取(Andrews,1997;Grainger &Jacobs,1996;Pollatsek,et al.,1999)。关于家族词汇的一个广为接受的定义是:在保留单词的字母的具体位置的情况下,改变词汇中的一个字母(Coltheart,et al.,1977)。因此,一个词汇的家族就是指该词汇临近的词,而家族词汇密度(neighborhood size)就是指临近的词的数目。
在拼音文字系统中,许多研究都集中在家族词汇的语音(听觉)和字/词形(视觉)效应。这些研究使用不同的实验范式,如词汇判断任务、渐近解蔽实验(progressive demasking experiment);不同的刺激材料,如词频组块(word frequency blocking)、家族词汇密度/频率组块(neighborhood density/frequency blocking)以及真词/假词组块(word/nonword blocking);被试的不同母语和目标语,如意大利语、法语、西班牙语、荷兰语及英语;被试的不同反应要求,如yes/no和go/no-go词汇判断任务。基于实验数据的分析,一些学者提出了大脑词库储存和加工语言的认知模型。在一系列的词汇判断任务和渐近解蔽实验中,van Heuven等人(1998)通过研究得出结论:一种语言目标词的再辨认受到双语者的两种语言家族词汇词形的影响。
在国内,许多专家也做了关于词汇辨认和家族效应的研究。桂诗春(2000)研究了词汇辨认过程英语大脑词库和汉语大脑词库之间的关系,他还做了有关中国学生词汇提取解码方面的研究。毕鸿燕等人(2006)用快速命名的实验范式,对汉字形声字声旁家族大小对整字语音通达的影响进行了研究。结果发现汉字阅读中也存在家族效应,但是与拼音文字正好相反,声旁家族越大,反应时越长,在不规则汉字阅读中表现更为明显,显示了汉语语音通达有别于拼音文字的特殊性。然而,对汉英双语者家族词汇的研究还很有限,特别是实证研究。
以前的研究表明,不同的实验范式会导致不同的家族密度效应。感知识别范式(perceptual identification paradigm)主要说明家族密度的抑制效应(Grainger &Jacobs,1996;Carreiras,et al.,1997),Snodgrass和Mintzer(1993)的分散任务范式(fragmentation task paradigm)也得出了同样的结果。与此相反,Andrews(1989;1992)在单语的词汇判断任务中发现了促进效应。Van Heuven等(1998)也得出了家族词汇判断任务中的促进效应。此外,Van Heuven等还通过提供一些家族密度通常要比渐近解蔽实验中的家族密度小的刺激,特别是荷兰语的刺激,进一步讨论了跨文化冲突实验中任务依赖性(task dependence)的因素。Carreiras等(1997)也做了类似的任务依赖实验,结果表明,就单语者而言,家族密度效应在渐近解蔽实验中表现为抑制趋势,在词汇判断任务中表现为微不足道的促进趋势,在词汇命名任务中表现为强烈的促进趋势。
在视觉词汇辨认任务中,与任务的难易程度相关的变量经常体现在书面语语料库中的词频上:与低频(low frequency,LF)词相比,对高频(high frequency,HF)词判断的速度更快,正确率更高。随着HF词数量的增加,加工早期产生的词汇活动总量也会增加(Snodgrass &Mintzer,1993)。对HF词而言,也出现了家族密度的抑制效应(Van Heuven,et al.,1998;Carreiras,et al.,1997;Perea,et al.,2004)。然而,Andrews发现,更高频率(Higher Frequency)的词汇并不受家族密度的影响(Andrews,1989;Andrews,1992)。Perea等(2004)发现,家族密度效应只出现在LF词中,而不出现在HF词中。大量研究人员发现了LF词中的促进效应(Pollatsek,et al.,1999;Andrews,1989;Siakaluk,et al.,2002),而其他研究人员发现了HF词的抑制效应(Perea,et al.,2004;Perea &Rosa,2002)。
假词是在不违反音位配列规则或拼写规则的情况下,通过改变英文单词中的一个字母而形成的词汇,例如:aunt和aunk,而二元模型用来保证包括唯一的组合。在词汇判断实验中,对词汇的积极和消极的反应都会受到家族词汇特征的影响(Coltheart,et al.,1977;Carreiras,et al.,1997;Andrews,1989;Andrews,1992;Sears,et al.,1995)。就假词而言,Van Heuven等(1998)发现L1(英语)被试和双语(英语和荷兰语)被试表现出来的结果:随着假词的家族密度的提高,反应时相应降低。而且,Van Heuven等认为,双语者的母语而不是L2对假词产生了很大的影响。本实验使用假词作为实验刺激来探讨中国的英语学习者对英语假词的辨认。
L2熟练程度直接影响L2词汇及其意思在大脑中的提取、加工和表征。一系列的心理语言学行为研究回答了这一问题:即,语言熟练程度如何影响形式、概念和词汇在大脑词库中的联系(Bijeljacbabic,et al.,1997;Chen,1990;Cheung &Chen,1998;Dufour &Kroll,1995;Gascoigne,2001;Kawakami,1994;Woutersen,et al.,1995)。在拼音文字系统中,许多研究人员针对不同的实验方法、被试的母语以及研究重点等做了大量研究。Van Heuven设计了行为实验以研究L2熟练程度。两组被试的母语均是荷兰语,L2是英语,组间的差异是英语的熟练程度。在渐近解蔽实验范式下,被试需要快速、准确地辨认屏幕上出现的单词。然而,很少的实验研究汉英双语者的L2熟练程度和家族词汇辨认之间的相关性。本实验的一个目的是研究汉英双语者的L2熟练程度、性别、家族密度、词频以及字/词形等因素之间的相关性,以说明双语者在加工家族词汇中语码转换的认知规律。
综上所述,本实验旨在回答以下几个问题:
(1)在词形方面,中国L2学习者在完成词汇判断任务时有哪些家族词汇效应,包括大家族(high neighborhood,HN)和小家族(low neighborhood,LN)效应?词频效应,包括HF、中词频(mediumfrequency,MF)和LF效应?真词/假词效应?
