



【摘要】:用于机器学习的最常见的贝叶斯网络模型很可能就是朴素贝叶斯模型。这大概是因为真实假设——是一棵决策树——无法通过朴素贝叶斯模型精确地表示。最后,朴素贝叶斯学习可以轻松地应付有噪声的数据,并在适当的时候给出概率预测。图20.3 把朴素贝叶斯学习方法应用于第十八章的餐馆问题得到的学习曲线;同时显示了使用决策树学习得到的学习曲线,作为对比
20.2.2 朴素贝叶斯模型
用于机器学习的最常见的贝叶斯网络模型很可能就是朴素贝叶斯模型。在这个模型中,“类”变量C(需要进行预测)是根节点,而“属性”变量Xi是叶节点。之所以这个模型是“朴素的”,是因为对于给定的类,它假定了各个属性彼此是条件独立的。(图20.2(b)中的模型是只有一个属性的朴素贝叶斯模型。)假设使用布尔型变量,则参数为
θ= P(C = true), θi1= P(Xi= true|C = true), θi2= P(Xi= true|C = false)
最大似然参数值通过与图 20.2(b)中完全相同的方式得到。一旦模型经过这种方式的训练,它就可以用于对类变量C尚未观察到的新实例进行分类。根据观察到的属性值x1, ... , xn,可以给出每个类的概率如下:
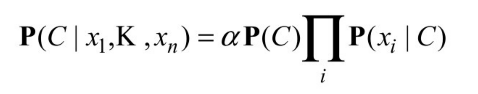
通过选取最可能的类可以得到确定性的预测。图20.3显示了当这种方法用于第十八章中的餐馆问题时得到的学习曲线。该方法学习的效果很好,尽管比不上决策树学习方法。这大概是因为真实假设——是一棵决策树——无法通过朴素贝叶斯模型精确地表示。当然,事实上朴素贝叶斯学习在很宽范围的应用中都有出人意料的好效果,它的经过 boost 改进的版本(习题 20.5)是最有效的通用学习算法之一。朴素贝叶斯学习可以很好地扩展到超大规模的问题:如果有n个布尔属性,就有2n+1个参数,并且不需要通过搜索来寻找最大似然的朴素贝叶斯假设hML。最后,朴素贝叶斯学习可以轻松地应付有噪声的数据,并在适当的时候给出概率预测。
图20.3 把朴素贝叶斯学习方法应用于第十八章的餐馆问题得到的学习曲线;同时显示了使用决策树学习得到的学习曲线,作为对比
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。