(2)汉英双语者(母语为汉语)和Van Heuven等所做的关于荷兰语-英语双语者(荷兰语为母语)在完成词汇判断任务时的表现有什么差异?
(3)家族密度(HN/LN)、词频(HF/MF/LF)、真词/假词因素如何影响汉英双语者的英语词汇辨认?
(4)与荷兰语-英语双语者的促进效应相比,对于汉英双语者来说,家族密度会产生促进效应,还是抑制效应?
(5)词频对于汉英双语者的英语词汇辨认会产生促进效应,还是抑制效应?这些效应与先前的研究有什么相同和不同之处?
(6)家族密度、词频、真词/假词因素三个因素之间是否相互联系?与拼音文字的语言有什么不同之处?
(7)在家族词汇增加的情况下,荷兰语-英语双语者需要花费更长的时间去排除假词,这种现象对于汉英双语者来说是否同样存在?
4.2.2 实验设计
4.2.2.1 被试
来自大连理工大学不同专业的硕士研究生(汉英双语者)参与了本实验,母语都是汉语,其中113名非英语专业学生和36名英语专业学生。除了推荐免试的研究生外,被试都通过了全国硕士研究生入学英语考试(Postgraduate Entrance English Examination,PEEE)。英语专业的研究生都通过了英语专业八级(English Majors Band 8,TEM8),非英语专业的研究生都通过了大学英语四级考试(College English Test Band 4,CET4)。所有被试都没有阅读和表达障碍,视力正常或矫正正常。实验前,所有被试先完成关于英语水平(PEEE,TEM4/8,CET4/6)和个人信息(专业、年龄、性别、利手等)的问卷。
4.2.2.2 实验材料
本实验采用3种变量:词形家族密度、词频和真词/假词。本试验的词频根据词汇数据库中的词频。被试的刺激词选自Van Heuven等实验中采用的刺激b。首先,从CELEX中选取4个字母的单词。选词的使用频率至少是2 o.p.m.(occurrences per million),只有名词、动词、形容词和副词(Baayen,et al.,1993)。对于每个目标词的家族词汇的数量都进行了统计。通过调整家族词汇的数量,把家族词汇分成两大类:HN和LN。每一类都有40个刺激词,大多是名词和形容词。此外,通过布朗语料库(Brown Corpus)中的Wordsmith Tools统计每一个刺激词的词频。布朗语料库是第一个使用电脑阅读的大型语料库,由美国布朗大学(Brown University)的两位教授Francis及Kucera所开发。该语料库包括了1961年的100万字的美国英语。稍后的LOB语料库(英国英语)和Kolhapur语料库(印度英语)都是按照Brown Corpus的格式制作的。统计出的词频分成三类:LF(低于20 o.p.m.)、MF(20 o.p.m.和50 o.p.m.之间)、HF(高于50 o.p.m.)。这80个刺激词,对应着80个假词。假词也分成两组:HN组和LN组。完整的刺激列表见附录C。
4.2.2.3 实验程序
实验设计是组块设计。每个组块包括160个刺激,其中80个真词(40个HN和40 LN)和80个假词(40个HN和40个LN)。每80个词分成HF、MF和LF3组。实验采用2×3×2的设计模式。每一个组块包括8个练习刺激和152个实验刺激,每一个组块中的刺激随机呈现。
实验刺激的呈现和反应时(reaction time,RTs)通过装有E-Prime软件的笔记本电脑记录。E-Prime是实现心理学实验计算机化的一个可视化编程语言平台,是一个涵盖实验生成到毫秒精度的数据收集分析的应用软件套装。其功能为:实验设计、生成、运行、收集数据、编辑和预处理分析数据。呈现的刺激可以是文本、图像和声音,也可以同时呈现三者的任意组合。E-Prime可以提供详细的时间信息和事件细节,包括呈现时间、反应时间的细节,可供进一步分析,有助于了解实际实验运行的时间问题。E-Prime包括了以下几部分:E-Studio图形化界面的编程环境、E-Basic script式语言、E-Run实时生成实验程序、E-Merge数据融合、E-Data Aid表格式数据处理。RTs的测量通过按鼠标的左/右键反应记录。单词以Courier18号字体出现在计算机屏幕的中央,字体为黑色,背景为白色。被试独立完成测试。实验之前,被试需要正确地理解指导语:“您将看到一系列的字母串依次出现在屏幕上,请尽可能准确、快速地判断这些字母串是否为真词。真词按鼠标左键,假词按鼠标右键。”被试理解了指导语之后,将有8次练习。练习之后,被试再阅读一遍指导语,并按空格键开始实验。152个刺激随机出现。每一个刺激呈现之前,在屏幕中央都会出现“+”号,500ms之后,“+”号消失,下一个刺激出现。被试按鼠标键反应,但反应时间不超过2000ms,否则认为反应错误。两个刺激之间的间隔为500ms。
4.2.3 实验结果
根据被试的L2熟练程度,正确率高于60%的数据为有效数据,低于60%(8人)的数据为无效数据。8个无效数据均为非英语专业的被试,因此,有效数据为141个,其中36个为英语专业,105个为非英语专业。所有行为数据分析都是通过SPSS 13.0统计软件进行的。通过方差分析(analyses of variance,ANOVA)来测量被试间两因素(HP/LP,H/M/LF)和被试间三因素(H/L N,H/M/L F,真词/假词)的平均RTs、基于判断正确时的平均反应时(ACCRTs)和平均正确率(ACC)。
为了考察L2熟练程度的影响,把被试分成两组:36个英语专业研究生为HP组,36个非英语专业研究生为LP组(随机从105名非英语专业研究生中选取)。另外,根据105名非英语专业研究生的研究生入学考试,被试分成两组,其中51人为HP组,54人为LP组。此外,为考察性别差异,被试分成两组,58名男性,47名女性。实验结果对反应时和正确率进行分析。
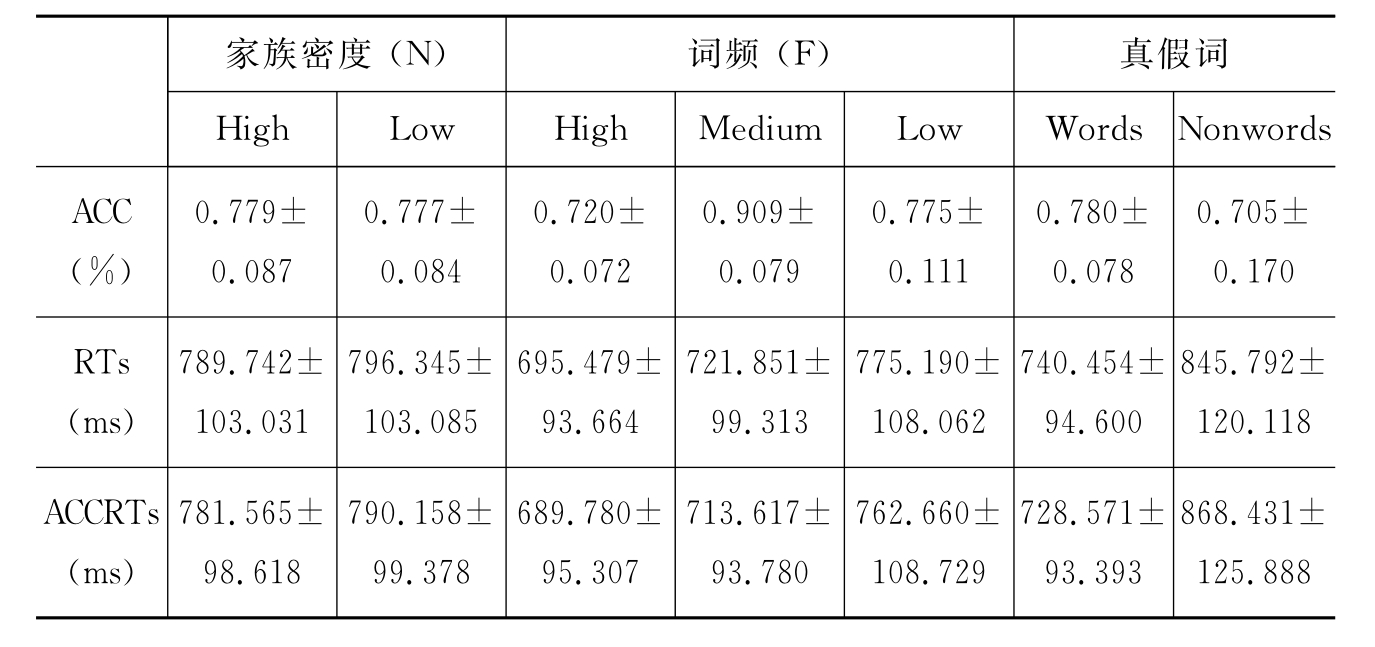
HN词汇和LN词汇的RTs数据差异不显著(p=0.075),但是,如下表所示,对于LN词汇的反应要比HN词汇的反应需要更长的时间;对于HN词汇和LN词汇,反应正确时,反应时间数据差异显著(p<0.05),LN词汇的RTs数据要显著大于HN词汇。就RTs数据和ACCRTs而言,家族效应在汉英双语者中表现出促进趋势,家族越大反应越快。另外,ACCRTs数据在HF、MF和LF词汇中,也存在显著性差异[F(2,357)=16.980,p<0.001]。就ACCRTs而言,词频效应在汉英双语者中也表现出促进趋势,频率越高,反应时越小。在真词/假词判断任务中,从汉英双语者的RTs和ACCRTs数据来看,判断真词的速度要显著高于假词(p<0.001)(见表4.5)。
表4.5 三因素的平均RT、ACCRT和ACC数据
1)RTs数据
(1)L2熟练程度(英语专业和非英语专业)和三因素之间的关系
英语专业(HP)和非英语专业(LP)之间的RTs数据不存在显著差异[F(1,70)=2.416,p=0.125],相对于LP组被试,HP组被试的RTs没有显著性优势。
L2熟练程度和N(H/L)之间的关系:在HP组和LP组之间,对于HN和LN因素的反应时数据不存在显著差异[F(1,70)=2.998,p=0.088;F(1,70)=1.801,p=0.184]。对于HN和LN词汇的反应,HP组被试的RTs没有显著性优势。
L2熟练程度和F(H/M/L)之间的关系:HF、MF和LF在HP组和LP组之间不存在显著差异[F(1,70)=1.212,p=0.275;F(1,70)=1.218,p=0.274;F(1,70)=0.783,p=0.379]。对于HF/MF/LF词汇的反应,HP组被试的RTs没有显著性优势。
L2熟练程度和真词/假词之间的关系:真词和假词在HP组和LP组之间不存在显著差异[F(1,70)=1.143,p=0.289;F(1,70)=3.049,p=0.085]。对于真词和假词的反应,HP组被试的RTs没有显著性优势。
(2)L2熟练程度(非英语专业高分段和低分段)和三因素之间的关系
RTs在非英语专业高分段(HP)和非英语专业低分段(LP)之间不存在显著差异[F(1,85)=0.085,p=0.772];相对于LP组被试,HP组被试的RTs没有显著性优势。
L2熟练程度和N(H/L)之间的关系:HN和LN在HP组和LP组之间不存在显著差异[F(1,85)=0.016,p=0.901;F(1,85)=0.196,p=0.659]。对于HN和LN词汇的反应,HP组被试的RTs没有显著性优势。
L2熟练程度和F(H/M/L)之间的关系:HF、MF和LF在HP组和LP组之间不存在显著差异[F(1,85)=1.268,p=0.263;F(1,85)=0.054,p=0.817;F(1,85)=0.000,p=0.991]。对于HF/MF/LF词汇的反应,HP组被试的RTs没有显著性优势。
L2熟练程度和真词/假词之间的关系:真词和假词在英语专业(HP)和非英语专业(LP)之间不存在显著差异[F(1,85)=0.099,p=0.754;F(1,85)=0.057,p=0.812]。对于真词和假词的反应,HP组被试的RTs没有显著性优势。
(3)三因素的RTs之间的关系
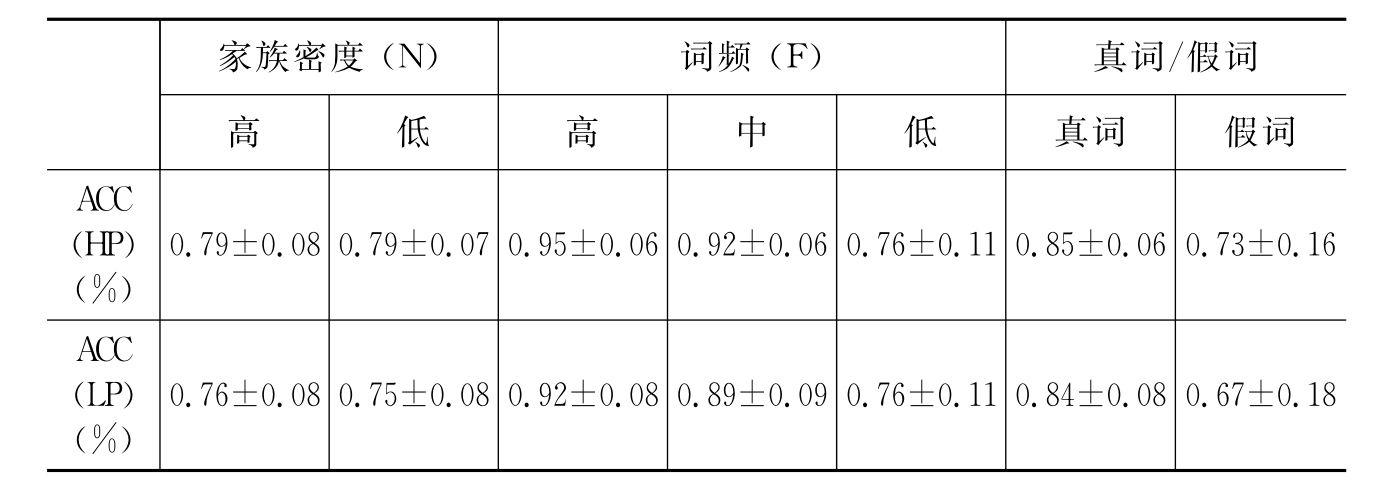
家族效应和词频效应之间的显著性差异比较明显[F(2,238)=9.843,p<0.001],其效应值是0.076。总的来说,HN和HF词汇要比其他情况的词汇辨认速度快。至于HF、MF和LF词汇,对HN词汇的反应时要短(见图4.2)。
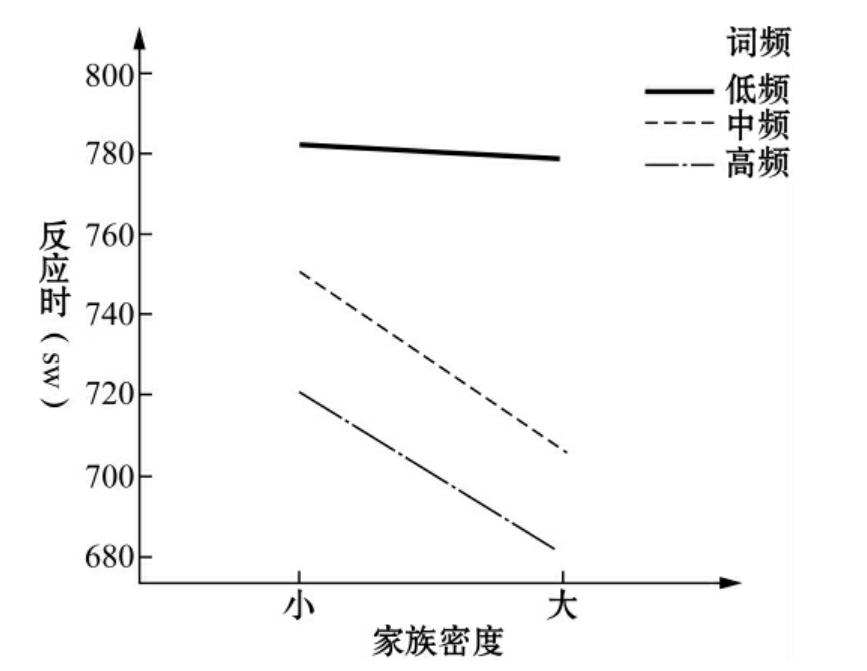
图4.2 家族密度和词频之间的相关性
家族效应和真词/假词之间的显著性差异也比较明显[F(1,119)=48.728,p<0.001],效应值是0.291。LN真词的RTs较短,而HN假词的RTs较短(见图4.3)。
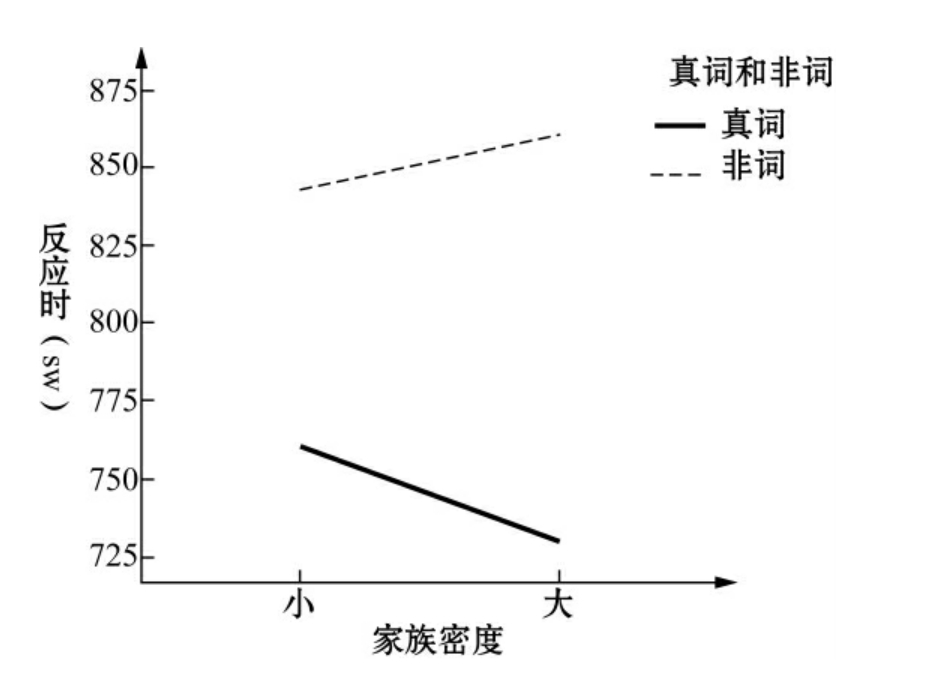
图4.3 家族密度和真词/假词之间的相关性
2)ACCRT数据
正确率数据基于被试间的两因素和被试内的三因素。
(1)L2熟练程度(英语专业和非英语专业)和被试内的三因素之间的关系
正确率在英语专业(HP)和非英语专业(LP)之间存在差异显著[F(1,70)=23.402,p<0.001]。在正确率上,HP组显示出比较大的优势(见表4.6)。
表4.6 L2熟练程度和被试内的三因素之间的关系
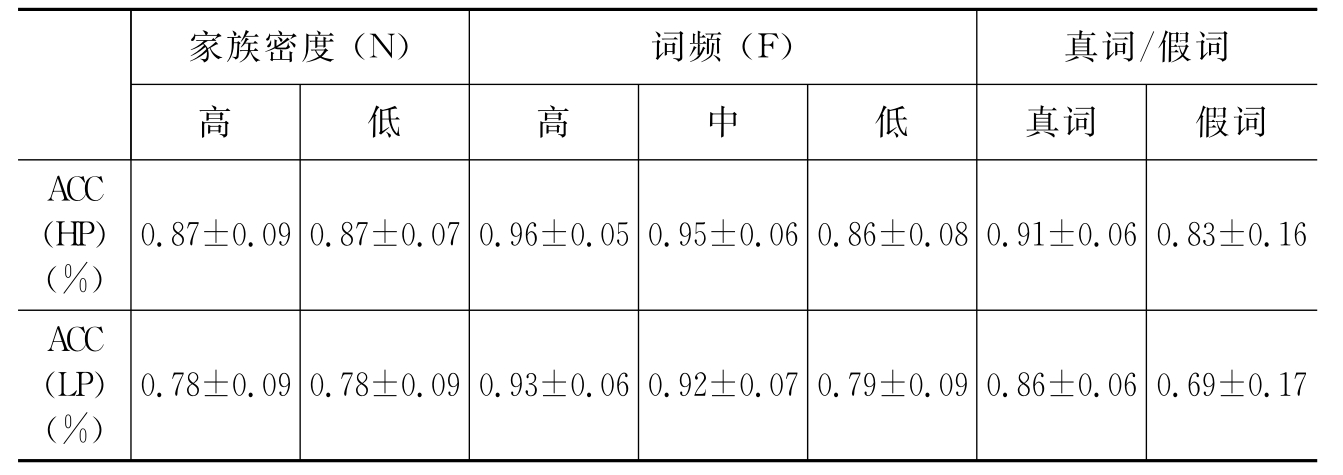
L2熟练程度和N(H/L)之间的关系:HP组和LP组被试对HN和LN词汇均表现出显著性差异[F(1,70)=17.217,p<0.001;F(1,70)=25.143,p<0.001]。在对HN和LN词汇做出反应时,HP组被试的正确率明显高于LP组被试。
L2熟练程度和F(H/M/L)之间的关系:HP组和LP组被试对HF和LF词汇均表现出显著性差异,对MF词汇的差异显著[F(1,70)=4.043,p<0.05;F(1,70)=3.286,p=0.074;F(1,70)=11.712,p=0.001]。在对HF和LF词汇做出反应时,HP组被试的正确率高于LP组被试;对于MF词汇,HP组被试的正确率远远高于LP组被试。
L2熟练程度和真词/假词之间的关系:HP组和LP组被试对真词和假词均表现出显著性差异[F(1,70)=11.960,p=0.001;F(1,70)=11.292,p=0.001]。因此,证据表明,对真词和假词做出反应时,HP组被试的正确率高于LP组被试。
(2)L2熟练程度(非英语专业高分段和低分段)和被试内三因素之间的关系
在非英语专业高分段(HP)和低分段(LP)之间,正确率差异显著。与LP组被试相比,HP组被试在正确率上表现出明显优势(见表4.7)。
表4.7 L2熟练程度与被试内三因素之间的关系
L2熟练程度和N(H/L)之间的关系:在HP组和LP组被试中,LN词汇差异不显著[F(1,85)=2.997;p=0.087],HN词汇差异显著[F(1,85)=6.110,p<0.05]。在对HN和LN词汇做出反应时,HP组被试的正确率明显高于LP被试。
L2熟练程度和F(H/M/L)之间的关系:HF词汇差异显著[F(1,85)=4.687,p<0.05];MF词汇差异不显著[F(1,85)=3.307;p=0.073];LF差异不显著[F(1,85)=0.065,p=0.799]。
L2熟练程度和真词/假词之间的关系:HP组和LP组被试对真词和假词均未表现出显著性差异[F(1,85)=0.705,p=0.404;F(1,85)=2.606,p=0.110]。L2熟练程度在真词/假词之间判断没有显著差异。
(3)性别和三因素之间的关系
RTs在男性和女性之间不存在显著差异[F(1,103)=0.911,p=0.342]。
性别和N(H/L)之间的关系:男性和女性对HN和LN词汇的反应不存在显著差异[F(1,103)=0.338,p=0.562;F(1,103)=1.655,p=0.201]。
L2熟练程度和F(H/M/L)之间的关系:男性和女性对HF、MF和LF词汇的反应不存在显著差异[F(1,103)=0.774,p=0.381;F(1,103)=0.338,p=0.562;F(1,103)=0.220,p=0.640]。
L2熟练程度和真词/假词之间的关系:男性和女性对真词和假词的反应不存在显著差异[F(1,103)=0.397,p=0.530;F(1,103)=1.253,p=0.266]。
(4)三因素之间的ACC数据
ACC数据在真词/假词之间差异显著(p<0.001),真词的ACC高于假词(见表4.5)。
ACC数据表明,家族效应和词频效应之间存在显著性差异[F(2,238)=8.490,p<0.001],其效应值为0.067。对于HN和HF词汇判断的ACC要高于其他词汇的判断。HN和LN词汇相较而言,HF词汇的ACC更高。就HF、MF和LF词汇而言,HN词汇的ACC更高(图4.4)。
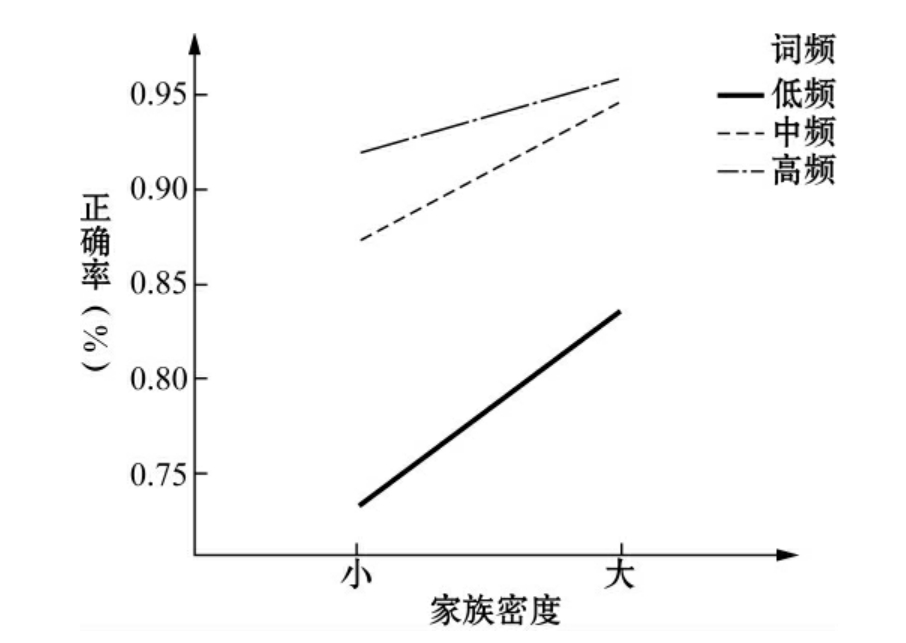
图4.4 家族密度和词频之间的相关性
ACC数据表明,家族效应和真词/假词效应之间存在显著性差异[F(1,119)=276.139,p<0.001],其效应值为0.699。对于HN词汇,真词的ACC更高,而对于LN词汇,假词的ACC更高(图4.5)。
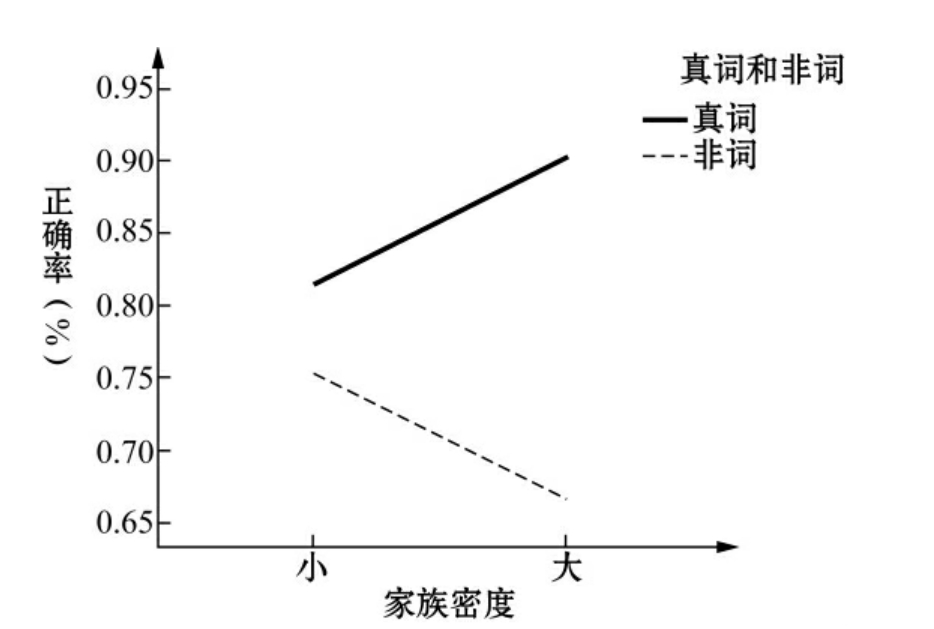
图4.5 家族密度和真词/假词之间的相关性
4.2.4 讨论
研究将从被试间因素(L2熟练程度和性别)和被试内因素(家族效应、词频效应、真词/假词效应)几个方面分别讨论。
4.2.4.1 L2水平(英语专业和非英语专业的被试)与三个被试内变量之间的关系
在对L2水平(英语专业和非英语专业的被试)与三个被试内变量之间交互作用的数据分析,较高L2水平的被试在正确率上表现出优势,在反应时上没有优势。对于家族密度因素来说,较高L2水平的被试对于大、小家族词汇的反应正确率更高。对于词频因素来说,较高L2水平的被试对于高、中、低频词汇的反应正确率也更高。对于真词和假词因素来说,较高L2水平的被试对真词和假词的反应正确率同样更高。因此,在以家族密度、词频、真/假词三因素建立组块的词汇判断实验中,较高的L2水平促进了汉英双语者的词汇辨认。在运用渐隔法的实验中,Van Heuven等人(1998)发现L2水平既没有产生显著的主效应,也没有与家族密度因素产生交互作用,即对L2水平因素的操纵并不十分有效。他们认为,较高L2水平的被试是否能够对大脑词库的相对激活施加一定程度的控制,还需要进一步研究。尽管采用的实验范式不同,本实验的结果同样有助于解释较高L2水平的被试能够对大脑词库的相对激活施加一定程度的控制这一观点。
对于真词和假词因素来说,较高L2水平的汉英双语者在对真词和假词的辨认中也更加准确。在采用相同刺激材料的词汇判断实验中,Van Heuven等人(1998)发现单语被试(以英语为母语)和双语被试(荷英双语者)表现出相同的效应类型,即当非词目标词的英语家族词的数量增加时,反应时也相应增加(抑制效应)。对于单语者和双语者来说,排除大家族的假词要比排除小家族的假词需要花费更长的时间。他们还认为,母语目标词的出现对于双语者的假词判断具有决定性的影响。当双语者运用L2进行听说和阅读时,L1中的信息仍然处于激活状态(Dijkstra &Van Heuven,2002;Jared &Kroll,2001;Marian &Spivey,2003)。在本实验中,较高L2水平的被试能对母语(汉语)的干扰施加更为有效的控制,所以他们能够在对假词的辨认中表现出更高的准确率。这一观点仍需更多定性、定量的研究来加以支撑。
4.2.4.2 L2水平(非英语专业的高分段和低分段)与三个被试内变量之间的关系
在对L2水平(非英语专业的高分段和低分段)与三个被试内变量之间交互作用的数据分析发现,较高L2水平的被试在正确率上表现出优势,在反应时上却没有优势。对于家族密度因素来说,较高L2水平的被试对于大家族词汇的反应更加准确。对于词频因素来说,较高L2水平的被试对于高频词汇的反应也更加准确。然而,较高和较低L2水平的被试对于高、中频词的反应差异边缘显著,对于低频词、真词和假词的反应差异不显著,这一结果反映了两组间L2水平效应的差异。本实验中被试的L2水平有所不同,而且他们均为非完全均衡的双语者。L2水平实验组的第一组由英语专业和非英语专业的学生组成,而第二组则由非英语专业的高分和低分学生组成。两组相比较可以看出,第一组被试之间的L2水平差异更为明显。
从对上述实验数据的分析中可以看出,L2水平的组内和组间差异同时存在。而且数据说明L2水平的差异和对母语干扰的控制程度之间线性相关。特别是,在对假词的判断中这种线性关系仍然存在。对于被试来说,L2水平的差异越大,对于母语干扰的控制能力的差异也越大。
4.2.4.3 性别因素与三个被试内变量之间的关系
在对性别因素与三个被试内变量之间交互作用的数据分析发现,男性和女性被试之间的反应时和正确率均无显著差异。因此,性别差异对汉英双语者的英语词汇判断没有产生显著影响。
4.2.4.4 家族效应、词频效应、真词/假词效应之间的关系
在汉英双语者的英语词汇辨认中,家族词汇因素呈现了促进效应(在RTs和ACCs中)。汉英双语者对大家族词的辨认要快于小家族词,这个发现与以往在拼音文字中对词形家族效应的研究结论相似(Van Heuven,et al.,1998;Perea,et al.,2004)。特别是,在相同的词汇判断实验范式和刺激材料下,家族密度因素对本研究中的汉英双语者和Van Heuven等人(1998)研究中的荷英双语者中均呈现出了促进效应。尽管母语的语系不同,汉英双语者和荷英双语者均受到了家族密度的促进性作用。在以后的研究中,不同母语双语者词汇辨认的心理机制还需要更多定性、定量的研究。
在汉英双语者的英语词汇辨认中词频因素在基于正确率的反应时方面也呈现出了促进效应。被试对较高词频单词的反应更快。这一发现也与以往的研究结果一致(Perea,et al.,2004)。
关于真/假词因素,汉英双语者在词汇辨认过程中对真词的反应要好于假词(反应时快,正确率高)。对于真/假词和家族密度因素交互作用的讨论将在以下因素间的讨论中作进一步分析。
4.2.4.5 家族密度和词频效应之间的关系
由上文可知,在以往的研究中,家族密度对高、中、低频词的辨认产生了不同的效应。对于高频词的辨认,家族密度呈现促进效应,而与此相反的观点是,高频词的辨认不受家族密度的影响。一些研究也发现:家族密度和词频因素间存在着交互作用;对于低频词的辨认,家族密度没有呈现出促进效应,而对于高频词的辨认则呈现出了抑制效应。但对于汉英双语者来说,对大家族的高频词辨认得最快、最准确。无论是大家族词还是小家族词,被试对较高频率的单词辨认得更快、更准确。无论是高、中、低频词,被试对较大家族单词的辨认也同样更快、更准确。因此,家族密度和词频因素在汉英双语者的英语词汇辨认中呈现因素内和因素间的共同促进作用,该发现有别于以往在拼音文字中的研究发现。
4.2.4.6 家族密度和真/假词效应之间的关系
本实验研究了家族密度和真/假词因素间的交互作用,与Van Heuven等人(1998)运用了相同的词汇判断范式和刺激材料。Van Heuven等人(1998)观察到英语单语者被试组和荷英双语者被试组显现出了相同的效应类型:当假词目标词的英语家族词的数量增加时,反应时也相应增加(抑制效应),即对于单语者和双语者来说,排除大家族的假词要比排除小家族的假词花费更长的时间。但对于汉英双语者来说,对小家族的真词反应得更慢,对大家族的假词反应得更快。因此,汉英双语者(母语为汉语)和荷英双语者(母语为荷兰语)在家族密度和假词因素间的交互作用方面表现出了差异。
Van Heuven等人(1998)还认为母语目标词的出现对于双语者的假词判断具有决定性的影响。当双语者运用L2进行听说和阅读时,L1中的信息仍然处于激活状态。相对于Van Heuven等人(1998)实验中以拼音文字为母语的被试,汉英双语被试受到母语汉语(非拼音文字)的干扰相对较少,而荷英双语被试受到母语荷兰语(拼音文字)的影响则更加明显,即母语和L2所属的语系不同也影响了被试对假词的辨认表现。当然,这一观点仍需更多定性、定量的研究加以支撑。
4.2.5 结论
(1)本实验的主要目的之一是研究汉英双语者的L2水平和性别差异对英语词汇辨认的影响。在对被试间变量(L2水平,性别差异)和被试内变量(家族密度,词频,真词和假词)交互作用的分析表明,较高的L2水平可以促进汉英双语者在词汇判断任务中的英语词汇辨认,但性别差异并无明显作用。尽管L2水平较高的被试在实验中的表现好于L2水平较低的被试,L2水平较高的汉英双语者能够对大脑词库的相对激活施加更大程度控制的这一观点仍需更多定性和定量的研究来加以证实。
(2)实验的另外一个主要目的是研究汉英双语者在英语词汇辨认中受家族密度、词频及真词/假词因素的影响。汉英双语者对大家族的高频真词辨认得最快、最准确。家族密度和词频因素在汉英双语者的英语词汇辨认中均呈现出了促进作用,这一发现与以往在拼音文字中的研究发现相似。家族密度和词频间的交互作用呈现了相互促进的趋势,这一发现与以往的发现有所不同。家族密度和假词间的交互作用为,家族密度越大,对真词的反应时越小,对假词的反应时越大;对真词的准确率越高,对假词的准确率越低。所以,简单说,家族密度对真词呈现了促进作用,对汉英双语者的假词辨认呈现了抑制作用。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











